
Выборочная оценка всегда ошибочна. Так, стандартная ошибка средней показывает разброс средней. Для бинарной переменной (с двумя возможными значениями) средней арифметической является доля «успехов». В этой статье показано, как рассчитать дисперсию и стандартную ошибку доли.
Долю используют в качестве выборочной оценки вероятности. Обозначим долю как p*, а истинную вероятность как p . При бесконечно большом количестве наблюдений доля p* стремится к теоретической вероятности p. Этот факт известен со времен Якоба Бернулли.
Дисперсия и стандартная ошибка доли
Обратимся вначале к дисперсии биномиальной переменной. Если истинная вероятность p не известна, то используют ее оценку p*.
![]()
где B – сумма «успехов» в выборке;
n – количество наблюдений;
p* – оценка вероятности, т.е. доля «успехов».
Нас интересует дисперсия величины B/n. Согласно одному из свойств дисперсии, постоянный множитель выносится за скобки и возводится в квадрат.
Получаем формулу дисперсию доли:
![]()
Почти полная аналогия со средней арифметической. В числителе дисперсия самой переменной (1 или 0), внизу – объем выборки.
Стандартная ошибка доли – корень из дисперсии:

Стандартная ошибка доли при увеличении выборки ведет себя так же, как и стандартная ошибка средней: чем больше выборка, тем меньше ошибка, но при этом уменьшение постоянно замедляется.
Как известно, максимально возможная дисперсия переменной в схеме Бернулли достигается при p*=0,5. Она равна 0,5*(1-0,5)=0,25. Отсюда легко рассчитать максимальную стандартную ошибку доли, полученную по некоторой выборке.

Изобразим эту зависимость на диаграмме.

График имеет знакомую конфигурацию: ошибка уменьшается с замедлением. Так, при объеме выборки равной 100 наблюдениям стандартная ошибка (максимально возможная!) равна 0,05 (или 5 процентных пункта). При n=1000 стандартная ошибка доли составляет всего 0,0158 (или 1,58 процентных пункта). Повторюсь, что это максимум. Именно поэтому опросы общественно мнения редко превышают 1500-2000 человек (чтобы еще была возможность разбить данные на группы достаточно размера).
На практике довольно часто приходится анализировать бинарные данные. Это может быть анкетирование покупателей, контроль качества продукции и много чего еще. Поэтому доля, как оценка вероятности наступления интересующего события, – довольно распространенный показатель. Дисперсия и стандартная ошибка доли используется в расчете приблизительных доверительных интервалов вероятности и в проверке статистических гипотез.
Поделиться в социальных сетях:
Выборочная оценка всегда ошибочна. Так, стандартная ошибка средней показывает разброс средней. Для бинарной переменной (с двумя возможными значениями) средней арифметической является доля «успехов». В этой статье показано, как рассчитать дисперсию и стандартную ошибку доли.
Долю используют в качестве выборочной оценки вероятности. Обозначим долю как p*, а истинную вероятность как p . При бесконечно большом количестве наблюдений доля p* стремится к теоретической вероятности p. Этот факт известен со времен Якоба Бернулли.
Дисперсия и стандартная ошибка доли
Обратимся вначале к дисперсии биномиальной переменной. Если истинная вероятность p не известна, то используют ее оценку p*.
![]()
где B – сумма «успехов» в выборке;
n – количество наблюдений;
p* – оценка вероятности, т.е. доля «успехов».
Нас интересует дисперсия величины B/n. Согласно одному из свойств дисперсии, постоянный множитель выносится за скобки и возводится в квадрат.
Получаем формулу дисперсию доли:
![]()
Почти полная аналогия со средней арифметической. В числителе дисперсия самой переменной (1 или 0), внизу – объем выборки.
Стандартная ошибка доли – корень из дисперсии:
Стандартная ошибка доли при увеличении выборки ведет себя так же, как и стандартная ошибка средней: чем больше выборка, тем меньше ошибка, но при этом уменьшение постоянно замедляется.
Как известно, максимально возможная дисперсия переменной в схеме Бернулли достигается при p*=0,5. Она равна 0,5*(1-0,5)=0,25. Отсюда легко рассчитать максимальную стандартную ошибку доли, полученную по некоторой выборке.
Изобразим эту зависимость на диаграмме.
График имеет знакомую конфигурацию: ошибка уменьшается с замедлением. Так, при объеме выборки равной 100 наблюдениям стандартная ошибка (максимально возможная!) равна 0,05 (или 5 процентных пункта). При n=1000 стандартная ошибка доли составляет всего 0,0158 (или 1,58 процентных пункта). Повторюсь, что это максимум. Именно поэтому опросы общественно мнения редко превышают 1500-2000 человек (чтобы еще была возможность разбить данные на группы достаточно размера).
На практике довольно часто приходится анализировать бинарные данные. Это может быть анкетирование покупателей, контроль качества продукции и много чего еще. Поэтому доля, как оценка вероятности наступления интересующего события, – довольно распространенный показатель. Дисперсия и стандартная ошибка доли используется в расчете приблизительных доверительных интервалов вероятности и в проверке статистических гипотез.
Поделиться в социальных сетях:
Точность оценки долей
Если бы в наших руках были данные по
всем членам совокупности, то не было бы
никаких проблем связанных с точностью
оценок. Однако нам всегда приходится
довольствоваться ограниченной выборкой.
Поэтому возникает вопрос, насколько
точно доли в выборке соответствуют
долям в совокупности.

Рис. 5.4. А. Из совокупности марсиан, среди
которых 150 зеленых и 50 розовых, извлекли
случайную выборку из 10 особей. В выборку
попало 5 зеленых и 5 розовых марсиан, на
рисунке они помечены черным. Б. В таком
виде данные предстанут перед исследователем,
который не может наблюдать всю совокупность
и вынужден судить о ней по выборке.
Оценка доли розовых марсиан p = 5/10 = 0,5.
Как любая выборочная оценка, оценка
доли (обозначим ее p^) отражает
долю р в совокупности, но отклоняется
от нее в силу случайности. Рассмотрим
теперь не совокупность марсиан, а
совокупность всех значений p^ ,
вычисленных по выборкам объемом 10
каждая. (Из совокупности в 200 членов
можно получить более 106 таких
выборок). По аналогии со стандартной
ошибкой среднего найдем стандартную
ошибку доли. Для этого нужно
охарактеризовать разброс выборочных
оценок доли, то есть рассчитать стандартное
отклонение совокупности p^.
![]()
где σ p^ — стандартная ошибка
доли, σ — стандартное отклонение, n —
объем выборки.

Заменив в приведенной формуле истинное
значение доли ее оценкой p^ ,
получим оценку стандартной ошибки доли:

Из центральной предельной теоремы
вытекает, что при достаточно большом
объеме выборки выборочная оценка p^
приближенно подчиняется
нормальному распределению, имеющему
среднее р и стандартное отклонение σˆp
. Однако при значениях р, близких к 0 или
1, и при малом объеме выборки это не так.
При какой численности выборки можно
пользоваться приведенным способом
оценки? Математическая статистика
утверждает, что нормальное распределение
служит хорошим приближением, если np^
и n(1-p^)
превосходят 5. Напомним, что примерно
95% всех членов нормально распределенной
совокупности находятся в пределах двух
стандартных отклонений от среднего.
Поэтому если перечисленные условия
соблюдены, то с вероятностью 95% можно
утверждать, что истинное значение р
лежит в пределах np^
и n(1-p^).
Вернемся на минуту к сравнению операционной
летальности при галотановой и морфиновой
анестезии. Напомним, что при использовании
галотана летальность составила 13,1%
(численность группы — 61 больной), а при
использовании морфина —
14,9% (численность группы — 67 больных).
Стандартная ошибка доли для группы


Если учесть, что различие в летальности
составило лишь 2%, то маловероятно, чтобы
оно было обусловлено чем-нибудь, кроме
случайного характера выборки.
Перечислим те предпосылки, на которых
основан излагаемый подход. Мы изучаем
то, что в статистике принято называть
независимыми испытаниями Бернулли.
Эти испытания обладают следующими
свойствами.
• Каждое отдельное испытание имеет
ровно два возможных взаимно исключающих
исхода.
• Вероятность данного исхода одна и та
же в любом испытании.
• Все испытания независимы друг от
друга.
21
Соседние файлы в папке Старый материал
- #
- #
- #
- #
- #
- #
- #
Выборочная оценка всегда ошибочна. Так, стандартная ошибка средней показывает разброс средней. Для бинарной переменной (с двумя возможными значениями) средней арифметической является доля «успехов». В этой статье показано, как рассчитать дисперсию и стандартную ошибку доли.
Долю используют в качестве выборочной оценки вероятности. Обозначим долю как p*, а истинную вероятность как p . При бесконечно большом количестве наблюдений доля p* стремится к теоретической вероятности p. Этот факт известен со времен Якоба Бернулли.
Дисперсия и стандартная ошибка доли
Обратимся вначале к дисперсии биномиальной переменной. Если истинная вероятность p не известна, то используют ее оценку p*.
![]()
где B – сумма «успехов» в выборке;
n – количество наблюдений;
p* – оценка вероятности, т.е. доля «успехов».
Нас интересует дисперсия величины B/n. Согласно одному из свойств дисперсии, постоянный множитель выносится за скобки и возводится в квадрат.
Получаем формулу дисперсию доли:
![]()
Почти полная аналогия со средней арифметической. В числителе дисперсия самой переменной (1 или 0), внизу – объем выборки.
Стандартная ошибка доли – корень из дисперсии:
Стандартная ошибка доли при увеличении выборки ведет себя так же, как и стандартная ошибка средней: чем больше выборка, тем меньше ошибка, но при этом уменьшение постоянно замедляется.
Как известно, максимально возможная дисперсия переменной в схеме Бернулли достигается при p*=0,5. Она равна 0,5*(1-0,5)=0,25. Отсюда легко рассчитать максимальную стандартную ошибку доли, полученную по некоторой выборке.
Изобразим эту зависимость на диаграмме.
График имеет знакомую конфигурацию: ошибка уменьшается с замедлением. Так, при объеме выборки равной 100 наблюдениям стандартная ошибка (максимально возможная!) равна 0,05 (или 5 процентных пункта). При n=1000 стандартная ошибка доли составляет всего 0,0158 (или 1,58 процентных пункта). Повторюсь, что это максимум. Именно поэтому опросы общественно мнения редко превышают 1500-2000 человек (чтобы еще была возможность разбить данные на группы достаточно размера).
На практике довольно часто приходится анализировать бинарные данные. Это может быть анкетирование покупателей, контроль качества продукции и много чего еще. Поэтому доля, как оценка вероятности наступления интересующего события, – довольно распространенный показатель. Дисперсия и стандартная ошибка доли используется в расчете приблизительных доверительных интервалов вероятности и в проверке статистических гипотез.
Поделиться в социальных сетях:
Точность оценки долей
Если бы в наших руках были данные по
всем членам совокупности, то не было бы
никаких проблем связанных с точностью
оценок. Однако нам всегда приходится
довольствоваться ограниченной выборкой.
Поэтому возникает вопрос, насколько
точно доли в выборке соответствуют
долям в совокупности.
Рис. 5.4. А. Из совокупности марсиан, среди
которых 150 зеленых и 50 розовых, извлекли
случайную выборку из 10 особей. В выборку
попало 5 зеленых и 5 розовых марсиан, на
рисунке они помечены черным. Б. В таком
виде данные предстанут перед исследователем,
который не может наблюдать всю совокупность
и вынужден судить о ней по выборке.
Оценка доли розовых марсиан p = 5/10 = 0,5.
Как любая выборочная оценка, оценка
доли (обозначим ее p^) отражает
долю р в совокупности, но отклоняется
от нее в силу случайности. Рассмотрим
теперь не совокупность марсиан, а
совокупность всех значений p^ ,
вычисленных по выборкам объемом 10
каждая. (Из совокупности в 200 членов
можно получить более 106 таких
выборок). По аналогии со стандартной
ошибкой среднего найдем стандартную
ошибку доли. Для этого нужно
охарактеризовать разброс выборочных
оценок доли, то есть рассчитать стандартное
отклонение совокупности p^.
![]()
где σ p^ — стандартная ошибка
доли, σ — стандартное отклонение, n —
объем выборки.
Заменив в приведенной формуле истинное
значение доли ее оценкой p^ ,
получим оценку стандартной ошибки доли:
Из центральной предельной теоремы
вытекает, что при достаточно большом
объеме выборки выборочная оценка p^
приближенно подчиняется
нормальному распределению, имеющему
среднее р и стандартное отклонение σˆp
. Однако при значениях р, близких к 0 или
1, и при малом объеме выборки это не так.
При какой численности выборки можно
пользоваться приведенным способом
оценки? Математическая статистика
утверждает, что нормальное распределение
служит хорошим приближением, если np^
и n(1-p^)
превосходят 5. Напомним, что примерно
95% всех членов нормально распределенной
совокупности находятся в пределах двух
стандартных отклонений от среднего.
Поэтому если перечисленные условия
соблюдены, то с вероятностью 95% можно
утверждать, что истинное значение р
лежит в пределах np^
и n(1-p^).
Вернемся на минуту к сравнению операционной
летальности при галотановой и морфиновой
анестезии. Напомним, что при использовании
галотана летальность составила 13,1%
(численность группы — 61 больной), а при
использовании морфина —
14,9% (численность группы — 67 больных).
Стандартная ошибка доли для группы
Если учесть, что различие в летальности
составило лишь 2%, то маловероятно, чтобы
оно было обусловлено чем-нибудь, кроме
случайного характера выборки.
Перечислим те предпосылки, на которых
основан излагаемый подход. Мы изучаем
то, что в статистике принято называть
независимыми испытаниями Бернулли.
Эти испытания обладают следующими
свойствами.
• Каждое отдельное испытание имеет
ровно два возможных взаимно исключающих
исхода.
• Вероятность данного исхода одна и та
же в любом испытании.
• Все испытания независимы друг от
друга.
21
Соседние файлы в папке Старый материал
- #
- #
- #
- #
- #
- #
- #
Стандартная ошибка пропорции: формула и пример
17 авг. 2022 г.
читать 1 мин
Часто в статистике нас интересует оценка доли людей в популяции с определенной характеристикой.
Например, нас может заинтересовать оценка доли жителей определенного города, поддерживающих новый закон.
Вместо того, чтобы ходить и спрашивать каждого жителя, поддерживают ли они закон, мы вместо этого собираем простую случайную выборку и выясняем, сколько жителей в выборке поддерживают закон.
Затем мы рассчитали бы долю выборки (p̂) как:
Пример формулы пропорции:
р̂ = х / п
куда:
- x: количество лиц в выборке с определенной характеристикой.
- n: общее количество лиц в выборке.
Затем мы использовали бы эту пропорцию выборки для оценки доли населения. Например, если 47 из 300 жителей выборки поддержали новый закон, то выборочная доля будет рассчитана как 47/300 = 0,157 .
Это означает, что наша наилучшая оценка доли жителей в населении, поддержавших закон, будет равна 0,157 .
Однако нет никакой гарантии, что эта оценка будет точно соответствовать истинной доле населения, поэтому мы обычно также рассчитываем стандартную ошибку доли .
Это рассчитывается как:
Стандартная ошибка формулы пропорции:
Стандартная ошибка = √ p̂(1-p̂) / n
Например, если p̂ = 0,157 и n = 300, то мы рассчитали бы стандартную ошибку пропорции как:
Стандартная ошибка пропорции = √ 0,157 (1-0,157) / 300 = 0,021
Затем мы обычно используем эту стандартную ошибку для расчета доверительного интервала для истинной доли жителей, поддерживающих закон.
Это рассчитывается как:
Доверительный интервал для формулы доли населения:
Доверительный интервал = p̂ +/- z * √ p̂(1-p̂) / n
Глядя на эту формулу, легко увидеть, что чем больше стандартная ошибка пропорции, тем шире доверительный интервал .
Обратите внимание, что z в формуле — это z-значение, которое соответствует популярным вариантам выбора уровня достоверности:
| Уровень достоверности | z-значение | | — | — | | 0,90 | 1,645 | | 0,95 | 1,96 | | 0,99 | 2,58 |
Например, вот как рассчитать 95% доверительный интервал для истинной доли жителей города, поддерживающих новый закон:
- 95% ДИ = p̂ +/- z * √ p̂(1-p̂) / n
- 95% ДИ = 0,157 +/- 1,96 * √ 0,157 (1-0,157) / 300
- 95% ДИ = 0,157 +/- 1,96*(0,021)
- 95% ДИ = [0,10884, 0,19816]
Таким образом, с уверенностью 95% можно сказать, что истинная доля жителей города, поддерживающих новый закон, составляет от 10,884% до 19,816%.
Дополнительные ресурсы
Стандартная ошибка калькулятора пропорций
Доверительный интервал для калькулятора пропорций
Что такое доля населения?
Стандартная ошибка пропорции: формула и пример
17 авг. 2022 г.
читать 1 мин
Часто в статистике нас интересует оценка доли людей в популяции с определенной характеристикой.
Например, нас может заинтересовать оценка доли жителей определенного города, поддерживающих новый закон.
Вместо того, чтобы ходить и спрашивать каждого жителя, поддерживают ли они закон, мы вместо этого собираем простую случайную выборку и выясняем, сколько жителей в выборке поддерживают закон.
Затем мы рассчитали бы долю выборки (p̂) как:
Пример формулы пропорции:
р̂ = х / п
куда:
- x: количество лиц в выборке с определенной характеристикой.
- n: общее количество лиц в выборке.
Затем мы использовали бы эту пропорцию выборки для оценки доли населения. Например, если 47 из 300 жителей выборки поддержали новый закон, то выборочная доля будет рассчитана как 47/300 = 0,157 .
Это означает, что наша наилучшая оценка доли жителей в населении, поддержавших закон, будет равна 0,157 .
Однако нет никакой гарантии, что эта оценка будет точно соответствовать истинной доле населения, поэтому мы обычно также рассчитываем стандартную ошибку доли .
Это рассчитывается как:
Стандартная ошибка формулы пропорции:
Стандартная ошибка = √ p̂(1-p̂) / n
Например, если p̂ = 0,157 и n = 300, то мы рассчитали бы стандартную ошибку пропорции как:
Стандартная ошибка пропорции = √ 0,157 (1-0,157) / 300 = 0,021
Затем мы обычно используем эту стандартную ошибку для расчета доверительного интервала для истинной доли жителей, поддерживающих закон.
Это рассчитывается как:
Доверительный интервал для формулы доли населения:
Доверительный интервал = p̂ +/- z * √ p̂(1-p̂) / n
Глядя на эту формулу, легко увидеть, что чем больше стандартная ошибка пропорции, тем шире доверительный интервал .
Обратите внимание, что z в формуле — это z-значение, которое соответствует популярным вариантам выбора уровня достоверности:
| Уровень достоверности | z-значение | | — | — | | 0,90 | 1,645 | | 0,95 | 1,96 | | 0,99 | 2,58 |
Например, вот как рассчитать 95% доверительный интервал для истинной доли жителей города, поддерживающих новый закон:
- 95% ДИ = p̂ +/- z * √ p̂(1-p̂) / n
- 95% ДИ = 0,157 +/- 1,96 * √ 0,157 (1-0,157) / 300
- 95% ДИ = 0,157 +/- 1,96*(0,021)
- 95% ДИ = [0,10884, 0,19816]
Таким образом, с уверенностью 95% можно сказать, что истинная доля жителей города, поддерживающих новый закон, составляет от 10,884% до 19,816%.
Дополнительные ресурсы
Стандартная ошибка калькулятора пропорций
Доверительный интервал для калькулятора пропорций
Что такое доля населения?
Точность оценки долей
Если бы в наших руках были данные по
всем членам совокупности, то не было бы
никаких проблем связанных с точностью
оценок. Однако нам всегда приходится
довольствоваться ограниченной выборкой.
Поэтому возникает вопрос, насколько
точно доли в выборке соответствуют
долям в совокупности.
Рис. 5.4. А. Из совокупности марсиан, среди
которых 150 зеленых и 50 розовых, извлекли
случайную выборку из 10 особей. В выборку
попало 5 зеленых и 5 розовых марсиан, на
рисунке они помечены черным. Б. В таком
виде данные предстанут перед исследователем,
который не может наблюдать всю совокупность
и вынужден судить о ней по выборке.
Оценка доли розовых марсиан p = 5/10 = 0,5.
Как любая выборочная оценка, оценка
доли (обозначим ее p^) отражает
долю р в совокупности, но отклоняется
от нее в силу случайности. Рассмотрим
теперь не совокупность марсиан, а
совокупность всех значений p^ ,
вычисленных по выборкам объемом 10
каждая. (Из совокупности в 200 членов
можно получить более 106 таких
выборок). По аналогии со стандартной
ошибкой среднего найдем стандартную
ошибку доли. Для этого нужно
охарактеризовать разброс выборочных
оценок доли, то есть рассчитать стандартное
отклонение совокупности p^.
![]()
где σ p^ — стандартная ошибка
доли, σ — стандартное отклонение, n —
объем выборки.
Заменив в приведенной формуле истинное
значение доли ее оценкой p^ ,
получим оценку стандартной ошибки доли:
Из центральной предельной теоремы
вытекает, что при достаточно большом
объеме выборки выборочная оценка p^
приближенно подчиняется
нормальному распределению, имеющему
среднее р и стандартное отклонение σˆp
. Однако при значениях р, близких к 0 или
1, и при малом объеме выборки это не так.
При какой численности выборки можно
пользоваться приведенным способом
оценки? Математическая статистика
утверждает, что нормальное распределение
служит хорошим приближением, если np^
и n(1-p^)
превосходят 5. Напомним, что примерно
95% всех членов нормально распределенной
совокупности находятся в пределах двух
стандартных отклонений от среднего.
Поэтому если перечисленные условия
соблюдены, то с вероятностью 95% можно
утверждать, что истинное значение р
лежит в пределах np^
и n(1-p^).
Вернемся на минуту к сравнению операционной
летальности при галотановой и морфиновой
анестезии. Напомним, что при использовании
галотана летальность составила 13,1%
(численность группы — 61 больной), а при
использовании морфина —
14,9% (численность группы — 67 больных).
Стандартная ошибка доли для группы
Если учесть, что различие в летальности
составило лишь 2%, то маловероятно, чтобы
оно было обусловлено чем-нибудь, кроме
случайного характера выборки.
Перечислим те предпосылки, на которых
основан излагаемый подход. Мы изучаем
то, что в статистике принято называть
независимыми испытаниями Бернулли.
Эти испытания обладают следующими
свойствами.
• Каждое отдельное испытание имеет
ровно два возможных взаимно исключающих
исхода.
• Вероятность данного исхода одна и та
же в любом испытании.
• Все испытания независимы друг от
друга.
21
Соседние файлы в папке Старый материал
- #
- #
- #
- #
- #
- #
- #
Стандартная ошибка пропорции: формула и пример
17 авг. 2022 г.
читать 1 мин
Часто в статистике нас интересует оценка доли людей в популяции с определенной характеристикой.
Например, нас может заинтересовать оценка доли жителей определенного города, поддерживающих новый закон.
Вместо того, чтобы ходить и спрашивать каждого жителя, поддерживают ли они закон, мы вместо этого собираем простую случайную выборку и выясняем, сколько жителей в выборке поддерживают закон.
Затем мы рассчитали бы долю выборки (p̂) как:
Пример формулы пропорции:
р̂ = х / п
куда:
- x: количество лиц в выборке с определенной характеристикой.
- n: общее количество лиц в выборке.
Затем мы использовали бы эту пропорцию выборки для оценки доли населения. Например, если 47 из 300 жителей выборки поддержали новый закон, то выборочная доля будет рассчитана как 47/300 = 0,157 .
Это означает, что наша наилучшая оценка доли жителей в населении, поддержавших закон, будет равна 0,157 .
Однако нет никакой гарантии, что эта оценка будет точно соответствовать истинной доле населения, поэтому мы обычно также рассчитываем стандартную ошибку доли .
Это рассчитывается как:
Стандартная ошибка формулы пропорции:
Стандартная ошибка = √ p̂(1-p̂) / n
Например, если p̂ = 0,157 и n = 300, то мы рассчитали бы стандартную ошибку пропорции как:
Стандартная ошибка пропорции = √ 0,157 (1-0,157) / 300 = 0,021
Затем мы обычно используем эту стандартную ошибку для расчета доверительного интервала для истинной доли жителей, поддерживающих закон.
Это рассчитывается как:
Доверительный интервал для формулы доли населения:
Доверительный интервал = p̂ +/- z * √ p̂(1-p̂) / n
Глядя на эту формулу, легко увидеть, что чем больше стандартная ошибка пропорции, тем шире доверительный интервал .
Обратите внимание, что z в формуле — это z-значение, которое соответствует популярным вариантам выбора уровня достоверности:
| Уровень достоверности | z-значение | | — | — | | 0,90 | 1,645 | | 0,95 | 1,96 | | 0,99 | 2,58 |
Например, вот как рассчитать 95% доверительный интервал для истинной доли жителей города, поддерживающих новый закон:
- 95% ДИ = p̂ +/- z * √ p̂(1-p̂) / n
- 95% ДИ = 0,157 +/- 1,96 * √ 0,157 (1-0,157) / 300
- 95% ДИ = 0,157 +/- 1,96*(0,021)
- 95% ДИ = [0,10884, 0,19816]
Таким образом, с уверенностью 95% можно сказать, что истинная доля жителей города, поддерживающих новый закон, составляет от 10,884% до 19,816%.
Дополнительные ресурсы
Стандартная ошибка калькулятора пропорций
Доверительный интервал для калькулятора пропорций
Что такое доля населения?
Страницы работы
Содержание работы
Тема:Анализ качественных признаков
(Критерий χ2. Сравнение долей.)
Критерий χ2 – это непараметрический
критерий, является аналогом дисперсионного анализа для качественных признаков.
По имеющимся данным исследования строят таблицу
сопряженности. Строки таблицы представляют собой сравниваемые факторы, а
столбцы — возможные исходы эксперимента. Подсчитывают число объектов в каждой
строке и каждом столбце. Наблюдаемые значения обозначают буквой О (observed).
Таблица сопряженности выглядит следующим образом (Ri – суммы в строках таблицы, Cj – суммы в столбцах таблицы, N – общий объем
исследования, r-число строк, c-число столбцов):
|
О11 |
О12 |
… |
O1c |
R1 |
|
О21 |
О22 |
… |
O2c |
R2 |
|
… |
… |
… |
… |
… |
|
Or1 |
Or2 |
… |
Orc |
Rr |
|
C1 |
C2 |
… |
Cc |
N |
Далее подсчитывают с точностью до двух знаков после
запятой ожидаемые числа – количество объектов, которое попало бы в каждую
клетку, если бы изучаемые факторы не влияли бы на исход. Ожидаемые значения
обозначают буквой E (expected).
Таблица ожидаемых чисел рассчитывается следующим образом (обратите внимание,
что суммы по строкам и столбцам должны сохраниться):
|
E11=R1∙C1/N |
E12=R1∙C2/N |
… |
E1c=R1∙Cc/N |
R1 |
|
E21=R2∙C1/N |
E22=R2∙C2/N |
… |
E2c=R2∙Cc/N |
R2 |
|
… |
… |
… |
… |
… |
|
Er1=Rr∙C1/N |
Er2=Rr∙C2/N |
… |
Erc=Rr∙Cc/N |
Rr |
|
C1 |
C2 |
… |
Сс |
N |
По полученным таблицам рассчитывается значение
критерия:
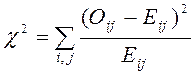 ,
,
где Оij – наблюдаемые значения в
клетках таблицы, Еij – ожидаемые значения. Суммирование производится по
всем клеткам таблицы.
Применение критерия χ2 правомерно, если
ожидаемые числа в любой из клеток больше либо равны 5.
Число степеней свободы ν=(r-1)(c-1).
В случае таблицы 2×2 в формулу вводят поправку Йейтса:
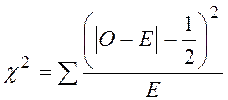 .
.
Пример.
Изучение влияния дополнительного
приема эстрогена на риск развития болезни Альцгеймера. В исследовании принимала
участие группа из 1124 пожилых женщин, 156 из которых длительное время получали
эстроген. Группа наблюдалась в течение пяти лет, регистрировались случаи
болезни Альцгеймера. Результаты расчетов:
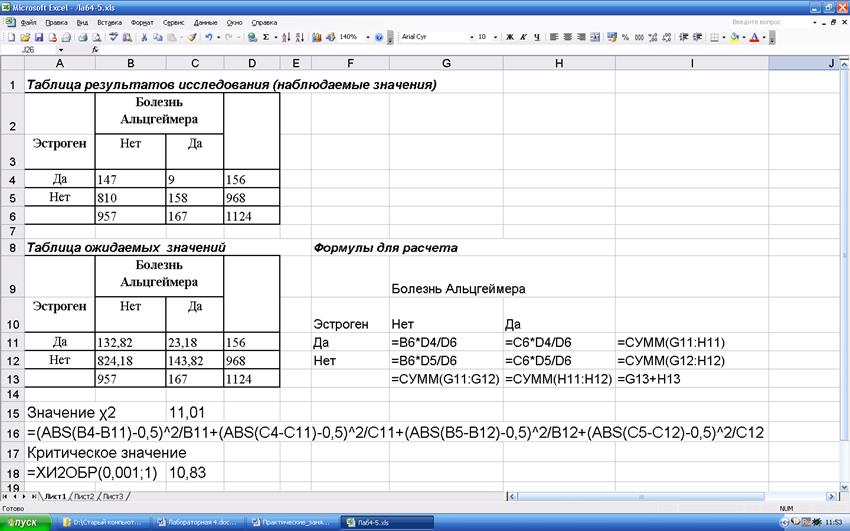
Рассчитанное значение больше критического, поэтому
можем утверждать, что дополнительный прием эстрогена снижает риск развития
болезни Альцгеймера (вероятность ошибки менее 0,1%).
Задание 1
1. Синдром внезапной детской смерти —
основная причина смерти детей в возрасте от 1 недели до 1 года. Обычно смерть
наступает на фоне полного здоровья незаметно, во сне, поэтому определение
факторов риска имеет первостепенное значение. Исследователи собрали сведения о
18 955 детях, родившихся в одном из роддомов Окленда, штат Калифорния, с
1960 по 1967 г. Судьбу детей проследили до 1 года. От синдрома внезапной
детской смерти умерли 44 ребенка. Данные о предполагаемых факторах риска
представлены в таблице. Найдите признаки, связанные с риском синдрома внезапной
детской смерти (два по выбору). По некоторым признакам данные отсутствуют,
поэтому сумма в третьем столбце может оказаться меньше 44, а в четвертом —
меньше 18955.
|
Фактор |
Синдром |
||
|
Да |
Нет |
||
|
Возраст матери |
До 25 лет 25 лет и старше |
29 15 |
7301 11241 |
|
Время от окончания |
Менее 1 года Более 1 года |
23 11 |
4694 7339 |
|
Планировалась ли |
Нет Да |
23 5 |
7654 4253 |
|
Курение во время |
Да Нет |
24 10 |
5228 9595 |
|
Низкий гемоглобин во |
Да Нет |
26 7 |
12613 2678 |
|
Раса |
Белые Негры Другие |
31 9 4 |
12240 4323 2153 |
1.2.
Проводилась оценка эффективности терапии для лечения синдрома хронической
обеспокоенности. В исследовании принимало участие 150 человек, 60 из которых
получали двухмесячную программу лечения. После двух месяцев проводилась оценка
состояния (ухудшилось, улучшилось, не изменилось). Результаты в таблице:
|
Терапия |
Состояние |
|||
|
Ухудшилось |
Не изменилось |
Улучшилось |
||
|
Да |
24 |
11 |
25 |
60 |
|
Нет |
30 |
31 |
29 |
90 |
|
54 |
42 |
54 |
150 |
Есть
статистически значимые различия между группами? Что произойдет, если удвоить
количество участников эксперимента при сохранении пропорций между группами?
Рассчитайте.
Оценка и сравнение долей
Пусть имеется выборка из n объектов, при
этом m из них обладает каким-то качественным признаком,
которого нет у остальных n-m объектов. Тогда доля объектов, выборки, обладающих
признаком, вычисляется как p=m/n. Показатель разброса значений – стандартное
отклонение доли – вычисляется по формуле: ![]() ;
;
стандартная ошибка доли: 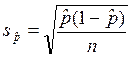 .
.
Критерий z для проверки нулевой гипотезы о равенстве
долей в двух выборках:
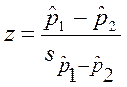
где
![]() — выборочные доли,
— выборочные доли, ![]() —
—
стандартная ошибка разности долей.
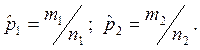 Объединенная оценка
Объединенная оценка
доли: 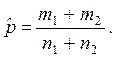
Стандартная ошибка разности долей вычисляется:
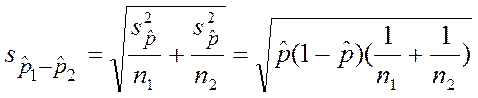 .
.
Для нахождения критических значений z необходимо
воспользоваться таблицами значений стандартного нормального распределения. При
увеличении числа степеней свободы распределение Стьюдента стремится к
нормальному, поэтому критические значения z можно найти в последней строке
таблицы распределения Стьюдента. Для α =0,05 z0,05=1,96; для α=0,01 z0,01=2,58.
С учетом этой поправки Йейтса формула для расчета z
имеет вид:
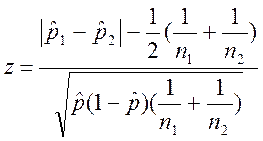 .
.
Пример. Применим z-критерий для задачи о влиянии
дополнительного приема эстрогена на риск развития болезни Альцгеймера. В группе
принимавшей эстроген (n1=156) количество заболевших составило 9 (m1=9). Во второй группе (n2=968) количество
заболевших составило 158 (m2=158).
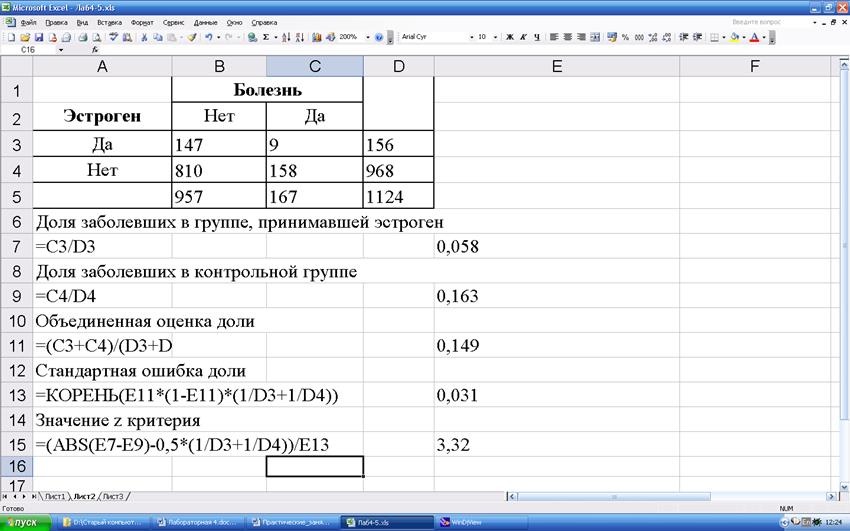
Рассчитанное значение больше, чем z0,01.
Поэтому с уровнем значимости 0,01 можем утверждать, что между долями
заболевших существуют статистически значимые различия.
Задание 1
Исследовалось
влияние экзогенных стероидных гормонов во время беременность у 108 матерей
детей с врожденными дефектами. Непреднамеренное использование оральных
контрацептивов на ранних сроках беременности рассматривалось как основной
фактор воздействия. У матерей больных детей отмечено употребление
контрацептивов в 15 случаях, в контрольной группе (также 108 матерей) – в 4
случаях. Есть ли статистически значимые различия между группами?
Похожие материалы
- Непараметрические методы (Лабораторная работа № 6)
- Дисперсионный анализ (Лабораторная работа № 3)
- Корреляционный и регрессионный анализ (Лабораторная работа № 5)
Информация о работе
Тип:
Методические указания и пособия
Уважаемый посетитель!
Чтобы распечатать файл, скачайте его (в формате Word).
Ссылка на скачивание — внизу страницы.