
11.2. Оценка результатов выборочного наблюдения
11.2.1. Средняя и предельная ошибки выборки. Построение доверительных границ для средней и доли
Средняя ошибка выборки показывает, насколько отклоняется в среднем параметр выборочной совокупности от соответствующего параметра генеральной. Если рассчитать среднюю из ошибок всех возможных выборок определенного вида заданного объема (n), извлеченных из одной и той же генеральной совокупности, то получим их обобщающую характеристику — среднюю ошибку выборки ( ).
).
В теории выборочного наблюдения выведены формулы для определения , которые индивидуальны для разных способов отбора (повторного и бесповторного), типов используемых выборок и видов оцениваемых статистических показателей.
Например, если применяется повторная собственно случайная выборка, то определяется как:
 — при оценивании среднего значения признака;
— при оценивании среднего значения признака;
 — если признак альтернативный, и оценивается доля.
— если признак альтернативный, и оценивается доля.
При бесповторном собственно случайном отборе в формулы вносится поправка (1 — n/N):
 — для среднего значения признака;
— для среднего значения признака;
 — для доли.
— для доли.
Вероятность получения именно такой величины ошибки всегда равна 0,683. На практике же предпочитают получать данные с большей вероятностью, но это приводит к возрастанию величины ошибки выборки.
Предельная ошибка выборки ( ) равна t-кратному числу средних ошибок выборки (в теории выборки принято коэффициент t называть коэффициентом доверия):
) равна t-кратному числу средних ошибок выборки (в теории выборки принято коэффициент t называть коэффициентом доверия):
 .
.
Если ошибку выборки увеличить в два раза (t = 2), то получим гораздо большую вероятность того, что она не превысит определенного предела (в нашем случае — двойной средней ошибки) — 0,954. Если взять t = 3, то доверительная вероятность составит 0,997 — практически достоверность.
Уровень предельной ошибки выборки зависит от следующих факторов:
- степени вариации единиц генеральной совокупности;
- объема выборки;
- выбранных схем отбора (бесповторный отбор дает меньшую величину ошибки);
- уровня доверительной вероятности.
Если объем выборки больше 30, то значение t определяется по таблице нормального распределения, если меньше — по таблице распределения Стьюдента.
Приведем некоторые значения коэффициента доверия из таблицы нормального распределения.
| Значение доверительной вероятности P | 0,683 | 0,954 | 0,997 |
|---|---|---|---|
| Значение коэффициента доверия t | 1,0 | 2,0 | 3,0 |
Доверительный интервал для среднего значения признака и для доли в генеральной совокупности устанавливается следующим образом:

Итак, определение границ генеральной средней и доли состоит из следующих этапов:
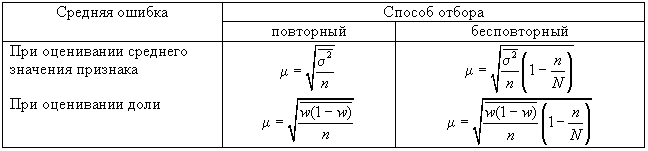
Ошибки выборки при различных видах отбора
- Собственно случайная и механическая выборка. Средняя ошибка собственно случайной и механической выборки находятся по формулам, представленным в табл. 11.3.
 |
|
где |
Пример 11.2. Для изучения уровня фондоотдачи было проведено выборочное обследование 90 предприятий из 225 методом случайной повторной выборки, в результате которого получены данные, представленные в таблице.
| Уровень фондоотдачи, руб. | До 1,4 | 1,4-1,6 | 1,6-1,8 | 1,8-2,0 | 2,0-2,2 | 2,2 и выше | Итого |
|---|---|---|---|---|---|---|---|
| Количество предприятий | 13 | 15 | 17 | 15 | 16 | 14 | 90 |
В рассматриваемом примере имеем 40%-ную выборку (90 : 225 = 0,4, или 40%). Определим ее предельную ошибку и границы для среднего значения признака в генеральной совокупности по шагам алгоритма:
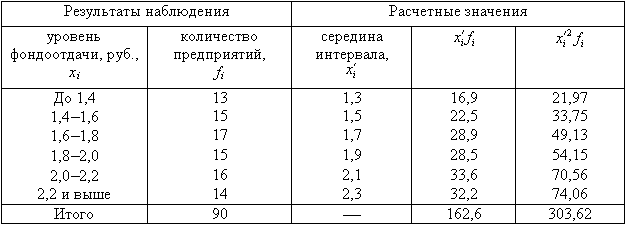
- По результатам выборочного обследования рассчитаем среднее значение и дисперсию в выборочной совокупности:
| Результаты наблюдения | Расчетные значения | |||
|---|---|---|---|---|
| уровень фондоотдачи, руб., xi | количество предприятий, fi | середина интервала, xixb4 | xixb4fi | xixb42fi |
| До 1,4 | 13 | 1,3 | 16,9 | 21,97 |
| 1,4-1,6 | 15 | 1,5 | 22,5 | 33,75 |
| 1,6-1,8 | 17 | 1,7 | 28,9 | 49,13 |
| 1,8-2,0 | 15 | 1,9 | 28,5 | 54,15 |
| 2,0-2,2 | 16 | 2,1 | 33,6 | 70,56 |
| 2,2 и выше | 14 | 2,3 | 32,2 | 74,06 |
| Итого | 90 | — | 162,6 | 303,62 |
Выборочная средняя

Выборочная дисперсия изучаемого признака

- Определяем среднюю ошибку повторной случайной выборки

- Зададим вероятность, на уровне которой будем говорить о величине предельной ошибки выборки. Чаще всего она принимается равной 0,999; 0,997; 0,954.

Для наших данных определим предельную ошибку выборки, например, с вероятностью 0,954. По таблице значений вероятности функции нормального распределения (см. выдержку из нее, приведенную в Приложении 1) находим величину коэффициента доверия t, соответствующего вероятности 0,954. При вероятности 0,954 коэффициент t равен 2.
- Предельная ошибка выборки с вероятностью 0,954 равна
- Найдем доверительные границы для среднего значения уровня фондоотдачи в генеральной совокупности


Таким образом, в 954 случаях из 1000 среднее значение фондоотдачи будет не выше 1,88 руб. и не ниже 1,74 руб.
Выше была использована повторная схема случайного отбора. Посмотрим, изменятся ли результаты обследования, если предположить, что отбор осуществлялся по схеме бесповторного отбора. В этом случае расчет средней ошибки проводится по формуле

Тогда при вероятности равной 0,954 величина предельной ошибки выборки составит:

Доверительные границы для среднего значения признака при бесповторном случайном отборе будут иметь следующие значения:

Сравнив результаты двух схем отбора, можно сделать вывод о том, что применение бесповторной случайной выборки дает более точные результаты по сравнению с применением повторного отбора при одной и той же доверительной вероятности. При этом, чем больше объем выборки, тем существеннее сужаются границы значений средней при переходе от одной схемы отбора к другой.
По данным примера определим, в каких границах находится доля предприятий с уровнем фондоотдачи, не превышающим значения 2,0 руб., в генеральной совокупности:
- рассчитаем выборочную долю.
Количество предприятий в выборке с уровнем фондоотдачи, не превышающим значения 2,0 руб., составляет 60 единиц. Тогда
m = 60, n = 90, w = m/n = 60 : 90 = 0,667;
- рассчитаем дисперсию доли в выборочной совокупности
 ;
;
- средняя ошибка выборки при использовании повторной схемы отбора составит

Если предположить, что была использована бесповторная схема отбора, то средняя ошибка выборки с учетом поправки на конечность совокупности составит

- зададим доверительную вероятность и определим предельную ошибку выборки.
При значении вероятности Р = 0,997 по таблице нормального распределения получаем значение для коэффициента доверия t = 3 (см. выдержку из нее, приведенную в Приложении 1):

- установим границы для генеральной доли с вероятностью 0,997:

Таким образом, с вероятностью 0,997 можно утверждать, что в генеральной совокупности доля предприятий с уровнем фондоотдачи, не превышающим значения 2,0 руб., не меньше, чем 54,7%, и не больше 78,7%.
- Типическая выборка. При типической выборке генеральная совокупность объектов разбита на k групп, тогда
N1 + N2 + … + Ni + … + Nk = N.
Объем извлекаемых из каждой типической группы единиц зависит от принятого способа отбора; их общее количество образует необходимый объем выборки
n1 + n2 + … + ni + … + nk = n.
Существуют следующие два способа организации отбора внутри типической группы: пропорциональной объему типических групп и пропорциональной степени колеблемости значений признака у единиц наблюдения в группах. Рассмотрим первый из них, как наиболее часто используемый.
Отбор, пропорциональный объему типических групп, предполагает, что в каждой из них будет отобрано следующее число единиц совокупности:
n = ni · Ni/N
где ni — количество извлекаемых единиц для выборки из i-й типической группы;
n — общий объем выборки;
Ni — количество единиц генеральной совокупности, составивших i-ю типическую группу;
N — общее количество единиц генеральной совокупности.
Отбор единиц внутри групп происходит в виде случайной или механической выборки.
Формулы для оценивания средней ошибки выборки для среднего и доли представлены в табл. 11.6.

|
 ) при использовании типического отбора, пропорционального объему типических групп
) при использовании типического отбора, пропорционального объему типических группЗдесь  — средняя из групповых дисперсий типических групп.
— средняя из групповых дисперсий типических групп.
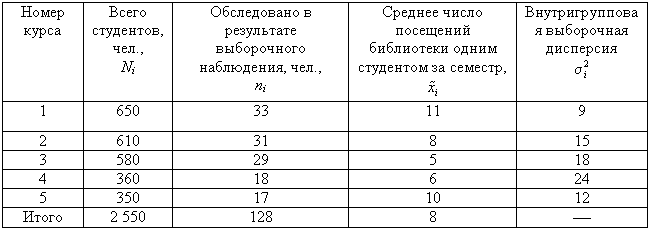
Пример 11.3. В одном из московских вузов проведено выборочное обследование студентов с целью определения показателя средней посещаемости вузовской библиотеки одним студентом за семестр. Для этого была использована 5%-ная бесповторная типическая выборка, типические группы которой соответствуют номеру курса. При отборе, пропорциональном объему типических групп, получены следующие данные:
| Номер курса | Всего студентов, чел., Ni | Обследовано в результате выборочного наблюдения, чел., ni | Среднее число посещений библиотеки одним студентом за семестр, xi | Внутригрупповая выборочная дисперсия, 
|
|---|---|---|---|---|
| 1 | 650 | 33 | 11 | 6 |
| 2 | 610 | 31 | 8 | 15 |
| 3 | 580 | 29 | 5 | 18 |
| 4 | 360 | 18 | 6 | 24 |
| 5 | 350 | 17 | 10 | 12 |
| Итого | 2 550 | 128 | 8 | — |
Число студентов, которое необходимо обследовать на каждом курсе, рассчитаем следующим образом:
- общий объем выборочной совокупности:
n = 2550/130*5 =128 (чел.);
- количество единиц, отобранных из каждой типической группы:

аналогично для других групп:
n2 = 31 (чел.);
n3 = 29 (чел.);
n4 = 18 (чел.);
n5 = 17 (чел.).
Проведем необходимые расчеты.
- Выборочная средняя, исходя из значений средних типических групп, составит:
- Средняя из внутригрупповых дисперсий
- Средняя ошибка выборки:
С вероятностью 0,954 находим предельную ошибку выборки:
- Доверительные границы для среднего значения признака в генеральной совокупности:





Таким образом, с вероятностью 0,954 можно утверждать, что один студент за семестр посещает вузовскую библиотеку в среднем от семи до девяти раз.
- Малая выборка. В связи с небольшим объемом выборочной совокупности те формулы для определения ошибок выборки, которые использовались нами ранее при «больших» выборках, становятся неподходящими и требуют корректировки.
Среднюю ошибку малой выборки определяют по формуле

Предельная ошибка малой выборки:

Распределение значений выборочных средних всегда имеет нормальный закон распределения (или приближается к нему) при п > 100, независимо от характера распределения генеральной совокупности. Однако в случае малых выборок действует иной закон распределения — распределение Стьюдента. В этом случае коэффициент доверия находится по таблице t-распределения Стьюдента в зависимости от величины доверительной вероятности Р и объема выборки п. В Приложении 1 приводится фрагмент таблицы t-распределения Стьюдента, представленной в виде зависимости доверительной вероятности от объема выборки и коэффициента доверия t.
Пример 11.4. Предположим, что выборочное обследование восьми студентов академии показало, что на подготовку к контрольной работе по статистике они затратили следующее количество часов: 8,5; 8,0; 7,8; 9,0; 7,2; 6,2; 8,4; 6,6.
Оценим выборочные средние затраты времени и построим доверительный интервал для среднего значения признака в генеральной совокупности, приняв доверительную вероятность равной 0,95.
- Среднее значение признака в выборке равно
- Значение среднего квадратического отклонения составляет
- Средняя ошибка выборки:
- Значение коэффициента доверия t = 2,365 для п = 8 и Р = 0,95 .
- Предельная ошибка выборки:
- Доверительный интервал для среднего значения признака в генеральной совокупности:





То есть с вероятностью 0,95 можно утверждать, что затраты времени студента на подготовку к контрольной работе находятся в пределах от 6,9 до 8,5 ч.
11.2.2. Определение численности выборочной совокупности
Перед непосредственным проведением выборочного наблюдения всегда решается вопрос, сколько единиц исследуемой совокупности необходимо отобрать для обследования. Формулы для определения численности выборки выводят из формул предельных ошибок выборки в соответствии со следующими исходными положениями (табл. 11.7):
- вид предполагаемой выборки;
- способ отбора (повторный или бесповторный);
- выбор оцениваемого параметра (среднего значения признака или доли).
Кроме того, следует заранее определиться со значением доверительной вероятности, устраивающей потребителя информации, и с размером допустимой предельной ошибки выборки.
 |
Примечание: при использовании приведенных в таблице формул рекомендуется получаемую численность выборки округлять в большую сторону для обеспечения некоторого запаса в точности.
Пример 11.5. Рассчитаем, сколько из 507 промышленных предприятий следует проверить налоговой инспекции, чтобы с вероятностью 0,997 определить долю предприятий с нарушениями в уплате налогов. По данным прошлого аналогичного обследования величина среднего квадратического отклонения составила 0,15; размер ошибки выборки предполагается получить не выше, чем 0,05.
При использовании повторного случайного отбора следует проверить

При бесповторном случайном отборе потребуется проверить

Как видим, использование бесповторного отбора позволяет проводить обследование гораздо меньшего числа объектов.
Пример 11.6. Планируется провести обследование заработной платы на предприятиях отрасли методом случайного бесповторного отбора. Какова должна быть численность выборочной совокупности, если на момент обследования в отрасли число занятых составляло 100 000 чел.? Предельная ошибка выборки не должна превышать 100 руб. с вероятностью 0,954. По результатам предыдущих обследований заработной платы в отрасли известно, что среднее квадратическое отклонение составляет 500 руб.

Следовательно, для решения поставленной задачи необходимо включить в выборку не менее 100 человек.
уголовных дел или средний срок лишения свободы, постольку возникает вопрос, насколько эта средняя (средний размер) типична или показательна, т.е. насколько правильно и точно характеризует средняя данную совокупность по изучаемому признаку? Для ответа на этот вопрос, как упоминалось в § 3 гл. X, необходимо вычислить особый показатель — среднее квадратическое отклонение (5).
Правовая статистика, в частности уголовно-правовая, чаще имеет дело с качественными признаками. При выборочном наблюдении интересующих исследователя явлений по этому признаку, как упоминалось, ставится задача установить долю явлений, обладающих этим признаком, например долю осужденных женщин в общем итоге осужденных. Если долю явлений, обладающих данным признаком, мы изобразим буквой Р, то доля остальных явлений, не обладающих этим признаком, будет равна (1 — Р). Действитель-
§ 2. Основные вопросы теории выборочного наблюдения
427
но, если допустить, что доля осужденных, совершивших хулиганство в состоянии опьянения, составляет 90% (или 0,9), то, очевидно, доля хулиганов «трезвенников» будет равна разности: 100% -90% (или 1 -0,9),
т.е. 10% (или 0,1).
Разработанная математической статистикой формула колеблемости отдельных вариантов ряда для совокупности явлений, исчисляемых по качественным признакам, выглядит следующим образом:
52 = />х (]-/>)■.’
Приведем условный пример. Допустим, доля осужденных, совершивших преступление в состоянии опьянения (Р), в общем числе осужденных составляет:
|
при /> = 0,l |
82 = Р{ — Р) = 0,1 х 0,9 = 0,09 |
|
|
при Р = 0,2 |
52 |
= Р{ -Р) = 0,2 У 0,8 = 0,16 |
|
при Р = 0,3 |
82 = Р{ -Р) = 0,3 х 0,7 = 0,21 |
|
|
при Р = 0,4 |
S2 = Р(1 — Р) = 0,4 х 0,6 = 0,24 |
|
|
при Р = 0,5 |
S2 ш Р( -Р) = 0,5 х 0,5 = 0,25 |
|
|
при Р = 0,6 |
S2 = Р{ — Р) = 0,6 х 0,4 = 0,24 |
|
|
при Р = 0,7 |
S2 = Р( -Р) = 0,7 х 0,3 = 0,21 |
|
|
при Р = 0,8 |
б2 |
= Р( — Р) = 0,8 х 0,2 = 0,16 |
|
при Р = 0,9 |
82 |
= Р{ — Р) = 0,9 х 0,1 = 0,09 |
Из приведенных расчетов явствует, что при относительно однородной совокупности осужденных («трезвенников» — 10%) показатель пестроты имел небольшое значение — 0,09. По мере возрастания доли осужденных, совершивших преступление в состоянии опьянения, этот показатель увеличивается, поскольку совокупность действительно становится все более пестрой. Так происходит до •/»= 0,5, когда совокупность осужденных достигает наибольшей пестроты и его показатель имеет максимальное значение — 0,25 (25%). С повышением доли осужденных, совершивших преступление в состоянии опьянения, идет обратный процесс.
Данный показатель колеблемости, как и связанные с ним расчеты, имеет первостепенное значение при проведении выборочного наблюдения.
428
Глава XI. Выборочное наблюдение и его применение в правовой статистике
Определение ошибки выборки
Как упоминалось, основной вопрос выборки заключается в том, насколько выборочная средняя отличается от так называемой генеральной средней, т.е. как велика ошибка репрезентативности.
Ответ на вопрос, каким образом определить размер ошибки выборки, дает математическая теория выборочного метода. Привлечение теории вероятности и математической статистики к решению вопроса об ошибке выборки стало возможным потому, что в основе процесса образования выборочной совокупности из генеральной лежит принцип случайного, непреднамеренного отбора, что позволяет рассматривать этот процесс как случайный.
При достаточно большом числе независимых наблюдений можно с вероятностью, близкой к единице (т.е. почти с достоверностью), утверждать, что отклонение выборочной средней от генеральной будет сколько угодно малым (теорема П.Л. Чебышева}. На размерах ошибки выборки будет сказываться, с одной стороны, действие закона больших чисел: чем больше единиц попадает в выборку, тем меньше будет возможная ошибка. Но, с другой стороны, размер ошибки, как отмечалось, зависит от колеблемости, пестроты обследуемых по определенному признаку единиц совокупности.
Существуют различные по степени точности и степени сложности формулы для расчета предельно допустимой ошибки1.
Для определения средней ошибки репрезентативности, обозначаемой в статистике W, рекомендуется пользоваться следующими двумя формулами2:
1) при определении среднего размера изучаемого количественного признака:
0)
2) при определении доли качественного признака:
1Когда требуется повышенная точность результатов исследования, допускается ошибка выборки до 3%, обычная точность допускает 3—10%, приближенная — от 10 до 20%, ориентировочная — от 20 до 40%, прикидочная — более 40%.
2См.: Остроумов С.С. Советская судебная статистика. С. 220.
§ 2. Основные вопросы теории выборочного наблюдения
429
w =
Р{-Р)
(2)
где W— средняя ошибка репрезентативности; 5 — показатель колеблемости количественного признака, т.е. среднее квадратичес-кое отклонение; п — число единиц, попавших в выборку; Р — доля данного качественного признака в выборке; (1 — Р) — доля противоположного признака.
Технология их исчисления весьма доступна и не требует каких-либо сложных расчетов. Приведем условный пример, позаимствованный нами из указанной работы С.С. Остроумова. Допустим, имеется совокупность в 6500 заключенных. В порядке случайной выборки обследовали 900 заключенных и установили следующие показатели: 1) средний возраст заключенных — 30 лет (Зс); 2) показатель пестроты возраста — 5 = 9 лет; 3) доля заключенных, совершивших преступление в состоянии опьянения, — Р = 0,8, или 80%. Требуется определить среднюю ошибку репрезентативности: а) при установлении среднего возраста заключенных; б) при определении доли заключенных, совершивших преступление в состоянии опьянения. Первый показатель будет определяться по формуле (1):
Здесь необходимо среднее квадратическое отклонение разделить на корень квадратный из числа единиц, попавших в выборку. Подставляем приведенные данные и обнаруживаем, что
W =
/900 30
= 0,3 года.
Из этого следует, что при определении среднего возраста заключенных мы могли допустить ошибку в ту или другую сторону, т.е. этот средний возраст во всей генеральной совокупности (6500 человек) находится в пределах Зс = Зс ± И^или 30 ± 0,3, т.е. от 29,7 до 30,3 года.
Аналогичный расчет по формуле (2) определения доли качественного признака (заключенных, совершивших преступление в состоянии опьянения) покажет, что она равна-± 1,3%, т.е. находится в пределах от 78,7 до 81,3%.
430
Глава XI. Выборочное наблюдение и его применение в правовой статистике
Теперь необходимо ответить на практически очень важный вопрос о том, какова вероятность того, что ошибка репрезентативности не будет превышать в нашем примере 0,3 года в первом случае и 1,3% во втором? Для ответа на этот вопрос теория статистики на основе соответствующих расчетов устанавливает, что вероятность отклонения выборочной средней или доли от генеральной в пределах вычисленной однократной ошибки (/|) равна 0,683.
Вероятность, которая принимается при расчете ошибки выборочной характеристики, называют доверительной. В статистической практике чаще всего принимают доверительную вероятность равной 0,95, 0,954, 0,997 или даже 0,999. Доверительный уровень вероятности 0,95 означает, что только в пяти случаях из 100 ошибка может выйти за установленные границы; при вероятности 0,954 — в 46 случаях из 1000, при 0,997 — в трех случаях, а при 0,999 — в одном случае из 1000.
В нашем примере вычисленная ошибка репрезентативности (/,) гарантируется с вероятностью, равной лишь 0,683. И если мы считаем это недостаточным, то для того, чтобы повысить размер гарантии в отношении полученных результатов, надо раздвинуть пределы возможной ошибки. В случае двукратной ошибки средний возраст заключенных для нашего примера будет находиться в пределах от 29,4 года до 30,6 лет (при (2 = 0,3 х 2 = 0,6 лет; 30 лет ± 0,6 года), что гарантируется с вероятностью 0,954.
Аналогично решается вопрос о пределах; возможной ошибки при установлении доли заключенных, совершивших преступление в состоянии опьянения. При t2 эта ошибка будет равна 1,3 * 2, или 2,6%, т.е. в нашем примере она будет находиться в пределах от 77,4 до 82,6% (80% ± 2,6%).
Как видно из этих формул, величина ошибки репрезентативности прямо пропорциональна корню квадратному из числа единиц, попавших в выборку. Из чего следует, что для уменьшения средней ошибки выборки, например, в 3 раза необходимо увеличить размер выборки в 9 раз.
Определение необходимого объема выборки
Следующим важнейшим вопросом проведения выборочного наблюдения является расчет необходимой численности выборки. Дей-

§ 2. Основные вопросы теории выборочного наблюдения
431
ствительно, сколько, например, заключенных должно быть подвергнуто анкетному опросу или каков процент уголовных или гражданских дел следует изучить, чтобы получить на основе этой выборки вполне типичные, характерные для всей совокупности заключенных, уголовных или гражданских дел показатели. Очевидно, излишняя численность выборки не экономична, а ее недостаточность приведет, как мы видели, к недопустимо большой ошибке репрезентативности.
Иными словами, перед исследователем всегда стоит вопрос: какой должен быть объем выборки, чтобы при минимальном ее объеме получить максимально точные данные?
Так как увеличение точности оценки всегда связано с увеличением объема выборки, необходимо определить максимально допустимую величину ошибки выборки для конкретного исследования.
Взависимости от того, по какому признаку формируется выборка (по количественному или по качественному признаку), в теории статистики разработаны формулы расчета объема выборочной совокупности.
Впервом случае (при определении среднего размера количественного признака) применяется формула
и =
W ‘
(О
а во втором случае (при определении доли качественного признака) и/
(2)
Особый практический интерес в криминологических обследованиях представляет формула (2) для определения необходимой численности выборки при установлении доли качественного признака. Предположим, имеется группа из 3500 человек, осужденных за убийство. Ставится задача: путем выборочного обследования этой группы установить мотивы совершения убийств, т.е. долю корысти, ревности, мести и т.п. Спрашивается, какое число заключенных (л) необходимо подвергнуть обследованию, чтобы ошибка выборки (W) не превышала 3%. Для решения этой задачи необходимо использовать формулу
(2):
432
Глава XI, Выборочное наблюдение и его применение в правовой статистике
Практически наибольшее затруднение при применении этой формулы вызывает то обстоятельство, что в момент проектирования выборочного обследования нам неизвестно значение среднего квадратического отклонения, т.е. числителя приведенной формулы, без чего невозможно определить численность выборки. Выход из создавшегося положения можно найти, если вспомнить, что максимальное значение среднего квадратического отклонения доли качественного признака равно 0,25 (или 25%). Это мы и возьмем в качестве />(1 -/>), что вполне гарантирует нам положительные результаты выборки. Ее численность согласно условиям задачи будет определена следующим образом:
0,25
= 277 человек.
Следовательно, из группы заключенных в 3500 человек (генеральная совокупность) достаточно подвергнуть обследованию 277 человек, чтобы полученные на основе этой выборки результаты по установлению отдельных мотивов убийств колебались в пределах 3%.
Для облегчения довольно громоздких расчетов численности выборки существуют специальные таблицы с уже готовыми результатами — предела ошибки при данном числе наблюдений, необходимого для того,
|
чтобы ошибка не превысила заданного преде- |
|||||||||
|
Табли ца 1 |
|||||||||
|
Предел |
ошибки при |
числе |
i |
||||||
|
данном |
наблюдение |
||||||||
|
При |
Число |
наблюде |
|||||||
|
величине |
ний |
||||||||
|
показателя |
100 |
200 |
300 |
400 |
500 |
600 |
700 |
800 |
900 |
|
, % |
|||||||||
|
10 |
6,0 |
4,3 |
3,5 |
3,0 |
2,7 |
2,5 |
2,3 |
2,1 |
2,0 |
|
15 |
7,2 |
5,1 |
4,1 |
3,6 |
3,2 |
2,9 |
2,7 |
2,5 |
2,4 |
|
20 |
8,0 |
5,7 |
4,6 |
4,0 |
3,6 |
3,3 |
3,0 |
2,8 |
2,7 |
|
30 |
9,2 |
6,5 |
5,3 |
4,6 |
4,1 |
3,7 |
3,5 |
3,2 |
3,1 |
|
35 |
9,6 |
6,8 |
5,5 |
4,8 |
4,3 |
3,9 |
3,6 |
3,4 |
3,2 |
|
40 |
9,9 |
7,0 |
5,6 |
4,9 |
4,4 |
4,0 |
3,7 |
3,5 |
3,3 |
|
45 |
10, |
7,1 |
5,7 |
5,0 |
4,5 |
4,1 |
3,8 |
3,5 |
3,3 |
|
0 |
|||||||||
|
55 |
10, |
7,1 |
5,7 |
5,0 |
4,5 |
4,1 |
3,8 |
3,5 |
3,3 |
|
0 |
|||||||||
|
65 |
9,6 |
6,8 |
5,5 |
4,8 |
4,3 |
3,9 |
3,6 |
3,4 |
3,2 |
|
70 |
9,2 |
6,5 |
5,3 |
4,6 |
4,1 |
3,7 |
3,5 |
3,2 |
3,1 |
|
75 |
8,7 |
6,2 |
5,0 |
4,3 |
3,9 |
3,5 |
3,3 |
3,1 |
2,9 |
|
80 |
8,0 |
5,7 |
4,6 |
4,0 |
3,6 |
3,3 |
3,0 |
2,8 |
2,7 |
§ 2. Основные вопросы теории выборочного наблюдения
433
ла. Приведем для ясности некоторые выдержки из двух таких таблиц1.
Таблица 1 нужна для ответа на вопрос, в каких пределах может колебаться показатель, полученный на основе данной численности выборки, т.е. какова достоверность этого показателя. Покажем на примере, как ею пользоваться. Допустим, на основе обследований 100 осужденных за кражу мы установили, что 80% из них совершили преступление с незаконным проникновением в жилище, помещение либо иное хранилище (ст. 158 ч. 2 п. «в» УК РФ). Насколько точен этот показатель? Ответ на этот вопрос мы найдем в приведенной таблице, где на пересечении горизонтальной строчки с числом 80 с вертикальной первой графой с числом 100 мы находим число 8,0. Это означает, что при данном числе наблюдений (100 человек) доля осужденных, совершивших квалифицированную кражу (по указанному признаку), может колебаться в пределах от 72 до 88% (80 ± 8%). Отметим, что все показатели таблицы вычислены с вероятностью 0,954, т.е. с учетом удвоенной ошибки (t2).
На вопрос о том, какое минимальное число наблюдений надо производить, чтобы ожидаемый показатель колебался в заданных пределах, отвечает табл. 2.
Как пользоваться этой таблицей? Допустим, требуется узнать, сколько нужно обследовать осужденных за убийство, чтобы выясТаблица 2
Число наблюдений, необходимых для того, чтобы ошибка не превысила заданного предела
|
При величине Предел ошибки, % |
||||||
|
показателя, |
1 |
2 |
3 |
4 |
5 |
10 |
|
% |
||||||
|
10 |
3600 |
900 |
400 |
230 |
150 |
37 |
|
20 |
6400 |
1600 |
710 |
400 |
260 |
65 |
|
40 |
9600 |
2400 |
1070 |
600 |
390 |
97 |
|
45 |
9900 |
2500 |
1100 |
620 |
400 |
100 |
|
55 |
9900 |
2500 |
1100 |
620 |
400 |
100 |
|
65 |
9100 |
2300 |
1010 |
570 |
370 |
92 |
|
70 |
8400 |
2100 |
930 |
530 |
340 |
85 |
|
80 |
6400 |
1600 |
710 |
400 |
260 |
65 |
1 Таблицы приводятся по работе: Боярский А.Я. Таблицы для определения достоверности статистических показателей и числа наблюдений в статистическом исследовании. М., 1947.
434 Глава XI. Выборочное наблюдение и его Применение в правовой статистике______
нить среди них долю лиц, совершивших преступления в состоянии опьянения. Предел ошибки должен быть не более 3%. На основе предварительного ознакомления по другим источникам будем считать, что ожидаемая доля составит 70%. Тогда из предпоследней строки таблицы мы видим, что величине показателя в 70% с пределом ошибки в 3% соответствует число 930. Отсюда нам необходимо обследовать минимум 930 человек осужденных.
Наряду с этими приемами, основанными на положениях теории вероятности, устанавливающими точную меру репрезентативности материалов выборки, С.С. Остроумов предлагает менее точный, но упрощенный прием. Он сводится к тому, что данные выборки сопоставляются с данными сплошного наблюдения (т.е. текущей статистической отчетности) в отношении совпадающих признаков. Наличие или отсутствие совпадения в этих признаках (например, доля отдельных видов преступлений) будет индикатором показательности материалов выборочного наблюдения. Но, как отмечалось ранее, число совпадающих признаков выборки и отчетности весьма ограничено.
§ 3. Способы отбора, обеспечивающие репрезентативность выборки. Виды выборки
Объективную гарантию репрезентативности полученной выборочной совокупности дает применение соответствующих научно обоснованных способов отбора подлежащих исследованию единиц.
В процессе формирования выборочной совокупности должен быть обеспечен строго объективный подход к отбору единиц. Нарушение этого принципа, когда наблюдению подвергаются единицы, отобранные на основании субъективного мнения исследователя, приводит к тому, что результаты такого наблюдения относятся не ко всей генеральной (сплошной) совокупности, а только к той ее части, которая была подвергнута обследованию.
Для того чтобы результаты, полученные при изучении выборочной совокупности, можно было без значительной погрешности распространить на всю совокупность, при организации выборочного наблюдения необходимо соблюдать следующие, выработанные теорией статистки требования:
§ 3. Способы отбора, обеспечивающие репрезентативность выборки. Виды выборки 435
|
— |
число единиц, взятых для выборочного обследования, должно быть достаточно большим; |
|
— |
выбор единиц наблюдения должен быть случайным, т.е. каждая единица изучаемой |
|
совокупности должна иметь равнозначную вероятность попасть в выборку; |
|
|
— |
выбор должен быть произведен из всех частей изучаемой совокупности (например, из всех |
|
категорий обследуемых преступлений); |
|
|
— |
выбор не должен зависеть от количества и значения признаков, которыми обладают |
единицы совокупности.
По способу организации различают следующие виды выборок: собственно случайную или простую, типическую, механическую, серийную. По степени охвата единиц исследуемой совокупности различают большие и малые выборки.
В зависимости от способа отбора единиц различают:
1) отбор по схеме возвращенного шара, обычно называемый повторной выборкой. При повторном отборе вероятность попадания каждой отдельной единицы в выборку остается постоянной, так как после отбора какой-то единицы (шара) она (он) снова возвращается в совокупность (в урну) и снова может быть выбрана (выбран); 2) отбор по схеме невозвращенного шара, называемый бесповторной выборкой. В этом случае
каждая отобранная единица не возвращается обратно, и вероятность попадания отдельных единиц в выборку все время изменяется (для оставшихся единиц она возрастает) (схема 1).
Первоначально сложился простой случайный отбор единиц наблюдения, основанный на случайном отборе единиц для выборочного наблюдения из всей генеральной совокупности в целом. Иногда этот способ называют выборкой собственно случайной в отличие от других видов выборки (например, типической, серийной), которые также в конечном счете основаны на случайном отборе.
Случайная выборка обычно проводится с помощью жеребьевки или при помощи таблиц случайных чисел. Проиллюстрируем это на примере отбора присяжных заседателей, институт которых ныне утверждается в российских судах. Они отбираются из граждан России, достигших 25-летнего возраста, внесенных в списки избирателей, составляемых при подготовке к выборам в представительные органы или к референдумам. Из их числа исключаются также те, кто не отвечает ря436____Глава XI, Выборочное наблюдение и его применение в
правовой статистике
Схема ХАРАКТЕРИСТИКА ВЫБОРОЧНОГО НАБЛЮДЕНИЯ
ВЫБОРОЧНОЕ НАБЛЮДЕНИЕ
Виды
1
Собственно случайный Типический
отбора
Систематический или механический Повторный
1
О ш Бесповторный
I 1
Серийный, иногда кластерный Комбинированный ибки выборки Репрезентативности Предельная Средняя
ду других требований, установленных в ст. 80 Закона РСФСР «О судоустройстве РСФСР»1 (например, наличие судимости, дефектов здоровья, которые не дают возможности выполнять функции присяжного, невладение языком, на котором ведется судопроизводство в данной местности, возрастной ценз — старше 70 лет, занимающие перечисленные в законе должности, например, судьи, прокурора, следователя, руководящего или оперативного работника органов внутренних дел либо ФСБ, нотариуса; ими не могут быть военнослужащие, священнослужители, а также другие лица, о которых сказано в упомянутой ст. 80 Закона о судоустройстве).
Отбор отвечающих этим требованиям кандидатов в присяжные заседатели проходит несколько этапов. На первом определяется число кандидатов в присяжные заседатели, необходимое для того суда, где возможно рассмотрение уголовного дела с их участием. Делает это председатель соответствующего краевого, областного или городского (федерального подчинения) суда с помощью подчиненных ему сотрудников канцелярии, ориентируясь на нагрузку (объем работы) суда в предшествующие годы.
1 См.: ВВС РФ. 1993. № 3. Ст. 1313.
____§ 3. Способы отбора, обеспечивающие репрезентативность выборки, Виды выборки 437
О требуемом числе присяжных заседателей председатель суда сообщает главе администрации края, области или города. Последний поручает определить, сколько кандидатов в присяжные заседатели должно быть отобрано от каждого района или города с учетом числа зарегистрированных там избирателей.
На основе полученной заявки администрация района (города) или орган местного самоуправления образуют комиссию в составе представителей трудовых коллективов и общественных объединений, а также представителей правоохранительных органов, органов здравоохранения и др. (последние помогают комиссии выявить лиц, которые по закону не должны включаться в списки кандидатов в присяжные). Используя списки избирателей районов (городов), комиссия на основе принципа равновозможности методом случайной выборки производит из них отбор кандидатов в присяжные заседатели. Это значит, что лица, включаемые в списки кандидатов в присяжные, ни в коем случае не могут отбираться по каким-то заранее заданным признакам (в зависимости, например, от должностного положения кандидата, его возраста, образования, пола, принадлежности к общественным объединениям, убеждений, отношения к религии и т.д.).
Важный этап — установление пропорции отбора, которая определяется соотнесением объемов выборочной и генеральной совокупности, т.е. определение интервала, через который необходимо производить отбор из списка избирателей (генеральная совокупность) в список кандидатов в присяжные (выборка), и порядкового номера, с которого начнется отбор. Для этого общее число избирателей делится на число необходимых кандидатов в присяжные. Например, представленный список избирателей состоит их 1000 человек: нужно отобрать 100 кандидатов, следовательно, интервал отбора будет 1000/100 = 10, т.е. необходимо отобрать из каждого десятка одного человека. Кого именно из первого десятка следует взять, практически безразлично. Можно начать отсчет от любого порядкового номера. Если начать отбор с первого номера, то отобранными будут: 1, 11, 21, 31, 41 и т.д. единицы. Если же его начать с 5 или 10, то отобранными соответственно будут: 5, 15, 25, 35 и т.д. или 10, 20, 30, 40 и т.д. Иногда предпочитают первую единицу отобрать в случайном порядке по жребию, а сам отбор производить, используя таблицы случайных чисел.
438____Глава XI, Выборочное наблюдение и его применение в правовой статистике______
После «фильтрации» списка кандидатов, исходя из требований, предъявляемых к ним указанным законом, он направляется главе вышестоящей администрации, который поручает свести воедино все составленные в районах и городах списки, затем подписывает и скрепляет печатью такой сведенный воедино список (он называется общим списком) и направляет его председателю суда, по представлению которого он составляется.
Одновременно с общим, с соблюдением той же процедуры, составляется запасной список кандидатов в присяжные заседатели. Этот список имеет некоторые особенности: в него включается не более четверти от общего числа потенциальных присяжных, которые внесены в общий список; включаемые в запасной список лица обязательно должны быть жителями краевого или областного центра. Запасные списки предназначены для того, чтобы оперативно обеспечивать замену выбывших по тем или иным причинам присяжных заседателей, уже участвующих в рассмотрении конкретного уголовного дела.
Процессуальные особенности дальнейшего отбора присяжных заседателей для рассмотрения конкретного уголовного дела установлены ст. 434 и 438—444 УПК’. При определенных условиях и на данном этапе для отбора присяжных проводится жеребьевка.
Настоящая процедура отбора присяжных на основе принципа равновозможности и случайности выборки — надежная гарантия обеспечения конституционных принципов в отправлении правосудия по уголовным делам с участием присяжных заседателей.
Случайная выборка дает достаточно хорошие результаты в тех случаях, когда между единицами исследуемой совокупности нет резких различий. Однако если генеральная совокупность состоит из элементов, значительно отличающихся друг от друга, простой случайный отбор оказывается недостаточно надежным способом формирования выборочной совокупности. В этом случае применяется типическая выборка.
Типическая (стратифицированная) выборка основана на отборе единиц для выборочного наблюдения не из всей генеральной совокупности в целом, а из ее типических групп. При типической выборке генеральная совокупность предварительно расчленяется на типы, каждый из которых в выборке представлен квотой, про-
1 Подробнее см.: Правоохранительные органы: Учебник для вузов / Под ред. проф. К.Ф. Гуценко. М., 1995. С. 196-199.
Г
____§ 3. Способы отбора, обеспечивающие репрезентативность выборки. Виды выборки 439
порциональной численности типа в генеральной совокупности. При обследованиях населения такими типическими группами могут быть районы, социальные, возрастные или образовательные группы, при обследовании учреждений уголовно-исполнительной системы — вид исправительных колоний в зависимости от режима, возраста заключенных и т.д. Непосредственный отбор единиц из типических групп производится в виде случайного отбора, механического отбора или какимнибудь другим способом. При этом отбор может быть либо пропорциональным численности единиц в отдельных типических группах, либо непропорциональным.
Типический отбор даст более репрезентативную выборку. Если при простом случайном отборе обеспечивается лишь количественная репрезентация выборки, то при типическом отборе обеспечивается как количественная, так и качественная репрезентация. Наиболее яркими примерами выборок, осуществляемых по методу квот, являются выборки с целью изучения общественного мнения. Число единиц в таких выборках определяется в 1—3 тыс. человек.
Так, известный институт Д. Гэллапа в США для опроса с целью изучения каких-либо характеристик, касающихся всего населения США, ограничивается выборкой 1200—1500 человек, т.е. порядка 0,001% населения (учитывая взрослое население страны). В данном случае используется строго случайная, структурированная, образуемая на основе тонкой, филигранной методики и техники выборка. Увеличение этой выборки в 10 раз дает уточнение результата не более чем на 2 %>.
Главная особенность этого метода состоит в том, что предварительно изучается реальная структура населения региона по целому ряду признаков (пол, возраст, образование, семейное положение, уровень доходов и др.). При этом обоснованно предполагается, что выборка будет иметь структуру, аналогичную генеральной совокупности, и по другим признакам, не учтенным при выборке.
Именно по такой выборке летом 1997 г. социологами фонда «Общественное мнение» проведен всероссийский опрос городского и сельского населения при участии 1500 респондентов. По его результатам лидерами народного доверия россиян признаны церковь, армия и средства массовой информации. Самым высоким доверием в стране пользуется православная церковь— 54% опрошенных. На вто-
См.: США — экономика, политика, идеология. 1972. № 5. С. 110—116.
440
Глава XI. Выборочное наблюдение и его применение в правовой статистике
ром месте по степени доверия оказалась армия — 42%. Третье место занимают мэры городов и главы городских и районных администраций — 35%. Средствам массовой информации доверяют 32% россиян. Губернаторы областей и краев пользуются доверием 31% респондентов. Судебным властям верят лишь 22%
опрошенных. Еше ниже уровень доверия милиции и органам внутренних дел — 19%. Такой же рейтинг отмечен у профсоюзов.
Законодательные собрания и думы областей., краев и республик пользуются доверием 18%, у Правительства РФ рейтинг доверия составляет 11%. Меньше всего респонденты доверяют Государственной Думе (10% голосов)’.
Механическая выборка применяется в случаях, когда генеральная совокупность каким-либо образом упорядочена, т.е. имеется определенная последовательность в расположении единиц совокупности (списки избирателей — по алфавиту, табельные номера работников — по цехам, отделам, номера учреждений уго- ловно-исполнительной системы — по регионам, номера уголовных дел — в зависимости от подследственности и т.п.). Отбор единиц производят в соответствии с установленной пропорцией через какой-нибудь интервал.-Например, при пропорции 1:50 (2%-ная выборка) отбирается каждая 50-я единица, при пропорции 1:20 (5%-ная выборка) — каждая 20-я единица совокупности и т.д.
В тех случаях, когда единицы совокупности объединены в небольшие группы или серии, используется серийная выборка (иногда кластерная) — от английского слова cluster sampling, смысл которой удобно пояснить на примере: чтобы определить для какого-то антропометрического обследования средний рост школьников-первоклассников, можно случайным или механическим способом выбрать город, в этом городе
— округ, в округе — школу, в ней класс, а затем произвести сплошное измерение роста всех учеников этого класса. То есть сущность серийной выборки заключается в собственно случайном либо механическом отборе серий, внутри которых производится сплошное обследование единиц. В качестве таких серий в уголовно-правовой статистике могут рассматриваться социальные или возрастные группы — при исследовании причин преступности, организационно-правовые формы
i См.: Материалы Информационно-аналитического управления аппарата Совета Федерации Федерального Собрания РФ. Вып. 13.
М., 1997. С. 19.
Контрольные вопросы и задания
441
собственности — при изучении экономических преступлений, оперативно-строевые подразделения правоохранительных органов — при исследовании эффективности их работы и т.д.
Втеории статистики разработаны соответствующие формулы расчета средней ошибки выборки применительно к каждому из перечисленных выше способов ее отбора1.
Комбинированный отбор. Кроме перечисленных способов отбора, в практике статистических обследований социально-правовых явлений применяется и их комбинация. Так, например, можно комбинировать типическую и серийную выборки, когда серии отбираются в установленном порядке из нескольких типических групп. Возможна также комбинация серийного и собственно случайного отборов, при которой отдельные единицы отбираются внутри серии в собственно случайном порядке.
Способ (или вид) отбора объектов — решающее условие качества выводов из любого выборочного метода исследования, который, в свою очередь, во многом определяется особенностями предмета исследования.
Взаключение несколько слов о малых выборках (к безусловно малым относятся выборки объемом менее 30 единиц). Теория малых выборок разработана английским статистиком В. Госсетом (писавшим под псевдонимом Стьюдент) в начале XX в. и продолжена в исследованиях Р. Фишера.
Как отмечалось, для определенного способа отбора единиц ошибка репрезентативности зависит от объема выборки и степени колеблемости, пестроты изучаемого признака в генеральной совокупности. Причем чем меньше объем выборки, тем большую ошибку репрезентативности следует ожидать, а это, в свою очередь, снижает точность оценки параметров генеральной совокупности. Так, уже при п< 100 получается несоответствие между табличными данными и вероятностью предела; при п < 30 погрешность становится значительной. Несоответствие вызывается главным образом распределением единиц генеральной совокупности (их колеблемостью или пестротой).
При выборках небольшого объема (уже менее 100 единиц) отбор должен проводиться из совокупности, имеющей нормальное распределение, что в объектах правовой статистики встречается очень
I См., напр.: Теория статистики: Учебник/Под ред. проф. Р.А. Шмойловой. С. 202-211.
442
Глава XI. Выборочное наблюдение и его применение в правовой статистике
редко. Поэтому малую выборку при обследовании правонарушений и контроля над ними следует применять с большой осторожностью при соответствующем теоретическом и практическом обосновании’.
Контрольные вопросы и задания
1.В чем преимущество выборочного метода в сравнении с другими видами статистических наблюдений?
2.Назовите общие и специфические этапы выборочного наблюдения.
3. Что означает ошибка репрезентативности, какие факторы определяют ее величину?
4.Охарактеризуйте сферы применения и особенности различных способов формирования (отбора) выборочной совокупности.
5.Какие факторы влияют на определение объема выборки при различных способах отбора?
6.В чем состоят преимущества типической выборки перед простой случайной выборкой?
Задание 1. Для изучения общественного мнения о работе правоохранительных органов в порядке механического отбора было опрошено 1500 человек, или 1% общей численности городского населения. Из числа опрошенных 340 человек положительно оценили работу правоохранительных органов. С вероятностью 0,997 определите пределы, в которых находится доля лиц, положительно оценивающих работу правоохранительных органов.
Задание 2. При изучении 200 уголовных дел, отобранных из общего числа возбужденных в случайном порядке, оказалось, что 20% были необоснованно прекращены.
С вероятностью 0,954 определите предел, в котором находится доля необоснованно прекращенных дел в общем числе возбужденных уголовных дел.
Задание 3. По материалам всех уголовных дел об умышленных убийствах доля преступлений с использованием огнестрельного оружия составила 70%. В порядке выборки обследовали 20% всех дел и установили, что доля таких преступлений равна 60%.
Определите ошибку репрезентативности такой выборки.
Задание 4. На основе обследования 200 осужденных за убийство установлено, что 60% из них совершили преступление в состоянии алкогольного опьянения.
1 Подробнее см.: Ефимова М.Р., Петрова Е.В., Румянцев ИВ. Общая теория статистики: Учебник. С. 178—186.
Рекомендуемая литература
443
Используя таблицу предела ошибки приданном числе наблюдений, определите достоверность этого показателя. Задание 5. Используя таблицу (число наблюдений, необходимых для того, чтобы ошибка не превысила заданного предела), определите, сколько нужно обследовать осужденных за нарушение правил дорожного движения и эксплуатации транспортных средств, чтобы выяснить среди них долю лиц, совершивших ДТП в состоянии опьянения. Предел ошибки при исследовании должен быть не более 3%. На основе предварительного ознакомления с различными материалами {статистическими отчетами, судебной практикой, показателями прошлых обследований и т.д.) следует исходить из ожидаемый доли примерно 40%.
Рекомендуемая литература
Блувштейн Ю.Д. Криминология и математика. М., 1974.
Влувштейн Ю.Д. Криминологическая статистика (статистические методы в анализе оперативной обстановки). Минск,
1981.
Вицин СЕ. Системный подход и преступность. М., 1980.
Выборочное наблюдение в статистике СССР / Под ред. А.Я. Боярского и др. М., 1966.
Дружинин Н.К. Выборочный метод и его применение в социально-экономических исследованиях. М., 1970. Елисеева И., Соколов Я. Выборочный метод в аудите //Вестник статистики. 1993. № 9.
Кокрен У Методы выборочного исследования / Под ред. А.Г. Волкова; Пер. с англ. И.М. Сонина. М., 1976. Королев Ю.Г. Выборочный метод в социологии: Учеб. пособие. М., 1975.
Рабочая книга социолога. 2-е изд., перераб. и доп. М, 1983. Остроумов С. С. Советская судебная статистика. М., 1976.
Чубарев В.Л. Теоретические вопросы организации выборки в криминологическом исследовании // Тр. ВНИИ МВД
СССР. 1980. № 56.
Глава XII. ИНДЕКСЫ И ИХ ИСПОЛЬЗОВАНИЕ В СОЦИАЛЬНО-ПРАВОВЫХ ИССЛЕДОВАНИЯХ § 1. Общее понятие об индексах и значение индексного метода анализа правовых явлений
В аналитической практике индексы наряду со средними величинами наиболее распространенные обобщающие показатели, характеризующие состояние или изменение исследуемого явле-
Индекс — это относительный показатель сравнения (во времени, пространстве или сравнение фактических данных с любым эталоном — план, прогноз, норматив и т.д.) одного и того же явления (простого или сложного, состоящего из соизмеримых или несоизмеримых элементов)1. Сфера использования таких показателей безгранична: с их помощью характеризуется развитие национальной экономики в целом и ее отдельных отраслей, анализируются результаты про- изводственно-хозяйственной деятельности предприятий и организаций, исследуется роль
отдельных факторов в формировании важнейших социально-экономических показателей, индексы используются также в международных сопоставлениях социально-экономических показателей, определении уровня жизни и т.д.
Так, объем валового внутреннего продукта (ВВП) России в январе 1997 г. составил в текущих ценах 201 трлн руб. (индекс состояния) при темпе его реального объема к январю 1996 г. 100,1%
(индекс изменения)2.
! Слей 1997 г. Госкомстат России. М., 1997. С. 6, 7.
происхождения (index), буквально озна1 веском положении России. Ян1
§ 1, Общее m
t индексного метода анализа
В первой половине 1997 г. продолжались процессы стабилизации ценовой динамики, прирост потребительских цен составил только 8,6% (за январь — июнь 1996 г. прирост цен составил
15,556)1.
Индекс потребительских иен (ИПЦ) широко используется в качестве показателя инфляции. ИПЦ измеряет изменение стоимости фиксированной потребительской корзины товаров и услуг, используемых семьями. Корзина товаров и услуг фиксирована,, с тем чтобы данному уровню жизни соответствовало одно и то же значение индекса. По этой причине ИПЦ называют индексом стоимости жизни. Стоимость такой потребительской корзины (набора из 25 основных продуктов питания), являющейся одним из составляющих прожиточного минимума населения, рассчитываемой на основе «Методических рекомендаций по расчетам прожиточного минимума по регионам России», утвержденных Министерством труда РФ 10 ноября 1992 г., в среднем по России в конце января 1996 г. составила 229,2 тыс. руб. в расчете на месяц и по сравнению с концом предыдущего месяца увеличилась на 4,3%2.
Широка амплитуда применения индексных показателей социально-правовых явлений — от динамики тяжести последствий отдельных видов правонарушений до изменения характера и степени общественной опасности преступности в целом. В частности, показатель-индекс состояния безопасности дорожного движения является нормативно-оценочным. Его учет по количеству пострадавших в ДТП граждан возложен на медицинские учреждения (независимо от форм собственности) и органы внутренних Дел3. Органы внутренних дел исчисляют тяжесть последствий ДТП путем отношения числа погибших к числу пострадавших в дорожнотранспортных происшествиях людей. Определенный по такой методике показатель-индекс за 1996 г., когда было совершено 160 523 ДТП, в которых пострадало 207 846 человек (погибло 29 468 и 178 378 ранено), составил 14,2 (29 468.x 100:207 846). В 1997 г. было совершено 156 515 ДТП, в которых погибло 27 665 и ранено 177 924 человека. Индекс тяжести последствий ДТП.составил
13,5.
3 См.: О порядке государств дорожного движения. Постаноп РФ. 1997. № 20. Ст2279.
я безопасности еля 1997г.//СЗ
446
ix использование в социально-правовых исследованиях
Юристам часто приходится иметь дело с индексами в практике правоохранительных органов, например при расследовании-дел экономической направленности, преступлений против государственной власти, интересов государственной службы и службы в органах местного самоуправления. Знание индексов необходимо для ориентировки в целом ряде важных экономических вопросов.
Этим объясняется необходимость уяснения индексного метода анализа социально-правовых явлений.
Чаще всего сопоставляемые показатели характеризуют явления, состоящие из разнородных элементов, непосредственное сумми-. рование которых невозможно в силу их несоизмеримости. Так, промышленные предприятия выпускают, как правило, разнообразные виды продукции (услуг), преступления различаются рядом признаков, характеризующих элементы состава преступления, и т.д. Получить общий объем продукции предприятия в таком случае нельзя суммированием количества различных видов продукции в натуральном выражении. Здесь возникает проблема соизмерения разнокачественных единиц совокупности. Если изделия предприятий несопоставимы как различные потребительные стоимости, то они обладают некоторыми общими признаками, дающими возможность их соизмерить. Как писал К. Маркс в «Капитале», «различные виды становятся качественно сравнимыми лишь после того, как они сведены к одному единству. Только как выражения одного и того же единства они являются одноименными, а следовательно, соизмеримыми величинами»1. В качестве такого соизмерителя в нашем примере

Маржа ошибки — важнейшее понятие для понимания точности и надежности данных исследования. В этой статье мы подробно рассмотрим ее определение и расчет, а также приведем примеры ее использования в исследованиях. Мы также обсудим важность учета предела погрешности при интерпретации результатов опроса и то, как он может повлиять на выводы, сделанные на основе данных. Итак, независимо от того, имеете ли вы опыт или только начинаете свой путь, эта статья — обязательное чтение для всех, кто хочет овладеть искусством предельной погрешности и обеспечить точность и надежность своих исследований. Давайте начнем!
Что такое предел ошибки?
Определение:
Предел ошибки в статистике — это степень погрешности результатов, полученных в ходе случайных выборочных исследований. Более высокая погрешность в статистике указывает на меньшую вероятность полагаться на результаты исследования или опроса, т.е. уверенность в том, что результаты будут представлять население, будет ниже. Это очень важный инструмент в маркетинговых исследованиях, поскольку он показывает уровень доверия исследователей к данным, полученным в ходе опросов.
Доверительный интервал — это уровень непредсказуемости конкретной статистики. Обычно он используется вместе с пределом погрешности, чтобы показать, насколько статистик уверен в том, что результаты онлайн-опроса или анкетирования достойно представляют все население.
Меньшая погрешность указывает на более высокий уровень доверия к полученным результатам.
Когда мы выбираем репрезентативную выборку для оценки всего населения, она будет иметь некоторый элемент неопределенности. Нам необходимо вывести реальную статистику из статистики выборки. Это означает, что наша оценка будет близка к реальной цифре. Учет предела ошибки еще больше улучшает эту оценку.
Расчет предела ошибки:
Необходимым условием для расчета предела ошибки является четко определенная популяция. В статистике «популяция» включает в себя все элементы определенной группы, которую исследователь намерен изучить и собрать данные. Погрешность может быть значительно высокой, если популяция не определена или в случаях, когда процесс отбора выборки проведен неправильно.
Каждый раз, когда исследователь проводит статистический опрос, требуется расчет предельной погрешности. Универсальная формула для выборки выглядит следующим образом:

где:
p? = доля выборки («P-hat»).
n = размер выборки
z = z-шкала, соответствующая желаемому уровню доверия.
Вы чувствуете себя немного растерянным? Не волнуйтесь! Вы можете воспользоваться нашим калькулятором погрешности.
Пример расчета погрешности
Например, дегустационные сессии, проводимые на виноградниках, зависят от качества и вкуса вин, представленных во время сессии. Эти вина представляют все производство, и в зависимости от того, насколько хорошо посетители принимают их, отзывы от них обобщаются на все производство.
Дегустация вина будет эффективной только тогда, когда посетители не имеют шаблона, то есть выбраны случайно. Вино проходит через определенный процесс, чтобы стать вкусным, и точно так же посетители также должны пройти через определенный процесс, чтобы обеспечить эффективные результаты.
Компоненты измерения доказывают, достойны ли бутылки вина представлять все производство винодельни или нет. Если статистик утверждает, что проведенный опрос будет иметь погрешность плюс-минус 5% при доверительном интервале 93%. Это означает, что если опрос посетителей виноградника проводился 100 раз, то полученные отзывы будут в пределах процентного деления либо выше, либо ниже того процента, который учитывается 93 раза из 100.
В данном случае, если 60 посетителей сообщают, что вина были исключительно хорошими. Поскольку предел ошибки составляет плюс-минус 5% при доверительном интервале в 93%, из 100 посетителей можно сделать вывод, что посетители, отметившие, что вина были «чрезвычайно хороши», будут 55 или 65 (93%) раз.
Чтобы объяснить это дальше, рассмотрим пример: опрос о волонтерстве был разослан 1000 респондентам, из которых 500 согласились с утверждением в опросе, что волонтерство делает жизнь лучше. Рассчитайте предел ошибки для 95-процентного уровня доверия.
Шаг 1: Рассчитайте P-hat, разделив количество респондентов, согласившихся с утверждением в опросе, на общее количество респондентов. В данном случае = 500/1000 = 50%
Шаг 2: Найдите z-балл, соответствующий 95%-ному уровню доверия. В данном случае z-шкала равна 1.96
Шаг 3: Рассчитайте, подставив эти значения в формулу
Шаг 4: Преобразовать в проценты

Предел ошибки в объемах выборки:
При вероятностной выборке каждый член популяции имеет вероятность быть отобранным в выборку. При этом методе исследователи и статистики могут отбирать членов из своей области исследований таким образом, чтобы предел ошибки в данных, полученных из этих выборок, был как можно меньше.
При не вероятностной выборке выборки формируются на основе экономической эффективности или удобства, а не на основе применения, и из-за этого процесса отбора некоторые части населения могут быть исключены. Опросы будут эффективны только при фильтрации участников в соответствии с интересами и применением к проводимому опросу.
Промышленный стандарт уровня доверия составляет 95%, и вот проценты погрешности для определенных размеров выборки:

Как видно из этой таблицы, чтобы уменьшить маржу ошибки в два раза, например, с 4 до 2, размер выборки был значительно увеличен, с 500 до 2000. Как вы, наверное, заметили, размер выборки обратно пропорционален. До размера выборки 1500 она значительно уменьшается, а после этого уменьшается.
Готовы вывести свою исследовательскую игру на новый уровень? Присоединяйтесь к и поднимите свои опросы с уровня «хо-хам» до уровня «о-вау»! Благодаря нашей удобной платформе вы сможете создавать опросы профессионального уровня в кратчайшие сроки. Кроме того, благодаря таким функциям, как настраиваемые шаблоны, расширенная аналитика и сбор данных в режиме реального времени, у вас будет все необходимое для сбора точных и надежных данных. Итак, не упустите возможность получить удовольствие. Присоединяйтесь к сегодня бесплатно и начните узнавать, что на самом деле думают ваши клиенты, сотрудники и сообщества. Кредитная карта не требуется.
2.1. Средняя и предельная ошибки выборки. Построение доверительных границ для средней и доли
Средняя ошибка
выборки
показывает, насколько отклоняется в
среднем параметр выборочной
совокупности
от соответствующего параметра генеральной.
Если рассчитать среднюю из ошибок всех
возможных выборок определенного вида
заданного объема (n),
извлеченных из одной и той же генеральной
совокупности,
то получим их обобщающую характеристику
среднюю
ошибку выборки
().
В
теории выборочного наблюдения
выведены формулы для определения ,
которые индивидуальны для разных
способов отбора (повторного и
бесповторного), типов используемых
выборок и видов оцениваемых статистических
показателей.
Например, если
применяется повторная собственно
случайная выборка, то
определяется как:
![]()
при
оценивании среднего значения признака;
![]()
если
признак альтернативный, и оценивается
доля.
При бесповторном
собственно случайном отборе в формулы
вносится поправка
![]()
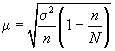
для
среднего значения признака;
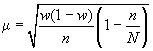
для
доли.
Вероятность
получения именно такой величины ошибки
всегда равна 0,683. На практике же
предпочитают получать данные с большей
вероятностью, но это приводит к возрастанию
величины ошибки выборки.
Предельная
ошибка выборки ()
равна t-кратному
числу средних ошибок выборки (в теории
выборки принято коэффициент t
называть
коэффициентом доверия):
t
.
Если ошибку выборки
увеличить в два раза (t
2), то получим гораздо большую вероятность
того, что она не превысит определенного
предела (в нашем случае
двойной средней ошибки)
0,954. Если взять t
3, то доверительная вероятность составит
0,997
практически достоверность.
Уровень предельной
ошибки выборки зависит от следующих
факторов:
степени вариации
единиц генеральной совокупности;
объема выборки;
выбранных схем
отбора (бесповторный отбор дает меньшую
величину ошибки);
уровня
доверительной вероятности.
Если объем выборки
больше 30, то значение t
определяется по таблице нормального
распределения, если меньше
по таблице распределения Стьюдента
(Приложение
1).
Приведем некоторые
значения коэффициента доверия из таблицы
нормального распределения.
![]()
Доверительный
интервал для среднего значения признака
и для доли в генеральной
совокупности
устанавливается следующим образом:
![]()
Итак, определение
границ генеральной средней и доли
состоит из следующих этапов:
нахождение в
выборке среднего значения признака
(или доли);
определение
в соответствии с выбранной схемой отбора
и вида выборки;
задание
доверительной вероятности Р
и определение коэффициента доверия t
по
соответствующей таблице;
вычисление
предельной ошибки выборки ;
построение
доверительного интервала для средней
(или доли).
Ошибки выборки
при различных видах отбора
1. Собственно
случайная и механическая выборка.
Средняя
ошибка собственно случайной и механической
выборки находятся по формулам,
представленным в табл. 11.1.
Таблица 1
Формулы для
расчета средней ошибки
собственно
случайной и механической выборки ()

где
2
дисперсия
признака в выборочной совокупности.
Пример 2. Для
изучения уровня фондоотдачи было
проведено выборочное обследование 90
предприятий из 225 методом случайной
повторной выборки, в результате которого
получены данные, представленные в
таблице.

В рассматриваемом
примере имеем 40%-ную выборку (90 : 225
0,4, или 40%). Определим ее предельную ошибку
и границы для среднего значения признака
в генеральной совокупности по шагам
алгоритма:
1. По результатам
выборочного обследования рассчитаем
среднее значение и дисперсию в выборочной
совокупности:
Выборочная средняя
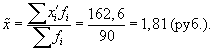
Выборочная
дисперсия изучаемого признака
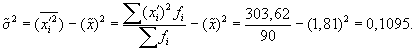
2. Определяем
среднюю ошибку повторной случайной
выборки
![]()
3. Зададим
вероятность, на уровне которой будем
говорить о величине предельной ошибки
выборки. Чаще всего она принимается
равной 0,999; 0,997; 0,954.
Для наших данных
определим предельную ошибку выборки,
например, с вероятностью 0,954. По таблице
значений вероятности функции нормального
распределения (см. выдержку из нее,
приведенную в Приложении 1) находим
величину коэффициента доверия t,
соответствующего вероятности 0,954. При
вероятности 0,954 коэффициент t
равен 2.
4. Предельная
ошибка выборки с вероятностью 0,954 равна
![]()
5. Найдем доверительные
границы для среднего значения уровня
фондоотдачи в генеральной совокупности
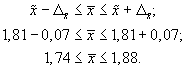
Таким образом, в
954 случаях из 1000 среднее значение
фондоотдачи будет не выше 1,88 руб. и не
ниже 1,74 руб.
Выше была
использована повторная схема случайного
отбора. Посмотрим, изменятся ли результаты
обследования, если предположить, что
отбор осуществлялся по схеме бесповторного
отбора. В этом случае расчет средней
ошибки проводится по формуле
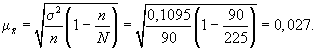
Тогда при вероятности
равной 0,954 величина предельной ошибки
выборки составит:
![]()
Доверительные
границы для среднего значения признака
при бесповторном случайном отборе будут
иметь следующие значения:
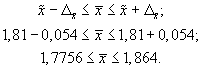
Сравнив результаты
двух схем отбора, можно сделать вывод
о том, что применение бесповторной
случайной выборки дает более точные
результаты по сравнению с применением
повторного отбора при одной и той же
доверительной вероятности. При этом,
чем больше объем выборки, тем существеннее
сужаются границы значений средней при
переходе от одной схемы отбора к другой.
По данным примера
определим, в каких границах находится
доля предприятий с уровнем фондоотдачи,
не превышающим значения 2,0 руб., в
генеральной совокупности:
1) рассчитаем
выборочную долю.
Количество
предприятий в выборке с уровнем
фондоотдачи, не превышающим значения
2,0 руб., составляет 60 единиц. Тогда
m
60, n
90, w
m/n
60 : 90
0,667;
2) рассчитаем
дисперсию доли в выборочной совокупности
w2
w(1
w)
0,667(1
0,667)
0,222;
3) средняя ошибка
выборки при использовании повторной
схемы отбора составит
![]()
Если предположить,
что была использована бесповторная
схема отбора, то средняя ошибка выборки
с учетом поправки на конечность
совокупности составит
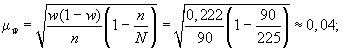
4) зададим
доверительную вероятность и определим
предельную ошибку выборки.
При значении
вероятности Р
0,997 по таблице нормального распределения
получаем значение для коэффициента
доверия t
3 (см. выдержку из нее, приведенную в
Приложении 1):
![]()
5) установим границы
для генеральной доли с вероятностью
0,997:

Таким образом, с
вероятностью 0,997 можно утверждать, что
в генеральной совокупности доля
предприятий с уровнем фондоотдачи, не
превышающим значения 2,0 руб., не меньше,
чем 54,7%, и не больше 78,7%.
2. Типическая
выборка. При
типической выборке генеральная
совокупность объектов разбита на k
групп, тогда
N1
N2
…
Ni
…
Nk
N.
Объем извлекаемых
из каждой типической группы единиц
зависит от принятого способа отбора;
их общее количество образует необходимый
объем выборки
n1
n2
…
ni
…
nk
n.
Существуют
следующие два способа организации
отбора внутри типической группы:
пропорциональной объему типических
групп и пропорциональной степени
колеблемости значений признака у единиц
наблюдения в группах. Рассмотрим первый
из них, как наиболее часто используемый.
Отбор, пропорциональный
объему типических групп, предполагает,
что в каждой из них будет отобрано
следующее число единиц совокупности:
![]()
где ni
количество извлекаемых единиц для
выборки из i-й
типической группы;
n
общий объем выборки;
Ni
количество единиц генеральной
совокупности, составивших i-ю
типическую группу;
N
общее количество единиц генеральной
совокупности.
Отбор единиц
внутри групп происходит в виде случайной
или механической выборки.
Формулы для
оценивания средней ошибки выборки для
среднего и доли представлены в табл.
11.2.
Таблица 2
Формулы для
расчета средней ошибки выборки ()
при использовании типического отбора,
пропорционального объему типических
групп
Здесь
![]()
средняя из групповых дисперсий типических
групп.
Пример 3. В
одном из московских вузов проведено
выборочное обследование студентов с
целью определения показателя средней
посещаемости вузовской библиотеки
одним студентом за семестр. Для этого
была использована 5%-ная бесповторная
типическая выборка, типические группы
которой соответствуют номеру курса.
При отборе, пропорциональном объему
типических групп, получены следующие
данные:
Число студентов,
которое необходимо обследовать на
каждом курсе, рассчитаем следующим
образом:
общий объем
выборочной совокупности:
![]()
количество
единиц, отобранных из каждой типической
группы:
![]()
аналогично для
других групп:
п2
31 (чел.);
п3
29 (чел.);
п4
18 (чел.);
п5
17 (чел.).
Проведем необходимые
расчеты.
1. Выборочная
средняя, исходя из значений средних
типических групп, составит:

2. Средняя из
внутригрупповых дисперсий
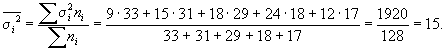
3. Средняя ошибка
выборки:
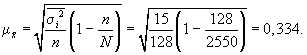
С вероятностью
0,954 находим предельную ошибку выборки:
![]()
4. Доверительные
границы для среднего значения признака
в генеральной совокупности:
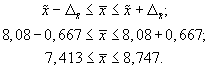
Таким образом, с
вероятностью 0,954 можно утверждать, что
один студент за семестр посещает
вузовскую библиотеку в среднем от семи
до девяти раз.
3.
Малая выборка. В
связи с небольшим объемом выборочной
совокупности
те формулы для определения ошибок
выборки,
которые использовались нами ранее при
«больших» выборках, становятся
неподходящими и требуют корректировки.
Среднюю ошибку
малой выборки
определяют по формуле
![]()
Предельная
ошибка малой выборки:
![]()
Распределение
значений выборочных средних всегда
имеет нормальный закон распределения
(или приближается к нему) при п
100, независимо от характера распределения
генеральной
совокупности.
Однако в случае малых выборок действует
иной закон распределения
распределение Стьюдента.
В этом случае коэффициент доверия
находится по таблице t-распределения
Стьюдента в зависимости от величины
доверительной вероятности Р
и объема выборки п.
В Приложении
1
приводится фрагмент таблицы t-распределения
Стьюдента, представленной в виде
зависимости доверительной вероятности
от объема выборки и коэффициента доверия
t.
Пример 4.
Предположим,
что выборочное обследование восьми
студентов академии показало, что на
подготовку к контрольной работе по
статистике они затратили следующее
количество часов: 8,5; 8,0; 7,8; 9,0; 7,2; 6,2; 8,4;
6,6.
Оценим выборочные
средние затраты времени и построим
доверительный интервал для среднего
значения признака в генеральной
совокупности, приняв доверительную
вероятность равной 0,95.
1. Среднее значение
признака в выборке равно
![]()
2. Значение среднего
квадратического отклонения составляет
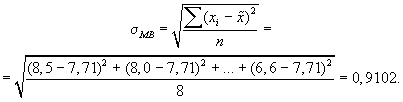
3. Средняя ошибка
выборки:
![]()
4. Значение
коэффициента доверия t
2,365 для п
8 и Р
0,95 (Приложение 1).
5. Предельная
ошибка выборки:
![]()
6. Доверительный
интервал для среднего значения признака
в генеральной совокупности:
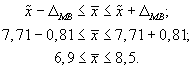
То есть с вероятностью
0,95 можно утверждать, что затраты времени
студента на подготовку к контрольной
работе находятся в пределах от 6,9 до 8,5
ч.
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
Содержание курса лекций “Статистика”
Выборочное наблюдение как источник статистической информации в изучении социально-экономических явлений и процессов

Статистическая методология исследования массовых явлений различает, как известно, два способа наблюдения в зависимости от полноты охвата объекта: сплошное и несплошное. Разновидностью несплошного наблюдения является выборочное, которое в условиях рыночных отношений в России находит все более широкое применение. Переход статистики РФ на международные стандарты системы национального счетоводства требует более широкого применения выборки для получения и анализа показателей СНС не только в промышленности, но и в других секторах экономики.
Под выборочным наблюдением понимается несплошное наблюдение, при котором статистическому обследованию (наблюдению) подвергаются единицы изучаемой совокупности, отобранные случайным способом. Выборочное наблюдение ставит перед собой задачу ‑ по обследуемой части дать характеристику всей совокупности единиц при условии соблюдения всех правил и принципов проведения статистического наблюдения и научно организованной работы по отбору единиц.
К выборочному наблюдению статистика прибегает по различным причинам. На современном этапе появилось множество субъектов хозяйственной деятельности, которые характерны для рыночной экономики. Речь идет об акционерных обществах, малых и совместных предприятиях, фермерских хозяйствах и т.д. Сплошное обследование этих статистических совокупностей, состоящих из десятков и сотен тысяч единиц, потребовало бы огромных материальных, финансовых и иных затрат. Использование же выборочного обследования позволяет значительно сэкономить силы и средства, что имеет немаловажное значение.
Наряду с экономией ресурсов одной из причин превращения выборочного наблюдения в важнейший источник статистической информации является возможность значительно ускорить получение необходимых данных. Ведь при обследовании, скажем, 10% единиц совокупности будет затрачено гораздо меньше времени, а результаты могут быть представлены быстрее, и будут более актуальными. Фактор времени важен для статистического исследования особенно в условиях изменяющейся социально-экономической ситуации.
Реализация выборочного метода базируется на понятиях генеральной и выборочной совокупностей.
Генеральной совокупностью называется вся исходная изучаемая статистическая совокупность, из которой на основе отбора единиц или групп единиц формируется совокупность выборочная. Поэтому генеральную совокупность также называют основой выборки.
Отбор единиц в выборочную совокупность может быть повторным или бесповторным.
При повторном отборе попавшая в выборку единица подвергается обследованию, т.е. регистрации значений ее признаков, возвращается в генеральную совокупность и наравне с другими единицами участвует в дальнейшей процедуре отбора. Таким образом, некоторые единицы могут попадать в выборку дважды, трижды или даже большее число раз. И при изучении выборочной совокупности они будут рассматриваться как отдельные независимые наблюдения.
Отметим, что число единиц генеральной совокупности, участвующих в отборе, при таком подходе остается постоянным. Поэтому вероятность попадания в выборку для всех единиц совокупности на протяжении всего процесса отбора также не меняется.
На практике методология повторного отбора обычно используется в тех случаях, когда объем генеральной совокупности не известен и теоретически возможно повторение единиц с уже встречавшимися значениями всех регистрируемых признаков.
Например, при проведении маркетинговых исследований мы не можем сколько-нибудь точно оценить, какое число потребителей предпочитают стиральный порошок конкретной торговой марки, сколько покупателей предпочитают делать покупки именно в данном супермаркете и т.д. Поэтому возможно повторение совершенно идентичных единиц как по причине практически неограниченных объемов совокупности, так и вследствие возможной повторной регистрации. Предположим, при проведении обследования один и тот же покупатель может дважды прийти в магазин и дважды подвергнуться обследованию.
При выборочном контроле качества продукции объем генеральной совокупности также часто не определен, так как процесс производства может осуществляться постоянно, каждый день дополняя генеральную совокупность новыми единицами-изделиями. Поэтому в выборочную совокупность могут попасть два и более изделий с абсолютно одинаковыми характеристиками. Следовательно, и в этом случае при обработке результатов выборки необходимо ориентироваться на методологию, используемую при повторном отборе.
При бесповоротном отборе попавшая в выборку единица подвергается обследованию и в дальнейшей процедуре отбора не участвует. Такой отбор целесообразен и практически возможен в тех случаях, когда объем генеральной совокупности четко определен. Получаемые при этом результаты, как правило, являются более точными по сравнению с результатами, основанными на повторной выборке.
Как уже отмечалось выше, выборочное наблюдение всегда связано с определенными ошибками получаемых характеристик. Эти ошибки называются ошибками репрезентативности (представительности).
Ошибки репрезентативности обусловлены тем обстоятельством, что выборочная совокупность не может по всем параметрам в точности воспроизвести совокупность генеральную. Получаемые расхождения или ошибки репрезентативности позволяют заключить, в какой степени попавшие в выборку единицы могут представлять всю генеральную совокупность. При этом следует различать систематические и случайные ошибки репрезентативности.
Систематические ошибки репрезентативности связаны с нарушением принципов формирования выборочной совокупности. Например, вследствие каких-либо причин, связанных с организацией отбора, в выборку попали единицы, характеризующиеся несколько большими или, наоборот, несколько меньшими по сравнению с другими единицами значениями наблюдаемых признаков. В этом случае и рассчитанные выборочные характеристики будут завышенными или заниженными.
Случайные ошибки репрезентативности обусловлены действием случайных факторов, не содержащих каких-либо элементов системности в направлении воздействия на рассчитываемые выборочные характеристики. Но даже при строгом соблюдении всех принципов формирования выборочной совокупности выборочные и генеральные характеристики будут несколько различаться. Получаемые случайные ошибки могут быть статистически оценены и учтены при распространении результатов выборочного наблюдения на всю генеральную совокупность. Оценка ошибок выборочного наблюдения основана на теоремах теории вероятностей.
При дальнейшем рассмотрении теории и методов выборочного наблюдения используются следующие общепринятые условные обозначения:
N ‑ объем (число единиц) генеральной совокупности;
n ‑ объем (число единиц) выборочной совокупности;
![]()
‑ генеральная средняя, т.е. среднее значение изучаемого признака по генеральной совокупности (средняя прибыль, средняя величина активов, средняя численность работников предприятия и т.п.);
![]()
‑ выборочная средняя,
т.е. среднее значение изучаемого признака по выборочной совокупности;
М ‑ численность единиц генеральной совокупности, обладающих определенным вариантом или вариантами изучаемого признака (численность городского населения, численность сельского населения, количество бракованных изделий, число нерентабельных предприятий и т.п.);
р ‑ генеральная доля, т.е. доля единиц, обладающих определенным вариантом или вариантами изучаемого признака, во всей генеральной совокупности (доля городского населения в общей численности населения, доля бракованной продукции в общем выпуске, доля нерентабельных предприятий в общей численности предприятий и т.п.); определяетcя как
m ‑ численность единиц выборочной совокупности, обладающих определенным вариантом или вариантами изучаемого признака;
w ‑ выборочная доля, т.е. доля единиц, обладающих определенным вариантом или вариантами изучаемого признака, в выборочной совокупности,
определяется как ;
![]()
‑ средняя ошибка выборки;
![]()
‑ предельная ошибка выборки;
![]()
‑ коэффициент доверия, определяемый в зависимости от уровня вероятности.
Ошибка выборки или отклонение выборочной средней от средней генеральной находится в прямой зависимости от дисперсии изучаемого признака в генеральной совокупности, и в обратной зависимости ‑ от объема выборки.
Таким образом среднюю ошибку выборки можно представить как

(10.1)
При проведении выборочного наблюдения дисперсия изучаемого признака в генеральной совокупности, как правило, не известна. В то же время, между генеральной дисперсией и средней из всех возможных выборочных дисперсий существует следующее соотношение:

(10.2)
В связи с тем, что на практике в большинстве случаев из генеральной совокупности в определенный момент времени производится только одна выборка, дисперсия изучаемого признака по этой выборке и используется при расчете ошибки.
Учитывая, что при достаточно большом объеме выборки отношение  близко к 1, формула средней ошибки повторной выборки принимает следующий вид:
близко к 1, формула средней ошибки повторной выборки принимает следующий вид:

(10.3)
Где ‑ ![]() дисперсия изучаемого признака по выборочной совокупности.
дисперсия изучаемого признака по выборочной совокупности.
При определении возможных границ значений характеристик генеральной совокупности рассчитывается предельная ошибка выборки, которая зависит от величины ее средней ошибки и уровня вероятности, с которым гарантируется, что генеральная средняя не выйдет за указанные границы.
Согласно теореме А.М. Ляпунова, вероятность той или иной величины предельной ошибки, при достаточно большом объеме выборочной совокупности, подчиняется нормальному закону распределения и может быть определена на основе интеграла Лапласа.
Значения интеграла Лапласа при различных величинах t табулированы и представлены в статистических справочниках.
При обобщении результатов выборочного наблюдения наиболее часто используются следующие уровни вероятности и соответствующие им значения t:
Таблица 10.1 ‑ !!!Некоторые значения t
| Вероятность, рi. | 0,683 | 0,866 | 0,954 | 0,988 | 0,997 | 0,999 |
| Значение t | 1,0 | 1,5 | 2,0 | 2,5 | 3,0 | 3,5 |
Например, если при расчете предельной ошибки выборки мы используем значение t=2, то с вероятностью 0,954 можно утверждать, что расхождение между выборочной средней и генеральной средней не превысит двукратной величины средней ошибки выборки.
Теоретической основой для определения границ генеральной доли, т.е. доли единиц, обладающих тем или иным вариантом признака, является теорема Вернули. Согласно данной теореме вероятность получения сколь угодно малого расхождения между выборочной долей и генеральной долей при достаточно большом объеме выборки будет стремиться к единице. С учетом того, что вероятность расхождения между выборочной и генеральной долями подчиняется нормальному закону распределения, эта вероятность также определяется по функции F(t) при заданном значении t.
Процесс подготовки и проведения выборочного наблюдения включает ряд последовательных этапов:
- Определение цели обследования.
- Установление границ генеральной совокупности.
- Составление программы наблюдения и программы разработки данных
- Определение вида выборки, процента отбора и метода отбора
- Отбор и регистрация наблюдаемых признаков у отобранных единиц.
- Насчет выборочных характеристик и их ошибок.
- Распространение полученных результатов на генеральную совокупность.
В зависимости от состава и структуры генеральной совокупности выбирается вид выборки или способ отбора.
К наиболее распространенным на практике видам относятся:
- собственно-случайная (простая случайная) выборка;
- механическая (систематическая) выборка;
- типическая (стратифицированная, расслоенная) выборка;
- серийная (гнездовая) выборка.
Отбор единиц из генеральной совокупности может быть комбинированным, многоступенчатым и многофазным.
Комбинированный отбор предполагает объединение нескольких видов выборки. Так, например, можно комбинировать типическую и серийную, серийную и собственно-случайную выборки. Ошибка такой выборки определяется ступенчатостью отбора.
Многоступенчатым называется отбор, при котором из генеральной совокупности сначала извлекаются укрупненные группы, потом ‑ более мелкие и так до тех пор, пока не будут отобраны те единицы, которые подвергаются обследованию.
Многофазная выборка, в отличие от многоступенчатой, предполагает сохранение одной и той же единицы отбора на всех этапах его проведения; при этом отобранные на каждой стадии единицы подвергаются обследованию, каждый раз – по более расширенной программе.
Собственно-случайная (простая случайная) выборка заключается в отборе единиц из генеральной совокупности наугад или наудачу без каких-либо элементов системности.
Однако прежде чем производить собственно-случайный отбор, необходимо убедиться, что все без исключения единицы генеральной совокупности имеют абсолютно равные шансы попадания в выборку, в списках или перечне отсутствуют пропуски, игнорирования отдельных единиц и т.п. Следует также установить четкие границы генеральной совокупности таким образом, чтобы включение или не включение в нее отдельных единиц не вызывало сомнений. Так, например, при обследовании студентов необходимо указать, будут ли приниматься во внимание лица, находящиеся в академическом отпуске, студенты негосударственных вузов, военных училищ и т.п.; при обследовании торговых предприятий важно определиться, включит ли генеральная совокупность торговые павильоны, коммерческие палатки и прочие подобные объекты.
Технически собственно-случайный отбор проводят методом жеребьевки или по таблице случайных чисел.
Расчет ошибок позволяет решить одну из главных проблем организации выборочного наблюдения – оценить репрезентативность (представительность) выборочной совокупности.
Различают среднюю и предельную ошибки выборки. Эти два вида связаны следующим соотношением:

(10.4)
Величина средней ошибки выборки рассчитывается дифференцированно в зависимости от способа отбора и процедуры выборки.
Так, при собственно-случайном повторном отборе средняя ошибка определяется по формуле:

(10.5)
а при расчете средней ошибки собственно-случайной бесповторной выборки:

(10.6)
Расчет средней и предельной ошибок выборки позволяет определить возможные пределы, в которых будут находиться характеристики генеральной совокупности.
Например, для выборочной средней такие пределы устанавливаются на основе следующих соотношений:

(10.7)
где ![]() и
и ![]() ‑ генеральная и выборочная средняя соответственно;
‑ генеральная и выборочная средняя соответственно;
![]() ‑ предельная ошибка выборочной средней.
‑ предельная ошибка выборочной средней.
Пример.
При проверке веса импортируемого груза на таможне методом случайной повторной выборки было отобрано 200 изделий. В результате был установлен средний вес изделия 30 г. при среднем квадратическом отклонении 4 г. С вероятностью 0,997 определите пределы, в которых находится средний вес изделия в генеральной совокупности.
Решение. Рассчитаем сначала предельную ошибку выборки. Так как при р = 0,997, t = 3, она равна:
Определим пределы генеральной средней:
 или
или

Вывод: Следовательно, с вероятностью 0,997 можно утверждать, что средний вес изделий в генеральной совокупности находится в пределах от 29,16 г. до 30,84 г.
Пример 2.
В городе проживает 250 тыс. семей. Для определения среднего числа детей в семье была организована 2%-ная случайная бесповторная выборка семей. По ее результатам было получено следующее распределение семей по числу детей:
Таблица 10.2 ‑ Распределение семей по числу детей в городе N
| Число детей в семье | 0 | 1 | 2 | 3 | 4 | 5 |
| Количество
семей |
1000 | 2000 | 1200 | 400 | 200 | 200 |
С вероятностью 0,954 определите пределы, в которых будет находиться среднее число детей в генеральной совокупности.
Решение. В начале на основе имеющегося распределения семей определим выборочные среднюю и дисперсию:
Таблица 10.3 ‑ Вспомогательная таблица для расчета среднего числа детей
|
Число детей в семье, х; |
Количество семей, f | ||||
|
0 1 2 3 4 5 |
1000 2000 1200 400 200 200 |
0
2000 2400 1200 800 1000 |
-1,5
-0,5 0,5 1,5 2,5 3,5 |
2,25
0,25 0,25 2,25 6,25 12,25 |
2250 500 300 900 1250 2450 |
|
Итого |
5000 | 7400 | – | – | 7650 |


Вычислим теперь предельную ошибку выборки (с учетом того, что при р = 0,954 t = 2).

Следовательно, пределы генеральной средней:

Таким образом, с вероятностью 0,954 можно утверждать, что среднее число детей в семьях города практически не отличается от 1,5, т.е. в среднем на каждые две семьи приходится три ребенка.
Наряду с определением ошибок выборки и пределов для генеральной средней эти же показатели могут быть определены для доли признака.
В этом случае особенности расчета связаны с определением дисперсии доли, которая вычисляется так:

(10.8)
где ![]() ‑ доля единиц, обладающих данным признаком в выборочной совокупности, определяемая как отношение количества соответствующих единиц к объему выборки.
‑ доля единиц, обладающих данным признаком в выборочной совокупности, определяемая как отношение количества соответствующих единиц к объему выборки.
Тогда, например, при собственно-случайном повторном отборе для определения предельной ошибки выборки используется следующая формула:

(10.9)
Соответственно, при бесповторном отборе:

(10.10)
Пределы доли признака в генеральной совокупности p выглядят следующим образом:

(10.11)
Рассмотрим пример.
С целью определения средней фактической продолжительности рабочего дня в государственном учреждении с численностью служащих 480 человек, в январе 2009 г. было проведена 25%-ная случайная бесповторная выборка. По результатам наблюдения оказалось, что у 10% обследованных потери времени достигали более 45 мин. в день. С вероятностью 0,683 установите пределы, в которых находится генеральная доля служащих с потерями рабочего времени более 45 мин. в день.
Решение. Определим объем выборочной совокупности:
n= 480 х 0,25 = 120 чел.
Выборочная доля w равна по условию 10%.
Учитывая, что при р = 0,683 t=1, вычислим предельную ошибку выборочной доли:

Пределы доли признака в генеральной совокупности:

Таким образом, с вероятностью 0,683 можно утверждать, что доля работников учреждения с потерями рабочего времени более 45 мин. в день находится в пределах от 7,6% до 12,4%.
Мы рассмотрели определение границ генеральной средней и генеральной доли по результатам уже проведенного выборочного наблюдения, при известном объеме выборки или проценте отбора. На этапе же проектирования выборочного наблюдения именно объем выборочной совокупности и требует определения.
Для определения необходимого объема собственно-случайной повторной выборки применяют следующую формулу:

(10.12)
Полученный на основе использования данной формулы результат всегда округляется в большую сторону. Например, если мы получили, что необходимый объем выборки составляет 493,1 единицы, то обследовав 493 единицы мы не достигнем требуемой точности. Поэтому, для достижения желаемого результата обследованием должны быть охвачены 494 единицы.
С другой стороны, рассчитанное значение необходимого объема выборки свободно может быть увеличено в большую сторону на несколько единиц. Если мы располагаем необходимыми ресурсами, если по причинам организационного порядка (компактность расположения единиц, фиксированная нагрузка на каждого регистратора и т.п.) мы вполне можем охватить больший объем, то включение в выборочную совокупность 500 или, например, 550 единиц только уменьшит значения полученных случайной и предельной ошибок.
При определении необходимого объема выборки для определения границ генеральной доли задача оценки вариации решается значительно проще. Если дисперсия изучаемого альтернативного признака неизвестна, то можно использовать ее максимальное возможное значение:

Например, предприятию связи с вероятностью 0,954 необходимо определить удельный вес телефонный разговоров продолжительностью менее 1 минуты с предельной ошибкой 2%. Сколько разговоров нужно обследовать в порядке собственно-случайного повторного отбора для решения этой задачи?
Для получения ответа на поставленный вопрос воспользуемся формулой (10.12) и будем ориентироваться на максимальную возможную дисперсию доли телефонных разговоров такой продолжительности. Расчет приводит к следующему результату:

Таким образом, обследованием должны быть охвачены не менее 2500 разговоров на предмет их продолжительности.
Необходимый объем собственно-случайной бесповторной выборки может быть определен по следующей формуле:

(10.13)
Укажем на одну особенность формулы (10.13). При проведении вычислений объем генеральной совокупности должен быть выражен только в единицах, а не в тысячах или в миллионах единиц.
Например, подставив в данную формулу общую численность населения региона, выраженную в тысячах человек, мы не получим правильное значение необходимой численности выборки, также выраженное в тысячах человек, как это иногда бывает в других расчетах. Результат вычислений будет неверен.
Механическая выборка может быть применена в тех случаях, когда генеральная совокупность каким-либо образом упорядочена, т.е. имеется определенная последовательность в расположении единиц (табельные номера работников, списки избирателей, телефонные номера респондентов, номера домов и квартир и т.п.). Для проведения отбора желательно, чтобы все единицы также имели порядковые номера от 1 до N.
Для проведения механической выборки устанавливается пропорция отбора, которая определяется соотнесением объемов выборочной и генеральной совокупностей.
Так, если из совокупности в 500000 единиц предполагается отобрать 10000 единиц, то пропорция отбора составит

Отбор единиц осуществляется в соответствии с установленной пропорцией через равные интервалы.
Например, при пропорции 1:50 (2%-ная выборка) отбирается каждая 50-я единица, при пропорции 1:20 (5%-ная выборка) – каждая 20-я единица и т.д.
Интервал отбора также можно определить как частное от деления 100% на установленный процент отбора.
Так, например при 2%-ном отборе интервал составит 50 (100%:2%), при 4%-ном отборе ‑ 25 (100%:4%). В тех случаях, когда результат деления получается дробным, сформировать выборку механическим способом при строгом соблюдении процента отбора не представляется возможным.
Например, по этой причине нельзя сформировать 3%-ную или 6%-ную выборки.
Генеральную совокупность при механическом отборе можно ранжировать или упорядочить по величине изучаемого или коррелирующего с ним признака, что позволит повысить репрезентативность выборки. Однако в этом случае возрастает опасность систематической ошибки, связанной с занижением значений изучаемого признака (если из каждого интервала регистрируется первое значение) или его завышением (если из каждого интервала регистрируется последнее значение). Поэтому целесообразно из каждого интервала отбирать центральную или одну из двух центральных единиц.
Например, при 5%-ной выборке интервал отбора составит 20 единиц, тогда отбор целесообразно начинать с 10-й или с 11-й единицы. В первом случае в выборку попадут 10, 30, 50, 70 и с таким же интервалом последующие единицы; во втором случае – единицы с номерами 11,31,51,71 и т.д.
При механической выборке также может появиться опасность систематической ошибки, обусловленной случайным совпадением выбранного интервала и циклических закономерностей в расположении единиц генеральной совокупности. Так, при переписи населения 1989 г. в ходе 25%-го выборочного обследования семей имела место опасность попадания в выборку квартир только одного типа (например, только однокомнатных или только трехкомнатных), так как на лестничных площадках многих типовых домов располагаются именно по 4 квартиры. Чтобы избежать систематической ошибки, в каждом новом подъезде счетчик менял начало отбора.
Для определения средней ошибки механической выборки, а также необходимой ее численности, используются соответствующие формулы, применяемые при собственно-случайном бесповторном отборе(10.6 и 10.13). При этом, определив необходимую численность выборки и сопоставив ее с объемом генеральной совокупности, как правило, приходится производить соответствующее округление для получения целочисленного интервала отбора.
Например, в области зарегистрировано 12000 фермерских хозяйств. Определим, сколько из них нужно отобрать в порядке механического отбора для определения средней площади сельхозугодий с ошибкой ± 2 га. (Р=0,997). По результатам ранее проведенного обследования известно, что среднее квадратическое отклонение площади сельхозугодий составляет 8 га. Произведем расчет, воспользовавшись формулой (10.13).

С учетом полученного необходимого объема выборки (143 фермерских хозяйства) определим интервал отбора: 12000:143=83,9.
Определенный таким способом интервал всегда округляется в меньшую сторону, так как при округлении в большую сторону произведенная выборка не достигнет рассчитанного по формуле необходимого объема.
Следовательно, в нашем примере, из общего списка фермерских хозяйств необходимо отобрать для обследования каждое 83-е хозяйство. При этом процент отбора составит 1,2% (100% : 83).
Типический отбор целесообразно использовать в тех случаях, когда все единицы генеральной совокупности объединены в несколько крупных типических групп.. Такие группы также называют стартами или слоями, в связи с чем типический отбор также называют стратифицированным или расслоенным. При обследованиях населения в качестве типических групп могут быть выбраны области, районы, социальные, возрастные или образовательные группы, при обследовании предприятий – отрасли или подотрасли, формы собственности и т.п.
Рассматривать генеральную совокупность в разрезе нескольких крупных групп единиц имеет смысл только в том случае, если средние значения изучаемых признаков по группам существенно различаются. Например, с большой уверенностью можно предположить, что доходы населения крупного города будут в среднем выше доходов населения, проживающего в сельской местности; численность работников промышленного предприятия в среднем будет выше численности работников торгового или сельскохозяйственного предприятия; средний возраст студентов будет значительно меньше среднего возраста занятого населения и, тем более, пенсионеров. В то же время, нет никакого смысла при выделении типических групп ориентироваться на признак, не связанный или очень слабо связанный с изучаемым.
Отбор единиц в выборочную совокупность из каждой типической группы осуществляется собственно-случайным или механическим способом. Поскольку в выборочную совокупность в той или иной пропорции обязательно попадают представители всех групп, типизация генеральной совокупности позволяет исключить влияние межгрупповой дисперсии на среднюю ошибку выборки. В то же время, в выделенных типических группах обследуются далеко не все единицы, а только включенные в выборку. Следовательно, на величине полученной ошибки будет сказываться различие между единицами внутри этих групп, т.е. внутригрупповая вариация. Поэтому, ошибка типической выборки будет определяться величиной не общей дисперсии, а только ее части – средней из внутригрупповых дисперсий.
При типической выборке, пропорциональной объему типических групп, число единиц, подлежащих отбору из каждой группы, определяется следующим образом:

(10.14)
Где Ni – объем i-ой группы. а ni ‑ объем выборки из i-ой группы.
Пример. Предположим, общая численность населения области составляет 1,5 млн. чел., в том числе городское – 900 тыс. чел. и сельское – 600 тыс. чел. Если в ходе выборочного наблюдения планируется обследовать 100 тыс. жителей, то эта численность должна быть поделена пропорционально объему типических групп следующим образом:

Средняя ошибка типической выборки определяется по формулам:

(10.15)
 (10.16)
(10.16)
где ![]() – средняя из внутригрупповых дисперсий.
– средняя из внутригрупповых дисперсий.
При выборке, пропорциональной дифференциации признака, число наблюдений по каждой группе рассчитывается по формуле:

(10.17)
Где ![]() ‑ среднее отклонение признака в i-ой группе.
‑ среднее отклонение признака в i-ой группе.
Cредняя ошибка такого отбора определяется следующим образом:

(10.18)

(10.19)
Отбор, пропорциональный дифференциации признака, дает лучшие результаты, однако на практике его применение затруднено вследствие трудности получения сведений о вариации до проведения выборочного наблюдения.
Таблица 10.4 ‑ Результаты обследования рабочих предприятия
| Цех | Всего рабочих, человек | Обследовано, человек | Число дней временной нетрудоспособности за год | |
| средняя | дисперсия | |||
| I
II III |
1000
1400 800 |
100
140 80 |
18
12 15 |
49
25 16 |
Рассмотрим оба варианта типической выборки на условном примере. Предположим, 10% бесповторный типический отбор рабочих предприятия, пропорциональный размерам цехов, проведенный с целью оценки потерь из-за временной нетрудоспособности, привел к следующим результатам (табл. 10.4)
Рассчитаем среднюю из внутригрупповых дисперсий:

Определим среднюю и предельную ошибки выборки (с вероятностью 0,954):

Рассчитаем выборочную среднюю:

С вероятностью 0,954 можно сделать вывод, что среднее число дней временной нетрудоспособности одного рабочего в целом по предприятию находится в пределах:

Воспользуемся полученными внутригрупповыми дисперсиями для проведения отбора пропорционального дифференциации признака. Определим необходимый объем выборки по каждому цеху:


С учетом полученных значений рассчитаем среднюю ошибку выборки:

В данном случае средняя, а следовательно, и предельная ошибки будут несколько меньше, что отразится и на границах генеральной средней.
Серийный отбор. Данный способ отбора удобен в тех случаях, когда единицы совокупности объединены в небольшие группы или серии. В качестве таких серий могут рассматриваться упаковки с определенным количеством готовой продукции, партии товара, студенческие группы, бригады и другие объединения. Сущность серийной выборки заключается в собственно-случайном или механическом отборе серий, внутри которых производится сплошное обследование единиц.
Поскольку внутри групп (серий) обследуются все без исключения единицы, средняя ошибка серийной выборки (при отборе равновеликих серий) зависит от величины только межгрупповой (межсерийной) дисперсии и определяется по следующим формулам:

(10.20)

(10.21)
Где r ‑ число отобранных серий; R ‑ общее число серий.
Межгрупповую дисперсию вычисляют следующим образом:
 (10.22)
(10.22)
где ![]() ‑ средняя i-й серии;
‑ средняя i-й серии;
![]() ‑ общая средняя по всей выборочной совокупности.
‑ общая средняя по всей выборочной совокупности.
Пример.
В области, состоящей из 20 районов, проводилось выборочное обследование урожайности на основе отбора серий (районов). Выборочные средние по районам составили соответственно 14,5 ц/га; 16 ц/га; 15,5 ц/га; 15 ц/га и 14 ц/га. С вероятностью 0,954 определите пределы урожайности во всей области.
Решение. Рассчитаем общую среднюю:

Межгрупповая (межсерийная) дисперсия равна:

Определим теперь предельную ошибку серийной бесповторной выборки (t = 2 при р = 0,954):

Вывод: Следовательно, урожайность будет с вероятностью 0,954 находиться в пределах:

Определение необходимого объема выборки
При проектировании выборочного наблюдения возникает вопрос о необходимой численности выборки. Эта численность может быть определена на базе допустимой ошибки при выборочном наблюдении, исходя из вероятности, на основе которой можно гарантировать величину устанавливаемой ошибки, и, наконец, на базе способа отбора.
Формулы необходимого объема выборки для различных способов формирования выборочной совокупности могут быть выведены из соответствующих соотношений, используемых при расчете предельных ошибок выборки. Приведем наиболее часто применяемые на практике выражения необходимого объема выборки:
– собственно-случайная и механическая выборка:

(10.23)

(10.24)
– типическая выборка:

(10.25)

(10.26)
– серийная выборка:

(10.27)

(10.28)
При этом в зависимости от целей исследования дисперсии и ошибки выборки могут быть рассчитаны для средней величины или доли признака.
Рассмотрим примеры определения необходимого объема выборки при различных способах формирования выборочной совокупности.
Пример.
В 100 туристических агентствах города предполагается провести обследование среднемесячного количества реализованных путевок методом механического отбора. Какова должна быть численность выборки, чтобы с вероятностью 0,683 ошибка не превышала 3 путевок, если по данным пробного обследования дисперсия составляет 225.
Решение. Рассчитаем необходимый объем выборки:

Пример.
С целью определения доли сотрудников коммерческих банков области в возрасте старше 40 лет предполагается организовать типическую выборку пропорциональную численности сотрудников мужского и женского пола с механическим отбором внутри групп. Общее число сотрудников банков составляет 12 тыс. чел., в том числе 7 тыс. мужчин и 5 тыс. женщин.
На основании предыдущих обследований известно, что средняя из внутригрупповых дисперсий составляет 1600. Определите необходимый объем выборки при вероятности 0,997 и ошибке 5%.
Решение. Рассчитаем общую численность типической выборки:

Вычислим теперь объем отдельных типических групп:

Вывод: Таким образом, необходимый объем выборочной совокупности сотрудников банков составляет 550 чел., в т.ч. 319 мужчин и 231 женщина.
Пример.
В акционерном обществе 200 бригад рабочих. Планируется проведение выборочного обследования с целью определения удельного веса рабочих, имеющих профессиональные заболевания. Известно, что межсерийная дисперсия доли равна 225. С вероятностью 0,954 рассчитайте необходимое количество бригад для обследования рабочих, если ошибка выборки не должна превышать 5%.
Решение. Необходимое количество бригад рассчитаем на основе формулы объема серийной бесповторной выборки:

Содержание курса лекций “Статистика”
Контрольные задания
Самостоятельно проведите выборочное наблюдение и произведите соответствующие расчеты.
Предельная ошибка выборки
Предельная ошибка — максимально возможное расхождение средних или максимум ошибок при заданной вероятности ее появления.
1. Предельную ошибку выборки для средней при повторном отборе в контрольных по статистике в ВУЗах рассчитывают по формуле:

где t — нормированное отклонение — «коэффициент доверия», который зависит от вероятности, гарантирующей предельную ошибку выборки;
мю х — средняя ошибка выборки.
2. Предельная ошибка выборки для доли при повторном отборе определяется по формуле:

3. Предельная ошибка выборки для средней при бесповторном отборе:

4. Предельная ошибка выборки для доли при бесповторном отборе:

Предельная относительная ошибка выборки
Предельную относительную ошибку выборки определяют как процентное соотношение предельной ошибки выборки к соответствующей характеристике выборочной совокупности. Она определяется таким образом:

Малая выборка
Теория малых выборок была разработана английским статистиком Стьюдентом в начале 20 века. В 1908 г. он выявил специальное распределение, которое позволяет и при малых выборках соотносить t и доверительную вероятность F(t). При n больше 100 дают такие же результаты, что и таблицы интеграла вероятностей Лапласа, при 30 < n < 100 различия получаются незначительные. Поэтому на практике к малым выборкам относятся выборки объемом менее 30 единиц.

Средняя и предельная ошибки для малой выборки
В малой выборке средняя ошибка рассчитывается по формуле:

Предельная ошибка малой выборки рассчитывается по формуле:

где t — отношение Стьюдента
Источник: Балинова B.C. Статистика в вопросах и ответах: Учеб. пособие. — М.: ТК. Велби, Изд-во Проспект, 2004. — 344 с.
Материалы сайта
Обращаем Ваше внимание на то, что все материалы опубликованы для образовательных целей.