
Copyright © 2023 Synology Inc. Все права защищены.
Положения и условия
|
Конфиденциальность
|
Настройки файлов cookie
|
Россия — Русский
Уважаемый Igr_ua
Благодарю за терпение и потраченное на меня время.
Пожалуйста 
Теперь к вопросам…
(пока собирался, на часть вопросов ответы уже дали)
Прежде всего внимательно изучаем содержимое файла /etc/fstab и содержимое файла /proc/mdstat. Если нужно, то записываем на листик исходные данные.
Из этих файлов вы узнаете много нужного в дальнейшем (пример содержимого файлов здесь
Проверка RAID разделов NAS на ошибки файловой системы
1. Останавливаем все сервисы
Как? Тупо из web интерфейса? Или есть какие-нибудь волшебные команды?
Да. Тупо из интерфейса.
2. Проверяем под каким номером RAID
mdadm -D /dev/md0 (md1, md2 и т.д.)
это мы уже узнали из файлов /etc/fstab и /proc/mdstat, но можно и проверить
2. Отмонтируем раздел
umount /volume1
Как определить правильно какую циферку ставить после volume? Если у меня в менеджере хранение написано «раздел 1» то и в этой команде тоже должно быть volume1?
Это тоже видно из тех же файлов.
Иногда может возникнуть ситуация, что раздел не захочет размонтироваться. Вроде бы и все сервисы остановили, пакеты отключили, но….
Тогда, заходим в терминал (через putty или кому как удобней) и смотрим активные процессы.
Это можно сделать с помощью команды Top либо ps.
после этого останавливаем процесс:
killall имя_процесса
3. Останавливаем RAID
mdadm -S /dev/md0
4. Проверяем раздел
e2fsck -f /dev/md0
если e2fsck отработала и вернула код «0» — значит все в порядке.
Запуск проверки раздела с автоматическим исправлением ошибок
e2fsck -p /dev/md0
да.
5. Монтируем раздел обратно
mount /dev/md0 /volume1
не получится, т.к. перед этим необходимо собрать массив
Create — создание RAID-массива из нескольких дисков (с суперблоком на каждом устройстве).
Assemble — сборка (ранее созданного) массива и его активация. Диски из которых собирается массив могут указываться явно или будет выполнен их автоматический поиск. mdadm проверяет, образуют ли компоненты корректный массив.
Пример:
mdadm —assemble -R —force /dev/md3 /dev/sdc3 /dev/sdd3
mdadm -Cf /dev/md2 -R -n 3 —level=linear /dev/sda3 /dev/sdb3 /dev/sdc3 /dev/sdd3 (это пример… не повторять буквально!!!!)
пример для массива JBOD — здесь — пункты 7-12
Вот после этого, когда собрали массив, монтируем его в систему.
6. Запустить все службы и программы на NAS
Как? И нужно ли? Может просто перезагрузить NAS?
Это зависит от того, какие цели вы преследуете.
Когда мне надо было вытаскивать данные, то я коробку не перегружал.
Если вам работать как обычно — лучше перегрузить (мало ли какие процессы вы пришибли вручную в п.2)
7. Перезагрузить NAS.
где-то так….
з.ы. про mdadm — тут
Осталось в заключении добавить, что все что вы делаете с собственным массивом, вы делаете на собственный страх и риск…
Всем привет!!!
Сегодня я расскажу как запускать тестирование SMART на жёстких дисках и чем отличается быстрый тест от расширенного.
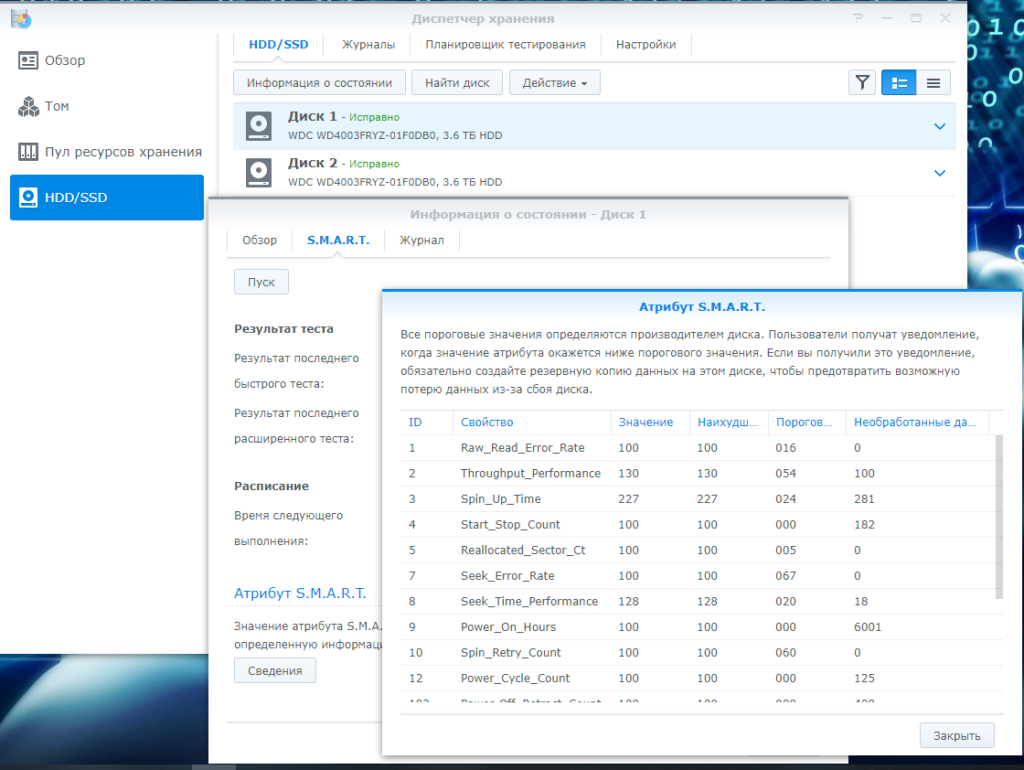
S.M.A.R.T. (от англ. self-monitoring, analysis and reporting technology — технология самоконтроля, анализа и отчётности) — технология оценки состояния жёсткого диска встроенной аппаратурой самодиагностики, а также механизм предсказания времени выхода его из строя. Технология S.M.A.R.T. является частью протоколов ATA и SATA.
S.M.A.R.T. — Википедия (wikipedia.org)
Я в этой статье не буду рассказывать про параметры SMART, что они означают и что делать, если что-то не так. На этот счет в интернете много всяких статей и авторов, которые разбираются в этом точно лучше меня. Я расскажу и акцентирую внимание на тестах SMART, которыми большая часть людей пренебрегает и как оказалось напрасно.
Давайте рассмотрим страшный сон любого владельца NAS сервера, это когда у вас сдыхает диск без резервирования. Ну например на нем система фиксирует битые сектора.


Что делать в этой ситуации понятно, пытаться копировать с диска уцелевшие данные и менять на новый. Да, наверняка есть возможность как-то проигнорировать или даже исправить повреждение, но во первых это только начало диск уже начал сыпаться, а во вторых в этой статья я выбрал другую тему.
И тут возникает вопрос, почему мониторинг SMART этого не показал заранее, что бы более безболезненно заранее исправить проблему. А все дело в том, как работает этот мониторинг. Во время работы диска информация считывается и записывается и если данные попадают на битый сектор, то в дело вступает смарт. Сначала блок помечается как битый и переносится в область SMART, а если эта область заканчивается, то просто помечается как битый. Естественно в этих случаях мы увидим в мониторинге SMART рост количества битых секторов.
А что если обращения к битому сектору не было? А ничего и не будет, никто не узнает, что он битый и этой информации по понятным причинам не будет в мониторинге SMART. Вот так, смарт чистый, а сектора битые есть. Но разработчики SMART не глупые люди, они предусмотрели такой вариант. Для таких ситуаций придуманы тесты SMART:
- Короткий (Short) – Проверяет электрические и механические параметры, а также производительность на чтение. Тест, как правило, длится около двух минут.
- Длинный/расширенный (Long/extended) – Тест проверяет всю поверхность диска и не имеет ограничения по времени. В среднем занимает около двух-трёх часов.
- Тест транспортировки (Conveyance) – Быстрый тест, предназначенный для оценки состояния диска после транспортировки диска от производителя к поставщику.
- Выборочный (Selective) – Некоторые диски позволяют проверить определённую часть поверхности.
Получается, что бы найти битый сектор на диске нужно выполнить проверку поверхности диска, а это расширенный тест SMART.
В Synology нам доступно два теста SMART называются они быстрый и расширенный:

В общем говоря всегда можно зайти и запустить эти тесты вручную. Но Synology продумали и этот вариант. Эти тесты можно запускать по расписанию
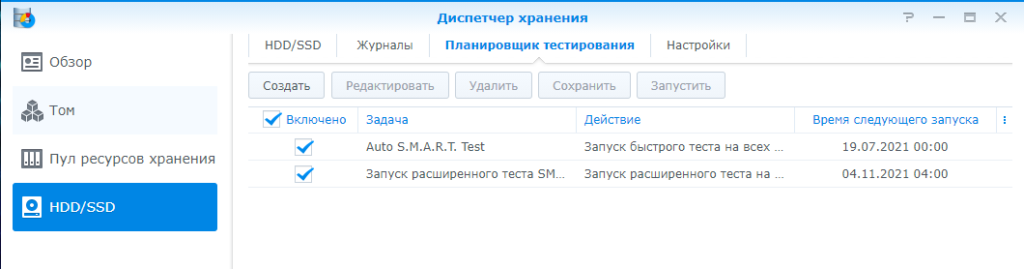
По умолчанию включен только быстрый тест, а расширенный нужно настроить самому
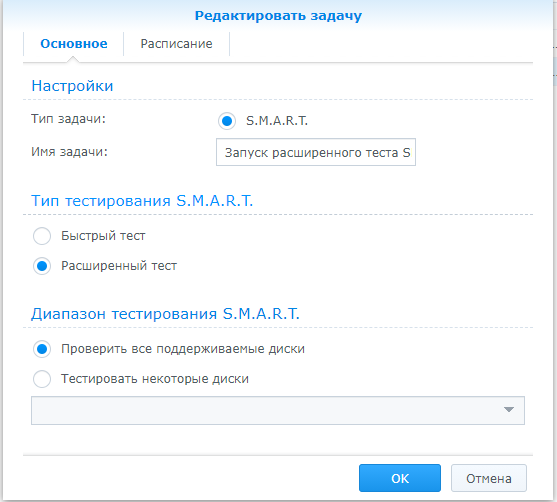
Ну как и везде есть не только плюсы, но и минусы. Если быстрый тест делается 2-3 минуты, то расширенный тест у меня на 4Т диске длился 4-6 часов, я просто сбился с подсчета времени, может и все 8, так это долго было. Но минус не в этом, а в том, что во время расширенного теста очень сильно падает производительность диска и все тормозит жутко. По этой причине расширенный тест лучше запускать на ночь или на выходные, когда NAS загружен минимум.
Что касается частоты запуска этих тестов, то тут вопрос щепетильный, ответ на который может дать только сам администратор NAS. Как часто и какой тест делать решаете только вы сами, так как факторов очень много. Я для себя для дома выбрал такую стратегию: раз в месяц я делаю быстрый тест SMART, а раз в полгода расширенный.
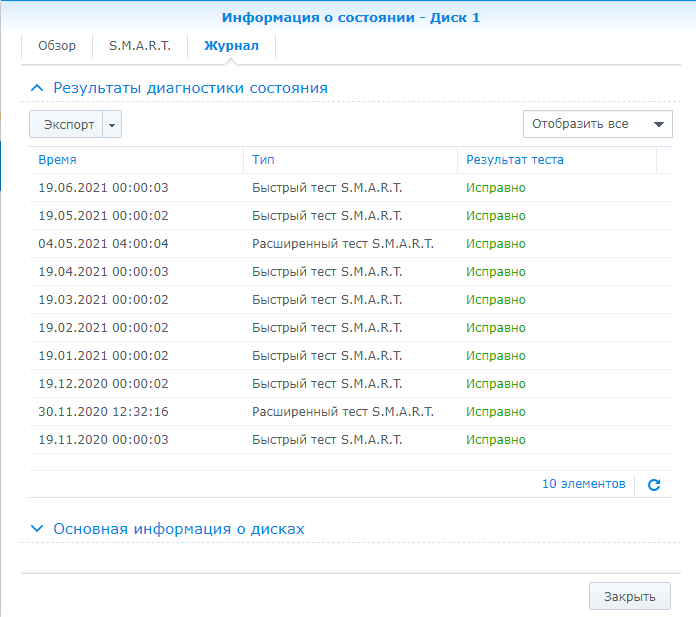
Берегите свои данные, настраивайте тестирование SMART по расписанию и делайте своевременно резервные копии и все будет хорошо!!!! Желаю всем удачи!!!!
Ну и в на последок хотел поделиться справкой, как можно заставить работать диск игнорируя предупреждения:
Изменение состояния предупреждения о проблемах на диске
Система непрерывно отслеживает состояние дисков и выдает предупреждения при обнаружении проблем. Некоторые проблемы могут быть серьезнее других. При возникновении определенных проблем, которые приводят к состоянию Предупреждение (выберите диск и нажмите Информация о состоянии > Обзор), можно изменить настройки отображения предупреждения. Для этого выполните следующие действия.
- Обратите внимание, что предупреждение о диске указывает на возникновение проблем с диском. Игнорирование такого предупреждения может привести к потере данных.
- Перейдите на страницу HDD/SSD и выберите диск в состоянии предупреждения.
- Нажмите Предупреждение об изменении диска.
- Нажмите пункт Скрытие предупреждения или Отключение предупреждения (в зависимости от типа проблемы могут отображаться два параметра):
- Скрытие предупреждения. Отслеживание поля с проблемными показателями продолжит выполняться, однако предупреждения будут инициироваться только в случае ухудшения показателей.
- Отключение предупреждения. Отслеживание поля S.M.A.R.T. будет навсегда отключено.
Примечание.
- Рекомендуется скрывать и отключать предупреждение о диске, только если вы понимаете, что рискуете потерять данные.
- Изменение состояния предупреждения о проблемах на диске не устраняет возникшие на диске проблемы, а также не исключает возможность их повторного возникновения в будущем, поэтому данное действие не должно рассматриваться как долгосрочное решение.
- Некоторые поля S.M.A.R.T. изначально являются критически важными и не могут быть скрыты или отключены.
- Для определенных атрибутов S.M.A.R.T. предупреждение отображается при снижении значения атрибута S.M.A.R.T. ниже наименьшего значения, заданного производителем диска. В раскрывающемся меню Скрыть предупреждение о диске эти атрибуты представлены в виде сообщения «Ранее произошел сбой атрибута S.M.A.R.T. (#ID)».
HDD/SSD | DSM – Центр знаний Synology
Уважаемый Igr_ua
Благодарю за терпение и потраченное на меня время.
Пожалуйста
Теперь к вопросам…
(пока собирался, на часть вопросов ответы уже дали)
Прежде всего внимательно изучаем содержимое файла /etc/fstab и содержимое файла /proc/mdstat. Если нужно, то записываем на листик исходные данные.
Из этих файлов вы узнаете много нужного в дальнейшем (пример содержимого файлов здесь
Проверка RAID разделов NAS на ошибки файловой системы
1. Останавливаем все сервисы
Как? Тупо из web интерфейса? Или есть какие-нибудь волшебные команды?
Да. Тупо из интерфейса.
2. Проверяем под каким номером RAID
mdadm -D /dev/md0 (md1, md2 и т.д.)
это мы уже узнали из файлов /etc/fstab и /proc/mdstat, но можно и проверить
2. Отмонтируем раздел
umount /volume1
Как определить правильно какую циферку ставить после volume? Если у меня в менеджере хранение написано «раздел 1» то и в этой команде тоже должно быть volume1?
Это тоже видно из тех же файлов.
Иногда может возникнуть ситуация, что раздел не захочет размонтироваться. Вроде бы и все сервисы остановили, пакеты отключили, но….
Тогда, заходим в терминал (через putty или кому как удобней) и смотрим активные процессы.
Это можно сделать с помощью команды Top либо ps.
после этого останавливаем процесс:
killall имя_процесса
3. Останавливаем RAID
mdadm -S /dev/md0
4. Проверяем раздел
e2fsck -f /dev/md0
если e2fsck отработала и вернула код «0» — значит все в порядке.
Запуск проверки раздела с автоматическим исправлением ошибок
e2fsck -p /dev/md0
да.
5. Монтируем раздел обратно
mount /dev/md0 /volume1
не получится, т.к. перед этим необходимо собрать массив
Create — создание RAID-массива из нескольких дисков (с суперблоком на каждом устройстве).
Assemble — сборка (ранее созданного) массива и его активация. Диски из которых собирается массив могут указываться явно или будет выполнен их автоматический поиск. mdadm проверяет, образуют ли компоненты корректный массив.
Пример:
mdadm —assemble -R —force /dev/md3 /dev/sdc3 /dev/sdd3
mdadm -Cf /dev/md2 -R -n 3 —level=linear /dev/sda3 /dev/sdb3 /dev/sdc3 /dev/sdd3 (это пример… не повторять буквально!!!!)
пример для массива JBOD — здесь — пункты 7-12
Вот после этого, когда собрали массив, монтируем его в систему.
6. Запустить все службы и программы на NAS
Как? И нужно ли? Может просто перезагрузить NAS?
Это зависит от того, какие цели вы преследуете.
Когда мне надо было вытаскивать данные, то я коробку не перегружал.
Если вам работать как обычно — лучше перегрузить (мало ли какие процессы вы пришибли вручную в п.2)
7. Перезагрузить NAS.
где-то так….
з.ы. про mdadm — тут
Осталось в заключении добавить, что все что вы делаете с собственным массивом, вы делаете на собственный страх и риск…
Как сказал Daxlerod, вам следует использовать инструменты SMART, однако вам также необходимо выполнить то, что называется очисткой данных.
Если вы еще этого не сделали, создайте группу дисков. Чтобы очистка данных была доступна, вам нужно как минимум 3 диска, по крайней мере, 1 резервный диск и как минимум 2 диска с данными. Подождите, пока группа дисков полностью синхронизируется, затем выполните очистку данных.
Начиная с версии Synology OS v4.2, очистка данных доступна из
Storage Manager -> Disk Group -> Manage -> Start data scrubbing
Это займет часы, поскольку он читает все сектора всех дисков и выполняет некоторые математические операции, чтобы увидеть, правильно ли складываются данные контрольной суммы. Вы можете использовать NAS, пока это происходит, но это будет немного медленнее. Многие люди запускают очистку данных раз в месяц. Лично я выполняю очистку данных один раз в неделю, а рабочую — в выходные, а домашнюю — в течение недели, пока я на работе.
Есть хорошая статья под названием Scrub Synology RAID-диски, в которой также рассказывается, как запустить средство проверки файловой системы, называемое fsck, даже если в веб-интерфейсе для этого нет опции.
Изменить: вышеуказанная страница, кажется, ушел, но в основном сказал
Команды для выполнения автономного fsck:
syno_poweroff_task fsck.ext4 -pvf /dev/vg[x]/volume_[y]Задача отключения питания выполняет некоторые размонтирования (том 1 и т.д.). Затем вы выполняете обычный Linux fsck.
Однако, читая еще несколько страниц, таких как https://forum.synology.com/enu/viewtopic.php?f=39&t=83186 и http://www.cyberciti.biz/faq/synology-complete-fsck-file-system- check-command/ кажется, что они изменились в DSM 5+. Кто-то предлагает использовать опцию -d (отладка) в задаче выключения, например
syno_poweroff_task -d
В то время как сайт киберцити предлагает использовать lsof, чтобы найти то, что использует том, используйте сценарии отключения службы в /usr/syno/etc/rc.d/ перед использованием команды umount .
Обратите внимание, что все это требует, чтобы вы вошли в окно NAS, если вам не нравится командная строка linux, а затем, возможно, сделайте запрос в Synology, чтобы добавить кнопку fsck в веб-интерфейс.

Руководство пользователя Synology NAS
Под управлением DSM 6.2
32 Глава 5: Управление объемом хранения
SSD TRIM
Если том состоит только из SSD (твердотельных накопителей), рекомендуется включить SSD TRIM.
Данная функция позволяет повысить скорость чтения и записи томов, созданных на SSD, что позволит
повысить эффективность и срок службы SSD.
Перед настройкой SSD TRIM ознакомьтесь с подробными инструкциями и дополнительными
ограничениями в
Справке DSM
.
Примечание.
Функция SSD TRIM доступна только на некоторых моделях Synology NAS и типах RAID.
Некоторые модели SSD не поддерживают выполнение SSD TRIM на томах RAID 5 и RAID 6. См. список
совместимости на веб-сайте
www.synology.com
.
Управление жесткими дисками
На вкладке
HDD/SSD
можно отслеживать состояние жестких дисков, установленных в Synology NAS, а
также организовывать и анализировать производительность и состояние дисков. Чтобы открыть эту
вкладку, выберите
Диспетчер хранения
и нажмите
HDD/SSD
. Для получения дополнительных
инструкций см.
Справку DSM
.
Включение поддержки записи в кэш
Включение поддержки записи в кэш повышает производительность Synology NAS. Эта функция
поддерживается только для некоторых моделей жестких дисков. Для обеспечения защиты данных при
поддержке записи в кэш настоятельно рекомендуется использовать устройство ИБП. Также
рекомендуется правильно выключать систему после каждого использования. Отключение записи в кэш
уменьшит вероятность потери данных при сбое питания, но сократит производительность.
Запуск тестов S.M.A.R.T.
Тесты S.M.A.R.T. для дисков изучают жесткий диск и сообщают о его состоянии, предупреждая о
возможных сбоях диска. При обнаружении ошибок рекомендуется сразу заменить диск. Также можно
запланировать автоматическое выполнение тестов S.M.A.R.T., создав задачи.
Проверка информации о диске
В разделе
Диспетчер хранения
>
HDD/SSD
>
HDD/SSD
нажмите стрелку вниз рядом с именем жесткого
диска, чтобы просмотреть название модели, серийный номер, версию микропрограммы и общий размер
жесткого диска.
Кэш SSD
Диски с кэшем SSD
1
можно установить и монтировать в конфигурации только для чтения (RAID 0) или
чтения-записи (RAID 1, RAID 5, RAID 6), чтобы увеличить скорость чтения и записи для тома. В разделе
Диспетчер хранения
>
Кэш SSD
можно создать кэш и просмотреть информацию о нем.
Сведения об установке SSD см. в Руководстве по установке оборудования для вашей модели Synology
NAS. Для получения дополнительных сведений об управлении SSD см.
Справку DSM
или
Техническую
документацию по кэшу SSD Synology
.
———
1
Кэш SSD поддерживается только в некоторых моделях. Для получения дополнительной информации посетите
страницу
www.synology.com
.
How to properly do a filesystem check (fsck or e2fck) on Synology DSM 6.0 e.g. DS414
I tried a lot of instructions and tutorials to do a file system check on a Synology DSM 6 device e.g the DS414.
The first step involves unmounting the partition you want to check e.g. the /volumes/ path before you can file system check it.
All the instructions I found are inaccurate, too old (most are for DSM 4 or 5), do not work or a dangerous. I just could not get the unmounting to work!
Presteps are install ipckg using instructions found here: https://github.com/basmussen/ds414-boostrap-dsm5
then install the packages less, lsof, mlocate
E.g. the common advice:
shuts down all services including telnet and the web interface etc. but it also shutsdown my ssh server and the webserver making the box completely inaccessible while still powered on -> you need to hard reset the box
the other common advice to just do a
and then kill the PID of the processes using the volume. Problem with this is that most services are watched by the system so if you kill them, they just restart again after a sec.
Here is my solution:
Get the list of services associated with your volume you want to fs check:
Or make the list more clear with:
lsof /volume1/ | sed 1d | cut -d" " -f1 | sort | uniq
e.g.
anvil
ash
cnid_dbd
cut
dovecot
img_backu
log
master
php56-fpm
pickup
postgres
qmgr
s2s_daemo
sed
sh
sort
syno_mail
afpd
cnid
If you are a bit into Linux you can spot/group these services into categories:
php5/httpd/apache2/nginx = searchterms httpd,nginx
postgres = searchterms postgres
dovecot/syno_mail = searchterm mail
...
to generally find services by name use the following syntax
find /usr/syno/etc.defaults/rc.sysv/ | grep -i <service name>
synoservicecfg --status | grep enable | grep -i <service name>
e.g.
find /usr/syno/etc.defaults/rc.sysv/ | grep -i postgres
synoservicecfg --status | grep enable | grep -i nginx
So my approach was to spot a service which sounds promising, stop it and then run
lsof /volume1/ | sed 1d | cut -d" " -f1 | sort | uniq to see if this service vanishes from the list.
So all in all I found the following services which I had to stop.
shutdown postgres — postgesql
/usr/syno/etc.defaults/rc.sysv/pgsql.sh stop
stop php5
synoservicecfg --stop pkgctl-PHP5.6
shutdown Mailserver
synoservicecfg --stop pkgctl-MailServer
shutdown backups (img_backu)
synoservicecfg --stop synobackupd
synoservicecfg --stop pkgctl-HyperBackupVault
synoservicecfg --stop pkgctl-synobackupd
synoservicecfg --stop pkgctl-HyperBackup
synoservicecfg --stop pkgctl-HyperBackupVault
synoservicecfg --stop pkgctl-TimeBackup
shutdown s2sdaemon
synoservicecfg --stop s2s_daemon
others: afp and cnid_dbd
Since I could not find any service definition file for those I simply killed the processes using good old kill command, which did not restart luckily within a minute or so.
disconnect the system user
now the last thing what was still in the list were some user cwd processes connected, as the /home folder was part of the /volumes1 folder:
sh 8480 Oli cwd DIR 253,1 4096 154796037 /volume1/homes/Oli
sudo 9104 root cwd DIR 253,1 4096 154796037 /volume1/homes/Oli
ash 9105 root cwd DIR 253,1 4096 154796037 /volume1/homes/Oli
lsof 9209 root cwd DIR 253,1 4096 154796037 /volume1/homes/Oli
lsof 9209 root txt REG 253,1 125544 369233175 /opt/sbin/lsof
lsof 9210 root cwd DIR 253,1 4096 154796037 /volume1/homes/Oli
lsof 9210 root txt REG 253,1 125544 369233175 /opt/sbin/lsof
Solution here was to logout your user and login the true root user using sshthen you can finally umount those beasts:
umount /opt
umount /volume1
then finally run your fsck diagnostic etc.
fsck.ext4 -fv /dev/mapper/vol1-origin
done!
Как сказал Daxlerod, вам следует использовать инструменты SMART, однако вам также необходимо выполнить то, что называется очисткой данных.
Если вы еще этого не сделали, создайте группу дисков. Чтобы очистка данных была доступна, вам нужно как минимум 3 диска, по крайней мере, 1 резервный диск и как минимум 2 диска с данными. Подождите, пока группа дисков полностью синхронизируется, затем выполните очистку данных.
Начиная с версии Synology OS v4.2, очистка данных доступна из
Storage Manager -> Disk Group -> Manage -> Start data scrubbing
Это займет часы, поскольку он читает все сектора всех дисков и выполняет некоторые математические операции, чтобы увидеть, правильно ли складываются данные контрольной суммы. Вы можете использовать NAS, пока это происходит, но это будет немного медленнее. Многие люди запускают очистку данных раз в месяц. Лично я выполняю очистку данных один раз в неделю, а рабочую — в выходные, а домашнюю — в течение недели, пока я на работе.
Есть хорошая статья под названием Scrub Synology RAID-диски, в которой также рассказывается, как запустить средство проверки файловой системы, называемое fsck, даже если в веб-интерфейсе для этого нет опции.
Изменить: вышеуказанная страница, кажется, ушел, но в основном сказал
Команды для выполнения автономного fsck:
syno_poweroff_task fsck.ext4 -pvf /dev/vg[x]/volume_[y]Задача отключения питания выполняет некоторые размонтирования (том 1 и т.д.). Затем вы выполняете обычный Linux fsck.
Однако, читая еще несколько страниц, таких как https://forum.synology.com/enu/viewtopic.php?f=39&t=83186 и http://www.cyberciti.biz/faq/synology-complete-fsck-file-system- check-command/ кажется, что они изменились в DSM 5+. Кто-то предлагает использовать опцию -d (отладка) в задаче выключения, например
syno_poweroff_task -d
В то время как сайт киберцити предлагает использовать lsof, чтобы найти то, что использует том, используйте сценарии отключения службы в /usr/syno/etc/rc.d/ перед использованием команды umount .
Обратите внимание, что все это требует, чтобы вы вошли в окно NAS, если вам не нравится командная строка linux, а затем, возможно, сделайте запрос в Synology, чтобы добавить кнопку fsck в веб-интерфейс.