
© Г. П. Тихова, 2013 УДК 616-07-092.41.9
Значение и интерпретация ошибки среднего в клиническом исследовании и эксперименте
Г. П. Тихова
ООО «ИнтелТекЛаб», Петрозаводск
Importance and interpretation of standard error of mean in clinical study and trial
G. P. Tikhova
IntelTeck Lab Ltd, Petrozavodsk
В статье рассмотрен содержательный смысл и различие между стандартной ошибкой среднего и среднеквадратическим отклонением, изложены факторы, влияющие на величину этих статистических параметров. Ключевые слова: обработка клинических данных, ошибка среднего, стандартное отклонение.
This paper highlighted the meaning and difference between standard error of mean and standard deviation as well as describes the factors that affect the values of this statistical parameters. Key words: clinical data processing, standard error of mean, standard deviation.
Прежде чем погрузиться в тонкости различных методов статистической обработки данных, зададимся вопросом: что мы собственно считаем с их помощью? Как рассчитанные на нашей выборке статистические параметры связаны с описанием исследуемой нами популяции?
Для примера рассмотрим числовую случайную величину с нормальным законом распределения -ударный объем у здоровых беременных женщин со сроком гестации не менее 30 недель.
Итак, во-первых, мы четко определяем интересующую нас популяцию — здоровые беременные женщины со сроком гестации 30 недель и более. Представим мысленно, что мы можем измерить ударный объем у всех без исключения членов этой популяции. (Конечно, на самом деле это сделать нереально!) Регистрируем ударный объем у 1-й беременной и получаем, допустим, 60 мл, затем у 2-й — 55 мл, у 3-й — 78 мл и т. д. В конечном итоге мы получаем бесконечное множество реализаций случайной величины под названием ударный объем. Можем ли мы посчитать среднее значение всех полученных измерений? Конечно, можем. Что же это будет за величина? Это будет точное среднее значение ударного объема, присущее популяции беременных со сроком от 30 недель и более. Подчеркну, именно точное среднее значение, без всякой ошибки, потому что по условию нашего мысленного эксперимента мы измерили ударный объем у всех без исключения членов популяции. Поскольку мы перебрали всех членов популяции, то откуда же взяться ошибке? Мы
не оставили никакой неопределенности, включив в расчет всю популяцию, поэтому и смогли посчитать точное среднее значение без всякой ошибки. Но из этого следует, что в рассматриваемой популяции среднее значение — это объективная реальность, а не придуманная математиками величина. Причем это среднее значение равно вполне конкретному числу, присущему именно этой популяции. В другой популяции оно, вообще говоря, может быть другим, и если это так, то по показателю ударного объема эти две популяции различаются, и данный показатель может служить признаком отличия этих популяций друг от друга. Точно также, имея полученные измерения, мы можем подсчитать точное значение стандартного отклонения ударного объема в этой популяции. Это же касается и медианы, и моды, и всех остальных статистик, которые обычно рассчитываются для числовой случайной величины. Что же получается? Все эти интегральные параметры случайной величины -не искусственное изобретение, а вполне реальные свойства, имеющие точные значения в конкретной популяции. Можно сказать, точные значения этих параметров определяются особенностями конкретной популяции и в свою очередь характеризуют ее, как отличительные признаки, присущие только ей. Когда мы проводим реальное исследование, то вынуждены довольствоваться выборкой, т. е. лишь частью (и, как правило, далеко не большей частью) интересующей нас популяции. Однако мы все-таки рассчитываем и среднее значение, и стандартное отклонение, и другие статистики в условиях,
когда подавляющее большинство членов популяции оказываются за рамками нашего исследования. Что же мы делаем и что получаем в итоге? Поскольку мы включаем в наш расчет лишь часть популяции, привносим некоторую неопределенность, неточность в расчет среднего и других статистик и в итоге получаем не точные значения, а лишь ОЦЕНКИ этих параметров. Такие оценки называют выборочными оценками, потому что они рассчитаны по конкретной выборке и в некоторой степени зависят от ее особенностей. Если мы повторим исследование, наберем другую выборку из этой же популяции, и снова рассчитаем среднее, то это новое рассчитанное значение, скорее всего, будет отличаться от первого, хотя, по сути, мы рассчитали то же самое. Почему нам следуем ожидать этого несовпадения? Потому что на выборке мы получаем лишь оценку точного значения, а не само популяционное значение статистики, и эта оценка, полученная на выборке, всегда, подчеркну, всегда без исключения имеет ошибку. Ошибка эта называется статистической, потому что она обусловлена случайными факторами. В отличие от коварной и вредоносной ошибки смещения, статистическая ошибка, можно сказать, безобидна, т. к. ее всегда можно рассчитать и сделать на нее поправку. Она всегда явная и точно известна по величине. Но если ошибки смещения можно попытаться избежать, то статистическая ошибка — это неотъемлемая часть выборочной оценки. При расчете любого параметра на выборке, статистическая ошибка будет иметь место и от нее никуда не деться.
Таким образом, рассчитывая на нашей выборке среднее значение, стандартное отклонение и другие параметры числовой случайной величины, мы на самом деле проводим оценивание их реальных точных значений в популяции, из которой эта выборка была взята. Оценка, как мы уже упоминали, может быть более или менее точной, но необходимо смириться с тем, что на выборке мы никогда не получим абсолютно точной величины, которая имеет место в данной исследуемой популяции. А это значит, что, вообще говоря, каждую рассчитанную на выборке статистику мы должны сопровождать ее ошибкой, чтобы можно было понять, с какой точностью оценен тот или иной параметр. На практике однако принято указывать ошибки не всех рассчитываемых статистических параметров, а лишь наиболее важных для сравнения выборок. Так, например, как правило, указывают ошибку среднего. О ней и поговорим поподробнее.
Поскольку ошибка среднего рассчитывается по очень простой формуле непосредственно из стандартного отклонения, то ее часто путают с этим последним. В научных статьях принято
указывать рядом со средним значением либо ошибку среднего, либо стандартное отклонение, но это только потому, что, зная одно, мы легко можем вычислить другое при известном объеме выборки. Из этого однако не следует, что ошибка среднего и стандартное отклонение — это одно и то же. Указанные два параметра описывают совершенно разные свойства исследуемого показателя. Ошибка среднего характеризует точность выборочной оценки среднего значения исследуемого показателя в заданной популяции и зависит от вариабельности, объективно присущей этому показателю в условиях данной популяции, и репрезентативности выборки:
— чем чище и больше наша выборка, тем меньше ошибка;
— чем меньше вариабельность исследуемого показателя, тем меньше ошибка.
Иными словами, ошибка среднего дает нам понять, насколько сильно мы отклоняемся в своих расчетах от точного значения среднего в популяции. Если бы наши расчеты охватили всю заданную популяцию, то ошибка среднего была бы равна нулю, т. е. отсутствовала бы полностью.
Что касается стандартного отклонения, то по своему смыслу к точности оценки среднего оно не имеет никакого отношения. Как мы уже разобрали ранее, стандартное отклонение характеризует объективно существующую вариабельность исследуемого показателя, и поскольку мы здесь обсуждаем только случайные величины с нормальным вероятностным распределением, эта статистика не может обращаться в ноль ни при каких обстоятельствах, даже в случае охвата всей популяции. Стандартное отклонение, рассчитанное по выборке, само является приближенной оценкой точного популяционного значения стандартного отклонения и, соответственно, тоже имеет статистическую ошибку, величина которой определяется теми же условиями, что и ошибка среднего. Просто эту ошибку, как правило, не указывают. В критериях сравнения она не играет такой важной роли, как ошибка среднего.
Таким образом, стандартное отклонение характеризует объективную природу данных, с которыми мы имеем дело в исследовании, а ошибка среднего отражает точность и адекватность нашего исследования и полученных результатов. С увеличением объема выборки ошибка среднего стремится к нулю, а стандартное отклонение -к определенному числу, являющемуся точным значением стандартного отклонения этого показателя в популяции.
Иными словами, стандартное отклонение определяется объективной природой исследуемых данных, а ошибка среднего зависит:
— от объективной природы данных (исследуемой случайной величины), а именно ее вариабельности, выражаемой в стандартном отклонении;
— субъективной особенности конкретного исследования — объема выборки.
Мы очень подробно рассмотрели выборочную оценку среднего и его ошибку, но другие статистики, рассчитанные на выборке, также обладают некоторой статистической ошибкой в силу тех же причин, что и выборочное среднее значение. Из этого следует, что, указывая полученное в ходе расчетов значение статистического параметра, мы должны указать и его статистическую ошибку. Все в точности так же, как это принято для выборочного среднего значения. Это касается всех рассчитываемых статистик независимо от типа исследуемого показателя. По популярности расчета следом за средним значением идет оценка частот или долей для качественных, а иногда и порядковых показателей, поэтому на одном таком примере мы и рассмотрим, как правильно описывать такие результаты.
В исследовании, посвященном спинальной анестезии у беременных, необходимо было определить долю различных вариантов интраоперацион-ной тошноты и рвоты (ИОТР), а именно:
— сколько процентов пациенток не имели никаких осложнений,
— у какой доли беременных отмечалась гипотония во время операции,
— сколько процентов пациенток жаловались на тошноту,
— у какой доли наблюдаемых развилась интра-операционная рвота.
Исследуемая популяция определена как беременные со сроком гестации более 35 недель (беременность без патологий), спинальная анестезия проводилась по поводу планового кесарева сечения. Понятно, что в этой популяции мы исследуем качественный признак ИОТР, который является случайной величиной, принимающей в каждом конкретном случае одно из перечисленных значений, и во всей популяции доля каждого из вариантов вполне определена и имеет точное значение. Всю популяцию мы охватить в своем исследовании не можем, поэтому довольствуемся выборкой и, следовательно, полученные процентные доли (или частоты осложнений) будут лишь оценками точных популяционных величин. Что из этого следует? То, что все полученные числа, выборочные значения долей, будут иметь статистические ошибки, которые мы также должны рассчитать
и указать. В качестве примера приведена табл., взятая из работы А. М. Погодина и Е. М. Шифмана, напечатанной в 1-м номере нашего журнала за 2009 г. [1].
Частота эпизодов ИОТР в исследуемых группах
Группа* Частота ИОТР (доля ± ошибка доли, %)
I (n = 35) 17,1 ± 2,4
II (n = 33) 18,2 ± 2,6
III (n = 36) 11,1 ± 1,6
Всего (n = 104) 15,4 ± 1,3
* Стратификация пациентов на 3 группы производилась в соответствии с антиэметиком, применявшимся в составе премедикации.
Если мы выделим из той же популяции выборку большего объема, то выборочные значения долей у нас буду ближе к реальным, а ошибки — меньше. Независимо от того, что и на каких данных вы считаете, поведение всех расчетных статистических параметров будет одинаково:
— если параметр отражает объективную реальность, то его выборочные оценки с увеличением объема выборки будут приближаться к конкретным числам — точным значениям в популяции;
— если параметр характеризует точность и адекватность исследования, то с увеличением объема выборки его значение будет неуклонно уменьшаться и стремиться к нулю.
Все статистические ошибки с ростом объема выборки снижаются и стремятся к нулю.
Процентные доли не являются исключением, поэтому при указании результатов в процентных долях необходимо записывать полученное выборочное значение с его статистической ошибкой (ошибкой доли), поскольку сравнение долей требует такой же математической строгости, как и сравнение средних значений. Нельзя утверждать, что одна доля больше другой лишь на том основании, что мы получили два числа, одно больше другого. Их разность может укладываться в статистическую ошибку одного из них (или обоих) и они могут быть просто неточными, приближенными, оценками одного и того же точного попу-ляционного значения. Например, в приведенной табл. в группе I частота ИОТР составила 17,1%, а в группе II — 18,2%, однако мы не можем утверждать, что в I группе частота меньше, чем во II, поскольку ошибки этих долей покрывают оба этих значения, указывая на то, что они с точки зрения статистики равны, а их различие — просто случайная неточность оценки, которую привносит данная, не очень большая, выборка и природная вариабельность данных.
Вопросы, которые мы здесь разобрали, порой кажутся второстепенными и мелкими, но на самом деле они требуют пристального внимания
исследователя при интерпретации результатов, полученных в ходе статистической обработки клинических данных. Глубокое понимание природы и источников статистической ошибки, а также строгий контроль ее величины позволят избежать неправомерных выводов: обнаружить эффект там, где его нет, или влияние фактора, когда в реальности оно отсутствует.
Литература
1. Погодин А. М., Шифман Е. М. Профилактика тошноты и рвоты при спинномозговой анестезии во время операции кесарева сечения // Регионарная анестезия и лечения острой боли. 2009; 1: 11-14.
Чтобы
судить о том, насколько точно проведенные
измерения отражают состав генеральной
совокупности, необходимо вычислить
стандартную ошибку средней арифметической
выборочной совокупности.
Стандартная
ошибка средней арифметической
характеризует степень отклонения
выборочной средней арифметической от
средней арифметической генеральной
совокупности.
Стандартная
ошибка средней арифметической вычисляется
по формуле:
![]() ,
,
где
– стандартное отклонение результатов
измерений, n
– объем выборки.
Зачастую
мы имеем дело с одной случайной выборкой
и с одной полученной при ее обработке
выборочной средней. Задача заключается
в суждении о величине неизвестной
генеральной средней по полученной
неточной величине случайной выборочной
средней.
Вычислим
среднюю ошибку найденного выборочного
среднего значения роста:
![]() 195
195
см; σ = 8,8 см;
![]() см.
см.
2,8 см
составляют не максимальную, а среднюю
возможную ошибку среднего. Отдельные
выборочные средние могут отклоняться
от генеральной как больше, так и меньше,
чем на 2,8 см.
Каковы
же пределы возможных ошибок случайной
выборки, какова ее максимальная ошибка?
Величина максимальной ошибки зависит
от величины средней ошибки и вычисляется
по формуле
![]() .
.
При
объеме выборки n
= 10:
![]() .
.
Все
случайные выборочные средние, которые
могут быть получены в подобных опытах
(в том числе и фактически полученная
выборочная средняя
![]() = 195 см), при своем варьировании около
= 195 см), при своем варьировании около
неизвестного генерального среднего в
подавляющем количестве группируются
около него так, что лишь ничтожный
процент их отклоняется от генеральной
средней более, чем на величину максимальной
ошибки.
Другими
словами, генеральная средняя определяется
как
![]() .
.
Эти пределы
колебаний значительно сужаются, если
средняя ошибка уменьшается благодаря
увеличению численности выборки.
Искомая
генеральная средняя лежит между
![]() и
и![]() .
.
Таким образом, при высокой точности
выполнения эксперимента и достаточно
большом числе измерений можно определить
среднюю арифметическую бесконечно
большого числа экспериментов.
До сих
пор мы определяли максимальную ошибку
выборочной средней, исходя из того, что
все остальные показатели известны. Если
же мы хотим достичь определенной
точности, определенного приближения к
генеральной средней, в этом случае
встает вопрос о численности выборки (о
том, сколько измерений, опытов необходимо
провести).
Допустим, что
максимальная ошибка должна быть равна
5 см. Сколько человек надо обследовать
(измерить) в нашем случае?
![]() .
.
Следовательно,
мы должны провести измерения роста у
36 баскетболистов высокого класса.
10. Достоверность различий
Следующим
важным вопросом практически для каждого
экспериментатора является умение
доказать достоверность различий между
двумя рядами признаков.
Проверку
достоверности различия двух рядов
измерений производят путем вычисления
критерия достоверности различия – t:
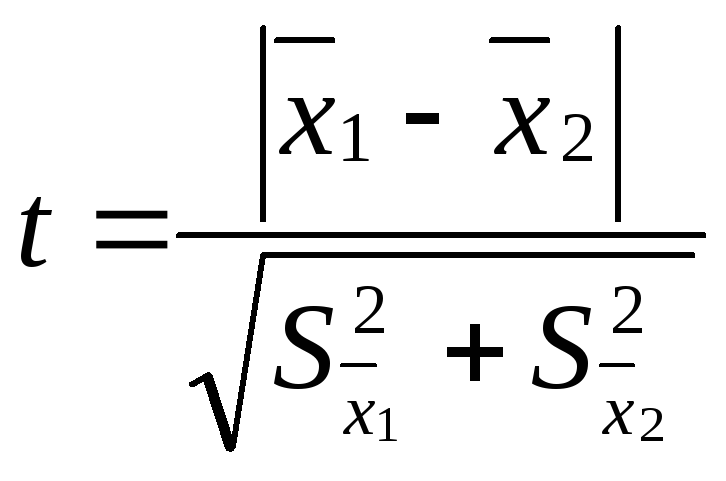 ,
,
где
![]() – средняя одной выборки;
– средняя одной выборки;![]() – средняя другой выборки;
– средняя другой выборки;![]() – средняя ошибка первой выборки;
– средняя ошибка первой выборки;![]() – второй выборки. Если t < 2, то различие
– второй выборки. Если t < 2, то различие
между двумя выборками считается
недостоверным, если t
2, то различие между двумя выборками
достоверно на 95%.
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
Среднее арифметическое, как известно, используется для получения обобщающей характеристики некоторого набора данных. Если данные более-менее однородны и в них нет аномальных наблюдений (выбросов), то среднее хорошо обобщает данные, сведя к минимуму влияние случайных факторов (они взаимопогашаются при сложении).
Когда анализируемые данные представляют собой выборку (которая состоит из случайных значений), то среднее арифметическое часто (но не всегда) выступает в роли приближенной оценки математического ожидания. Почему приближенной? Потому что среднее арифметическое – это величина, которая зависит от набора случайных чисел, и, следовательно, сама является случайной величиной. При повторных экспериментах (даже в одних и тех же условиях) средние будут отличаться друг от друга.
Для того, чтобы на основе статистического анализа данных делать корректные выводы, необходимо оценить возможный разброс полученного результата. Для этого рассчитываются различные показатели вариации. Но то исходные данные. И как мы только что установили, среднее арифметическое также обладает разбросом, который необходимо оценить и учитывать в дальнейшем (в выводах, в выборе метода анализа и т.д.).
Интуитивно понятно, что разброс средней должен быть как-то связан с разбросом исходных данных. Основной характеристикой разброса средней выступает та же дисперсия.
Дисперсия выборочных данных – это средний квадрат отклонения от средней, и рассчитать ее по исходным данным не составляет труда, например, в Excel предусмотрены специальные функции. Однако, как же рассчитать дисперсию средней, если в распоряжении есть только одна выборка и одно среднее арифметическое?
Расчет дисперсии и стандартной ошибки средней арифметической
Чтобы получить дисперсию средней арифметической нет необходимости проводить множество экспериментов, достаточно иметь только одну выборку. Это легко доказать. Для начала вспомним, что средняя арифметическая (простая) рассчитывается по формуле:
![]()
где xi – значения переменной,
n – количество значений.
Теперь учтем два свойства дисперсии, согласно которым, 1) — постоянный множитель можно вынести за знак дисперсии, возведя его в квадрат и 2) — дисперсия суммы независимых случайных величин равняется сумме соответствующих дисперсий. Предполагается, что каждое случайное значение xi обладает одинаковым разбросом, поэтому несложно вывести формулу дисперсии средней арифметической:
![]()
Используя более привычные обозначения, формулу записывают как:
![]()
где σ2 – это дисперсия, случайной величины, причем генеральная.
На практике же, генеральная дисперсия известна далеко не всегда, точнее совсем редко, поэтому в качестве оной используют выборочную дисперсию:
![]()
Стандартное отклонение средней арифметической называется стандартной ошибкой средней и рассчитывается, как квадратный корень из дисперсии.
Формула стандартной ошибки средней при использовании генеральной дисперсии
![]()
Формула стандартной ошибки средней при использовании выборочной дисперсии
![]()
Последняя формула на практике используется чаще всего, т.к. генеральная дисперсия обычно не известна. Чтобы не вводить новые обозначения, стандартную ошибку средней обычно записывают в виде соотношения стандартного отклонения выборки и корня объема выборки.
Назначение и свойство стандартной ошибки средней арифметической
Стандартная ошибка средней много, где используется. И очень полезно понимать ее свойства. Посмотрим еще раз на формулу стандартной ошибки средней:
![]()
Числитель – это стандартное отклонение выборки и здесь все понятно. Чем больше разброс данных, тем больше стандартная ошибка средней – прямо пропорциональная зависимость.
Посмотрим на знаменатель. Здесь находится квадратный корень из объема выборки. Соответственно, чем больше объем выборки, тем меньше стандартная ошибка средней. Для наглядности изобразим на одной диаграмме график нормально распределенной переменной со средней равной 10, сигмой – 3, и второй график – распределение средней арифметической этой же переменной, полученной по 16-ти наблюдениям (которое также будет нормальным).

Судя по формуле, разброс стандартной ошибки средней должен быть в 4 раза (корень из 16) меньше, чем разброс исходных данных, что и видно на рисунке выше. Чем больше наблюдений, тем меньше разброс средней.
Казалось бы, что для получения наиболее точной средней достаточно использовать максимально большую выборку и тогда стандартная ошибка средней будет стремиться к нулю, а сама средняя, соответственно, к математическому ожиданию. Однако квадратный корень объема выборки в знаменателе говорит о том, что связь между точностью выборочной средней и размером выборки не является линейной. Например, увеличение выборки с 20-ти до 50-ти наблюдений, то есть на 30 значений или в 2,5 раза, уменьшает стандартную ошибку средней только на 36%, а со 100-а до 130-ти наблюдений (на те же 30 значений), снижает разброс данных лишь на 12%.
Лучше всего изобразить эту мысль в виде графика зависимости стандартной ошибки средней от размера выборки. Пусть стандартное отклонение равно 10 (на форму графика это не влияет).

Видно, что примерно после 50-ти значений, уменьшение стандартной ошибки средней резко замедляется, после 100-а – наклон постепенно становится почти нулевым.
Таким образом, при достижении некоторого размера выборки ее дальнейшее увеличение уже почти не сказывается на точности средней. Этот факт имеет далеко идущие последствия. Например, при проведении выборочного обследования населения (опроса) чрезмерное увеличение выборки ведет к неоправданным затратам, т.к. точность почти не меняется. Именно поэтому количество опрошенных редко превышает 1,5 тысячи человек. Точность при таком размере выборки часто является достаточной, а дальнейшее увеличение выборки – нецелесообразным.
Подведем итог. Расчет дисперсии и стандартной ошибки средней имеет довольно простую формулу и обладает полезным свойством, связанным с тем, что относительно хорошая точность средней достигается уже при 100 наблюдениях (в этом случае стандартная ошибка средней становится в 10 раз меньше, чем стандартное отклонение выборки). Больше, конечно, лучше, но бесконечно увеличивать объем выборки не имеет практического смысла. Хотя, все зависит от поставленных задач и цены ошибки. В некоторых опросах участие принимают десятки тысяч людей.
Дисперсия и стандартная ошибка средней имеют большое практическое значение. Они используются в проверке гипотез и расчете доверительных интервалов.
Поделиться в социальных сетях:
Стандартное отклонение и стандартная ошибка: в чем разница?
17 авг. 2022 г.
читать 2 мин
В статистике студенты часто путают два термина: стандартное отклонение и стандартная ошибка .
Стандартное отклонение измеряет, насколько разбросаны значения в наборе данных.
Стандартная ошибка — это стандартное отклонение среднего значения в повторных выборках из совокупности.
Давайте рассмотрим пример, чтобы ясно проиллюстрировать эту идею.
Пример: стандартное отклонение против стандартной ошибки
Предположим, мы измеряем вес 10 разных черепах.

Для этой выборки из 10 черепах мы можем вычислить среднее значение выборки и стандартное отклонение выборки:

Предположим, что стандартное отклонение оказалось равным 8,68. Это дает нам представление о том, насколько распределен вес этих черепах.
Но предположим, что мы собираем еще одну простую случайную выборку из 10 черепах и также проводим их измерения. Более чем вероятно, что эта выборка из 10 черепах будет иметь немного другое среднее значение и стандартное отклонение, даже если они взяты из одной и той же популяции:

Теперь, если мы представим, что мы берем повторные выборки из одной и той же совокупности и записываем выборочное среднее и выборочное стандартное отклонение для каждой выборки:

Теперь представьте, что мы наносим каждое среднее значение выборки на одну и ту же строку:

Стандартное отклонение этих средних значений известно как стандартная ошибка.

Формула для фактического расчета стандартной ошибки:
Стандартная ошибка = s/ √n
куда:
- s: стандартное отклонение выборки
- n: размер выборки
Какой смысл использовать стандартную ошибку?
Когда мы вычисляем среднее значение данной выборки, нас на самом деле интересует не среднее значение этой конкретной выборки, а скорее среднее значение большей совокупности, из которой взята выборка.
Однако мы используем выборки, потому что для них гораздо проще собирать данные, чем для всего населения. И, конечно же, среднее значение выборки будет варьироваться от выборки к выборке, поэтому мы используем стандартную ошибку среднего значения как способ измерить, насколько точна наша оценка среднего значения.
Вы заметите из формулы для расчета стандартной ошибки, что по мере увеличения размера выборки (n) стандартная ошибка уменьшается:
Стандартная ошибка = s/ √n
Это должно иметь смысл, поскольку большие размеры выборки уменьшают изменчивость и увеличивают вероятность того, что среднее значение нашей выборки ближе к фактическому среднему значению генеральной совокупности.
Когда использовать стандартное отклонение против стандартной ошибки
Если мы просто заинтересованы в измерении того, насколько разбросаны значения в наборе данных, мы можем использовать стандартное отклонение .
Однако, если мы заинтересованы в количественной оценке неопределенности оценки среднего значения, мы можем использовать стандартную ошибку среднего значения .
В зависимости от вашего конкретного сценария и того, чего вы пытаетесь достичь, вы можете использовать либо стандартное отклонение, либо стандартную ошибку.
Что такое Стандартная ошибка?
Стандартная ошибка (SE) статистики – это приблизительное стандартное отклонение статистической выборки. Стандартная ошибка – это статистический термин, который измеряет точность, с которой выборочное распределение представляет генеральную совокупность с помощью стандартного отклонения. В статистике выборочное среднее отклоняется от фактического среднего для генеральной совокупности; это отклонение представляет собой стандартную ошибку среднего.
Ключевые моменты
- Стандартная ошибка – это приблизительное стандартное отклонение статистической выборки.
- Стандартная ошибка может включать вариацию между вычисленным средним для генеральной совокупности и тем, которое считается известным или принимаемым как точное.
- Чем больше точек данных участвует в расчетах среднего, тем меньше стандартная ошибка.
Понимание стандартной ошибки
Термин «стандартная ошибка» используется для обозначения стандартного отклонения различных статистических данных выборки, таких как среднее или медианное значение. Например, «стандартная ошибка среднего» относится к стандартному отклонению распределения выборочных средних, взятых из генеральной совокупности. Чем меньше стандартная ошибка, тем более репрезентативной будет выборка для генеральной совокупности.
Связь между стандартной ошибкой и стандартным отклонением такова, что для данного размера выборки стандартная ошибка равна стандартному отклонению, деленному на квадратный корень из размера выборки. Стандартная ошибка также обратно пропорциональна размеру выборки; Чем больше размер выборки, тем меньше стандартная ошибка, поскольку статистика приближается к фактическому значению.
Стандартная ошибка считается частью выводимой статистики. Он представляет собой стандартное отклонение среднего значения в наборе данных. Это служит мерой вариации случайных величин, обеспечивая измерение спреда. Чем меньше разброс, тем точнее набор данных.
Краткая справка
Стандартная ошибка и стандартное отклонение – это меры изменчивости, в то время как меры центральной тенденции включают среднее значение, медианное значение и т. Д.
Требования к стандартной ошибке
Когда производится выборка из генеральной совокупности , обычно рассчитывается среднее или среднее значение. Стандартная ошибка может включать разброс между вычисленным средним для генеральной совокупности и тем, которое считается известным или принимаемым как точное. Это помогает компенсировать любые случайные неточности, связанные со сбором пробы.
В случаях, когда собирается несколько образцов, среднее значение каждой выборки может незначительно отличаться от других, создавая разброс между переменными. Этот разброс чаще всего измеряется как стандартная ошибка, учитывающая различия между средними значениями в наборах данных.
Чем больше точек данных участвует в расчетах среднего, тем меньше стандартная ошибка. Когда стандартная ошибка мала, данные считаются более репрезентативными для истинного среднего значения. В случаях, когда стандартная ошибка велика, данные могут иметь некоторые заметные отклонения.
Стандартное отклонение – это представление разброса каждой точки данных. Стандартное отклонение используется для определения достоверности данных на основе количества точек данных, отображаемых на каждом уровне стандартного отклонения. Стандартные ошибки больше служат способом определения точности образца или точности нескольких образцов путем анализа отклонения в пределах средних.
(note that I’m focusing on standard error of the mean, which I believe the questioner was as well, but you can generate a standard error for any sample statistic)
The standard error is related to the standard deviation but they are not the same thing and increasing sample size does not make them closer together. Rather, it makes them farther apart. The standard deviation of the sample becomes closer to the population standard deviation as sample size increases but not the standard error.
Sometimes the terminology around this is a bit thick to get through.
When you gather a sample and calculate the standard deviation of that sample, as the sample grows in size the estimate of the standard deviation gets more and more accurate. It seems from your question that was what you were thinking about. But also consider that the mean of the sample tends to be closer to the population mean on average. That’s critical for understanding the standard error.
The standard error is about what would happen if you got multiple samples of a given size. If you take a sample of 10 you can get some estimate of the mean. Then you take another sample of 10 and new mean estimate, and so on. The standard deviation of the means of those samples is the standard error. Given that you posed your question you can probably see now that if the N is high then the standard error is smaller because the means of samples will be less likely to deviate much from the true value.
To some that sounds kind of miraculous given that you’ve calculated this from one sample. So, what you could do is bootstrap a standard error through simulation to demonstrate the relationship. In R that would look like:
# the size of a sample
n <- 10
# set true mean and standard deviation values
m <- 50
s <- 100
# now generate lots and lots of samples with mean m and standard deviation s
# and get the means of those samples. Save them in y.
y <- replicate( 10000, mean( rnorm(n, m, s) ) )
# standard deviation of those means
sd(y)
# calcuation of theoretical standard error
s / sqrt(n)
You’ll find that those last two commands generate the same number (approximately). You can vary the n, m, and s values and they’ll always come out pretty close to each other.
(note that I’m focusing on standard error of the mean, which I believe the questioner was as well, but you can generate a standard error for any sample statistic)
The standard error is related to the standard deviation but they are not the same thing and increasing sample size does not make them closer together. Rather, it makes them farther apart. The standard deviation of the sample becomes closer to the population standard deviation as sample size increases but not the standard error.
Sometimes the terminology around this is a bit thick to get through.
When you gather a sample and calculate the standard deviation of that sample, as the sample grows in size the estimate of the standard deviation gets more and more accurate. It seems from your question that was what you were thinking about. But also consider that the mean of the sample tends to be closer to the population mean on average. That’s critical for understanding the standard error.
The standard error is about what would happen if you got multiple samples of a given size. If you take a sample of 10 you can get some estimate of the mean. Then you take another sample of 10 and new mean estimate, and so on. The standard deviation of the means of those samples is the standard error. Given that you posed your question you can probably see now that if the N is high then the standard error is smaller because the means of samples will be less likely to deviate much from the true value.
To some that sounds kind of miraculous given that you’ve calculated this from one sample. So, what you could do is bootstrap a standard error through simulation to demonstrate the relationship. In R that would look like:
# the size of a sample
n <- 10
# set true mean and standard deviation values
m <- 50
s <- 100
# now generate lots and lots of samples with mean m and standard deviation s
# and get the means of those samples. Save them in y.
y <- replicate( 10000, mean( rnorm(n, m, s) ) )
# standard deviation of those means
sd(y)
# calcuation of theoretical standard error
s / sqrt(n)
You’ll find that those last two commands generate the same number (approximately). You can vary the n, m, and s values and they’ll always come out pretty close to each other.
2.1. Стандартное отклонение среднего выборочного значения (ошибка среднего) и доверительный интервал
Результаты измерений обычно показывают с так называемой «средней статистической ошибкой средней величины» и для нашего случая (см. табл. 1.1) это будет запись: «высота сеянцев в опыте составила 5,0 ± 0,28 см». Словосочетание «средняя статистическая ошибка» обычно сокращают до названия «ошибка среднего» или просто «ошибка», обозначают буквой m и определяют по очень простой формуле. Для итогов упомянутой таблицы, где расчеты по 25 высотам дали значение δ = 1,42 см, эта ошибка составит:
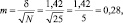 (2.1)
(2.1)
|
где δ – |
стандартное отклонение; |
|
N – |
число наблюдений или объем выборки, шт. |
Если объем выборки взять 100 шт., то ошибка снизится в 2 раза: 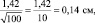 а если увеличить до 10000 шт., то в 10 раз, до 0,014 см.
а если увеличить до 10000 шт., то в 10 раз, до 0,014 см.
Рассмотрим эту «среднюю статистическую ошибку» (далее просто ошибка) подробно, так как именно в ней скрыто понимание того, что называют статистическим мышлением. Интуитивно мы понимаем, что малая выборка дает большую ошибку, т.е. неточное определение среднего значения. Последний термин настолько привычен, что мы даже не задумываемся о том, что его правильное и полное название «среднее выборочное значение», т.е. среднее, определяемое в некоторой выборке. И выборки могут быть очень разные по численности. Начнем с самых малых. Например, что произойдет с ошибкой, если объем выборки сократить до 2 измерений? Такие выборки бывают, например, в почвенных исследованиях, когда каждое измерение достается дорогой ценой. Для этого вернемся к рис. 1.1. На нем стандартное отклонение ±δ, которое отражает разброс значений вокруг среднего в левую и правую сторону в виде холма, наблюдается при объеме выборки 1 шт. В этом случае ошибка среднего выборочного значения будет равна стандартному отклонению: m = δ = 1,42. С увеличением N ошибка уменьшается:
при объеме выборки N = 2 ошибка будет
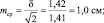
при объеме выборки N = 4 ошибка будет
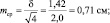
при объеме выборки N = 16 ошибка будет
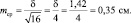
Важно понять, что ряд распределения частот этих выборочных средних будет постепенно как бы съеживаться и приближаться к центру, где находится так называемое «генеральное» среднее. Поясним, что в математике генеральное среднее значение называется математическим ожиданием и его обозначают буквой «М». Например, это может быть средняя высота, рассчитанная по всем измеренным в теплице сеянцам, или среднее число семян в 1 шишке у дерева после подсчета семян во всех собранных с дерева шишках (50, 100, 500 и т.д., т.е. весьма небольшая генеральная совокупность). Распределение частот значений выборочных средних, которых может быть множество, будет иметь форму такого же холма, как и распределение единичных значений на рис. 1.1. При этом, если выборка будет из 1 шт., то холм будет в точности таким же, но при выборках из 2 шт. его форма съежится в  = в 1,41 раза; при выборках из 4 шт. –
= в 1,41 раза; при выборках из 4 шт. –
в  = в 2 раза; при выборках из 9 шт. – в
= в 2 раза; при выборках из 9 шт. – в 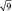 = в 3 раза и т.д.
= в 3 раза и т.д.
Для этих сокращающихся рядов распределения выборочных средних можно рассчитать свое, особое стандартное отклонение. Вероятно, чтобы не путать его со СТАНДОТКЛ, его стали называть по-другому, т.е. «средней статистической ошибкой средней величины». Чем больше по объему выборки, тем короче ряд распределения средних значений этих выборок с его «хвостами» в левую и правую сторону, и тем меньше величина этого особого стандартного отклонения. Закон распределения частот выборочных средних точно такой же, и имеет те же свойства: в пределах ±2m находится 95 % всех значений выборочных средних, в пределах ±3m – 99,5 %, а в пределах ±4m находится 100 % всех значений xср. Форма этого распределения меняется от пологой при малых выборках до очень крутой, вплоть до «схлопывания» в центре при выборках большого объема, когда ошибка среднего стремится к нулю.
Здесь следует пояснить, что, на наш взгляд, словосочетание «средняя статистическая ошибка средней величины», сокращаемое до «ошибки среднего значения» или просто до «ошибки», вводит нас в некоторое заблуждение, так как мы привыкли со школы, что ошибки надобно исправлять. Более правильным, вместо слов «ошибка среднего значения», будет использование слов «стандартное отклонение выборочных средних значений от генерального среднего». Не случайно математики выбрали для обозначения величины этого отклонения букву «m», а для обозначения генерального среднего (математического ожидания) – букву «М». Слова для объяснения этих сложных явлений могут быть разными, но и у математиков, и у биологов есть единодушие в понимании статистического смысла, лежащего за этими буквенными символами. Вообще, лучше было бы ввести некий иной термин вместо слов «ошибка» или «отклонение», так как они изначально имеют в нашем сознании иной смысл; на наш взгляд, более всего подходит слово «скачок» (чем сильнее отскакивает выборочное среднее от генерального среднего, тем реже оно встречается). Но так уж получилось, что не нашлось нейтрального (иностранного) слова, и слово «ошибка» традиционно используют, и мы также будем его использовать; важно понимать его иной, чем в обыденном употреблении, математический и статистический смысл.
Для самого точного определения средней высоты сеянцев нужно измерять все растения в питомнике, и тогда мы получим «генеральное среднее значение». Но так не делают, а измеряют несколько сотен растений в разных местах и этого бывает достаточно для определения среднего выборочного значения с приемлемой точностью. В нашем примере при 100 растениях ошибка его определения составит 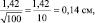 а ее отнесение к средней высоте сеянцев 5,0 см, выражаемое в %, дает нам так называемую точность опыта: 0,14/5,0×100 = 2,8 %. В биологии точность опыта ±2–3 % считается высокой, ±5 % – достаточной, а ±6–7 % – пониженной, но это весьма упрощенное представление о планировании эксперимента.
а ее отнесение к средней высоте сеянцев 5,0 см, выражаемое в %, дает нам так называемую точность опыта: 0,14/5,0×100 = 2,8 %. В биологии точность опыта ±2–3 % считается высокой, ±5 % – достаточной, а ±6–7 % – пониженной, но это весьма упрощенное представление о планировании эксперимента.
Вообще, точность опыта не самоцель; гораздо важнее сократить численность (объем) выборки до минимума. Представим себе, что средняя высота сеянцев xср = 5,0 см, а ее ±δ = 1,42 см, рассмотренные выше, получены при измерении 1000 растений потомства сосны, например, из Кунгура. Поделив ±δ на корень из 1000 получаем ошибку опыта m = ±0,045 см. Далее получаем точность опыта
Р = m/xср×100 = 0,045/5,0×100 = 0,9 %.
Точность получилась очень высокой. Но в питомнике есть потомства и из других мест и такой уровень точности совершенно не нужен, так как нужно узнать еще высоты сеянцев, например, из Очера, Осы, Добрянки и других районов. Если выборку из 1 тыс. растений снижать, то будет увеличиваться ошибка в определении средней высоты. И нужно найти приемлемую величину такой ошибки, которая позволит нам, тем не менее, уверенно утверждать, что это потомство растет быстрее, либо медленнее других. Причем происхождений может быть несколько сотен и минимизация выборок крайне важна, так как масштабы работ ограничены физическими возможностями бригады селекционеров. Следовательно, надо сокращать объем выборки. Как это сделать правильно?
Рассмотрим два потомства. Первое – это упомянутые сеянцы происхождением из Кунгура (хср1), второе – сеянцы из Кизела с хср2 = 6,0 см и δ2 = ± 1,0 см (превышение высоты на 20 %). Надо это превышение доказать. При выборках из 100 растений ранее определенная ошибка m1 была равна 0,14 см, вторая ошибка m2 после расчетов по формуле (2.1) составит 0,1 см. По закону нормального распределения 99,5 % всех возможных значений этих средних хср1 и хср2 будут в пределах «плюс-минус три ошибки», что можно показать графически (рис. 2.1) или в виде формул:
хср1 ± 3m1 = 5,0 ± 3×0,14 = 5,0 ± 0,4 см
и
хср2 ± 3m2 = 6,0 ± 3×0,1 = 6,0 ± 0,3 см.
Возможные теоретические значения средних в генеральной совокупности не перекрывают друг друга, значит, различие достоверно. А если сократить выборки до 50 сеянцев? Тогда 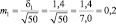 и
и 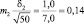 и пределы колебаний возможных значений средних будут:
и пределы колебаний возможных значений средних будут:
хср1 ± 3m1 = 5,0 ± 3×0,20 = 5,0 ± 0,6 см;
хср2 ± 3m2 = 6,0 ± 3×0,14 = 6,0 ± 0,3 см.

Рис. 2.1. Средние значения по выборкам из 100 растений и их тройные ошибки (пределы возможных значений выборочных средних в 99,5 % случаев)
Снова вынесем эти пределы на график (рис. 2.2).

Рис. 2.2. Средние значения при N = 50 растений и их тройные ошибки
Как видим, пределы сблизились и если еще сократить выборки, то они перекроются. Можно ли далее снижать объем выборки?
Можно, но здесь вступает в силу так называемое условие безошибочного прогноза. Мы это условие задали на уровне 99,5 % и для этого взяли ±3m для распределения ошибок. Но можно взять уровень пониже, с пределами ±2δ (уровень 95 %) и даже с пределами ±1,7δ (уровень 90 %).
При выборках из 25 штук сеянцев, получаем две ошибки: 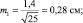
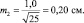 Тогда пределы значений для этих двух выборочных средних для уровня прогноза в 95 % будут:
Тогда пределы значений для этих двух выборочных средних для уровня прогноза в 95 % будут:
хср1 ± 2m1 = 5,0 ± 2×0,28 = 5,0 ± 0,56 см;
хср2 ± 2m2 = 6,0 ± 2×0,20 = 6,0 ± 0,40 см.
Выносим эти пределы опять на график (рис. 2.3).
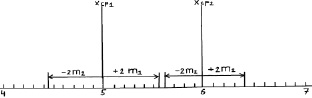
Рис. 2.3. Средние значения при N = 25 растений и их двойные ошибки (пределы возможных значений средних в 95 % случаев)
Как видим, просвет все еще есть, и поэтому между возможными значениями средних высот сеянцев в других выборках из происхождений Кунгур и Кизел различия будут опять доказаны. Но уровень доказательства понизился до 95 %, и для 5 % оставшихся случаев нет гарантии, что различия будут иметь место при выборке из 25 растений. Их может и не быть, но эту вероятность в 5 % мы допускаем.
Стандартное отклонение и стандартная ошибка: в чем разница?
17 авг. 2022 г.
читать 2 мин
В статистике студенты часто путают два термина: стандартное отклонение и стандартная ошибка .
Стандартное отклонение измеряет, насколько разбросаны значения в наборе данных.
Стандартная ошибка — это стандартное отклонение среднего значения в повторных выборках из совокупности.
Давайте рассмотрим пример, чтобы ясно проиллюстрировать эту идею.
Пример: стандартное отклонение против стандартной ошибки
Предположим, мы измеряем вес 10 разных черепах.
Для этой выборки из 10 черепах мы можем вычислить среднее значение выборки и стандартное отклонение выборки:
Предположим, что стандартное отклонение оказалось равным 8,68. Это дает нам представление о том, насколько распределен вес этих черепах.
Но предположим, что мы собираем еще одну простую случайную выборку из 10 черепах и также проводим их измерения. Более чем вероятно, что эта выборка из 10 черепах будет иметь немного другое среднее значение и стандартное отклонение, даже если они взяты из одной и той же популяции:
Теперь, если мы представим, что мы берем повторные выборки из одной и той же совокупности и записываем выборочное среднее и выборочное стандартное отклонение для каждой выборки:
Теперь представьте, что мы наносим каждое среднее значение выборки на одну и ту же строку:
Стандартное отклонение этих средних значений известно как стандартная ошибка.
Формула для фактического расчета стандартной ошибки:
Стандартная ошибка = s/ √n
куда:
- s: стандартное отклонение выборки
- n: размер выборки
Какой смысл использовать стандартную ошибку?
Когда мы вычисляем среднее значение данной выборки, нас на самом деле интересует не среднее значение этой конкретной выборки, а скорее среднее значение большей совокупности, из которой взята выборка.
Однако мы используем выборки, потому что для них гораздо проще собирать данные, чем для всего населения. И, конечно же, среднее значение выборки будет варьироваться от выборки к выборке, поэтому мы используем стандартную ошибку среднего значения как способ измерить, насколько точна наша оценка среднего значения.
Вы заметите из формулы для расчета стандартной ошибки, что по мере увеличения размера выборки (n) стандартная ошибка уменьшается:
Стандартная ошибка = s/ √n
Это должно иметь смысл, поскольку большие размеры выборки уменьшают изменчивость и увеличивают вероятность того, что среднее значение нашей выборки ближе к фактическому среднему значению генеральной совокупности.
Когда использовать стандартное отклонение против стандартной ошибки
Если мы просто заинтересованы в измерении того, насколько разбросаны значения в наборе данных, мы можем использовать стандартное отклонение .
Однако, если мы заинтересованы в количественной оценке неопределенности оценки среднего значения, мы можем использовать стандартную ошибку среднего значения .
В зависимости от вашего конкретного сценария и того, чего вы пытаетесь достичь, вы можете использовать либо стандартное отклонение, либо стандартную ошибку.
Среднее арифметическое, как известно, используется для получения обобщающей характеристики некоторого набора данных. Если данные более-менее однородны и в них нет аномальных наблюдений (выбросов), то среднее хорошо обобщает данные, сведя к минимуму влияние случайных факторов (они взаимопогашаются при сложении).
Когда анализируемые данные представляют собой выборку (которая состоит из случайных значений), то среднее арифметическое часто (но не всегда) выступает в роли приближенной оценки математического ожидания. Почему приближенной? Потому что среднее арифметическое – это величина, которая зависит от набора случайных чисел, и, следовательно, сама является случайной величиной. При повторных экспериментах (даже в одних и тех же условиях) средние будут отличаться друг от друга.
Для того, чтобы на основе статистического анализа данных делать корректные выводы, необходимо оценить возможный разброс полученного результата. Для этого рассчитываются различные показатели вариации. Но то исходные данные. И как мы только что установили, среднее арифметическое также обладает разбросом, который необходимо оценить и учитывать в дальнейшем (в выводах, в выборе метода анализа и т.д.).
Интуитивно понятно, что разброс средней должен быть как-то связан с разбросом исходных данных. Основной характеристикой разброса средней выступает та же дисперсия.
Дисперсия выборочных данных – это средний квадрат отклонения от средней, и рассчитать ее по исходным данным не составляет труда, например, в Excel предусмотрены специальные функции. Однако, как же рассчитать дисперсию средней, если в распоряжении есть только одна выборка и одно среднее арифметическое?
Расчет дисперсии и стандартной ошибки средней арифметической
Чтобы получить дисперсию средней арифметической нет необходимости проводить множество экспериментов, достаточно иметь только одну выборку. Это легко доказать. Для начала вспомним, что средняя арифметическая (простая) рассчитывается по формуле:
![]()
где xi – значения переменной,
n – количество значений.
Теперь учтем два свойства дисперсии, согласно которым, 1) — постоянный множитель можно вынести за знак дисперсии, возведя его в квадрат и 2) — дисперсия суммы независимых случайных величин равняется сумме соответствующих дисперсий. Предполагается, что каждое случайное значение xi обладает одинаковым разбросом, поэтому несложно вывести формулу дисперсии средней арифметической:
![]()
Используя более привычные обозначения, формулу записывают как:
![]()
где σ2 – это дисперсия, случайной величины, причем генеральная.
На практике же, генеральная дисперсия известна далеко не всегда, точнее совсем редко, поэтому в качестве оной используют выборочную дисперсию:
![]()
Стандартное отклонение средней арифметической называется стандартной ошибкой средней и рассчитывается, как квадратный корень из дисперсии.
Формула стандартной ошибки средней при использовании генеральной дисперсии
![]()
Формула стандартной ошибки средней при использовании выборочной дисперсии
![]()
Последняя формула на практике используется чаще всего, т.к. генеральная дисперсия обычно не известна. Чтобы не вводить новые обозначения, стандартную ошибку средней обычно записывают в виде соотношения стандартного отклонения выборки и корня объема выборки.
Назначение и свойство стандартной ошибки средней арифметической
Стандартная ошибка средней много, где используется. И очень полезно понимать ее свойства. Посмотрим еще раз на формулу стандартной ошибки средней:
![]()
Числитель – это стандартное отклонение выборки и здесь все понятно. Чем больше разброс данных, тем больше стандартная ошибка средней – прямо пропорциональная зависимость.
Посмотрим на знаменатель. Здесь находится квадратный корень из объема выборки. Соответственно, чем больше объем выборки, тем меньше стандартная ошибка средней. Для наглядности изобразим на одной диаграмме график нормально распределенной переменной со средней равной 10, сигмой – 3, и второй график – распределение средней арифметической этой же переменной, полученной по 16-ти наблюдениям (которое также будет нормальным).
Судя по формуле, разброс стандартной ошибки средней должен быть в 4 раза (корень из 16) меньше, чем разброс исходных данных, что и видно на рисунке выше. Чем больше наблюдений, тем меньше разброс средней.
Казалось бы, что для получения наиболее точной средней достаточно использовать максимально большую выборку и тогда стандартная ошибка средней будет стремиться к нулю, а сама средняя, соответственно, к математическому ожиданию. Однако квадратный корень объема выборки в знаменателе говорит о том, что связь между точностью выборочной средней и размером выборки не является линейной. Например, увеличение выборки с 20-ти до 50-ти наблюдений, то есть на 30 значений или в 2,5 раза, уменьшает стандартную ошибку средней только на 36%, а со 100-а до 130-ти наблюдений (на те же 30 значений), снижает разброс данных лишь на 12%.
Лучше всего изобразить эту мысль в виде графика зависимости стандартной ошибки средней от размера выборки. Пусть стандартное отклонение равно 10 (на форму графика это не влияет).
Видно, что примерно после 50-ти значений, уменьшение стандартной ошибки средней резко замедляется, после 100-а – наклон постепенно становится почти нулевым.
Таким образом, при достижении некоторого размера выборки ее дальнейшее увеличение уже почти не сказывается на точности средней. Этот факт имеет далеко идущие последствия. Например, при проведении выборочного обследования населения (опроса) чрезмерное увеличение выборки ведет к неоправданным затратам, т.к. точность почти не меняется. Именно поэтому количество опрошенных редко превышает 1,5 тысячи человек. Точность при таком размере выборки часто является достаточной, а дальнейшее увеличение выборки – нецелесообразным.
Подведем итог. Расчет дисперсии и стандартной ошибки средней имеет довольно простую формулу и обладает полезным свойством, связанным с тем, что относительно хорошая точность средней достигается уже при 100 наблюдениях (в этом случае стандартная ошибка средней становится в 10 раз меньше, чем стандартное отклонение выборки). Больше, конечно, лучше, но бесконечно увеличивать объем выборки не имеет практического смысла. Хотя, все зависит от поставленных задач и цены ошибки. В некоторых опросах участие принимают десятки тысяч людей.
Дисперсия и стандартная ошибка средней имеют большое практическое значение. Они используются в проверке гипотез и расчете доверительных интервалов.
Поделиться в социальных сетях:
What Is the Standard Error?
The standard error (SE) of a statistic is the approximate standard deviation of a statistical sample population.
The standard error is a statistical term that measures the accuracy with which a sample distribution represents a population by using standard deviation. In statistics, a sample mean deviates from the actual mean of a population; this deviation is the standard error of the mean.
Key Takeaways
- The standard error (SE) is the approximate standard deviation of a statistical sample population.
- The standard error describes the variation between the calculated mean of the population and one which is considered known, or accepted as accurate.
- The more data points involved in the calculations of the mean, the smaller the standard error tends to be.
Standard Error
Understanding Standard Error
The term «standard error» is used to refer to the standard deviation of various sample statistics, such as the mean or median. For example, the «standard error of the mean» refers to the standard deviation of the distribution of sample means taken from a population. The smaller the standard error, the more representative the sample will be of the overall population.
The relationship between the standard error and the standard deviation is such that, for a given sample size, the standard error equals the standard deviation divided by the square root of the sample size. The standard error is also inversely proportional to the sample size; the larger the sample size, the smaller the standard error because the statistic will approach the actual value.
The standard error is considered part of inferential statistics. It represents the standard deviation of the mean within a dataset. This serves as a measure of variation for random variables, providing a measurement for the spread. The smaller the spread, the more accurate the dataset.
Standard error and standard deviation are measures of variability, while central tendency measures include mean, median, etc.
Formula and Calculation of Standard Error
The standard error of an estimate can be calculated as the standard deviation divided by the square root of the sample size:
SE = σ / √n
where
- σ = the population standard deviation
- √n = the square root of the sample size
If the population standard deviation is not known, you can substitute the sample standard deviation, s, in the numerator to approximate the standard error.
Requirements for Standard Error
When a population is sampled, the mean, or average, is generally calculated. The standard error can include the variation between the calculated mean of the population and one which is considered known, or accepted as accurate. This helps compensate for any incidental inaccuracies related to the gathering of the sample.
In cases where multiple samples are collected, the mean of each sample may vary slightly from the others, creating a spread among the variables. This spread is most often measured as the standard error, accounting for the differences between the means across the datasets.
The more data points involved in the calculations of the mean, the smaller the standard error tends to be. When the standard error is small, the data is said to be more representative of the true mean. In cases where the standard error is large, the data may have some notable irregularities.
The standard deviation is a representation of the spread of each of the data points. The standard deviation is used to help determine the validity of the data based on the number of data points displayed at each level of standard deviation. Standard errors function more as a way to determine the accuracy of the sample or the accuracy of multiple samples by analyzing deviation within the means.
Standard Error vs. Standard Deviation
The standard error normalizes the standard deviation relative to the sample size used in an analysis. Standard deviation measures the amount of variance or dispersion of the data spread around the mean. The standard error can be thought of as the dispersion of the sample mean estimations around the true population mean. As the sample size becomes larger, the standard error will become smaller, indicating that the estimated sample mean value better approximates the population mean.
Example of Standard Error
Say that an analyst has looked at a random sample of 50 companies in the S&P 500 to understand the association between a stock’s P/E ratio and subsequent 12-month performance in the market. Assume that the resulting estimate is -0.20, indicating that for every 1.0 point in the P/E ratio, stocks return 0.2% poorer relative performance. In the sample of 50, the standard deviation was found to be 1.0.
The standard error is thus:
SE = 1.0/√50 = 1/7.07 = 0.141
Therefore, we would report the estimate as -0.20% ± 0.14, giving us a confidence interval of (-0.34 — -0.06). The true mean value of the association of the P/E on returns of the S&P 500 would therefore fall within that range with a high degree of probability.
Say now that we increase the sample of stocks to 100 and find that the estimate changes slightly from -0.20 to -0.25, and the standard deviation falls to 0.90. The new standard error would thus be:
SE = 0.90/√100 = 0.90/10 = 0.09.
The resulting confidence interval becomes -0.25 ± 0.09 = (-0.34 — -0.16), which is a tighter range of values.
What Is Meant by Standard Error?
Standard error is intuitively the standard deviation of the sampling distribution. In other words, it depicts how much disparity there is likely to be in a point estimate obtained from a sample relative to the true population mean.
What Is a Good Standard Error?
Standard error measures the amount of discrepancy that can be expected in a sample estimate compared to the true value in the population. Therefore, the smaller the standard error the better. In fact, a standard error of zero (or close to it) would indicate that the estimated value is exactly the true value.
How Do You Find the Standard Error?
The standard error takes the standard deviation and divides it by the square root of the sample size. Many statistical software packages automatically compute standard errors.
The Bottom Line
The standard error (SE) measures the dispersion of estimated values obtained from a sample around the true value to be found in the population. Statistical analysis and inference often involves drawing samples and running statistical tests to determine associations and correlations between variables. The standard error thus tells us with what degree of confidence we can expect the estimated value to approximate the population value.
Чтобы
судить о том, насколько точно проведенные
измерения отражают состав генеральной
совокупности, необходимо вычислить
стандартную ошибку средней арифметической
выборочной совокупности.
Стандартная
ошибка средней арифметической
характеризует степень отклонения
выборочной средней арифметической от
средней арифметической генеральной
совокупности.
Стандартная
ошибка средней арифметической вычисляется
по формуле:
![]() ,
,
где
– стандартное отклонение результатов
измерений, n
– объем выборки.
Зачастую
мы имеем дело с одной случайной выборкой
и с одной полученной при ее обработке
выборочной средней. Задача заключается
в суждении о величине неизвестной
генеральной средней по полученной
неточной величине случайной выборочной
средней.
Вычислим
среднюю ошибку найденного выборочного
среднего значения роста:
![]() 195
195
см; σ = 8,8 см;
![]() см.
см.
2,8 см
составляют не максимальную, а среднюю
возможную ошибку среднего. Отдельные
выборочные средние могут отклоняться
от генеральной как больше, так и меньше,
чем на 2,8 см.
Каковы
же пределы возможных ошибок случайной
выборки, какова ее максимальная ошибка?
Величина максимальной ошибки зависит
от величины средней ошибки и вычисляется
по формуле
![]() .
.
При
объеме выборки n
= 10:
![]() .
.
Все
случайные выборочные средние, которые
могут быть получены в подобных опытах
(в том числе и фактически полученная
выборочная средняя
![]() = 195 см), при своем варьировании около
= 195 см), при своем варьировании около
неизвестного генерального среднего в
подавляющем количестве группируются
около него так, что лишь ничтожный
процент их отклоняется от генеральной
средней более, чем на величину максимальной
ошибки.
Другими
словами, генеральная средняя определяется
как
![]() .
.
Эти пределы
колебаний значительно сужаются, если
средняя ошибка уменьшается благодаря
увеличению численности выборки.
Искомая
генеральная средняя лежит между
![]() и
и![]() .
.
Таким образом, при высокой точности
выполнения эксперимента и достаточно
большом числе измерений можно определить
среднюю арифметическую бесконечно
большого числа экспериментов.
До сих
пор мы определяли максимальную ошибку
выборочной средней, исходя из того, что
все остальные показатели известны. Если
же мы хотим достичь определенной
точности, определенного приближения к
генеральной средней, в этом случае
встает вопрос о численности выборки (о
том, сколько измерений, опытов необходимо
провести).
Допустим, что
максимальная ошибка должна быть равна
5 см. Сколько человек надо обследовать
(измерить) в нашем случае?
![]() .
.
Следовательно,
мы должны провести измерения роста у
36 баскетболистов высокого класса.
10. Достоверность различий
Следующим
важным вопросом практически для каждого
экспериментатора является умение
доказать достоверность различий между
двумя рядами признаков.
Проверку
достоверности различия двух рядов
измерений производят путем вычисления
критерия достоверности различия – t:
,
где
![]() – средняя одной выборки;
– средняя одной выборки;![]() – средняя другой выборки;
– средняя другой выборки;![]() – средняя ошибка первой выборки;
– средняя ошибка первой выборки;![]() – второй выборки. Если t < 2, то различие
– второй выборки. Если t < 2, то различие
между двумя выборками считается
недостоверным, если t
2, то различие между двумя выборками
достоверно на 95%.
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
Стандартная ошибка или ошибка выборки является мерой дисперсии для функции оценки для неизвестного параметра в популяции . Стандартная ошибка определяется как стандартное отклонение оценки, то есть положительный квадратный корень из дисперсии . В естествознании и метрологии также используется термин « стандартная неопределенность» , введенный в обращение ГУМом .



В случае несмещенного оценщика стандартная ошибка, следовательно, является мерой среднего отклонения оцененного значения параметра от истинного значения параметра. Чем меньше стандартная ошибка, тем точнее неизвестный параметр можно оценить с помощью оценщика. Стандартная ошибка зависит, помимо прочего, от
- размер выборки и
- дисперсия населения.
Как правило, чем больше размер выборки, тем меньше стандартная ошибка; чем меньше дисперсия, тем меньше стандартная ошибка.
Стандартная ошибка также играет важную роль в вычислении ошибок оценки , доверительных интервалов и статистики испытаний .
интерпретация
Стандартная ошибка дает представление о качестве оцениваемого параметра. Чем больше имеется индивидуальных значений, тем меньше стандартная ошибка и тем точнее можно оценить неизвестный параметр. Стандартная ошибка делает измеренный разброс (стандартное отклонение) двух наборов данных с разными размерами выборки сопоставимым путем нормализации стандартного отклонения к размеру выборки.
Если неизвестный параметр оценивается с помощью нескольких образцов, результаты будут отличаться от образца к образцу. Конечно, это изменение происходит не из-за изменения неизвестного параметра (потому что он фиксирован), а из-за случайных влияний, например Б. Неточности измерения. Стандартная ошибка — это стандартное отклонение оцененных параметров во многих выборках. Как правило, уменьшение стандартной ошибки вдвое требует увеличения размера выборки в четыре раза.
В отличие от этого, стандартное отклонение отображает фактический разброс в популяции , который также присутствует с высочайшей точностью измерения и бесконечным количеством индивидуальных измерений (например, для распределения веса, распределения по размерам, ежемесячного дохода). Он показывает, близки ли отдельные значения друг к другу или данные широко разбросаны.
пример
Предположим, вы изучаете популяцию старшеклассников с точки зрения их интеллекта. Таким образом, неизвестный параметр — это средний уровень интеллекта детей, посещающих среднюю школу. Если случайная выборка размера (например, с детьми) отбирается из этой совокупности , то среднее значение может быть вычислено по всем результатам измерений . Если после этой выборки будет нарисована другая случайная выборка с тем же количеством дочерних элементов и будет определено среднее значение, два средних значения не будут точно совпадать. Если нарисовать большое количество других случайных выборок из диапазона , то можно определить разброс всех эмпирически определенных средних значений вокруг среднего значения генеральной совокупности. Этот разброс — стандартная ошибка. Поскольку среднее значение выборки является наилучшей оценкой среднего значения генеральной совокупности, стандартная ошибка представляет собой разброс эмпирических средних значений вокруг среднего значения генеральной совокупности. Он показывает не распределение интеллекта детей, а точность рассчитанного среднего значения.

обозначение
Для обозначения стандартной ошибки используются различные термины, чтобы отличить ее от стандартного отклонения генеральной совокупности и прояснить, что это разброс оцениваемого параметра выборок:

оценивать
Поскольку стандартное отклонение генеральной совокупности включено в стандартную ошибку, стандартное отклонение генеральной совокупности должно быть оценено с использованием максимально точного оценщика, чтобы оценить стандартную ошибку.
Доверительные интервалы и тесты
Стандартная ошибка также играет важную роль в доверительных интервалах и тестах . Если оценка соответствует ожиданиям и, по крайней мере, приблизительно нормально распределена ( ), то

-
 .
.

Исходя из этого, — для неизвестного параметра можно указать доверительные интервалы :


или сформулировать тесты, например Б. принимает ли параметр определенное значение :

-
против.


а результаты статистики теста:
-
.

 это — квантиль стандартного нормального распределения , а также критическое значение для сформулированного теста. Как правило, его нужно оценивать по выборке, чтобы
это — квантиль стандартного нормального распределения , а также критическое значение для сформулированного теста. Как правило, его нужно оценивать по выборке, чтобы



где — количество наблюдений. Для t-распределение можно аппроксимировать стандартным нормальным распределением.

Стандартная ошибка среднего арифметического
Стандартная ошибка среднего арифметического такая же
-
,

где обозначает стандартное отклонение единичного измерения.
Вывод
Среднее значение размера выборки определяется как

Глядя на оценщик

с независимыми, одинаково распределенными случайными величинами с конечной дисперсией стандартная ошибка определяется как квадратный корень из дисперсии . Используя правила расчета дисперсий и уравнение Биенайме, можно рассчитать :




откуда следует формула для стандартной ошибки. Если это так , то аналогично следует

-
.

Расчет
Предполагая выборочное распределение, стандартная ошибка может быть рассчитана с использованием дисперсии выборочного распределения:
- в биномиальном распределении с параметрами

-
,



Обозначьте это
Если стандартная ошибка среднего должна быть оценена, тогда дисперсия оценивается с помощью скорректированной дисперсии выборки .
пример
Для данных по мороженому рассчитывались среднее арифметическое, стандартная ошибка и стандартное отклонение за 1951, 1952 и 1953 годы для потребления мороженого на душу населения (измеряемого в пинтах ).
| год | В среднем | Стандартная ошибка среднего |
Стандартное отклонение |
Количество наблюдений |
|---|---|---|---|---|
| 1951 г. | 0,34680 | 0,01891 | 0,05980 | 10 |
| 1952 г. | 0,34954 | 0,01636 | 0,05899 | 13-е |
| 1953 г. | 0,39586 | 0,03064 | 0,08106 | 7-е |
Для 1951 и 1952 годов расчетные средние значения и стандартные отклонения, а также числа наблюдений примерно одинаковы. Следовательно, оцененные стандартные ошибки также дают примерно такое же значение. В 1953 г., с одной стороны, количество наблюдений меньше, а стандартное отклонение больше. Таким образом, стандартная ошибка почти вдвое превышает стандартные ошибки 1951 и 1952 годов.

Графическое представление может быть выполнено с помощью гистограммы ошибок . Справа показаны 95% интервалы оценки для 1951, 1952 и 1953 годов. Если функция выборки, по крайней мере, приблизительно нормально распределена, то 95% интервалы оценки задаются с помощью, а также средними значениями выборки и дисперсиями выборки.





Здесь также ясно видно, что среднее значение для 1953 г. может быть оценено более неточно, чем средние значения для 1951 и 1952 гг. (Более длинная полоса для 1953 г.).
Стандартная ошибка коэффициентов регрессии в модели простой регрессии
Классическая модель регрессии для простой линейной регрессии предполагает , что

с наблюдениями, сделанными при беге. Для оценщиков
-
а также


затем результаты
-
и .


В стандартные ошибки коэффициентов регрессии определяются

а также
-
.

Пример : Для данных по мороженому была проведена простая линейная регрессия для потребления мороженого на душу населения (измеренного в поллитрах) со средней недельной температурой (в градусах Фаренгейта) в качестве независимой переменной. Оценка регрессионной модели привела к:
-
.

| модель | Нестандартизированные коэффициенты | Стандартизированные коэффициенты |
Т | Sig. | |
|---|---|---|---|---|---|
| Коэффициенты регрессии | Стандартная ошибка | ||||
| постоянный | 0,20686 | 0,02470 | 8,375 | 0,000 | |
| температура | 0,00311 | 0,00048 | 0,776 | 6,502 | 0,000 |
Хотя расчетный коэффициент регрессии для средней недельной температуры очень мал, расчетная стандартная ошибка дала еще меньшее значение. Точность оценки коэффициента регрессии в 6,5 раз меньше, чем самого коэффициента.
Отношение к логарифмической вероятности
Термин также известен как стандартная ошибка оценки максимального правдоподобия , где в функции логарифмического правдоподобия и представляет собой наблюдаемую информацию Фишера (информация Фишера вместо оценки ML ).



Смотри тоже
- Стандартная ошибка регрессии
Индивидуальные доказательства
- ↑ a b Котешвара Рао Кадияла (1970): Проверка независимости регрессионных нарушений. В: Econometrica , 38, 97-117.
- ↑ а б финики мороженого. In: Data and Story Library , по состоянию на 16 февраля 2010 г.
- ↑ Приложение: логарифм правдоподобия и доверительные интервалы. Проверено 14 июля 2021 года .
Стандартная ошибка
Стандартная ошибка — это стандартное отклонение выборочного распределения статистики. Этот термин также может использоваться для оценки (хорошего предположения) этого стандартного отклонения, взятого из выборки всей группы.
Среднее значение некоторой части группы (называемой выборкой) является обычным способом оценки среднего значения для всей группы. Часто бывает слишком сложно или стоит слишком много денег, чтобы измерить всю группу. Но если измерить другую выборку, то ее среднее значение будет немного отличаться от первой выборки. Стандартная ошибка среднего — это способ узнать, насколько близка средняя по выборке к средней по всей группе. Это способ узнать, насколько вы можете быть уверены в среднем значении по выборке.
В реальных измерениях истинное значение стандартного отклонения среднего для всей группы обычно неизвестно. Поэтому термин стандартная ошибка часто используется для обозначения близкого к истинному значению для всей группы. Чем больше измерений в выборке, тем ближе к истинному значению для всей группы.
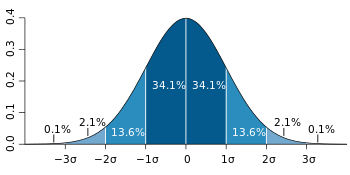
![]()
Для значения, отобранного с несмещенной нормально распределенной ошибкой, выше показана доля выборок, которые будут находиться в пределах 0, 1, 2 и 3 стандартных отклонений выше и ниже фактического значения.
Как найти стандартную ошибку среднего значения
Один из способов найти стандартную ошибку среднего — это множество выборок. Сначала находят среднее значение для каждой выборки. Затем находят среднее и стандартное отклонение этих средних по выборкам. Стандартное отклонение для всех средних по выборке и есть стандартная ошибка среднего. Это может быть большой объем работы. Иногда иметь большое количество образцов слишком сложно или стоит слишком много денег.
Другой способ найти стандартную ошибку среднего — использовать уравнение, для которого нужна только одна выборка. Стандартная ошибка среднего обычно оценивается по стандартному отклонению для выборки из всей группы (стандартное отклонение выборки), деленному на квадратный корень из размера выборки.
S E x ¯ = s n {displaystyle SE_{bar {x}} ={frac {s}{sqrt {n}}}} 
где
s — стандартное отклонение выборки (т.е. выборочная оценка стандартного отклонения популяции), и
n — количество измерений в выборке.
Насколько большой должна быть выборка, чтобы оценка стандартной ошибки среднего была близка к фактической стандартной ошибке среднего для всей группы? В выборке должно быть не менее шести измерений. Тогда стандартная ошибка среднего для выборки будет находиться в пределах 5% от стандартной ошибки среднего, если бы измерялась вся группа.
Исправления для некоторых случаев
Существует еще одно уравнение, которое можно использовать, если количество измерений составляет 5% или более от всей группы:
Существуют специальные уравнения, которые необходимо использовать, если образец имеет менее 20 измерений.
Иногда выборка поступает из одного места, хотя вся группа может быть рассредоточена. Кроме того, иногда выборка может быть сделана за короткий промежуток времени, когда вся группа охватывает более длительный период. В этом случае числа в выборке не являются независимыми. Тогда используются специальные уравнения, чтобы попытаться исправить это.
Полезность
Практический результат: Можно быть более уверенным в среднем значении, если провести больше измерений в выборке. Тогда стандартная ошибка среднего значения будет меньше, поскольку стандартное отклонение делится на большее число. Однако, чтобы сделать неопределенность (стандартную ошибку среднего) среднего значения в два раза меньше, размер выборки (n) должен быть в четыре раза больше. Это происходит потому, что стандартное отклонение делится на квадратный корень из размера выборки. Чтобы сделать неопределенность на одну десятую больше, размер выборки (n) должен быть в сто раз больше!
Стандартные ошибки легко вычисляются и часто используются, потому что:
- Если известна стандартная ошибка нескольких отдельных величин, то во многих случаях можно легко рассчитать стандартную ошибку некоторой функции этих величин;
- Если вероятностное распределение значения известно, его можно использовать для расчета хорошего приближения к точному доверительному интервалу; и
- Если распределение вероятности неизвестно, для оценки доверительного интервала можно использовать другие уравнения
- Когда размер выборки становится очень большим, принцип центральной предельной теоремы показывает, что числа в выборке очень похожи на числа во всей группе (они имеют нормальное распределение).
Относительная стандартная ошибка
Относительная стандартная ошибка (RSE) — это стандартная ошибка, деленная на среднее значение. Это число меньше единицы. Умножение его на 100% дает его в процентах от среднего значения. Это помогает показать, является ли неопределенность важной или нет. Например, рассмотрим два исследования доходов домохозяйств, в результате которых среднее значение по выборке составляет $50 000. Если стандартная ошибка одного опроса составляет $10 000, а другого — $5 000, то относительные стандартные ошибки равны 20% и 10% соответственно. Опрос с меньшей относительной стандартной ошибкой лучше, потому что он имеет более точное измерение (неопределенность меньше).
На самом деле, люди, которым необходимо знать средние значения, часто решают, насколько мала должна быть неопределенность, прежде чем они решат использовать информацию. Например, Национальный центр статистики здравоохранения США не сообщает среднее значение, если относительная стандартная ошибка превышает 30%. NCHS также требует не менее 30 наблюдений для того, чтобы оценка была представлена в отчете. []
Пример
Например, в воде Мексиканского залива водится много красной рыбы. Чтобы узнать, сколько в среднем весит красноперка длиной 42 см, невозможно измерить всех красноперок длиной 42 см. Вместо этого можно измерить некоторых из них. Рыба, которую измеряют, называется образцом. В таблице показан вес двух образцов красноперки длиной 42 см. Средний (средний) вес первого образца составляет 0,741 кг. Средний (средний) вес второго образца — 0,735 кг, что немного отличается от первого образца. Каждое из этих средних значений немного отличается от среднего значения, которое было бы получено при измерении каждой красной рыбы длиной 42 см (что в любом случае невозможно).
Неопределенность среднего значения можно использовать для того, чтобы узнать, насколько близки средние значения выборок к среднему значению, которое было бы получено в результате измерения всей группы. Неопределенность среднего оценивается как стандартное отклонение для выборки, деленное на квадратный корень из числа выборок минус один. Из таблицы видно, что неопределенности в средних для двух выборок очень близки друг к другу. Кроме того, относительная неопределенность — это неопределенность среднего значения, деленная на среднее значение, умноженное на 100%. Относительная неопределенность в данном примере составляет 2,38% и 2,50% для двух образцов.
Зная неопределенность среднего, можно узнать, насколько близко выборочное среднее к среднему, которое было бы получено в результате измерения всей группы. Среднее по всей группе находится между а) средним по выборке плюс неопределенность в среднем и б) средним по выборке минус неопределенность в среднем. В данном примере средний вес всей красноперки длиной 42 см в Мексиканском заливе, как ожидается, составит 0,723-0,759 кг по первой выборке и 0,717-0,753 по второй выборке.
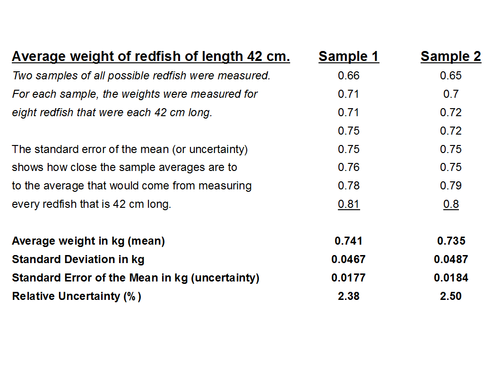
![]()
.jpg)
![]()
Пример красной рыбы (также известной как красный барабан, Sciaenops ocellatus), используемой в примере.
Стандартное отклонение (SD), измеряет количество изменчивости или дисперсии, из отдельных значений данных, к среднему значению, в то время как стандартная ошибка среднего (SEM) мер, как далеко образец среднее (среднее) данных, вероятно, будет от истинного среднего значения населения. SEM всегда меньше SD.
Ключевые выводы
- Стандартное отклонение (SD) измеряет разброс набора данных относительно его среднего значения.
- Стандартная ошибка среднего (SEM) измеряет, насколько вероятно расхождение между средним значением выборки по сравнению со средним значением генеральной совокупности.
- SEM берет SD и делит его на квадратный корень из размера выборки.
SEM против SD
Стандартное отклонение и стандартная ошибка используются во всех типах статистических исследований, включая исследования в области финансов, медицины, биологии, инженерии, психологии и т. Д. В этих исследованиях стандартное отклонение (SD) и расчетная стандартная ошибка среднего (SEM) ) используются для представления характеристик данных выборки и объяснения результатов статистического анализа. Однако некоторые исследователи иногда путают SD и SEM. Таким исследователям следует помнить, что расчеты SD и SEM включают разные статистические выводы, каждый из которых имеет свое значение. SD — это разброс отдельных значений данных.
Другими словами, SD указывает, насколько точно среднее значение представляет данные выборки. Однако значение SEM включает статистический вывод, основанный на распределении выборки. SEM — это стандартное отклонение теоретического распределения выборочных средних (выборочное распределение).
Расчет стандартного отклонения

Формула SD требует нескольких шагов:
- Во-первых, возьмите квадрат разницы между каждой точкой данных и средним значением выборки, найдя сумму этих значений.
- Затем разделите эту сумму на размер выборки минус один, который представляет собой дисперсию.
- Наконец, извлеките квадратный корень из дисперсии, чтобы получить стандартное отклонение.
Стандартная ошибка среднего
SEM рассчитывается путем деления стандартного отклонения на квадратный корень из размера выборки.
Стандартная ошибка дает точность выборочного среднего путем измерения изменчивости выборочного среднего от образца к образцу. SEM описывает, насколько точное среднее значение выборки является оценкой истинного среднего значения совокупности. По мере увеличения размера выборки данных SEM уменьшается по сравнению с SD; следовательно, по мере увеличения размера выборки среднее значение выборки оценивает истинное среднее значение генеральной совокупности с большей точностью. Напротив, увеличение размера выборки не обязательно делает SD больше или меньше, это просто становится более точной оценкой SD населения.
Стандартная ошибка и стандартное отклонение в финансах
В финансах стандартная ошибка средней дневной доходности актива измеряет точность выборочного среднего как оценки долгосрочной (постоянной) средней дневной доходности актива.
С другой стороны, стандартное отклонение доходности измеряет отклонения индивидуальных доходов от среднего значения. Таким образом, SD является мерой волатильности и может использоваться в качестве меры риска для инвестиций. Активы с более высокими ежедневными движениями цен имеют более высокое SD, чем активы с меньшими ежедневными движениями. Предполагая нормальное распределение, около 68% дневных изменений цен находятся в пределах одного стандартного отклонения от среднего, при этом около 95% дневных изменений цен находятся в пределах двух стандартных значений среднего.