
Когда мы подгоняем регрессионную модель к набору данных, нас часто интересует, насколько хорошо регрессионная модель «подходит» к набору данных. Две метрики, обычно используемые для измерения согласия, включают R -квадрат (R2) и стандартную ошибку регрессии , часто обозначаемую как S.
В этом руководстве объясняется, как интерпретировать стандартную ошибку регрессии (S), а также почему она может предоставить более полезную информацию, чем R 2 .
Стандартная ошибка по сравнению с R-квадратом в регрессии
Предположим, у нас есть простой набор данных, который показывает, сколько часов 12 студентов занимались в день в течение месяца, предшествующего важному экзамену, а также их баллы за экзамен:

Если мы подгоним простую модель линейной регрессии к этому набору данных в Excel, мы получим следующий результат:

R-квадрат — это доля дисперсии переменной отклика, которая может быть объяснена предикторной переменной. При этом 65,76% дисперсии экзаменационных баллов можно объяснить количеством часов, потраченных на учебу.
Стандартная ошибка регрессии — это среднее расстояние, на которое наблюдаемые значения отклоняются от линии регрессии. В этом случае наблюдаемые значения отклоняются от линии регрессии в среднем на 4,89 единицы.
Если мы нанесем фактические точки данных вместе с линией регрессии, мы сможем увидеть это более четко:

Обратите внимание, что некоторые наблюдения попадают очень близко к линии регрессии, в то время как другие не так близки. Но в среднем наблюдаемые значения отклоняются от линии регрессии на 4,19 единицы .
Стандартная ошибка регрессии особенно полезна, поскольку ее можно использовать для оценки точности прогнозов. Примерно 95% наблюдений должны находиться в пределах +/- двух стандартных ошибок регрессии, что является быстрым приближением к 95% интервалу прогнозирования.
Если мы заинтересованы в прогнозировании с использованием модели регрессии, стандартная ошибка регрессии может быть более полезной метрикой, чем R-квадрат, потому что она дает нам представление о том, насколько точными будут наши прогнозы в единицах измерения.
Чтобы проиллюстрировать, почему стандартная ошибка регрессии может быть более полезной метрикой для оценки «соответствия» модели, рассмотрим другой пример набора данных, который показывает, сколько часов 12 студентов занимались в день в течение месяца, предшествующего важному экзамену, а также их экзаменационная оценка:

Обратите внимание, что это точно такой же набор данных, как и раньше, за исключением того, что все значения s сокращены вдвое.Таким образом, студенты из этого набора данных учились ровно в два раза дольше, чем студенты из предыдущего набора данных, и получили ровно половину экзаменационного балла.
Если мы подгоним простую модель линейной регрессии к этому набору данных в Excel, мы получим следующий результат:

Обратите внимание, что R-квадрат 65,76% точно такой же, как и в предыдущем примере.
Однако стандартная ошибка регрессии составляет 2,095 , что ровно вдвое меньше стандартной ошибки регрессии в предыдущем примере.
Если мы нанесем фактические точки данных вместе с линией регрессии, мы сможем увидеть это более четко:

Обратите внимание на то, что наблюдения располагаются гораздо плотнее вокруг линии регрессии. В среднем наблюдаемые значения отклоняются от линии регрессии на 2,095 единицы .
Таким образом, несмотря на то, что обе модели регрессии имеют R-квадрат 65,76% , мы знаем, что вторая модель будет давать более точные прогнозы, поскольку она имеет более низкую стандартную ошибку регрессии.
Преимущества использования стандартной ошибки
Стандартную ошибку регрессии (S) часто бывает полезнее знать, чем R-квадрат модели, потому что она дает нам фактические единицы измерения. Если мы заинтересованы в использовании регрессионной модели для получения прогнозов, S может очень легко сказать нам, достаточно ли точна модель для прогнозирования.
Например, предположим, что мы хотим создать 95-процентный интервал прогнозирования, в котором мы можем прогнозировать результаты экзаменов с точностью до 6 баллов от фактической оценки.
Наша первая модель имеет R-квадрат 65,76%, но это ничего не говорит нам о том, насколько точным будет наш интервал прогнозирования. К счастью, мы также знаем, что у первой модели показатель S равен 4,19. Это означает, что 95-процентный интервал прогнозирования будет иметь ширину примерно 2*4,19 = +/- 8,38 единиц, что слишком велико для нашего интервала прогнозирования.
Наша вторая модель также имеет R-квадрат 65,76%, но опять же это ничего не говорит нам о том, насколько точным будет наш интервал прогнозирования. Однако мы знаем, что вторая модель имеет S 2,095. Это означает, что 95-процентный интервал прогнозирования будет иметь ширину примерно 2*2,095= +/- 4,19 единиц, что меньше 6 и, следовательно, будет достаточно точным для использования для создания интервалов прогнозирования.
Дальнейшее чтение
Введение в простую линейную регрессию
Что такое хорошее значение R-квадрата?
На
основании уравнения (3.20) можно показать,
что b
будет несмещенной оценкой
,
если выполняется 4-е условие Гаусса —
Маркова:
![]()
(3.21)
так
как
— константа. Если мы примем сильную форму
4-го условия Гаусса — Маркова и предположим,
что х — неслучайная величина, мы можем
также считать Var(x)
известной константой и, таким образом,
![]()
(3.22)
Далее,
если х — неслучайная величина, то
M{Cov(x,u)}
= 0 и, следовательно, M{b}
=
![]()
Таким
образом,
![]()
— несмещенная оценка
Можно получить тот же результат со
слабой формой 4-го условия Гаусса —
Маркова (которая допускает, что переменная
х имеет случайную ошибку, но предполагает,
что она распределена независимо от u
).
За
исключением того случая, когда случайные
факторы в n
наблюдениях в точности «гасят»
друг друга, что может произойти лишь
при случайном совпадении, b
будет отличаться от
в каждом конкретном эксперименте. Не
будет систематической ошибки, завышающей
или занижающей оценку. То же самое
справедливо и для коэффициента а.
Используем
уравнение (2.15):
![]()
(3.23)
Следовательно,
![]()
(3.24)
Поскольку
у определяется уравнением (3.1),
![]()
(3.25)
так
как M{u}=0,
если выполнено 1-е условие Гаусса —
Маркова. Следовательно
![]()
(3.26)
Подставив
это выражение в (3.24) и воспользовавшись
тем, что
![]()
получим:
![]()
(3.27)
Таким
образом, а
— это несмещенная оценка а при условии
выполнения 1-го и 4-го условий Гаусса —
Маркова. Безусловно, для любой конкретной
выборки фактор случайности приведет к
расхождению оценки и истинного значения.
Рассмотрим
теперь теоретические дисперсии оценок
а и Ь. Они задаются следующими выражениями
(доказательства для эквивалентных
выражений можно найти в работе Дж. Томаса
[Thomas,
1983, section
833]):
![]()
(3.28)
Из
уравнения 3.28 можно сделать три очевидных
заключения. Во-первых, дисперсии а
и b
прямо пропорциональны дисперсии
остаточного члена
![]()
.
Чем
больше фактор случайности, тем хуже
будут оценки при прочих равных условиях.
Это уже было проиллюстрировано в
экспериментах по методу Монте-Карло.
Оценки в серии II
были гораздо более неточными, чем в
серии I,
и это произошло потому, что в каждой
выборке мы удвоили случайный член.
Удвоив u,
мы удвоили его стандартное отклонение
и, следовательно, удвоили стандартные
отклонения a
и b.
Во вторых, чем больше число наблюдений,
тем меньше дисперсионных оценок. Это
также имеет определенный смысл. Чем
большей информацией вы располагаете,
тем более точными, вероятно, будут ваши
оценки. В третьих, чем больше дисперсия
![]()
,
тем меньше будет дисперсия коэффициентов
регрессии. В чем причина этого? Напомним,
что (I)
коэффициенты регрессии вычисляются на
основании предположения, что наблюдаемые
изменения
![]()
происходят вследствие изменений
,
но (2) в действительности они лишь отчасти
вызваны изменениями
,
а отчасти вариациями u.
Чем меньше дисперсия
,
тем больше, вероятно, будет относительное
влияние фактора случайности при
определении отклонений
и тем более вероятно, что регрессионный
анализ может оказаться неверным. В
действительности, как видно из уравнения
(3.28), важное значение имеет не абсолютная,
а относительная величина
![]()
и Var(x).
На
практике мы не можем вычислить
теоретические дисперсии
![]()
или
![]()
,
так как
неизвестно, однако мы можем получить
оценку
на основе остатков. Очевидно, что разброс
остатков относительно линии регрессии
будет отражать неизвестный разброс u
относительно линии
![]()
,
хотя в общем остаток и случайный член
в любом данном наблюдении не равны друг
другу. Следовательно, выборочная
дисперсия остатков Var(е),
которую мы можем измерить, сможет быть
использована для оценки
,
которую мы получить не можем.
Прежде
чем пойти дальше, задайте себе следующий
вопрос: какая прямая будет ближе к
точкам, представляющим собой выборку
наблюдений по
и
,
истинная прямая
или линия регрессии
![]()
?
Ответ будет таков: линия регрессии,
потому что по определению она строится
таким образом, чтобы свести к минимуму
сумму квадратов расстояний между ней
и значениями наблюдений. Следовательно,
разброс остатков у нее меньше, чем
разброс значений u,
и Var(e)
имеет тенденцию занижать оценку
.
Действительно, можно показать, что
математическое ожидание Var(e),
если имеется всего одна независимая
переменная, равно
![]()
.
Однако отсюда следует, что если определить
![]()
как
![]()
,
(3.29)
То
будет представлять собой несмещенную
оценку
.
Таким
образом, несмещенной оценкой параметра
регрессии
![]()
является оценка
![]()
.
(3.30)
Теперь
вспомним следующие определения:
стандартное
отклонение случайной величины
– корень квадратный из теоретической
дисперсии случайной величины; среднее
ожидаемое расстояние между наблюдениями
этой случайной величины и ее математическим
ожиданием,
стандартная
ошибка случайной величины
– оценка стандартного отклонения
случайной величины, полученная по данным
выборки.
Используя
уравнения (3.28) и (3.29), можно получить
оценки теоретических дисперсий для a
и b
и после извлечения квадратного корня
– оценки их стандартных отклонений.
Вместо слишком громоздкого термина
«оценка стандартного отклонения функции
плотности вероятости» коэффицинта
регрессии будем использовать термин
«стандартная ошибка» коэффициента
регрессии, которую в дальнейшем мы будем
обозначать в виде сокрашения «с.о.».
Таким образом, для парного регрессионного
анализа мы имеем:
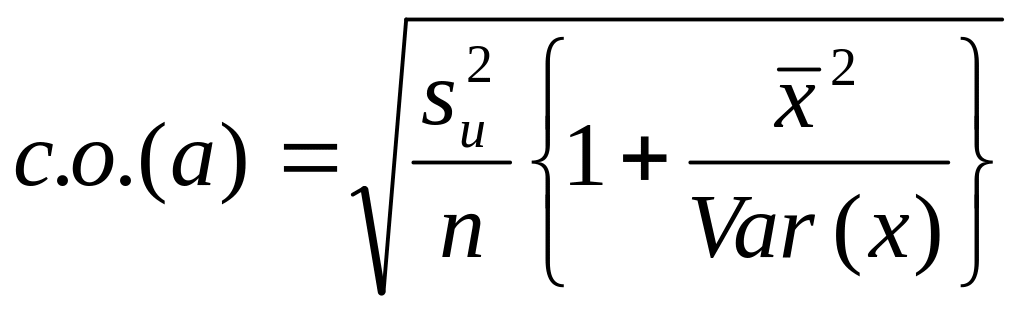
и
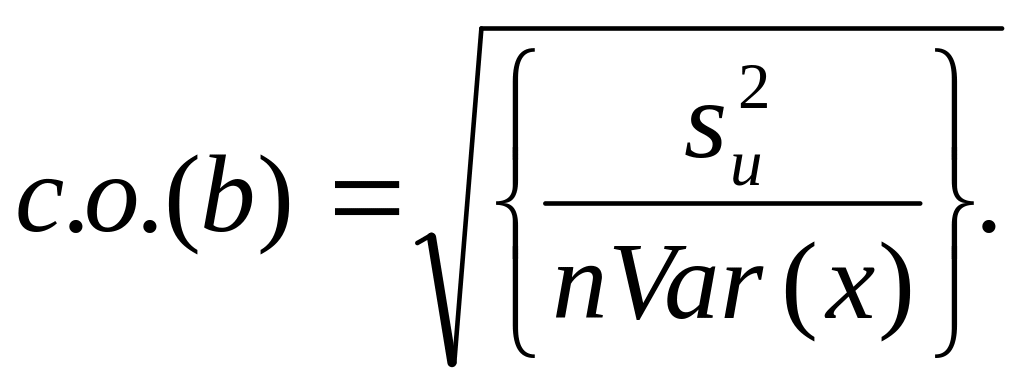
(3.31)
Если
воспользоваться компьютерной программой
оценивания регрессии, то стандартные
ошибки будут подсчитаны автоматически
одновременно с оценками a
и b.
Подводя
итог сказанному о точности коэффициентов
регрессии, акценктируем внимание на
следующих выводах.
1.
Оценка a
для параметра
имеет нормальное распределение с
математическим ожиданием a
и стандартным отклонением

,
оценка b
для параметра
имеет
нормальное распределение с математическим
ожиданием b
и стандартным отклонением
![]()
.
2.
Для улучшения точности оценок по МНК
можно увеличивать количество наблюдений
в выборке n,
увеличивать диапазон наблюдений Var(x)
или уменьшать
,
(например, увеличивать точность
измерений).
3.
Стандартная ошибка оценки a
считается по формуле
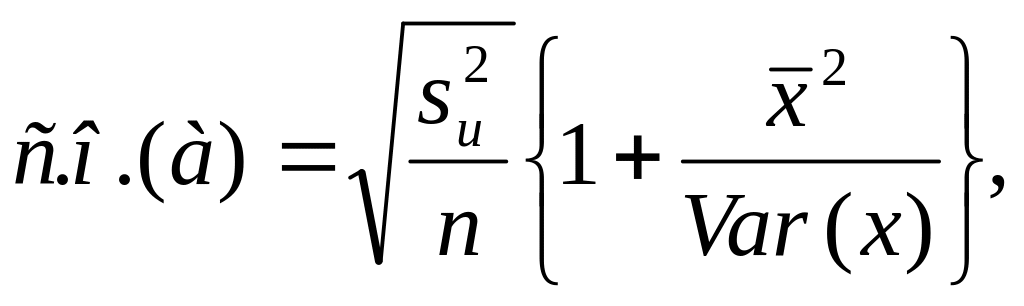
а
стандартная ошибка оценки b
считается по формуле
![]()
.
В компьютерных программах именно эти
числа приводятся в круглых скобках под
значениями оценок.
Полученные
соотношения проиллюстрируем экспериментами
по методу Монте-Карло, описанными ранее.
В серии I
u
определялось на основе случайных чисел,
взятых из генеральной совокупности с
нулевым средним и единичной дисперсией
![]()
а x
представлял собой набор чисел от 1 до
20. Можно легко вычислить Var(x),
которая равна 33,25.
Следовательно,
![]()
(3.32)
![]()
.
(3.33)
Таким
образом, истинное стандартное отклонение
для b
равно
![]()
.
Какие же результаты получены вместо
этого компьютером в 10 экспериментах
серии I?
Он должен был вычислить стандартную
ошибку, используя уравнение (3.31).
Результаты этих расчетов для 10
экспериментов представлены в табл. 3.5.
Таблица 3.5
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
22.03.2016179.71 Кб71а1.doc
- #
- #
- #
- #
- #
- #
- #
Когда мы подгоняем регрессионную модель к набору данных, нас часто интересует, насколько хорошо регрессионная модель «подходит» к набору данных. Две метрики, обычно используемые для измерения согласия, включают R -квадрат (R2) и стандартную ошибку регрессии , часто обозначаемую как S.
В этом руководстве объясняется, как интерпретировать стандартную ошибку регрессии (S), а также почему она может предоставить более полезную информацию, чем R 2 .
Стандартная ошибка по сравнению с R-квадратом в регрессии
Предположим, у нас есть простой набор данных, который показывает, сколько часов 12 студентов занимались в день в течение месяца, предшествующего важному экзамену, а также их баллы за экзамен:
Если мы подгоним простую модель линейной регрессии к этому набору данных в Excel, мы получим следующий результат:
R-квадрат — это доля дисперсии переменной отклика, которая может быть объяснена предикторной переменной. При этом 65,76% дисперсии экзаменационных баллов можно объяснить количеством часов, потраченных на учебу.
Стандартная ошибка регрессии — это среднее расстояние, на которое наблюдаемые значения отклоняются от линии регрессии. В этом случае наблюдаемые значения отклоняются от линии регрессии в среднем на 4,89 единицы.
Если мы нанесем фактические точки данных вместе с линией регрессии, мы сможем увидеть это более четко:
Обратите внимание, что некоторые наблюдения попадают очень близко к линии регрессии, в то время как другие не так близки. Но в среднем наблюдаемые значения отклоняются от линии регрессии на 4,19 единицы .
Стандартная ошибка регрессии особенно полезна, поскольку ее можно использовать для оценки точности прогнозов. Примерно 95% наблюдений должны находиться в пределах +/- двух стандартных ошибок регрессии, что является быстрым приближением к 95% интервалу прогнозирования.
Если мы заинтересованы в прогнозировании с использованием модели регрессии, стандартная ошибка регрессии может быть более полезной метрикой, чем R-квадрат, потому что она дает нам представление о том, насколько точными будут наши прогнозы в единицах измерения.
Чтобы проиллюстрировать, почему стандартная ошибка регрессии может быть более полезной метрикой для оценки «соответствия» модели, рассмотрим другой пример набора данных, который показывает, сколько часов 12 студентов занимались в день в течение месяца, предшествующего важному экзамену, а также их экзаменационная оценка:
Обратите внимание, что это точно такой же набор данных, как и раньше, за исключением того, что все значения s сокращены вдвое.Таким образом, студенты из этого набора данных учились ровно в два раза дольше, чем студенты из предыдущего набора данных, и получили ровно половину экзаменационного балла.
Если мы подгоним простую модель линейной регрессии к этому набору данных в Excel, мы получим следующий результат:
Обратите внимание, что R-квадрат 65,76% точно такой же, как и в предыдущем примере.
Однако стандартная ошибка регрессии составляет 2,095 , что ровно вдвое меньше стандартной ошибки регрессии в предыдущем примере.
Если мы нанесем фактические точки данных вместе с линией регрессии, мы сможем увидеть это более четко:
Обратите внимание на то, что наблюдения располагаются гораздо плотнее вокруг линии регрессии. В среднем наблюдаемые значения отклоняются от линии регрессии на 2,095 единицы .
Таким образом, несмотря на то, что обе модели регрессии имеют R-квадрат 65,76% , мы знаем, что вторая модель будет давать более точные прогнозы, поскольку она имеет более низкую стандартную ошибку регрессии.
Преимущества использования стандартной ошибки
Стандартную ошибку регрессии (S) часто бывает полезнее знать, чем R-квадрат модели, потому что она дает нам фактические единицы измерения. Если мы заинтересованы в использовании регрессионной модели для получения прогнозов, S может очень легко сказать нам, достаточно ли точна модель для прогнозирования.
Например, предположим, что мы хотим создать 95-процентный интервал прогнозирования, в котором мы можем прогнозировать результаты экзаменов с точностью до 6 баллов от фактической оценки.
Наша первая модель имеет R-квадрат 65,76%, но это ничего не говорит нам о том, насколько точным будет наш интервал прогнозирования. К счастью, мы также знаем, что у первой модели показатель S равен 4,19. Это означает, что 95-процентный интервал прогнозирования будет иметь ширину примерно 2*4,19 = +/- 8,38 единиц, что слишком велико для нашего интервала прогнозирования.
Наша вторая модель также имеет R-квадрат 65,76%, но опять же это ничего не говорит нам о том, насколько точным будет наш интервал прогнозирования. Однако мы знаем, что вторая модель имеет S 2,095. Это означает, что 95-процентный интервал прогнозирования будет иметь ширину примерно 2*2,095= +/- 4,19 единиц, что меньше 6 и, следовательно, будет достаточно точным для использования для создания интервалов прогнозирования.
Дальнейшее чтение
Введение в простую линейную регрессию
Что такое хорошее значение R-квадрата?
Стандартная ошибка уравнения регрессии, Эта статистика SEE представляет собой стандартное отклонение фактических значений теоретических значений У. [c.650]
Что такое стандартная ошибка уравнения регрессии ).Какие допущения лежат в основе парной регрессии 10. Что такое множественная регрессия [c.679]
Следующий этап корреляционного анализа — расчет уравнения связи (регрессии). Решение проводится обычно шаговым способом. Сначала в расчет принимается один фактор, который оказывает наиболее значимое влияние на результативный показатель, потом второй, третий и т.д. И на каждом шаге рассчитываются уравнение связи, множественный коэффициент корреляции и детерминации, /»»-отношение (критерий Фишера), стандартная ошибка и другие показатели, с помощью которых оценивается надежность уравнения связи. Величина их на каждом шаге сравнивается с предыдущей. Чем выше величина коэффициентов множественной корреляции, детерминации и критерия Фишера и чем ниже величина стандартной ошибки, тем точнее уравнение связи описывает зависимости, сложившиеся между исследуемыми показателями. Если добавление следующих факторов не улучшает оценочных показателей связи, то надо их отбросить, т.е. остановиться на том уравнении, где эти показатели наиболее оптимальны.
[c.149]
Прогнозное значение ур определяется путем подстановки в уравнение регрессии ух =а + Ьх соответствующего (прогнозного) значения хр. Вычисляется средняя стандартная ошибка прогноза
[c.9]
В линейной регрессии обычно оценивается значимость не только уравнения в целом, но и отдельных его параметров. С этой целью по каждому из параметров определяется его стандартная ошибка ть и та.
[c.53]
В прогнозных расчетах по уравнению регрессии определяется предсказываемое (ур) значение как точечный прогноз ух при хр =хь т. е. путем подстановки в уравнение регрессии 5 = а + b х соответствующего значения х. Однако точечный прогноз явно не реален. Поэтому он дополняется расчетом стандартной ошибки ух, т. е. Шух, и соответственно интервальной оценкой прогнозного значения (у )
[c.57]
Чтобы понять, как строится формула для определения величин стандартной ошибки ух, обратимся к уравнению линейной регрессии ух = а + b х. Подставим в это уравнение выражение параметра а [c.57]
При прогнозировании на основе уравнения регрессии следует помнить, что величина прогноза зависит не только от стандартной ошибки индивидуального значения у, но и от точности прогноза значения фактора х. Его величина может задаваться на основе анализа других моделей исходя из конкретной ситуации, а также из анализа динамики данного фактора.
[c.61]
В скобках указаны стандартные ошибки параметров уравнения регрессии.
[c.327]
В скобках указаны стандартные ошибки параметров уравнения регрессии. Определим по этому уравнению расчетные значения >>, ,, а затем параметры уравнения регрессии (7.44). Получим следующие результаты [c.328]
Стандартные ошибки коэффициентов уравнения регрессии, t — критерий
[c.7]
На каждом шаге рассматриваются уравнение регрессии, коэффициенты корреляции и детерминации, F-критерий, стандартная ошибка оценки и другие оценочные показатели. После каждого шага перечисленные оценочные показатели сравниваются с
[c.39]
Проблемы с методологией регрессии. Методология регрессии — это традиционный способ уплотнения больших массивов данных и их сведения в одно уравнение, отражающее связь между мультипликаторами РЕ и финансовыми фундаментальными переменными. Но данный подход имеет свои ограничения. Во-первых, независимые переменные коррелируют друг с другом . Например, как видно из таблицы 18,2, обобщающей корреляцию между коэффициентами бета, ростом и коэффициентами выплат для всех американских фирм, быстрорастущие фирмы обычно имеют большой риск и низкие коэффициенты выплат. Обратите внимание на отрицательную корреляцию между коэффициентами выплат и ростом, а также на положительную корреляцию между коэффициентами бета и ростом. Эта мультиколлинеарность делает мультипликаторы регрессии ненадежными (увеличивает стандартную ошибку) и, возможно, объясняет ошибочные знаки при коэффициентах и крупные изменения этих мультипликаторов в разные периоды. Во-вторых, регрессия основывается на линейной связи между мультипликаторами РЕ и фундаментальными переменными, и данное свойство, по всей вероятности, неадекватно. Анализ остаточных явлений, связанных с корреляцией, может привести к трансформациям независимых переменных (их квадратов или натуральных логарифмов), которые в большей степени подходят для объяснения мультипликаторов РЕ. В-третьих, базовая связь между мультипликаторами РЕ и финансовыми переменными сама по себе не является стабильной. Если же эта связь смещается из года в год, то прогнозы, полученные из регрессионного уравнения, могут оказаться ненадежными для более длительных периодов времени. По всем этим причинам, несмотря на полезность регрессионного анализа, его следует рассматривать только как еще один инструмент поиска подлинного значения ценности.
[c.649]
На рисунке 16.6 явно просматривается четкая линейная зависимость объема частного потребления от величины располагаемого дохода. Уравнение парной линейной регрессии, оцененное по этим данным, имеет вид С= -217,6 + 1,007 Yf Стандартные ошибки для свободного члена и коэффициента парной регрессии равны, соответственно, 28,4 и 0,012, а -статистики — -7,7 и 81 9. Обе они по модулю существенно превышают 3, следовательно, их статистическая значимость весьма высока. Впрочем, несмотря на то, что здесь удалось оценить статистически значимую линейную функцию потребления, в ней нарушены сразу две предпосылки Кейнса — уровень автономного потребления С0 оказался отрицательным, а предель-
[c.304]
Стандартные ошибки свободного члена и коэффициента регрессии равны, соответственно, 84,7 и 0,46 их /-статистики — (-21,4 и 36,8). По абсолютной величине /-статистики намного превышают 3, и это свидетельствует о высокой надежности оцененных коэффициентов. Коэффициент детерминации /Р уравнения равен 0,96, то есть объяснено 96% дисперсии объема потребления. И в то же время уже по рисунку видно, что оцененная рефессия не очень хоро-
[c.320]
Эта стандартная ошибка S у, равная 0,65, указывает отклонение фактических данных от прогнозируемых на основании использования воздействующих факторов j i и Х2 (влияние среди покупателей бабушек с внучками и высокопрофессионального вклада Шарика). В то же время мы располагаем обычным стандартным отклонением Sn, равным 1,06 (см. табл.8), которое было рассчитано для одной переменной, а именно сами текущие значения уги величина среднего арифметического у, которое равно 6,01. Легко видеть, что S у< Sn следовательно, ошибки прогнозирования, как правило, оказываются меньшими, если использовать уравнение регрессии (учитывается вклад факторов j i и Х2), а не ограничиваться только значением у.
[c.64]
Эти два выражения показывают, как возникает ковариация между [52 и Рз в СИЛУ присутствия 2ыу в каждом из выражений для ошибок Р2 и (33. Положительное и большое значение ос приводит, как мы видим, к большим противоположным значениям ошибок J32 и(33- Если (32 оценивает значение р 2 снизу, то р3 оценивает значение ps сверху, и наоборот. Очень важным является то обстоятельство, что стандартные ошибки могут служить одним из индикаторов наличия мульти-коллинеарности. Формула (5.84) показывает, что истинное значение стандартной ошибки возрастает с увеличением а, однако эта формула содержит неизвестный параметр а . В оцененной величине стандартной ошибки значение а заменяется на Ее2/(п — /г), где 2е2 — сумма квадратов остатков после подгонки уравнения регрессии к эмпирическим данным. Как было показано в (5.19),
[c.162]
С помощью парной регрессии устанавливается математическая зависимость (в виде уравнения) между метрической зависимой (критериальной) переменной и метрической независимой переменной (предиктором). Уравнение описывает прямую линиию, и для его вывода используют метод наименьших В случае построения регрессии с нормированными данными отрезок, отсекаемый на оси OY, принимает значение, равное 0, и коэффициенты регрессии называют взвешенными Силу тесноты связи измеряют ко-детерминации который получают, вычисляя отношение к Стандартную ошибку уравнения регрессии используют для оценки точности предсказания, и ее можно интерпретировать как род средней ошибки, сделанной при теоретическом предсказании Y, исходя из уравнения регрессии.
[c.678]
В скобках указаны стандартные ошибки коэффициентов регрессии. «Коэффициенты детерминации рассчитаны по линеаризованным уравнениям регрессии. [c.237]
Это уравнение намного лучше, чем (5). Все коэффициенты статистически значимы, их коэффициенты по абсолютной величине в 7-10 раз превышают свои стандартные ошибки. Уравнение соответствует макроэкономической теории, говорящей об отрицательной зависимости величины реального чистого экспорта от реального ВНП и валютного курса. Взглянув на рис. 18.7, можно отметить, что рассчитанные по уравнению регрессии величины ВНП за 1965-1990 гг. очень близки к фактическим. Единственной проблемой является то, что статистика Дарбина-Уотсона существенно меньше двух, -таким образом, можно попытаться улучшить это уравнение. При этом мы надеемся избавиться от автокорреляции остатков (то есть, получить более близкую к двум DW) и, возможно, увеличить долю объясненной дисперсии RNX, то есть R2.
[c.346]
В скобках указаны стандартные ошибки параметров уравнения регрессии. Применение метода инструментальных переменных привело к статистической незначимости параметра С[ = 0,109 при переменной yf . Это произошло ввиду высокой мультиколлинеарности факторов, иyt v. Несмотря на то что результаты, полученные обычным МНК, на первый взгляд лучше, чем результаты применения метода инструментальных переменных, результатам обычного МНК вряд ли можно доверять вследствие нарушения в данной модели его предпосылок. Поскольку ни один из методов не привел к получению достоверных результатов расчетов параметров, следует перейти к получению оценок параметров данной модели авторегрессии методом максимального правдоподобия.
[c.328]
Нетрудно заметить, что в данном случае не выполняются необходимые предпосылки МНК об отклонениях Si точек наблюдений от линии регрессии (см. параграф 6.1). Эти отклонения явно не обладают постоянной дисперсией и не являются взаимно независимыми. Нарушение необходимых предпосылок делает неточными полученные оценки коэффициентов регрессии, увеличивая их стандартные ошибки, и обычно свидетельствует о неверной спецификации самого уравнения. Поэтому следующим этапом проверки качества уравнения регрессии является проверка выполнимости предпосылок МНК. Причины невыполнимости этих предпосылок, их последствия и методы корректировки будут подробно рассмотрены в последующих главах. В данном разделе мы лишь обозначим эти проблемы, а также обсудим весьма популярную в регрессионном анализе статистику Дарбина— Уотсона.
[c.164]
В скобках указаны стандартные ошибки соответствующих коэффициентов. Можно отметить, что статистическое качество полученного уравнения регрессии практически идеально. Все г-статистики превышают 5 по абсолютной величине (а, грубо говоря, границей для очень хорошей оценки является 3). Очень высока доля дисперсии зависимой переменной, объясненная с помощью уравнения регрессии, — 94,2% — особенно с учетом того, что уравнение регрессии связывает относительные величины, не имеющие выраженного временного тренда. Статистика Дарбина-Уотсона ЯИ очень близка к 2, и, даже не прибегая к таблицам, здесь ясно, что гипотеза об отсутствии автокорреляции остатков первого порядка будет принята при любом разумно малом уровне значимости. Итак, мы имеем хороший пример линейной регрессии, когда можно оценить ее статистическую значимость, не прибегая к таблицам распределений Стьюден-та, Фишера или Дарбина-Уотсона, а лишь по общему порядку полученных статистик.
[c.330]
Это уравнение приемлемо по всем параметрам и статистическим характеристикам. Единственное, что имеет смысл сделать в нем, это замена переменных ER и ER на одну переменную ER(-l). Это можно сделать, поскольку абсолютные величины коэффициентов при ER и ER почти одинаковы. В таком случае можно сделать преобразование (-a-ER+aAER) = (-aER + a(ER — ER(-l))=-aER(-l), и мы можем использовать это равенство для сокращения числа объясняющих переменных.1 Включив снова преобразование AR(l) (для которого коэффициент авторегрессии соседних отклонений et получился равен р=0,71, со стандартной ошибкой 0,16), получаем уравнение регрессии [c.363]
Подобным же образом на основе соответствующих формул рассчитывают стандартные ошибки параметров уравнения регрессии, а затем и t-критерии для каждого параметра. Важно опять-таки проверить, чтобы соблюдалось условие tpa 4 > tTa6n. В противном случае доверять полученной оценке параметра нет оснований.
[c.139]
Для определения профиля посетителей магазинов местного торгового центра, не имеющих определенной цели (browsers), маркетологи использовали три набора независимых переменных демографические, покупательское поведение психологические. Зависимая переменная представляет собой индекс посещения магазина без определенной цели, индекс (browsing index). Методом ступенчатой включающей все три набора переменных, выявлено, что демографические факторы — наиболее сильные предикторы, определяющие поведение покупателей, не преследующих конкретных целей. Окончательное уравнение регрессии, 20 из 36 возможных переменных, включало все демографические переменные. В следующей таблице приведены коэффициенты регрессии, стандартные ошибки коэффициентов, а также их уровни значимости.
[c.668]
Так как гетероскедастичность не приводит к смещению оценок коэффициентов, можно по-прежнему использовать МНК. Смещены и несостоятельны оказываются не сами оценки коэффициентов, а их стандартные ошибки, поэтому формула для расчета стандартных ошибок в условиях гомоскедастичности не подходит для случая гетероскедастичности.
Естественной идеей в этой ситуации является корректировка формулы расчета стандартных ошибок, чтобы она давала «правильный» (состоятельный) результат. Тогда можно снова будет корректно проводить тесты, проверяющие, например, незначимость коэффициентов, и строить доверительные интервалы. Соответствующие «правильные» стандартные ошибки называются состоятельными в условиях гетероскедастичности стандартными ошибками (heteroskedasticity consistent (heteroskedasticity robust) standard errors)1. Первоначальная формула для их расчета была предложена Уайтом, поэтому иногда их также называют стандартными ошибками в форме Уайта (White standard errors). Предложенная Уайтом состоятельная оценка ковариационной матрицы вектора оценок коэффициентов имеет вид:
(widehat{V}{left( widehat{beta} right) = n}left( {X^{‘}X} right)^{- 1}left( {frac{1}{n}{sumlimits_{s = 1}^{n}e_{s}^{2}}x_{s}x_{s}^{‘}} right)left( {X^{‘}X} right)^{- 1},)
где (x_{s}) – это s-я строка матрицы регрессоров X. Легко видеть, что эта формула более громоздка, чем формула (widehat{V}{left( widehat{beta} right) = left( {X^{‘}X} right)^{- 1}}S^{2}), которую мы вывели в третьей главе для случая гомоскедастичности. К счастью, на практике соответствующие вычисления не представляют сложности, так как возможность автоматически рассчитывать стандартные ошибки в форме Уайта реализована во всех современных эконометрических пакетах. Общепринятое обозначение для этой версии стандартных ошибок: «HC0». В работах (MacKinnon, White,1985) и (Davidson, MacKinnon, 2004) были предложены и альтернативные версии, которые обычно обозначаются в эконометрических пакетах «HC1», «HC2» и «HC3». Их расчетные формулы несколько отличаются, однако суть остается прежней: они позволяют состоятельно оценивать стандартные отклонения МНК-оценок коэффициентов в условиях гетероскедастичности.
Для случая парной регрессии состоятельная в условиях гетероскедастичности стандартная ошибка оценки коэффициента при регрессоре имеет вид:
(mathit{se}{left( widehat{beta_{2}} right) = sqrt{frac{1}{n}frac{frac{1}{n — 2}{sumlimits_{i = 1}^{n}{left( {x_{i} — overline{x}} right)^{2}e_{i}^{2}}}}{widehat{mathit{var}}(x)^{2}}.}})
Формальное доказательство состоятельности будет приведено в следующей главе. Пока же обсудим пример, иллюстрирующий важность использования робастных стандартных ошибок.
Пример 5.1. Оценка эффективности использования удобрений
В файле Agriculture в материалах к этому учебнику содержатся следующие данные 2010 года об урожайности яровой и озимой пшеницы в Спасском районе Пензенской области:
PRODP — урожайность в денежном выражении, в тысячах рублей с 1 га,
SIZE – размер пахотного поля, га,
LABOUR – трудозатраты, руб. на 1 га,
FUNG1 – фунгициды, протравители семян, расходы на удобрение в руб. на 1 га,
FUNG2 – фунгициды, во время роста, расходы на удобрение в руб. на 1 га,
GIRB – гербициды, расходы на удобрение в руб. на 1 га,
INSEC – инсектициды, расходы на удобрение в руб. на 1 га,
YDOB1 – аммофос, во время сева, расходы на удобрение в руб. на 1 га,
YDOB2 – аммиачная селитра, во время роста, расходы на удобрение в руб. на 1 га.
Представим, что вас интересует ответ на вопрос: влияет ли использование фунгицидов на урожайность поля?
(а) Оцените зависимость урожайности в денежном выражении от константы и переменных FUNG1, FUNG2, YDOB1, YDOB2, GIRB, INSEC, LABOUR. Запишите уравнение регрессии в стандартной форме, указав коэффициент детерминации и (в скобках под соответствующими коэффициентами) стандартные ошибки для случая гомоскедастичности. Какие из переменных значимы на 5-процентном уровне значимости?
(б) Решите предыдущий пункт заново, используя теперь состоятельные в условиях гетероскедастичности стандартные ошибки. Сопоставьте выводы по поводу значимости (при пятипроцентном уровне) переменных, характеризующих использование фунгицидов.
Решение:
(а) Оценим требуемое уравнение:
Модель 1: МНК, использованы наблюдения 1-200
Зависимая переменная: PRODP
| Коэффициент | Ст. ошибка | t-статистика | P-значение | ||
| const | -38,4019 | 7,5273 | -5,1017 | <0,00001 | *** |
| FUNG1 | 0,0445755 | 0,0487615 | 0,9142 | 0,36178 | |
| FUNG2 | 0,103625 | 0,049254 | 2,1039 | 0,03669 | ** |
| GIRB | 0,0776059 | 0,0523553 | 1,4823 | 0,13990 | |
| INSEC | 0,0782521 | 0,0484667 | 1,6146 | 0,10805 | |
| LABOUR | 0,0415064 | 0,00275277 | 15,0781 | <0,00001 | *** |
| YDOB1 | 0,0492168 | 0,0233328 | 2,1093 | 0,03621 | ** |
| YDOB2 | -0,0906824 | 0,025864 | -3,5061 | 0,00057 | *** |
| Сумма кв. остатков | 150575,6 | Ст. ошибка модели | 28,00443 | |
| R-квадрат | 0,801958 | Испр. R-квадрат | 0,794738 | |
| F(7, 192) | 111,0701 | Р-значение (F) | 5,08e-64 |
Переменные FUNG2, LABOUR, YDOB1 и YDOB2 значимы на пятипроцентном уровне значимости (причем LABOUR и YDOB2 — ещё и на однопроцентном).
Если представить те же самые результаты в форме уравнения, то получится вот так:
({widehat{mathit{PRODP}}}_{i} = {{- underset{(7,53)}{38,40}} + {underset{(0,05)}{0,04} ast {mathit{FUNG}1}_{i}} + {underset{(0,05)}{0,10} ast {mathit{FUNG}2}_{i}} +})
({{+ underset{(0,05)}{0,08}} ast mathit{GIRB}_{i}} + {underset{(0,05)}{0,08} ast mathit{INSEC}_{i}} + {underset{(0,003)}{0,04} ast mathit{LABOUR}_{i}} + {})
({{{+ underset{(0,02)}{0,05}} ast {mathit{YDOB}1}_{i}} — {underset{(0,03)}{0,09} ast {mathit{YDOB}2}_{i}}},{R^{2} = 0,802})
(б) При использовании альтернативных стандартных ошибок получим следующий результат:
Модель 2: МНК, использованы наблюдения 1-200
Зависимая переменная: PRODP
Робастные оценки стандартных ошибок (с поправкой на гетероскедастичность),
вариант HC1
| Коэффициент | Ст. ошибка | t-статистика | P-значение | ||
| const | -38,4019 | 7,40425 | -5,1865 | <0,00001 | *** |
| FUNG1 | 0,0445755 | 0,0629524 | 0,7081 | 0,47975 | |
| FUNG2 | 0,103625 | 0,0624082 | 1,6604 | 0,09846 | * |
| GIRB | 0,0776059 | 0,0623777 | 1,2441 | 0,21497 | |
| INSEC | 0,0782521 | 0,0536527 | 1,4585 | 0,14634 | |
| LABOUR | 0,0415064 | 0,00300121 | 13,8299 | <0,00001 | *** |
| YDOB1 | 0,0492168 | 0,0197491 | 2,4921 | 0,01355 | ** |
| YDOB2 | -0,0906824 | 0,030999 | -2,9253 | 0,00386 | *** |
| Сумма кв. остатков | 150575,6 | Ст. ошибка модели | 28,00443 | |
| R-квадрат | 0,801958 | Испр. R-квадрат | 0,794738 | |
| F(7, 192) | 119,2263 | Р-значение (F) | 2,16e-66 |
Оценки коэффициентов по сравнению с пунктом (а) не поменялись, что естественно: мы ведь по-прежнему используем обычный МНК. Однако стандартные ошибки теперь немного другие. В некоторых случаях это меняет выводы тестов на незначимость.
Переменные LABOUR, YDOB1 и YDOB2 значимы на пятипроцентном уровне значимости (причем LABOUR и YDOB2 — ещё и на однопроцентном).
Переменная FUNG2 перестала быть значимой на пятипроцентном уровне. Таким образом, при использовании корректных стандартных ошибок следует сделать вывод о том, что соответствующий вид удобрений не важен для урожайности. Обратите внимание, что если бы мы использовали «обычные» стандартные ошибки, то мы пришли бы к противоположному заключению (см. пункт (а)).
* * *
Важно подчеркнуть, что в реальных пространственных данных гетероскедастичность в той или иной степени наблюдается практически всегда. А даже если её и нет, то состоятельные в условиях гетероскедастичности стандартные ошибки по-прежнему будут… состоятельными (и будут близки к «обычным» стандартным ошибкам, посчитанным по формулам из третьей главы). Поэтому в современных прикладных исследованиях при оценке уравнений по умолчанию используются именно робастные стандартные ошибки, а не стандартные ошибки для случая гомоскедастичности. Мы настоятельно рекомендуем читателю поступать так же2. В нашем учебнике с этого момента и во всех последующих главах, если прямо не оговорено иное, для МНК-оценок параметров всегда используются состоятельные в условиях гетероскедастичности стандартные ошибки.
-
Поскольку довольно утомительно каждый раз произносить это название полностью в англоязычном варианте их часто называют просто robust standard errors, что на русском языке эконометристов превратилось в «робастные стандартные ошибки». Кому-то подобный англицизм, конечно, режет слух, однако в устной речи он и правда куда удобней своей длинной альтернативы.↩︎
-
Просто не забывайте включать соответствующую опцию в своем эконометрическом пакете.↩︎
Имея
прямую регрессии, необходимо оценить
насколько сильно точки исходных данных
отклоняются от прямой регрессии. Можно
выполнить оценку разброса, аналогичную
стандартному отклонению выборки. Этот
показатель, называемый стандартной
ошибкой оценки, демонстрирует величину
отклонения точек исходных данных от
прямой регрессии в направлении оси Y.
Стандартная ошибка оценки (![]() )
)
вычисляется по следующей формуле.
![]()
Стандартная
ошибка оценки измеряет степень отличия
реальных значений Y от оцененной величины.
Для сравнительно больших выборок следует
ожидать, что около 67% разностей по модулю
не будет превышать
![]()
и около 95% модулей разностей будет не
больше 2![]() .
.
Стандартная
ошибка оценки подобна стандартному
отклонению. Ее можно использовать для
оценки стандартного отклонения
совокупности. Фактически
![]()
оценивает стандартное отклонение
![]()
слагаемого ошибки
![]()
в статистической модели простой линейной
регрессии. Другими словами,
![]()
оценивает общее стандартное отклонение
![]()
нормального распределения значений Y,
имеющих математические ожидания
![]()
для каждого X.
Малая
стандартная ошибка оценки, полученная
при регрессионном анализе, свидетельствует,
что все точки данных находятся очень
близко к прямой регрессии. Если стандартная
ошибка оценки велика, точки данных могут
значительно удаляться от прямой.
2.3 Прогнозирование величины y
Регрессионную
прямую можно использовать для оценки
величины переменной Y
при данных значениях переменной X. Чтобы
получить точечный прогноз, или предсказание
для данного значения X, просто вычисляется
значение найденной функции регрессии
в точке X.
Конечно
реальные значения величины Y,
соответствующие рассматриваемым
значениям величины X, к сожалению, не
лежат в точности на регрессионной
прямой. Фактически они разбросаны
относительно прямой в соответствии с
величиной
![]() .
.
Более того, выборочная регрессионная
прямая является оценкой регрессионной
прямой генеральной совокупности,
основанной на выборке из определенных
пар данных. Другая случайная выборка
даст иную выборочную прямую регрессии;
это аналогично ситуации, когда различные
выборки из одной и той же генеральной
совокупности дают различные значения
выборочного среднего.
Есть
два источника неопределенности в
точечном прогнозе, использующем уравнение
регрессии.
-
Неопределенность,
обусловленная отклонением точек данных
от выборочной прямой регрессии. -
Неопределенность,
обусловленная отклонением выборочной
прямой регрессии от регрессионной
прямой генеральной совокупности.
Интервальный
прогноз значений переменной Y
можно построить так, что при этом будут
учтены оба источника неопределенности.
Стандартная
ошибка прогноза
![]()
дает меру вариативности предсказанного
значения Y
около истинной величины Y
для данного значения X.
Стандартная ошибка прогноза равна:

Стандартная
ошибка прогноза зависит от значения X,
для которого прогнозируется величина
Y.
![]()
минимально, когда
![]() ,
,
поскольку тогда числитель в третьем
слагаемом под корнем в уравнении будет
0. При прочих неизменных величинах
большему отличию соответствует большее
значение стандартной ошибки прогноза.
Если
статистическая модель простой линейной
регрессии соответствует действительности,
границы интервала прогноза величины Y
равны:
![]()
где
![]()
— квантиль распределения Стьюдента с
n-2 степенями свободы (![]() ).
).
Если выборка велика (![]() ),
),
этот квантиль можно заменить соответствующим
квантилем нормального распределения.
Например, для большой выборки 95%-ный
интервал прогноза задается следующими
значениями:
![]()
Завершим
раздел обзором предположений, положенных
в основу статистической модели линейной
регрессии.
-
Для
заданного значения X генеральная
совокупность значений Y имеет нормальное
распределение относительно регрессионной
прямой совокупности. На практике
приемлемые результаты получаются
и
тогда, когда значения Y имеют
нормальное распределение лишь
приблизительно. -
Разброс
генеральной совокупности точек данных
относительно регрессионной прямой
совокупности остается постоянным всюду
вдоль этой прямой. Иными словами, при
возрастании значений X в точках данных
дисперсия генеральной совокупности
не увеличивается и не уменьшается.
Нарушение этого предположения называется
гетероскедастичностью. -
Слагаемые
ошибок

независимы между собой. Это предположение
определяет случайность выборки точек
Х-Y.
Если точки данных X-Y
записывались в течение некоторого
времени, данное предположение часто
нарушается. Вместо независимых данных,
такие последовательные наблюдения
будут давать серийно коррелированные
значения. -
В
генеральной совокупности существует
линейная зависимость между X и Y.
По аналогии с простой линейной регрессией
может рассматриваться и нелинейная
зависимость между X и У. Некоторые такие
случаи будут обсуждаться ниже.
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
Так как гетероскедастичность не приводит к смещению оценок коэффициентов, можно по-прежнему использовать МНК. Смещены и несостоятельны оказываются не сами оценки коэффициентов, а их стандартные ошибки, поэтому формула для расчета стандартных ошибок в условиях гомоскедастичности не подходит для случая гетероскедастичности.
Естественной идеей в этой ситуации является корректировка формулы расчета стандартных ошибок, чтобы она давала «правильный» (состоятельный) результат. Тогда можно снова будет корректно проводить тесты, проверяющие, например, незначимость коэффициентов, и строить доверительные интервалы. Соответствующие «правильные» стандартные ошибки называются состоятельными в условиях гетероскедастичности стандартными ошибками (heteroskedasticity consistent (heteroskedasticity robust) standard errors)1. Первоначальная формула для их расчета была предложена Уайтом, поэтому иногда их также называют стандартными ошибками в форме Уайта (White standard errors). Предложенная Уайтом состоятельная оценка ковариационной матрицы вектора оценок коэффициентов имеет вид:
(widehat{V}{left( widehat{beta} right) = n}left( {X^{‘}X} right)^{- 1}left( {frac{1}{n}{sumlimits_{s = 1}^{n}e_{s}^{2}}x_{s}x_{s}^{‘}} right)left( {X^{‘}X} right)^{- 1},)
где (x_{s}) – это s-я строка матрицы регрессоров X. Легко видеть, что эта формула более громоздка, чем формула (widehat{V}{left( widehat{beta} right) = left( {X^{‘}X} right)^{- 1}}S^{2}), которую мы вывели в третьей главе для случая гомоскедастичности. К счастью, на практике соответствующие вычисления не представляют сложности, так как возможность автоматически рассчитывать стандартные ошибки в форме Уайта реализована во всех современных эконометрических пакетах. Общепринятое обозначение для этой версии стандартных ошибок: «HC0». В работах (MacKinnon, White,1985) и (Davidson, MacKinnon, 2004) были предложены и альтернативные версии, которые обычно обозначаются в эконометрических пакетах «HC1», «HC2» и «HC3». Их расчетные формулы несколько отличаются, однако суть остается прежней: они позволяют состоятельно оценивать стандартные отклонения МНК-оценок коэффициентов в условиях гетероскедастичности.
Для случая парной регрессии состоятельная в условиях гетероскедастичности стандартная ошибка оценки коэффициента при регрессоре имеет вид:
(mathit{se}{left( widehat{beta_{2}} right) = sqrt{frac{1}{n}frac{frac{1}{n — 2}{sumlimits_{i = 1}^{n}{left( {x_{i} — overline{x}} right)^{2}e_{i}^{2}}}}{widehat{mathit{var}}(x)^{2}}.}})
Формальное доказательство состоятельности будет приведено в следующей главе. Пока же обсудим пример, иллюстрирующий важность использования робастных стандартных ошибок.
Пример 5.1. Оценка эффективности использования удобрений
В файле Agriculture в материалах к этому учебнику содержатся следующие данные 2010 года об урожайности яровой и озимой пшеницы в Спасском районе Пензенской области:
PRODP — урожайность в денежном выражении, в тысячах рублей с 1 га,
SIZE – размер пахотного поля, га,
LABOUR – трудозатраты, руб. на 1 га,
FUNG1 – фунгициды, протравители семян, расходы на удобрение в руб. на 1 га,
FUNG2 – фунгициды, во время роста, расходы на удобрение в руб. на 1 га,
GIRB – гербициды, расходы на удобрение в руб. на 1 га,
INSEC – инсектициды, расходы на удобрение в руб. на 1 га,
YDOB1 – аммофос, во время сева, расходы на удобрение в руб. на 1 га,
YDOB2 – аммиачная селитра, во время роста, расходы на удобрение в руб. на 1 га.
Представим, что вас интересует ответ на вопрос: влияет ли использование фунгицидов на урожайность поля?
(а) Оцените зависимость урожайности в денежном выражении от константы и переменных FUNG1, FUNG2, YDOB1, YDOB2, GIRB, INSEC, LABOUR. Запишите уравнение регрессии в стандартной форме, указав коэффициент детерминации и (в скобках под соответствующими коэффициентами) стандартные ошибки для случая гомоскедастичности. Какие из переменных значимы на 5-процентном уровне значимости?
(б) Решите предыдущий пункт заново, используя теперь состоятельные в условиях гетероскедастичности стандартные ошибки. Сопоставьте выводы по поводу значимости (при пятипроцентном уровне) переменных, характеризующих использование фунгицидов.
Решение:
(а) Оценим требуемое уравнение:
Модель 1: МНК, использованы наблюдения 1-200
Зависимая переменная: PRODP
| Коэффициент | Ст. ошибка | t-статистика | P-значение | ||
| const | -38,4019 | 7,5273 | -5,1017 | <0,00001 | *** |
| FUNG1 | 0,0445755 | 0,0487615 | 0,9142 | 0,36178 | |
| FUNG2 | 0,103625 | 0,049254 | 2,1039 | 0,03669 | ** |
| GIRB | 0,0776059 | 0,0523553 | 1,4823 | 0,13990 | |
| INSEC | 0,0782521 | 0,0484667 | 1,6146 | 0,10805 | |
| LABOUR | 0,0415064 | 0,00275277 | 15,0781 | <0,00001 | *** |
| YDOB1 | 0,0492168 | 0,0233328 | 2,1093 | 0,03621 | ** |
| YDOB2 | -0,0906824 | 0,025864 | -3,5061 | 0,00057 | *** |
| Сумма кв. остатков | 150575,6 | Ст. ошибка модели | 28,00443 | |
| R-квадрат | 0,801958 | Испр. R-квадрат | 0,794738 | |
| F(7, 192) | 111,0701 | Р-значение (F) | 5,08e-64 |
Переменные FUNG2, LABOUR, YDOB1 и YDOB2 значимы на пятипроцентном уровне значимости (причем LABOUR и YDOB2 — ещё и на однопроцентном).
Если представить те же самые результаты в форме уравнения, то получится вот так:
({widehat{mathit{PRODP}}}_{i} = {{- underset{(7,53)}{38,40}} + {underset{(0,05)}{0,04} ast {mathit{FUNG}1}_{i}} + {underset{(0,05)}{0,10} ast {mathit{FUNG}2}_{i}} +})
({{+ underset{(0,05)}{0,08}} ast mathit{GIRB}_{i}} + {underset{(0,05)}{0,08} ast mathit{INSEC}_{i}} + {underset{(0,003)}{0,04} ast mathit{LABOUR}_{i}} + {})
({{{+ underset{(0,02)}{0,05}} ast {mathit{YDOB}1}_{i}} — {underset{(0,03)}{0,09} ast {mathit{YDOB}2}_{i}}},{R^{2} = 0,802})
(б) При использовании альтернативных стандартных ошибок получим следующий результат:
Модель 2: МНК, использованы наблюдения 1-200
Зависимая переменная: PRODP
Робастные оценки стандартных ошибок (с поправкой на гетероскедастичность),
вариант HC1
| Коэффициент | Ст. ошибка | t-статистика | P-значение | ||
| const | -38,4019 | 7,40425 | -5,1865 | <0,00001 | *** |
| FUNG1 | 0,0445755 | 0,0629524 | 0,7081 | 0,47975 | |
| FUNG2 | 0,103625 | 0,0624082 | 1,6604 | 0,09846 | * |
| GIRB | 0,0776059 | 0,0623777 | 1,2441 | 0,21497 | |
| INSEC | 0,0782521 | 0,0536527 | 1,4585 | 0,14634 | |
| LABOUR | 0,0415064 | 0,00300121 | 13,8299 | <0,00001 | *** |
| YDOB1 | 0,0492168 | 0,0197491 | 2,4921 | 0,01355 | ** |
| YDOB2 | -0,0906824 | 0,030999 | -2,9253 | 0,00386 | *** |
| Сумма кв. остатков | 150575,6 | Ст. ошибка модели | 28,00443 | |
| R-квадрат | 0,801958 | Испр. R-квадрат | 0,794738 | |
| F(7, 192) | 119,2263 | Р-значение (F) | 2,16e-66 |
Оценки коэффициентов по сравнению с пунктом (а) не поменялись, что естественно: мы ведь по-прежнему используем обычный МНК. Однако стандартные ошибки теперь немного другие. В некоторых случаях это меняет выводы тестов на незначимость.
Переменные LABOUR, YDOB1 и YDOB2 значимы на пятипроцентном уровне значимости (причем LABOUR и YDOB2 — ещё и на однопроцентном).
Переменная FUNG2 перестала быть значимой на пятипроцентном уровне. Таким образом, при использовании корректных стандартных ошибок следует сделать вывод о том, что соответствующий вид удобрений не важен для урожайности. Обратите внимание, что если бы мы использовали «обычные» стандартные ошибки, то мы пришли бы к противоположному заключению (см. пункт (а)).
* * *
Важно подчеркнуть, что в реальных пространственных данных гетероскедастичность в той или иной степени наблюдается практически всегда. А даже если её и нет, то состоятельные в условиях гетероскедастичности стандартные ошибки по-прежнему будут… состоятельными (и будут близки к «обычным» стандартным ошибкам, посчитанным по формулам из третьей главы). Поэтому в современных прикладных исследованиях при оценке уравнений по умолчанию используются именно робастные стандартные ошибки, а не стандартные ошибки для случая гомоскедастичности. Мы настоятельно рекомендуем читателю поступать так же2. В нашем учебнике с этого момента и во всех последующих главах, если прямо не оговорено иное, для МНК-оценок параметров всегда используются состоятельные в условиях гетероскедастичности стандартные ошибки.
-
Поскольку довольно утомительно каждый раз произносить это название полностью в англоязычном варианте их часто называют просто robust standard errors, что на русском языке эконометристов превратилось в «робастные стандартные ошибки». Кому-то подобный англицизм, конечно, режет слух, однако в устной речи он и правда куда удобней своей длинной альтернативы.↩︎
-
Просто не забывайте включать соответствующую опцию в своем эконометрическом пакете.↩︎