
Стандартное отклонение и стандартная ошибка: в чем разница?
17 авг. 2022 г.
читать 2 мин
В статистике студенты часто путают два термина: стандартное отклонение и стандартная ошибка .
Стандартное отклонение измеряет, насколько разбросаны значения в наборе данных.
Стандартная ошибка — это стандартное отклонение среднего значения в повторных выборках из совокупности.
Давайте рассмотрим пример, чтобы ясно проиллюстрировать эту идею.
Пример: стандартное отклонение против стандартной ошибки
Предположим, мы измеряем вес 10 разных черепах.

Для этой выборки из 10 черепах мы можем вычислить среднее значение выборки и стандартное отклонение выборки:

Предположим, что стандартное отклонение оказалось равным 8,68. Это дает нам представление о том, насколько распределен вес этих черепах.
Но предположим, что мы собираем еще одну простую случайную выборку из 10 черепах и также проводим их измерения. Более чем вероятно, что эта выборка из 10 черепах будет иметь немного другое среднее значение и стандартное отклонение, даже если они взяты из одной и той же популяции:

Теперь, если мы представим, что мы берем повторные выборки из одной и той же совокупности и записываем выборочное среднее и выборочное стандартное отклонение для каждой выборки:

Теперь представьте, что мы наносим каждое среднее значение выборки на одну и ту же строку:

Стандартное отклонение этих средних значений известно как стандартная ошибка.

Формула для фактического расчета стандартной ошибки:
Стандартная ошибка = s/ √n
куда:
- s: стандартное отклонение выборки
- n: размер выборки
Какой смысл использовать стандартную ошибку?
Когда мы вычисляем среднее значение данной выборки, нас на самом деле интересует не среднее значение этой конкретной выборки, а скорее среднее значение большей совокупности, из которой взята выборка.
Однако мы используем выборки, потому что для них гораздо проще собирать данные, чем для всего населения. И, конечно же, среднее значение выборки будет варьироваться от выборки к выборке, поэтому мы используем стандартную ошибку среднего значения как способ измерить, насколько точна наша оценка среднего значения.
Вы заметите из формулы для расчета стандартной ошибки, что по мере увеличения размера выборки (n) стандартная ошибка уменьшается:
Стандартная ошибка = s/ √n
Это должно иметь смысл, поскольку большие размеры выборки уменьшают изменчивость и увеличивают вероятность того, что среднее значение нашей выборки ближе к фактическому среднему значению генеральной совокупности.
Когда использовать стандартное отклонение против стандартной ошибки
Если мы просто заинтересованы в измерении того, насколько разбросаны значения в наборе данных, мы можем использовать стандартное отклонение .
Однако, если мы заинтересованы в количественной оценке неопределенности оценки среднего значения, мы можем использовать стандартную ошибку среднего значения .
В зависимости от вашего конкретного сценария и того, чего вы пытаетесь достичь, вы можете использовать либо стандартное отклонение, либо стандартную ошибку.
Основные выводы:
-
Стандартная ошибка среднего указывает, насколько среднее значение генеральной совокупности может отличаться от среднего выборочного.
-
Вы можете уменьшить стандартную ошибку, увеличив размер выборки.
-
Стандартная ошибка среднего и стандартное отклонение являются мерами изменчивости, используемыми для обобщения наборов данных.
Если вы собираете данные для научных или статистических целей, стандартная ошибка среднего может помочь вам определить, насколько точно набор данных представляет фактическую совокупность. Проверка точности вашего образца подтверждает ваше клиническое исследование и помогает вам сделать правильные выводы.
В этой статье мы определяем стандартную ошибку среднего, объясняем, как она отличается от стандартного отклонения, и предлагаем формулу для ее расчета.
Какова стандартная ошибка среднего?
Стандартная ошибка среднего (SEM) используется для определения различий между более чем одной выборкой данных. Это помогает вам оценить, насколько хорошо ваши выборочные данные представляют всю совокупность, измеряя точность, с которой выборочные данные представляют совокупность, используя стандартное отклонение.
В статистике, среднеквадратичное отклонение является мерой того, насколько разбросаны числа. Иметь в виду относится к среднему числу. Стандартные функции ошибок используются для проверки точности выборки из нескольких выборок путем анализа отклонений в пределах средних значений.
Высокая стандартная ошибка показывает, что средние значения выборки широко разбросаны по среднему значению генеральной совокупности, поэтому ваша выборка может не точно представлять вашу генеральную совокупность. Низкая стандартная ошибка показывает, что средние значения выборки близко распределены вокруг среднего значения совокупности, что означает, что ваша выборка репрезентативна для вашей совокупности. Вы можете уменьшить стандартную ошибку, увеличив размер выборки.
Например, если вы измерите вес большой выборки мужчин, их вес может варьироваться от 125 до более чем 300 фунтов. Однако, если вы посмотрите на среднее значение выборочных данных, образцы будут различаться всего на несколько фунтов. Затем вы можете использовать стандартную ошибку среднего, чтобы определить, насколько вес отличается от среднего.
Связанный: Как рассчитать стандартную ошибку в Excel (с советами)
Стандартная ошибка среднего по сравнению со стандартным отклонением
Стандартная ошибка среднего и стандартное отклонение являются мерами изменчивости, используемыми для суммирования наборов данных.
Стандартная ошибка среднего значенияСтандартное отклонениеОценивает изменчивость в нескольких выборках генеральной совокупностиОписывает изменчивость в пределах одной выборкиВыводная статистика, которую можно оценитьОписательная статистика, которую можно рассчитатьИзмеряет, насколько вероятно, что среднее значение выборки будет отличаться от фактического среднего значения в популяции. выборка отличается от фактического среднего значенияСтандартная ошибка — это стандартное отклонение, деленное на квадратный корень размера выборкиСтандартное отклонение — это квадратный корень из дисперсии
Стандартная ошибка средней формулы
Формула для стандартной ошибки среднего выражается как:
SE = σ/√n
-
SE = стандартная ошибка выборки
-
σ = стандартное отклонение выборки
-
n = размер выборки
Обратите внимание, что σ — это греческая буква сигма, а √ — символ квадратного корня.
Формула стандартного отклонения выборки выражается следующим образом:
-
x̄ = среднее значение выборки, сначала найдите это значение
-
xᵢ = отдельные значения x
-
x = значение в наборе данных
-
n = количество точек данных
-
Σ — это сигма-обозначение для суммирования
Вот шаги, которые вы можете использовать для расчета стандартной ошибки среднего, используя выборку из пяти результатов теста SAT. Сначала рассчитайте стандартное отклонение, а затем подставьте это значение в формулу SEM.
1. Рассчитайте среднее
Сложите все образцы вместе и разделите общую сумму на количество образцов.
Пример: пять общих баллов SAT: 1000 + 1200 + 820 + 1300 + 680 = 5000.
Среднее (мк) = 5000 / 5 = 1000
2. Рассчитать отклонение от среднего
Рассчитайте отклонение каждого измерения от среднего, вычитая отдельные измерения из среднего.
Пример. Вычтите средний балл SAT, равный 1000, из каждого балла SAT.
хᵢ — мю
1000 — 1000 = 0
1200 — 1000 = 200
820 — 1000 = -180
1300 — 1000 = 300
680 — 1000 = -320
3. Возведите в квадрат каждое отклонение от среднего
Вычислите квадрат отклонения каждого измерения от среднего. Измерения, которые были отрицательными, после возведения в квадрат станут положительными.
Пример: Найдите квадратный корень отклонения каждой оценки от среднего.
(xᵢ — μ)²
0² = 0
200² = 40000
-180² = 32400
300² = 90000
-320² = 102400
4. Рассчитайте сумму квадратов отклонений
Определить сумму квадратов отклонений, сложив все числа из третьего шага.
Пример: 0 + 10 + 40000 + 32400 + 90000 + 102400 = 264810 = Σ
5. Разделите эту сумму на количество точек данных.
Возьмите сумму, которую вы подсчитали на четвертом шаге, и разделите ее на единицу меньше размера выборки. Используя приведенную выше формулу, это будет выглядеть как n-1.
Пример: 264810 / (5-1) = 66202,5
6. Вычислить квадратный корень, чтобы найти стандартное отклонение
Возьмите квадратный корень из числа, которое вы вычислили на пятом шаге. Это даст вам стандартное отклонение.
Пример: σ = √ 66202,5 = 257,298
7. Разделите стандартное отклонение на квадратный корень из размера выборки.
Используя стандартное отклонение, которое вы определили на шестом шаге, разделите это число на квадратный корень из размера выборки. Это позволит вам определить стандартную ошибку.
Пример: SE = σ/√n
SE = 257,298/√5
SE = 115,067
8. Рассчитайте стандартную ошибку среднего
Вычтите из среднего значения стандартную ошибку и запишите это число. Это стандартная ошибка ниже среднего. Затем добавьте стандартную ошибку к среднему значению и запишите число. Это стандартная ошибка выше среднего.
Пример:
SE ниже среднего: 1000 — 115,067 = 884,933
SE выше среднего: 1000 + 115,067 = 1115,067
Стандартная ошибка среднего может быть представлена следующим образом:
Средний балл SAT случайной выборки испытуемых составляет 1000 ± 115,067.
Пример СЭМ
Чтобы понять силу информации, которую вы можете получить из случайной выборки, используя стандартную ошибку среднего, рассмотрим следующий пример.
Вам дан вес при рождении 17 000 детей, рожденных в больницах Нью-Йорка. Средний вес при рождении составлял семь фунтов и три унции, а стандартное отклонение — один фунт три унции. Допустим, вы хотели узнать средний вес при рождении в этом районе, но получили веса только 30 случайных рождений по сравнению с общей численностью населения. Если бы эта выборка была взята только из всего населения, то вам лучше всего было бы предположить, что средний вес при рождении в выборке также будет равен семи фунтам и трем унциям.
Это предположение вряд ли будет точным, поскольку среднее значение выборки из 30 не будет таким точным, как среднее значение выборки из 17 000. Если бы вы продолжали брать случайные выборки из 30, вполне вероятно, что среднее значение каждой из них несколько изменилось бы.
Поскольку стандартное отклонение генеральной совокупности обычно неизвестно, вам необходимо оценить его, используя стандартное отклонение выборки. Чтобы сделать это с некоторой точностью, ваша выборка должна иметь нормальное распределение и состоять как минимум из 20 измерений. Хотя оценка может быть не совсем точной даже при большой выборке, ошибки в выборочной оценке стандартного отклонения генеральной совокупности будут уменьшены, если вы разделите его на квадратный корень из размера выборки.
Допустим, у вас есть шесть случайных выборок из 30 масс при рождении со стандартными отклонениями 1,3 фунта, 1,16 фунта, 1,14 фунта, 1,2 фунта, 1,25 фунта и 1,19 фунта, что на 0,098 фунта отличается от истинного значения стандартного отклонения населения. Эти шесть образцов приводят к оценкам стандартной ошибки, которые находятся в пределах 0,017 фунта от истинного значения. Ошибки стандартной ошибки средних оценок меньше, чем ошибки оценок стандартного отклонения, а значит, они более точные. Если бы размер выборки был больше 30, стандартная ошибка среднего была бы еще больше уменьшена.
Стандартное отклонение (SD), измеряет количество изменчивости или дисперсии, из отдельных значений данных, к среднему значению, в то время как стандартная ошибка среднего (SEM) мер, как далеко образец среднее (среднее) данных, вероятно, будет от истинного среднего значения населения. SEM всегда меньше SD.
Ключевые выводы
- Стандартное отклонение (SD) измеряет разброс набора данных относительно его среднего значения.
- Стандартная ошибка среднего (SEM) измеряет, насколько вероятно расхождение между средним значением выборки по сравнению со средним значением генеральной совокупности.
- SEM берет SD и делит его на квадратный корень из размера выборки.
SEM против SD
Стандартное отклонение и стандартная ошибка используются во всех типах статистических исследований, включая исследования в области финансов, медицины, биологии, инженерии, психологии и т. Д. В этих исследованиях стандартное отклонение (SD) и расчетная стандартная ошибка среднего (SEM) ) используются для представления характеристик данных выборки и объяснения результатов статистического анализа. Однако некоторые исследователи иногда путают SD и SEM. Таким исследователям следует помнить, что расчеты SD и SEM включают разные статистические выводы, каждый из которых имеет свое значение. SD — это разброс отдельных значений данных.
Другими словами, SD указывает, насколько точно среднее значение представляет данные выборки. Однако значение SEM включает статистический вывод, основанный на распределении выборки. SEM — это стандартное отклонение теоретического распределения выборочных средних (выборочное распределение).
Расчет стандартного отклонения

Формула SD требует нескольких шагов:
- Во-первых, возьмите квадрат разницы между каждой точкой данных и средним значением выборки, найдя сумму этих значений.
- Затем разделите эту сумму на размер выборки минус один, который представляет собой дисперсию.
- Наконец, извлеките квадратный корень из дисперсии, чтобы получить стандартное отклонение.
Стандартная ошибка среднего
SEM рассчитывается путем деления стандартного отклонения на квадратный корень из размера выборки.
Стандартная ошибка дает точность выборочного среднего путем измерения изменчивости выборочного среднего от образца к образцу. SEM описывает, насколько точное среднее значение выборки является оценкой истинного среднего значения совокупности. По мере увеличения размера выборки данных SEM уменьшается по сравнению с SD; следовательно, по мере увеличения размера выборки среднее значение выборки оценивает истинное среднее значение генеральной совокупности с большей точностью. Напротив, увеличение размера выборки не обязательно делает SD больше или меньше, это просто становится более точной оценкой SD населения.
Стандартная ошибка и стандартное отклонение в финансах
В финансах стандартная ошибка средней дневной доходности актива измеряет точность выборочного среднего как оценки долгосрочной (постоянной) средней дневной доходности актива.
С другой стороны, стандартное отклонение доходности измеряет отклонения индивидуальных доходов от среднего значения. Таким образом, SD является мерой волатильности и может использоваться в качестве меры риска для инвестиций. Активы с более высокими ежедневными движениями цен имеют более высокое SD, чем активы с меньшими ежедневными движениями. Предполагая нормальное распределение, около 68% дневных изменений цен находятся в пределах одного стандартного отклонения от среднего, при этом около 95% дневных изменений цен находятся в пределах двух стандартных значений среднего.
Между
признаками выборочной совокупности и
признаками генеральной совокупности,
как правило, существует некоторое
расхождение, которое называется ошибкой
статистического наблюдения. При массовом
наблюдении ошибки неизбежны, но возникают
они в результате действия различных
причин. Величина возможной ошибки
выборочного признака происходит из-за
ошибок регистрации и ошибок
репрезентативности. Ошибки регистрации,
или технические ошибки, связаны с
недостаточной квалификацией наблюдателей,
неточностью подсчетов, несовершенством
приборов и т. п.
Под
ошибкой
репрезентативности
(представительства) понимают расхождение
между выборочной характеристикой и
предполагаемой характеристикой
генеральной совокупности. Ошибки
репрезентативности бывают случайными
и систематическими. Систематические
ошибки связаны с нарушением установленных
правил отбора. Случайные
ошибки объясняются недостаточно
равномерным представлением в выборочной
совокупности различных категорий
единиц генеральной совокупности.
В
результате первой причины выборка
легко может оказаться смещенной, так
как при отборе каждой единицы допускается
ошибка, всегда направленная в одну и
ту же сторону. Эта ошибка получила
название ошибки
смещения.
Ее размер может превышать величину
случайной ошибки. Особенность ошибки
смещения состоит в том, что, являясь
постоянной частью ошибки репрезентативности,
она увеличивается с увеличением объема
выборки. Случайная же ошибка с увеличением
объема выборки уменьшается. Кроме того,
величину случайной ошибки можно
определить, тогда как размер ошибки
смещения практически определить очень
сложно, а иногда и невозможно, поэтому
важно знать причины, вызывающие ошибку
смещения, и предусмотреть мероприятия
по ее устранению.
Ошибки
смещения бывают преднамеренные и
непреднамеренные. Причиной возникновения
преднамеренной
ошибки
является тенденциозный подход к выбору
единиц из генеральной совокупности.
Чтобы не допустить появление такой
ошибки, необходимо соблюдать принцип
случайности отбора единиц.
Непреднамеренные
ошибки
могут возникать на стадии подготовки
выборочного наблюдения, формирования
выборочной совокупности и анализа ее
данных. Чтобы не допустить появление
таких ошибок, необходима хорошая основа
выборки, т. е. та генеральная
совокупность, из которой предполагается
производить отбор, например список
единиц отбора. Основа выборки должна
быть достоверной, полной и соответствовать
цели исследования, а единицы отбора и
их характеристики должны соответствовать
действительному их состоянию на момент
подготовки выборочного наблюдения.
Нередки случаи, когда в отношении
некоторых единиц, попавших в выборку,
трудно собрать сведения из-за их
отсутствия на момент наблюдения,
нежелания дать сведения и т. п. В
таких случаях эти единицы приходится
заменять другими. Необходимо следить,
чтобы замена осуществлялась равноценными
единицами.
Случайная
ошибка
выборки возникает в результате случайных
различий между единицами, попавшими в
выборку, и единицами генеральной
совокупности, т. е. она связана со
случайным отбором. Теоретическим
обоснованием появления случайных
ошибок выборки является теория
вероятностей и ее предельные теоремы.
Сущность
предельных
теорем
состоит в том, что в массовых явлениях
совокупное влияние различных случайных
причин на формирование закономерностей
и обобщающих характеристик будет сколь
угодно малой величиной или практически
не зависит от случая. Так как случайная
ошибка выборки возникает в результате
случайных различий между единицами
выборочной и генеральной совокупностей,
то при достаточно большом объеме выборки
она будет сколь угодно мала.
Предельные
теоремы теории вероятностей позволяют
определять размер случайных ошибок
выборки. Различают среднюю (стандартную)
и предельную ошибку выборки. Под средней
(стандартной) ошибкой
выборки понимают такое расхождение
между средней выборочной и генеральной
совокупностями (~ —), которое не превышает
±.
Предельной
ошибкой
выборки принято считать максимально
возможное расхождение (~ —), т. е.
максимум ошибки при заданной вероятности
ее появления.
В
математической теории выборочного
метода сравниваются средние характеристики
признаков выборочной и генеральной
совокупностей и доказывается, что с
увеличением объема выборки вероятность
появления больших ошибок и пределы
максимально возможной ошибки уменьшаются.
Чем больше обследуется единиц, тем
меньше будет величина расхождений
выборочных и генеральных характеристик.
На основании теоремы, доказанной П.Л.
Чебышевым, величину стандартной ошибки
простой случайной выборки при достаточно
большом объеме выборки (n)
можно определить по формуле

– стандартная
ошибка.
Из
этой формулы средней (стандартной)
ошибки простой случайной выборки видно,
что величина зависит от изменчивости
признака в генеральной совокупности
(чем больше вариация признака, тем
больше ошибка выборки) и от объема
выборки n
(чем больше обследуется единиц, тем
меньше будет величина расхождений
выборочных и генеральных характеристик).
Академик
A.M. Ляпунов доказал, что вероятность
появления случайной ошибки выборки
при достаточно большом ее объеме
подчиняется закону нормального
распределения. Эта вероятность
определяется по формуле

В
математической статистике употребляют
коэффициент доверия t, значения функции
F(t)
табулированы при разных его значениях,
при этом получают соответствующие
уровни доверительной вероятности
(табл. 6.1).
Таблица
6.1
Коэффициент
доверия t и соответствующие уровни
доверительной вероятности
![]()
Коэффициент
доверия позволяет вычислить предельную
ошибку выборки,

т. е.
предельная ошибка выборки равна
t-кратному числу средних ошибок выборки.
Таким
образом, величина предельной ошибки
выборки может быть установлена с
определенной вероятностью. Как видно
из последней графы табл. 6.1, вероятность
появления ошибки равной или большей
утроенной средней ошибки выборки,
т. е.
![]()
крайне
мала и равна 0,003(1–0,997). Такие маловероятные
события считаются практически
невозможными, а потому величину
![]()
можно
принять за предел возможной ошибки
выборки.
Выборочное
наблюдение дает возможность определить
среднюю арифметическую выборочной
совокупности и величину предельной
ошибки этой средней, которая показывает
(с определенной вероятностью), насколько
выборочная величина может отличаться
от генеральной средней в большую или
меньшую сторону. Тогда величина
генеральной средней будет представлена
интервальной оценкой, для которой
нижняя граница будет равна

Интервал,
в который с данной степенью вероятности
будет заключена неизвестная величина
оцениваемого параметра, называют
доверительным,
а вероятность Р
– доверительной вероятностью.
Чаще всего доверительную вероятность
принимают равной 0,95 или 0,99, тогда
коэффициент доверия t
равен соответственно 1,96 и 2,58. Это
означает, что доверительный интервал
с заданной вероятностью заключает в
себе генеральную среднюю.
Наряду
с абсолютной величиной предельной
ошибки выборки рассчитывается и
относительная
ошибка
выборки, которая определяется как
процентное отношение предельной ошибки
выборки к соответствующей характеристике
выборочной совокупности:

Чем
больше величина предельной ошибки
выборки, тем больше величина доверительного
интервала и тем, следовательно, ниже
точность оценки. Средняя (стандартная)
ошибка выборки зависит от объема выборки
и степени вариации признака в генеральной
совокупности.
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
12.04.2015613.89 Кб24pr.doc
- #
- #
- #
- #
Что такое Стандартная формула ошибки?
Стандартная ошибка — это ошибка, которая возникает в распределении выборки при выполнении статистического анализа. Это вариант стандартного отклонения, так как оба понятия соответствуют мерам спреда. Высокая стандартная ошибка соответствует более высокому разбросу данных для взятой выборки. Вычисление формулы стандартной ошибки выполняется для выборки. В то же время стандартное отклонение определяет генеральную совокупность.
Оглавление
- Что такое Стандартная формула ошибки?
- Объяснение
- Пример формулы стандартной ошибки
- Калькулятор стандартной ошибки
- Актуальность и использование
- Стандартная формула ошибки в Excel
- Рекомендуемые статьи
Следовательно, стандартная ошибка среднего значения будет выражаться и определяться в соответствии с соотношением, описанным следующим образом:
σ͞x = σ/√n

Здесь,
- Стандартная ошибка, выраженная как σ͞x.
- Стандартное отклонение совокупности выражается как σ.
- Количество переменных в выборке, выраженное как n.
В статистическом анализе среднее значение, медиана и мода являются центральной тенденцией. Центральная тенденция Центральная тенденция — это статистическая мера, которая отображает центральную точку всего распределения данных, и вы можете найти ее с помощью 3 различных мер, т. е. среднего, медианы и моды.Подробнее меры. Стандартное отклонение, дисперсия и стандартная ошибка среднего классифицируются как меры изменчивости. Стандартная ошибка среднего для выборочных данных напрямую связана со стандартным отклонением большей совокупности и обратно пропорциональна или связана с квадратным корнем. число. Чтобы использовать эту функцию, введите термин =SQRT и нажмите клавишу табуляции, которая вызовет функцию SQRT. Более того, эта функция принимает один аргумент из нескольких переменных, используемых для создания выборки. Следовательно, если размер выборки Размер выборкиФормула размера выборки отображает соответствующий диапазон генеральной совокупности, в которой проводится эксперимент или опрос. Он измеряется с использованием размера генеральной совокупности, критического значения нормального распределения при требуемом доверительном уровне, доли выборки и предела погрешности. Если больше, то может быть равная вероятность того, что стандартная ошибка также будет большой.
Объяснение
Можно объяснить формулу для стандартной ошибки среднего, используя следующие шаги:
- Определите и организуйте выборку и определите количество переменных.
- Затем среднее значение выборки соответствует количеству переменных, присутствующих в выборке.
- Затем определите стандартное отклонение выборки.
- Затем определите квадратный корень из числа переменных, включенных в выборку.
- Теперь разделите стандартное отклонение, вычисленное на шаге 3, на полученное значение на шаге 4, чтобы получить стандартную ошибку.
Пример формулы стандартной ошибки
Ниже приведены примеры формул для расчета стандартной ошибки.
.free_excel_div{фон:#d9d9d9;размер шрифта:16px;радиус границы:7px;позиция:относительная;margin:30px;padding:25px 25px 25px 45px}.free_excel_div:before{content:»»;фон:url(центр центр без повтора #207245;ширина:70px;высота:70px;позиция:абсолютная;верх:50%;margin-top:-35px;слева:-35px;граница:5px сплошная #fff;граница-радиус:50%} Вы можете скачать этот шаблон стандартной формулы ошибки Excel здесь — Стандартная формула ошибки Шаблон Excel
Пример №1
Возьмем в качестве примера акции ABC. В течение 30 лет акции приносили средний долларовый доход в размере 45 долларов. Кроме того, было замечено, что акции приносят прибыль со стандартным отклонением в 2 доллара. Помогите инвестору рассчитать общую стандартную ошибку средней доходности, предлагаемой акцией ABC.
Решение:
- Стандартное отклонение (σ) = $2
- Количество лет (n) = 30
- Средняя доходность в долларах = 45 долларов.
Расчет стандартной ошибки выглядит следующим образом:

- σ͞x = σ/√n
- = 2 доллара США/√30
- = 2 доллара США / 5,4773
Стандартная ошибка,

- σx = 0,3651 доллара США
Таким образом, инвестиция предлагает инвестору стандартную долларовую ошибку в среднем 0,36515 доллара при удерживании позиции ABC в течение 30 лет. Однако, если бы акции сохранялись для более высокого инвестиционного горизонта, то стандартная ошибка среднего значения в долларах значительно уменьшилась бы.
Пример #2
Возьмем в качестве примера инвестора, который получил следующую доходность акций XYZ:
Год инвестиций Предлагаемая доходность120%225%35%410%
Помогите инвестору рассчитать общую стандартную ошибку средней доходности акций XYZ.
Решение:
Сначала определите среднее значение доходности, как показано ниже: –

- ͞X = (x1+x2+x3+x4)/количество лет
- = (20+25+5+10)/4
- =15%
Теперь определите стандартное отклонение доходности, как показано ниже: –

- σ = √ ((x1-͞X)2 + (x2-͞X)2 + (x3-͞X)2 + (x4-͞X)2) / √ (количество лет -1)
- = √ ((20-15) 2 + (25-15) 2 + (5-15) 2 + (10-15) 2) / √ (4-1)
- = (√ (5) 2 + (10) 2 + (-10) 2 + (-5) 2 ) / √ (3)
- = (√25+100+100+25)/ √ (3)
- =√250/√3
- =√83,3333
- «=» 9,1287%
Теперь вычисление стандартной ошибки выглядит следующим образом:

- σ͞x = σ/√n
- = 9,128709/√4
- = 9,128709/2
Стандартная ошибка,

- σx = 4,56%
Таким образом, инвестиции предлагают инвестору стандартную ошибку в долларах в среднем 4,56% при удержании позиции XYZ в течение 4 лет.
Калькулятор стандартной ошибки
Вы можете использовать следующий калькулятор.
.cal-tbl td{ верхняя граница: 0 !важно; }.cal-tbl tr{ высота строки: 0.5em; } Только экран @media и (минимальная ширина устройства: 320 пикселей) и (максимальная ширина устройства: 480 пикселей) { .cal-tbl tr{ line-height: 1em !important; } } σnСтандартная формула ошибки
Формула стандартной ошибки =σ =√n 0 = 0√0
Актуальность и использование
Стандартная ошибка имеет тенденцию быть высокой, если размер выборки для анализа мал. Следовательно, выборка всегда берется из большей совокупности, которая включает больший размер переменных. Это всегда помогает статистику определить достоверность среднего значения выборки относительно среднего значения генеральной совокупности.
Большая стандартная ошибка говорит статистику, что выборка неоднородна в отношении среднего значения генеральной совокупности. Относительно населения наблюдается большой разброс в выборке. Точно так же небольшая стандартная ошибка говорит статистику, что выборка однородна относительно среднего значения генеральной совокупности. Отсутствуют или незначительные различия в выборке относительно населения.
Не следует смешивать его со стандартным отклонением. Вместо этого следует рассчитать стандартное отклонение для всей совокупности. Стандартная ошибкаСтандартная ошибкаСтандартная ошибка (SE) — это метрика, которая измеряет точность выборочного распределения, обозначающего совокупность, с использованием стандартного отклонения. Другими словами, это мера дисперсии среднего значения выборки, связанная со средним значением генеральной совокупности, а не стандартное отклонение. С другой стороны, оно определяется для среднего значения выборки.
Стандартная формула ошибки в Excel
Теперь давайте возьмем пример Excel, чтобы проиллюстрировать концепцию стандартной формулы ошибки в шаблоне Excel ниже. Предположим, администрация школы хочет определить стандартную ошибку среднего значения роста футболистов.
Выборка состоит из следующих значений: –

Помогите администрации оценить стандартную ошибку среднего значения.
Шаг 1: Определите среднее значение, как показано ниже: –
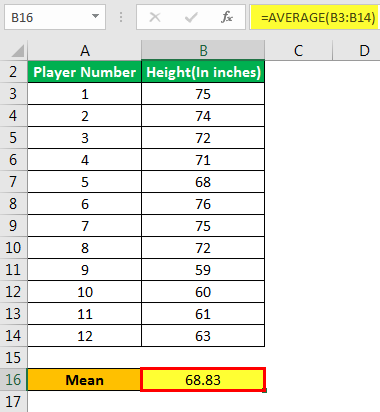
Шаг 2: Определите стандартное отклонение, как показано ниже: –

Шаг 3: Определите стандартную ошибку среднего значения, как показано ниже: –

Следовательно, стандартная ошибка среднего значения для футболистов составляет 1,846 дюйма. Руководство должно заметить, что оно значительно велико. Таким образом, выборочные данные, взятые для анализа, неоднородны и имеют большую дисперсию.
Руководству следует либо исключить более мелких игроков, либо добавить игроков значительно выше, чтобы сбалансировать средний рост футбольной команды, заменив их людьми с меньшим ростом по сравнению с их сверстниками.
Рекомендуемые статьи
Эта статья была руководством по формуле стандартной ошибки. Здесь мы обсуждаем формулу для расчета среднего значения, стандартную ошибку, примеры и загружаемый лист Excel. Вы можете узнать больше из следующих статей: –
- Формула рентабельности EBITDA
- Формула валовой прибыли
- Формула относительного стандартного отклонения
- Формула погрешности