
Условные обозначения характеристик генеральной и выборочной совокупности.
|
№ п/п |
Показатели |
Символы |
|
|
Генеральная совокупность |
Выборочная совокупность |
||
|
1 |
Объем совокупности (число |
N |
n |
|
2 |
Среднее |
̅ ̅X |
̅ x͂ |
|
3 |
Число единиц, обладающие |
M |
m |
|
4 |
Доля единиц, обладающая |
p N (генеральная |
W n (выборочная доля) |
|
5 |
Доля единиц, не обладающая |
q = 1 – p |
1 – W |
|
6 |
Дисперсия |
ơ2 (генеральная) |
S2 (выборочная) |
|
7 |
Дисперсия альтернативного |
ơ2p |
S2w |
|
8 |
Среднее квадратическое |
ơ |
S |
Ошибки выборки.
Ошибка выборки– это величина
возможных расхождений между показателями
генеральной и выборочной совокупности.
Чем больше значение ошибки, тем в большей
степени выборочные показатели отличаются
от генеральных.
Выборочная средняя и выборочная
доля– это два основных обобщающих
показателя. Они, по своей сути, являются
случайными величинами. Поэтому определяют
среднюю из возможных ошибок. Средняя
ошибка выборки обозначается значком
(μ) мю.
Определение средней ошибки выборки (μ):
_________
а) Для средней количественного признака
μ х̅
= √ S2
.(1- n)
n N
________________
б) Для доли (альтернативного признака)
μ
w
= √ W.
(1-W)
. (1-n)
n
N
Средняя ошибка выборки зависит от
вариаций изучаемого признака, которая
характеризуется, главным образом,
дисперсией. Чем меньше дисперсия, тем
меньше вариация признака, а следовательно
меньше средняя ошибка.
Определение предельной ошибки выборки (δ)
Распространение выборочных обобщающих
показателей (х͂ и w)
проводится с учетом предела их возможной
ошибки.
В каждой конкретной выборке расхождение
между выборочной и генеральной средней
может быть меньше, равно или больше
средней ошибки. Причем каждая из этих
расхождений имеет различную вероятность
появления. Именно поэтому и рассчитывается
предельная ошибка выборки. То есть,
предельная ошибка отвечает на вопрос:
о точности выборки и значения ее
определяется коэффициентом
(t) – коэффициент доверия,
нормированное отклонение.
Δ = t
μ1
Зависимость коэффициента доверия от
вероятности (Р)
|
t |
1,000 |
1,960 |
2,000 |
2,580 |
3,000 |
|
P |
0,683 |
0,950 |
0,954 |
0,990 |
0,997 |
В практических социологических расчетах
заданная вероятность не должна быть
меньше 1,95. Следовательно,брать не меньше 2 (коэффициент доверия),
или лучше 3 .
Формулы предельной ошибки выборки: (случайный бесповторный отбор)
___________
а) Для средней количественного признака
Δ
x̅
=
tμ x̅
=
t √ S2
.
(1 – n)
n
N
________________
б) Для доли (альтернативного признака)
Δ
w
=
tμw
= t √ W(1-W)
. (1- n)
n
N
Определение доверительного интервала
Главной задачей для проведения выборочного
наблюдения явл. распространение
выборочных результатов (x͂
и W) на генеральные
показатели (x̅и
P).
Для генеральной средней x̅
= x͂ ± Δ ; x͂ — Δx͂
≤
x̅ ≤ x͂ + Δx͂
Для генеральной доли P
= W ± Δw
; W
— Δw
≤
P ≤ W + Δw
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
11.2. Оценка результатов выборочного наблюдения
11.2.1. Средняя и предельная ошибки выборки. Построение доверительных границ для средней и доли
Средняя ошибка выборки показывает, насколько отклоняется в среднем параметр выборочной совокупности от соответствующего параметра генеральной. Если рассчитать среднюю из ошибок всех возможных выборок определенного вида заданного объема (n), извлеченных из одной и той же генеральной совокупности, то получим их обобщающую характеристику — среднюю ошибку выборки ( ).
).
В теории выборочного наблюдения выведены формулы для определения , которые индивидуальны для разных способов отбора (повторного и бесповторного), типов используемых выборок и видов оцениваемых статистических показателей.
Например, если применяется повторная собственно случайная выборка, то определяется как:
 — при оценивании среднего значения признака;
— при оценивании среднего значения признака;
 — если признак альтернативный, и оценивается доля.
— если признак альтернативный, и оценивается доля.
При бесповторном собственно случайном отборе в формулы вносится поправка (1 — n/N):
 — для среднего значения признака;
— для среднего значения признака;
 — для доли.
— для доли.
Вероятность получения именно такой величины ошибки всегда равна 0,683. На практике же предпочитают получать данные с большей вероятностью, но это приводит к возрастанию величины ошибки выборки.
Предельная ошибка выборки ( ) равна t-кратному числу средних ошибок выборки (в теории выборки принято коэффициент t называть коэффициентом доверия):
) равна t-кратному числу средних ошибок выборки (в теории выборки принято коэффициент t называть коэффициентом доверия):
 .
.
Если ошибку выборки увеличить в два раза (t = 2), то получим гораздо большую вероятность того, что она не превысит определенного предела (в нашем случае — двойной средней ошибки) — 0,954. Если взять t = 3, то доверительная вероятность составит 0,997 — практически достоверность.
Уровень предельной ошибки выборки зависит от следующих факторов:
- степени вариации единиц генеральной совокупности;
- объема выборки;
- выбранных схем отбора (бесповторный отбор дает меньшую величину ошибки);
- уровня доверительной вероятности.
Если объем выборки больше 30, то значение t определяется по таблице нормального распределения, если меньше — по таблице распределения Стьюдента.
Приведем некоторые значения коэффициента доверия из таблицы нормального распределения.
| Значение доверительной вероятности P | 0,683 | 0,954 | 0,997 |
|---|---|---|---|
| Значение коэффициента доверия t | 1,0 | 2,0 | 3,0 |
Доверительный интервал для среднего значения признака и для доли в генеральной совокупности устанавливается следующим образом:

Итак, определение границ генеральной средней и доли состоит из следующих этапов:
Ошибки выборки при различных видах отбора
- Собственно случайная и механическая выборка. Средняя ошибка собственно случайной и механической выборки находятся по формулам, представленным в табл. 11.3.
 |
|
где |
Пример 11.2. Для изучения уровня фондоотдачи было проведено выборочное обследование 90 предприятий из 225 методом случайной повторной выборки, в результате которого получены данные, представленные в таблице.
| Уровень фондоотдачи, руб. | До 1,4 | 1,4-1,6 | 1,6-1,8 | 1,8-2,0 | 2,0-2,2 | 2,2 и выше | Итого |
|---|---|---|---|---|---|---|---|
| Количество предприятий | 13 | 15 | 17 | 15 | 16 | 14 | 90 |
В рассматриваемом примере имеем 40%-ную выборку (90 : 225 = 0,4, или 40%). Определим ее предельную ошибку и границы для среднего значения признака в генеральной совокупности по шагам алгоритма:
- По результатам выборочного обследования рассчитаем среднее значение и дисперсию в выборочной совокупности:
| Результаты наблюдения | Расчетные значения | |||
|---|---|---|---|---|
| уровень фондоотдачи, руб., xi | количество предприятий, fi | середина интервала, xixb4 | xixb4fi | xixb42fi |
| До 1,4 | 13 | 1,3 | 16,9 | 21,97 |
| 1,4-1,6 | 15 | 1,5 | 22,5 | 33,75 |
| 1,6-1,8 | 17 | 1,7 | 28,9 | 49,13 |
| 1,8-2,0 | 15 | 1,9 | 28,5 | 54,15 |
| 2,0-2,2 | 16 | 2,1 | 33,6 | 70,56 |
| 2,2 и выше | 14 | 2,3 | 32,2 | 74,06 |
| Итого | 90 | — | 162,6 | 303,62 |
Выборочная средняя

Выборочная дисперсия изучаемого признака

- Определяем среднюю ошибку повторной случайной выборки

- Зададим вероятность, на уровне которой будем говорить о величине предельной ошибки выборки. Чаще всего она принимается равной 0,999; 0,997; 0,954.

Для наших данных определим предельную ошибку выборки, например, с вероятностью 0,954. По таблице значений вероятности функции нормального распределения (см. выдержку из нее, приведенную в Приложении 1) находим величину коэффициента доверия t, соответствующего вероятности 0,954. При вероятности 0,954 коэффициент t равен 2.
- Предельная ошибка выборки с вероятностью 0,954 равна
- Найдем доверительные границы для среднего значения уровня фондоотдачи в генеральной совокупности


Таким образом, в 954 случаях из 1000 среднее значение фондоотдачи будет не выше 1,88 руб. и не ниже 1,74 руб.
Выше была использована повторная схема случайного отбора. Посмотрим, изменятся ли результаты обследования, если предположить, что отбор осуществлялся по схеме бесповторного отбора. В этом случае расчет средней ошибки проводится по формуле

Тогда при вероятности равной 0,954 величина предельной ошибки выборки составит:

Доверительные границы для среднего значения признака при бесповторном случайном отборе будут иметь следующие значения:

Сравнив результаты двух схем отбора, можно сделать вывод о том, что применение бесповторной случайной выборки дает более точные результаты по сравнению с применением повторного отбора при одной и той же доверительной вероятности. При этом, чем больше объем выборки, тем существеннее сужаются границы значений средней при переходе от одной схемы отбора к другой.
По данным примера определим, в каких границах находится доля предприятий с уровнем фондоотдачи, не превышающим значения 2,0 руб., в генеральной совокупности:
- рассчитаем выборочную долю.
Количество предприятий в выборке с уровнем фондоотдачи, не превышающим значения 2,0 руб., составляет 60 единиц. Тогда
m = 60, n = 90, w = m/n = 60 : 90 = 0,667;
- рассчитаем дисперсию доли в выборочной совокупности
 ;
;
- средняя ошибка выборки при использовании повторной схемы отбора составит

Если предположить, что была использована бесповторная схема отбора, то средняя ошибка выборки с учетом поправки на конечность совокупности составит

- зададим доверительную вероятность и определим предельную ошибку выборки.
При значении вероятности Р = 0,997 по таблице нормального распределения получаем значение для коэффициента доверия t = 3 (см. выдержку из нее, приведенную в Приложении 1):

- установим границы для генеральной доли с вероятностью 0,997:

Таким образом, с вероятностью 0,997 можно утверждать, что в генеральной совокупности доля предприятий с уровнем фондоотдачи, не превышающим значения 2,0 руб., не меньше, чем 54,7%, и не больше 78,7%.
- Типическая выборка. При типической выборке генеральная совокупность объектов разбита на k групп, тогда
N1 + N2 + … + Ni + … + Nk = N.
Объем извлекаемых из каждой типической группы единиц зависит от принятого способа отбора; их общее количество образует необходимый объем выборки
n1 + n2 + … + ni + … + nk = n.
Существуют следующие два способа организации отбора внутри типической группы: пропорциональной объему типических групп и пропорциональной степени колеблемости значений признака у единиц наблюдения в группах. Рассмотрим первый из них, как наиболее часто используемый.
Отбор, пропорциональный объему типических групп, предполагает, что в каждой из них будет отобрано следующее число единиц совокупности:
n = ni · Ni/N
где ni — количество извлекаемых единиц для выборки из i-й типической группы;
n — общий объем выборки;
Ni — количество единиц генеральной совокупности, составивших i-ю типическую группу;
N — общее количество единиц генеральной совокупности.
Отбор единиц внутри групп происходит в виде случайной или механической выборки.
Формулы для оценивания средней ошибки выборки для среднего и доли представлены в табл. 11.6.

|
 ) при использовании типического отбора, пропорционального объему типических групп
) при использовании типического отбора, пропорционального объему типических группЗдесь  — средняя из групповых дисперсий типических групп.
— средняя из групповых дисперсий типических групп.
Пример 11.3. В одном из московских вузов проведено выборочное обследование студентов с целью определения показателя средней посещаемости вузовской библиотеки одним студентом за семестр. Для этого была использована 5%-ная бесповторная типическая выборка, типические группы которой соответствуют номеру курса. При отборе, пропорциональном объему типических групп, получены следующие данные:
| Номер курса | Всего студентов, чел., Ni | Обследовано в результате выборочного наблюдения, чел., ni | Среднее число посещений библиотеки одним студентом за семестр, xi | Внутригрупповая выборочная дисперсия, 
|
|---|---|---|---|---|
| 1 | 650 | 33 | 11 | 6 |
| 2 | 610 | 31 | 8 | 15 |
| 3 | 580 | 29 | 5 | 18 |
| 4 | 360 | 18 | 6 | 24 |
| 5 | 350 | 17 | 10 | 12 |
| Итого | 2 550 | 128 | 8 | — |
Число студентов, которое необходимо обследовать на каждом курсе, рассчитаем следующим образом:
- общий объем выборочной совокупности:
n = 2550/130*5 =128 (чел.);
- количество единиц, отобранных из каждой типической группы:

аналогично для других групп:
n2 = 31 (чел.);
n3 = 29 (чел.);
n4 = 18 (чел.);
n5 = 17 (чел.).
Проведем необходимые расчеты.
- Выборочная средняя, исходя из значений средних типических групп, составит:
- Средняя из внутригрупповых дисперсий
- Средняя ошибка выборки:
С вероятностью 0,954 находим предельную ошибку выборки:
- Доверительные границы для среднего значения признака в генеральной совокупности:





Таким образом, с вероятностью 0,954 можно утверждать, что один студент за семестр посещает вузовскую библиотеку в среднем от семи до девяти раз.
- Малая выборка. В связи с небольшим объемом выборочной совокупности те формулы для определения ошибок выборки, которые использовались нами ранее при «больших» выборках, становятся неподходящими и требуют корректировки.
Среднюю ошибку малой выборки определяют по формуле

Предельная ошибка малой выборки:

Распределение значений выборочных средних всегда имеет нормальный закон распределения (или приближается к нему) при п > 100, независимо от характера распределения генеральной совокупности. Однако в случае малых выборок действует иной закон распределения — распределение Стьюдента. В этом случае коэффициент доверия находится по таблице t-распределения Стьюдента в зависимости от величины доверительной вероятности Р и объема выборки п. В Приложении 1 приводится фрагмент таблицы t-распределения Стьюдента, представленной в виде зависимости доверительной вероятности от объема выборки и коэффициента доверия t.
Пример 11.4. Предположим, что выборочное обследование восьми студентов академии показало, что на подготовку к контрольной работе по статистике они затратили следующее количество часов: 8,5; 8,0; 7,8; 9,0; 7,2; 6,2; 8,4; 6,6.
Оценим выборочные средние затраты времени и построим доверительный интервал для среднего значения признака в генеральной совокупности, приняв доверительную вероятность равной 0,95.
- Среднее значение признака в выборке равно
- Значение среднего квадратического отклонения составляет
- Средняя ошибка выборки:
- Значение коэффициента доверия t = 2,365 для п = 8 и Р = 0,95 .
- Предельная ошибка выборки:
- Доверительный интервал для среднего значения признака в генеральной совокупности:





То есть с вероятностью 0,95 можно утверждать, что затраты времени студента на подготовку к контрольной работе находятся в пределах от 6,9 до 8,5 ч.
11.2.2. Определение численности выборочной совокупности
Перед непосредственным проведением выборочного наблюдения всегда решается вопрос, сколько единиц исследуемой совокупности необходимо отобрать для обследования. Формулы для определения численности выборки выводят из формул предельных ошибок выборки в соответствии со следующими исходными положениями (табл. 11.7):
- вид предполагаемой выборки;
- способ отбора (повторный или бесповторный);
- выбор оцениваемого параметра (среднего значения признака или доли).
Кроме того, следует заранее определиться со значением доверительной вероятности, устраивающей потребителя информации, и с размером допустимой предельной ошибки выборки.
 |
Примечание: при использовании приведенных в таблице формул рекомендуется получаемую численность выборки округлять в большую сторону для обеспечения некоторого запаса в точности.
Пример 11.5. Рассчитаем, сколько из 507 промышленных предприятий следует проверить налоговой инспекции, чтобы с вероятностью 0,997 определить долю предприятий с нарушениями в уплате налогов. По данным прошлого аналогичного обследования величина среднего квадратического отклонения составила 0,15; размер ошибки выборки предполагается получить не выше, чем 0,05.
При использовании повторного случайного отбора следует проверить

При бесповторном случайном отборе потребуется проверить

Как видим, использование бесповторного отбора позволяет проводить обследование гораздо меньшего числа объектов.
Пример 11.6. Планируется провести обследование заработной платы на предприятиях отрасли методом случайного бесповторного отбора. Какова должна быть численность выборочной совокупности, если на момент обследования в отрасли число занятых составляло 100 000 чел.? Предельная ошибка выборки не должна превышать 100 руб. с вероятностью 0,954. По результатам предыдущих обследований заработной платы в отрасли известно, что среднее квадратическое отклонение составляет 500 руб.

Следовательно, для решения поставленной задачи необходимо включить в выборку не менее 100 человек.
1.1. Ошибки
выборочного наблюдения
Средняя
ошибка выборки показывает, как генеральная средняя отклоняется в среднем от выборочной средней в ту или другую сторону. Формула
расчета средней ошибки выборки определяется видом исследуемого признака единиц
совокупности (количественный или альтернативный) и
способом отбора (бесповторный или повторный).
·
Если отбор повторный, а признак количественный
средняя ошибка выборки определяется по формуле
![]() , где
, где ![]() — дисперсия признака в выборочной совокупности
— дисперсия признака в выборочной совокупности
n- число единиц
в выборке
·
Если отбор бесповторный, а признак
количественный
 , где N—
, где N—
число единиц в генеральной совокупности
·
Если отбор повторный, а признак альтернативный
 , где w-выборочная
, где w-выборочная
доля
·
Если отбор бесповторный, а признак
альтернативный

Предельная ошибка выборки— показывающая с определенной степенью вероятности
отклонения средней от выборочной средней.
Предельная ошибка выборки
![]() , где параметр t зависит
, где параметр t зависит
от вероятности
Некоторые значения параметра t приведены
в таблице:
|
Вероятность, p |
0.95 |
0.954 |
0.9876 |
0.9907 |
0.9973 |
0.9999 |
|
Параметр t |
1.96 |
2.0 |
2.5 |
2.6 |
3.0 |
4.0 |
·
Если отбор повторный, а признак количественный
средняя ошибка выборки определяется по формуле
![]() , где
, где ![]() — дисперсия признака в выборочной совокупности
— дисперсия признака в выборочной совокупности
n- число единиц
в выборке
·
Если отбор бесповторный, а признак
количественный
 , где N—
, где N—
число единиц в генеральной совокупности
·
Если отбор повторный, а признак альтернативный
 , где w-выборочная
, где w-выборочная
доля
·
Если отбор бесповторный, а признак
альтернативный

Доверительный интервал для генеральной средней
![]()
Доверительный интервал для
генеральной доли
![]()
Пример расчета доверительного
интервала:
При выборочном обследовании 5% продукции по методу случайного
бесповторного отбора получены данные о содержании сахара в образцах:
|
Сахарность, % |
Число |
|
16-17 17-18 18-19 19-20 20-21 |
10 158 154 50 28 |
|
На основании этих данных вычислите:
1. Средний процент сахаристости.
2. Дисперсию и среднее квадратическое
отклонение.
3. С вероятностью 0.954 возможные пределы среднего значения
сахаристости продукции для всей партии.
4. С вероятностью 0.997 возможный процент продукции высшего
сорта по всей партии, если известно, что из 400 проб, попавших в выборку , 80
ед. отнесены к продукции высшего сорта.
Решение.
1.
Средний процент сахаристости найдем по формуле средней взвешенной
![]() , где xi–
, где xi–
середина i-го интервала
![]() =18,32 %
=18,32 %
2.
Дисперсия
![]()
![]()
![]() =336,49
=336,49
D(X)=336.49–
18.322=0.8676
Среднее квадратическое отклонение
![]() =0,93%
=0,93%
5. Предельная ошибка для
среднего процента сахаристости
![]()
для вероятности 0,954 параметр t=2.0
![]()
Доверительный интервал для среднего значения процента
сахаристости
![]()
![]()
![]()
С вероятностью 0,954 можно утверждать, что в генеральной
совокупности средний процент сахаристости лежит в пределах от 18,23% до 18,41%.
5. Доля продукции высшего сорта в выборочной совокупности
![]()
Предельная ошибка для
доли продукции высшего сорта
![]()
для вероятности 0,997 параметр t=3.0
![]()
Доверительный интервал для доли продукции высшего сорта
![]()
![]()
![]()
С вероятностью 0,997 можно утверждать, что в генеральной
совокупности доля продукции высшего сорта лежит в пределах от 14,0% до 26,0%.
2.1. Стандартное отклонение среднего выборочного значения (ошибка среднего) и доверительный интервал
Результаты измерений обычно показывают с так называемой «средней статистической ошибкой средней величины» и для нашего случая (см. табл. 1.1) это будет запись: «высота сеянцев в опыте составила 5,0 ± 0,28 см». Словосочетание «средняя статистическая ошибка» обычно сокращают до названия «ошибка среднего» или просто «ошибка», обозначают буквой m и определяют по очень простой формуле. Для итогов упомянутой таблицы, где расчеты по 25 высотам дали значение δ = 1,42 см, эта ошибка составит:
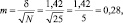 (2.1)
(2.1)
|
где δ – |
стандартное отклонение; |
|
N – |
число наблюдений или объем выборки, шт. |
Если объем выборки взять 100 шт., то ошибка снизится в 2 раза: 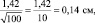 а если увеличить до 10000 шт., то в 10 раз, до 0,014 см.
а если увеличить до 10000 шт., то в 10 раз, до 0,014 см.
Рассмотрим эту «среднюю статистическую ошибку» (далее просто ошибка) подробно, так как именно в ней скрыто понимание того, что называют статистическим мышлением. Интуитивно мы понимаем, что малая выборка дает большую ошибку, т.е. неточное определение среднего значения. Последний термин настолько привычен, что мы даже не задумываемся о том, что его правильное и полное название «среднее выборочное значение», т.е. среднее, определяемое в некоторой выборке. И выборки могут быть очень разные по численности. Начнем с самых малых. Например, что произойдет с ошибкой, если объем выборки сократить до 2 измерений? Такие выборки бывают, например, в почвенных исследованиях, когда каждое измерение достается дорогой ценой. Для этого вернемся к рис. 1.1. На нем стандартное отклонение ±δ, которое отражает разброс значений вокруг среднего в левую и правую сторону в виде холма, наблюдается при объеме выборки 1 шт. В этом случае ошибка среднего выборочного значения будет равна стандартному отклонению: m = δ = 1,42. С увеличением N ошибка уменьшается:
при объеме выборки N = 2 ошибка будет
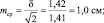
при объеме выборки N = 4 ошибка будет
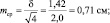
при объеме выборки N = 16 ошибка будет
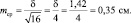
Важно понять, что ряд распределения частот этих выборочных средних будет постепенно как бы съеживаться и приближаться к центру, где находится так называемое «генеральное» среднее. Поясним, что в математике генеральное среднее значение называется математическим ожиданием и его обозначают буквой «М». Например, это может быть средняя высота, рассчитанная по всем измеренным в теплице сеянцам, или среднее число семян в 1 шишке у дерева после подсчета семян во всех собранных с дерева шишках (50, 100, 500 и т.д., т.е. весьма небольшая генеральная совокупность). Распределение частот значений выборочных средних, которых может быть множество, будет иметь форму такого же холма, как и распределение единичных значений на рис. 1.1. При этом, если выборка будет из 1 шт., то холм будет в точности таким же, но при выборках из 2 шт. его форма съежится в 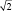 = в 1,41 раза; при выборках из 4 шт. –
= в 1,41 раза; при выборках из 4 шт. –
в 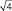 = в 2 раза; при выборках из 9 шт. – в
= в 2 раза; при выборках из 9 шт. – в 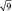 = в 3 раза и т.д.
= в 3 раза и т.д.
Для этих сокращающихся рядов распределения выборочных средних можно рассчитать свое, особое стандартное отклонение. Вероятно, чтобы не путать его со СТАНДОТКЛ, его стали называть по-другому, т.е. «средней статистической ошибкой средней величины». Чем больше по объему выборки, тем короче ряд распределения средних значений этих выборок с его «хвостами» в левую и правую сторону, и тем меньше величина этого особого стандартного отклонения. Закон распределения частот выборочных средних точно такой же, и имеет те же свойства: в пределах ±2m находится 95 % всех значений выборочных средних, в пределах ±3m – 99,5 %, а в пределах ±4m находится 100 % всех значений xср. Форма этого распределения меняется от пологой при малых выборках до очень крутой, вплоть до «схлопывания» в центре при выборках большого объема, когда ошибка среднего стремится к нулю.
Здесь следует пояснить, что, на наш взгляд, словосочетание «средняя статистическая ошибка средней величины», сокращаемое до «ошибки среднего значения» или просто до «ошибки», вводит нас в некоторое заблуждение, так как мы привыкли со школы, что ошибки надобно исправлять. Более правильным, вместо слов «ошибка среднего значения», будет использование слов «стандартное отклонение выборочных средних значений от генерального среднего». Не случайно математики выбрали для обозначения величины этого отклонения букву «m», а для обозначения генерального среднего (математического ожидания) – букву «М». Слова для объяснения этих сложных явлений могут быть разными, но и у математиков, и у биологов есть единодушие в понимании статистического смысла, лежащего за этими буквенными символами. Вообще, лучше было бы ввести некий иной термин вместо слов «ошибка» или «отклонение», так как они изначально имеют в нашем сознании иной смысл; на наш взгляд, более всего подходит слово «скачок» (чем сильнее отскакивает выборочное среднее от генерального среднего, тем реже оно встречается). Но так уж получилось, что не нашлось нейтрального (иностранного) слова, и слово «ошибка» традиционно используют, и мы также будем его использовать; важно понимать его иной, чем в обыденном употреблении, математический и статистический смысл.
Для самого точного определения средней высоты сеянцев нужно измерять все растения в питомнике, и тогда мы получим «генеральное среднее значение». Но так не делают, а измеряют несколько сотен растений в разных местах и этого бывает достаточно для определения среднего выборочного значения с приемлемой точностью. В нашем примере при 100 растениях ошибка его определения составит 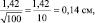 а ее отнесение к средней высоте сеянцев 5,0 см, выражаемое в %, дает нам так называемую точность опыта: 0,14/5,0×100 = 2,8 %. В биологии точность опыта ±2–3 % считается высокой, ±5 % – достаточной, а ±6–7 % – пониженной, но это весьма упрощенное представление о планировании эксперимента.
а ее отнесение к средней высоте сеянцев 5,0 см, выражаемое в %, дает нам так называемую точность опыта: 0,14/5,0×100 = 2,8 %. В биологии точность опыта ±2–3 % считается высокой, ±5 % – достаточной, а ±6–7 % – пониженной, но это весьма упрощенное представление о планировании эксперимента.
Вообще, точность опыта не самоцель; гораздо важнее сократить численность (объем) выборки до минимума. Представим себе, что средняя высота сеянцев xср = 5,0 см, а ее ±δ = 1,42 см, рассмотренные выше, получены при измерении 1000 растений потомства сосны, например, из Кунгура. Поделив ±δ на корень из 1000 получаем ошибку опыта m = ±0,045 см. Далее получаем точность опыта
Р = m/xср×100 = 0,045/5,0×100 = 0,9 %.
Точность получилась очень высокой. Но в питомнике есть потомства и из других мест и такой уровень точности совершенно не нужен, так как нужно узнать еще высоты сеянцев, например, из Очера, Осы, Добрянки и других районов. Если выборку из 1 тыс. растений снижать, то будет увеличиваться ошибка в определении средней высоты. И нужно найти приемлемую величину такой ошибки, которая позволит нам, тем не менее, уверенно утверждать, что это потомство растет быстрее, либо медленнее других. Причем происхождений может быть несколько сотен и минимизация выборок крайне важна, так как масштабы работ ограничены физическими возможностями бригады селекционеров. Следовательно, надо сокращать объем выборки. Как это сделать правильно?
Рассмотрим два потомства. Первое – это упомянутые сеянцы происхождением из Кунгура (хср1), второе – сеянцы из Кизела с хср2 = 6,0 см и δ2 = ± 1,0 см (превышение высоты на 20 %). Надо это превышение доказать. При выборках из 100 растений ранее определенная ошибка m1 была равна 0,14 см, вторая ошибка m2 после расчетов по формуле (2.1) составит 0,1 см. По закону нормального распределения 99,5 % всех возможных значений этих средних хср1 и хср2 будут в пределах «плюс-минус три ошибки», что можно показать графически (рис. 2.1) или в виде формул:
хср1 ± 3m1 = 5,0 ± 3×0,14 = 5,0 ± 0,4 см
и
хср2 ± 3m2 = 6,0 ± 3×0,1 = 6,0 ± 0,3 см.
Возможные теоретические значения средних в генеральной совокупности не перекрывают друг друга, значит, различие достоверно. А если сократить выборки до 50 сеянцев? Тогда 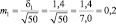 и
и 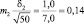 и пределы колебаний возможных значений средних будут:
и пределы колебаний возможных значений средних будут:
хср1 ± 3m1 = 5,0 ± 3×0,20 = 5,0 ± 0,6 см;
хср2 ± 3m2 = 6,0 ± 3×0,14 = 6,0 ± 0,3 см.

Рис. 2.1. Средние значения по выборкам из 100 растений и их тройные ошибки (пределы возможных значений выборочных средних в 99,5 % случаев)
Снова вынесем эти пределы на график (рис. 2.2).

Рис. 2.2. Средние значения при N = 50 растений и их тройные ошибки
Как видим, пределы сблизились и если еще сократить выборки, то они перекроются. Можно ли далее снижать объем выборки?
Можно, но здесь вступает в силу так называемое условие безошибочного прогноза. Мы это условие задали на уровне 99,5 % и для этого взяли ±3m для распределения ошибок. Но можно взять уровень пониже, с пределами ±2δ (уровень 95 %) и даже с пределами ±1,7δ (уровень 90 %).
При выборках из 25 штук сеянцев, получаем две ошибки: 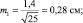
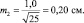 Тогда пределы значений для этих двух выборочных средних для уровня прогноза в 95 % будут:
Тогда пределы значений для этих двух выборочных средних для уровня прогноза в 95 % будут:
хср1 ± 2m1 = 5,0 ± 2×0,28 = 5,0 ± 0,56 см;
хср2 ± 2m2 = 6,0 ± 2×0,20 = 6,0 ± 0,40 см.
Выносим эти пределы опять на график (рис. 2.3).
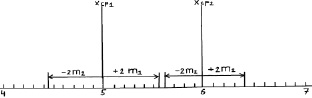
Рис. 2.3. Средние значения при N = 25 растений и их двойные ошибки (пределы возможных значений средних в 95 % случаев)
Как видим, просвет все еще есть, и поэтому между возможными значениями средних высот сеянцев в других выборках из происхождений Кунгур и Кизел различия будут опять доказаны. Но уровень доказательства понизился до 95 %, и для 5 % оставшихся случаев нет гарантии, что различия будут иметь место при выборке из 25 растений. Их может и не быть, но эту вероятность в 5 % мы допускаем.
2. Виды отбора.
3. Ошибки выборки, определение объема выборочной совокупности.
4. Способы распространения выборочных характеристик.
1. Понятие выборочного наблюдения, репрезентативность выборочного наблюдения.
1. Выборочное наблюдение несложное наблюдение, при котором обследуется не вся совокупность, а лишь часть, отобранная по определенным правилам выборки и обеспечивающая получение данных, характеризующих всю совокупность в целом.
При проведении выборочного наблюдения нельзя получить абсолютно точные данные, как при сплошном, т. к. обследованию подвергается не вся совокупность, а ее часть. Поэтому при проведении выборочного наблюдения неизбежна некоторая свойственная ему погрешность, ошибка.
Ошибки, свойственные выборочному наблюдению, называются ошибками репрезентативности, т. е. представительства. Они характеризуют размер расхождения между данными выборочного наблюдения и всей совокупности.
Ошибки репрезентативности делятся на случайные и систематические.
Случайные ошибки возникают вследствие того, что выборочная совокупность недостаточно точно воспроизводит совокупность, вследствие несплошного характера наблюдения. Случайные ошибки м. б. доведены до незначительных размеров, а главное размеры и пределы их можно определить с достаточной точностью на основании закона больших чисел и теории вероятности.
Систематические ошибки возникают в результате нарушения принципа случайности отбора единиц совокупности для наблюдения.
Вся совокупность единиц, из которой производится отбор, называется генеральной совокупностью и обозначается буквой N. Часть генеральной совокупности, попавшая в выборку, называется выборочной совокупностью и обозначается n.
Обобщающие показатели генеральной совокупности средняя, дисперсия, доля называются генеральными и соответственно обозначаются ![]() доля отнесения М единиц, обладающих определенным признаком, ко всей численности генеральной совокупности, т. е. М/N.
доля отнесения М единиц, обладающих определенным признаком, ко всей численности генеральной совокупности, т. е. М/N.
Обобщающие характеристики в выборочной совокупности называются выборочными и обозначаются соответственно x*, ![]() частость отношение числа единиц, обладающих данным признаком, в выборочной совокупности n, т. е.
частость отношение числа единиц, обладающих данным признаком, в выборочной совокупности n, т. е. ![]()
![]()
Теория выборочного метода дает возможность определить случайные ошибки обобщающих характеристик в выборочной совокупности.
Ошибка репрезентативности разность между выборочной средней и генеральной средней при достаточно большом числе наблюдений будет сколько угодно малой, т. е.
![]()
где ![]() абсолютная величина расхождения между генеральной средней и выборочной средней, составляющая ошибку репрезентативности.
абсолютная величина расхождения между генеральной средней и выборочной средней, составляющая ошибку репрезентативности.
![]() — среднее квадратическое отклонение вариантов выборочной средней от генеральной средней (средняя ошибка выборки). Она зависит от колеблемости признака в генеральной совокупности
— среднее квадратическое отклонение вариантов выборочной средней от генеральной средней (средняя ошибка выборки). Она зависит от колеблемости признака в генеральной совокупности ![]() и числа отобранных единиц n:
и числа отобранных единиц n: ![]() . Величина m зависит также от способа образования выборочной совокупности, т. к. между
. Величина m зависит также от способа образования выборочной совокупности, т. к. между ![]() средней ошибкой выборки и n числом отбираемых единиц существует обратно пропорциональная связь. Отсюда вытекает следующее правило: если надо уменьшить ошибку выборки, например, в 3 раза, необходимо увеличить объем выборки в девять раз.
средней ошибкой выборки и n числом отбираемых единиц существует обратно пропорциональная связь. Отсюда вытекает следующее правило: если надо уменьшить ошибку выборки, например, в 3 раза, необходимо увеличить объем выборки в девять раз.
Увеличение колеблемости признака в генеральной совокупности влечет за собой увеличение среднего квадратического отклонения, и следовательно и ошибки выборки.
Доказано, что соотношение между дисперсиями генеральной и выборочной совокупностей выражаются формулой:
![]() , т. к.
, т. к. ![]() при больших n приближается к 1, то
при больших n приближается к 1, то ![]()
Средняя ошибка выборки показывает, какие возможны отклонения характеристик выборочной совокупности от соответствующих характеристик генеральной совокупности. Однако о величине этой ошибки можно судить с определенной вероятностью, на величину которой указывает коэффициент доверия t.
Величина ![]() обозначается
обозначается ![]() называется предельной ошибкой выборки. Следовательно предельная ошибка выборки определяется формулой
называется предельной ошибкой выборки. Следовательно предельная ошибка выборки определяется формулой ![]() =
= ![]() . С увеличением t увеличивается вероятность нашего утверждения, но вместе с тем увеличивается и величина ошибки.
. С увеличением t увеличивается вероятность нашего утверждения, но вместе с тем увеличивается и величина ошибки.
2. Виды и схемы отбора.
Формирование выборочной совокупности из генеральной может осуществляться по-разному: в зависимости от вида и схемы отбора, и т. д. От их особенностей зависит размер ошибки и методы определения. Различаются 4 вида отбора:
1. собственно-случайный
2. механический
3. типический
4. серийный (гнездовой)
Собственно-случайный отбор включение единиц совокупности осуществляется наудачу. Наиболее распространенным способом отбора в случайной выборке является жеребьевка, при которой на каждую единицу заготавливают билет с порядковым номером. Затем в случайном порядке отбирают необходимое количество единиц совокупности. При этих условиях каждая из них имеет одинаковую вероятность попасть в выборку.
Механический отбор вся совокупность разбивается на равные по объему группы по случайному признаку. Затем из каждой группы случайно отбирается одна единица.
Типичный отбор совокупность расчленяется по существенному, типическому признаку на качественно однородные, однотипные группы. Затем из каждой группы случайным или механическим способом отбирается количество единиц, пропорциональное удельному весу группы во всей совокупности.
Типический отбор дает более точные результаты чем случайный или механический, потому что при нем в выборку в такой же пропорции как и в генеральной совокупности, попадают представители всех типических групп.
Серийный отбор (гнездовой) отбору подлежат не отдельные единицы совокупности, а целые группы, серии, гнезда, отобранные случайным или механическим способом. В каждой такой группе, серии проводится сплошное наблюдение, а результаты переносятся на всю совокупность.
Точность выборки зависит и от схемы отбора. Выборка м. б. проведена по схеме повторного или бесповторного отбора.
Повторный отбор каждая отобранная единица или серия возвращается во всю совокупность и может вновь попасть в выборку.
Бесповторный отбор каждая обследованная единица не возвращается в совокупность и не м. б. подвергнута повторному обследованию. Бесповторный отбор дает более точные результаты, т. к. при одном и том же объеме выборки наблюдение охватывает большее количество единиц изучаемой совокупности.
Обе схемы отбора могут применяться в сочетании с разными видами отбора, за исключением механического, который всегда бывает бесповторным.
3. Ошибки выборки, определение объема выборочной совокупности
Для суждения о праве распространения данных выборочного наблюдения на генеральную совокупность определяют величину ошибок между сводимыми показателями выборочной и генеральной совокупностей.
Обычно сопоставляют такие показатели:
1. Среднюю выборочной совокупности со средней генеральной совокупности, в результате чего получаем ошибку средней.
![]()
2. Частость выборочной совокупности с долей генеральной совокупности, что дает возможность определить ошибку частостей:
![]()
Разность между показателями выборочной и генеральной совокупностей называется ошибкой репрезентативности. Если эти показатели достаточно близки, то выборка считается репрезентативной.
Выборочная средняя и частость являются переменными величинами, т. е. могут принимать различные значения в зависимости от того, какие единицы совокупности попали в выборку. Следовательно, ошибки выборки также являются переменными величинами и также могут принимать различные значения в зависимости от единиц совокупности, попавшие в выборку. Вот почему определяется средняя из возможных ошибок, которая обозначается буквой ![]() . Величина
. Величина ![]() зависит от степени колеблемости значений признака в генеральной совокупности и от численности выборки n. Степень колеблемости в генеральной совокупности определяется средним квадратом отклонений или дисперсией
зависит от степени колеблемости значений признака в генеральной совокупности и от численности выборки n. Степень колеблемости в генеральной совокупности определяется средним квадратом отклонений или дисперсией ![]() . Из математических теорем и закона больших чисел следует, что при случайном отборе, проведенном по системе повторной выборки, между
. Из математических теорем и закона больших чисел следует, что при случайном отборе, проведенном по системе повторной выборки, между ![]() и п существует следующая зависимость:
и п существует следующая зависимость:
![]()
Ошибка выборочного наблюдения это разность между величиной параметра в генеральной совокупности и его величиной, вычисленной по результатам выборочного наблюдения
![]()
Чебышев доказал, что при достаточно большом числе независимых наблюдений можно с вероятностью, близкой к единице утверждать, что отклонение выборочной средней от генеральной будет сколь угодно малым.
![]() , величину
, величину ![]() называют средней ошибкой выборки.
называют средней ошибкой выборки.
Соотношение между дисперсиями генеральной и выборочной совокупности выражается формулой
![]()
Если выборочное наблюдение применяется для определения доли признака, то средняя ошибка доли исчисляется по формуле
![]() , т. к. дисперсия альтернативного признака
, т. к. дисперсия альтернативного признака ![]() , где p доля единиц совокупности, обладающих данным признаком, а q не обладающим данным признаком.
, где p доля единиц совокупности, обладающих данным признаком, а q не обладающим данным признаком.
В этих формулах ![]() и pq характеристики генеральной совокупности, которые при выборочном наблюдении неизвестны. На практике их заменяют аналогичными характеристиками выборочной совокупности, что вполне правомерно, т. к. основано на законе больших чисел, по которому выборочная совокупность при достаточно большом объеме выборки достаточно точно воспроизводит характеристики генеральной совокупности.
и pq характеристики генеральной совокупности, которые при выборочном наблюдении неизвестны. На практике их заменяют аналогичными характеристиками выборочной совокупности, что вполне правомерно, т. к. основано на законе больших чисел, по которому выборочная совокупность при достаточно большом объеме выборки достаточно точно воспроизводит характеристики генеральной совокупности.
При бесповторном отборе средняя ошибка выборки равна
![]() , а ошибка доли
, а ошибка доли ![]() , где N численность единиц генеральной совокупности.
, где N численность единиц генеральной совокупности.
Множитель ![]() всегда меньше единицы, т. к. n < N. Поэтому величина средней ошибки выборки при бесповторном отборе меньше чем при повторном.
всегда меньше единицы, т. к. n < N. Поэтому величина средней ошибки выборки при бесповторном отборе меньше чем при повторном.
Для решения практических задач выборочного обследования средней ошибки выборки недостаточно, потому что при исчислении ошибки конкретной выборки фактическая ошибка м. б. больше или меньше средней ошибки выборки ![]() . Поэтому пользуются не средней, а предельной ошибкой выборки, т. е. пределами, за которые не выйдет фактическая ошибка выборки.
. Поэтому пользуются не средней, а предельной ошибкой выборки, т. е. пределами, за которые не выйдет фактическая ошибка выборки.
Предельная ошибка выборки зависит от того, с какой вероятностью должна гарантироваться ошибка выборки. Уровень вероятности определяется на основе теорем Чебышева и Ляпунова при помощи специального коэффициента t.
Если предельную ошибку выборки обозначить буквой ![]() , то
, то 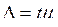 , где t коэффициент, зависящий от вероятности, с которой гарантируется ошибка выборки. Он называется еще коэффициентом доверия. Чтобы определить величину вероятности для различных значений t на практике пользуются готовой таблицей.
, где t коэффициент, зависящий от вероятности, с которой гарантируется ошибка выборки. Он называется еще коэффициентом доверия. Чтобы определить величину вероятности для различных значений t на практике пользуются готовой таблицей.
Систематизируем формулы для определения предельной ошибки средней и доли
|
Схема отбора |
Предельная ошибка выборки |
|
|
Для средней |
Для доли |
|
|
Повторный отбор Бесповторный отбор |
|
|
Из формул видно, что предельная ошибка выборки прямо пропорциональна коэффициенту t, дисперсии ![]() и обратно пропорциональна корню квадратному из численности выборки.
и обратно пропорциональна корню квадратному из численности выборки.
Дисперсия ![]() величина конкретная, свойственная данной совокупности. Обычно она неизвестна, а известна
величина конкретная, свойственная данной совокупности. Обычно она неизвестна, а известна ![]() *, которой и заменяют величину
*, которой и заменяют величину ![]() , потому что в силу действия закона больших чисел при достаточно большом объеме выборки n распределение признака x в выборочной совокупности близко воспроизводит распределение этого признака в генеральной совокупности.
, потому что в силу действия закона больших чисел при достаточно большом объеме выборки n распределение признака x в выборочной совокупности близко воспроизводит распределение этого признака в генеральной совокупности.
Ошибка выборки зависит и от ее объема n. Чем больше объем выборки, тем меньше предельная ошибка (при данных ![]() и t)
и t)
Рассмотренные формулы средней и предельной ошибки и доли применяются при случайном и механическом видах отбора.
При типическом отборе предельная ошибка выборки и доли определяется по формулам:
|
Схема отбора |
Предельная ошибка выборки |
|
|
Для средней |
Для доли |
|
|
Повторный отбор Бесповторный отбор |
|
|
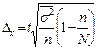
т. е. при типичном отборе надо брать средние из внутригрупповых дисперсий и доли, полученные по каждой типической группе.
Из этих формул видно, что при типическом отборе в отличие от случайного исключается влияние межгрупповой вариации на точность выборки, т. к. в выборку обязательно попадают представители всех групп в тех же пропорциях, что и в генеральной совокупности. Ошибка выборки при типичном отборе зависит только от средней из внутригрупповых дисперсий, а не от общей дисперсии, как при случайном отборе т. к.
![]() , откуда
, откуда 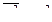
Следовательно ошибка выборки при типическом отборе всегда меньше ошибки выборки, проведенной случайным отбором.
При серийном отборе каждая серия рассматривается как единица совокупности, и мерой колеблемости будет межсерийная выборочная дисперсия, т. е. средний квадрат отклонений серийных средних от общей выборочной средней:
![]() , где
, где ![]() средняя по каждой серии, x* общая выборочная средняя, s число отобранных серий.
средняя по каждой серии, x* общая выборочная средняя, s число отобранных серий.
Предельная ошибка выборки и доли при серийном отборе с равновеликими сериями определяется по формулам, где S общее число серий в генеральной совокупности.
|
Схема отбора |
Предельная ошибка выборки |
|
|
Для средней |
Для доли |
|
|
Повторный отбор Бесповторный отбор |
|
|
Выборочное наблюдение, объем которого превышает 20 единиц, называется малой выборкой. Для определения средней и предельной ошибок при малой выборке пользуются теми же формулами, что и при большой, но только с некоторыми особенностями, так ![]() , а
, а 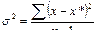 .
.
Кроме того, в случае малой выборки действует особый закон распределения величин t, и при определении вероятности учитывается не только коэффициент t, но и объем выборки n.
Необходимая численность выборки (n) определяется на основе формул предельной ошибки выборки.
Если выборка повторная, то при случайном и механическом отборах определяется по формуле
![]() , при бесповторном отборе
, при бесповторном отборе ![]()
4. Способы распространения выборочных характеристик.
Есть два способа распространения выборочных характеристик на всю совокупность прямой пересчет и способ коэффициентов
Способ прямого пересчета заключается в том, что средние или частости выборочной совокупности умножаются на числа единиц генеральной совокупности.
Когда выборочное обследование проводится в целях уточнения данных сплошного наблюдения, применяется способ коэффициентов. В этом случае данные сплошного наблюдения сопоставляют с данными выборочного наблюдения и устанавливают процент расхождения между ними, т. е. процент надоучета или переучета. Коэффициенты, полученные в результате такого сопоставления, используются для внесения поправок в данные сплошного учета.
Пример.
1) способ прямого пересчета
Для определения качества продукции проверено 500 изделий из 10000. В результате чего установлено, что средний % изделий 3-го сорта всей партии будет находиться в пределах 6,1-13,9%. Способом прямого пересчета определяем, что обще кол-во изделий 3-го сорта всей партии составит от 610 до 1390
10000*0,061= 610
10000*0,139 = 1390
2) способ коэффициентов
Пример
Необходимо определить численность выборки, которая позволила бы оценить долю брака в партии продукции с точностью до 2%, с вероятностью Р =0,954. Партия состоит из 10000 изделий
![]() ,
, ![]()
![]()
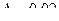 , P =0,954, t =2
, P =0,954, t =2
![]() pq=0,25 (p=0,5; q=0,5)
pq=0,25 (p=0,5; q=0,5)