
В
линейной регрессии обычно оценивается
значимость не только уравнения в целом,
но и отдельных его параметров. С этой
целью по каждому из параметров определяется
его стандартная ошибка: тb
и
та.
Стандартная
ошибка коэффициента регрессии параметра
b
рассчитывается
по формуле:
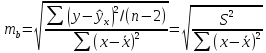
Где
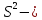
остаточная дисперсия на одну степень
свободы.
Отношение
коэффициента регрессии к его стандартной
ошибке дает t-статистику,
которая подчиняется статистике Стьюдента
при
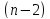
степенях
свободы. Эта статистика применяется
для проверки статистической значимости
коэффициента регрессии и для расчета
его доверительных интервалов.
Для
оценки значимости коэффициента регрессии
его величину сравнивают с его стандартной
ошибкой, т.е. определяют фактическое
значение t-критерия
Стьюдента:
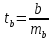 ,
,
которое затем сравнивают с табличным
значением при определенном уровне
значимостиα
и
числе степеней свободы
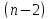 .
.
Справедливо
равенство
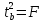
Доверительный
интервал для коэффициента регрессии
определяется как
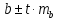 .
.
Стандартная
ошибка параметра а
определяется
по формуле
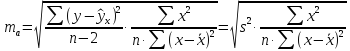
Процедура
оценивания значимости данного параметра
не отличается от рассмотренной выше
для коэффициента регрессии: вычисляется
t-критерий:
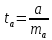
Его
величина сравнивается с табличным
значением при
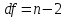
степенях свободы.
Значимость
линейного коэффициента корреляции
проверяется на основе величины ошибки
коэффициента корреляции mr:
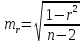
Фактическое
значение t-критерия
Стьюдента определяется как
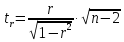
Данная
формула свидетельствует, что в парной
линейной регрессии
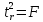 ,
,
ибо как уже указывалось,
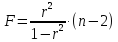 .
.
Кроме того,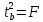 ,
,
следовательно,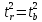 .
.
Таким
образом, проверка гипотез о значимости
коэффициентов регрессии и корреляции
равносильна проверке гипотезы о
значимости линейного уравнения регрессии.
Рассмотренную
формулу оценки коэффициента корреляции
рекомендуется применять при большом
числе наблюдений, а также если r
не близко к +1 или –1.
2.3 Интервальный прогноз на основе линейного уравнения регрессии
В
прогнозных расчетах по уравнению
регрессии определяется предсказываемое
yр
значение
как точечный прогноз
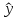 х
х
при
хр
= хk
т.
е. путем подстановки в линейное уравнение
регрессии
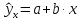
соответствующего
значения х.
Однако
точечный прогноз явно нереален, поэтому
он дополняется расчетом стандартной
ошибки
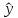 х,
х,
т.
е.
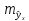 ,
,
и
соответственно мы получаем интервальную
оценку прогнозного значения у*:
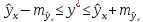
Считая,
что прогнозное значение фактора хр
= хk
получим
следующую формулу расчета стандартной
ошибки предсказываемого по линии
регрессии значения, т. е.
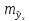
имеет выражение:
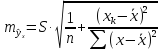
Рассмотренная
формула стандартной ошибки предсказываемого
среднего значения у
при
заданном значении хk
характеризует
ошибку положения линии регрессии.
Величина стандартной ошибки
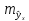 достигает
достигает
минимума при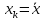
и
возрастает по мере того, как «удаляется»
от
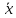 в любом направлении. Иными словами, чем
в любом направлении. Иными словами, чем
больше разность между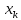 и
и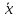 ,
,
тем больше ошибка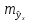 ,
,
с
которой предсказывается среднее значение
у
для
заданного значения
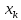 .
.
Можно ожидать наилучшие результаты
прогноза, если признак-фактор х находится
в центре области наблюдений х, и нельзя
ожидать хороших результатов прогноза
при удалении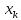 .
.
от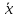 . Если же значение
. Если же значение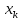 .
.
оказывается за пределами наблюдаемых
значенийх,
используемых при построении линейной
регрессии, то результаты прогноза
ухудшаются в зависимости от того,
насколько
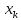 .
.
отклоняется от области наблюдаемых
значений факторах.
На
графике, приведенном на рис. 1, доверительные
границы для
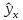
представляют
собой гиперболы, расположенные по обе
стороны от линии регрессии. Рис. 1
показывает, как изменяются пределы в
зависимости от изменения
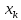 .:
.:
две гиперболы по обе стороны от линии
регрессии определяют 95 %-ные доверительные
интервалы для среднего значенияу
при
заданном значении х.
Однако
фактические значения у
варьируют
около среднего значения
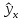 .
.
Индивидуальные
значения у
могут
отклоняться от
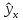
на
величину случайной ошибки ε, дисперсия
которой оценивается как остаточная
дисперсия на одну степень свободы
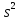 .
.
Поэтому ошибка предсказываемого
индивидуального значенияу
должна включать не только стандартную
ошибку
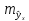 ,
,
но и случайную ошибкуs.
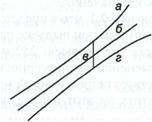
Рис.
1. Доверительный интервал линии регрессии:
а
— верхняя
доверительная граница; б
— линия
регрессии;
в
— доверительный
интервал для
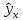
при
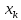 ;
;
г
— нижняя
доверительная граница.
Средняя
ошибка прогнозируемого индивидуального
значения у
составит:
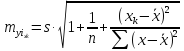
При
прогнозировании на основе уравнения
регрессии следует помнить, что величина
прогноза зависит не только от стандартной
ошибки индивидуального значения у,
но
и от точности прогноза значения фактора
х.
Его
величина может задаваться на основе
анализа других моделей исходя из
конкретной ситуации, а также анализа
динамики данного фактора.
Рассмотренная
формула средней ошибки индивидуального
значения признака у
 может
может
быть использована также для оценки
существенности различия предсказываемого
значения и некоторого гипотетического
значения.
11
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
Регрессия позволяет прогнозировать зависимую переменную на основании значений фактора. В
MS
EXCEL
имеется множество функций, которые возвращают не только наклон и сдвиг линии регрессии, характеризующей линейную взаимосвязь между факторами, но и регрессионную статистику. Здесь рассмотрим простую линейную регрессию, т.е. прогнозирование на основе одного фактора.
Disclaimer
: Данную статью не стоит рассматривать, как пересказ главы из учебника по статистике. Статья не обладает ни полнотой, ни строгостью изложения положений статистической науки. Эта статья – о применении MS EXCEL для целей
Регрессионного анализа.
Теоретические отступления приведены лишь из соображения логики изложения. Использование данной статьи для изучения
Регрессии
– плохая идея.
Статья про
Регрессионный анализ
получилась большая, поэтому ниже для удобства приведены ее разделы:
- Немного теории и основные понятия
- Предположения линейной регрессионной модели
- Задачи регрессионного анализа
- Оценка неизвестных параметров линейной модели (используя функции MS EXCEL)
- Оценка неизвестных параметров линейной модели (через статистики выборок)
- Оценка неизвестных параметров линейной модели (матричная форма)
- Построение линии регрессии
- Коэффициент детерминации
- Стандартная ошибка регрессии
- Стандартные ошибки и доверительные интервалы для наклона и сдвига
- Проверка значимости взаимосвязи переменных
- Доверительные интервалы для нового наблюдения Y и среднего значения
- Проверка адекватности линейной регрессионной модели
Примечание
: Если прогнозирование переменной осуществляется на основе нескольких факторов, то имеет место
множественная регрессия
.
Чтобы разобраться, чем может помочь MS EXCEL при проведении регрессионного анализа, напомним вкратце теорию, введем термины и обозначения, которые могут отличаться в зависимости от различных источников.
Примечание
: Для тех, кому некогда, незачем или просто не хочется разбираться в теоретических выкладках предлагается сразу перейти к вычислительной части —
оценке неизвестных параметров линейной модели
.
Немного теории и основные понятия
Пусть у нас есть массив данных, представляющий собой значения двух переменных Х и Y. Причем значения переменной Х мы можем произвольно задавать (контролировать) и использовать эту переменную для предсказания значений зависимой переменной Y. Таким образом, случайной величиной является только переменная Y.
Примером такой задачи может быть производственный процесс изготовления некого волокна, причем
прочность этого волокна
(Y) зависит только от
рабочей температуры процесса
в реакторе (Х), которая задается оператором.
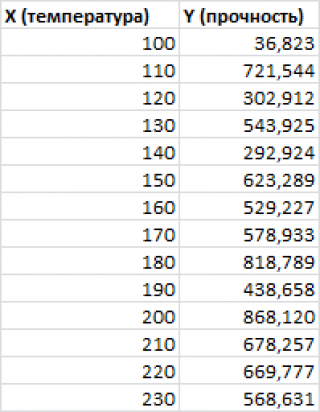
Построим
диаграмму рассеяния
(см.
файл примера лист Линейный
), созданию которой
посвящена отдельная статья
. Вообще, построение
диаграммы рассеяния
для целей
регрессионного анализа
де-факто является стандартом.
СОВЕТ
: Подробнее о построении различных типов диаграмм см. статьи
Основы построения диаграмм
и
Основные типы диаграмм
.
Приведенная выше
диаграмма рассеяния
свидетельствует о возможной
линейной взаимосвязи
между Y от Х: очевидно, что точки данных в основном располагаются вдоль прямой линии.
Примечание
: Наличие даже такой очевидной
линейной взаимосвязи
не может являться доказательством о наличии причинной взаимосвязи переменных. Наличие
причинной
взаимосвязи не может быть доказано на основании только анализа имеющихся измерений, а должно быть обосновано с помощью других исследований, например теоретических выкладок.
Примечание
: Как известно, уравнение прямой линии имеет вид
Y
=
m
*
X
+
k
, где коэффициент
m
отвечает за наклон линии (
slope
),
k
– за сдвиг линии по вертикали (
intercept
),
k
равно значению Y при Х=0.
Предположим, что мы можем зафиксировать переменную Х (
рабочую температуру процесса
) при некотором значении Х
i
и произвести несколько наблюдений переменной Y (
прочность нити
). Очевидно, что при одном и том же значении Хi мы получим различные значения Y. Это обусловлено влиянием других факторов на Y. Например, локальные колебания давления в реакторе, концентрации раствора, наличие ошибок измерения и др. Предполагается, что воздействие этих факторов имеет случайную природу и для каждого измерения имеются одинаковые условия проведения эксперимента (т.е. другие факторы не изменяются).
Полученные значения Y, при заданном Хi, будут колебаться вокруг некого
значения
. При увеличении количества измерений, среднее этих измерений, будет стремиться к
математическому ожиданию
случайной величины Y (при Х
i
) равному μy(i)=Е(Y
i
).
Подобные рассуждения можно привести для любого значения Хi.
Чтобы двинуться дальше, воспользуемся материалом из раздела
Проверка статистических гипотез
. В статье о
проверке гипотезы о среднем значении генеральной совокупности
в качестве
нулевой
гипотезы
предполагалось равенство неизвестного значения μ заданному μ0.
В нашем случае
простой линейной регрессии
в качестве
нулевой
гипотезы
предположим, что между переменными μy(i) и Хi существует линейная взаимосвязь μ
y(i)
=α* Х
i
+β. Уравнение μ
y(i)
=α* Х
i
+β можно переписать в обобщенном виде (для всех Х и μ
y
) как μ
y
=α* Х +β.
Для наглядности проведем прямую линию соединяющую все μy(i).
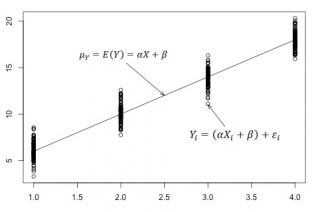
Данная линия называется
регрессионной линией генеральной совокупности
(population regression line), параметры которой (
наклон
a и
сдвиг β
) нам не известны (по аналогии с
гипотезой о среднем значении генеральной совокупности
, где нам было неизвестно истинное значение μ).
Теперь сделаем переход от нашего предположения, что μy=a* Х +
β
, к предсказанию значения случайной переменной Y в зависимости от значения контролируемой переменной Х. Для этого уравнение связи двух переменных запишем в виде Y=a*X+β+ε, где ε — случайная ошибка, которая отражает суммарный эффект влияния других факторов на Y (эти «другие» факторы не участвуют в нашей модели). Напомним, что т.к. переменная Х фиксирована, то ошибка ε определяется только свойствами переменной Y.
Уравнение Y=a*X+b+ε называют
линейной регрессионной моделью
. Часто Х еще называют
независимой переменной
(еще
предиктором
и
регрессором
, английский термин
predictor
,
regressor
), а Y –
зависимой
(или
объясняемой
,
response
variable
). Так как
регрессор
у нас один, то такая модель называется
простой линейной регрессионной моделью
(
simple
linear
regression
model
). α часто называют
коэффициентом регрессии.
Предположения линейной регрессионной модели перечислены в следующем разделе.
Предположения линейной регрессионной модели
Чтобы модель линейной регрессии Yi=a*Xi+β+ε
i
была адекватной — требуется:
- Ошибки ε
i
должны быть независимыми переменными; - При каждом значении Xi ошибки ε
i
должны быть иметь нормальное распределение (также предполагается равенство нулю математического ожидания, т.е. Е[ε
i
]=0); - При каждом значении Xi ошибки ε
i
должны иметь равные дисперсии (обозначим ее σ
2
).
Примечание
: Последнее условие называется
гомоскедастичность
— стабильность, гомогенность дисперсии случайной ошибки e. Т.е.
дисперсия
ошибки σ
2
не должна зависеть от значения Xi.
Используя предположение о равенстве математического ожидания Е[ε
i
]=0 покажем, что μy(i)=Е[Yi]:
Е[Yi]= Е[a*Xi+β+ε
i
]= Е[a*Xi+β]+ Е[ε
i
]= a*Xi+β= μy(i), т.к. a, Xi и β постоянные значения.
Дисперсия
случайной переменной Y равна
дисперсии
ошибки ε, т.е. VAR(Y)= VAR(ε)=σ
2
. Это является следствием, что все значения переменной Х являются const, а VAR(ε)=VAR(ε
i
).
Задачи регрессионного анализа
Для проверки гипотезы о линейной взаимосвязи переменной Y от X делают выборку из генеральной совокупности (этой совокупности соответствует
регрессионная линия генеральной совокупности
, т.е. μy=a* Х +β). Выборка будет состоять из n точек, т.е. из n пар значений {X;Y}.
На основании этой выборки мы можем вычислить оценки наклона a и сдвига β, которые обозначим соответственно
a
и
b
. Также часто используются обозначения â и b̂.
Далее, используя эти оценки, мы также можем проверить гипотезу: имеется ли линейная связь между X и Y статистически значимой?
Таким образом:
Первая задача
регрессионного анализа
– оценка неизвестных параметров (
estimation
of
the
unknown
parameters
). Подробнее см. раздел
Оценки неизвестных параметров модели
.
Вторая задача
регрессионного анализа
–
Проверка адекватности модели
(
model
adequacy
checking
).
Примечание
: Оценки параметров модели обычно вычисляются
методом наименьших квадратов
(МНК),
которому посвящена отдельная статья
.
Оценка неизвестных параметров линейной модели (используя функции MS EXCEL)
Неизвестные параметры
простой линейной регрессионной модели
Y=a*X+β+ε оценим с помощью
метода наименьших квадратов
(в
статье про МНК подробно описано этот метод
).
Для вычисления параметров линейной модели методом МНК получены следующие выражения:
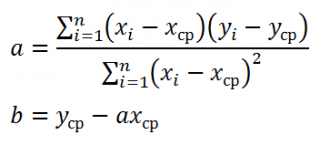
Таким образом, мы получим уравнение прямой линии Y=
a
*X+
b
, которая наилучшим образом аппроксимирует имеющиеся данные.
Примечание
: В статье про
метод наименьших квадратов
рассмотрены случаи аппроксимации
линейной
и
квадратичной функцией
, а также
степенной
,
логарифмической
и
экспоненциальной функцией
.
Оценку параметров в MS EXCEL можно выполнить различными способами:
- с помощью функций
НАКЛОН()
и
ОТРЕЗОК()
; - с помощью функции
ЛИНЕЙН()
; см. статьюФункция MS EXCEL ЛИНЕЙН()
- формулами через статистики выборок
;
- в матричной форме
;
- с помощью
инструмента Регрессия надстройки Пакет Анализа
.
Сначала рассмотрим функции
НАКЛОН()
,
ОТРЕЗОК()
и
ЛИНЕЙН()
.
Пусть значения Х и Y находятся соответственно в диапазонах
C
23:
C
83
и
B
23:
B
83
(см.
файл примера
внизу статьи).
Примечание
: Значения двух переменных Х и Y можно сгенерировать, задав тренд и величину случайного разброса (см. статью
Генерация данных для линейной регрессии в MS EXCEL
).
В MS EXCEL наклон прямой линии
а
(
оценку
коэффициента регрессии
), можно найти по
методу МНК
с помощью функции
НАКЛОН()
, а сдвиг
b
(
оценку
постоянного члена
или
константы регрессии
), с помощью функции
ОТРЕЗОК()
. В английской версии это функции SLOPE и INTERCEPT соответственно.
Аналогичный результат можно получить с помощью функции
ЛИНЕЙН()
, английская версия LINEST (см.
статью об этой функции
).
Формула
=ЛИНЕЙН(C23:C83;B23:B83)
вернет наклон
а
. А формула =
ИНДЕКС(ЛИНЕЙН(C23:C83;B23:B83);2)
— сдвиг
b
. Здесь требуются пояснения.
Функция
ЛИНЕЙН()
имеет 4 аргумента и возвращает целый массив значений:
ЛИНЕЙН(известные_значения_y; [известные_значения_x]; [конст]; [статистика])
Если 4-й аргумент
статистика
имеет значение ЛОЖЬ или опущен, то функция
ЛИНЕЙН()
возвращает только оценки параметров модели:
a
и
b
.
Примечание
: Остальные значения, возвращаемые функцией
ЛИНЕЙН()
, нам потребуются при вычислении
стандартных ошибок
и для
проверки значимости регрессии
. В этом случае аргумент
статистика
должен иметь значение ИСТИНА.
Чтобы вывести сразу обе оценки:
- в одной строке необходимо выделить 2 ячейки,
- ввести формулу в
Строке формул
- нажать
CTRL
+
SHIFT
+
ENTER
(см. статью проформулы массива
).
Если в
Строке формул
выделить формулу =
ЛИНЕЙН(C23:C83;B23:B83)
и нажать
клавишу F9
, то мы увидим что-то типа {3,01279389265416;154,240057900613}. Это как раз значения
a
и
b
. Как видно, оба значения разделены точкой с запятой «;», что свидетельствует, что функция вернула значения «в нескольких ячейках одной строки».
Если требуется вывести параметры линии не в одной строке, а одном столбце (ячейки друг под другом), то используйте формулу =
ТРАНСП(ЛИНЕЙН(C23:C83;B23:B83))
. При этом выделять нужно 2 ячейки в одном столбце. Если теперь выделить новую формулу и нажать клавишу F9, то мы увидим что 2 значения разделены двоеточием «:», что означает, что значения выведены в столбец (функция
ТРАНСП()
транспонировала строку в столбец
).
Чтобы разобраться в этом подробнее необходимо ознакомиться с
формулами массива
.
Чтобы не связываться с вводом
формул массива
, можно
использовать функцию ИНДЕКС()
. Формула =
ИНДЕКС(ЛИНЕЙН(C23:C83;B23:B83);1)
или просто
ЛИНЕЙН(C23:C83;B23:B83)
вернет параметр, отвечающий за наклон линии, т.е.
а
. Формула
=ИНДЕКС(ЛИНЕЙН(C23:C83;B23:B83);2)
вернет параметр
b
.
Оценка неизвестных параметров линейной модели (через статистики выборок)
Наклон линии, т.е. коэффициент
а
, можно также вычислить через
коэффициент корреляции
и
стандартные отклонения выборок
:
=
КОРРЕЛ(B23:B83;C23:C83) *(СТАНДОТКЛОН.В(C23:C83)/ СТАНДОТКЛОН.В(B23:B83))
Вышеуказанная формула математически эквивалентна отношению
ковариации
выборок Х и Y и
дисперсии
выборки Х:
=
КОВАРИАЦИЯ.В(B23:B83;C23:C83)/ДИСП.В(B23:B83)
И, наконец, запишем еще одну формулу для нахождения сдвига
b
. Воспользуемся тем фактом, что
линия регрессии
проходит через точку
средних значений
переменных Х и Y.
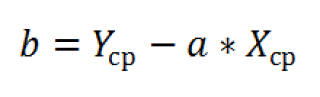
Вычислив
средние значения
и подставив в формулу ранее найденный наклон
а
, получим сдвиг
b
.
Оценка неизвестных параметров линейной модели (матричная форма)
Также параметры
линии регрессии
можно найти в матричной форме (см.
файл примера лист Матричная форма
).
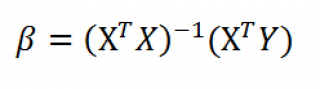
В формуле символом β обозначен столбец с искомыми параметрами модели: β0 (сдвиг
b
), β1 (наклон
a
).
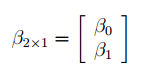
Матрица Х равна:
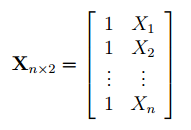
Матрица
Х
называется
регрессионной матрицей
или
матрицей плана
. Она состоит из 2-х столбцов и n строк, где n – количество точек данных. Первый столбец — столбец единиц, второй – значения переменной Х.
Матрица
Х
T
– это
транспонированная матрица
Х
. Она состоит соответственно из n столбцов и 2-х строк.
В формуле символом
Y
обозначен столбец значений переменной Y.
Чтобы
перемножить матрицы
используйте функцию
МУМНОЖ()
. Чтобы
найти обратную матрицу
используйте функцию
МОБР()
.
Пусть дан массив значений переменных Х и Y (n=10, т.е.10 точек).
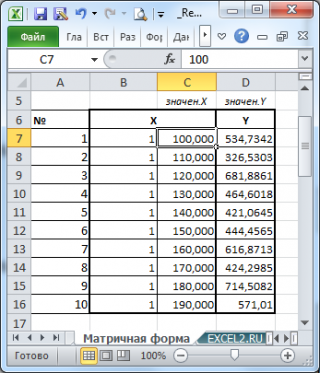
Слева от него достроим столбец с 1 для матрицы Х.
Записав формулу
=
МУМНОЖ(МОБР(МУМНОЖ(ТРАНСП(B7:C16);(B7:C16))); МУМНОЖ(ТРАНСП(B7:C16);(D7:D16)))
и введя ее как
формулу массива
в 2 ячейки, получим оценку параметров модели.
Красота применения матричной формы полностью раскрывается в случае
множественной регрессии
.
Построение линии регрессии
Для отображения
линии регрессии
построим сначала
диаграмму рассеяния
, на которой отобразим все точки (см.
начало статьи
).
Для построения прямой линии используйте вычисленные выше оценки параметров модели
a
и
b
(т.е. вычислите
у
по формуле
y
=
a
*
x
+
b
) или функцию
ТЕНДЕНЦИЯ()
.
Формула =
ТЕНДЕНЦИЯ($C$23:$C$83;$B$23:$B$83;B23)
возвращает расчетные (прогнозные) значения ŷi для заданного значения Хi из столбца
В2
.
Примечание
:
Линию регрессии
можно также построить с помощью функции
ПРЕДСКАЗ()
. Эта функция возвращает прогнозные значения ŷi, но, в отличие от функции
ТЕНДЕНЦИЯ()
работает только в случае одного регрессора. Функция
ТЕНДЕНЦИЯ()
может быть использована и в случае
множественной регрессии
(в этом случае 3-й аргумент функции должен быть ссылкой на диапазон, содержащий все значения Хi для выбранного наблюдения i).
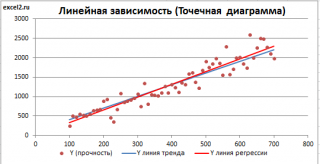
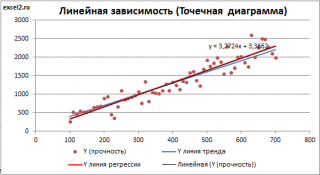
Как видно из диаграммы выше
линия тренда
и
линия регрессии
не обязательно совпадают: отклонения точек от
линии тренда
случайны, а МНК лишь подбирает линию наиболее точно аппроксимирующую случайные точки данных.
Линию регрессии
можно построить и с помощью встроенных средств диаграммы, т.е. с помощью инструмента
Линия тренда.
Для этого выделите диаграмму, в меню выберите
вкладку Макет
, в
группе Анализ
нажмите
Линия тренда
, затем
Линейное приближение.
В диалоговом окне установите галочку
Показывать уравнение на диаграмме
(подробнее см. в
статье про МНК
).
Построенная таким образом линия, разумеется, должна совпасть с ранее построенной нами
линией регрессии,
а параметры уравнения
a
и
b
должны совпасть с параметрами уравнения отображенными на диаграмме.
Примечание:
Для того, чтобы вычисленные параметры уравнения
a
и
b
совпадали с параметрами уравнения на диаграмме, необходимо, чтобы тип у диаграммы был
Точечная, а не График
, т.к. тип диаграммы
График
не использует значения Х, а вместо значений Х используется последовательность 1; 2; 3; … Именно эти значения и берутся при расчете параметров
линии тренда
. Убедиться в этом можно если построить диаграмму
График
(см.
файл примера
), а значения
Хнач
и
Хшаг
установить равным 1. Только в этом случае параметры уравнения на диаграмме совпадут с
a
и
b
.
Коэффициент детерминации R
2
Коэффициент детерминации
R
2
показывает насколько полезна построенная нами
линейная регрессионная модель
.
Предположим, что у нас есть n значений переменной Y и мы хотим предсказать значение yi, но без использования значений переменной Х (т.е. без построения
регрессионной модели
). Очевидно, что лучшей оценкой для yi будет
среднее значение
ȳ. Соответственно, ошибка предсказания будет равна (yi — ȳ).
Примечание
: Далее будет использована терминология и обозначения
дисперсионного анализа
.
После построения
регрессионной модели
для предсказания значения yi мы будем использовать значение ŷi=a*xi+b. Ошибка предсказания теперь будет равна (yi — ŷi).
Теперь с помощью диаграммы сравним ошибки предсказания полученные без построения модели и с помощью модели.
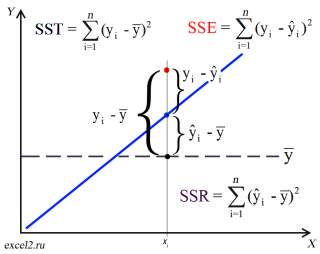
Очевидно, что используя
регрессионную модель
мы уменьшили первоначальную (полную) ошибку (yi — ȳ) на значение (ŷi — ȳ) до величины (yi — ŷi).
(yi — ŷi) – это оставшаяся, необъясненная ошибка.
Очевидно, что все три ошибки связаны выражением:
(yi — ȳ)= (ŷi — ȳ) + (yi — ŷi)
Можно показать, что в общем виде справедливо следующее выражение:
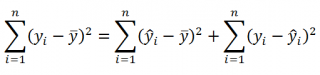
Доказательство:
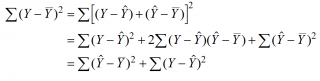
или в других, общепринятых в зарубежной литературе, обозначениях:
SST
=
SSR
+
SSE
Что означает:
Total Sum of Squares
=
Regression Sum of Squares
+
Error Sum of Squares
Примечание
: SS — Sum of Squares — Сумма Квадратов.
Как видно из формулы величины SST, SSR, SSE имеют размерность
дисперсии
(вариации) и соответственно описывают разброс (изменчивость):
Общую изменчивость
(Total variation),
Изменчивость объясненную моделью
(Explained variation) и
Необъясненную изменчивость
(Unexplained variation).
По определению
коэффициент детерминации
R
2
равен:
R
2
=
Изменчивость объясненная моделью / Общая изменчивость.
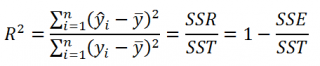
Этот показатель равен квадрату
коэффициента корреляции
и в MS EXCEL его можно вычислить с помощью функции
КВПИРСОН()
или
ЛИНЕЙН()
:
=
ИНДЕКС(ЛИНЕЙН(C23:C83;B23:B83;;ИСТИНА);3)
R
2
принимает значения от 0 до 1 (1 соответствует идеальной линейной зависимости Y от Х). Однако, на практике малые значения R2 вовсе не обязательно указывают, что переменную Х нельзя использовать для прогнозирования переменной Y. Малые значения R2 могут указывать на нелинейность связи или на то, что поведение переменной Y объясняется не только Х, но и другими факторами.
Стандартная ошибка регрессии
Стандартная ошибка регрессии
(
Standard Error of a regression
) показывает насколько велика ошибка предсказания значений переменной Y на основании значений Х. Отдельные значения Yi мы можем предсказывать лишь с точностью +/- несколько значений (обычно 2-3, в зависимости от формы распределения ошибки ε).
Теперь вспомним уравнение
линейной регрессионной модели
Y=a*X+β+ε. Ошибка ε имеет случайную природу, т.е. является случайной величиной и поэтому имеет свою функцию распределения со
средним значением
μ и
дисперсией
σ
2
.
Оценив значение
дисперсии
σ
2
и вычислив из нее квадратный корень – получим
Стандартную ошибку регрессии.
Чем точки наблюдений на диаграмме
рассеяния
ближе находятся к прямой линии, тем меньше
Стандартная ошибка.
Примечание
:
Вспомним
, что при построении модели предполагается, что
среднее значение
ошибки ε равно 0, т.е. E[ε]=0.
Оценим
дисперсию σ
2
. Помимо вычисления
Стандартной ошибки регрессии
эта оценка нам потребуется в дальнейшем еще и при построении
доверительных интервалов
для оценки параметров регрессии
a
и
b
.
Для оценки
дисперсии
ошибки ε используем
остатки регрессии
— разности между имеющимися значениями
yi
и значениями, предсказанными регрессионной моделью ŷ. Чем лучше регрессионная модель согласуется с данными (точки располагается близко к прямой линии), тем меньше величина остатков.
Для оценки
дисперсии σ
2
используют следующую формулу:
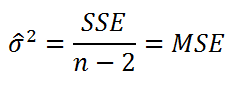
где SSE – сумма квадратов значений ошибок модели ε
i
=yi — ŷi (
Sum of Squared Errors
).
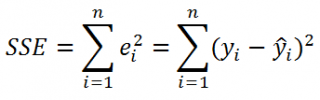
SSE часто обозначают и как SSres – сумма квадратов остатков (
Sum
of
Squared
residuals
).
Оценка
дисперсии
s
2
также имеет общепринятое обозначение MSE (Mean Square of Errors), т.е. среднее квадратов
ошибок
или MSRES (Mean Square of Residuals), т.е. среднее квадратов
остатков
. Хотя правильнее говорить сумме квадратов остатков, т.к. ошибка чаще ассоциируется с ошибкой модели ε, которая является непрерывной случайной величиной. Но, здесь мы будем использовать термины SSE и MSE, предполагая, что речь идет об остатках.
Примечание
: Напомним, что когда
мы использовали МНК
для нахождения параметров модели, то критерием оптимизации была минимизация именно SSE (SSres). Это выражение представляет собой сумму квадратов расстояний между наблюденными значениями yi и предсказанными моделью значениями ŷi, которые лежат на
линии регрессии.
Математическое ожидание
случайной величины MSE равно
дисперсии ошибки
ε, т.е.
σ
2
.
Чтобы понять почему SSE выбрана в качестве основы для оценки
дисперсии
ошибки ε, вспомним, что
σ
2
является также
дисперсией
случайной величины Y (относительно
среднего значения
μy, при заданном значении Хi). А т.к. оценкой μy является значение ŷi =
a
* Хi +
b
(значение
уравнения регрессии
при Х= Хi), то логично использовать именно SSE в качестве основы для оценки
дисперсии
σ
2
. Затем SSE усредняется на количество точек данных n за вычетом числа 2. Величина n-2 – это количество
степеней свободы
(
df
–
degrees
of
freedom
), т.е. число параметров системы, которые могут изменяться независимо (вспомним, что у нас в этом примере есть n независимых наблюдений переменной Y). В случае
простой линейной регрессии
число степеней свободы
равно n-2, т.к. при построении
линии регрессии
было оценено 2 параметра модели (на это было «потрачено» 2
степени свободы
).
Итак, как сказано было выше, квадратный корень из s
2
имеет специальное название
Стандартная ошибка регрессии
(
Standard Error of a regression
) и обозначается SEy. SEy показывает насколько велика ошибка предсказания. Отдельные значения Y мы можем предсказывать с точностью +/- несколько значений SEy (см.
этот раздел
). Если ошибки предсказания ε имеют
нормальное распределение
, то примерно 2/3 всех предсказанных значений будут на расстоянии не больше SEy от
линии регрессии
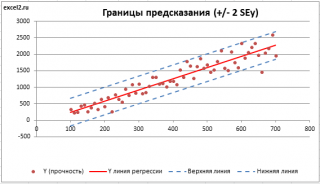
. SEy имеет размерность переменной Y и откладывается по вертикали. Часто на
диаграмме рассеяния
строят
границы предсказания
соответствующие +/- 2 SEy (т.е. 95% точек данных будут располагаться в пределах этих границ).
В MS EXCEL
стандартную ошибку
SEy можно вычислить непосредственно по формуле:
=
КОРЕНЬ(СУММКВРАЗН(C23:C83; ТЕНДЕНЦИЯ(C23:C83;B23:B83;B23:B83)) /( СЧЁТ(B23:B83) -2))
или с помощью функции
ЛИНЕЙН()
:
=
ИНДЕКС(ЛИНЕЙН(C23:C83;B23:B83;;ИСТИНА);3;2)
Примечание
: Подробнее о функции
ЛИНЕЙН()
см.
эту статью
.
Стандартные ошибки и доверительные интервалы для наклона и сдвига
В разделе
Оценка неизвестных параметров линейной модели
мы получили точечные оценки наклона
а
и сдвига
b
. Так как эти оценки получены на основе случайных величин (значений переменных Х и Y), то эти оценки сами являются случайными величинами и соответственно имеют функцию распределения со
средним значением
и
дисперсией
. Но, чтобы перейти от
точечных оценок
к
интервальным
, необходимо вычислить соответствующие
стандартные ошибки
(т.е.
стандартные отклонения
).
Стандартная ошибка коэффициента регрессии
a
вычисляется на основании
стандартной ошибки регрессии
по следующей формуле:
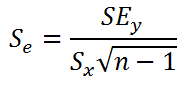
где Sx – стандартное отклонение величины х, вычисляемое по формуле:
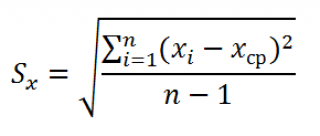
где Sey –
стандартная ошибка регрессии,
т.е. ошибка предсказания значения переменой Y
(
см. выше
).
В MS EXCEL
стандартную ошибку коэффициента регрессии
Se можно вычислить впрямую по вышеуказанной формуле:
=
КОРЕНЬ(СУММКВРАЗН(C23:C83; ТЕНДЕНЦИЯ(C23:C83;B23:B83;B23:B83)) /( СЧЁТ(B23:B83) -2))/ СТАНДОТКЛОН.В(B23:B83) /КОРЕНЬ(СЧЁТ(B23:B83) -1)
или с помощью функции
ЛИНЕЙН()
:
=
ИНДЕКС(ЛИНЕЙН(C23:C83;B23:B83;;ИСТИНА);2;1)
Формулы приведены в
файле примера на листе Линейный
в разделе
Регрессионная статистика
.
Примечание
: Подробнее о функции
ЛИНЕЙН()
см.
эту статью
.
При построении
двухстороннего доверительного интервала
для
коэффициента регрессии
его границы определяются следующим образом:
![]()
где —
квантиль распределения Стьюдента
с n-2 степенями свободы. Величина
а
с «крышкой» является другим обозначением
наклона
а
.
Например для
уровня значимости
альфа=0,05, можно вычислить с помощью формулы
=СТЬЮДЕНТ.ОБР.2Х(0,05;n-2)
Вышеуказанная формула следует из того факта, что если ошибки регрессии распределены нормально и независимо, то выборочное распределение случайной величины
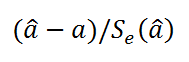
является
t-распределением Стьюдента
с n-2 степенью свободы (то же справедливо и для наклона
b
).
Примечание
: Подробнее о построении
доверительных интервалов
в MS EXCEL можно прочитать в этой статье
Доверительные интервалы в MS EXCEL
.
В результате получим, что найденный
доверительный интервал
с вероятностью 95% (1-0,05) накроет истинное значение
коэффициента регрессии.
Здесь мы считаем, что
коэффициент регрессии
a
имеет
распределение Стьюдента
с n-2
степенями свободы
(n – количество наблюдений, т.е. пар Х и Y).
Примечание
: Подробнее о построении
доверительных интервалов
с использованием t-распределения см. статью про построение
доверительных интервалов
для среднего
.
Стандартная ошибка сдвига
b
вычисляется по следующей формуле:
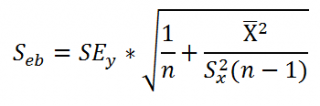
В MS EXCEL
стандартную ошибку сдвига
Seb можно вычислить с помощью функции
ЛИНЕЙН()
:
=
ИНДЕКС(ЛИНЕЙН(C23:C83;B23:B83;;ИСТИНА);2;2)
При построении
двухстороннего доверительного интервала
для
сдвига
его границы определяются аналогичным образом как для
наклона
:
b
+/- t*Seb.
Проверка значимости взаимосвязи переменных
Когда мы строим модель Y=αX+β+ε мы предполагаем, что между Y и X существует линейная взаимосвязь. Однако, как это иногда бывает в статистике, можно вычислять параметры связи даже тогда, когда в действительности она не существует, и обусловлена лишь случайностью.
Единственный вариант, когда Y не зависит X (в рамках модели Y=αX+β+ε), возможен, когда
коэффициент регрессии
a
равен 0.
Чтобы убедиться, что вычисленная нами оценка
наклона
прямой линии не обусловлена лишь случайностью (не случайно отлична от 0), используют
проверку гипотез
. В качестве
нулевой гипотезы
Н
0
принимают, что связи нет, т.е. a=0. В качестве альтернативной гипотезы
Н
1
принимают, что a <>0.
Ниже на рисунках показаны 2 ситуации, когда
нулевую гипотезу
Н
0
не удается отвергнуть.
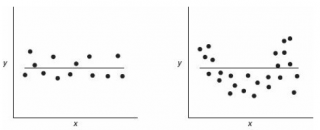
На левой картинке отсутствует любая зависимость между переменными, на правой – связь между ними нелинейная, но при этом
коэффициент линейной корреляции
равен 0.
Ниже — 2 ситуации, когда
нулевая гипотеза
Н
0
отвергается.
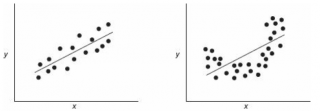
На левой картинке очевидна линейная зависимость, на правой — зависимость нелинейная, но коэффициент корреляции не равен 0 (метод МНК вычисляет показатели наклона и сдвига просто на основании значений выборки).
Для проверки гипотезы нам потребуется:
- Установить
уровень значимости
, пусть альфа=0,05;
- Рассчитать с помощью функции
ЛИНЕЙН()
стандартное отклонение
Se для
коэффициента регрессии
(см.предыдущий раздел
);
- Рассчитать число степеней свободы: DF=n-2 или по формуле =
ИНДЕКС(ЛИНЕЙН(C24:C84;B24:B84;;ИСТИНА);4;2)
- Вычислить значение тестовой статистики t
0
=a/S
e
, которая имеетраспределение Стьюдента
с
числом степеней свободы
DF=n-2; - Сравнить значение
тестовой статистики
|t0| с пороговым значением t
альфа
,n-2. Если значение
тестовой статистики
больше порогового значения, то
нулевая гипотеза
отвергается (
наклон
не может быть объяснен лишь случайностью при заданном уровне альфа) либо - вычислить
p-значение
и сравнить его с
уровнем значимости
.
В
файле примера
приведен пример проверки гипотезы:
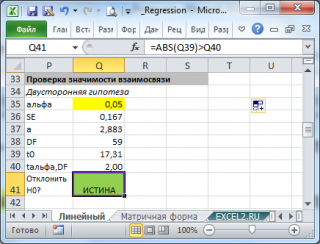
Изменяя
наклон
тренда k (ячейка
В8
) можно убедиться, что при малых углах тренда (например, 0,05) тест часто показывает, что связь между переменными случайна. При больших углах (k>1), тест практически всегда подтверждает значимость линейной связи между переменными.
Примечание
: Проверка значимости взаимосвязи эквивалентна
проверке статистической значимости коэффициента корреляции
. В
файле примера
показана эквивалентность обоих подходов. Также проверку значимости можно провести с помощью
процедуры F-тест
.
Доверительные интервалы для нового наблюдения Y и среднего значения
Вычислив параметры
простой линейной регрессионной модели
Y=aX+β+ε мы получили точечную оценку значения нового наблюдения Y при заданном значении Хi, а именно: Ŷ=
a
* Хi +
b
Ŷ также является точечной оценкой для
среднего значения
Yi при заданном Хi. Но, при построении
доверительных интервалов
используются различные
стандартные ошибки
.
Стандартная ошибка
нового наблюдения Y при заданном Хi учитывает 2 источника неопределенности:
- неопределенность связанную со случайностью оценок параметров модели
a
и
b
; - случайность ошибки модели ε.
Учет этих неопределенностей приводит к
стандартной ошибке
S(Y|Xi), которая рассчитывается с учетом известного значения Xi.
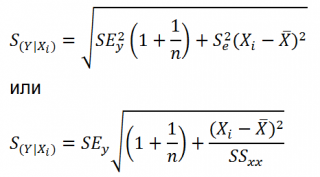
где SS
xx
– сумма квадратов отклонений от
среднего
значений переменной Х:
![]()
Примечание
: Se –
стандартная ошибка коэффициента регрессии
(
наклона
а
).
В
MS EXCEL 2010
нет функции, которая бы рассчитывала эту
стандартную ошибку
, поэтому ее необходимо рассчитывать по вышеуказанным формулам.
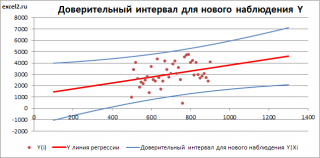
Доверительный интервал
или
Интервал предсказания для нового наблюдения
(Prediction Interval for a New Observation) построим по схеме показанной в разделе
Проверка значимости взаимосвязи переменных
(см.
файл примера лист Интервалы
). Т.к. границы интервала зависят от значения Хi (точнее от расстояния Хi до среднего значения Х
ср
), то интервал будет постепенно расширяться при удалении от Х
ср
.
Границы
доверительного интервала
для
нового наблюдения
рассчитываются по формуле:
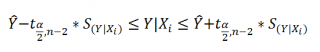
Аналогичным образом построим
доверительный интервал
для
среднего значения
Y при заданном Хi (Confidence Interval for the Mean of Y). В этом случае
доверительный интервал
будет уже, т.к.
средние значения
имеют меньшую изменчивость по сравнению с отдельными наблюдениями (
средние значения,
в рамках нашей линейной модели Y=aX+β+ε, не включают ошибку ε).
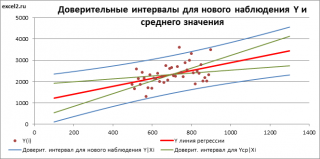
Стандартная ошибка
S(Yср|Xi) вычисляется по практически аналогичным формулам как и
стандартная ошибка
для нового наблюдения:
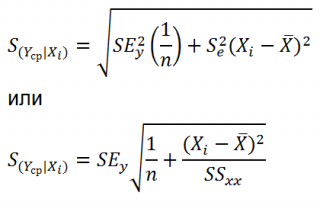
Как видно из формул,
стандартная ошибка
S(Yср|Xi) меньше
стандартной ошибки
S(Y|Xi) для индивидуального значения
.
Границы
доверительного интервала
для
среднего значения
рассчитываются по формуле:
![]()
Проверка адекватности линейной регрессионной модели
Модель адекватна, когда все предположения, лежащие в ее основе, выполнены (см. раздел
Предположения линейной регрессионной модели
).
Проверка адекватности модели в основном основана на исследовании остатков модели (model residuals), т.е. значений ei=yi – ŷi для каждого Хi. В рамках
простой линейной модели
n остатков имеют только n-2 связанных с ними
степеней свободы
. Следовательно, хотя, остатки не являются независимыми величинами, но при достаточно большом n это не оказывает какого-либо влияния на проверку адекватности модели.
Чтобы проверить предположение о
нормальности распределения
ошибок строят
график проверки на нормальность
(Normal probability Plot).
В
файле примера на листе Адекватность
построен
график проверки на нормальность
. В случае
нормального распределения
значения остатков должны быть близки к прямой линии.
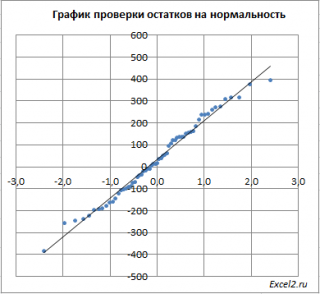
Так как значения переменной Y мы
генерировали с помощью тренда
, вокруг которого значения имели нормальный разброс, то ожидать сюрпризов не приходится – значения остатков располагаются вблизи прямой.
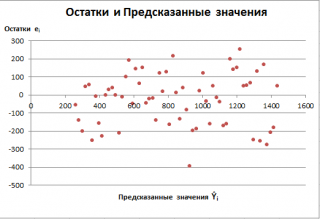
Также при проверке модели на адекватность часто строят график зависимости остатков от предсказанных значений Y. Если точки не демонстрируют характерных, так называемых «паттернов» (шаблонов) типа вор
о
нок или другого неравномерного распределения, в зависимости от значений Y, то у нас нет очевидных доказательств неадекватности модели.
В нашем случае точки располагаются примерно равномерно.
Часто при проверке адекватности модели вместо остатков используют нормированные остатки. Как показано в разделе
Стандартная ошибка регрессии
оценкой
стандартного отклонения ошибок
является величина SEy равная квадратному корню из величины MSE. Поэтому логично нормирование остатков проводить именно на эту величину.
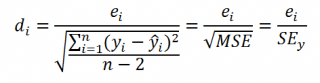
SEy можно вычислить с помощью функции
ЛИНЕЙН()
:
=
ИНДЕКС(ЛИНЕЙН(C23:C83;B23:B83;;ИСТИНА);3;2)
Иногда нормирование остатков производится на величину
стандартного отклонения
остатков (это мы увидим в статье об инструменте
Регрессия
, доступного в
надстройке MS EXCEL Пакет анализа
), т.е. по формуле:
Вышеуказанное равенство приблизительное, т.к. среднее значение остатков близко, но не обязательно точно равно 0.
По территориям региона приводятся данные за 200Х г.
| Номер региона | Среднедушевой прожиточный минимум в день одного трудоспособного, руб., х | Среднедневная заработная плата, руб., у |
|---|---|---|
| 1 | 78 | 133 |
| 2 | 82 | 148 |
| 3 | 87 | 134 |
| 4 | 79 | 154 |
| 5 | 89 | 162 |
| 6 | 106 | 195 |
| 7 | 67 | 139 |
| 8 | 88 | 158 |
| 9 | 73 | 152 |
| 10 | 87 | 162 |
| 11 | 76 | 159 |
| 12 | 115 | 173 |
Задание:
1. Постройте поле корреляции и сформулируйте гипотезу о форме связи.
2. Рассчитайте параметры уравнения линейной регрессии
 .
.
3. Оцените тесноту связи с помощью показателей корреляции и детерминации.
4. Дайте с помощью среднего (общего) коэффициента эластичности сравнительную оценку силы связи фактора с результатом.
5. Оцените с помощью средней ошибки аппроксимации качество уравнений.
6. Оцените с помощью F-критерия Фишера статистическую надёжность результатов регрессионного моделирования.
7. Рассчитайте прогнозное значение результата, если прогнозное значение фактора увеличится на 10% от его среднего уровня. Определите доверительный интервал прогноза для уровня значимости  .
.
8. Оцените полученные результаты, выводы оформите в аналитической записке.
Решение:
Решим данную задачу с помощью Excel.
1. Сопоставив имеющиеся данные х и у, например, ранжировав их в порядке возрастания фактора х, можно наблюдать наличие прямой зависимости между признаками, когда увеличение среднедушевого прожиточного минимума увеличивает среднедневную заработную плату. Исходя из этого, можно сделать предположение, что связь между признаками прямая и её можно описать уравнением прямой. Этот же вывод подтверждается и на основе графического анализа.
Чтобы построить поле корреляции можно воспользоваться ППП Excel. Введите исходные данные в последовательности: сначала х, затем у.
Выделите область ячеек, содержащую данные.
Затем выберете: Вставка / Точечная диаграмма / Точечная с маркерами как показано на рисунке 1.

Рисунок 1 Построение поля корреляции
Анализ поля корреляции показывает наличие близкой к прямолинейной зависимости, так как точки расположены практически по прямой линии.
2. Для расчёта параметров уравнения линейной регрессии
воспользуемся встроенной статистической функцией ЛИНЕЙН.
Для этого:
1) Откройте существующий файл, содержащий анализируемые данные;
2) Выделите область пустых ячеек 5×2 (5 строк, 2 столбца) для вывода результатов регрессионной статистики.
3) Активизируйте Мастер функций: в главном меню выберете Формулы / Вставить функцию.
4) В окне Категория выберете Статистические, в окне функция – ЛИНЕЙН. Щёлкните по кнопке ОК как показано на Рисунке 2;

Рисунок 2 Диалоговое окно «Мастер функций»
5) Заполните аргументы функции:
Известные значения у – диапазон, содержащий данные результативного признака;
Известные значения х – диапазон, содержащий данные факторного признака;
Константа – логическое значение, которое указывает на наличие или на отсутствие свободного члена в уравнении; если Константа = 1, то свободный член рассчитывается обычным образом, если Константа = 0, то свободный член равен 0;
Статистика – логическое значение, которое указывает, выводить дополнительную информацию по регрессионному анализу или нет. Если Статистика = 1, то дополнительная информация выводится, если Статистика = 0, то выводятся только оценки параметров уравнения.
Щёлкните по кнопке ОК;

Рисунок 3 Диалоговое окно аргументов функции ЛИНЕЙН
6) В левой верхней ячейке выделенной области появится первый элемент итоговой таблицы. Чтобы раскрыть всю таблицу, нажмите на клавишу <F2>, а затем на комбинацию клавиш <Ctrl>+<Shift>+<Enter>.
Дополнительная регрессионная статистика будет выводиться в порядке, указанном в следующей схеме:
| Значение коэффициента b | Значение коэффициента a |
| Стандартная ошибка b | Стандартная ошибка a |
| Коэффициент детерминации R2 | Стандартная ошибка y |
| F-статистика | Число степеней свободы df |
| Регрессионная сумма квадратов
|
Остаточная сумма квадратов
|



Рисунок 4 Результат вычисления функции ЛИНЕЙН
Получили уровнение регрессии:

Делаем вывод: С увеличением среднедушевого прожиточного минимума на 1 руб. среднедневная заработная плата возрастает в среднем на 0,92 руб.
3. Коэффициент детерминации  означает, что 52% вариации заработной платы (у) объясняется вариацией фактора х – среднедушевого прожиточного минимума, а 48% — действием других факторов, не включённых в модель.
означает, что 52% вариации заработной платы (у) объясняется вариацией фактора х – среднедушевого прожиточного минимума, а 48% — действием других факторов, не включённых в модель.
По вычисленному коэффициенту детерминации можно рассчитать коэффициент корреляции:  .
.
Связь оценивается как тесная.
4. С помощью среднего (общего) коэффициента эластичности определим силу влияния фактора на результат.
Для уравнения прямой средний (общий) коэффициент эластичности определим по формуле:

Средние значения найдём, выделив область ячеек со значениями х, и выберем Формулы / Автосумма / Среднее, и то же самое произведём со значениями у.

Рисунок 5 Расчёт средних значений функции и аргумент

Таким образом, при изменении среднедушевого прожиточного минимума на 1% от своего среднего значения среднедневная заработная плата изменится в среднем на 0,51%.
С помощью инструмента анализа данных Регрессия можно получить:
— результаты регрессионной статистики,
— результаты дисперсионного анализа,
— результаты доверительных интервалов,
— остатки и графики подбора линии регрессии,
— остатки и нормальную вероятность.
Порядок действий следующий:
1) проверьте доступ к Пакету анализа. В главном меню последовательно выберите: Файл/Параметры/Надстройки.
2) В раскрывающемся списке Управление выберите пункт Надстройки Excel и нажмите кнопку Перейти.
3) В окне Надстройки установите флажок Пакет анализа, а затем нажмите кнопку ОК.
• Если Пакет анализа отсутствует в списке поля Доступные надстройки, нажмите кнопку Обзор, чтобы выполнить поиск.
• Если выводится сообщение о том, что пакет анализа не установлен на компьютере, нажмите кнопку Да, чтобы установить его.
4) В главном меню последовательно выберите: Данные / Анализ данных / Инструменты анализа / Регрессия, а затем нажмите кнопку ОК.
5) Заполните диалоговое окно ввода данных и параметров вывода:
Входной интервал Y – диапазон, содержащий данные результативного признака;
Входной интервал X – диапазон, содержащий данные факторного признака;
Метки – флажок, который указывает, содержит ли первая строка названия столбцов или нет;
Константа – ноль – флажок, указывающий на наличие или отсутствие свободного члена в уравнении;
Выходной интервал – достаточно указать левую верхнюю ячейку будущего диапазона;
6) Новый рабочий лист – можно задать произвольное имя нового листа.
Затем нажмите кнопку ОК.

Рисунок 6 Диалоговое окно ввода параметров инструмента Регрессия
Результаты регрессионного анализа для данных задачи представлены на рисунке 7.

Рисунок 7 Результат применения инструмента регрессия
5. Оценим с помощью средней ошибки аппроксимации качество уравнений. Воспользуемся результатами регрессионного анализа представленного на Рисунке 8.

Рисунок 8 Результат применения инструмента регрессия «Вывод остатка»
Составим новую таблицу как показано на рисунке 9. В графе С рассчитаем относительную ошибку аппроксимации по формуле:


Рисунок 9 Расчёт средней ошибки аппроксимации
Средняя ошибка аппроксимации рассчитывается по формуле:

Качество построенной модели оценивается как хорошее, так как  не превышает 8 – 10%.
не превышает 8 – 10%.
6. Из таблицы с регрессионной статистикой (Рисунок 4) выпишем фактическое значение F-критерия Фишера: 

Поскольку  при 5%-ном уровне значимости, то можно сделать вывод о значимости уравнения регрессии (связь доказана).
при 5%-ном уровне значимости, то можно сделать вывод о значимости уравнения регрессии (связь доказана).
8. Оценку статистической значимости параметров регрессии проведём с помощью t-статистики Стьюдента и путём расчёта доверительного интервала каждого из показателей.
Выдвигаем гипотезу Н0 о статистически незначимом отличии показателей от нуля:
 .
.
 для числа степеней свободы
для числа степеней свободы 
На рисунке 7 имеются фактические значения t-статистики:

t-критерий для коэффициента корреляции можно рассчитать двумя способами:
I способ: 
где  – случайная ошибка коэффициента корреляции.
– случайная ошибка коэффициента корреляции.
Данные для расчёта возьмём из таблицы на Рисунке 7.

II способ: 
Фактические значения t-статистики превосходят табличные значения:


Поэтому гипотеза Н0 отклоняется, то есть параметры регрессии и коэффициент корреляции не случайно отличаются от нуля, а статистически значимы.
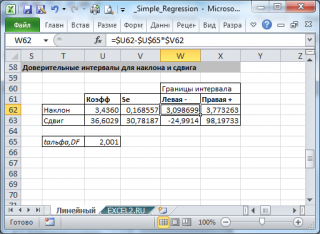
Доверительный интервал для параметра a определяется как

Для параметра a 95%-ные границы как показано на рисунке 7 составили:

Доверительный интервал для коэффициента регрессии определяется как

Для коэффициента регрессии b 95%-ные границы как показано на рисунке 7 составили:

Анализ верхней и нижней границ доверительных интервалов приводит к выводу о том, что с вероятностью  параметры a и b, находясь в указанных границах, не принимают нулевых значений, т.е. не являются статистически незначимыми и существенно отличны от нуля.
параметры a и b, находясь в указанных границах, не принимают нулевых значений, т.е. не являются статистически незначимыми и существенно отличны от нуля.
7. Полученные оценки уравнения регрессии позволяют использовать его для прогноза. Если прогнозное значение прожиточного минимума составит:

Тогда прогнозное значение прожиточного минимума составит:

Ошибку прогноза рассчитаем по формуле:

где 
Дисперсию посчитаем также с помощью ППП Excel. Для этого:
1) Активизируйте Мастер функций: в главном меню выберете Формулы / Вставить функцию.
2) В окне Категория выберете Статистические, в окне функция – ДИСП.Г. Щёлкните по кнопке ОК.
3) Заполните диапазон, содержащий числовые данные факторного признака. Нажмите ОК.

Рисунок 10 Расчёт дисперсии
Получили значение дисперсии 
Для подсчёта остаточной дисперсии на одну степень свободы воспользуемся результатами дисперсионного анализа как показано на Рисунке 7.


Доверительные интервалы прогноза индивидуальных значений у при  с вероятностью 0,95 определяются выражением:
с вероятностью 0,95 определяются выражением:



Интервал достаточно широк, прежде всего, за счёт малого объёма наблюдений. В целом выполненный прогноз среднемесячной заработной платы оказался надёжным.
Условие задачи взято из: Практикум по эконометрике: Учеб. пособие / И.И. Елисеева, С.В. Курышева, Н.М. Гордеенко и др.; Под ред. И.И. Елисеевой. – М.: Финансы и статистика, 2003. – 192 с.: ил.
Обновлено: 06.06.2023
В прогнозных расчетах по уравнению регрессии определяется предсказываемое ( у р ) значение как точечный прогноз при x p = x k , т. е. путем подстановки в уравнение регрессии соответствующего значения х. Однако точечный прогноз явно не реален. Поэтому он дополняется расчетом стандартной ошибки у х т. е. , и соответственно интервальной оценкой прогнозного значения ( у* )
Чтобы понять, как строится формула для определения величин стандартной ошибки обратимся к уравнению линейной регрессии: . Подставим в это уравнение выражение параметра а :
тогда уравнение регрессии примет вид
Отсюда вытекает, что стандартная ошибка зависит от ошибки и ошибки коэффициента регрессии b , т. е.
Из теории выборки известно, что . Используя в качестве оценки остаточную дисперсию на одну степень свободы S 2 , получим формулу расчета ошибки среднего значения переменной у.
Ошибка коэффициента регрессии, как уже было показано, определяется формулой
Считая, что прогнозное значение фактора х р = x k , получим следующую формулу расчета стандартной ошибки предсказываемого по линии регрессии значения, т. е. :
Соответственно имеет выражение:
Для нашего примера составит:
Соответственно составит эту же величину и при х k = 2,286. Для прогнозируемого значения 95%-ные доверительные интервалы при заданном х k определяются выражением
При х k . = 4, прогнозное значение у составит:
которое представляет собой точечный прогноз. Прогноз линии регрессии в интервале составит:
На графике доверительные границы для представляют собой гиперболы, расположенные по обе стороны от линии регрессии (рис. 2.3).
Рис. 2.3 показывает, как изменяются пределы в зависимости от изменения х k : две гиперболы по обе стороны от линии регрессии определяют 95 %-ные доверительные интервалы для среднего значения у при заданном значении х.
Однако фактические значения у варьируют около среднего значения . Индивидуальные значения у могут отклоняться от на величину случайной ошибки ε , дисперсия которой оценивается как остаточная дисперсия на одну степень свободы S 2 . Поэтому ошибка предсказываемого индивидуального значения у должна включать не только стандартную ошибку , но и случайную ошибку S .
Рис. 2.3. Доверительный интервал линии регрессии:
а — верхняя доверительная граница; б — линия регрессии;
в — доверительный интервал для при х k ;
г — нижняя доверительная граница
Средняя ошибка прогнозируемого индивидуального значения у — составит:
По данным рассматриваемого примера получим:
Доверительные интервалы прогноза индивидуальных значений у при x k = 4 с вероятностью 0,95 составят: , или 141,57 ±20,59, это означает, что 120,98 ≤ y р ≤ 162,1б.
Интервал достаточно широк, прежде всего, за счет малого объема наблюдений.
При прогнозировании на основе уравнения регрессии следует помнить, что величина прогноза зависит не только от стандартной ошибки индивидуального значения у, но и от точности прогноза значения фактора х. Его величина может задаваться на основе анализа других моделей исходя из конкретной ситуации, а также из анализа динамики данного фактора.
Рассмотренная формула средней ошибки индивидуального значения признака у ( ) может быть использована также для оценки существенности различия предсказываемого значения исходя из регрессионной модели и выдвинутой гипотезы развития событий.
Предположим, что в нашем примере с функцией издержек выдвигается предположение, что в предстоящем году в связи со стабилизацией экономики при выпуске продукции в 8 тыс. ед. затраты на производство не превысят 250 млн. руб. Означает ли это действительно изменение найденной закономерности или же данная величина затрат соответствует регрессионной модели?
Чтобы ответить на этот вопрос, найдем точечный прогноз при х = 8, т.е.
Предполагаемое же значение затрат, исходя из экономической ситуации, – 250,0. Для оценки существенности различия этих величин определим среднюю ошибку прогнозируемого индивидуального значения:
Сравним ее с величиной предполагаемого снижения издержек производства, т. е. 38,93:
Поскольку оценивается значимость только уменьшения затрат, то используется односторонний t-критерий Стьюдента. При ошибке в 5% с пятью степенями свободы t табл =2,015. Следовательно, предполагаемое уменьшение затрат значимо отличается от прогнозируемого по модели при 95%-ном уровне доверия. Однако если увеличить вероятность до 99%, при ошибке в 1% фактическое значение t-критерия оказывается ниже табличного 3,365, и рассматриваемое различие в величине затрат статистически не значимо.
3. СРЕДНЯЯ ОШИБКА АППРОКСИМАЦИИ
Фактические значения результативного признака отличаются от теоретических, рассчитанных по уравнению регрессии, т.е. у и . Чем меньше это отличие, тем ближе теоретические значения подходят к эмпирическим данным, лучше качество модели. Величина отклонений фактических и расчетных значений результативного признака ( у — ) по каждому наблюдению представляет собой ошибку аппроксимации. Их число соответствует объему совокупности. В отдельных случаях ошибка аппроксимации может оказаться равной нулю. Отклонения ( у – ) несравнимы между собой, исключая величину, равную нулю. Так, если для одного наблюдения ( у – ) = 5 , а для другого она равна 10, то это не означает, что во втором случае модель дает вдвое худший результат. Для сравнения используются величины отклонений, выраженные в процентах к фактическим значениям. Так, если для первого наблюдения у = 20, а для второго у = 50, ошибка аппроксимации составит 25% для первого наблюдения и 20% — для второго.
Поскольку ( у – ) может быть как величиной положительной, так и отрицательной, то ошибки аппроксимации для каждого наблюдения принято определять в процентах по модулю.
Отклонения ( у – ) можно рассматривать как абсолютную ошибку аппроксимации, а
— как относительную ошибку аппроксимации. Чтобы иметь общее суждение о качестве модели из относительных отклонений по каждому наблюдению, определяют среднюю ошибку аппроксимации как среднюю арифметическую простую:
Представим расчет средней ошибки аппроксимации для уравнения в табл. 2.7. , что говорит о хорошем качестве уравнения регрессии, ибо ошибка аппроксимации в пределах 5-7% свидетельствует о хорошем подборе модели к исходным данным.
Цель этой статьи — рассказать о линейной регрессии, а именно собрать и показать формулировки и интерпретации задачи регрессии с точки зрения математического анализа, статистики, линейной алгебры и теории вероятностей. Хотя в учебниках эта тема изложена строго и исчерпывающе, ещё одна научно-популярная статья не помешает.
! Осторожно, трафик! В статье присутствует заметное число изображений для иллюстраций, часть в формате gif.
Содержание
Введение
Есть три сходных между собой понятия, три сестры: интерполяция, аппроксимация и регрессия.
У них общая цель: из семейства функций выбрать ту, которая обладает определенным свойством.

Интерполяция — способ выбрать из семейства функций ту, которая проходит через заданные точки. Часто функцию затем используют для вычисления в промежуточных точках. Например, мы вручную задаем цвет нескольким точкам и хотим чтобы цвета остальных точек образовали плавные переходы между заданными. Или задаем ключевые кадры анимации и хотим плавные переходы между ними. Классические примеры: интерполяция полиномами Лагранжа, сплайн-интерполяция, многомерная интерполяция (билинейная, трилинейная, методом ближайшего соседа и т.д). Есть также родственное понятие экстраполяции — предсказание поведения функции вне интервала. Например, предсказание курса доллара на основании предыдущих колебаний — экстраполяция.
В этой статье мы рассмотрим линейную регрессию. Это означает, что семейство функций, из которых мы выбираем, представляет собой линейную комбинацию наперед заданных базисных функций
Цель регрессии — найти коэффициенты этой линейной комбинации, и тем самым определить регрессионную функцию (которую также называют моделью). Отмечу, что линейную регрессию называют линейной именно из-за линейной комбинации базисных функций — это не связано с самыми базисными функциями (они могут быть линейными или нет).
Точки генерируются случайно по распределению Гаусса с заданным средним и вариациями. Синяя линия — регрессионная прямая.
Метод наименьших квадратов
Начнём с простейшего двумерного случая. Пусть нам даны точки на плоскости и мы ищем такую аффинную функцию

чтобы ее график ближе всего находился к точкам. Таким образом, наш базис состоит из константной функции и линейной .
Как видно из иллюстрации, расстояние от точки до прямой можно понимать по-разному, например геометрически — это длина перпендикуляра. Однако в контексте нашей задачи нам нужно функциональное расстояние, а не геометрическое. Нас интересует разница между экспериментальным значением и предсказанием модели для каждого поэтому измерять нужно вдоль оси .
Первое, что приходит в голову, в качестве функции потерь попробовать выражение, зависящее от абсолютных значений разниц . Простейший вариант — сумма модулей отклонений приводит к Least Absolute Distance (LAD) регрессии.
Впрочем, более популярная функция потерь — сумма квадратов отклонений регрессанта от модели. В англоязычной литературе она носит название Sum of Squared Errors (SSE)
Метод наименьших квадратов (по англ. OLS) — линейная регрессия c в качестве функции потерь.

Такой выбор прежде всего удобен: производная квадратичной функции — линейная функция, а линейные уравнения легко решаются. Впрочем, далее я укажу и другие соображения в пользу .
Регрессионная прямая (синяя) и пробная прямая (зеленая). Справа показана функция потерь и точки соответствующие параметра пробной и регрессионной прямых.
Математический анализ
Простейший способ найти — вычислить частные производные по и , приравнять их нулю и решить систему линейных уравнений
Значения параметров, минимизирующие функцию потерь, удовлетворяют уравнениям
которые легко решить
Мы получили громоздкие и неструктурированные выражения. Сейчас мы их облагородим и вдохнем в них смысл.
Статистика
Полученные формулы можно компактно записать с помощью статистических эстиматоров: среднего , вариации (стандартного отклонения), ковариации и корреляции
где это нескорректированное (смещенное) стандартное выборочное отклонение, а — ковариация. Теперь вспомним, что коэффициент корреляции (коэффициент корреляции Пирсона)

Теперь мы можем оценить все изящество дескриптивной статистики, записав уравнение регрессионной прямой так
- прямая проходит через центр масс ;
- если по оси за единицу длины выбрать , а по оси — , то угол наклона прямой будет от до . Это связано с тем, что .
Возведя коэффициент корреляции в квадрат, получим коэффициент детерминации . Квадрат этой статистической меры показывает насколько хорошо регрессионная модель описывает данные. , равный , означает что функция идеально ложится на все точки — данные идеально скоррелированны. Можно доказать, что показывает какая доля вариативности в данных объясняется лучшей из линейных моделей. Чтобы понять, что это значит, введем определения
— вариация исходных данных (вариация точек ).
— вариация остатков, то есть вариация отклонений от регрессионной модели — от нужно отнять предсказание модели и найти вариацию.
— вариация регрессии, то есть вариация предсказаний регрессионной модели в точках (обратите внимание, что среднее предсказаний модели совпадает с ).

Дело в том, что вариация исходных данных разлагается в сумму двух других вариаций: вариации случайного шума (остатков) и вариации, которая объясняется моделью (регрессии)
Как видим, стандартные отклонения образуют прямоугольный треугольник.

Мы стремимся избавиться от вариативности, связанной с шумом и оставить лишь вариативность, которая объясняется моделью, — хотим отделить зерна от плевел. О том, насколько это удалось лучшей из линейных моделей, свидетельствует , равный единице минус доля вариации ошибок в суммарной вариации
или доле объясненной вариации (доля вариации регрессии в полной вариации)
равен косинусу угла в прямоугольном треугольнике . Кстати, иногда вводят долю необъясненной вариации и она равна квадрату синуса в этом треугольнике. Если коэффициент детерминации мал, возможно мы выбрали неудачные базисные функции, линейная регрессия неприменима вовсе и т.п.
Теория вероятностей
Ранее мы пришли к функции потерь из соображений удобства, но к ней же можно прийти с помощью теории вероятностей и метода максимального правдоподобия (ММП). Напомню вкратце его суть. Предположим, у нас есть независимых одинаково распределенных случайных величин (в нашем случае — результатов измерений). Мы знаем вид функции распределения (напр. нормальное распределение), но хотим определить параметры, которые в нее входят (например и ). Для этого нужно вычислить вероятность получить датапоинтов в предположении постоянных, но пока неизвестных параметров. Благодаря независимости измерений, мы получим произведение вероятностей реализации каждого измерения. Если мыслить полученную величину как функцию параметров (функция правдоподобия) и найти её максимум, мы получим оценку параметров. Зачастую вместо функции правдоподобия используют ее логарифм — дифференцировать его проще, а результат — тот же.
Вернемся к задаче простой регрессии. Допустим, что значения нам известны точно, а в измерении присутствует случайный шум (свойство слабой экзогенности). Более того, положим, что все отклонения от прямой (свойство линейности) вызваны шумом с постоянным распределением (постоянство распределения). Тогда
где — нормально распределенная случайная величина

Таким образом, максимум правдоподобия достигается при минимуме
что дает основание принять ее в качестве функции потерь. Кстати, если
мы получим функцию потерь LAD регрессии
которую мы упоминали ранее.
Подход, который мы использовали в этом разделе — один из возможных. Можно прийти к такому же результату, используя более общие свойства. В частности, свойство постоянства распределения можно ослабить, заменив на свойства независимости, постоянства вариации (гомоскедастичность) и отсутствия мультиколлинеарности. Также вместо ММП эстимации можно воспользоваться другими методами, например линейной MMSE эстимацией.
Мультилинейная регрессия
До сих пор мы рассматривали задачу регрессии для одного скалярного признака , однако обычно регрессор — это -мерный вектор . Другими словами, для каждого измерения мы регистрируем фич, объединяя их в вектор. В этом случае логично принять модель с независимыми базисными функциями векторного аргумента — степеней свободы соответствуют фичам и еще одна — регрессанту . Простейший выбор — линейные базисные функции . При получим уже знакомый нам базис .
Итак, мы хотим найти такой вектор (набор коэффициентов) , что
Знак «» означает, что мы ищем решение, которое минимизирует сумму квадратов ошибок
Последнее уравнение можно переписать более удобным образом. Для этого расположим в строках матрицы (матрицы информации)
Тогда столбцы матрицы отвечают измерениям -ой фичи. Здесь важно не запутаться: — количество измерений, — количество признаков (фич), которые мы регистрируем. Систему можно записать как
Квадрат нормы разности векторов в правой и левой частях уравнения образует функцию потерь
которую мы намерены минимизировать
Продифференцируем финальное выражение по (если забыли как это делается — загляните в Matrix cookbook)
приравняем производную к и получим т.н. нормальные уравнения
Если столбцы матрицы информации линейно независимы (нет идеально скоррелированных фич), то матрица имеет обратную (доказательство можно посмотреть, например, в видео академии Хана). Тогда можно записать
псевдообратная к . Понятие псевдообратной матрицы введено в 1903 году Фредгольмом, она сыграла важную роль в работах Мура и Пенроуза.
Напомню, что обратить и найти можно только если столбцы линейно независимы. Впрочем, если столбцы близки к линейной зависимости, вычисление уже становится численно нестабильным. Степень линейной зависимости признаков в или, как говорят, мультиколлинеарности матрицы , можно измерить числом обусловленности — отношением максимального собственного значения к минимальному. Чем оно больше, тем ближе к вырожденной и неустойчивее вычисление псевдообратной.
Линейная алгебра
К решению задачи мультилинейной регрессии можно прийти довольно естественно и с помощью линейной алгебры и геометрии, ведь даже то, что в функции потерь фигурирует норма вектора ошибок уже намекает, что у задачи есть геометрическая сторона. Мы видели, что попытка найти линейную модель, описывающую экспериментальные точки, приводит к уравнению
Если количество переменных равно количеству неизвестных и уравнения линейно независимы, то система имеет единственное решение. Однако, если число измерений превосходит число признаков, то есть уравнений больше чем неизвестных — система становится несовместной, переопределенной. В этом случае лучшее, что мы можем сделать — выбрать вектор , образ которого ближе остальных к . Напомню, что множество образов или колоночное пространство — это линейная комбинация вектор-столбцов матрицы
— -мерное линейное подпространство (мы считаем фичи линейно независимыми), линейная оболочка вектор-столбцов . Итак, если принадлежит , то мы можем найти решение, если нет — будем искать, так сказать, лучшее из нерешений.
Если в дополнение к векторам мы рассмотрим все вектора им перпендикулярные, то получим еще одно подпространство и сможем любой вектор из разложить на две компоненты, каждая из которых живет в своем подпространстве. Второе, перпендикулярное пространство, можно характеризовать следующим образом (нам это понадобится в дальнейшем). Пускай , тогда

где . В каждое из подпространств можно попасть с помощью соответствующего оператора проекции, но об этом ниже.


Если мы ищем решение , то естественно потребовать, чтобы была минимальна, ведь это длина вектора-остатка. Учитывая перпендикулярность подпространств и теорему Пифагора
но поскольку, выбрав подходящий , я могу получить любой вектор колоночного пространства, то задача сводится к
а останется в качестве неустранимой ошибки. Любой другой выбор сделает ошибку только больше.
что очень удобно, так как у нас нет, а вот — есть. Вспомним из предыдущего параграфа, что имеет обратную при условии линейной независимости признаков и запишем решение
где уже знакомая нам псевдообратная матрица. Если нам интересна проекция , то можно записать
где — оператор проекции на колоночное пространство.
Выясним геометрический смысл коэффициента детерминации.

Заметьте, что фиолетовый вектор пропорционален первому столбцу матрицы информации , который состоит из одних единиц согласно нашему выбору базисных функций. В RGB треугольнике
Так как этот треугольник прямоугольный, то по теореме Пифагора
Это геометрическая интерпретация уже известного нам факта, что
Красиво, не правда ли?
Произвольный базис
но до сих пор мы использовали простейшие , которые просто ретранслировали изначальные признаки без изменений, ну разве что дополняли их постоянной фичей . Как можно было заметить, на самом деле ни вид , ни их количество ничем не ограничены — главное, чтобы функции в базисе были линейно независимы. Обычно, выбор делается исходя из предположений о природе процесса, который мы моделируем. Если у нас есть основания полагать, что точки ложатся на параболу, а не на прямую, то стоит выбрать базис . Количество базисных функций может быть как меньшим, так и большим, чем количество изначальных фич.
Регрессия в полиномиальном базисе. Выделенная часть кода демонстрирует использование стандартных функций scikit-learn для выполнения регрессии полиномами разной степени, снизу — визуализация результата работы.
Если мы определились с базисом, то дальше действуем следующим образом. Мы формируем матрицу информации
записываем функцию потерь
и находим её минимум, например с помощью псевдообратной матрицы
Заключительные замечания
Проблема выбора размерности
Есть два способа выйти из ситуации. Первый: последовательно наращивать количество базисных функций, проверять качество регрессии и вовремя остановиться. Или же второй: выбрать функцию потерь, которая определит число степеней свободы автоматически. В качестве критерия успешности регрессии можно использовать коэффициент детерминации, о котором уже упоминалось выше, однако, проблема в том, что монотонно растет с ростом размерности базиса. Поэтому вводят скорректированный коэффициент
где — размер выборки, — количество независимых переменных. Следя за , мы можем вовремя остановиться и перестать добавлять дополнительные степени свободы.
Вторая группа подходов — регуляризации, самые известные из которых Ridge(/гребневая/Тихоновская регуляризация), Lasso( регуляризация) и Elastic Net(Ridge+Lasso). Главная идея этих методов: модифицировать функцию потерь дополнительными слагаемыми, которые не позволят вектору коэффициентов неограниченно расти и тем самым воспрепятствуют переобучению

Численные методы
Скажу пару слов, как минимизировать функцию потерь на практике. SSE — это обычная квадратичная функция, которая параметризируется входными данными, так что принципиально ее можно минимизировать методом скорейшего спуска или другими методами оптимизации. Разумеется, лучшие результаты показывают алгоритмы, которые учитывают вид функции SSE, например метод стохастического градиентного спуска. Реализация Lasso регрессии в scikit-learn использует метод координатного спуска.
Также можно решить нормальные уравнения с помощью численных методов линейной алгебры. Эффективный метод, который используется в scikit-learn для МНК — нахождение псевдообратной матрицы с помощью сингулярного разложения. Поля этой статьи слишком узки, чтобы касаться этой темы, за подробностями советую обратиться к курсу лекций К.В.Воронцова.
Реклама и заключение
Прогнозирование по уравнению регрессии представляет собой подстановку в уравнение регрессии соответственного значения х. Такой прогноз называется точечным. Он не является точным, поэтому дополняется расчетом стандартной ошибки ; получается интервальная оценка прогнозного значения :
 |
(30) |
Преобразуем уравнение регрессии:

ошибка зависит от ошибки и ошибки коэффициента регрессии то есть

Из теории выборки известно, что
Используем в качестве оценки остаточную дисперсию на одну степень свободы получаем:
Ошибка коэффициента регрессии из формулы (20):


Таким образом, при получаем:


(31)
Как видно из формулы, величина достигает минимума при и возрастает по мере удаления от в любом направлении.

Для нашего примера эта величина составит:

При . При

Для прогнозируемого значения 95% — ные доверительные интервалы при заданном определены выражением:

(32)
то есть при или При прогнозное значение составит — это точечный прогноз.
Прогноз линии регрессии лежит в интервале:

Мы рассмотрели доверительные интервалы для среднего значения при заданном Однако фактические значения варьируются около среднего значения они могут отклоняться на величину случайной ошибки ε, дисперсия которой оценивается как остаточная дисперсия на одну степень свободы Поэтому ошибка прогноза отдельного значения должна включать не только стандартную ошибку , но и случайную ошибку S. Таким образом, средняя ошибка прогноза индивидуального значения составит:

(33)

где .

Доверительный интервал прогноза индивидуальных значений при с верностью 0,95 составит: или
Пусть в примере с функцией издержек выдвигается предположение, что в предстоящем году в связи со стабилизацией экономики затраты на производство 8 тыс. ед. продукции не превысят 250 млн. руб. Означает ли это изменение найденной закономерности или затраты соответствуют регрессионной модели?

Точечный прогноз:
Предполагаемое значение — 250. Средняя ошибка прогнозного индивидуального значения:

Сравним ее с предполагаемым снижением издержек производства, то есть 250–288,93=–38,93:

Поскольку оценивается только значимость уменьшения затрат, то используется односторонний t— критерий Стьюдента. При ошибке в 5 % с , поэтому предполагаемое уменьшение затрат значимо отличается от прогнозируемого значения при 95 % — ном уровне доверия. Однако, если увеличить вероятность до 99%, при ошибке 1 % фактическое значение t – критерия оказывается ниже табличного 3,365, и различие в затратах статистически не значимо, то есть затраты соответствуют предложенной регрессионной модели.
Если мы полагаем, что y зависит от x, причём изменения в y вызываются именно изменениями в x, мы можем определить линию регрессии (регрессия y на x), которая лучше всего описывает прямолинейное соотношение между этими двумя переменными.
Статистическое использование слова «регрессия» исходит из явления, известного как регрессия к среднему, приписываемого сэру Френсису Гальтону (1889).
Он показал, что, хотя высокие отцы имеют тенденцию иметь высоких сыновей, средний рост сыновей меньше, чем у их высоких отцов. Средний рост сыновей «регрессировал» и «двигался вспять» к среднему росту всех отцов в популяции. Таким образом, в среднем высокие отцы имеют более низких (но всё-таки высоких) сыновей, а низкие отцы имеют сыновей более высоких (но всё-таки довольно низких).
Линия регрессии
Математическое уравнение, которое оценивает линию простой (парной) линейной регрессии:
x называется независимой переменной или предиктором.
- a – свободный член (пересечение) линии оценки; это значение Y, когда x=0 (Рис.1).
- b – угловой коэффициент или градиент оценённой линии; она представляет собой величину, на которую Y увеличивается в среднем, если мы увеличиваем x на одну единицу.
- a и b называют коэффициентами регрессии оценённой линии, хотя этот термин часто используют только для b.
Парную линейную регрессию можно расширить, включив в нее более одной независимой переменной; в этом случае она известна как множественная регрессия.
Рис.1. Линия линейной регрессии, показывающая пересечение a и угловой коэффициент b (величину возрастания Y при увеличении x на одну единицу)
Метод наименьших квадратов
Мы выполняем регрессионный анализ, используя выборку наблюдений, где a и b – выборочные оценки истинных (генеральных) параметров, α и β , которые определяют линию линейной регрессии в популяции (генеральной совокупности).
Наиболее простым методом определения коэффициентов a и b является метод наименьших квадратов (МНК).
Подгонка оценивается, рассматривая остатки (вертикальное расстояние каждой точки от линии, например, остаток = наблюдаемому y – предсказанный y, Рис. 2).
Линию лучшей подгонки выбирают так, чтобы сумма квадратов остатков была минимальной.
Рис. 2. Линия линейной регрессии с изображенными остатками (вертикальные пунктирные линии) для каждой точки.
Предположения линейной регрессии
Итак, для каждой наблюдаемой величины остаток равен разнице и соответствующего предсказанного Каждый остаток может быть положительным или отрицательным.
Можно использовать остатки для проверки следующих предположений, лежащих в основе линейной регрессии:
- Между и существует линейное соотношение: для любых пар данные должны аппроксимировать прямую линию. Если нанести на двумерный график остатки, то мы должны наблюдать случайное рассеяние точек, а не какую-либо систематическую картину.
- Остатки нормально распределены с нулевым средним значением;
- Остатки имеют одну и ту же вариабельность (постоянную дисперсию) для всех предсказанных величин Если нанести остатки против предсказанных величин от мы должны наблюдать случайное рассеяние точек. Если график рассеяния остатков увеличивается или уменьшается с увеличением то это допущение не выполняется;
Если допущения линейности, нормальности и/или постоянной дисперсии сомнительны, мы можем преобразовать или и рассчитать новую линию регрессии, для которой эти допущения удовлетворяются (например, использовать логарифмическое преобразование или др.).
Аномальные значения (выбросы) и точки влияния
«Влиятельное» наблюдение, если оно опущено, изменяет одну или больше оценок параметров модели (т.е. угловой коэффициент или свободный член).
Выброс (наблюдение, которое противоречит большинству значений в наборе данных) может быть «влиятельным» наблюдением и может хорошо обнаруживаться визуально, при осмотре двумерной диаграммы рассеяния или графика остатков.
И для выбросов, и для «влиятельных» наблюдений (точек) используют модели, как с их включением, так и без них, обращают внимание на изменение оценки (коэффициентов регрессии).
При проведении анализа не стоит отбрасывать выбросы или точки влияния автоматически, поскольку простое игнорирование может повлиять на полученные результаты. Всегда изучайте причины появления этих выбросов и анализируйте их.
Гипотеза линейной регрессии
При построении линейной регрессии проверяется нулевая гипотеза о том, что генеральный угловой коэффициент линии регрессии β равен нулю.
Если угловой коэффициент линии равен нулю, между и нет линейного соотношения: изменение не влияет на
Для тестирования нулевой гипотезы о том, что истинный угловой коэффициент равен нулю можно воспользоваться следующим алгоритмом:
Вычислить статистику критерия, равную отношению , которая подчиняется распределению с степенями свободы, где стандартная ошибка коэффициента
— оценка дисперсии остатков.
Обычно если достигнутый уровень значимости нулевая гипотеза отклоняется.
Можно рассчитать 95% доверительный интервал для генерального углового коэффициента :
где процентная точка распределения со степенями свободы что дает вероятность двустороннего критерия
Это тот интервал, который содержит генеральный угловой коэффициент с вероятностью 95%.
Для больших выборок, скажем, мы можем аппроксимировать значением 1,96 (то есть статистика критерия будет стремиться к нормальному распределению)
Оценка качества линейной регрессии: коэффициент детерминации R 2
Из-за линейного соотношения и мы ожидаем, что изменяется, по мере того как изменяется , и называем это вариацией, которая обусловлена или объясняется регрессией. Остаточная вариация должна быть как можно меньше.
Если это так, то большая часть вариации будет объясняться регрессией, а точки будут лежать близко к линии регрессии, т.е. линия хорошо соответствует данным.
Долю общей дисперсии , которая объясняется регрессией называют коэффициентом детерминации, обычно выражают через процентное соотношение и обозначают R 2 (в парной линейной регрессии это величина r 2 , квадрат коэффициента корреляции), позволяет субъективно оценить качество уравнения регрессии.
Разность представляет собой процент дисперсии который нельзя объяснить регрессией.
Нет формального теста для оценки мы вынуждены положиться на субъективное суждение, чтобы определить качество подгонки линии регрессии.
Применение линии регрессии для прогноза
Можно применять регрессионную линию для прогнозирования значения по значению в пределе наблюдаемого диапазона (никогда не экстраполируйте вне этих пределов).
Мы предсказываем среднюю величину для наблюдаемых, которые имеют определенное значение путем подстановки этого значения в уравнение линии регрессии.
Итак, если прогнозируем как Используем эту предсказанную величину и ее стандартную ошибку, чтобы оценить доверительный интервал для истинной средней величины в популяции.
Повторение этой процедуры для различных величин позволяет построить доверительные границы для этой линии. Это полоса или область, которая содержит истинную линию, например, с 95% доверительной вероятностью.
Подобным образом можно рассчитать более широкую область, внутри которой, как мы ожидаем, лежит наибольшее число (обычно 95%) наблюдений.
Простые регрессионные планы
Простые регрессионные планы содержат один непрерывный предиктор. Если существует 3 наблюдения со значениями предиктора P , например, 7, 4 и 9, а план включает эффект первого порядка P , то матрица плана X будет иметь вид
а регрессионное уравнение с использованием P для X1 выглядит как
Если простой регрессионный план содержит эффект высшего порядка для P , например квадратичный эффект, то значения в столбце X1 в матрице плана будут возведены во вторую степень:
а уравнение примет вид
Y = b 0 + b 1 P 2
Сигма -ограниченные и сверхпараметризованные методы кодирования не применяются по отношению к простым регрессионным планам и другим планам, содержащим только непрерывные предикторы (поскольку, просто не существует категориальных предикторов). Независимо от выбранного метода кодирования, значения непрерывных переменных увеличиваются в соответствующей степени и используются как значения для переменных X . При этом перекодировка не выполняется. Кроме того, при описании регрессионных планов можно опустить рассмотрение матрицы плана X , а работать только с регрессионным уравнением.
Пример: простой регрессионный анализ
Этот пример использует данные, представленные в таблице:
Рис. 3. Таблица исходных данных.
Данные составлены на основе сравнения переписей 1960 и 1970 в произвольно выбранных 30 округах. Названия округов представлены в виде имен наблюдений. Информация относительно каждой переменной представлена ниже:
Рис. 4. Таблица спецификаций переменных.
Задача исследования
Для этого примера будут анализироваться корреляция уровня бедности и степень, которая предсказывает процент семей, которые находятся за чертой бедности. Следовательно мы будем трактовать переменную 3 ( Pt_Poor ) как зависимую переменную.
Можно выдвинуть гипотезу: изменение численности населения и процент семей, которые находятся за чертой бедности, связаны между собой. Кажется разумным ожидать, что бедность ведет к оттоку населения, следовательно, здесь будет отрицательная корреляция между процентом людей за чертой бедности и изменением численности населения. Следовательно мы будем трактовать переменную 1 ( Pop_Chng ) как переменную-предиктор.
Просмотр результатов
Коэффициенты регрессии
Рис. 5. Коэффициенты регрессии Pt_Poor на Pop_Chng.
На пересечении строки Pop_Chng и столбца Парам. не стандартизованный коэффициент для регрессии Pt_Poor на Pop_Chng равен -0.40374 . Это означает, что для каждого уменьшения численности населения на единицу, имеется увеличение уровня бедности на .40374. Верхний и нижний (по умолчанию) 95% доверительные пределы для этого не стандартизованного коэффициента не включают ноль, так что коэффициент регрессии значим на уровне p . Обратите внимание на не стандартизованный коэффициент, который также является коэффициентом корреляции Пирсона для простых регрессионных планов, равен -.65, который означает, что для каждого уменьшения стандартного отклонения численности населения происходит увеличение стандартного отклонения уровня бедности на .65.
Распределение переменных
Коэффициенты корреляции могут стать существенно завышены или занижены, если в данных присутствуют большие выбросы. Изучим распределение зависимой переменной Pt_Poor по округам. Для этого построим гистограмму переменной Pt_Poor .
Рис. 6. Гистограмма переменной Pt_Poor.
Как вы можете заметить, распределение этой переменной заметно отличается от нормального распределения. Тем не менее, хотя даже два округа (два правых столбца) имеют высокий процент семей, которые находятся за чертой бедности, чем ожидалось в случае нормального распределения, кажется, что они находятся «внутри диапазона.»
Рис. 7. Гистограмма переменной Pt_Poor.
Это суждение в некоторой степени субъективно. Эмпирическое правило гласит, что выбросы необходимо учитывать, если наблюдение (или наблюдения) не попадают в интервал (среднее ± 3 умноженное на стандартное отклонение). В этом случае стоит повторить анализ с выбросами и без, чтобы убедиться, что они не оказывают серьезного эффекта на корреляцию между членами совокупности.
Диаграмма рассеяния
Если одна из гипотез априори о взаимосвязи между заданными переменными, то ее полезно проверить на графике соответствующей диаграммы рассеяния.
Рис. 8. Диаграмма рассеяния.
Диаграмма рассеяния показывает явную отрицательную корреляцию ( -.65 ) между двумя переменными. На ней также показан 95% доверительный интервал для линии регрессии, т.е., с 95% вероятностью линия регрессии проходит между двумя пунктирными кривыми.
Критерии значимости
Рис. 9. Таблица, содержащая критерии значимости.
Критерий для коэффициента регрессии Pop_Chng подтверждает, что Pop_Chng сильно связано с Pt_Poor , p .
На этом примере было показано, как проанализировать простой регрессионный план. Была также представлена интерпретация не стандартизованных и стандартизованных коэффициентов регрессии. Обсуждена важность изучения распределения откликов зависимой переменной, продемонстрирована техника определения направления и силы взаимосвязи между предиктором и зависимой переменной.
Читайте также:
- Структура наставления по огневой подготовке кратко
- Моральный вред это кратко
- Полезные свойства лимона кратко для детей
- Легенда о гитаре кратко
- Казуальное право это кратко