
Ошибки первого и второго рода
Выдвинутая гипотеза
может быть правильной или неправильной,
поэтому возникает необходимость её
проверки. Поскольку проверку производят
статистическими методами, её называют
статистической. В итоге статистической
проверки гипотезы в двух случаях может
быть принято неправильное решение, т.
е. могут быть допущены ошибки двух родов.
Ошибка первого
рода состоит в том, что будет отвергнута
правильная гипотеза.
Ошибка второго
рода состоит в том, что будет принята
неправильная гипотеза.
Подчеркнём, что
последствия этих ошибок могут оказаться
весьма различными. Например, если
отвергнуто правильное решение «продолжать
строительство жилого дома», то эта
ошибка первого рода повлечёт материальный
ущерб: если же принято неправильное
решение «продолжать строительство»,
несмотря на опасность обвала стройки,
то эта ошибка второго рода может повлечь
гибель людей. Можно привести примеры,
когда ошибка первого рода влечёт более
тяжёлые последствия, чем ошибка второго
рода.
Замечание 1.
Правильное решение может быть принято
также в двух случаях:
-
гипотеза принимается,
причём и в действительности она
правильная; -
гипотеза отвергается,
причём и в действительности она неверна.
Замечание 2.
Вероятность совершить ошибку первого
рода принято обозначать через
![]() ;
;
её называют уровнем значимости. Наиболее
часто уровень значимости принимают
равным 0,05 или 0,01. Если, например, принят
уровень значимости, равный 0,05, то это
означает, что в пяти случаях из ста
имеется риск допустить ошибку первого
рода (отвергнуть правильную гипотезу).
Статистический
критерий проверки нулевой гипотезы.
Наблюдаемое значение критерия
Для проверки
нулевой гипотезы используют специально
подобранную случайную величину, точное
или приближённое распределение которой
известно. Обозначим эту величину в целях
общности через
![]() .
.
Статистическим
критерием
(или просто критерием) называют случайную
величину
![]() ,
,
которая служит для проверки нулевой
гипотезы.
Например, если
проверяют гипотезу о равенстве дисперсий
двух нормальных генеральных совокупностей,
то в качестве критерия
![]() принимают отношение исправленных
принимают отношение исправленных
выборочных дисперсий: .
.
Эта величина
случайная, потому что в различных опытах
дисперсии принимают различные, наперёд
неизвестные значения, и распределена
по закону Фишера – Снедекора.
Для проверки
гипотезы по данным выборок вычисляют
частные значения входящих в критерий
величин и таким образом получают частное
(наблюдаемое) значение критерия.
Наблюдаемым
значением
![]() называют значение критерия, вычисленное
называют значение критерия, вычисленное
по выборкам. Например, если по двум
выборкам найдены исправленные выборочные
дисперсии![]() и
и![]() ,
,
то наблюдаемое значение критерия .
.
Критическая
область. Область принятия гипотезы.
Критические точки
После выбора
определённого критерия множество всех
его возможных значений разбивают на
два непересекающихся подмножества:
одно из них содержит значения критерия,
при которых нулевая гипотеза отвергается,
а другая – при которых она принимается.
Критической
областью называют совокупность значений
критерия, при которых нулевую гипотезу
отвергают.
Областью принятия
гипотезы (областью допустимых значений)
называют совокупность значений критерия,
при которых гипотезу принимают.
Основной принцип
проверки статистических гипотез можно
сформулировать так: если наблюдаемое
значение критерия принадлежит критической
области – гипотезу отвергают, если
наблюдаемое значение критерия принадлежит
области принятия гипотезы – гипотезу
принимают.
Поскольку критерий
![]() — одномерная случайная величина, все её
— одномерная случайная величина, все её
возможные значения принадлежат некоторому
интервалу. Поэтому критическая область
и область принятия гипотезы также
являются интервалами и, следовательно,
существуют точки, которые их разделяют.
Критическими
точками (границами)
![]() называют точки, отделяющие критическую
называют точки, отделяющие критическую
область от области принятия гипотезы.
Различают
одностороннюю (правостороннюю или
левостороннюю) и двустороннюю критические
области.
Правосторонней
называют критическую область, определяемую
неравенством
![]() >
>![]() ,
,
где![]() — положительное число.
— положительное число.
Левосторонней
называют критическую область, определяемую
неравенством
![]() <
<![]() ,
,
где![]() — отрицательное число.
— отрицательное число.
Односторонней
называют правостороннюю или левостороннюю
критическую область.
Двусторонней
называют критическую область, определяемую
неравенствами
![]() где
где![]() .
.
В частности, если
критические точки симметричны относительно
нуля, двусторонняя критическая область
определяется неравенствами ( в
предположении, что
![]() >0):
>0):
![]() ,
,
или равносильным неравенством
![]() .
.
Отыскание
правосторонней критической области
Как найти критическую
область? Обоснованный ответ на этот
вопрос требует привлечения довольно
сложной теории. Ограничимся её элементами.
Для определённости начнём с нахождения
правосторонней критической области,
которая определяется неравенством
![]() >
>![]() ,
,
где![]() >0.
>0.
Видим, что для отыскания правосторонней
критической области достаточно найти
критическую точку. Следовательно,
возникает новый вопрос: как её найти?
Для её нахождения
задаются достаточной малой вероятностью
– уровнем значимости
![]() .
.
Затем ищут критическую точку![]() ,
,
исходя из требования, чтобы при условии
справедливости нулевой гипотезы
вероятность того, критерий![]() примет значение, большее
примет значение, большее![]() ,
,
была равна принятому уровню значимости:
Р(![]() >
>![]() )=
)=![]() .
.
Для каждого критерия
имеются соответствующие таблицы, по
которым и находят критическую точку,
удовлетворяющую этому требованию.
Замечание 1.
Когда
критическая точка уже найдена, вычисляют
по данным выборок наблюдаемое значение
критерия и, если окажется, что
![]() >
>![]() ,
,
то нулевую гипотезу отвергают; если же![]() <
<![]() ,
,
то нет оснований, чтобы отвергнуть
нулевую гипотезу.
Пояснение. Почему
правосторонняя критическая область
была определена, исходя из требования,
чтобы при справедливости нулевой
гипотезы выполнялось соотношение
Р(![]() >
>![]() )=
)=![]() ?
?
(*)
Поскольку вероятность
события
![]() >
>![]() мала (
мала (![]() — малая вероятность), такое событие при
— малая вероятность), такое событие при
справедливости нулевой гипотезы, в силу
принципа практической невозможности
маловероятных событий, в единичном
испытании не должно наступить. Если всё
же оно произошло, т.е. наблюдаемое
значение критерия оказалось больше![]() ,
,
то это можно объяснить тем, что нулевая
гипотеза ложна и, следовательно, должна
быть отвергнута. Таким образом, требование
(*) определяет такие значения критерия,
при которых нулевая гипотеза отвергается,
а они и составляют правостороннюю
критическую область.
Замечание 2.
Наблюдаемое значение критерия может
оказаться большим
![]() не потому, что нулевая гипотеза ложна,
не потому, что нулевая гипотеза ложна,
а по другим причинам (малый объём выборки,
недостатки методики эксперимента и
др.). В этом случае, отвергнув правильную
нулевую гипотезу, совершают ошибку
первого рода. Вероятность этой ошибки
равна уровню значимости![]() .
.
Итак, пользуясь требованием (*), мы с
вероятностью![]() рискуем совершить ошибку первого рода.
рискуем совершить ошибку первого рода.
Замечание 3. Пусть
нулевая гипотеза принята; ошибочно
думать, что тем самым она доказана.
Действительно, известно, что один пример,
подтверждающий справедливость некоторого
общего утверждения, ещё не доказывает
его. Поэтому более правильно говорить,
«данные наблюдений согласуются с нулевой
гипотезой и, следовательно, не дают
оснований её отвергнуть».
На практике для
большей уверенности принятия гипотезы
её проверяют другими способами или
повторяют эксперимент, увеличив объём
выборки.
Отвергают гипотезу
более категорично, чем принимают.
Действительно, известно, что достаточно
привести один пример, противоречащий
некоторому общему утверждению, чтобы
это утверждение отвергнуть. Если
оказалось, что наблюдаемое значение
критерия принадлежит критической
области, то этот факт и служит примером,
противоречащим нулевой гипотезе, что
позволяет её отклонить.
Отыскание
левосторонней и двусторонней критических
областей***
Отыскание
левосторонней и двусторонней критических
областей сводится (так же, как и для
правосторонней) к нахождению соответствующих
критических точек. Левосторонняя
критическая область определяется
неравенством
![]() <
<![]() (
(![]() <0).
<0).
Критическую точку находят, исходя из
требования, чтобы при справедливости
нулевой гипотезы вероятность того, что
критерий примет значение, меньшее![]() ,
,
была равна принятому уровню значимости:
Р(![]() <
<![]() )=
)=![]() .
.
Двусторонняя
критическая область определяется
неравенствами
![]() Критические
Критические
точки находят, исходя из требования,
чтобы при справедливости нулевой
гипотезы сумма вероятностей того, что
критерий примет значение, меньшее![]() или большее
или большее![]() ,
,
была равна принятому уровню значимости:
![]() .
.
(*)
Ясно, что критические
точки могут быть выбраны бесчисленным
множеством способов. Если же распределение
критерия симметрично относительно нуля
и имеются основания (например, для
увеличения мощности) выбрать симметричные
относительно нуля точки (-
![]() )и
)и![]() (
(![]() >0),
>0),
то
![]() Учитывая (*), получим
Учитывая (*), получим
![]() .
.
Это соотношение
и служит для отыскания критических
точек двусторонней критической области.
Критические точки находят по соответствующим
таблицам.
Дополнительные
сведения о выборе критической области.
Мощность критерия
Мы строили
критическую область, исходя из требования,
чтобы вероятность попадания в неё
критерия была равна
![]() при условии, что нулевая гипотеза
при условии, что нулевая гипотеза
справедлива. Оказывается целесообразным
ввести в рассмотрение вероятность
попадания критерия в критическую область
при условии, что нулевая гипотеза неверна
и, следовательно, справедлива конкурирующая.
Мощностью критерия
называют вероятность попадания критерия
в критическую область при условии, что
справедлива конкурирующая гипотеза.
Другими словами, мощность критерия есть
вероятность того, что нулевая гипотеза
будет отвергнута, если верна конкурирующая
гипотеза.
Пусть для проверки
гипотезы принят определённый уровень
значимости и выборка имеет фиксированный
объём. Остаётся произвол в выборе
критической области. Покажем, что её
целесообразно построить так, чтобы
мощность критерия была максимальной.
Предварительно убедимся, что если
вероятность ошибки второго рода (принять
неправильную гипотезу) равна
![]() ,
,
то мощность равна 1-![]() .
.
Действительно, если![]() — вероятность ошибки второго рода, т.е.
— вероятность ошибки второго рода, т.е.
события «принята нулевая гипотеза,
причём справедливо конкурирующая», то
мощность критерия равна 1 —![]() .
.
Пусть мощность 1
—
![]() возрастает; следовательно, уменьшается
возрастает; следовательно, уменьшается
вероятность![]() совершить ошибку второго рода. Таким
совершить ошибку второго рода. Таким
образом, чем мощность больше, тем
вероятность ошибки второго рода меньше.
Итак, если уровень
значимости уже выбран, то критическую
область следует строить так, чтобы
мощность критерия была максимальной.
Выполнение этого требования должно
обеспечить минимальную ошибку второго
рода, что, конечно, желательно.
Замечание 1.
Поскольку вероятность события «ошибка
второго рода допущена» равна
![]() ,
,
то вероятность противоположного события
«ошибка второго рода не допущена» равна
1 —![]() ,
,
т.е. мощности критерия. Отсюда следует,
что мощность критерия есть вероятность
того, что не будет допущена ошибка
второго рода.
Замечание 2. Ясно,
что чем меньше вероятности ошибок
первого и второго рода, тем критическая
область «лучше». Однако при заданном
объёме выборки уменьшить одновременно
![]() и
и![]() невозможно; если уменьшить
невозможно; если уменьшить![]() ,
,
то![]() будет возрастать. Например, если принять
будет возрастать. Например, если принять![]() =0,
=0,
то будут приниматься все гипотезы, в
том числе и неправильные, т.е. возрастает
вероятность![]() ошибки второго рода.
ошибки второго рода.
Как же выбрать
![]() наиболее целесообразно? Ответ на этот
наиболее целесообразно? Ответ на этот
вопрос зависит от «тяжести последствий»
ошибок для каждой конкретной задачи.
Например, если ошибка первого рода
повлечёт большие потери, а второго рода
– малые, то следует принять возможно
меньшее![]() .
.
Если
![]() уже выбрано, то, пользуясь теоремой Ю.
уже выбрано, то, пользуясь теоремой Ю.
Неймана и Э.Пирсона, можно построить
критическую область, для которой![]() будет минимальным и, следовательно,
будет минимальным и, следовательно,
мощность критерия максимальной.
Замечание 3.
Единственный способ одновременного
уменьшения вероятностей ошибок первого
и второго рода состоит в увеличении
объёма выборок.
Что такое ошибка второго рода?
Ошибка типа II, обычно называемая ошибкой «β», представляет собой вероятность сохранения неверного фактического утверждения. Это ошибка ложного срабатывания, т. е. утверждение фактически ложно, и мы уверены в этом.
Оглавление
- Что такое ошибка второго рода?
- Объяснение
- Пример ошибки типа II
- Как возникает ошибка типа II?
- Можно ли избежать ошибок типа II?
- Важность
- Ошибка типа I против ошибки типа II
- Заключение
- Рекомендуемые статьи
Объяснение
Ошибки типа обычно используются для создания гипотезы, определения решения на основе вероятности их появления и определения фактической корректировки данных, которые структурировали гипотезу.
На диаграмме показано создание нулевой гипотезыНулевая гипотезаНулевая гипотеза предполагает, что данные выборки и данные населения не имеют различий, или, говоря простыми словами, она предполагает, что утверждение, сделанное человеком в отношении данных или населения, является абсолютной истиной и всегда верно . Таким образом, даже если выборка берется из населения, результат, полученный в результате изучения выборки, будет таким же, как и предположение. Читать далее, альтернативная гипотеза, среднее значение выборки и вероятность ошибки.
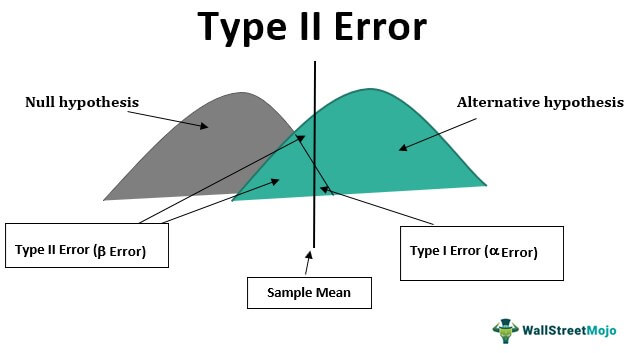
Каждый тест, который мы проводим, всегда имеет вероятность ошибки при принятии решения, и такое решение может быть ошибкой типа I или типа II. Проще говоря, принимая решения, мы можем отвергать правильные факты или принимать неправильные. Отвержение правильных фактов — это ошибка первого рода, а принятие неверных фактов — ошибка второго рода. Эта ошибка может быть очень опасной в корпоративном мире, поскольку полный анализ и эксперимент могут быть ошибочными, если сама база неверна.
Ниже приведена матрица того, какой тип ошибки можно совершить, если факты будут приняты неправильно:
Было принято решение сохранитьПринято решение об отказе (Положительный) (Отрицательный) Нулевая гипотеза верна Истинно положительная Истинно отрицательная (1-a) = ошибка типа I Нулевая гипотеза ложная Ложноположительная ложноотрицательная (β) = ошибка типа II (1 – β) популяция сравнительно очень мала, чтобы обнаружить
Если тенденция к изменению не видна в самой популяции, то любая проверка гипотез Проверка гипотез Проверка гипотез является статистическим инструментом, который помогает измерить вероятность правильности результата гипотезы, полученного после выполнения гипотезы на выборочных данных. Это подтверждает правильность полученных результатов первичной гипотезы. Такой сценарий приведет к принятию неверных фактов, что приведет к ошибкам второго рода.
№ 2. Размер выборки охватывает очень небольшую часть населения.
Выборка должна представлять всю совокупность. Таким образом, если выборка не является идеальным представлением генеральной совокупности, маловероятно, что она даст правильный анализ. Аналитик не сможет определить правильные факты. В результате они будут полагаться на неправильные факты, что приведет к ошибке типа II.
#3 – Неправильный выбор образца
Как правило, во всем мире используется случайная выборка, поскольку она считается одним из самых объективных методов отбора выборки. Однако во многих случаях это приводит к неправильному выбору образцов. В результате это приводит к неправильному охвату населения и приводит к ошибке второго рода.
Можно ли избежать ошибок типа II?
# 1 — Повторяйте анализ, пока не достигнете требуемой значимости
Значимость указывает, является ли нулевая гипотеза фактически верной или нет. В конце всех анализов принимается нулевая гипотеза и проверяется правильность фактов. Однако часто только один анализ не может достичь такой значимости. Такой односторонний анализ может привести к ошибкам типа I или типа II. С другой стороны, если при повторном анализе будут получены одни и те же выходные данные, можно гарантировать отсутствие ошибок.
#2 – При каждом повторении анализа меняйте размер критерия значимости
Как обсуждалось в пункте 1, значимость показывает правильность нулевой гипотезы. Если обнаруживается, что выборка недостаточно охвачена, можно повторить, что размер значимости увеличивается. Это поможет понять поведение и избежать ошибки типа II.
№ 3. Уровень альфа около 0,1 является идеальным.
Как правило, альфа около 0,1 приводит к отклонению гипотезы. Любой отказ позволит несколько проверок. В результате вероятность возникновения ошибок снижается. Ошибка типа II возникает, когда что-то принимается неправильно. Если возможности для принятия нет, такой ошибки не произойдет.
Важность
- Это более опасно по сравнению с ошибками первого рода.
- Любой анализ может быть разработан на основе нескольких необходимых деталей и основных предположений. В конце гипотезы можно определить, соответствует ли тестовая статистика данному факту или нет. Такие особенности теста будут отображать, эквивалентны ли выборочные средние среднему значению генеральной совокупности.
- Если кажется, что нулевая гипотеза достигает значимости из-за какой-то ошибки в анализе, можно принять этот факт в нулевой гипотезе.
- Однако в действительности такая нулевая гипотеза должна быть неприемлемой. В результате нужно быть очень уверенным, принимая утверждение нулевой гипотезы. Повторно проверяя его, можно получить большее значение, чтобы повысить правильность факта.
Ошибка типа I против ошибки типа II
Ниже приведены основные различия между двумя типами ошибок:
старший нетОшибка I типаОшибка второго рода1 Это происходит, когда правильная нулевая гипотеза не принимается. Это происходит, когда принимается неверная нулевая гипотеза.2 Такие ошибки действительно отрицательные. Такие ошибки являются ложноположительными.3Обозначается альфа. Обозначается бета4Нулевая гипотеза и ошибка 1-го рода Альтернативная гипотеза и ошибка 2-го рода5Если результирующий эффект этой ошибки хуже, чем ошибка типа I, следует рассматривать альфа со значением выше 0,10. Если результирующий эффект ошибки типа I хуже, следует установить альфа со значением ниже 0,01.
Заключение
Ошибка II рода — это ложноотрицательный результат, возникающий в результате принятия неверной нулевой гипотезы. В практическом мире такие ошибки приводят к провалу всего проекта, поскольку база неточна. Более того, такой базой могут быть как детали, факты или предположения, ставящие под угрозу полноту анализа.
Рекомендуемые статьи
Эта статья представляет собой руководство по ошибке типа II и ее определению. Здесь мы обсуждаем примеры, объяснения, как это происходит и как этого избежать. Вы можете узнать больше о финансировании из следующих статей: –
- P-значение
- Дисперсионный анализ в Excel
- Т-тест
- Статистика
Ошибки первого и второго рода
Выдвинутая гипотеза
может быть правильной или неправильной,
поэтому возникает необходимость её
проверки. Поскольку проверку производят
статистическими методами, её называют
статистической. В итоге статистической
проверки гипотезы в двух случаях может
быть принято неправильное решение, т.
е. могут быть допущены ошибки двух родов.
Ошибка первого
рода состоит в том, что будет отвергнута
правильная гипотеза.
Ошибка второго
рода состоит в том, что будет принята
неправильная гипотеза.
Подчеркнём, что
последствия этих ошибок могут оказаться
весьма различными. Например, если
отвергнуто правильное решение «продолжать
строительство жилого дома», то эта
ошибка первого рода повлечёт материальный
ущерб: если же принято неправильное
решение «продолжать строительство»,
несмотря на опасность обвала стройки,
то эта ошибка второго рода может повлечь
гибель людей. Можно привести примеры,
когда ошибка первого рода влечёт более
тяжёлые последствия, чем ошибка второго
рода.
Замечание 1.
Правильное решение может быть принято
также в двух случаях:
-
гипотеза принимается,
причём и в действительности она
правильная; -
гипотеза отвергается,
причём и в действительности она неверна.
Замечание 2.
Вероятность совершить ошибку первого
рода принято обозначать через
![]() ;
;
её называют уровнем значимости. Наиболее
часто уровень значимости принимают
равным 0,05 или 0,01. Если, например, принят
уровень значимости, равный 0,05, то это
означает, что в пяти случаях из ста
имеется риск допустить ошибку первого
рода (отвергнуть правильную гипотезу).
Статистический
критерий проверки нулевой гипотезы.
Наблюдаемое значение критерия
Для проверки
нулевой гипотезы используют специально
подобранную случайную величину, точное
или приближённое распределение которой
известно. Обозначим эту величину в целях
общности через
![]() .
.
Статистическим
критерием
(или просто критерием) называют случайную
величину
![]() ,
,
которая служит для проверки нулевой
гипотезы.
Например, если
проверяют гипотезу о равенстве дисперсий
двух нормальных генеральных совокупностей,
то в качестве критерия
![]() принимают отношение исправленных
принимают отношение исправленных
выборочных дисперсий:.
Эта величина
случайная, потому что в различных опытах
дисперсии принимают различные, наперёд
неизвестные значения, и распределена
по закону Фишера – Снедекора.
Для проверки
гипотезы по данным выборок вычисляют
частные значения входящих в критерий
величин и таким образом получают частное
(наблюдаемое) значение критерия.
Наблюдаемым
значением
![]() называют значение критерия, вычисленное
называют значение критерия, вычисленное
по выборкам. Например, если по двум
выборкам найдены исправленные выборочные
дисперсии![]() и
и![]() ,
,
то наблюдаемое значение критерия.
Критическая
область. Область принятия гипотезы.
Критические точки
После выбора
определённого критерия множество всех
его возможных значений разбивают на
два непересекающихся подмножества:
одно из них содержит значения критерия,
при которых нулевая гипотеза отвергается,
а другая – при которых она принимается.
Критической
областью называют совокупность значений
критерия, при которых нулевую гипотезу
отвергают.
Областью принятия
гипотезы (областью допустимых значений)
называют совокупность значений критерия,
при которых гипотезу принимают.
Основной принцип
проверки статистических гипотез можно
сформулировать так: если наблюдаемое
значение критерия принадлежит критической
области – гипотезу отвергают, если
наблюдаемое значение критерия принадлежит
области принятия гипотезы – гипотезу
принимают.
Поскольку критерий
![]() — одномерная случайная величина, все её
— одномерная случайная величина, все её
возможные значения принадлежат некоторому
интервалу. Поэтому критическая область
и область принятия гипотезы также
являются интервалами и, следовательно,
существуют точки, которые их разделяют.
Критическими
точками (границами)
![]() называют точки, отделяющие критическую
называют точки, отделяющие критическую
область от области принятия гипотезы.
Различают
одностороннюю (правостороннюю или
левостороннюю) и двустороннюю критические
области.
Правосторонней
называют критическую область, определяемую
неравенством
![]() >
>![]() ,
,
где![]() — положительное число.
— положительное число.
Левосторонней
называют критическую область, определяемую
неравенством
![]() <
<![]() ,
,
где![]() — отрицательное число.
— отрицательное число.
Односторонней
называют правостороннюю или левостороннюю
критическую область.
Двусторонней
называют критическую область, определяемую
неравенствами
![]() где
где![]() .
.
В частности, если
критические точки симметричны относительно
нуля, двусторонняя критическая область
определяется неравенствами ( в
предположении, что
![]() >0):
>0):
![]() ,
,
или равносильным неравенством
![]() .
.
Отыскание
правосторонней критической области
Как найти критическую
область? Обоснованный ответ на этот
вопрос требует привлечения довольно
сложной теории. Ограничимся её элементами.
Для определённости начнём с нахождения
правосторонней критической области,
которая определяется неравенством
![]() >
>![]() ,
,
где![]() >0.
>0.
Видим, что для отыскания правосторонней
критической области достаточно найти
критическую точку. Следовательно,
возникает новый вопрос: как её найти?
Для её нахождения
задаются достаточной малой вероятностью
– уровнем значимости
![]() .
.
Затем ищут критическую точку![]() ,
,
исходя из требования, чтобы при условии
справедливости нулевой гипотезы
вероятность того, критерий![]() примет значение, большее
примет значение, большее![]() ,
,
была равна принятому уровню значимости:
Р(![]() >
>![]() )=
)=![]() .
.
Для каждого критерия
имеются соответствующие таблицы, по
которым и находят критическую точку,
удовлетворяющую этому требованию.
Замечание 1.
Когда
критическая точка уже найдена, вычисляют
по данным выборок наблюдаемое значение
критерия и, если окажется, что
![]() >
>![]() ,
,
то нулевую гипотезу отвергают; если же![]() <
<![]() ,
,
то нет оснований, чтобы отвергнуть
нулевую гипотезу.
Пояснение. Почему
правосторонняя критическая область
была определена, исходя из требования,
чтобы при справедливости нулевой
гипотезы выполнялось соотношение
Р(![]() >
>![]() )=
)=![]() ?
?
(*)
Поскольку вероятность
события
![]() >
>![]() мала (
мала (![]() — малая вероятность), такое событие при
— малая вероятность), такое событие при
справедливости нулевой гипотезы, в силу
принципа практической невозможности
маловероятных событий, в единичном
испытании не должно наступить. Если всё
же оно произошло, т.е. наблюдаемое
значение критерия оказалось больше![]() ,
,
то это можно объяснить тем, что нулевая
гипотеза ложна и, следовательно, должна
быть отвергнута. Таким образом, требование
(*) определяет такие значения критерия,
при которых нулевая гипотеза отвергается,
а они и составляют правостороннюю
критическую область.
Замечание 2.
Наблюдаемое значение критерия может
оказаться большим
![]() не потому, что нулевая гипотеза ложна,
не потому, что нулевая гипотеза ложна,
а по другим причинам (малый объём выборки,
недостатки методики эксперимента и
др.). В этом случае, отвергнув правильную
нулевую гипотезу, совершают ошибку
первого рода. Вероятность этой ошибки
равна уровню значимости![]() .
.
Итак, пользуясь требованием (*), мы с
вероятностью![]() рискуем совершить ошибку первого рода.
рискуем совершить ошибку первого рода.
Замечание 3. Пусть
нулевая гипотеза принята; ошибочно
думать, что тем самым она доказана.
Действительно, известно, что один пример,
подтверждающий справедливость некоторого
общего утверждения, ещё не доказывает
его. Поэтому более правильно говорить,
«данные наблюдений согласуются с нулевой
гипотезой и, следовательно, не дают
оснований её отвергнуть».
На практике для
большей уверенности принятия гипотезы
её проверяют другими способами или
повторяют эксперимент, увеличив объём
выборки.
Отвергают гипотезу
более категорично, чем принимают.
Действительно, известно, что достаточно
привести один пример, противоречащий
некоторому общему утверждению, чтобы
это утверждение отвергнуть. Если
оказалось, что наблюдаемое значение
критерия принадлежит критической
области, то этот факт и служит примером,
противоречащим нулевой гипотезе, что
позволяет её отклонить.
Отыскание
левосторонней и двусторонней критических
областей***
Отыскание
левосторонней и двусторонней критических
областей сводится (так же, как и для
правосторонней) к нахождению соответствующих
критических точек. Левосторонняя
критическая область определяется
неравенством
![]() <
<![]() (
(![]() <0).
<0).
Критическую точку находят, исходя из
требования, чтобы при справедливости
нулевой гипотезы вероятность того, что
критерий примет значение, меньшее![]() ,
,
была равна принятому уровню значимости:
Р(![]() <
<![]() )=
)=![]() .
.
Двусторонняя
критическая область определяется
неравенствами
![]() Критические
Критические
точки находят, исходя из требования,
чтобы при справедливости нулевой
гипотезы сумма вероятностей того, что
критерий примет значение, меньшее![]() или большее
или большее![]() ,
,
была равна принятому уровню значимости:
![]() .
.
(*)
Ясно, что критические
точки могут быть выбраны бесчисленным
множеством способов. Если же распределение
критерия симметрично относительно нуля
и имеются основания (например, для
увеличения мощности) выбрать симметричные
относительно нуля точки (-
![]() )и
)и![]() (
(![]() >0),
>0),
то
![]() Учитывая (*), получим
Учитывая (*), получим
![]() .
.
Это соотношение
и служит для отыскания критических
точек двусторонней критической области.
Критические точки находят по соответствующим
таблицам.
Дополнительные
сведения о выборе критической области.
Мощность критерия
Мы строили
критическую область, исходя из требования,
чтобы вероятность попадания в неё
критерия была равна
![]() при условии, что нулевая гипотеза
при условии, что нулевая гипотеза
справедлива. Оказывается целесообразным
ввести в рассмотрение вероятность
попадания критерия в критическую область
при условии, что нулевая гипотеза неверна
и, следовательно, справедлива конкурирующая.
Мощностью критерия
называют вероятность попадания критерия
в критическую область при условии, что
справедлива конкурирующая гипотеза.
Другими словами, мощность критерия есть
вероятность того, что нулевая гипотеза
будет отвергнута, если верна конкурирующая
гипотеза.
Пусть для проверки
гипотезы принят определённый уровень
значимости и выборка имеет фиксированный
объём. Остаётся произвол в выборе
критической области. Покажем, что её
целесообразно построить так, чтобы
мощность критерия была максимальной.
Предварительно убедимся, что если
вероятность ошибки второго рода (принять
неправильную гипотезу) равна
![]() ,
,
то мощность равна 1-![]() .
.
Действительно, если![]() — вероятность ошибки второго рода, т.е.
— вероятность ошибки второго рода, т.е.
события «принята нулевая гипотеза,
причём справедливо конкурирующая», то
мощность критерия равна 1 —![]() .
.
Пусть мощность 1
—
![]() возрастает; следовательно, уменьшается
возрастает; следовательно, уменьшается
вероятность![]() совершить ошибку второго рода. Таким
совершить ошибку второго рода. Таким
образом, чем мощность больше, тем
вероятность ошибки второго рода меньше.
Итак, если уровень
значимости уже выбран, то критическую
область следует строить так, чтобы
мощность критерия была максимальной.
Выполнение этого требования должно
обеспечить минимальную ошибку второго
рода, что, конечно, желательно.
Замечание 1.
Поскольку вероятность события «ошибка
второго рода допущена» равна
![]() ,
,
то вероятность противоположного события
«ошибка второго рода не допущена» равна
1 —![]() ,
,
т.е. мощности критерия. Отсюда следует,
что мощность критерия есть вероятность
того, что не будет допущена ошибка
второго рода.
Замечание 2. Ясно,
что чем меньше вероятности ошибок
первого и второго рода, тем критическая
область «лучше». Однако при заданном
объёме выборки уменьшить одновременно
![]() и
и![]() невозможно; если уменьшить
невозможно; если уменьшить![]() ,
,
то![]() будет возрастать. Например, если принять
будет возрастать. Например, если принять![]() =0,
=0,
то будут приниматься все гипотезы, в
том числе и неправильные, т.е. возрастает
вероятность![]() ошибки второго рода.
ошибки второго рода.
Как же выбрать
![]() наиболее целесообразно? Ответ на этот
наиболее целесообразно? Ответ на этот
вопрос зависит от «тяжести последствий»
ошибок для каждой конкретной задачи.
Например, если ошибка первого рода
повлечёт большие потери, а второго рода
– малые, то следует принять возможно
меньшее![]() .
.
Если
![]() уже выбрано, то, пользуясь теоремой Ю.
уже выбрано, то, пользуясь теоремой Ю.
Неймана и Э.Пирсона, можно построить
критическую область, для которой![]() будет минимальным и, следовательно,
будет минимальным и, следовательно,
мощность критерия максимальной.
Замечание 3.
Единственный способ одновременного
уменьшения вероятностей ошибок первого
и второго рода состоит в увеличении
объёма выборок.
Соседние файлы в папке Лекции 2 семестр
- #
- #
- #
- #
5.3. Ошибки первого и второго рода
Ошибка первого рода состоит в том, что гипотеза ![]() будет отвергнута, хотя на самом деле она правильная. Вероятность
будет отвергнута, хотя на самом деле она правильная. Вероятность
допустить такую ошибку называют уровнем значимости и обозначают буквой ![]() («альфа»).
(«альфа»).
Ошибка второго рода состоит в том, что гипотеза ![]() будет принята, но на самом деле она неправильная. Вероятность
будет принята, но на самом деле она неправильная. Вероятность
совершить эту ошибку обозначают буквой ![]() («бета»). Значение
(«бета»). Значение ![]() называют мощностью критерия – это вероятность отвержения неправильной
называют мощностью критерия – это вероятность отвержения неправильной
гипотезы.
В практических задачах, как правило, задают уровень значимости, наиболее часто выбирают значения ![]() .
.
И тут возникает мысль, что чем меньше «альфа», тем вроде бы лучше. Но это только вроде: при уменьшении
вероятности ![]() —
—
отвергнуть правильную гипотезу растёт вероятность ![]() — принять неверную гипотезу (при прочих равных условиях).
— принять неверную гипотезу (при прочих равных условиях).
Поэтому перед исследователем стоит задача грамотно подобрать соотношение вероятностей ![]() и
и ![]() , при этом учитывается тяжесть последствий, которые
, при этом учитывается тяжесть последствий, которые
повлекут за собой та и другая ошибки.
Понятие ошибок 1-го и 2-го рода используется не только в статистике, и для лучшего понимания я приведу пару
нестатистических примеров.
Петя зарегистрировался в почтовике. По умолчанию, ![]() – он считается добропорядочным пользователем. Так считает антиспам
– он считается добропорядочным пользователем. Так считает антиспам
фильтр. И вот Петя отправляет письмо. В большинстве случаев всё произойдёт, как должно произойти – нормальное письмо дойдёт до
адресата (правильное принятие нулевой гипотезы), а спамное – попадёт в спам (правильное отвержение). Однако фильтр может
совершить ошибку двух типов:
1) с вероятностью ![]() ошибочно отклонить нулевую гипотезу (счесть нормальное письмо
ошибочно отклонить нулевую гипотезу (счесть нормальное письмо
за спам и Петю за спаммера) или
2) с вероятностью ![]() ошибочно принять нулевую гипотезу (хотя Петя редиска).
ошибочно принять нулевую гипотезу (хотя Петя редиска).
Какая ошибка более «тяжелая»? Петино письмо может быть ОЧЕНЬ важным для адресата, и поэтому при настройке фильтра
целесообразно уменьшить уровень значимости ![]() , «пожертвовав» вероятностью
, «пожертвовав» вероятностью ![]() (увеличив её). В результате в основной ящик будут попадать все
(увеличив её). В результате в основной ящик будут попадать все
«подозрительные» письма, в том числе особо талантливых спаммеров. …Такое и почитать даже можно, ведь сделано с любовью 
Существует примеры, где наоборот – более тяжкие последствия влечёт ошибка 2-го рода, и вероятность ![]() следует увеличить (в пользу уменьшения
следует увеличить (в пользу уменьшения
вероятности ![]() ). Не хотел я
). Не хотел я
приводить подобные примеры, и даже отшутился на сайте, но по какой-то мистике через пару месяцев сам столкнулся с непростой
дилеммой. Видимо, таки, надо рассказать:
У человека появилась серьёзная болячка. В медицинской практике её принято лечить (основное «нулевое» решение). Лечение
достаточно эффективно, однако не гарантирует результата и более того опасно (иногда приводит к серьёзному пожизненному
увечью). С другой стороны, если не лечить, то возможны осложнения и долговременные функциональные нарушения.
Вопрос: что делать? И ответ не так-то прост – в разных ситуациях разные люди могут принять разные
решения (упаси вас).
Если болезнь не особо «мешает жить», то более тяжёлые последствия повлечёт ошибка 2-го рода – когда человек соглашается
на лечение, но получает фатальный результат (принимает, как оказалось, неверное «нулевое» решение). Если же…, нет, пожалуй,
достаточно, возвращаемся к теме:
 5.4. Процесс проверки статистической гипотезы
5.4. Процесс проверки статистической гипотезы
 5.2. Нулевая и альтернативная гипотезы
5.2. Нулевая и альтернативная гипотезы
| Оглавление |
20 октября 2021 г.
Многие отрасли нанимают исследователей для проведения исследований, которые приносят пользу компаниям и людям, например клиентам, клиентам или пациентам. Эти исследователи часто используют статистику, чтобы определить, верны или ложны гипотезы, чтобы они могли внести изменения в существующие отрасли или улучшить стандартные методы компании. Как исследователь, вы можете захотеть узнать о потенциальных ошибках, которые могут возникнуть при проверке гипотез с помощью статистических исследований. В этой статье мы определяем ошибку типа II в статистике и ее сравнение с ошибками типа I, а также значение ошибок типа II и советы по их уменьшению при рассмотрении гипотез.
Что такое ошибка второго рода в статистике?
Ошибка типа II в статистике возникает, когда исследователь принимает нулевую гипотезу, которая является ложной. В статистике нулевая гипотеза относится к гипотезе, которая является отправной точкой для исследователей, чтобы проверить и попытаться опровергнуть ее, используя статистически значимые данные. Нулевая гипотеза может быть истинной или ложной в зависимости от статистической значимости ваших данных, что просто означает, полезны ли данные в качестве измерения для опровержения гипотезы. Однако исследователи обычно рассматривают нулевую гипотезу как истинную, пока данные не опровергают ее.
Когда исследователь полагает, что его данные доказывают, что нулевая гипотеза верна, хотя на самом деле она ложна, возникает ошибка типа II. Это распространенная ошибка в статистике, которую исследователи иногда называют ложным отрицанием, потому что гипотеза ложна, но вы не отвергаете ее и не опровергаете.
Ошибки типа II и ошибки типа I
В дополнение к ошибкам типа I существуют также ошибки типа II, которые могут повлиять на исследовательские решения в статистике. Ошибки типа I противоположны и обратно пропорциональны ошибкам типа II, что означает, что если вы исправите ошибку одного типа слишком далеко, вы можете получить ошибку другого типа. Вы можете лучше понять это, изучив следующую таблицу:
Нулевая гипотеза верна**Нулевая гипотеза ложна**Принять/не отклонить нулевую гипотезуПравильное решение (принять истинную гипотезу)Ошибка второго рода (принять ложную гипотезу)Отклонить нулевую гипотезуОшибка первого рода (отклонить верную гипотезу)Правильное решение (отклонить ложную гипотезу) ) Каждая из этих ошибок может нарушить исследование и создать ситуации, когда исследователи упускают из виду важную информацию. Самая большая разница между ошибками типа I и типа II заключается в том, как они создаются. Например, ошибка типа I часто возникает, если вы принимаете случайные или случайные данные как статистически значимые. Часто это означает, что установленный вами уровень значимости, который обычно составляет около 0,05 или 5%, слишком высок. Однако для ошибок типа II ошибка возникает, если вы упускаете важные данные из-за небольшого размера выборки, низкого уровня значимости или ошибки измерения.
Значение ошибок типа II
Ошибки типа II могут существенно повлиять на результаты вашего исследования, потому что они означают, что нулевая гипотеза ложна, но вы верите, что она верна. Когда случаются ошибки такого типа, вы можете упустить возможность создавать инновационные продукты, улучшать свою компанию и приносить пользу людям различными способами. Если вы считаете, что столкнулись с ошибкой типа II в своем исследовании, рассмотрите возможность еще раз просмотреть данные и нулевую гипотезу, чтобы убедиться, что вы включили все важные статистические данные в свое решение принять гипотезу. Примите во внимание следующие причины, по которым вы заметите, что ошибки Типа II могут существенно повлиять на вашу компанию:
-
Производство полезных лекарств, которые сначала казались непригодными
-
Создание эффективных маркетинговых кампаний, которые сначала казались неэффективными
-
Удаление неблагоприятной рекламы, которая сначала показалась благоприятной
-
Предоставление полезных медицинских услуг, которые сначала казались бесполезными
-
Изменение неудачных методов управления, которые сначала казались успешными
Советы по уменьшению ошибок типа II
Вот несколько советов, которые помогут вам уменьшить количество ошибок типа II в вашем исследовании:
-
Тщательно планируйте свое обучение. Тщательное планирование может помочь вам избежать ошибок типа II, обеспечив наличие всех данных для принятия взвешенного решения относительно нулевой гипотезы. Подготовьте свои данные и поймите все переменные в вашей статистике, чтобы убедиться, что внешние факторы не влияют на данные, и вы не упустили ни одной важной информации.
-
Увеличьте размер выборки участников. Часто увеличение размера выборки может помочь вам получить лучшие результаты и избежать принятия ложных нулевых гипотез в вашем исследовании. Это связано с тем, что наличие большего количества данных от разных людей и источников может дать вам более широкий спектр информации для создания более стабильного среднего значения и устранения выбросов, которые могут повлиять на результаты исследования.
-
Запускайте тесты на более длительные периоды. Запуск тестов в течение более длительных периодов — это еще один способ увеличить размер выборки для исследования, гарантируя, что данные непротиворечивы и не связаны с внезапными всплесками или падениями активности. Имея более согласованные данные, вы можете гарантировать, что информация, на которой вы основываете свое решение, будет значимой и более точной, чем при более коротких временных рамках.
-
Поднимите уровень своей значимости. Еще один способ уменьшить количество ошибок типа II — поднять уровень значимости выше 5%, что означает, что вы можете считать большее количество данных значимыми и увеличить размер выборки. Однако слишком большое значение может привести к ошибкам типа I, поэтому рассмотрите возможность проведения нескольких тестов с разными уровнями и сравнения данных с другими исследователями, чтобы быть более точными.
Пример ошибки второго рода
Используйте следующий пример ошибки типа II, чтобы понять, что это за ошибка и как она возникает:
Пример: вы работаете с розничной компанией, которая хочет повысить удовлетворенность клиентов, внедрив функцию живого чата на своем веб-сайте. Ваша нулевая гипотеза состоит в том, что функция живого чата не повысит удовлетворенность клиентов. Чтобы проверить это, вы отправляете опрос об удовлетворенности клиентов в конце каждого живого чата и регулярно просматриваете результаты. Через месяц удовлетворенность клиентов не увеличивается, поэтому вы принимаете свою нулевую гипотезу о том, что функция живого чата не повышает удовлетворенность клиентов.
Однако розничная компания предпочитает проводить опрос в конце каждого живого чата. Вы просматриваете результаты через три месяца и видите, что уровень удовлетворенности клиентов медленно растет с тех пор, как вы в последний раз проверяли результаты. Вы понимаете, что совершили ошибку типа II и приняли ложную гипотезу, не имея достаточно информации для принятия точного решения.