
Уровень
значимости — это вероятность того, что
мы сочли различия существенными, а они
на самом деле случайны.
Когда
мы указываем, что различия достоверны
на 5%-ом уровне значимости, или при р<0,05,
то мы имеем виду, что вероятность того,
что они все-таки недостоверны, составляет
0,05.
Когда
мы указываем, что различия достоверны
на 1%-ом уровне значимости, или при р<0,01,
то мы имеем в виду, что вероятность того,
что они все-таки недостоверны, составляет
0,01.
Если
перевести все это на более формализованный
язык, то уровень значимости — это
вероятность отклонения нулевой гипотезы,
в то время как она верна.
Ошибка,
состоящая в том, что мы отклонили нулевую
гипотезу, в то время как она верна,
называется ошибкой 1 рода.
Вероятность
такой ошибки обычно обозначается как
а. В сущности, мы должны были бы указывать
в скобках не р<0,05 или р<0,01, а а<0,05
или <Х<0,01. В некоторых руководствах
так и делается (Рунион Р., 1982; Захаров
В.П., 1985 и др.).
Если
вероятность ошибки — это а, то вероятность
правильного решения: 1—а. Чем меньше а,
тем больше вероятность правильного
решения.
Исторически
сложилось так, что в психологии принято
считать низшим уровнем статистической
значимости 5%-ый уровень (р<0,05): достаточным
— 1%-ый уровень (р^О.01) и высшим 0,1% -ый
уровень (р<0,001), поэтому в таблицах
критических значений обычно приводятся
значения критериев, соответствующих
уровням статистической значимости
р<0,05 и р<0,01, иногда — р<0,001. Для
некоторых критериев в таблицах указан
точный уровень значимости их разных
эмпирических значений. Например, для
ф*=1,56 р=0,06.
До
тех пор, однако, пока уровень статистической
значимости не достигнет р=0,05, мы еще не
имеем права отклонить нулевую гипотезу.
Правило
отклонения HQ и принятия Hi
Если
эмпирическое значение критерия равняется
критическому значению, соответствующему
р^0,05 или превышает его, то HQ отклоняется,
но мы еще не можем определенно принять
W.
Если
эмпирическое значение критерия равняется
критическому значению, соответствующему
р<0,01 или превышает его, то HQ отклоняется
и принимается Н^.
Исключения:
критерий
знаков G, критерий Т Вилкоксона и критерий
U Манна-Уитни. Для них устанавливаются
обратные соотношения. Для облегчения
процесса принятия решения можно всякий
раз вычерчивать «ось значимости».

Критические
значения критерия обозначены как Qo,O5 и
Qo,O1> эмпирическое значение критерия
как QaMn. Оно заключено в эллипс.
Вправо
от критического значения Qo.oi простирается
«зона значимости» — сюда попадают
эмпирические значения, превышающие
Qooi и, следовательно, безусловно значимые.
Влево
от критического значения Qo,O5 простирается
«зона незначимое™», — сюда попадают
эмпирические значения Q, которые ниже
Qo,O5′ и≫
следовательно, безусловно незначимы.
Мы видим, что Qo,o5=6; Qo.oi=9; Q9Mn=8.
Эмпирическое
значение критерия попадает в область
между Qo,O5 и Qo.oi- Это зона «неопределенности»:
мы уже можем отклонить гипотезу о
недостоверности различий (HQ), НО еще не
можем принять гипотезы об их достоверности
(Hf).
Практически,
однако, исследователь может считать
достоверными уже те различия, которые
не попадают в зону незначимости, заявив,
что они достоверны при р<0,05, или указав
точный уровень значимости полученного
эмпирического значения критерия,
например: р=0,02. С помощью таблиц Приложения
1 это можно сделать по отношению к
критериям Н Крускала-Уоллиса, у}г
Фридмана,
L Пейджа, ф* Фишера, X
Колмогорова.
Уровень
статистической значимости или критические
значения критериев определяются
по-разному при проверке направленных
и ненаправленных статистических гипотез.
При направленной статистической гипотезе
используется односторонний критерий,
при ненаправленной гипотезе — двусторонний
критерий. Двусторонний критерий более
строг, поскольку он проверяет различия
в обе стороны, и поэтому то эмпирическое
значение критерия, которое ранее
соответствовало уровню значимости
р<0,05, теперь соответствует лишь уровню
р<0,10.
Билет 9 Параметрические
и непараметрические методы. Мощность
критериев
-
Параметрические и непараметрические
методы
Методы обучения, т.е. нахождения достаточно
хорошей распознающей функ-
ции f 2 F, традиционно подразделяются на
параметрические и непарамет-
рические в соответствии с тем, просто
или сложно устроено пространство F.
Параметрические — это те методы, в
которых F = fF(w; ¢)jw 2 Wg для неко-
торого достаточно удобного (например,
евклидова) пространства параметров
W и некоторой функции F: W £ X ! Y, а
непараметрические — это мето-
ды, в которых, якобы, пространство F не
зафиксировано заранее, а зависит
от обучающего набора T. На самом деле
разница между параметрическими и
непараметрическими методами — только
в употребляемых словах.
Полезный пример параметрических методов
— методы обучения линейных
распознавателей, которых даже для
простейшей линейной регрессии (X = Rd,
Y
= R,
W
= R
£ Rd,
F(w;
x)
= w0
+Pdj=1
wjxj) довольно много. Подробнее
эти методы рассматриваются в разделе
2.
[А.Б. Мерков]
непараметрические
методы в
математической статистике, методы
непосредственной оценки теоретического
распределения вероятностей и тех или
иных его общих свойств (симметрии и
т.п.) по результатам наблюдений. Название
Н. м. подчёркивает их отличие от
классических (параметрических)
методов, в которых
предполагается, что неизвестное
теоретическое распределение принадлежит
какому-либо семейству, зависящему от
конечного числа параметров (например,
семейству нормальных распределений, и
которые позволяют по результатам
наблюдений оценивать неизвестные
значения этих параметров и проверять
те или иные гипотезы относительно их
значений. Разработка Н. м. является в
значительной степени заслугой советских
учёных.
-
Мощность критериев
Мощность критерия — это его способность
выявлять различия, если они есть. Иными
словами, это его способность отклонить
нулевую гипотезу об отсутствии различий,
если
она неверна.
Ошибка, состоящая в том, что мы приняли
нулевую гипотезу, в то время как
она неверна, называется ошибкой II рода.
Вероятность такой ошибки обозначается
как β. Мощность критерия — это его
способность не допустить ошибку II рода,
поэтому:
Мощность=1—β
Мощность критерия определяется
эмпирическим путем. Одни и те же задачи
могут
быть решены с помощью разных критериев,
при этом обнаруживается, что некоторые
критерии позволяют выявить различия
там, где другие оказываются неспособными
это
сделать, или выявляют более высокий
уровень значимости различий. Возникает
вопрос: а
зачем же тогда использовать менее
мощные критерии? Дело в том, что
основанием для
выбора критерия может быть не только
мощность, но и другие его характеристики,
а
именно:
а) простота;
б) более широкий диапазон использования
(например, по отношению к данным,
определенным по номинативной шкале,
или по отношению к большим n);
в) применимость по отношению к неравным
по объему выборкам;
г) большая информативность результатов.
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
Результат любого измерения не определён однозначно и имеет случайную составляющую.
Поэтому адекватным языком для описания погрешностей является язык вероятностей.
Тот факт, что значение некоторой величины «случайно», не означает, что
она может принимать совершенно произвольные значения. Ясно, что частоты, с которыми
возникает те или иные значения, различны. Вероятностные законы, которым
подчиняются случайные величины, называют распределениями.
2.1 Случайная величина
Случайной будем называть величину, значение которой не может быть достоверно определено экспериментатором. Чаще всего подразумевается, что случайная величина будет изменяться при многократном повторении одного и того же эксперимента. При интерпретации результатов измерений в физических экспериментах, обычно случайными также считаются величины, значение которых является фиксированным, но не известно экспериментатору. Например смещение нуля шкалы прибора. Для формализации работы со случайными величинами используют понятие вероятности. Численное значение вероятности того, что какая-то величина примет то или иное значение определяется либо как относительная частота наблюдения того или иного значения при повторении опыта большое количество раз, либо как оценка на основе данных других экспериментов.
Замечание.
Хотя понятия вероятности и случайной величины являются основополагающими, в литературе нет единства в их определении. Обсуждение формальных тонкостей или построение строгой теории лежит за пределами данного пособия. Поэтому на начальном этапе лучше использовать «интуитивное» понимание этих сущностей. Заинтересованным читателям рекомендуем обратиться к специальной литературе: [5].
Рассмотрим случайную физическую величину x, которая при измерениях может
принимать непрерывный набор значений. Пусть
P[x0,x0+δx] — вероятность того, что результат окажется вблизи
некоторой точки x0 в пределах интервала δx: x∈[x0,x0+δx].
Устремим интервал
δx к нулю. Нетрудно понять, что вероятность попасть в этот интервал
также будет стремиться к нулю. Однако отношение
w(x0)=P[x0,x0+δx]δx будет оставаться конечным.
Функцию w(x) называют плотностью распределения вероятности или кратко
распределением непрерывной случайной величины x.
Замечание. В математической литературе распределением часто называют не функцию
w(x), а её интеграл W(x)=∫w(x)𝑑x. Такую функцию в физике принято
называть интегральным или кумулятивным распределением. В англоязычной литературе
для этих функций принято использовать сокращения:
pdf (probability distribution function) и
cdf (cumulative distribution function)
соответственно.
Гистограммы.
Проиллюстрируем наглядно понятие плотности распределения. Результат
большого числа измерений случайной величины удобно представить с помощью
специального типа графика — гистограммы.
Для этого область значений x, размещённую на оси абсцисс, разобьём на
равные малые интервалы — «корзины» или «бины» (англ. bins)
некоторого размера h. По оси ординат будем откладывать долю измерений w,
результаты которых попадают в соответствующую корзину. А именно,
пусть k — номер корзины; nk — число измерений, попавших
в диапазон x∈[kh,(k+1)h]. Тогда на графике изобразим «столбик»
шириной h и высотой wk=nk/n.
В результате получим картину, подобную изображённой на рис. 2.1.
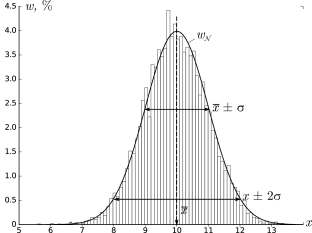
σ=1,0, h=0,1, n=104)
Высоты построенных столбиков будут приближённо соответствовать значению
плотности распределения w(x) вблизи соответствующей точки x.
Если устремить число измерений к бесконечности (n→∞), а ширину корзин
к нулю (h→0), то огибающая гистограммы будет стремиться к некоторой
непрерывной функции w(x).
Самые высокие столбики гистограммы будут группироваться вблизи максимума
функции w(x) — это наиболее вероятное значение случайной величины.
Если отклонения в положительную и отрицательную стороны равновероятны,
то гистограмма будет симметрична — в таком случае среднее значение ⟨x⟩
также будет лежать вблизи этого максимума. Ширина гистограммы будет характеризовать разброс
значений случайной величины — по порядку величины
она, как правило, близка к среднеквадратичному отклонению sx.
Свойства распределений.
Из определения функции w(x) следует, что вероятность получить в результате
эксперимента величину x в диапазоне от a до b
можно найти, вычислив интеграл:
| Px∈[a,b]=∫abw(x)𝑑x. | (2.1) |
Согласно определению вероятности, сумма вероятностей для всех возможных случаев
всегда равна единице. Поэтому интеграл распределения w(x) по всей области
значений x (то есть суммарная площадь под графиком w(x)) равен единице:
Это соотношение называют условием нормировки.
Среднее и дисперсия.
Вычислим среднее по построенной гистограмме. Если размер корзин
h достаточно мал, все измерения в пределах одной корзины можно считать примерно
одинаковыми. Тогда среднее арифметическое всех результатов можно вычислить как
Переходя к пределу, получим следующее определение среднего значения
случайной величины:
где интегрирование ведётся по всей области значений x.
В теории вероятностей x¯ также называют математическим ожиданием
распределения.
Величину
| σ2=(x-x¯)2¯=∫(x-x¯)2w𝑑x | (2.3) |
называют дисперсией распределения. Значение σ есть
срекднеквадратичное отклонение в пределе n→∞. Оно имеет ту
же размерность, что и сама величина x и характеризует разброс распределения.
Именно эту величину, как правило, приводят как характеристику погрешности
измерения x.
Доверительный интервал.
Обозначим как P|Δx|<δ вероятность
того, что отклонение от среднего Δx=x-x¯ составит величину,
не превосходящую по модулю значение δ:
| P|Δx|<δ=∫x¯-δx¯+δw(x)𝑑x. | (2.4) |
Эту величину называют доверительной вероятностью для
доверительного интервала |x-x¯|≤δ.
2.2 Нормальное распределение
Одним из наиболее примечательных результатов теории вероятностей является
так называемая центральная предельная теорема. Она утверждает,
что сумма большого количества независимых случайных слагаемых, каждое
из которых вносит в эту сумму относительно малый вклад, подчиняется
универсальному закону, не зависимо от того, каким вероятностным законам
подчиняются её составляющие, — так называемому нормальному
распределению (или распределению Гаусса).
Доказательство теоремы довольно громоздко и мы его не приводим (его можно найти
в любом учебнике по теории вероятностей). Остановимся
кратко на том, что такое нормальное распределение и его основных свойствах.
Плотность нормального распределения выражается следующей формулой:
| w𝒩(x)=12πσe-(x-x¯)22σ2. | (2.5) |
Здесь x¯ и σ
— параметры нормального распределения: x¯ равно
среднему значению x, a σ —
среднеквадратичному отклонению, вычисленным в пределе n→∞.
Как видно из рис. 2.1, распределение представляет собой
симметричный
«колокол», положение вершины которого
соответствует x¯ (ввиду симметрии оно же
совпадает с наиболее вероятным значением — максимумом
функции w𝒩(x)).
При значительном отклонении x от среднего величина
w𝒩(x)
очень быстро убывает. Это означает, что вероятность встретить отклонения,
существенно большие, чем σ, оказывается пренебрежимо
мала. Ширина «колокола» по порядку величины
равна σ — она характеризует «разброс»
экспериментальных данных относительно среднего значения.
Замечание. Точки x=x¯±σ являются точками
перегиба графика w(x) (в них вторая производная по x
обращается в нуль, w′′=0), а их положение по высоте составляет
w(x¯±σ)/w(x¯)=e-1/2≈0,61
от высоты вершины.
Универсальный характер центральной предельной теоремы позволяет широко
применять на практике нормальное (гауссово) распределение для обработки
результатов измерений, поскольку часто случайные погрешности складываются из
множества случайных независимых факторов. Заметим, что на практике
для приближённой оценки параметров нормального распределения
случайной величины используются выборочные значения среднего
и дисперсии: x¯≈⟨x⟩, sx≈σx.
Вычислим некоторые доверительные вероятности (2.4) для нормально Замечание. Значение интеграла вида ∫e-x2/2𝑑x Вероятность того, что результат отдельного измерения x окажется Вероятность отклонения в пределах x¯±2σ: а в пределах x¯±3σ: Иными словами, при большом числе измерений нормально распределённой Пример. В сообщениях об открытии бозона Хиггса на Большом адронном коллайдере Полученные значения доверительных вероятностей используются при означает, что измеренное значение лежит в диапазоне (доверительном Замечание. Хотя нормальный закон распределения встречается на практике довольно Теперь мы можем дать количественный критерий для сравнения двух измеренных Пусть x1 и x2 (x1≠x2) измерены с Допустим, одна из величин известна с существенно большей точностью: Пусть погрешности измерений сравнимы по порядку величины: Замечание. Изложенные здесь соображения применимы, только если x¯ и x-x0σ2=2w(x)σ1=1
x-x0σ2=2w(x)σ1=1Доверительные вероятности.
распределённых случайных величин.
(его называют интегралом ошибок) в элементарных функциях не выражается,
но легко находится численно.
в пределах x¯±σ оказывается равна
P|Δx|<σ=∫x¯-σx¯+σw𝒩𝑑x≈0,68.
величины можно ожидать, что лишь треть измерений выпадут за пределы интервала
[x¯-σ,x¯+σ]. При этом около 5%
измерений выпадут за пределы [x¯-2σ;x¯+2σ],
и лишь 0,27% окажутся за пределами
[x¯-3σ;x¯+3σ].
говорилось о том, что исследователи ждали подтверждение результатов
с точностью «5 сигма». Используя нормальное распределение (2.5)
нетрудно посчитать, что они использовали доверительную вероятность
P≈1-5,7⋅10-7=0,99999943. Такую точность можно назвать фантастической.
стандартной записи результатов измерений. В физических измерениях
(в частности, в учебной лаборатории), как правило, используется P=0,68,
то есть, запись
интервале) x∈[x¯-δx;x¯+δx] с
вероятностью 68%. Таким образом погрешность ±δx считается
равной одному среднеквадратичному отклонению: δx=σ.
В технических измерениях чаще используется P=0,95, то есть под
абсолютной погрешностью имеется в виду удвоенное среднеквадратичное
отклонение, δx=2σ. Во избежание разночтений доверительную
вероятность следует указывать отдельно.
часто, стоит помнить, что он реализуется далеко не всегда.
Полученные выше соотношения для вероятностей попадания значений в
доверительные интервалы можно использовать в качестве простейшего
признака нормальности распределения: в частности, если количество попадающих
в интервал ±σ результатов существенно отличается от 2/3 — это повод
для более детального исследования закона распределения ошибок.Сравнение результатов измерений.
величин или двух результатов измерения одной и той же величины.
погрешностями σ1 и σ2 соответственно.
Ясно, что если различие результатов |x2-x1| невелико,
его можно объяснить просто случайными отклонениями.
Если же теория предсказывает, что вероятность обнаружить такое отклонение
слишком мала, различие результатов следует признать значимым.
Предварительно необходимо договориться о соответствующем граничном значении
вероятности. Универсального значения здесь быть не может,
поэтому приходится полагаться на субъективный выбор исследователя. Часто
в качестве «разумной» границы выбирают вероятность 5%,
что, как видно из изложенного выше, для нормального распределения
соответствует отклонению более, чем на 2σ.
σ2≪σ1 (например, x1 — результат, полученный
студентом в лаборатории, x2 — справочное значение).
Поскольку σ2 мало, x2 можно принять за «истинное»:
x2≈x¯. Предполагая, что погрешность измерения
x1 подчиняется нормальному закону с и дисперсией σ12,
можно утверждать, что
различие считают будет значимы, если
σ1∼σ2. В теории вероятностей показывается, что
линейная комбинация нормально распределённых величин также имеет нормальное
распределение с дисперсией σ2=σ12+σ22
(см. также правила сложения погрешностей (2.7)). Тогда
для проверки гипотезы о том, что x1 и x2 являются измерениями
одной и той же величины, нужно вычислить, является ли значимым отклонение
|x1-x2| от нуля при σ=σ12+σ22.
Пример. Два студента получили следующие значения для теплоты испарения
некоторой жидкости: x1=40,3±0,2 кДж/моль и
x2=41,0±0,3 кДж/моль, где погрешность соответствует
одному стандартному отклонению. Можно ли утверждать, что они исследовали
одну и ту же жидкость?
Имеем наблюдаемую разность |x1-x2|=0,7 кДж/моль,
среднеквадратичное отклонение для разности
σ=0,22+0,32=0,36 кДж/моль.
Их отношение |x2-x1|σ≈2. Из
свойств нормального распределения находим вероятность того, что измерялась
одна и та же величина, а различия в ответах возникли из-за случайных
ошибок: P≈5%. Ответ на вопрос, «достаточно»
ли мала или велика эта вероятность, остаётся на усмотрение исследователя.
его стандартное отклонение σ получены на основании достаточно
большой выборки n≫1 (или заданы точно). При небольшом числе измерений
(n≲10) выборочные средние ⟨x⟩ и среднеквадратичное отклонение
sx сами имеют довольно большую ошибку, а
их распределение будет описываться не нормальным законом, а так
называемым t-распределением Стъюдента. В частности, в зависимости от
значения n интервал ⟨x⟩±sx будет соответствовать несколько
меньшей доверительной вероятности, чем P=0,68. Особенно резко различия
проявляются при высоких уровнях доверительных вероятностей P→1.
2.3 Независимые величины
Величины x и y называют независимыми если результат измерения одной
из них никак не влияет на результат измерения другой. Для таких величин вероятность того, что x окажется в некоторой области X, и одновременно y — в области Y,
равна произведению соответствующих вероятностей:
Обозначим отклонения величин от их средних как Δx=x-x¯ и
Δy=y-y¯.
Средние значения этих отклонений равны, очевидно, нулю: Δx¯=x¯-x¯=0,
Δy¯=0. Из независимости величин x и y следует,
что среднее значение от произведения Δx⋅Δy¯
равно произведению средних Δx¯⋅Δy¯
и, следовательно, равно нулю:
| Δx⋅Δy¯=Δx¯⋅Δy¯=0. | (2.6) |
Пусть измеряемая величина z=x+y складывается из двух независимых
случайных слагаемых x и y, для которых известны средние
x¯ и y¯, и их среднеквадратичные погрешности
σx и σy. Непосредственно из определения (1.1)
следует, что среднее суммы равно сумме средних:
Найдём дисперсию σz2. В силу независимости имеем
| Δz2¯=Δx2¯+Δy2¯+2Δx⋅Δy¯≈Δx2¯+Δy2¯, |
то есть:
Таким образом, при сложении независимых величин их погрешности
складываются среднеквадратичным образом.
Подчеркнём, что для справедливости соотношения (2.7)
величины x и y не обязаны быть нормально распределёнными —
достаточно существования конечных значений их дисперсий. Однако можно
показать, что если x и y распределены нормально, нормальным
будет и распределение их суммы.
Замечание. Требование независимости
слагаемых является принципиальным. Например, положим y=x. Тогда
z=2x. Здесь y и x, очевидно, зависят друг от друга. Используя
(2.7), находим σ2x=2σx,
что, конечно, неверно — непосредственно из определения
следует, что σ2x=2σx.
Отдельно стоит обсудить математическую структуру формулы (2.7).
Если одна из погрешностей много больше другой, например,
σx≫σy,
то меньшей погрешностью можно пренебречь, σx+y≈σx.
С другой стороны, если два источника погрешностей имеют один порядок
σx∼σy, то и σx+y∼σx∼σy.
Эти обстоятельства важны при планирования эксперимента: как правило,
величина, измеренная наименее точно, вносит наибольший вклад в погрешность
конечного результата. При этом, пока не устранены наиболее существенные
ошибки, бессмысленно гнаться за повышением точности измерения остальных
величин.
Пример. Пусть σy=σx/3,
тогда σz=σx1+19≈1,05σx,
то есть при различии двух погрешностей более, чем в 3 раза, поправка
к погрешности составляет менее 5%, и уже нет особого смысла в учёте
меньшей погрешности: σz≈σx. Это утверждение
касается сложения любых независимых источников погрешностей в эксперименте.
2.4 Погрешность среднего
Выборочное среднее арифметическое значение ⟨x⟩, найденное
по результатам n измерений, само является случайной величиной.
Действительно, если поставить серию одинаковых опытов по n измерений,
то в каждом опыте получится своё среднее значение, отличающееся от
предельного среднего x¯.
Вычислим среднеквадратичную погрешность среднего арифметического
σ⟨x⟩.
Рассмотрим вспомогательную сумму n слагаемых
Если {xi} есть набор независимых измерений
одной и той же физической величины, то мы можем, применяя результат
(2.7) предыдущего параграфа, записать
| σZ=σx12+σx22+…+σxn2=nσx, |
поскольку под корнем находится n одинаковых слагаемых. Отсюда с
учётом ⟨x⟩=Z/n получаем
Таким образом, погрешность среднего значения x по результатам
n независимых измерений оказывается в n раз меньше погрешности
отдельного измерения. Это один из важнейших результатов, позволяющий
уменьшать случайные погрешности эксперимента за счёт многократного
повторения измерений.
Подчеркнём отличия между σx и σ⟨x⟩:
величина σx — погрешность отдельного
измерения — является характеристикой разброса значений
в совокупности измерений {xi}, i=1..n. При
нормальном законе распределения примерно 68% измерений попадают в
интервал ⟨x⟩±σx;
величина σ⟨x⟩ — погрешность
среднего — характеризует точность, с которой определено
среднее значение измеряемой физической величины ⟨x⟩ относительно
предельного («истинного») среднего x¯;
при этом с доверительной вероятностью P=68% искомая величина x¯
лежит в интервале
⟨x⟩-σ⟨x⟩<x¯<⟨x⟩+σ⟨x⟩.
2.5 Результирующая погрешность опыта
Пусть для некоторого результата измерения известна оценка его максимальной
систематической погрешности Δсист и случайная
среднеквадратичная
погрешность σслуч. Какова «полная»
погрешность измерения?
Предположим для простоты, что измеряемая величина в принципе
может быть определена сколь угодно точно, так что можно говорить о
некотором её «истинном» значении xист
(иными словами, погрешность результата связана в основном именно с
процессом измерения). Назовём полной погрешностью измерения
среднеквадратичное значения отклонения от результата измерения от
«истинного»:
Отклонение x-xист можно представить как сумму случайного
отклонения от среднего δxслуч=x-x¯
и постоянной (но, вообще говоря, неизвестной) систематической составляющей
δxсист=x¯-xист=const:
Причём случайную составляющую можно считать независимой от систематической.
В таком случае из (2.7) находим:
| σполн2=⟨δxсист2⟩+⟨δxслуч2⟩≤Δсист2+σслуч2. | (2.9) |
Таким образом, для получения максимального значения полной
погрешности некоторого измерения нужно квадратично сложить максимальную
систематическую и случайную погрешности.
Если измерения проводятся многократно, то согласно (2.8)
случайная составляющая погрешности может быть уменьшена, а систематическая
составляющая при этом остаётся неизменной:
Отсюда следует важное практическое правило
(см. также обсуждение в п. 2.3): если случайная погрешность измерений
в 2–3 раза меньше предполагаемой систематической, то
нет смысла проводить многократные измерения в попытке уменьшить погрешность
всего эксперимента. В такой ситуации измерения достаточно повторить
2–3 раза — чтобы убедиться в повторяемости результата, исключить промахи
и проверить, что случайная ошибка действительно мала.
В противном случае повторение измерений может иметь смысл до
тех пор, пока погрешность среднего
σ⟨x⟩=σxn
не станет меньше систематической.
Замечание. Поскольку конкретная
величина систематической погрешности, как правило, не известна, её
можно в некотором смысле рассматривать наравне со случайной —
предположить, что её величина была определена по некоторому случайному
закону перед началом измерений (например, при изготовлении линейки
на заводе произошло некоторое случайное искажение шкалы). При такой
трактовке формулу (2.9) можно рассматривать просто
как частный случай формулы сложения погрешностей независимых величин
(2.7).
Подчеркнем, что вероятностный закон, которому подчиняется
систематическая ошибка, зачастую неизвестен. Поэтому неизвестно и
распределение итогового результата. Из этого, в частности, следует,
что мы не можем приписать интервалу x±Δсист какую-либо
определённую доверительную вероятность — она равна 0,68
только если систематическая ошибка имеет нормальное распределение.
Можно, конечно, предположить,
— и так часто делают — что, к примеру, ошибки
при изготовлении линеек на заводе имеют гауссов характер. Также часто
предполагают, что систематическая ошибка имеет равномерное
распределение (то есть «истинное» значение может с равной вероятностью
принять любое значение в пределах интервала ±Δсист).
Строго говоря, для этих предположений нет достаточных оснований.
Пример. В результате измерения диаметра проволоки микрометрическим винтом,
имеющим цену деления h=0,01 мм, получен следующий набор из n=8 значений:
Вычисляем среднее значение: ⟨d⟩≈386,3 мкм.
Среднеквадратичное отклонение:
σd≈9,2 мкм. Случайная погрешность среднего согласно
(2.8):
σ⟨d⟩=σd8≈3,2
мкм. Все результаты лежат в пределах ±2σd, поэтому нет
причин сомневаться в нормальности распределения. Максимальную погрешность
микрометра оценим как половину цены деления, Δ=h2=5 мкм.
Результирующая полная погрешность
σ≤Δ2+σd28≈6,0 мкм.
Видно, что σслуч≈Δсист и проводить дополнительные измерения
особого смысла нет. Окончательно результат измерений может быть представлен
в виде (см. также правила округления
результатов измерений в п. 4.3.2)
d=386±6мкм,εd=1,5%.
Заметим, что поскольку случайная погрешность и погрешность
прибора здесь имеют один порядок величины, наблюдаемый случайный разброс
данных может быть связан как с неоднородностью сечения проволоки,
так и с дефектами микрометра (например, с неровностями зажимов, люфтом
винта, сухим трением, деформацией проволоки под действием микрометра
и т. п.). Для ответа на вопрос, что именно вызвало разброс, требуются
дополнительные исследования, желательно с использованием более точных
приборов.
Пример. Измерение скорости
полёта пули было осуществлено с погрешностью δv=±1 м/c.
Результаты измерений для n=6 выстрелов представлены в таблице:
Усреднённый результат ⟨v⟩=162,0м/с,
среднеквадратичное отклонение σv=13,8м/c, случайная
ошибка для средней скорости
σv¯=σv/6=5,6м/с.
Поскольку разброс экспериментальных данных существенно превышает погрешность
каждого измерения, σv≫δv, он почти наверняка связан
с реальным различием скоростей пули в разных выстрелах, а не с ошибками
измерений. В качестве результата эксперимента представляют интерес
как среднее значение скоростей ⟨v⟩=162±6м/с
(ε≈4%), так и значение σv≈14м/с,
характеризующее разброс значений скоростей от выстрела к выстрелу.
Малая инструментальная погрешность в принципе позволяет более точно
измерить среднее и дисперсию, и исследовать закон распределения выстрелов
по скоростям более детально — для этого требуется набрать
бо́льшую статистику по выстрелам.
Пример. Измерение скорости
полёта пули было осуществлено с погрешностью δv=10 м/c. Результаты
измерений для n=6 выстрелов представлены в таблице:
Усреднённый результат ⟨v⟩=163,3м/с,
σv=12,1м/c, σ⟨v⟩=5м/с,
σполн≈11,2м/с. Инструментальная
погрешность каждого измерения превышает разброс данных, поэтому в
этом опыте затруднительно сделать вывод о различии скоростей от выстрела
к выстрелу. Результат измерений скорости пули:
⟨v⟩=163±11м/с,
ε≈7%. Проводить дополнительные выстрелы при такой
большой инструментальной погрешности особого смысла нет —
лучше поработать над точностью приборов и методикой измерений.
2.6 Обработка косвенных измерений
Косвенными называют измерения, полученные в результате расчётов,
использующих результаты прямых (то есть «непосредственных»)
измерений физических величин. Сформулируем основные правила пересчёта
погрешностей при косвенных измерениях.
2.6.1 Случай одной переменной
Пусть в эксперименте измеряется величина x, а её «наилучшее»
(в некотором смысле) значение равно x⋆ и оно известно с
погрешностью σx. После чего с помощью известной функции
вычисляется величина y=f(x).
В качестве «наилучшего» приближения для y используем значение функции
при «наилучшем» x:
Найдём величину погрешности σy. Обозначая отклонение измеряемой
величины как Δx=x-x⋆, и пользуясь определением производной,
при условии, что функция y(x) — гладкая
вблизи x≈x⋆, запишем
где f′≡dydx — производная фукнции f(x), взятая в точке
x⋆. Возведём полученное в квадрат, проведём усреднение
(σy2=⟨Δy2⟩,
σx2=⟨Δx2⟩), и затем снова извлечём
корень. В результате получим
Пример. Для степенной функции
y=Axn имеем σy=nAxn-1σx, откуда
σyy=nσxx,или εy=nεx,
то есть относительная погрешность степенной функции возрастает пропорционально
показателю степени n.
Пример. Для y=1/x имеем ε1/x=εx
— при обращении величины сохраняется её относительная
погрешность.
Упражнение. Найдите погрешность логарифма y=lnx, если известны x
и σx.
Упражнение. Найдите погрешность показательной функции y=ax,
если известны x и σx. Коэффициент a задан точно.
2.6.2 Случай многих переменных
Пусть величина u вычисляется по измеренным значениям нескольких
различных независимых физических величин x, y, …
на основе известного закона u=f(x,y,…). В качестве
наилучшего значения можно по-прежнему взять значение функции f
при наилучших значениях измеряемых параметров:
Для нахождения погрешности σu воспользуемся свойством,
известным из математического анализа, — малые приращения гладких
функции многих переменных складываются линейно, то есть справедлив
принцип суперпозиции малых приращений:
где символом fx′≡∂f∂x обозначена
частная производная функции f по переменной x —
то есть обычная производная f по x, взятая при условии, что
все остальные аргументы (кроме x) считаются постоянными параметрами.
Тогда пользуясь формулой для нахождения дисперсии суммы независимых
величин (2.7), получим соотношение, позволяющее вычислять
погрешности косвенных измерений для произвольной функции
u=f(x,y,…):
| σu2=fx′2σx2+fy′2σy2+… | (2.11) |
Это и есть искомая общая формула пересчёта погрешностей при косвенных
измерениях.
Отметим, что формулы (2.10) и (2.11) применимы
только если относительные отклонения всех величин малы
(εx,εy,…≪1),
а измерения проводятся вдали от особых точек функции f (производные
fx′, fy′ … не должны обращаться в бесконечность).
Также подчеркнём, что все полученные здесь формулы справедливы только
для независимых переменных x, y, …
Остановимся на некоторых важных частных случаях формулы
(2.11).
Пример. Для суммы (или разности) u=∑i=1naixi имеем
σu2=∑i=1nai2σxi2.
(2.12)
Пример. Найдём погрешность степенной функции:
u=xα⋅yβ⋅…. Тогда нетрудно получить,
что
σu2u2=α2σx2x2+β2σy2y2+…
или через относительные погрешности
εu2=α2εx2+β2εy2+…
(2.13)
Пример. Вычислим погрешность произведения и частного: u=xy или u=x/y.
Тогда в обоих случаях имеем
εu2=εx2+εy2,
(2.14)
то есть при умножении или делении относительные погрешности складываются
квадратично.
Пример. Рассмотрим несколько более сложный случай: нахождение угла по его тангенсу
u=arctgyx.
В таком случае, пользуясь тем, что (arctgz)′=11+z2,
где z=y/x, и используя производную сложной функции, находим
ux′=uz′zx′=-yx2+y2,
uy′=uz′zy′=xx2+y2, и наконец
σu2=y2σx2+x2σy2(x2+y2)2.
Упражнение. Найти погрешность вычисления гипотенузы z=x2+y2
прямоугольного треугольника по измеренным катетам x и y.
По итогам данного раздела можно дать следующие практические рекомендации.
-
•
Как правило, нет смысла увеличивать точность измерения какой-то одной
величины, если другие величины, используемые в расчётах, остаются
измеренными относительно грубо — всё равно итоговая погрешность
скорее всего будет определяться самым неточным измерением. Поэтому
все измерения имеет смысл проводить примерно с одной и той же
относительной погрешностью. -
•
При этом, как следует из (2.13), особое внимание
следует уделять измерению величин, возводимых при расчётах в степени
с большими показателями. А при сложных функциональных зависимостях
имеет смысл детально проанализировать структуру формулы
(2.11):
если вклад от некоторой величины в общую погрешность мал, нет смысла
гнаться за высокой точностью её измерения, и наоборот, точность некоторых
измерений может оказаться критически важной. -
•
Следует избегать измерения малых величин как разности двух близких
значений (например, толщины стенки цилиндра как разности внутреннего
и внешнего радиусов): если u=x-y, то абсолютная погрешность
σu=σx2+σy2
меняется мало, однако относительная погрешность
εu=σux-y
может оказаться неприемлемо большой, если x≈y.
Проверка корректности А/Б тестов
Хабр, привет! Сегодня поговорим о том, что такое корректность статистических критериев в контексте А/Б тестирования. Узнаем, как проверить, является критерий корректным или нет. Разберём пример, в котором тест Стьюдента не работает.

Меня зовут Коля, я работаю аналитиком данных в X5 Tech. Мы с Сашей продолжаем писать серию статей по А/Б тестированию, это наша третья статья. Первые две можно посмотреть тут:
-
Стратификация. Как разбиение выборки повышает чувствительность A/Б теста
-
Бутстреп и А/Б тестирование
Корректный статистический критерий
В А/Б тестировании при проверке гипотез с помощью статистических критериев можно совершить одну из двух ошибок:
-
ошибку первого рода – отклонить нулевую гипотезу, когда на самом деле она верна. То есть сказать, что эффект есть, хотя на самом деле его нет;
-
ошибку второго рода – не отклонить нулевую гипотезу, когда на самом деле она неверна. То есть сказать, что эффекта нет, хотя на самом деле он есть.
Совсем не ошибаться нельзя. Чтобы получить на 100% достоверные результаты, нужно бесконечно много данных. На практике получить столько данных затруднительно. Если совсем не ошибаться нельзя, то хотелось бы ошибаться не слишком часто и контролировать вероятности ошибок.
В статистике ошибка первого рода считается более важной. Поэтому обычно фиксируют допустимую вероятность ошибки первого рода, а затем пытаются минимизировать вероятность ошибки второго рода.
Предположим, мы решили, что допустимые вероятности ошибок первого и второго рода равны 0.1 и 0.2 соответственно. Будем называть статистический критерий корректным, если его вероятности ошибок первого и второго рода равны допустимым вероятностям ошибок первого и второго рода соответственно.
Как сделать критерий, в котором вероятности ошибок будут равны допустимым вероятностям ошибок?
Вероятность ошибки первого рода по определению равна уровню значимости критерия. Если уровень значимости положить равным допустимой вероятности ошибки первого рода, то вероятность ошибки первого рода должна стать равной допустимой вероятности ошибки первого рода.
Вероятность ошибки второго рода можно подогнать под желаемое значение, меняя размер групп или снижая дисперсию в данных. Чем больше размер групп и чем ниже дисперсия, тем меньше вероятность ошибки второго рода. Для некоторых гипотез есть готовые формулы оценки размера групп, при которых достигаются заданные вероятности ошибок.
Например, формула оценки необходимого размера групп для гипотезы о равенстве средних:
![n > frac{left[ Phi^{-1} left( 1-alpha / 2 right) + Phi^{-1} left( 1-beta right) right]^2 (sigma_A^2 + sigma_B^2)}{varepsilon^2}](https://habrastorage.org/getpro/habr/upload_files/5d2/f18/735/5d2f18735269b594598add742c905d53.svg)
где ![]() и
и ![]() – допустимые вероятности ошибок первого и второго рода,
– допустимые вероятности ошибок первого и второго рода, ![]() – ожидаемый эффект (на сколько изменится среднее),
– ожидаемый эффект (на сколько изменится среднее), ![]() и
и ![]() – стандартные отклонения случайных величин в контрольной и экспериментальной группах.
– стандартные отклонения случайных величин в контрольной и экспериментальной группах.
Проверка корректности
Допустим, мы работаем в онлайн-магазине с доставкой. Хотим исследовать, как новый алгоритм ранжирования товаров на сайте влияет на среднюю выручку с покупателя за неделю. Продолжительность эксперимента – одна неделя. Ожидаемый эффект равен +100 рублей. Допустимая вероятность ошибки первого рода равна 0.1, второго рода – 0.2.
Оценим необходимый размер групп по формуле:
import numpy as np
from scipy import stats
alpha = 0.1 # допустимая вероятность ошибки I рода
beta = 0.2 # допустимая вероятность ошибки II рода
mu_control = 2500 # средняя выручка с пользователя в контрольной группе
effect = 100 # ожидаемый размер эффекта
mu_pilot = mu_control + effect # средняя выручка с пользователя в экспериментальной группе
std = 800 # стандартное отклонение
# исторические данные выручки для 10000 клиентов
values = np.random.normal(mu_control, std, 10000)
def estimate_sample_size(effect, std, alpha, beta):
"""Оценка необходимого размер групп."""
t_alpha = stats.norm.ppf(1 - alpha / 2, loc=0, scale=1)
t_beta = stats.norm.ppf(1 - beta, loc=0, scale=1)
var = 2 * std ** 2
sample_size = int((t_alpha + t_beta) ** 2 * var / (effect ** 2))
return sample_size
estimated_std = np.std(values)
sample_size = estimate_sample_size(effect, estimated_std, alpha, beta)
print(f'оценка необходимого размера групп = {sample_size}')оценка необходимого размера групп = 784Чтобы проверить корректность, нужно знать природу случайных величин, с которыми мы работаем. В этом нам помогут исторические данные. Представьте, что мы перенеслись в прошлое на несколько недель назад и запустили эксперимент с таким же дизайном, как мы планировали запустить его сейчас. Дизайн – это совокупность параметров эксперимента, таких как: целевая метрика, допустимые вероятности ошибок первого и второго рода, размеры групп и продолжительность эксперимента, техники снижения дисперсии и т.д.
Так как это было в прошлом, мы знаем, какие покупки совершили пользователи, можем вычислить метрики и оценить значимость отличий. Кроме того, мы знаем, что эффекта на самом деле не было, так как в то время эксперимент на самом деле не запускался. Если значимые отличия были найдены, то мы совершили ошибку первого рода. Иначе получили правильный результат.
Далее нужно повторить эту процедуру с мысленным запуском эксперимента в прошлом на разных группах и временных интервалах много раз, например, 1000.
После этого можно посчитать долю экспериментов, в которых была совершена ошибка. Это будет точечная оценка вероятности ошибки первого рода.
Оценку вероятности ошибки второго рода можно получить аналогичным способом. Единственное отличие состоит в том, что каждый раз нужно искусственно добавлять ожидаемый эффект в данные экспериментальной группы. В этих экспериментах эффект на самом деле есть, так как мы сами его добавили. Если значимых отличий не будет найдено – это ошибка второго рода. Проведя 1000 экспериментов и посчитав долю ошибок второго рода, получим точечную оценку вероятности ошибки второго рода.
Посмотрим, как оценить вероятности ошибок в коде. С помощью численных синтетических А/А и А/Б экспериментов оценим вероятности ошибок и построим доверительные интервалы:
def run_synthetic_experiments(values, sample_size, effect=0, n_iter=10000):
"""Проводим синтетические эксперименты, возвращаем список p-value."""
pvalues = []
for _ in range(n_iter):
a, b = np.random.choice(values, size=(2, sample_size,), replace=False)
b += effect
pvalue = stats.ttest_ind(a, b).pvalue
pvalues.append(pvalue)
return np.array(pvalues)
def print_estimated_errors(pvalues_aa, pvalues_ab, alpha):
"""Оценивает вероятности ошибок."""
estimated_first_type_error = np.mean(pvalues_aa < alpha)
estimated_second_type_error = np.mean(pvalues_ab >= alpha)
ci_first = estimate_ci_bernoulli(estimated_first_type_error, len(pvalues_aa))
ci_second = estimate_ci_bernoulli(estimated_second_type_error, len(pvalues_ab))
print(f'оценка вероятности ошибки I рода = {estimated_first_type_error:0.4f}')
print(f' доверительный интервал = [{ci_first[0]:0.4f}, {ci_first[1]:0.4f}]')
print(f'оценка вероятности ошибки II рода = {estimated_second_type_error:0.4f}')
print(f' доверительный интервал = [{ci_second[0]:0.4f}, {ci_second[1]:0.4f}]')
def estimate_ci_bernoulli(p, n, alpha=0.05):
"""Доверительный интервал для Бернуллиевской случайной величины."""
t = stats.norm.ppf(1 - alpha / 2, loc=0, scale=1)
std_n = np.sqrt(p * (1 - p) / n)
return p - t * std_n, p + t * std_n
pvalues_aa = run_synthetic_experiments(values, sample_size, effect=0)
pvalues_ab = run_synthetic_experiments(values, sample_size, effect=effect)
print_estimated_errors(pvalues_aa, pvalues_ab, alpha)оценка вероятности ошибки I рода = 0.0991
доверительный интервал = [0.0932, 0.1050]
оценка вероятности ошибки II рода = 0.1978
доверительный интервал = [0.1900, 0.2056]Оценки вероятностей ошибок примерно равны 0.1 и 0.2, как и должно быть. Всё верно, тест Стьюдента на этих данных работает корректно.
Распределение p-value
Выше рассмотрели случай, когда тест контролирует вероятность ошибки первого рода при фиксированном уровне значимости. Если решим изменить уровень значимости с 0.1 на 0.01, будет ли тест контролировать вероятность ошибки первого рода? Было бы хорошо, если тест контролировал вероятность ошибки первого рода при любом заданном уровне значимости. Формально это можно записать так:
Для любого ![]() выполняется
выполняется ![]() .
.
Заметим, что в левой части равенства записано выражение для функции распределения p-value. Из равенства следует, что функция распределения p-value в точке X равна X для любого X от 0 до 1. Эта функция распределения является функцией распределения равномерного распределения от 0 до 1. Мы только что показали, что статистический критерий контролирует вероятность ошибки первого рода на заданном уровне для любого уровня значимости тогда и только тогда, когда при верности нулевой гипотезы p-value распределено равномерно от 0 до 1.
При верности нулевой гипотезы p-value должно быть распределено равномерно. А как должно быть распределено p-value при верности альтернативной гипотезы? Из условия для вероятности ошибки второго рода ![]() следует, что
следует, что ![]() .
.
Получается, график функции распределения p-value при верности альтернативной гипотезы должен проходить через точку ![]() , где
, где ![]() и
и ![]() – допустимые вероятности ошибок конкретного эксперимента.
– допустимые вероятности ошибок конкретного эксперимента.
Проверим, как распределено p-value в численном эксперименте. Построим эмпирические функции распределения p-value:
import matplotlib.pyplot as plt
def plot_pvalue_distribution(pvalues_aa, pvalues_ab, alpha, beta):
"""Рисует графики распределения p-value."""
estimated_first_type_error = np.mean(pvalues_aa < alpha)
estimated_second_type_error = np.mean(pvalues_ab >= alpha)
y_one = estimated_first_type_error
y_two = 1 - estimated_second_type_error
X = np.linspace(0, 1, 1000)
Y_aa = [np.mean(pvalues_aa < x) for x in X]
Y_ab = [np.mean(pvalues_ab < x) for x in X]
plt.plot(X, Y_aa, label='A/A')
plt.plot(X, Y_ab, label='A/B')
plt.plot([alpha, alpha], [0, 1], '--k', alpha=0.8)
plt.plot([0, alpha], [y_one, y_one], '--k', alpha=0.8)
plt.plot([0, alpha], [y_two, y_two], '--k', alpha=0.8)
plt.plot([0, 1], [0, 1], '--k', alpha=0.8)
plt.title('Оценка распределения p-value', size=16)
plt.xlabel('p-value', size=12)
plt.legend(fontsize=12)
plt.grid()
plt.show()
plot_pvalue_distribution(pvalues_aa, pvalues_ab, alpha, beta)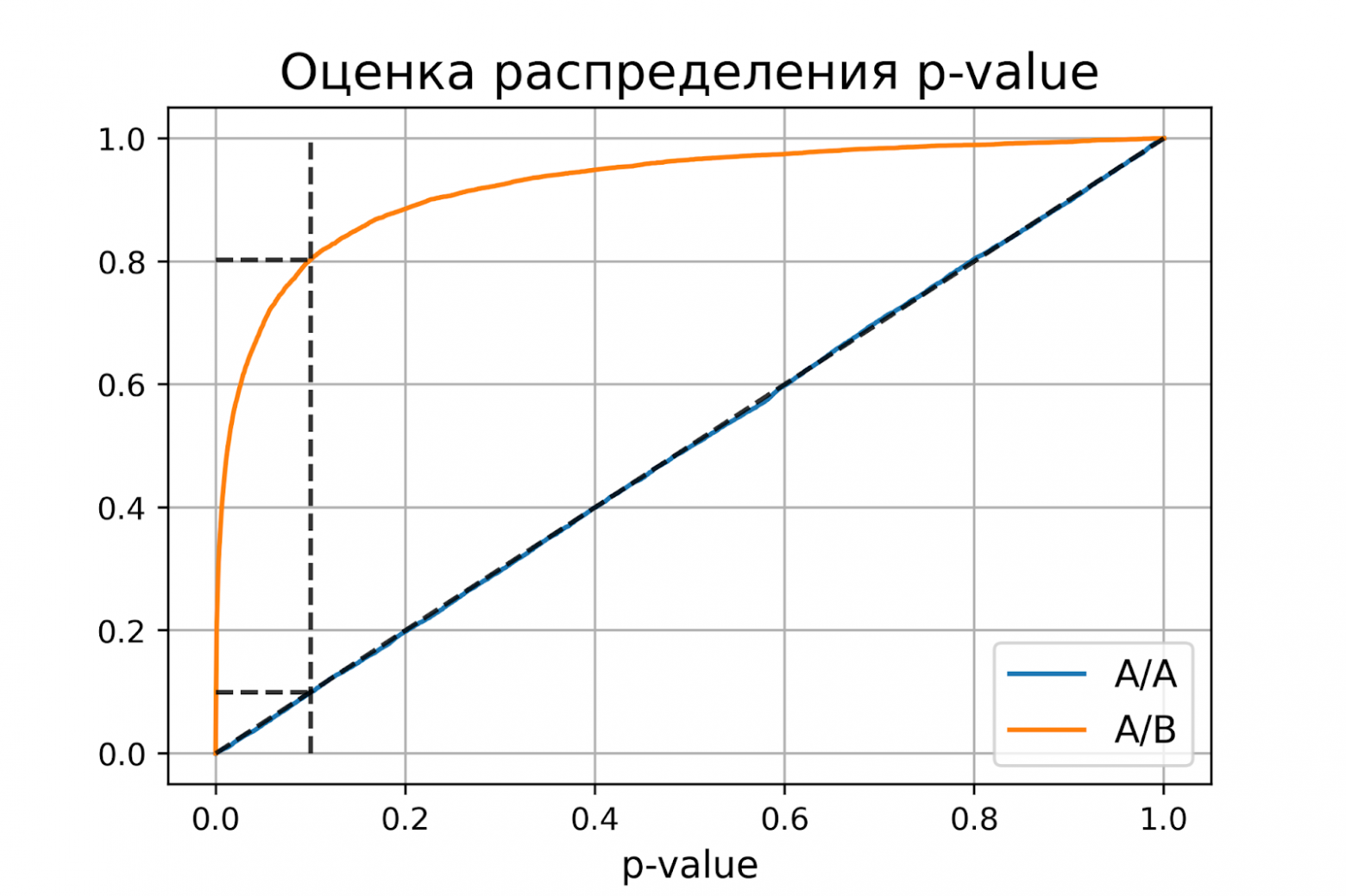
P-value для синтетических А/А тестах действительно оказалось распределено равномерно от 0 до 1, а для синтетических А/Б тестов проходит через точку ![]() .
.
Кроме оценок распределений на графике дополнительно построены четыре пунктирные линии:
-
диагональная из точки [0, 0] в точку [1, 1] – это функция распределения равномерного распределения на отрезке от 0 до 1, по ней можно визуально оценивать равномерность распределения p-value;
-
вертикальная линия с
 – пороговое значение p-value, по которому определяем отвергать нулевую гипотезу или нет. Проекция на ось ординат точки пересечения вертикальной линии с функцией распределения p-value для А/А тестов – это вероятность ошибки первого рода. Проекция точки пересечения вертикальной линии с функцией распределения p-value для А/Б тестов – это мощность теста (мощность = 1 —
– пороговое значение p-value, по которому определяем отвергать нулевую гипотезу или нет. Проекция на ось ординат точки пересечения вертикальной линии с функцией распределения p-value для А/А тестов – это вероятность ошибки первого рода. Проекция точки пересечения вертикальной линии с функцией распределения p-value для А/Б тестов – это мощность теста (мощность = 1 —  ).
). -
две горизонтальные линии – проекции на ось ординат точки пересечения вертикальной линии с функцией распределения p-value для А/А и А/Б тестов.
График с оценками распределения p-value для синтетических А/А и А/Б тестов позволяет проверить корректность теста для любого значения уровня значимости.
Некорректный критерий
Выше рассмотрели пример, когда тест Стьюдента оказался корректным критерием для случайных данных из нормального распределения. Может быть, все критерии всегда работаю корректно, и нет смысла каждый раз проверять вероятности ошибок?
Покажем, что это не так. Немного изменим рассмотренный ранее пример, чтобы продемонстрировать некорректную работу критерия. Допустим, мы решили увеличить продолжительность эксперимента до 2-х недель. Для каждого пользователя будем вычислять стоимость покупок за первую неделю и стоимость покупок за второю неделю. Полученные стоимости будем передавать в тест Стьюдента для проверки значимости отличий. Положим, что поведение пользователей повторяется от недели к неделе, и стоимости покупок одного пользователя совпадают.
def run_synthetic_experiments_two(values, sample_size, effect=0, n_iter=10000):
"""Проводим синтетические эксперименты на двух неделях."""
pvalues = []
for _ in range(n_iter):
a, b = np.random.choice(values, size=(2, sample_size,), replace=False)
b += effect
# дублируем данные
a = np.hstack((a, a,))
b = np.hstack((b, b,))
pvalue = stats.ttest_ind(a, b).pvalue
pvalues.append(pvalue)
return np.array(pvalues)
pvalues_aa = run_synthetic_experiments_two(values, sample_size)
pvalues_ab = run_synthetic_experiments_two(values, sample_size, effect=effect)
print_estimated_errors(pvalues_aa, pvalues_ab, alpha)
plot_pvalue_distribution(pvalues_aa, pvalues_ab, alpha, beta)оценка вероятности ошибки I рода = 0.2451
доверительный интервал = [0.2367, 0.2535]
оценка вероятности ошибки II рода = 0.0894
доверительный интервал = [0.0838, 0.0950]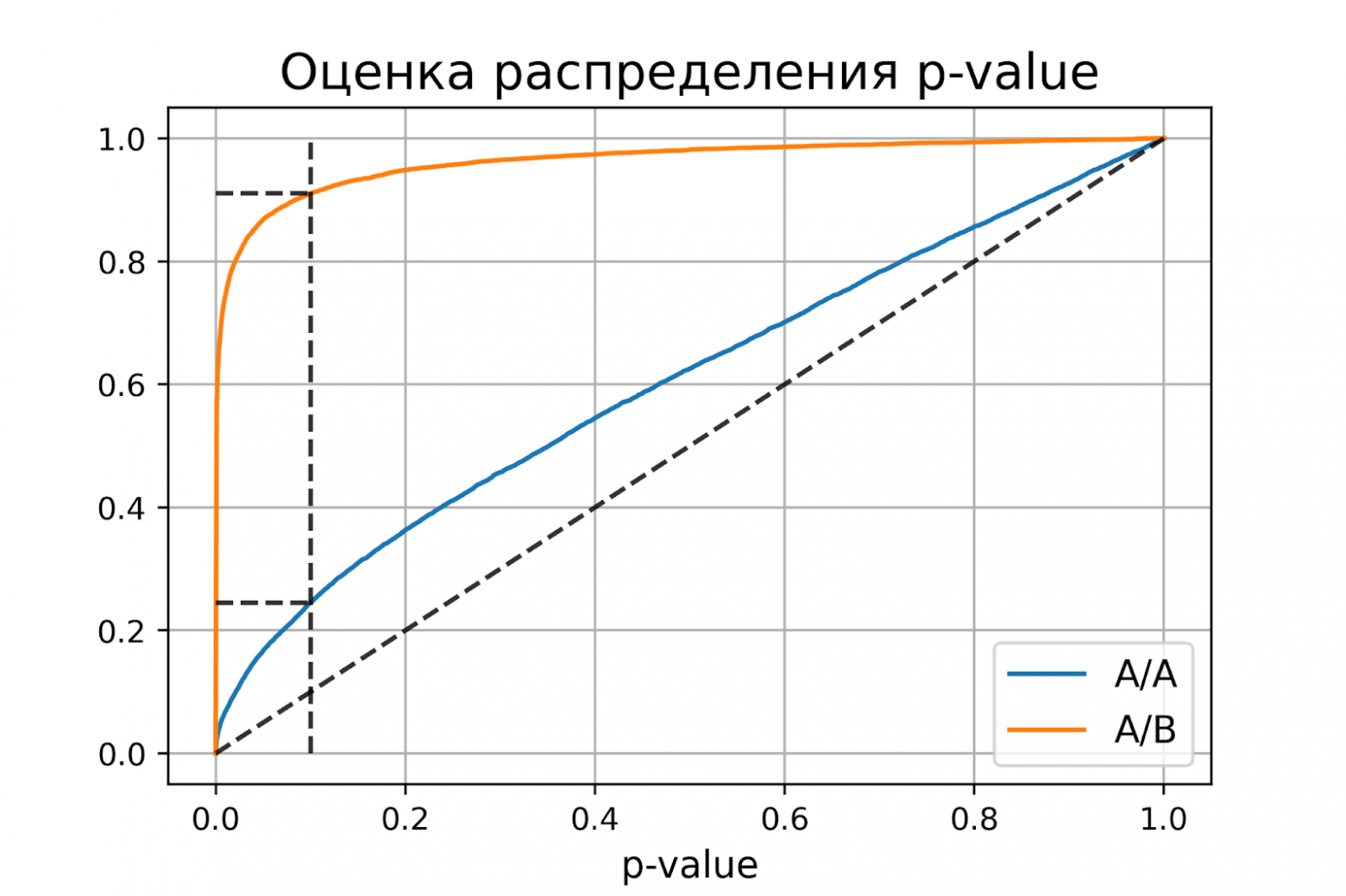
Получили оценку вероятности ошибки первого рода около 0.25, что сильно больше уровня значимости 0.1. На графике видно, что распределение p-value для синтетических А/А тестов не равномерно, оно отклоняется от диагонали. В этом примере тест Стьюдента работает некорректно, так как данные зависимые (стоимости покупок одного человека зависимы). Если бы мы сразу не догадались про зависимость данных, то оценка вероятностей ошибок помогла бы нам понять, что такой тест некорректен.
Итоги
Мы обсудили, что такое корректность статистического теста, посмотрели, как оценить вероятности ошибок на исторических данных и привели пример некорректной работы критерия.
Таким образом:
-
корректный критерий – это критерий, у которого вероятности ошибок первого и второго рода равны допустимым вероятностям ошибок первого и второго рода соответственно;
-
чтобы критерий контролировал вероятность ошибки первого рода для любого уровня значимости, необходимо и достаточно, чтобы p-value при верности нулевой гипотезы было распределено равномерно от 0 до 1.
Ошибки первого и второго рода
Выдвинутая гипотеза
может быть правильной или неправильной,
поэтому возникает необходимость её
проверки. Поскольку проверку производят
статистическими методами, её называют
статистической. В итоге статистической
проверки гипотезы в двух случаях может
быть принято неправильное решение, т.
е. могут быть допущены ошибки двух родов.
Ошибка первого
рода состоит в том, что будет отвергнута
правильная гипотеза.
Ошибка второго
рода состоит в том, что будет принята
неправильная гипотеза.
Подчеркнём, что
последствия этих ошибок могут оказаться
весьма различными. Например, если
отвергнуто правильное решение «продолжать
строительство жилого дома», то эта
ошибка первого рода повлечёт материальный
ущерб: если же принято неправильное
решение «продолжать строительство»,
несмотря на опасность обвала стройки,
то эта ошибка второго рода может повлечь
гибель людей. Можно привести примеры,
когда ошибка первого рода влечёт более
тяжёлые последствия, чем ошибка второго
рода.
Замечание 1.
Правильное решение может быть принято
также в двух случаях:
-
гипотеза принимается,
причём и в действительности она
правильная; -
гипотеза отвергается,
причём и в действительности она неверна.
Замечание 2.
Вероятность совершить ошибку первого
рода принято обозначать через
![]() ;
;
её называют уровнем значимости. Наиболее
часто уровень значимости принимают
равным 0,05 или 0,01. Если, например, принят
уровень значимости, равный 0,05, то это
означает, что в пяти случаях из ста
имеется риск допустить ошибку первого
рода (отвергнуть правильную гипотезу).
Статистический
критерий проверки нулевой гипотезы.
Наблюдаемое значение критерия
Для проверки
нулевой гипотезы используют специально
подобранную случайную величину, точное
или приближённое распределение которой
известно. Обозначим эту величину в целях
общности через
![]() .
.
Статистическим
критерием
(или просто критерием) называют случайную
величину
![]() ,
,
которая служит для проверки нулевой
гипотезы.
Например, если
проверяют гипотезу о равенстве дисперсий
двух нормальных генеральных совокупностей,
то в качестве критерия
![]() принимают отношение исправленных
принимают отношение исправленных
выборочных дисперсий: .
.
Эта величина
случайная, потому что в различных опытах
дисперсии принимают различные, наперёд
неизвестные значения, и распределена
по закону Фишера – Снедекора.
Для проверки
гипотезы по данным выборок вычисляют
частные значения входящих в критерий
величин и таким образом получают частное
(наблюдаемое) значение критерия.
Наблюдаемым
значением
![]() называют значение критерия, вычисленное
называют значение критерия, вычисленное
по выборкам. Например, если по двум
выборкам найдены исправленные выборочные
дисперсии![]() и
и![]() ,
,
то наблюдаемое значение критерия .
.
Критическая
область. Область принятия гипотезы.
Критические точки
После выбора
определённого критерия множество всех
его возможных значений разбивают на
два непересекающихся подмножества:
одно из них содержит значения критерия,
при которых нулевая гипотеза отвергается,
а другая – при которых она принимается.
Критической
областью называют совокупность значений
критерия, при которых нулевую гипотезу
отвергают.
Областью принятия
гипотезы (областью допустимых значений)
называют совокупность значений критерия,
при которых гипотезу принимают.
Основной принцип
проверки статистических гипотез можно
сформулировать так: если наблюдаемое
значение критерия принадлежит критической
области – гипотезу отвергают, если
наблюдаемое значение критерия принадлежит
области принятия гипотезы – гипотезу
принимают.
Поскольку критерий
![]() — одномерная случайная величина, все её
— одномерная случайная величина, все её
возможные значения принадлежат некоторому
интервалу. Поэтому критическая область
и область принятия гипотезы также
являются интервалами и, следовательно,
существуют точки, которые их разделяют.
Критическими
точками (границами)
![]() называют точки, отделяющие критическую
называют точки, отделяющие критическую
область от области принятия гипотезы.
Различают
одностороннюю (правостороннюю или
левостороннюю) и двустороннюю критические
области.
Правосторонней
называют критическую область, определяемую
неравенством
![]() >
>![]() ,
,
где![]() — положительное число.
— положительное число.
Левосторонней
называют критическую область, определяемую
неравенством
![]() <
<![]() ,
,
где![]() — отрицательное число.
— отрицательное число.
Односторонней
называют правостороннюю или левостороннюю
критическую область.
Двусторонней
называют критическую область, определяемую
неравенствами
![]() где
где![]() .
.
В частности, если
критические точки симметричны относительно
нуля, двусторонняя критическая область
определяется неравенствами ( в
предположении, что
![]() >0):
>0):
![]() ,
,
или равносильным неравенством
![]() .
.
Отыскание
правосторонней критической области
Как найти критическую
область? Обоснованный ответ на этот
вопрос требует привлечения довольно
сложной теории. Ограничимся её элементами.
Для определённости начнём с нахождения
правосторонней критической области,
которая определяется неравенством
![]() >
>![]() ,
,
где![]() >0.
>0.
Видим, что для отыскания правосторонней
критической области достаточно найти
критическую точку. Следовательно,
возникает новый вопрос: как её найти?
Для её нахождения
задаются достаточной малой вероятностью
– уровнем значимости
![]() .
.
Затем ищут критическую точку![]() ,
,
исходя из требования, чтобы при условии
справедливости нулевой гипотезы
вероятность того, критерий![]() примет значение, большее
примет значение, большее![]() ,
,
была равна принятому уровню значимости:
Р(![]() >
>![]() )=
)=![]() .
.
Для каждого критерия
имеются соответствующие таблицы, по
которым и находят критическую точку,
удовлетворяющую этому требованию.
Замечание 1.
Когда
критическая точка уже найдена, вычисляют
по данным выборок наблюдаемое значение
критерия и, если окажется, что
![]() >
>![]() ,
,
то нулевую гипотезу отвергают; если же![]() <
<![]() ,
,
то нет оснований, чтобы отвергнуть
нулевую гипотезу.
Пояснение. Почему
правосторонняя критическая область
была определена, исходя из требования,
чтобы при справедливости нулевой
гипотезы выполнялось соотношение
Р(![]() >
>![]() )=
)=![]() ?
?
(*)
Поскольку вероятность
события
![]() >
>![]() мала (
мала (![]() — малая вероятность), такое событие при
— малая вероятность), такое событие при
справедливости нулевой гипотезы, в силу
принципа практической невозможности
маловероятных событий, в единичном
испытании не должно наступить. Если всё
же оно произошло, т.е. наблюдаемое
значение критерия оказалось больше![]() ,
,
то это можно объяснить тем, что нулевая
гипотеза ложна и, следовательно, должна
быть отвергнута. Таким образом, требование
(*) определяет такие значения критерия,
при которых нулевая гипотеза отвергается,
а они и составляют правостороннюю
критическую область.
Замечание 2.
Наблюдаемое значение критерия может
оказаться большим
![]() не потому, что нулевая гипотеза ложна,
не потому, что нулевая гипотеза ложна,
а по другим причинам (малый объём выборки,
недостатки методики эксперимента и
др.). В этом случае, отвергнув правильную
нулевую гипотезу, совершают ошибку
первого рода. Вероятность этой ошибки
равна уровню значимости![]() .
.
Итак, пользуясь требованием (*), мы с
вероятностью![]() рискуем совершить ошибку первого рода.
рискуем совершить ошибку первого рода.
Замечание 3. Пусть
нулевая гипотеза принята; ошибочно
думать, что тем самым она доказана.
Действительно, известно, что один пример,
подтверждающий справедливость некоторого
общего утверждения, ещё не доказывает
его. Поэтому более правильно говорить,
«данные наблюдений согласуются с нулевой
гипотезой и, следовательно, не дают
оснований её отвергнуть».
На практике для
большей уверенности принятия гипотезы
её проверяют другими способами или
повторяют эксперимент, увеличив объём
выборки.
Отвергают гипотезу
более категорично, чем принимают.
Действительно, известно, что достаточно
привести один пример, противоречащий
некоторому общему утверждению, чтобы
это утверждение отвергнуть. Если
оказалось, что наблюдаемое значение
критерия принадлежит критической
области, то этот факт и служит примером,
противоречащим нулевой гипотезе, что
позволяет её отклонить.
Отыскание
левосторонней и двусторонней критических
областей***
Отыскание
левосторонней и двусторонней критических
областей сводится (так же, как и для
правосторонней) к нахождению соответствующих
критических точек. Левосторонняя
критическая область определяется
неравенством
![]() <
<![]() (
(![]() <0).
<0).
Критическую точку находят, исходя из
требования, чтобы при справедливости
нулевой гипотезы вероятность того, что
критерий примет значение, меньшее![]() ,
,
была равна принятому уровню значимости:
Р(![]() <
<![]() )=
)=![]() .
.
Двусторонняя
критическая область определяется
неравенствами
![]() Критические
Критические
точки находят, исходя из требования,
чтобы при справедливости нулевой
гипотезы сумма вероятностей того, что
критерий примет значение, меньшее![]() или большее
или большее![]() ,
,
была равна принятому уровню значимости:
![]() .
.
(*)
Ясно, что критические
точки могут быть выбраны бесчисленным
множеством способов. Если же распределение
критерия симметрично относительно нуля
и имеются основания (например, для
увеличения мощности) выбрать симметричные
относительно нуля точки (-
![]() )и
)и![]() (
(![]() >0),
>0),
то
![]() Учитывая (*), получим
Учитывая (*), получим
![]() .
.
Это соотношение
и служит для отыскания критических
точек двусторонней критической области.
Критические точки находят по соответствующим
таблицам.
Дополнительные
сведения о выборе критической области.
Мощность критерия
Мы строили
критическую область, исходя из требования,
чтобы вероятность попадания в неё
критерия была равна
![]() при условии, что нулевая гипотеза
при условии, что нулевая гипотеза
справедлива. Оказывается целесообразным
ввести в рассмотрение вероятность
попадания критерия в критическую область
при условии, что нулевая гипотеза неверна
и, следовательно, справедлива конкурирующая.
Мощностью критерия
называют вероятность попадания критерия
в критическую область при условии, что
справедлива конкурирующая гипотеза.
Другими словами, мощность критерия есть
вероятность того, что нулевая гипотеза
будет отвергнута, если верна конкурирующая
гипотеза.
Пусть для проверки
гипотезы принят определённый уровень
значимости и выборка имеет фиксированный
объём. Остаётся произвол в выборе
критической области. Покажем, что её
целесообразно построить так, чтобы
мощность критерия была максимальной.
Предварительно убедимся, что если
вероятность ошибки второго рода (принять
неправильную гипотезу) равна
![]() ,
,
то мощность равна 1-![]() .
.
Действительно, если![]() — вероятность ошибки второго рода, т.е.
— вероятность ошибки второго рода, т.е.
события «принята нулевая гипотеза,
причём справедливо конкурирующая», то
мощность критерия равна 1 —![]() .
.
Пусть мощность 1
—
![]() возрастает; следовательно, уменьшается
возрастает; следовательно, уменьшается
вероятность![]() совершить ошибку второго рода. Таким
совершить ошибку второго рода. Таким
образом, чем мощность больше, тем
вероятность ошибки второго рода меньше.
Итак, если уровень
значимости уже выбран, то критическую
область следует строить так, чтобы
мощность критерия была максимальной.
Выполнение этого требования должно
обеспечить минимальную ошибку второго
рода, что, конечно, желательно.
Замечание 1.
Поскольку вероятность события «ошибка
второго рода допущена» равна
![]() ,
,
то вероятность противоположного события
«ошибка второго рода не допущена» равна
1 —![]() ,
,
т.е. мощности критерия. Отсюда следует,
что мощность критерия есть вероятность
того, что не будет допущена ошибка
второго рода.
Замечание 2. Ясно,
что чем меньше вероятности ошибок
первого и второго рода, тем критическая
область «лучше». Однако при заданном
объёме выборки уменьшить одновременно
![]() и
и![]() невозможно; если уменьшить
невозможно; если уменьшить![]() ,
,
то![]() будет возрастать. Например, если принять
будет возрастать. Например, если принять![]() =0,
=0,
то будут приниматься все гипотезы, в
том числе и неправильные, т.е. возрастает
вероятность![]() ошибки второго рода.
ошибки второго рода.
Как же выбрать
![]() наиболее целесообразно? Ответ на этот
наиболее целесообразно? Ответ на этот
вопрос зависит от «тяжести последствий»
ошибок для каждой конкретной задачи.
Например, если ошибка первого рода
повлечёт большие потери, а второго рода
– малые, то следует принять возможно
меньшее![]() .
.
Если
![]() уже выбрано, то, пользуясь теоремой Ю.
уже выбрано, то, пользуясь теоремой Ю.
Неймана и Э.Пирсона, можно построить
критическую область, для которой![]() будет минимальным и, следовательно,
будет минимальным и, следовательно,
мощность критерия максимальной.
Замечание 3.
Единственный способ одновременного
уменьшения вероятностей ошибок первого
и второго рода состоит в увеличении
объёма выборок.
Соседние файлы в папке Лекции 2 семестр
- #
- #
- #
- #
Ошибки I и II рода при проверке гипотез, мощность
Общий обзор
Принятие неправильного решения
Мощность и связанные факторы
Проверка множественных гипотез
Общий обзор
Большинство проверяемых гипотез сравнивают между собой группы объектов, которые испытывают влияние различных факторов.
Например, можно сравнить эффективность двух видов лечения, чтобы сократить 5-летнюю смертность от рака молочной железы. Для данного исхода (например, смерть) сравнение, представляющее интерес (например, различные показатели смертности через 5 лет), называют эффектом или, если уместно, эффектом лечения.
Нулевую гипотезу выражают как отсутствие эффекта (например 5-летняя смертность от рака молочной железы одинаковая в двух группах, получающих разное лечение); двусторонняя альтернативная гипотеза будет означать, что различие эффектов не равно нулю.
Критериальная проверка гипотезы дает возможность определить, достаточно ли аргументов, чтобы отвергнуть нулевую гипотезу. Можно принять только одно из двух решений:
- отвергнуть нулевую гипотезу и принять альтернативную гипотезу
- остаться в рамках нулевой гипотезы
Важно: В литературе достаточно часто встречается понятие «принять нулевую гипотезу». Хотелось бы внести ясность, что со статистической точки зрения принять нулевую гипотезу невозможно, т.к. нулевая гипотеза представляет собой достаточно строгое утверждение (например, средние значения в сравниваемых группах равны ![]() ).
).
Поэтому фразу о принятии нулевой гипотезы следует понимать как то, что мы просто остаемся в рамках гипотезы.
Принятие неправильного решения
Возможно неправильное решение, когда отвергают/не отвергают нулевую гипотезу, потому что есть только выборочная информация.
| Верная гипотеза | |||
|---|---|---|---|
| H0 | H1 | ||
| Результат
применения критерия |
H0 | H0 верно принята | H0 неверно принята
(Ошибка второго рода) |
| H1 | H0 неверно отвергнута
(Ошибка первого рода) |
H0 верно отвергнута |
Ошибка 1-го рода: нулевую гипотезу отвергают, когда она истинна, и делают вывод, что имеется эффект, когда в действительности его нет. Максимальный шанс (вероятность) допустить ошибку 1-го рода обозначается α (альфа). Это уровень значимости критерия; нулевую гипотезу отвергают, если наше значение p ниже уровня значимости, т. е., если p < α.
Следует принять решение относительно значения а прежде, чем будут собраны данные; обычно назначают условное значение 0,05, хотя можно выбрать более ограничивающее значение, например 0,01.
Шанс допустить ошибку 1-го рода никогда не превысит выбранного уровня значимости, скажем α = 0,05, так как нулевую гипотезу отвергают только тогда, когда p< 0,05. Если обнаружено, что p > 0,05, то нулевую гипотезу не отвергнут и, следовательно, не допустят ошибки 1-го рода.
Ошибка 2-го рода: не отвергают нулевую гипотезу, когда она ложна, и делают вывод, что нет эффекта, тогда как в действительности он существует. Шанс возникновения ошибки 2-го рода обозначается β (бета); а величина (1-β) называется мощностью критерия.
Следовательно, мощность — это вероятность отклонения нулевой гипотезы, когда она ложна, т.е. это шанс (обычно выраженный в процентах) обнаружить реальный эффект лечения в выборке данного объема как статистически значимый.
В идеале хотелось бы, чтобы мощность критерия составляла 100%; однако это невозможно, так как всегда остается шанс, хотя и незначительный, допустить ошибку 2-го рода.
К счастью, известно, какие факторы влияют на мощность и, таким образом, можно контролировать мощность критерия, рассматривая их.
Мощность и связанные факторы
Планируя исследование, необходимо знать мощность предложенного критерия. Очевидно, можно начинать исследование, если есть «хороший» шанс обнаружить уместный эффект, если таковой существует (под «хорошим» мы подразумеваем, что мощность должна быть по крайней мере 70-80%).
Этически безответственно начинать исследование, у которого, скажем, только 40% вероятности обнаружить реальный эффект лечения; это бесполезная трата времени и денежных средств.
Ряд факторов имеют прямое отношение к мощности критерия.
Объем выборки: мощность критерия увеличивается по мере увеличения объема выборки. Это означает, что у большей выборки больше возможностей, чем у незначительной, обнаружить важный эффект, если он существует.
Когда объем выборки небольшой, у критерия может быть недостаточно мощности, чтобы обнаружить отдельный эффект. Эти методы также можно использовать для оценки мощности критерия для точно установленного объема выборки.
Вариабельность наблюдений: мощность увеличивается по мере того, как вариабельность наблюдений уменьшается.
Интересующий исследователя эффект: мощность критерия больше для более высоких эффектов. Критерий проверки гипотез имеет больше шансов обнаружить значительный реальный эффект, чем незначительный.
Уровень значимости: мощность будет больше, если уровень значимости выше (это эквивалентно увеличению допущения ошибки 1-го рода, α, а допущение ошибки 2-го рода, β, уменьшается).
Таким образом, вероятнее всего, исследователь обнаружит реальный эффект, если на стадии планирования решит, что будет рассматривать значение р как значимое, если оно скорее будет меньше 0,05, чем меньше 0,01.
Обратите внимание, что проверка ДИ для интересующего эффекта указывает на то, была ли мощность адекватной. Большой доверительный интервал следует из небольшой выборки и/или набора данных с существенной вариабельностью и указывает на недостаточную мощность.
Проверка множественных гипотез
Часто нужно выполнить критериальную проверку значимости множественных гипотез на наборе данных с многими переменными или существует более двух видов лечения.
Ошибка 1-го рода драматически увеличивается по мере увеличения числа сравнений, что приводит к ложным выводам относительно гипотез. Следовательно, следует проверить только небольшое число гипотез, выбранных для достижения первоначальной цели исследования и точно установленных априорно.
Можно использовать какую-нибудь форму апостериорного уточнения значения р, принимая во внимание число выполненных проверок гипотез.
Например, при подходе Бонферрони (его часто считают довольно консервативным) умножают каждое значение р на число выполненных проверок; тогда любые решения относительно значимости будут основываться на этом уточненном значении р.
Связанные определения:
p-уровень
Альтернативная гипотеза, альтернатива
Альфа-уровень
Бета-уровень
Гипотеза
Двусторонний критерий
Критерий для проверки гипотезы
Критическая область проверки гипотезы
Мощность
Мощность исследования
Мощность статистического критерия
Нулевая гипотеза
Односторонний критерий
Ошибка I рода
Ошибка II рода
Статистика критерия
Эквивалентные статистические критерии
В начало
Содержание портала
5.6. Вероятность ошибки р
Если следовать подразделению статистики на описательную и аналитическую, то задача аналитической статистики — предоставить методы, с помощью которых можно было бы объективно выяснить,
например, является ли наблюдаемая разница в средних значениях или взаимосвязь (корреляция) выборок случайной или нет.
Например, если сравниваются два средних значения выборок, то можно сформулировать две предварительных гипотезы:
-
Гипотеза 0 (нулевая): Наблюдаемые различия между средними значениями выборок находятся в пределах случайных отклонений.
-
Гипотеза 1 (альтернативная): Наблюдаемые различия между средними значениями нельзя объяснить случайными отклонениями.
В аналитической статистике разработаны методы вычисления так называемых тестовых (контрольных) величин, которые рассчитываются по определенным формулам на основе данных,
содержащихся в выборках или полученных из них характеристик. Эти тестовые величины соответствуют определенным теоретическим распределениям
(t-pacnpeлелению, F-распределению, распределению X2 и т.д.), которые позволяют вычислить так называемую вероятность ошибки. Это вероятность равна проценту ошибки,
которую можно допустить отвергнув нулевую гипотезу и приняв альтернативную.
Вероятность определяется в математике, как величина, находящаяся в диапазоне от 0 до 1. В практической статистике она также часто выражаются в процентах. Обычно вероятность обозначаются буквой р:
0 < р < 1
Вероятности ошибки, при которой допустимо отвергнуть нулевую гипотезу и принять альтернативную гипотезу, зависит от каждого конкретного случая.
В значительной степени эта вероятность определяется характером исследуемой ситуации. Чем больше требуемая вероятность, с которой надо избежать ошибочного решения,
тем более узкими выбираются границы вероятности ошибки, при которой отвергается нулевая гипотеза, так называемый доверительный интервал вероятности.
Обычно в исследованиях используют 5% вероятность ошибки.
Существует общепринятая терминология, которая относится к доверительным интервалам вероятности:
- Высказывания, имеющие вероятность ошибки р <= 0,05 — называются значимыми.
- Высказывания с вероятностью ошибки р <= 0,01 — очень значимыми,
- А высказывания с вероятностью ошибки р <= 0,001 — максимально значимыми.
В литературе такие ситуации иногда обозначают одной, двумя или тремя звездочками.
| Вероятность ошибки | Значимость | Обозначение |
| р > 0.05 | Не значимая | ns |
| р <= 0.05 | Значимая | * |
| р <= 0.01 | Очень значимая | ** |
| р <= 0.001 | Максимально значимая | *** |
В SPSS вероятность ошибки р имеет различные обозначения; звездочки для указания степени значимости применяются лишь в немногих случаях. Обычно в SPSS значение р обозначается Sig. (Significant).
Времена, когда не было компьютеров, пригодных для статистического анализа, давали практикам по крайней мере одно преимущество. Так как все вычисления надо было выполнять вручную,
статистик должен был сначала тщательно обдумать, какие вопросы можно решить с помощью того или иного теста. Кроме того, особое значение придавалось точной формулировке нулевой гипотезы.
Но с помощью компьютера и такой мощной программы, как SPSS, очень легко можно провести множество тестов за очень короткое время. К примеру, если в таблицу сопряженности свести 50 переменных
с другими 20 переменными и выполнить тест X2, то получится 1000 результатов проверки значимости или 1000 значений р. Некритический подбор значимых величин может
дать бессмысленный результат, так как уже при граничном уровне значимости р = 0,05 в пяти процентах наблюдений, то есть в 50 возможных наблюдениях, можно ожидать значимые результаты.
Этим ошибкам первого рода (когда нулевая гипотеза отвергается, хотя она верна) следует уделять достаточно внимания. Ошибкой второго рода называется ситуация,
когда нулевая гипотеза принимается, хотя она ложна. Вероятность допустить ошибку первого рода равна вероятности ошибки р. Вероятность ошибки второго рода тем меньше, чем больше вероятность ошибки р.
Определим выражение для вычисления ошибки второго рода и мощности теста, построим в
MS
EXCEL
кривые оперативной характеристики (Operating-characteristic curves).
Тема этой статьи – вычисление
ошибки второго рода
(type II error) при
проверке гипотез
. Основная статья про
проверку гипотез
находится здесь
.
Напомним, что процедура
проверки гипотез
состоит из следующих шагов:
- из исследуемого распределения берется
выборка
; - на основании значений
выборки
вычисляется
тестовая статистика
; - значение
тестовой статистики
сравнивается со значениями, соответствующим заданномууровню значимости (ошибке первого рода)
;
- по результату сравнения делается вывод об отклонении (или не отклонении)
нулевой гипотезы
.
Обычно с
проверкой гипотез
связывают 2 типа ошибок. Если
нулевая гипотеза
отклоняется, когда она верна – это
ошибка первого рода
(обозначается α,
альфа
). Если нулевая гипотеза не отклоняется, когда она неверна, то это
ошибка второго рода
(обозначается β,
бета
).
Ошибка первого рода
часто называется риском производителя. Это осознанный риск, на который идет производитель продукции, т.к. он определяет вероятность того, что годная продукция может быть забракована, хотя на самом деле она таковой не является. Величина
ошибки первого рода
задается перед
проверкой гипотезы
, таким образом, она контролируется исследователем напрямую и может быть задана в соответствии с условиями решаемой задачи. После этого, процедура проверки гипотезы составляется таким образом, чтобы вероятность
ошибки второго рода
была как можно меньше.
Ошибка второго рода
β
зависит от размера
выборки
n и
уровня значимости α
, и поэтому контролируется косвенно. Чем больше размер
выборки
, тем меньше
ошибка второго рода
(при прочих равных).
Часто также используют величину
1-β
, которая называется
мощностью статистического критерия
(мощностью теста, мощностью исследования, англ. power of a statistical test).
Мощность статистического критерия
— это вероятность правильно отклонить нулевую гипотезу. Чем ближе эта величина к единице, тем меньше у нас шансов ошибиться при проверке гипотезы (тем лучше критерий различает гипотезы Н
0
и Н
1
).
Ошибку второго рода
вычисляют для каждого вида
проверки гипотез
по-разному. Получим выражение для вычисления
ошибки второго рода
для
проверки двусторонней гипотезы о равенстве среднего значения распределения некоторой величине (стандартное отклонение известно)
.
Для
проверки гипотезы
этого типа используется
тестовая статистика
Z
0
:
![]()
которая имеет
стандартное нормальное распределение
.
Чтобы найти
Ошибку второго рода
необходимо предположить, что гипотеза Н
0
: μ=μ
0
не верна, и соответственно истинное
среднее значение распределения
μ=μ
0
+Δ, где Δ>0. В этом случае,
тестовая статистика
Z
0
будет иметь
нормальное распределение
N(Δ√n/σ;1), т.е. будет смещено вправо на Δ√n/σ (см.
файл примера на листе Бета
).
Согласно определения,
ошибка второго рода
равна вероятности, принять нулевую гипотезу, если на самом деле справедлива Н
1
. Эта вероятность соответствует выделенной на рисунке области.
Статистика
Z
0
, в этом случае, примет значение между -Z
α/2
и Z
α/2
(эти значения соответствуют границам
доверительного интервала
). Z
α/2
– это
верхний α/2-квантиль стандартного нормального распределения
.
Определим
ошибку второго рода
в терминах
стандартного нормального распределения
:
![]()
Это выражение будет работать и для Δ<0. Как видно из выражения,
ошибка второго рода
является функцией от α, Δ и n. В
файле примера на листе Бета
можно быстро рассчитать β и
мощность теста
в зависимости от этих параметров. Диаграмма, приведенная выше, будет автоматически перестроена.
Для заданного значения α часто строят семейство кривых, которые иллюстрируют зависимость
ошибки второго рода
от Δ и n. Такие кривые называются
операционными характеристиками
(Operating-characteristic curves).
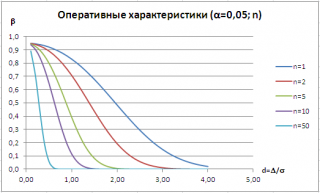
Как видно из рисунка, чем дальше истинное значение
среднего
от μ
0
, т.е. чем больше Δ, тем меньше
ошибка второго рода.
Таким образом, для заданных α и n, тест легче определит большие отклонения от
среднего
, чем малые (тест обладает, в данном случае, большей
мощностью
). При росте n
мощность теста
также растет.
Кривые
операционных характеристик
используются для оценки размера
выборки
, достаточного для определения заданной разницы между истинным значением
среднего
μ
от μ
0
с требуемой вероятностью.
В
файле примера на листе ОХ
создана форма для определения размера
выборки
, достаточного для обеспечения заданной
мощности теста
.
Например, Н
0
: μ
0
=20, истинное значение μ=20,05,
стандартное отклонение
=0,1, α=0,05. Чтобы вероятность правильно отклонить гипотезу H
0
была равна 0,9 (
мощность теста
), размер
выборки
должен быть 42 или более.
Примечание
:
Для нахождения размера
выборки
потребуется использование инструмента MS EXCEL
Подбор параметра
.
5.6. Вероятность ошибки р
Если следовать подразделению статистики на описательную и аналитическую, то задача аналитической статистики — предоставить методы, с помощью которых можно было бы объективно выяснить,
например, является ли наблюдаемая разница в средних значениях или взаимосвязь (корреляция) выборок случайной или нет.
Например, если сравниваются два средних значения выборок, то можно сформулировать две предварительных гипотезы:
-
Гипотеза 0 (нулевая): Наблюдаемые различия между средними значениями выборок находятся в пределах случайных отклонений.
-
Гипотеза 1 (альтернативная): Наблюдаемые различия между средними значениями нельзя объяснить случайными отклонениями.
В аналитической статистике разработаны методы вычисления так называемых тестовых (контрольных) величин, которые рассчитываются по определенным формулам на основе данных,
содержащихся в выборках или полученных из них характеристик. Эти тестовые величины соответствуют определенным теоретическим распределениям
(t-pacnpeлелению, F-распределению, распределению X2 и т.д.), которые позволяют вычислить так называемую вероятность ошибки. Это вероятность равна проценту ошибки,
которую можно допустить отвергнув нулевую гипотезу и приняв альтернативную.
Вероятность определяется в математике, как величина, находящаяся в диапазоне от 0 до 1. В практической статистике она также часто выражаются в процентах. Обычно вероятность обозначаются буквой р:
0 < р < 1
Вероятности ошибки, при которой допустимо отвергнуть нулевую гипотезу и принять альтернативную гипотезу, зависит от каждого конкретного случая.
В значительной степени эта вероятность определяется характером исследуемой ситуации. Чем больше требуемая вероятность, с которой надо избежать ошибочного решения,
тем более узкими выбираются границы вероятности ошибки, при которой отвергается нулевая гипотеза, так называемый доверительный интервал вероятности.
Обычно в исследованиях используют 5% вероятность ошибки.
Существует общепринятая терминология, которая относится к доверительным интервалам вероятности:
- Высказывания, имеющие вероятность ошибки р <= 0,05 — называются значимыми.
- Высказывания с вероятностью ошибки р <= 0,01 — очень значимыми,
- А высказывания с вероятностью ошибки р <= 0,001 — максимально значимыми.
В литературе такие ситуации иногда обозначают одной, двумя или тремя звездочками.
| Вероятность ошибки | Значимость | Обозначение |
| р > 0.05 | Не значимая | ns |
| р <= 0.05 | Значимая | * |
| р <= 0.01 | Очень значимая | ** |
| р <= 0.001 | Максимально значимая | *** |
В SPSS вероятность ошибки р имеет различные обозначения; звездочки для указания степени значимости применяются лишь в немногих случаях. Обычно в SPSS значение р обозначается Sig. (Significant).
Времена, когда не было компьютеров, пригодных для статистического анализа, давали практикам по крайней мере одно преимущество. Так как все вычисления надо было выполнять вручную,
статистик должен был сначала тщательно обдумать, какие вопросы можно решить с помощью того или иного теста. Кроме того, особое значение придавалось точной формулировке нулевой гипотезы.
Но с помощью компьютера и такой мощной программы, как SPSS, очень легко можно провести множество тестов за очень короткое время. К примеру, если в таблицу сопряженности свести 50 переменных
с другими 20 переменными и выполнить тест X2, то получится 1000 результатов проверки значимости или 1000 значений р. Некритический подбор значимых величин может
дать бессмысленный результат, так как уже при граничном уровне значимости р = 0,05 в пяти процентах наблюдений, то есть в 50 возможных наблюдениях, можно ожидать значимые результаты.
Этим ошибкам первого рода (когда нулевая гипотеза отвергается, хотя она верна) следует уделять достаточно внимания. Ошибкой второго рода называется ситуация,
когда нулевая гипотеза принимается, хотя она ложна. Вероятность допустить ошибку первого рода равна вероятности ошибки р. Вероятность ошибки второго рода тем меньше, чем больше вероятность ошибки р.