
From Wikipedia, the free encyclopedia

For a value that is sampled with an unbiased normally distributed error, the above depicts the proportion of samples that would fall between 0, 1, 2, and 3 standard deviations above and below the actual value.
The standard error (SE)[1] of a statistic (usually an estimate of a parameter) is the standard deviation of its sampling distribution[2] or an estimate of that standard deviation. If the statistic is the sample mean, it is called the standard error of the mean (SEM).[1]
The sampling distribution of a mean is generated by repeated sampling from the same population and recording of the sample means obtained. This forms a distribution of different means, and this distribution has its own mean and variance. Mathematically, the variance of the sampling mean distribution obtained is equal to the variance of the population divided by the sample size. This is because as the sample size increases, sample means cluster more closely around the population mean.
Therefore, the relationship between the standard error of the mean and the standard deviation is such that, for a given sample size, the standard error of the mean equals the standard deviation divided by the square root of the sample size.[1] In other words, the standard error of the mean is a measure of the dispersion of sample means around the population mean.
In regression analysis, the term «standard error» refers either to the square root of the reduced chi-squared statistic or the standard error for a particular regression coefficient (as used in, say, confidence intervals).
Standard error of the sample mean[edit]
Exact value[edit]
Suppose a statistically independent sample of  observations
observations  is taken from a statistical population with a standard deviation of
is taken from a statistical population with a standard deviation of  . The mean value calculated from the sample,
. The mean value calculated from the sample,  , will have an associated standard error on the mean,
, will have an associated standard error on the mean,  , given by:[1]
, given by:[1]
 .
.

Practically this tells us that when trying to estimate the value of a population mean, due to the factor  , reducing the error on the estimate by a factor of two requires acquiring four times as many observations in the sample; reducing it by a factor of ten requires a hundred times as many observations.
, reducing the error on the estimate by a factor of two requires acquiring four times as many observations in the sample; reducing it by a factor of ten requires a hundred times as many observations.
Estimate[edit]
The standard deviation of the population being sampled is seldom known. Therefore, the standard error of the mean is usually estimated by replacing with the sample standard deviation  instead:
instead:
- .

As this is only an estimator for the true «standard error», it is common to see other notations here such as:
- or alternately .


A common source of confusion occurs when failing to distinguish clearly between:
Accuracy of the estimator[edit]
When the sample size is small, using the standard deviation of the sample instead of the true standard deviation of the population will tend to systematically underestimate the population standard deviation, and therefore also the standard error. With n = 2, the underestimate is about 25%, but for n = 6, the underestimate is only 5%. Gurland and Tripathi (1971) provide a correction and equation for this effect.[3] Sokal and Rohlf (1981) give an equation of the correction factor for small samples of n < 20.[4] See unbiased estimation of standard deviation for further discussion.
Derivation[edit]
The standard error on the mean may be derived from the variance of a sum of independent random variables,[5] given the definition of variance and some simple properties thereof. If is a sample of independent observations from a population with mean and standard deviation , then we can define the total

which due to the Bienaymé formula, will have variance

where we’ve approximated the standard deviations, i.e., the uncertainties, of the measurements themselves with the best value for the standard deviation of the population. The mean of these measurements is simply given by
- .

The variance of the mean is then

The standard error is, by definition, the standard deviation of which is simply the square root of the variance:
- .

For correlated random variables the sample variance needs to be computed according to the Markov chain central limit theorem.
Independent and identically distributed random variables with random sample size[edit]
There are cases when a sample is taken without knowing, in advance, how many observations will be acceptable according to some criterion. In such cases, the sample size  is a random variable whose variation adds to the variation of
is a random variable whose variation adds to the variation of  such that,
such that,
- [6]

If has a Poisson distribution, then  with estimator
with estimator  . Hence the estimator of
. Hence the estimator of  becomes
becomes  , leading the following formula for standard error:
, leading the following formula for standard error:

(since the standard deviation is the square root of the variance)
Student approximation when σ value is unknown[edit]
In many practical applications, the true value of σ is unknown. As a result, we need to use a distribution that takes into account that spread of possible σ’s.
When the true underlying distribution is known to be Gaussian, although with unknown σ, then the resulting estimated distribution follows the Student t-distribution. The standard error is the standard deviation of the Student t-distribution. T-distributions are slightly different from Gaussian, and vary depending on the size of the sample. Small samples are somewhat more likely to underestimate the population standard deviation and have a mean that differs from the true population mean, and the Student t-distribution accounts for the probability of these events with somewhat heavier tails compared to a Gaussian. To estimate the standard error of a Student t-distribution it is sufficient to use the sample standard deviation «s» instead of σ, and we could use this value to calculate confidence intervals.
Note: The Student’s probability distribution is approximated well by the Gaussian distribution when the sample size is over 100. For such samples one can use the latter distribution, which is much simpler.
Assumptions and usage[edit]
An example of how  is used is to make confidence intervals of the unknown population mean. If the sampling distribution is normally distributed, the sample mean, the standard error, and the quantiles of the normal distribution can be used to calculate confidence intervals for the true population mean. The following expressions can be used to calculate the upper and lower 95% confidence limits, where is equal to the sample mean, is equal to the standard error for the sample mean, and 1.96 is the approximate value of the 97.5 percentile point of the normal distribution:
is used is to make confidence intervals of the unknown population mean. If the sampling distribution is normally distributed, the sample mean, the standard error, and the quantiles of the normal distribution can be used to calculate confidence intervals for the true population mean. The following expressions can be used to calculate the upper and lower 95% confidence limits, where is equal to the sample mean, is equal to the standard error for the sample mean, and 1.96 is the approximate value of the 97.5 percentile point of the normal distribution:
- Upper 95% limit and
- Lower 95% limit


In particular, the standard error of a sample statistic (such as sample mean) is the actual or estimated standard deviation of the sample mean in the process by which it was generated. In other words, it is the actual or estimated standard deviation of the sampling distribution of the sample statistic. The notation for standard error can be any one of SE, SEM (for standard error of measurement or mean), or SE.
Standard errors provide simple measures of uncertainty in a value and are often used because:
- in many cases, if the standard error of several individual quantities is known then the standard error of some function of the quantities can be easily calculated;
- when the probability distribution of the value is known, it can be used to calculate an exact confidence interval;
- when the probability distribution is unknown, Chebyshev’s or the Vysochanskiï–Petunin inequalities can be used to calculate a conservative confidence interval; and
- as the sample size tends to infinity the central limit theorem guarantees that the sampling distribution of the mean is asymptotically normal.
Standard error of mean versus standard deviation[edit]
In scientific and technical literature, experimental data are often summarized either using the mean and standard deviation of the sample data or the mean with the standard error. This often leads to confusion about their interchangeability. However, the mean and standard deviation are descriptive statistics, whereas the standard error of the mean is descriptive of the random sampling process. The standard deviation of the sample data is a description of the variation in measurements, while the standard error of the mean is a probabilistic statement about how the sample size will provide a better bound on estimates of the population mean, in light of the central limit theorem.[7]
Put simply, the standard error of the sample mean is an estimate of how far the sample mean is likely to be from the population mean, whereas the standard deviation of the sample is the degree to which individuals within the sample differ from the sample mean.[8] If the population standard deviation is finite, the standard error of the mean of the sample will tend to zero with increasing sample size, because the estimate of the population mean will improve, while the standard deviation of the sample will tend to approximate the population standard deviation as the sample size increases.
Extensions[edit]
Finite population correction (FPC)[edit]
The formula given above for the standard error assumes that the population is infinite. Nonetheless, it is often used for finite populations when people are interested in measuring the process that created the existing finite population (this is called an analytic study). Though the above formula is not exactly correct when the population is finite, the difference between the finite- and infinite-population versions will be small when sampling fraction is small (e.g. a small proportion of a finite population is studied). In this case people often do not correct for the finite population, essentially treating it as an «approximately infinite» population.
If one is interested in measuring an existing finite population that will not change over time, then it is necessary to adjust for the population size (called an enumerative study). When the sampling fraction (often termed f) is large (approximately at 5% or more) in an enumerative study, the estimate of the standard error must be corrected by multiplying by a »finite population correction» (a.k.a.: FPC):[9]
[10]

which, for large N:

to account for the added precision gained by sampling close to a larger percentage of the population. The effect of the FPC is that the error becomes zero when the sample size n is equal to the population size N.
This happens in survey methodology when sampling without replacement. If sampling with replacement, then FPC does not come into play.
Correction for correlation in the sample[edit]

Expected error in the mean of A for a sample of n data points with sample bias coefficient ρ. The unbiased standard error plots as the ρ = 0 diagonal line with log-log slope −½.
If values of the measured quantity A are not statistically independent but have been obtained from known locations in parameter space x, an unbiased estimate of the true standard error of the mean (actually a correction on the standard deviation part) may be obtained by multiplying the calculated standard error of the sample by the factor f:

where the sample bias coefficient ρ is the widely used Prais–Winsten estimate of the autocorrelation-coefficient (a quantity between −1 and +1) for all sample point pairs. This approximate formula is for moderate to large sample sizes; the reference gives the exact formulas for any sample size, and can be applied to heavily autocorrelated time series like Wall Street stock quotes. Moreover, this formula works for positive and negative ρ alike.[11] See also unbiased estimation of standard deviation for more discussion.
See also[edit]
- Illustration of the central limit theorem
- Margin of error
- Probable error
- Standard error of the weighted mean
- Sample mean and sample covariance
- Standard error of the median
- Variance
- Variance of the mean and predicted responses
References[edit]
- ^ a b c d Altman, Douglas G; Bland, J Martin (2005-10-15). «Standard deviations and standard errors». BMJ: British Medical Journal. 331 (7521): 903. doi:10.1136/bmj.331.7521.903. ISSN 0959-8138. PMC 1255808. PMID 16223828.
- ^ Everitt, B. S. (2003). The Cambridge Dictionary of Statistics. CUP. ISBN 978-0-521-81099-9.
- ^ Gurland, J; Tripathi RC (1971). «A simple approximation for unbiased estimation of the standard deviation». American Statistician. 25 (4): 30–32. doi:10.2307/2682923. JSTOR 2682923.
- ^ Sokal; Rohlf (1981). Biometry: Principles and Practice of Statistics in Biological Research (2nd ed.). p. 53. ISBN 978-0-7167-1254-1.
- ^ Hutchinson, T. P. (1993). Essentials of Statistical Methods, in 41 pages. Adelaide: Rumsby. ISBN 978-0-646-12621-0.
- ^ Cornell, J R, and Benjamin, C A, Probability, Statistics, and Decisions for Civil Engineers, McGraw-Hill, NY, 1970, ISBN 0486796094, pp. 178–9.
- ^ Barde, M. (2012). «What to use to express the variability of data: Standard deviation or standard error of mean?». Perspect. Clin. Res. 3 (3): 113–116. doi:10.4103/2229-3485.100662. PMC 3487226. PMID 23125963.
- ^ Wassertheil-Smoller, Sylvia (1995). Biostatistics and Epidemiology : A Primer for Health Professionals (Second ed.). New York: Springer. pp. 40–43. ISBN 0-387-94388-9.
- ^ Isserlis, L. (1918). «On the value of a mean as calculated from a sample». Journal of the Royal Statistical Society. 81 (1): 75–81. doi:10.2307/2340569. JSTOR 2340569. (Equation 1)
- ^ Bondy, Warren; Zlot, William (1976). «The Standard Error of the Mean and the Difference Between Means for Finite Populations». The American Statistician. 30 (2): 96–97. doi:10.1080/00031305.1976.10479149. JSTOR 2683803. (Equation 2)
- ^ Bence, James R. (1995). «Analysis of Short Time Series: Correcting for Autocorrelation». Ecology. 76 (2): 628–639. doi:10.2307/1941218. JSTOR 1941218.
Выборочная оценка всегда ошибочна. Так, стандартная ошибка средней показывает разброс средней. Для бинарной переменной (с двумя возможными значениями) средней арифметической является доля «успехов». В этой статье показано, как рассчитать дисперсию и стандартную ошибку доли.
Долю используют в качестве выборочной оценки вероятности. Обозначим долю как p*, а истинную вероятность как p . При бесконечно большом количестве наблюдений доля p* стремится к теоретической вероятности p. Этот факт известен со времен Якоба Бернулли.
Дисперсия и стандартная ошибка доли
Обратимся вначале к дисперсии биномиальной переменной. Если истинная вероятность p не известна, то используют ее оценку p*.
![]()
где B – сумма «успехов» в выборке;
n – количество наблюдений;
p* – оценка вероятности, т.е. доля «успехов».
Нас интересует дисперсия величины B/n. Согласно одному из свойств дисперсии, постоянный множитель выносится за скобки и возводится в квадрат.
Получаем формулу дисперсию доли:
![]()
Почти полная аналогия со средней арифметической. В числителе дисперсия самой переменной (1 или 0), внизу – объем выборки.
Стандартная ошибка доли – корень из дисперсии:

Стандартная ошибка доли при увеличении выборки ведет себя так же, как и стандартная ошибка средней: чем больше выборка, тем меньше ошибка, но при этом уменьшение постоянно замедляется.
Как известно, максимально возможная дисперсия переменной в схеме Бернулли достигается при p*=0,5. Она равна 0,5*(1-0,5)=0,25. Отсюда легко рассчитать максимальную стандартную ошибку доли, полученную по некоторой выборке.

Изобразим эту зависимость на диаграмме.

График имеет знакомую конфигурацию: ошибка уменьшается с замедлением. Так, при объеме выборки равной 100 наблюдениям стандартная ошибка (максимально возможная!) равна 0,05 (или 5 процентных пункта). При n=1000 стандартная ошибка доли составляет всего 0,0158 (или 1,58 процентных пункта). Повторюсь, что это максимум. Именно поэтому опросы общественно мнения редко превышают 1500-2000 человек (чтобы еще была возможность разбить данные на группы достаточно размера).
На практике довольно часто приходится анализировать бинарные данные. Это может быть анкетирование покупателей, контроль качества продукции и много чего еще. Поэтому доля, как оценка вероятности наступления интересующего события, – довольно распространенный показатель. Дисперсия и стандартная ошибка доли используется в расчете приблизительных доверительных интервалов вероятности и в проверке статистических гипотез.
Поделиться в социальных сетях:
Стандартное отклонение и стандартная ошибка: в чем разница?
17 авг. 2022 г.
читать 2 мин
В статистике студенты часто путают два термина: стандартное отклонение и стандартная ошибка .
Стандартное отклонение измеряет, насколько разбросаны значения в наборе данных.
Стандартная ошибка — это стандартное отклонение среднего значения в повторных выборках из совокупности.
Давайте рассмотрим пример, чтобы ясно проиллюстрировать эту идею.
Пример: стандартное отклонение против стандартной ошибки
Предположим, мы измеряем вес 10 разных черепах.

Для этой выборки из 10 черепах мы можем вычислить среднее значение выборки и стандартное отклонение выборки:

Предположим, что стандартное отклонение оказалось равным 8,68. Это дает нам представление о том, насколько распределен вес этих черепах.
Но предположим, что мы собираем еще одну простую случайную выборку из 10 черепах и также проводим их измерения. Более чем вероятно, что эта выборка из 10 черепах будет иметь немного другое среднее значение и стандартное отклонение, даже если они взяты из одной и той же популяции:

Теперь, если мы представим, что мы берем повторные выборки из одной и той же совокупности и записываем выборочное среднее и выборочное стандартное отклонение для каждой выборки:

Теперь представьте, что мы наносим каждое среднее значение выборки на одну и ту же строку:

Стандартное отклонение этих средних значений известно как стандартная ошибка.

Формула для фактического расчета стандартной ошибки:
Стандартная ошибка = s/ √n
куда:
- s: стандартное отклонение выборки
- n: размер выборки
Какой смысл использовать стандартную ошибку?
Когда мы вычисляем среднее значение данной выборки, нас на самом деле интересует не среднее значение этой конкретной выборки, а скорее среднее значение большей совокупности, из которой взята выборка.
Однако мы используем выборки, потому что для них гораздо проще собирать данные, чем для всего населения. И, конечно же, среднее значение выборки будет варьироваться от выборки к выборке, поэтому мы используем стандартную ошибку среднего значения как способ измерить, насколько точна наша оценка среднего значения.
Вы заметите из формулы для расчета стандартной ошибки, что по мере увеличения размера выборки (n) стандартная ошибка уменьшается:
Стандартная ошибка = s/ √n
Это должно иметь смысл, поскольку большие размеры выборки уменьшают изменчивость и увеличивают вероятность того, что среднее значение нашей выборки ближе к фактическому среднему значению генеральной совокупности.
Когда использовать стандартное отклонение против стандартной ошибки
Если мы просто заинтересованы в измерении того, насколько разбросаны значения в наборе данных, мы можем использовать стандартное отклонение .
Однако, если мы заинтересованы в количественной оценке неопределенности оценки среднего значения, мы можем использовать стандартную ошибку среднего значения .
В зависимости от вашего конкретного сценария и того, чего вы пытаетесь достичь, вы можете использовать либо стандартное отклонение, либо стандартную ошибку.
Содержание
- Расчет ошибки средней арифметической
- Способ 1: расчет с помощью комбинации функций
- Способ 2: применение инструмента «Описательная статистика»
- Вопросы и ответы

Стандартная ошибка или, как часто называют, ошибка средней арифметической, является одним из важных статистических показателей. С помощью данного показателя можно определить неоднородность выборки. Он также довольно важен при прогнозировании. Давайте узнаем, какими способами можно рассчитать величину стандартной ошибки с помощью инструментов Microsoft Excel.
Расчет ошибки средней арифметической
Одним из показателей, которые характеризуют цельность и однородность выборки, является стандартная ошибка. Эта величина представляет собой корень квадратный из дисперсии. Сама дисперсия является средним квадратном от средней арифметической. Средняя арифметическая вычисляется делением суммарной величины объектов выборки на их общее количество.
В Экселе существуют два способа вычисления стандартной ошибки: используя набор функций и при помощи инструментов Пакета анализа. Давайте подробно рассмотрим каждый из этих вариантов.
Способ 1: расчет с помощью комбинации функций
Прежде всего, давайте составим алгоритм действий на конкретном примере по расчету ошибки средней арифметической, используя для этих целей комбинацию функций. Для выполнения задачи нам понадобятся операторы СТАНДОТКЛОН.В, КОРЕНЬ и СЧЁТ.
Для примера нами будет использована выборка из двенадцати чисел, представленных в таблице.

- Выделяем ячейку, в которой будет выводиться итоговое значение стандартной ошибки, и клацаем по иконке «Вставить функцию».
- Открывается Мастер функций. Производим перемещение в блок «Статистические». В представленном перечне наименований выбираем название «СТАНДОТКЛОН.В».
- Запускается окно аргументов вышеуказанного оператора. СТАНДОТКЛОН.В предназначен для оценивания стандартного отклонения при выборке. Данный оператор имеет следующий синтаксис:
=СТАНДОТКЛОН.В(число1;число2;…)«Число1» и последующие аргументы являются числовыми значениями или ссылками на ячейки и диапазоны листа, в которых они расположены. Всего может насчитываться до 255 аргументов этого типа. Обязательным является только первый аргумент.
Итак, устанавливаем курсор в поле «Число1». Далее, обязательно произведя зажим левой кнопки мыши, выделяем курсором весь диапазон выборки на листе. Координаты данного массива тут же отображаются в поле окна. После этого клацаем по кнопке «OK».
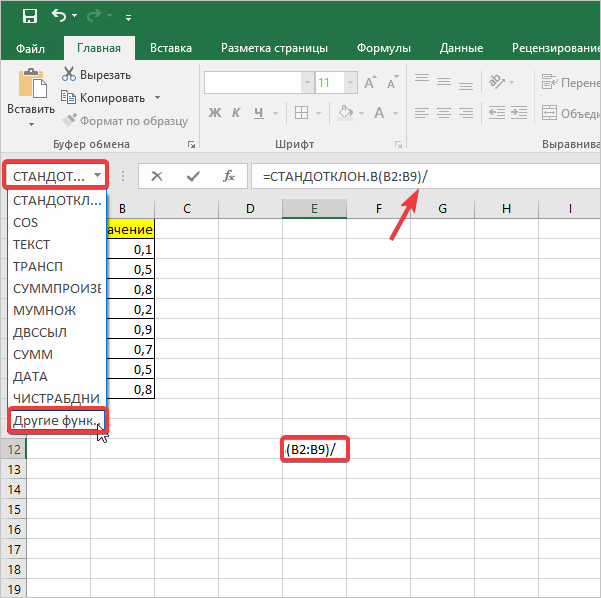
- В ячейку на листе выводится результат расчета оператора СТАНДОТКЛОН.В. Но это ещё не ошибка средней арифметической. Для того, чтобы получить искомое значение, нужно стандартное отклонение разделить на квадратный корень от количества элементов выборки. Для того, чтобы продолжить вычисления, выделяем ячейку, содержащую функцию СТАНДОТКЛОН.В. После этого устанавливаем курсор в строку формул и дописываем после уже существующего выражения знак деления (/). Вслед за этим клацаем по пиктограмме перевернутого вниз углом треугольника, которая располагается слева от строки формул. Открывается список недавно использованных функций. Если вы в нем найдете наименование оператора «КОРЕНЬ», то переходите по данному наименованию. В обратном случае жмите по пункту «Другие функции…».
- Снова происходит запуск Мастера функций. На этот раз нам следует посетить категорию «Математические». В представленном перечне выделяем название «КОРЕНЬ» и жмем на кнопку «OK».
- Открывается окно аргументов функции КОРЕНЬ. Единственной задачей данного оператора является вычисление квадратного корня из заданного числа. Его синтаксис предельно простой:
=КОРЕНЬ(число)Как видим, функция имеет всего один аргумент «Число». Он может быть представлен числовым значением, ссылкой на ячейку, в которой оно содержится или другой функцией, вычисляющей это число. Последний вариант как раз и будет представлен в нашем примере.
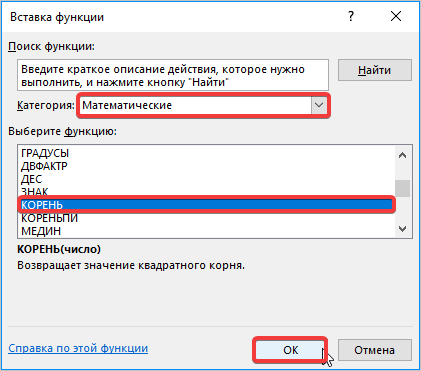
Устанавливаем курсор в поле «Число» и кликаем по знакомому нам треугольнику, который вызывает список последних использованных функций. Ищем в нем наименование «СЧЁТ». Если находим, то кликаем по нему. В обратном случае, опять же, переходим по наименованию «Другие функции…».
- В раскрывшемся окне Мастера функций производим перемещение в группу «Статистические». Там выделяем наименование «СЧЁТ» и выполняем клик по кнопке «OK».
- Запускается окно аргументов функции СЧЁТ. Указанный оператор предназначен для вычисления количества ячеек, которые заполнены числовыми значениями. В нашем случае он будет подсчитывать количество элементов выборки и сообщать результат «материнскому» оператору КОРЕНЬ. Синтаксис функции следующий:
=СЧЁТ(значение1;значение2;…)В качестве аргументов «Значение», которых может насчитываться до 255 штук, выступают ссылки на диапазоны ячеек. Ставим курсор в поле «Значение1», зажимаем левую кнопку мыши и выделяем весь диапазон выборки. После того, как его координаты отобразились в поле, жмем на кнопку «OK».
- После выполнения последнего действия будет не только рассчитано количество ячеек заполненных числами, но и вычислена ошибка средней арифметической, так как это был последний штрих в работе над данной формулой. Величина стандартной ошибки выведена в ту ячейку, где размещена сложная формула, общий вид которой в нашем случае следующий:
=СТАНДОТКЛОН.В(B2:B13)/КОРЕНЬ(СЧЁТ(B2:B13))Результат вычисления ошибки средней арифметической составил 0,505793. Запомним это число и сравним с тем, которое получим при решении поставленной задачи следующим способом.










Но дело в том, что для малых выборок (до 30 единиц) для большей точности лучше применять немного измененную формулу. В ней величина стандартного отклонения делится не на квадратный корень от количества элементов выборки, а на квадратный корень от количества элементов выборки минус один. Таким образом, с учетом нюансов малой выборки наша формула приобретет следующий вид:
=СТАНДОТКЛОН.В(B2:B13)/КОРЕНЬ(СЧЁТ(B2:B13)-1)

Урок: Статистические функции в Экселе
Способ 2: применение инструмента «Описательная статистика»
Вторым вариантом, с помощью которого можно вычислить стандартную ошибку в Экселе, является применение инструмента «Описательная статистика», входящего в набор инструментов «Анализ данных» («Пакет анализа»). «Описательная статистика» проводит комплексный анализ выборки по различным критериям. Одним из них как раз и является нахождение ошибки средней арифметической.
Но чтобы воспользоваться данной возможностью, нужно сразу активировать «Пакет анализа», так как по умолчанию в Экселе он отключен.
- После того, как открыт документ с выборкой, переходим во вкладку «Файл».
- Далее, воспользовавшись левым вертикальным меню, перемещаемся через его пункт в раздел «Параметры».
- Запускается окно параметров Эксель. В левой части данного окна размещено меню, через которое перемещаемся в подраздел «Надстройки».
- В самой нижней части появившегося окна расположено поле «Управление». Выставляем в нем параметр «Надстройки Excel» и жмем на кнопку «Перейти…» справа от него.
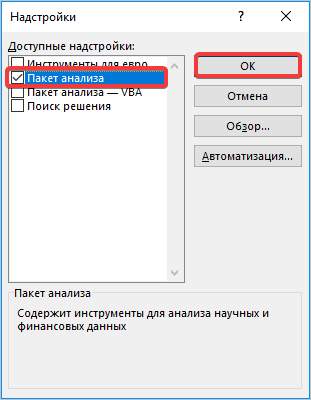
- Запускается окно надстроек с перечнем доступных скриптов. Отмечаем галочкой наименование «Пакет анализа» и щелкаем по кнопке «OK» в правой части окошка.
- После выполнения последнего действия на ленте появится новая группа инструментов, которая имеет наименование «Анализ». Чтобы перейти к ней, щелкаем по названию вкладки «Данные».
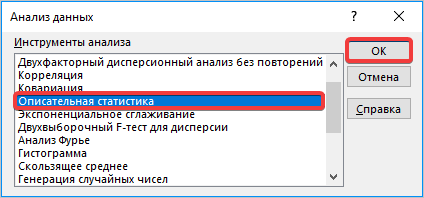
- После перехода жмем на кнопку «Анализ данных» в блоке инструментов «Анализ», который расположен в самом конце ленты.
- Запускается окошко выбора инструмента анализа. Выделяем наименование «Описательная статистика» и жмем на кнопку «OK» справа.
- Запускается окно настроек инструмента комплексного статистического анализа «Описательная статистика».
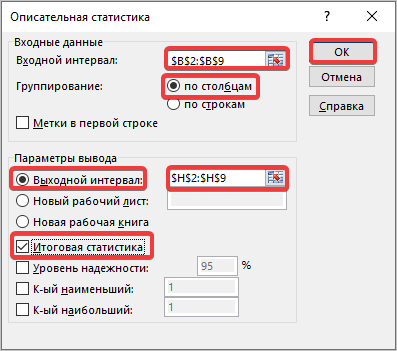
В поле «Входной интервал» необходимо указать диапазон ячеек таблицы, в которых находится анализируемая выборка. Вручную это делать неудобно, хотя и можно, поэтому ставим курсор в указанное поле и при зажатой левой кнопке мыши выделяем соответствующий массив данных на листе. Его координаты тут же отобразятся в поле окна.
В блоке «Группирование» оставляем настройки по умолчанию. То есть, переключатель должен стоять около пункта «По столбцам». Если это не так, то его следует переставить.
Галочку «Метки в первой строке» можно не устанавливать. Для решения нашего вопроса это не важно.
Далее переходим к блоку настроек «Параметры вывода». Здесь следует указать, куда именно будет выводиться результат расчета инструмента «Описательная статистика»:
- На новый лист;
- В новую книгу (другой файл);
- В указанный диапазон текущего листа.
Давайте выберем последний из этих вариантов. Для этого переставляем переключатель в позицию «Выходной интервал» и устанавливаем курсор в поле напротив данного параметра. После этого клацаем на листе по ячейке, которая станет верхним левым элементом массива вывода данных. Её координаты должны отобразиться в поле, в котором мы до этого устанавливали курсор.
Далее следует блок настроек определяющий, какие именно данные нужно вводить:
- Итоговая статистика;
- К-ый наибольший;
- К-ый наименьший;
- Уровень надежности.
Для определения стандартной ошибки обязательно нужно установить галочку около параметра «Итоговая статистика». Напротив остальных пунктов выставляем галочки на свое усмотрение. На решение нашей основной задачи это никак не повлияет.
После того, как все настройки в окне «Описательная статистика» установлены, щелкаем по кнопке «OK» в его правой части.
- После этого инструмент «Описательная статистика» выводит результаты обработки выборки на текущий лист. Как видим, это довольно много разноплановых статистических показателей, но среди них есть и нужный нам – «Стандартная ошибка». Он равен числу 0,505793. Это в точности тот же результат, который мы достигли путем применения сложной формулы при описании предыдущего способа.










Урок: Описательная статистика в Экселе
Как видим, в Экселе можно произвести расчет стандартной ошибки двумя способами: применив набор функций и воспользовавшись инструментом пакета анализа «Описательная статистика». Итоговый результат будет абсолютно одинаковый. Поэтому выбор метода зависит от удобства пользователя и поставленной конкретной задачи. Например, если ошибка средней арифметической является только одним из многих статистических показателей выборки, которые нужно рассчитать, то удобнее воспользоваться инструментом «Описательная статистика». Но если вам нужно вычислить исключительно этот показатель, то во избежание нагромождения лишних данных лучше прибегнуть к сложной формуле. В этом случае результат расчета уместится в одной ячейке листа.
![]()
Загрузить PDF
![]()
Загрузить PDF
Стандартной ошибкой называется величина, которая характеризует стандартное (среднеквадратическое) отклонение выборочного среднего. Другими словами, эту величину можно использовать для оценки точности выборочного среднего. Множество областей применения стандартной ошибки по умолчанию предполагают нормальное распределение. Если вам нужно рассчитать стандартную ошибку, перейдите к шагу 1.
-
1
Запомните определение среднеквадратического отклонения. Среднеквадратическое отклонение выборки – это мера рассеянности значения. Среднеквадратическое отклонение выборки обычно обозначается буквой s. Математическая формула среднеквадратического отклонения приведена выше.
-
2
Узнайте, что такое истинное среднее значение. Истинное среднее является средним группы чисел, включающим все числа всей группы – другими словами, это среднее всей группы чисел, а не выборки.
-
3
Научитесь рассчитывать среднеарифметическое значение. Среднеаримфетическое означает попросту среднее: сумму значений собранных данных, разделенную на количество значений этих данных.
-
4
Узнайте, что такое выборочное среднее. Когда среднеарифметическое значение основано на серии наблюдений, полученных в результате выборок из статистической совокупности, оно называется “выборочным средним”. Это среднее выборки чисел, которое описывает среднее значение лишь части чисел из всей группы. Его обозначают как:
-
5
Усвойте понятие нормального распределения. Нормальные распределения, которые используются чаще других распределений, являются симметричными, с единичным максимумом в центре – на среднем значении данных. Форма кривой подобна очертаниям колокола, при этом график равномерно опускается по обе стороны от среднего. Пятьдесят процентов распределения лежит слева от среднего, а другие пятьдесят процентов – справа от него. Рассеянность значений нормального распределения описывается стандартным отклонением.
-
6
Запомните основную формулу. Формула для вычисления стандартной ошибки приведена выше.
Реклама






-
1
Рассчитайте выборочное среднее. Чтобы найти стандартную ошибку, сначала нужно определить среднеквадратическое отклонение (поскольку среднеквадратическое отклонение s входит в формулу для вычисления стандартной ошибки). Начните с нахождения средних значений. Выборочное среднее выражается как среднее арифметическое измерений x1, x2, . . . , xn. Его рассчитывают по формуле, приведенной выше.
- Допустим, например, что вам нужно рассчитать стандартную ошибку выборочного среднего результатов измерения массы пяти монет, указанных в таблице:
Вы сможете рассчитать выборочное среднее, подставив значения массы в формулу:
- Допустим, например, что вам нужно рассчитать стандартную ошибку выборочного среднего результатов измерения массы пяти монет, указанных в таблице:
-
2
Вычтите выборочное среднее из каждого измерения и возведите полученное значение в квадрат. Как только вы получите выборочное среднее, вы можете расширить вашу таблицу, вычтя его из каждого измерения и возведя результат в квадрат.
- Для нашего примера расширенная таблица будет иметь следующий вид:
-
3
Найдите суммарное отклонение ваших измерений от выборочного среднего. Общее отклонение – это сумма возведенных в квадрат разностей от выборочного среднего. Чтобы определить его, сложите ваши новые значения.
- В нашем примере нужно будет выполнить следующий расчет:
Это уравнение дает сумму квадратов отклонений измерений от выборочного среднего.
- В нашем примере нужно будет выполнить следующий расчет:
-
4
Рассчитайте среднеквадратическое отклонение ваших измерений от выборочного среднего. Как только вы будете знать суммарное отклонение, вы сможете найти среднее отклонение, разделив ответ на n -1. Обратите внимание, что n равно числу измерений.
- В нашем примере было сделано 5 измерений, следовательно n – 1 будет равно 4. Расчет нужно вести следующим образом:
-
5
Найдите среднеквадратичное отклонение. Сейчас у вас есть все необходимые значения для того, чтобы воспользоваться формулой для нахождения среднеквадратичного отклонения s.
- В нашем примере вы будете рассчитывать среднеквадратичное отклонение следующим образом:
Следовательно, среднеквадратичное отклонение равно 0,0071624.
Реклама
- В нашем примере вы будете рассчитывать среднеквадратичное отклонение следующим образом:





-
1
Чтобы вычислить стандартную ошибку, воспользуйтесь базовой формулой со среднеквадратическим отклонением.
- В нашем примере вы сможете рассчитать стандартную ошибку следующим образом:
Таким образом в нашем примере стандартная ошибка (среднеквадратическое отклонение выборочного среднего) составляет 0,0032031 грамма.
- В нашем примере вы сможете рассчитать стандартную ошибку следующим образом:

Советы
- Стандартную ошибку и среднеквадратическое отклонение часто путают. Обратите внимание, что стандартная ошибка описывает среднеквадратическое отклонение выборочного распределения статистических данных, а не распределения отдельных значений
- В научных журналах понятия стандартной ошибки и среднеквадратического отклонения несколько размыты. Для объединения двух величин используется знак ±.
Реклама
Об этой статье
Эту страницу просматривали 47 997 раз.
Была ли эта статья полезной?
17 авг. 2022 г.
читать 2 мин
Стандартная ошибка среднего — это способ измерить, насколько разбросаны значения в наборе данных. Он рассчитывается как:
Стандартная ошибка = с / √n
куда:
- s : стандартное отклонение выборки
- n : размер выборки
Вы можете рассчитать стандартную ошибку среднего для любого набора данных в Excel, используя следующую формулу:
= СТАНДОТКЛОН (диапазон значений) / КОРЕНЬ ( СЧЁТ (диапазон значений))
В следующем примере показано, как использовать эту формулу.
Пример: Стандартная ошибка в Excel
Предположим, у нас есть следующий набор данных:
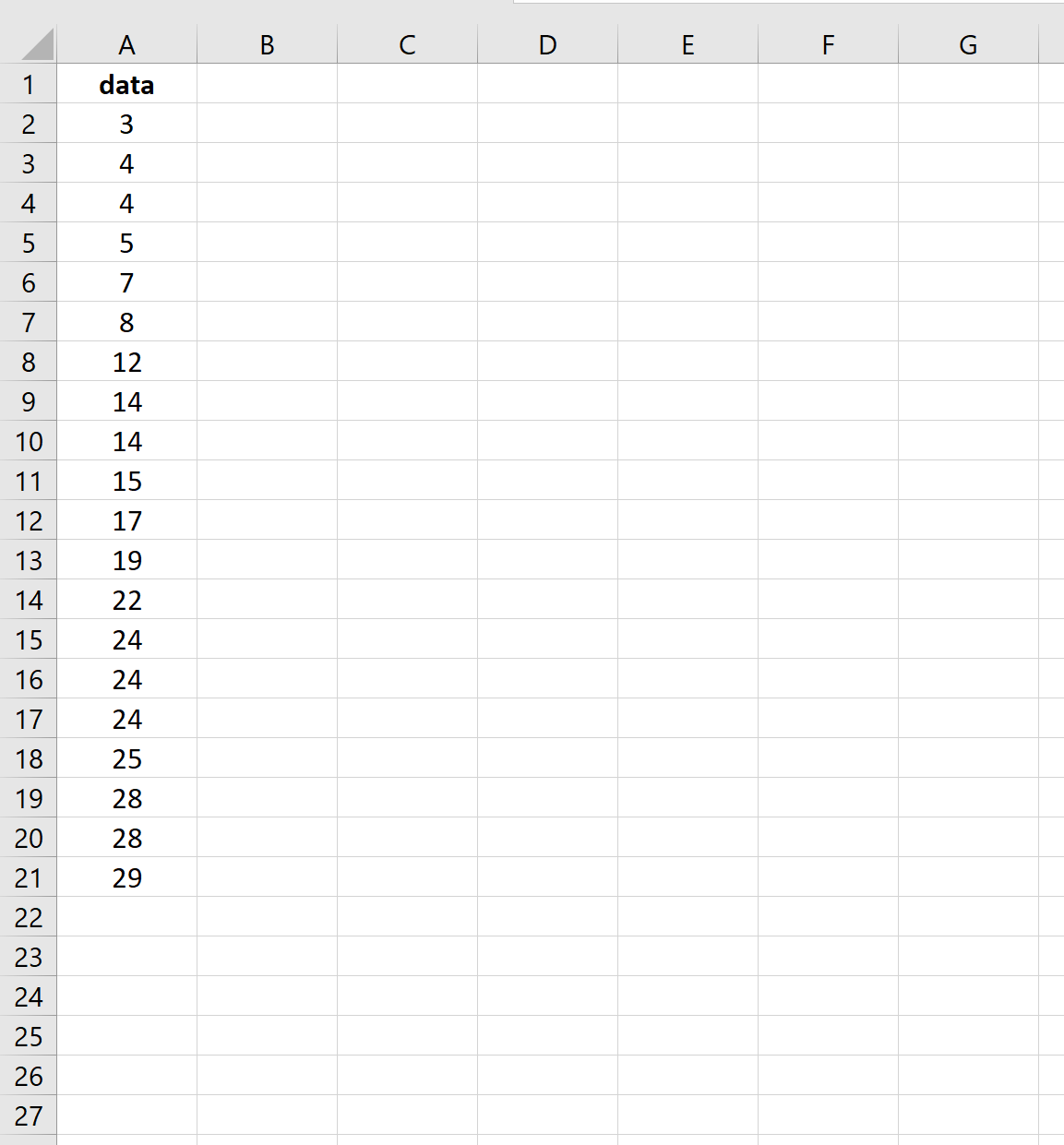
На следующем снимке экрана показано, как рассчитать стандартную ошибку среднего значения для этого набора данных:
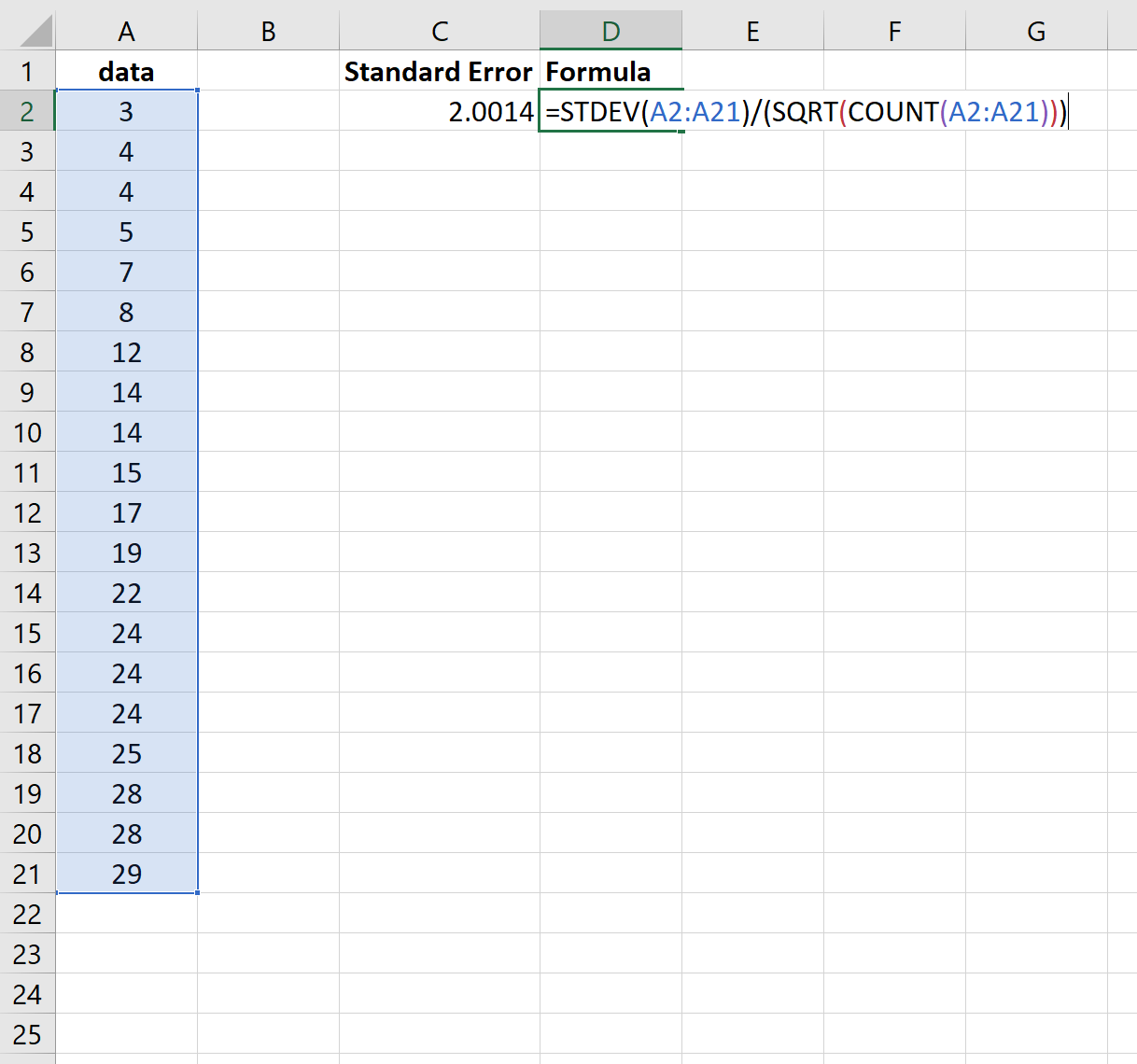
Стандартная ошибка оказывается равной 2,0014 .
Обратите внимание, что функция =СТАНДОТКЛОН() вычисляет выборочное среднее, что эквивалентно функции =СТАНДОТКЛОН.С() в Excel.
Таким образом, мы могли бы использовать следующую формулу для получения тех же результатов:
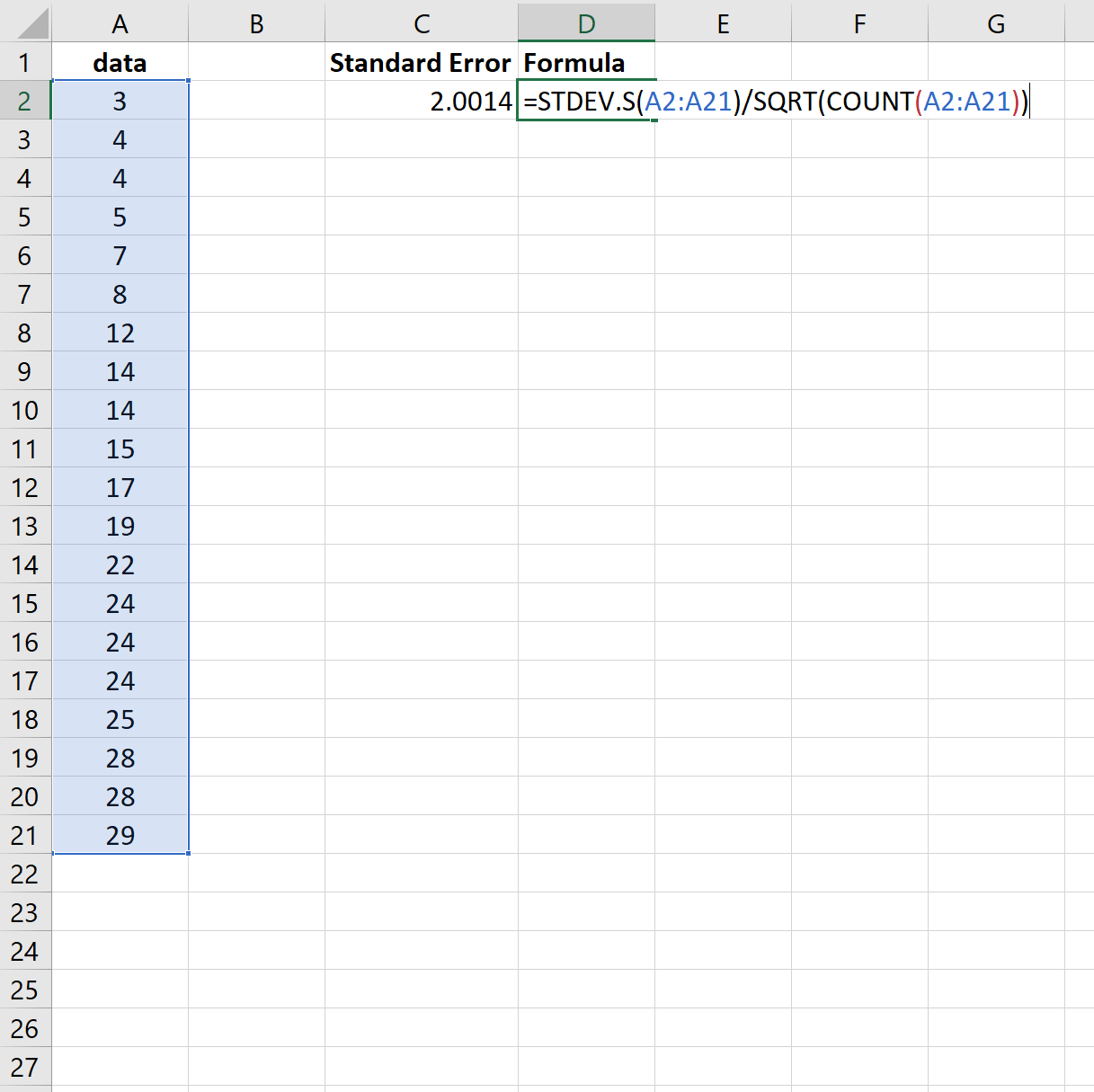
И снова стандартная ошибка оказывается равной 2,0014 .
Как интерпретировать стандартную ошибку среднего
Стандартная ошибка среднего — это просто мера того, насколько разбросаны значения вокруг среднего. При интерпретации стандартной ошибки среднего следует помнить о двух вещах:
1. Чем больше стандартная ошибка среднего, тем более разбросаны значения вокруг среднего в наборе данных.
Чтобы проиллюстрировать это, рассмотрим, изменим ли мы последнее значение в предыдущем наборе данных на гораздо большее число:
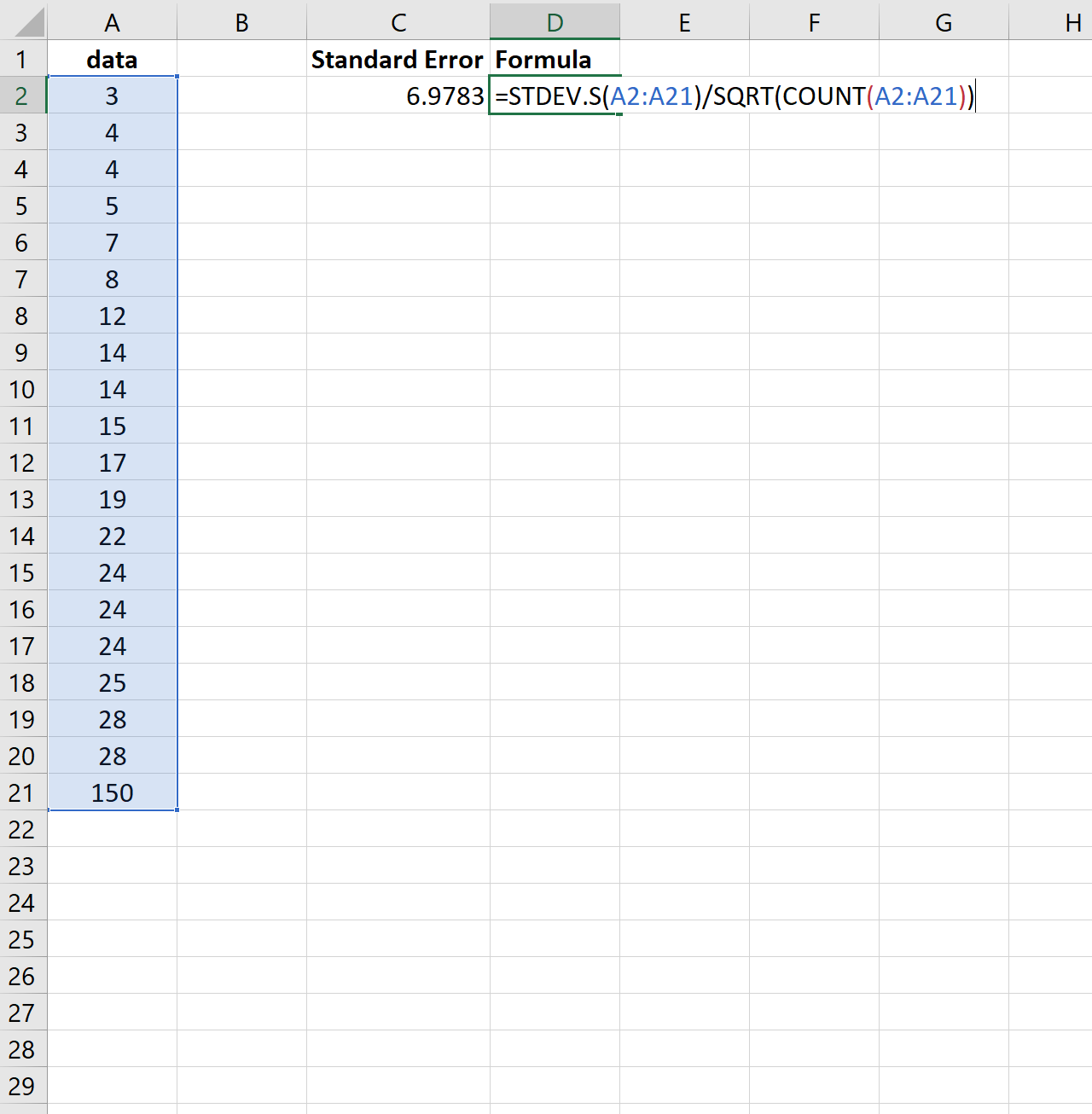
Обратите внимание на скачок стандартной ошибки с 2,0014 до 6,9783.Это указывает на то, что значения в этом наборе данных более разбросаны вокруг среднего значения по сравнению с предыдущим набором данных.
2. По мере увеличения размера выборки стандартная ошибка среднего имеет тенденцию к уменьшению.
Чтобы проиллюстрировать это, рассмотрим стандартную ошибку среднего для следующих двух наборов данных:
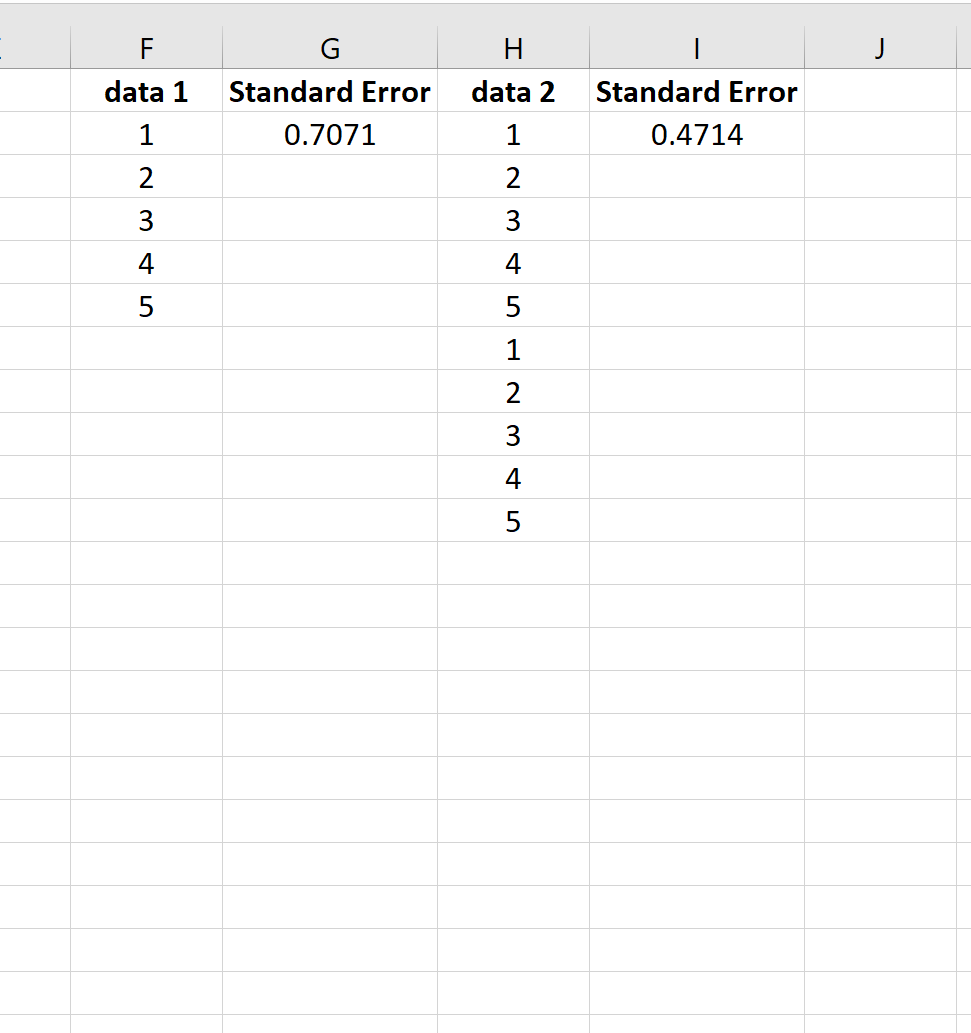
Второй набор данных — это просто первый набор данных, повторенный дважды. Таким образом, два набора данных имеют одинаковое среднее значение, но второй набор данных имеет больший размер выборки, поэтому стандартная ошибка меньше.
Стандартная ошибка появляется при прогнозировании каких-либо данных или арифметических вычислениях, поэтому важно научиться находить этот параметр. В этой публикации разбираем, как найти и исправить стандартную ошибку путем использования инструментов Excel.
Расчет средней арифметической ошибки
В Microsoft Excel цельность и однородность выборки определяется при помощи стандартной ошибки. Стандартная ошибка — это квадратный корень из дисперсии. В приложении предусмотрено два варианта поиска стандартной ошибки: при помощи пакетного анализа и расширенных функций программы.
Чтобы найти значение средней арифметической, необходимо выполнить деление суммарной величины выборки на ее количество в электронной книге.
Расчет стандартной ошибки при помощи встроенных функций
Для того, чтобы правильно вычислять, необходимо изучить пошаговую инструкцию. В этом способе подбор результатов будет осуществляться с помощью комбинированных манипуляций.
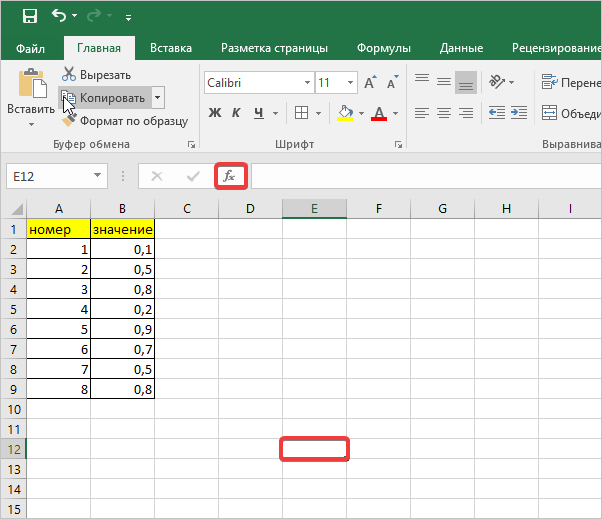
- Для расчетов будем использовать таблицу с выборкой чисел. Кликаем на любой пустой ячейке на листе, где будет отображаться результат. Затем нажимаем кнопку «Вставить функцию.
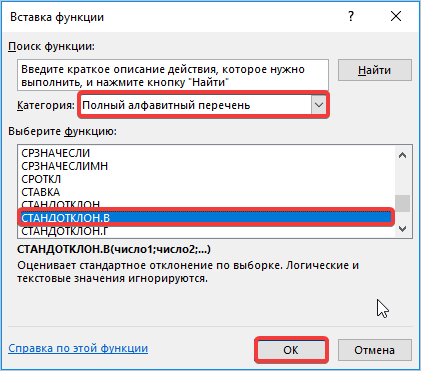
- Далее перед вами открывается диалоговое окно, в котором необходимо использовать «СТАНДОТКЛ.В», для этого в поле «Категория» необходимо выбрать «Полный алфавитный перечень». Затем нажмите кнопку «ОК».
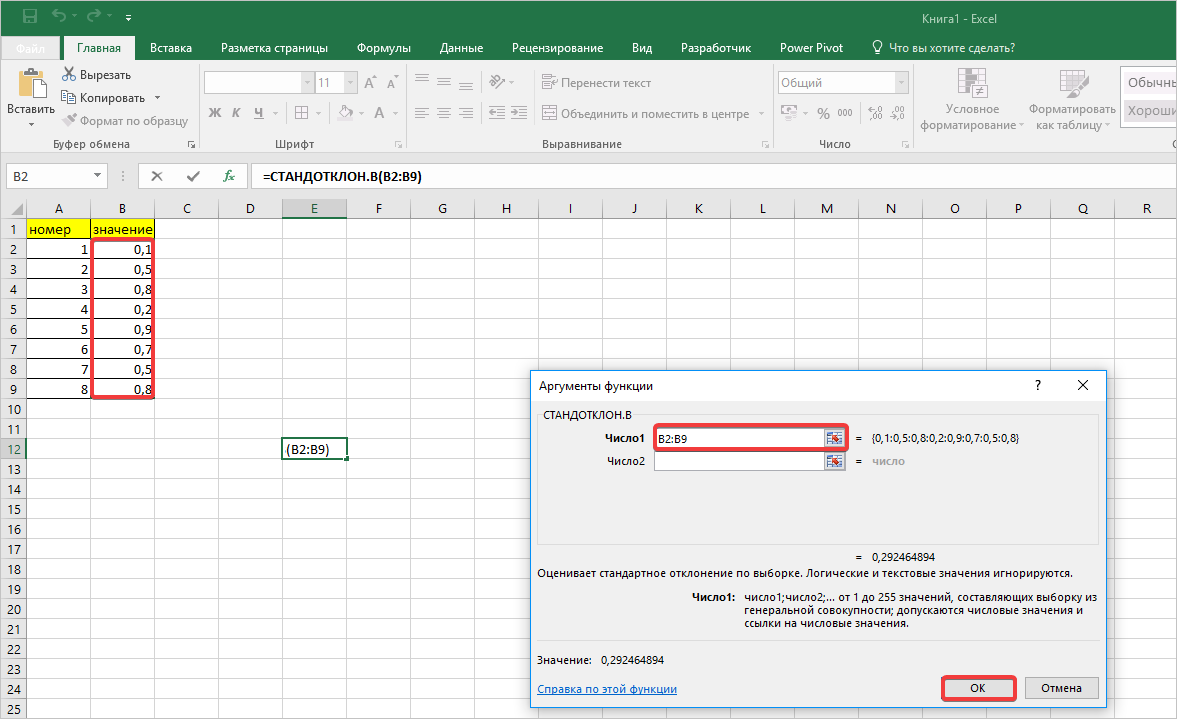
- В окне «Аргументы функции» кликаем в первом поле «Число 1», затем выполняем выделение мышью диапазона ячеек со значениями таблицы и нажимаем кнопку «ОК».
- Далее активируем ячейку с нашими значениями, переходим в строку формулы и ставим после значений наклонную линию. Переходим в поле наименования, кликаем на указывающий вниз флажок, где из списка выбираем «Другие функции».
- Снова активируется окно с перечнем функций, в котором необходимо выбрать категорию «Математические», затем функцию «Корень». Далее нажмите кнопку «ОК».
- Далее открывается окно, в котором необходимо заполнить поле с числом. Для этого переходим в поле «Имя», где спускаемся к пункту «Счет». Если его нет, ищите в дополнительных функциях.
После выполнения этих шагов, стандартная ошибка высчитывается автоматически, пользователю остается только сверить их и проверить значение на некорректное отображение.
Для малых и стандартных выборок необходимо использовать разные формулы. В первом случае (если находится до 30 значений), ее необходимо видоизменить.
Решение задачи с помощью опции «Описательная статистика»
Благодаря опции «Описательная статистика» удается выполнить вычисление по различным критериям. По этим правилам удается найти среднюю арифметическую ошибку. Для использования данного метода предварительно нужно запустить «Пакет анализа».
- Переходим во вкладку «Файл», где перемещаемся в пункт «Параметры». Далее нажимаем на запись «Надстройки».
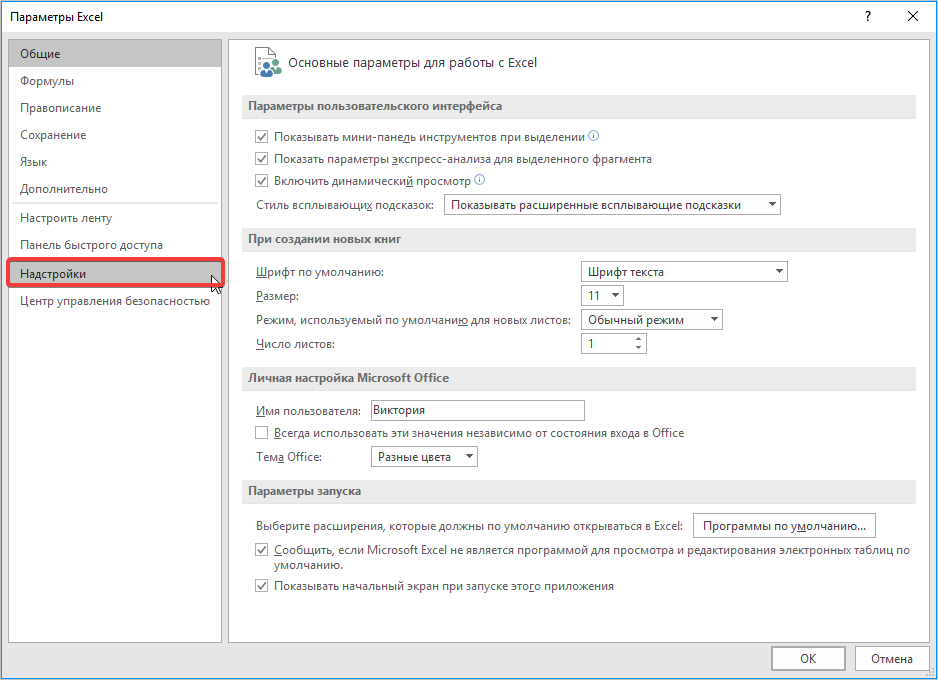
- Открывается окошко, в нем в графе «Управление» должно быть прописано «Надстройки Excel», затем рядом нажимаем кнопку «Параметры».
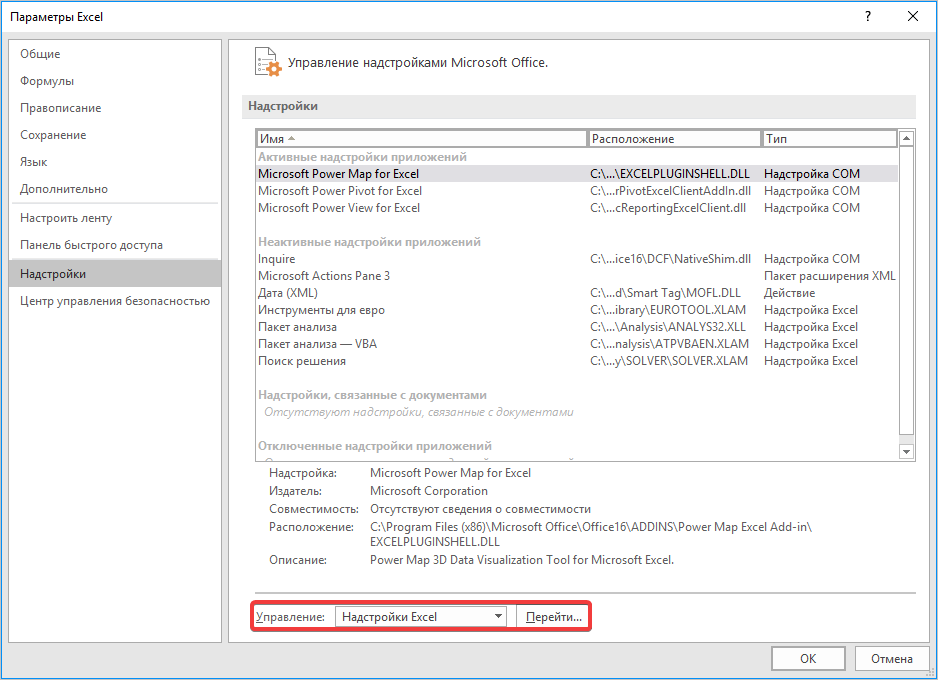
- В появившемся окне находим «Пакет анализа» и нажимаем кнопку «ОК».
- Далее выбираем любую свободную ячейку, переходим во вкладку «Данные» и нажимаем «Анализ данных» в блоке «Анализ».

- Происходит запуск вспомогательного окошка, в котором необходимо выбрать из всех инструментов «Описательную статистику» и нажать кнопку «ОК».
- Открывается новый мастер значений. Здесь нужно вводить данные предельно внимательно. В поле «Входной интервал» вносим адрес диапазона ячеек с выборкой. Затем указываем параметр «Группирование» «По столбцам». Затем выбираем место для «выходного интервала», его должно быть столько же, сколько и «входного». Ставим галочку напротив «Итоговая статистика» и нажимаем кнопку «ОК».
В результате вычислений вы получаете небольшую таблицу, в которой указаны все данные с определенной стандартной ошибкой.
Чтобы
судить о том, насколько точно проведенные
измерения отражают состав генеральной
совокупности, необходимо вычислить
стандартную ошибку средней арифметической
выборочной совокупности.
Стандартная
ошибка средней арифметической
характеризует степень отклонения
выборочной средней арифметической от
средней арифметической генеральной
совокупности.
Стандартная
ошибка средней арифметической вычисляется
по формуле:
![]() ,
,
где
– стандартное отклонение результатов
измерений, n
– объем выборки.
Зачастую
мы имеем дело с одной случайной выборкой
и с одной полученной при ее обработке
выборочной средней. Задача заключается
в суждении о величине неизвестной
генеральной средней по полученной
неточной величине случайной выборочной
средней.
Вычислим
среднюю ошибку найденного выборочного
среднего значения роста:
![]() 195
195
см; σ = 8,8 см;
![]() см.
см.
2,8 см
составляют не максимальную, а среднюю
возможную ошибку среднего. Отдельные
выборочные средние могут отклоняться
от генеральной как больше, так и меньше,
чем на 2,8 см.
Каковы
же пределы возможных ошибок случайной
выборки, какова ее максимальная ошибка?
Величина максимальной ошибки зависит
от величины средней ошибки и вычисляется
по формуле
![]() .
.
При
объеме выборки n
= 10:
![]() .
.
Все
случайные выборочные средние, которые
могут быть получены в подобных опытах
(в том числе и фактически полученная
выборочная средняя
![]() = 195 см), при своем варьировании около
= 195 см), при своем варьировании около
неизвестного генерального среднего в
подавляющем количестве группируются
около него так, что лишь ничтожный
процент их отклоняется от генеральной
средней более, чем на величину максимальной
ошибки.
Другими
словами, генеральная средняя определяется
как
![]() .
.
Эти пределы
колебаний значительно сужаются, если
средняя ошибка уменьшается благодаря
увеличению численности выборки.
Искомая
генеральная средняя лежит между
![]() и
и![]() .
.
Таким образом, при высокой точности
выполнения эксперимента и достаточно
большом числе измерений можно определить
среднюю арифметическую бесконечно
большого числа экспериментов.
До сих
пор мы определяли максимальную ошибку
выборочной средней, исходя из того, что
все остальные показатели известны. Если
же мы хотим достичь определенной
точности, определенного приближения к
генеральной средней, в этом случае
встает вопрос о численности выборки (о
том, сколько измерений, опытов необходимо
провести).
Допустим, что
максимальная ошибка должна быть равна
5 см. Сколько человек надо обследовать
(измерить) в нашем случае?
![]() .
.
Следовательно,
мы должны провести измерения роста у
36 баскетболистов высокого класса.
10. Достоверность различий
Следующим
важным вопросом практически для каждого
экспериментатора является умение
доказать достоверность различий между
двумя рядами признаков.
Проверку
достоверности различия двух рядов
измерений производят путем вычисления
критерия достоверности различия – t:
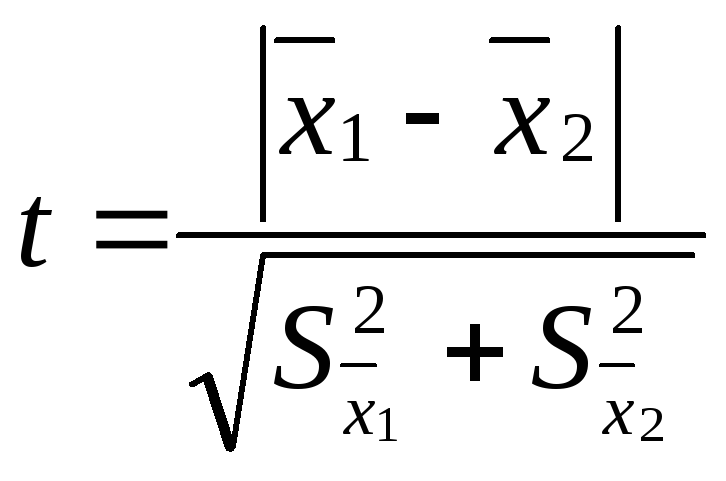 ,
,
где
![]() – средняя одной выборки;
– средняя одной выборки;![]() – средняя другой выборки;
– средняя другой выборки;![]() – средняя ошибка первой выборки;
– средняя ошибка первой выборки;![]() – второй выборки. Если t < 2, то различие
– второй выборки. Если t < 2, то различие
между двумя выборками считается
недостоверным, если t
2, то различие между двумя выборками
достоверно на 95%.
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
![]()
Download Article
![]()
Download Article
After collecting data, oftentimes the first thing you need to do is analyze it. This usually entails finding the mean, the standard deviation, and the standard error of the data. This article will show you how it’s done.
Cheat Sheets
-
1
Obtain a set of numbers you wish to analyze. This information is referred to as a sample.
- For example, a test was given to a class of 5 students, and the test results are 12, 55, 74, 79 and 90.

Advertisement
-
1
Calculate the mean. Add up all the numbers and divide by the population size:[1]
- Mean (μ) = ΣX/N, where Σ is the summation (addition) sign, xi is each individual number, and N is the population size.
- In the case above, the mean μ is simply (12+55+74+79+90)/5 = 62.

-
1
Calculate the standard deviation. This represents the spread of the population.
Standard deviation = σ = sq rt [(Σ((X-μ)^2))/(N)].[2]
- For the example given, the standard deviation is sqrt[((12-62)^2 + (55-62)^2 + (74-62)^2 + (79-62)^2 + (90-62)^2)/(5)] = 27.4. (Note that if this was the sample standard deviation, you would divide by n-1, the sample size minus 1.)

Advertisement
-
1
Calculate the standard error (of the mean). This represents how well the sample mean approximates the population mean. The larger the sample, the smaller the standard error, and the closer the sample mean approximates the population mean. Do this by dividing the standard deviation by the square root of N, the sample size.[3]
Standard error = σ/sqrt(n)[4]
- So for the example above, if this were a sampling of 5 students from a class of 50 and the 50 students had a standard deviation of 17 (σ = 21), the standard error = 17/sqrt(5) = 7.6.

Add New Question
-
Question
How do you find the mean given number of observations?

To find the mean, add all the numbers together and divide by how many numbers there are. e.g to find the mean of 1,7,8,4,2: 1+7+8+4+2 = 22/5 = 4.4.
-
Question
The standard error is calculated as 0.2 and the standard deviation of a sample is 5kg. Can it be said to be smaller or larger than the standard deviation?
The standard error (SE) must be smaller than the standard deviation (SD), because the SE is calculating by dividing the SD by something — i.e. making it smaller.
-
Question
How can I find out the standard deviation of 50 samples?
The results of all your figures (number plus number plus number etc.) divided by quantity of samples 50 =SD.
See more answers
Ask a Question
200 characters left
Include your email address to get a message when this question is answered.
Submit
Advertisement
Video
-
Calculations of the mean, standard deviation, and standard error are most useful for analysis of normally distributed data. One standard deviation about the central tendency covers approximately 68 percent of the data, 2 standard deviation 95 percent of the data, and 3 standard deviation 99.7 percent of the data. The standard error gets smaller (narrower spread) as the sample size increases.
Thanks for submitting a tip for review!
Advertisement
-
Check your math carefully. It is very easy to make mistakes or enter numbers incorrectly.
Advertisement
References
About This Article
Article SummaryX
The mean is simply the average of a set of numbers. You can work it out by adding up all the numbers and dividing the total by the amount of numbers. For example, if you wanted to find the average test score of 3 students who scored 74, 79, and 90, you’d add the 3 numbers together to get 243, then divide it by 3 to get 81. The standard error represents how well the sample mean approximates the population mean. All you need to do is divide the standard deviation by the square root of the sample size. For instance, if you were sampling 5 students from a class of 50 and the 50 students had a standard deviation of 17, you’d divide 17 by the square root of 5 to get 7.6. For more tips, including how to calculate the standard deviation, read on!
Did this summary help you?
Thanks to all authors for creating a page that has been read 995,237 times.
Did this article help you?
![]()
Download Article
![]()
Download Article
After collecting data, oftentimes the first thing you need to do is analyze it. This usually entails finding the mean, the standard deviation, and the standard error of the data. This article will show you how it’s done.
Cheat Sheets
-
1
Obtain a set of numbers you wish to analyze. This information is referred to as a sample.
- For example, a test was given to a class of 5 students, and the test results are 12, 55, 74, 79 and 90.
Advertisement
-
1
Calculate the mean. Add up all the numbers and divide by the population size:[1]
- Mean (μ) = ΣX/N, where Σ is the summation (addition) sign, xi is each individual number, and N is the population size.
- In the case above, the mean μ is simply (12+55+74+79+90)/5 = 62.
-
1
Calculate the standard deviation. This represents the spread of the population.
Standard deviation = σ = sq rt [(Σ((X-μ)^2))/(N)].[2]
- For the example given, the standard deviation is sqrt[((12-62)^2 + (55-62)^2 + (74-62)^2 + (79-62)^2 + (90-62)^2)/(5)] = 27.4. (Note that if this was the sample standard deviation, you would divide by n-1, the sample size minus 1.)
Advertisement
-
1
Calculate the standard error (of the mean). This represents how well the sample mean approximates the population mean. The larger the sample, the smaller the standard error, and the closer the sample mean approximates the population mean. Do this by dividing the standard deviation by the square root of N, the sample size.[3]
Standard error = σ/sqrt(n)[4]
- So for the example above, if this were a sampling of 5 students from a class of 50 and the 50 students had a standard deviation of 17 (σ = 21), the standard error = 17/sqrt(5) = 7.6.
Add New Question
-
Question
How do you find the mean given number of observations?
To find the mean, add all the numbers together and divide by how many numbers there are. e.g to find the mean of 1,7,8,4,2: 1+7+8+4+2 = 22/5 = 4.4.
-
Question
The standard error is calculated as 0.2 and the standard deviation of a sample is 5kg. Can it be said to be smaller or larger than the standard deviation?
The standard error (SE) must be smaller than the standard deviation (SD), because the SE is calculating by dividing the SD by something — i.e. making it smaller.
-
Question
How can I find out the standard deviation of 50 samples?
The results of all your figures (number plus number plus number etc.) divided by quantity of samples 50 =SD.
See more answers
Ask a Question
200 characters left
Include your email address to get a message when this question is answered.
Submit
Advertisement
Video
-
Calculations of the mean, standard deviation, and standard error are most useful for analysis of normally distributed data. One standard deviation about the central tendency covers approximately 68 percent of the data, 2 standard deviation 95 percent of the data, and 3 standard deviation 99.7 percent of the data. The standard error gets smaller (narrower spread) as the sample size increases.
Thanks for submitting a tip for review!
Advertisement
-
Check your math carefully. It is very easy to make mistakes or enter numbers incorrectly.
Advertisement
References
About This Article
Article SummaryX
The mean is simply the average of a set of numbers. You can work it out by adding up all the numbers and dividing the total by the amount of numbers. For example, if you wanted to find the average test score of 3 students who scored 74, 79, and 90, you’d add the 3 numbers together to get 243, then divide it by 3 to get 81. The standard error represents how well the sample mean approximates the population mean. All you need to do is divide the standard deviation by the square root of the sample size. For instance, if you were sampling 5 students from a class of 50 and the 50 students had a standard deviation of 17, you’d divide 17 by the square root of 5 to get 7.6. For more tips, including how to calculate the standard deviation, read on!
Did this summary help you?
Thanks to all authors for creating a page that has been read 995,237 times.
Did this article help you?
Excel для Microsoft 365 Excel для Microsoft 365 для Mac Excel для Интернета Excel 2021 Excel 2021 for Mac Excel 2019 Excel 2019 для Mac Excel 2016 Excel 2016 для Mac Excel 2013 Excel 2010 Excel 2007 Excel для Mac 2011 Excel Starter 2010 Еще…Меньше
В этой статье описаны синтаксис формулы и использование функции СТОШYX в Microsoft Excel.
Описание
Возвращает стандартную ошибку предсказанных значений y для каждого значения x в регрессии. Стандартная ошибка — это мера ошибки предсказанного значения y для отдельного значения x.
Синтаксис
СТОШYX(известные_значения_y;известные_значения_x)
Аргументы функции СТОШYX описаны ниже.
-
Известные_значения_y Обязательный. Массив или диапазон зависимых точек данных.
-
Известные_значения_x Обязательный. Массив или диапазон независимых точек данных.
Замечания
-
Аргументы могут быть либо числами, либо содержащими числа именами, массивами или ссылками.
-
Учитываются логические значения и текстовые представления чисел, которые непосредственно введены в список аргументов.
-
Если аргумент, который является массивом или ссылкой, содержит текст, логические значения или пустые ячейки, то такие значения пропускаются; однако ячейки, которые содержат нулевые значения, учитываются.
-
Аргументы, которые представляют собой значения ошибок или текст, не преобразуемый в числа, вызывают ошибку.
-
Если аргументы «известные_значения_y» и «известные_значения_x» содержат различное количество точек данных, то функция СТОШYX возвращает значение ошибки #Н/Д.
-
Если known_y и known_x пустые или имеют менее трех точек данных, steYX возвращает #DIV/0! значение ошибки #ЗНАЧ!.
-
Уравнение для стандартной ошибки предсказанного y имеет следующий вид:
где x и y — выборочные средние значения СРЗНАЧ(известные_значения_x) и СРЗНАЧ(известные_значения_y), а n — размер выборки.
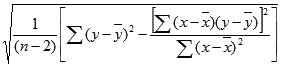
Пример
Скопируйте образец данных из следующей таблицы и вставьте их в ячейку A1 нового листа Excel. Чтобы отобразить результаты формул, выделите их и нажмите клавишу F2, а затем — клавишу ВВОД. При необходимости измените ширину столбцов, чтобы видеть все данные.
|
Данные |
||
|
Известные значения y |
Известные значения x |
|
|
2 |
6 |
|
|
3 |
5 |
|
|
9 |
11 |
|
|
1 |
7 |
|
|
8 |
5 |
|
|
7 |
4 |
|
|
5 |
4 |
|
|
Формула |
Описание (результат) |
Результат |
|
=СТОШYX(A3:A9;B3:B9) |
Стандартная ошибка предсказанных значений y для каждого значения x в регрессии (3,305719) |
3,305719 |
Нужна дополнительная помощь?
Что такое Стандартная формула ошибки?
Стандартная ошибка — это ошибка, которая возникает в распределении выборки при выполнении статистического анализа. Это вариант стандартного отклонения, так как оба понятия соответствуют мерам спреда. Высокая стандартная ошибка соответствует более высокому разбросу данных для взятой выборки. Вычисление формулы стандартной ошибки выполняется для выборки. В то же время стандартное отклонение определяет генеральную совокупность.
Оглавление
- Что такое Стандартная формула ошибки?
- Объяснение
- Пример формулы стандартной ошибки
- Калькулятор стандартной ошибки
- Актуальность и использование
- Стандартная формула ошибки в Excel
- Рекомендуемые статьи
Следовательно, стандартная ошибка среднего значения будет выражаться и определяться в соответствии с соотношением, описанным следующим образом:
σ͞x = σ/√n

Здесь,
- Стандартная ошибка, выраженная как σ͞x.
- Стандартное отклонение совокупности выражается как σ.
- Количество переменных в выборке, выраженное как n.
В статистическом анализе среднее значение, медиана и мода являются центральной тенденцией. Центральная тенденция Центральная тенденция — это статистическая мера, которая отображает центральную точку всего распределения данных, и вы можете найти ее с помощью 3 различных мер, т. е. среднего, медианы и моды.Подробнее меры. Стандартное отклонение, дисперсия и стандартная ошибка среднего классифицируются как меры изменчивости. Стандартная ошибка среднего для выборочных данных напрямую связана со стандартным отклонением большей совокупности и обратно пропорциональна или связана с квадратным корнем. число. Чтобы использовать эту функцию, введите термин =SQRT и нажмите клавишу табуляции, которая вызовет функцию SQRT. Более того, эта функция принимает один аргумент из нескольких переменных, используемых для создания выборки. Следовательно, если размер выборки Размер выборкиФормула размера выборки отображает соответствующий диапазон генеральной совокупности, в которой проводится эксперимент или опрос. Он измеряется с использованием размера генеральной совокупности, критического значения нормального распределения при требуемом доверительном уровне, доли выборки и предела погрешности. Если больше, то может быть равная вероятность того, что стандартная ошибка также будет большой.
Объяснение
Можно объяснить формулу для стандартной ошибки среднего, используя следующие шаги:
- Определите и организуйте выборку и определите количество переменных.
- Затем среднее значение выборки соответствует количеству переменных, присутствующих в выборке.
- Затем определите стандартное отклонение выборки.
- Затем определите квадратный корень из числа переменных, включенных в выборку.
- Теперь разделите стандартное отклонение, вычисленное на шаге 3, на полученное значение на шаге 4, чтобы получить стандартную ошибку.
Пример формулы стандартной ошибки
Ниже приведены примеры формул для расчета стандартной ошибки.
.free_excel_div{фон:#d9d9d9;размер шрифта:16px;радиус границы:7px;позиция:относительная;margin:30px;padding:25px 25px 25px 45px}.free_excel_div:before{content:»»;фон:url(центр центр без повтора #207245;ширина:70px;высота:70px;позиция:абсолютная;верх:50%;margin-top:-35px;слева:-35px;граница:5px сплошная #fff;граница-радиус:50%} Вы можете скачать этот шаблон стандартной формулы ошибки Excel здесь — Стандартная формула ошибки Шаблон Excel
Пример №1
Возьмем в качестве примера акции ABC. В течение 30 лет акции приносили средний долларовый доход в размере 45 долларов. Кроме того, было замечено, что акции приносят прибыль со стандартным отклонением в 2 доллара. Помогите инвестору рассчитать общую стандартную ошибку средней доходности, предлагаемой акцией ABC.
Решение:
- Стандартное отклонение (σ) = $2
- Количество лет (n) = 30
- Средняя доходность в долларах = 45 долларов.
Расчет стандартной ошибки выглядит следующим образом:

- σ͞x = σ/√n
- = 2 доллара США/√30
- = 2 доллара США / 5,4773
Стандартная ошибка,

- σx = 0,3651 доллара США
Таким образом, инвестиция предлагает инвестору стандартную долларовую ошибку в среднем 0,36515 доллара при удерживании позиции ABC в течение 30 лет. Однако, если бы акции сохранялись для более высокого инвестиционного горизонта, то стандартная ошибка среднего значения в долларах значительно уменьшилась бы.
Пример #2
Возьмем в качестве примера инвестора, который получил следующую доходность акций XYZ:
Год инвестиций Предлагаемая доходность120%225%35%410%
Помогите инвестору рассчитать общую стандартную ошибку средней доходности акций XYZ.
Решение:
Сначала определите среднее значение доходности, как показано ниже: –

- ͞X = (x1+x2+x3+x4)/количество лет
- = (20+25+5+10)/4
- =15%
Теперь определите стандартное отклонение доходности, как показано ниже: –

- σ = √ ((x1-͞X)2 + (x2-͞X)2 + (x3-͞X)2 + (x4-͞X)2) / √ (количество лет -1)
- = √ ((20-15) 2 + (25-15) 2 + (5-15) 2 + (10-15) 2) / √ (4-1)
- = (√ (5) 2 + (10) 2 + (-10) 2 + (-5) 2 ) / √ (3)
- = (√25+100+100+25)/ √ (3)
- =√250/√3
- =√83,3333
- «=» 9,1287%
Теперь вычисление стандартной ошибки выглядит следующим образом:

- σ͞x = σ/√n
- = 9,128709/√4
- = 9,128709/2
Стандартная ошибка,

- σx = 4,56%
Таким образом, инвестиции предлагают инвестору стандартную ошибку в долларах в среднем 4,56% при удержании позиции XYZ в течение 4 лет.
Калькулятор стандартной ошибки
Вы можете использовать следующий калькулятор.
.cal-tbl td{ верхняя граница: 0 !важно; }.cal-tbl tr{ высота строки: 0.5em; } Только экран @media и (минимальная ширина устройства: 320 пикселей) и (максимальная ширина устройства: 480 пикселей) { .cal-tbl tr{ line-height: 1em !important; } } σnСтандартная формула ошибки
Формула стандартной ошибки =σ =√n 0 = 0√0
Актуальность и использование
Стандартная ошибка имеет тенденцию быть высокой, если размер выборки для анализа мал. Следовательно, выборка всегда берется из большей совокупности, которая включает больший размер переменных. Это всегда помогает статистику определить достоверность среднего значения выборки относительно среднего значения генеральной совокупности.
Большая стандартная ошибка говорит статистику, что выборка неоднородна в отношении среднего значения генеральной совокупности. Относительно населения наблюдается большой разброс в выборке. Точно так же небольшая стандартная ошибка говорит статистику, что выборка однородна относительно среднего значения генеральной совокупности. Отсутствуют или незначительные различия в выборке относительно населения.
Не следует смешивать его со стандартным отклонением. Вместо этого следует рассчитать стандартное отклонение для всей совокупности. Стандартная ошибкаСтандартная ошибкаСтандартная ошибка (SE) — это метрика, которая измеряет точность выборочного распределения, обозначающего совокупность, с использованием стандартного отклонения. Другими словами, это мера дисперсии среднего значения выборки, связанная со средним значением генеральной совокупности, а не стандартное отклонение. С другой стороны, оно определяется для среднего значения выборки.
Стандартная формула ошибки в Excel
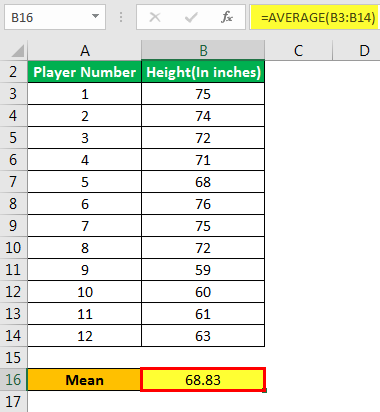
Теперь давайте возьмем пример Excel, чтобы проиллюстрировать концепцию стандартной формулы ошибки в шаблоне Excel ниже. Предположим, администрация школы хочет определить стандартную ошибку среднего значения роста футболистов.
Выборка состоит из следующих значений: –

Помогите администрации оценить стандартную ошибку среднего значения.
Шаг 1: Определите среднее значение, как показано ниже: –
Шаг 2: Определите стандартное отклонение, как показано ниже: –

Шаг 3: Определите стандартную ошибку среднего значения, как показано ниже: –

Следовательно, стандартная ошибка среднего значения для футболистов составляет 1,846 дюйма. Руководство должно заметить, что оно значительно велико. Таким образом, выборочные данные, взятые для анализа, неоднородны и имеют большую дисперсию.
Руководству следует либо исключить более мелких игроков, либо добавить игроков значительно выше, чтобы сбалансировать средний рост футбольной команды, заменив их людьми с меньшим ростом по сравнению с их сверстниками.
Рекомендуемые статьи
Эта статья была руководством по формуле стандартной ошибки. Здесь мы обсуждаем формулу для расчета среднего значения, стандартную ошибку, примеры и загружаемый лист Excel. Вы можете узнать больше из следующих статей: –
- Формула рентабельности EBITDA
- Формула валовой прибыли
- Формула относительного стандартного отклонения
- Формула погрешности