

«Код должен легко считываться» — это стало главной целью для японской компании «Denso-Wave» при создании двумерного матричного кода в 1994г.
Действительно, QR-код распознается даже в перевернутом состоянии. Три угловых квадрата привязки, ставшие отличительной особенностью кода, позволяют правильно развернуть его в памяти программы сканера.

По спецификации коды делятся на версии. Номера версий варьируются от 1 до 40. Каждая версия имеет особенности в конфигурации и количестве точек(модулей) составляющих QR-код. Версия 1 содержит 21×21 модулей, версия 40 — 177×177. От версии к версии размер кода увеличивается на 4 модуля на сторону.
При создании матричного кода следует учесть, что лучшие QR-ридеры способны прочитать версию 40, стандартные мобильные устройства — вплоть до версии 4 (33x33 модулей)
Каждой версии соответствует определенная емкость с учетом уровня коррекции ошибок. Чем больше информации необходимо закодировать и чем больший уровень избыточности используется, тем большая версия кода нам потребуется. Современные QR-генераторы автоматически подбирают версию QR-кода с учетом этих моментов.
В следующей таблице показаны характеристики различных версий QR-кодов:
| Версия | Количество модулей | Уровень коррекции ошибок |
Максимальное количество символов с учетом уровня коррекции ошибок и типа символов | |||
|---|---|---|---|---|---|---|
| Числа: 0 — 9 | Числа и символы латинского алфавита*, пробел, $ % * + — . / : |
Двоичные данные | Символы японского алфавита Kanji |
|||
| 1 | 21×21 | L | 41 | 25 | 17 | 10 |
| M | 34 | 20 | 14 | 8 | ||
| Q | 27 | 16 | 11 | 7 | ||
| H | 17 | 10 | 7 | 4 | ||
| 2 | 25×25 | L | 77 | 47 | 32 | 20 |
| M | 63 | 38 | 26 | 16 | ||
| Q | 48 | 29 | 20 | 12 | ||
| H | 34 | 20 | 14 | 8 | ||
| 3 | 29×29 | L | 127 | 77 | 53 | 32 |
| M | 101 | 61 | 42 | 26 | ||
| Q | 77 | 47 | 32 | 20 | ||
| H | 58 | 35 | 24 | 15 | ||
| 4 | 33×33 | L | 187 | 114 | 78 | 48 |
| M | 149 | 90 | 62 | 38 | ||
| Q | 111 | 67 | 46 | 28 | ||
| H | 82 | 50 | 34 | 21 | ||
| 10 | 57×57 | L | 652 | 395 | 271 | 167 |
| M | 513 | 311 | 213 | 131 | ||
| Q | 364 | 221 | 151 | 93 | ||
| H | 288 | 174 | 119 | 74 | ||
| 40 | 177×177 | L | 7,089 | 4,296 | 2,953 | 1,817 |
| M | 5,596 | 3,391 | 2,331 | 1,435 | ||
| Q | 3,993 | 2,420 | 1,663 | 1,024 | ||
| H | 3,057 | 1,852 | 1,273 | 784 |
* При использовании кириллицы один символ считается за 2 латинских символа (кодировка UTF-8)
Уровни коррекции ошибок в QR-кодах
QR-код имеет специальный механизм увеличения надежности хранения зашифрованной информации. Для кодов созданных с самым высоким уровнем надежности могут быть испорчены или затерты до 30% поверхности, но они сохранят информацию и будут корректно прочитаны. Для исправления ошибок используется алгоритм Рида-Соломона (Reed-Solomon). При создании QR-кода можно использовать один из 4 уровней коррекции ошибок. Увеличение уровня способствует увеличению надежности хранения информации, но приводит к увеличению размера матричного кода.
| Допустимый процент нарушений | |
|---|---|
| L | около 7% |
| M | около 15% |
| Q | около 25% |
| H | около 30% |
Полезные ссылки:
Стандарт ISO 18004 (Automatic identification and data capture techniques — QR Code 2005 bar code symbology specification)
«Код должен легко считываться» — это стало главной целью для японской компании «Denso-Wave» при создании двумерного матричного кода в 1994г.
Действительно, QR-код распознается даже в перевернутом состоянии. Три угловых квадрата привязки, ставшие отличительной особенностью кода, позволяют правильно развернуть его в памяти программы сканера.
По спецификации коды делятся на версии. Номера версий варьируются от 1 до 40. Каждая версия имеет особенности в конфигурации и количестве точек(модулей) составляющих QR-код. Версия 1 содержит 21×21 модулей, версия 40 — 177×177. От версии к версии размер кода увеличивается на 4 модуля на сторону.
При создании матричного кода следует учесть, что лучшие QR-ридеры способны прочитать версию 40, стандартные мобильные устройства — вплоть до версии 4 (33x33 модулей)
Каждой версии соответствует определенная емкость с учетом уровня коррекции ошибок. Чем больше информации необходимо закодировать и чем больший уровень избыточности используется, тем большая версия кода нам потребуется. Современные QR-генераторы автоматически подбирают версию QR-кода с учетом этих моментов.
В следующей таблице показаны характеристики различных версий QR-кодов:
| Версия | Количество модулей | Уровень коррекции ошибок |
Максимальное количество символов с учетом уровня коррекции ошибок и типа символов | |||
|---|---|---|---|---|---|---|
| Числа: 0 — 9 | Числа и символы латинского алфавита*, пробел, $ % * + — . / : |
Двоичные данные | Символы японского алфавита Kanji |
|||
| 1 | 21×21 | L | 41 | 25 | 17 | 10 |
| M | 34 | 20 | 14 | 8 | ||
| Q | 27 | 16 | 11 | 7 | ||
| H | 17 | 10 | 7 | 4 | ||
| 2 | 25×25 | L | 77 | 47 | 32 | 20 |
| M | 63 | 38 | 26 | 16 | ||
| Q | 48 | 29 | 20 | 12 | ||
| H | 34 | 20 | 14 | 8 | ||
| 3 | 29×29 | L | 127 | 77 | 53 | 32 |
| M | 101 | 61 | 42 | 26 | ||
| Q | 77 | 47 | 32 | 20 | ||
| H | 58 | 35 | 24 | 15 | ||
| 4 | 33×33 | L | 187 | 114 | 78 | 48 |
| M | 149 | 90 | 62 | 38 | ||
| Q | 111 | 67 | 46 | 28 | ||
| H | 82 | 50 | 34 | 21 | ||
| 10 | 57×57 | L | 652 | 395 | 271 | 167 |
| M | 513 | 311 | 213 | 131 | ||
| Q | 364 | 221 | 151 | 93 | ||
| H | 288 | 174 | 119 | 74 | ||
| 40 | 177×177 | L | 7,089 | 4,296 | 2,953 | 1,817 |
| M | 5,596 | 3,391 | 2,331 | 1,435 | ||
| Q | 3,993 | 2,420 | 1,663 | 1,024 | ||
| H | 3,057 | 1,852 | 1,273 | 784 |
* При использовании кириллицы один символ считается за 2 латинских символа (кодировка UTF-8)
QR-код имеет специальный механизм увеличения надежности хранения зашифрованной информации. Для кодов созданных с самым высоким уровнем надежности могут быть испорчены или затерты до 30% поверхности, но они сохранят информацию и будут корректно прочитаны. Для исправления ошибок используется алгоритм Рида-Соломона (Reed-Solomon). При создании QR-кода можно использовать один из 4 уровней коррекции ошибок. Увеличение уровня способствует увеличению надежности хранения информации, но приводит к увеличению размера матричного кода.
| Допустимый процент нарушений | |
|---|---|
| L | около 7% |
| M | около 15% |
| Q | около 25% |
| H | около 30% |
Полезные ссылки:
Стандарт ISO 18004 (Automatic identification and data capture techniques — QR Code 2005 bar code symbology specification)
 Иногда возникают такие ситуации, когда нужно прочитать QR код, а смартфона под рукой нет. Что же делать? В голову приходит лишь попробовать прочитать вручную. Если кто-нибудь сталкивался с такими ситуациями или кому просто интересно как же читается QR код машинами, то данная статья поможет вам разобраться в этой проблеме.
Иногда возникают такие ситуации, когда нужно прочитать QR код, а смартфона под рукой нет. Что же делать? В голову приходит лишь попробовать прочитать вручную. Если кто-нибудь сталкивался с такими ситуациями или кому просто интересно как же читается QR код машинами, то данная статья поможет вам разобраться в этой проблеме.
В статье рассмотрены базовые особенности QR кодов и методика дешифрирования информации без использования вычислительных машин.
Иллюстраций: 14, символов: 8 510.
Для тех, кто не в курсе что такое QR код, есть неплохая статья в английской Wikipedia. Также можно почитать тематический блог на Хабре и несколько хороших статей по смежной тематике, которые можно найти поиском.
Решение задачи непосредственного чтения информации с QR-картинки рассмотрим на примере двух кодов. Информация была закодирована в online-генераторе QR Coder.ru.
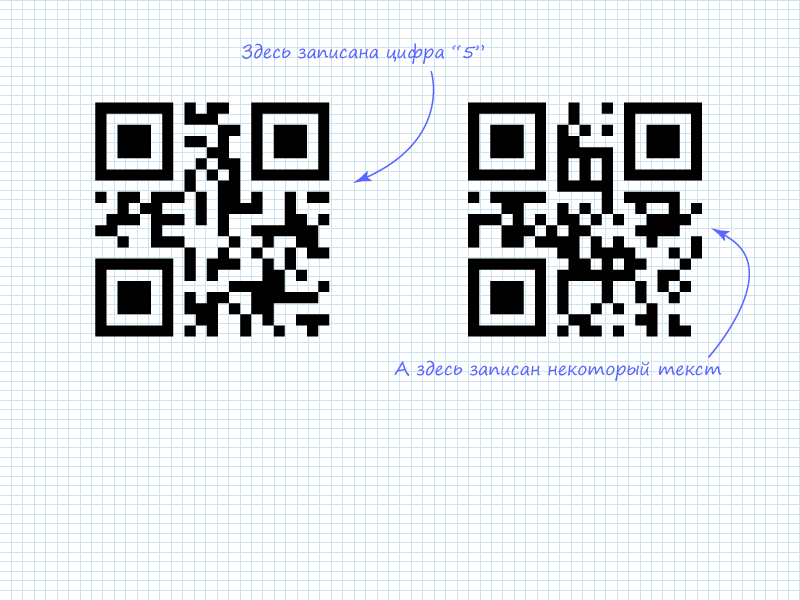
Чтобы понять, как извлечь данные из кода, нужно разобраться в алгоритме. Существует несколько стандартов в семействе QR кодов, с их базовыми принципами можно ознакомиться в спецификациях. Кратко поясню: данные, которые необходимо закодировать, разбиваются на блоки в зависимости от режима кодирования. К разбитым по блокам данным прибавляется заголовок, указывающий на режим и количество блоков. Существуют и такие режимы, в которых используется более сложная структура размещения информации. Данные режимы рассматривать не будем ввиду того, что извлекать вручную из них информацию нецелесообразно. Однако, основываясь на тех принципах, которые описаны ниже, можно адаптироваться и к этим режимам.
На случай некорректного чтения данных, в QR применяются специальные коды, которые способны исправить недочёты при чтении. Это так называемые коды Рида-Соломона. Принцип вычисления кодов, а также исправление ошибок в блоках информации рассматривать не будем, это тема отдельной статьи. Корректирующие ошибки коды Рида-Соломона (RS) записываются после всех информационных данных. Это очень упрощает задачу непосредственного чтения информации: можно просто считать данные, не трогая коды. Как показывает практика, обычно бОльшую часть QR -матрицы занимают корректирующие RS-коды.
По стандарту, данные с RS-кодами перед записью в картинку «перемешиваются». Для этих целей используют специальные маски. Существует 8 алгоритмов, среди которых выбирается наилучший. Критерии выбора основаны на системе штрафов, о которых можно также почитать в спецификации.
«Перемешанные» данные записываются в особой последовательности на шаблонную картинку, куда добавляется техническая информация для декодирующих устройств. Исходя из описанного алгоритма, можно выделить схему извлечения данных из QR кода:
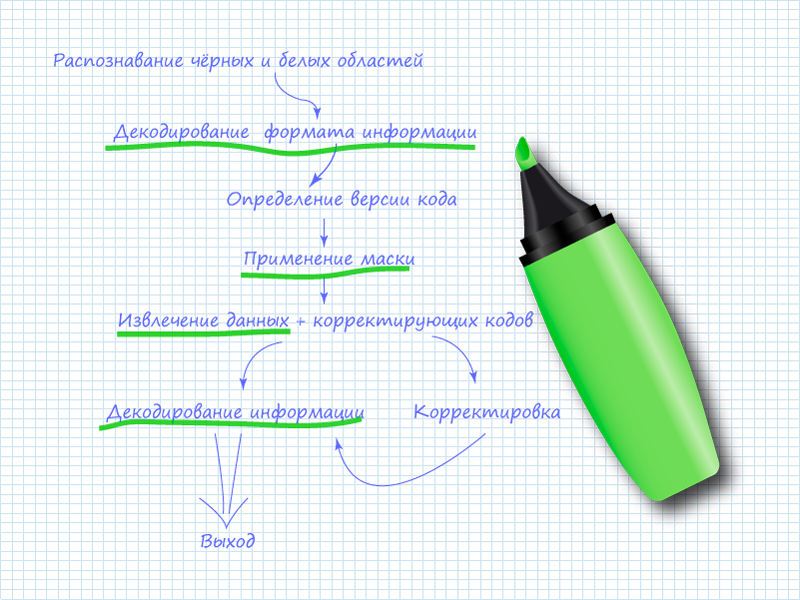
Здесь зелёным фломастером подчёркнуты пункты, которые нужно будет выполнить при непосредственном чтении кода. Остальные пункты можно опустить ввиду того, что считывание производит человек.
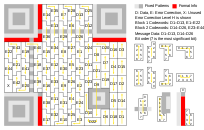
Шаг 0. QR код

Взглянув на картинки, можно заметить несколько отчётливых областей. Эти области используются для детектирования QR кода. Эти данные не представляют интереса с точки зрения записанной информации, но их нужно вычеркнуть или просто запомнить их расположение, чтобы они не мешали. Всё остальное поле кода несёт уже полезную информацию. Её можно разбить на две части: системная информация и данные. Также существует информация о версии кода. От версии кода зависит максимальный объём данных, которые могут быть записаны в код. При повышении версии – добавляются специальные блоки, например как здесь:

По ним можно сориентироваться и понять какая версия QR перед вами. Коды высоких версий обычно также нецелесообразно считывать вручную.
Размещение системной информации показано на рисунке:

Системная информация дублируется, что позволяет значительно понизить вероятность возникновения ошибок при детектировании кода и считывании. Системная информация – это 15 бит данных, среди которых первые 5 — это полезная информация, а остальные 10 — это BCH(15,5) код, который позволяет исправлять ошибки в системных данных. К классу BCH кодов относят и RS коды. Обратите внимание, что на рисунке две полоски по 15 бит не пересекаются.
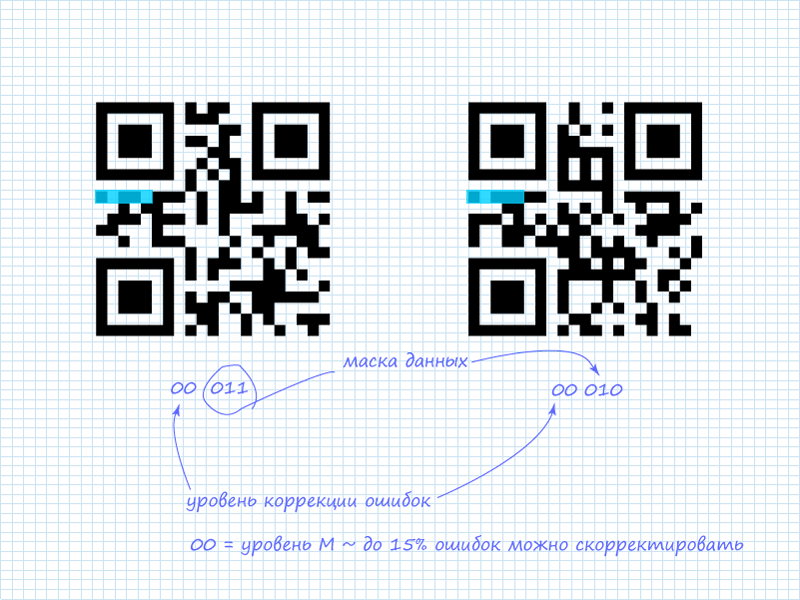
Шаг 1. Чтение 5 бит системной информации
Как уже говорилось, интерес представляют только первые 5 бит. Из которых 2 бита показывают уровень коррекции ошибок, а остальные 3 бита показывают какая маска из доступных 8 применяется к данным. В рассматриваемых QR кодах системная информация содержит:

Шаг 2. Маска для системной информации
Кроме уже озвученных схем защиты системной информации, вдобавок, используется статическая маска, которая применяется к любой системной информации. Она имеет вид: 101010000010010. Так как имеет интерес только первые 5 бит, то маску можно сократить и легко запомнить: 10101 (десять — сто один). После применения операции «исключающего или» (xor) получаем информацию.
Возможные уровни коррекции ошибок:
Возможные маски:
Шаг 3. Чтение заголовка данных
Чтобы понять с какими данными предстоит иметь дело, необходимо изначально прочитать 4-х битный заголовок, который содержит в себе информацию о режиме. Специфика чтения данных изображена на картинке:

Список возможных режимов:
Шаг 4. Применение маски к заголовку
После извлечения 4-х бит, описывающих режим, необходимо к ним применить маску.
В нашем случае для двух кодов используются разные маски. Маска определяется выражением, приведённым в таблице выше. Если данное выражение сводится к TRUE (верное) для бита с координатами (i,j), то бит инвертируется, иначе всё остаётся без изменений. Начало координат в левом верхнем углу (0,0). Взглянув на выражения, можно заметить в них закономерности. Для рассматриваемых QR кодов, маски будут выглядеть так:

Получим режимы:

Шаг 5. Чтение данных
После получения данных о режиме можно приступать к чтению информации. Надо оговорить, что наиболее интересно считывать числовые и буквенно-числовые данные, так как они легко интерпретируются. Но также не стоит бояться 8-битных. Это может быть также легко интерпретируемая информация. Например, многие онлайн генераторы QR текст кодируют в этом режиме, используя ASCII. Ещё одна причина, почему следует изначально прочитать режим, это то, что от него зависит количество пакетов данных. Которая также зависит и от версии кода. Для версий с первой по девятую длины блоков для более читабельных режимов:
Первый блок после указателя режима — это количество символов. Для числового режима количество закодировано в 10 следующих битах, а для 8-битного режима в 8 битах (прошу прощения за тавтологию).
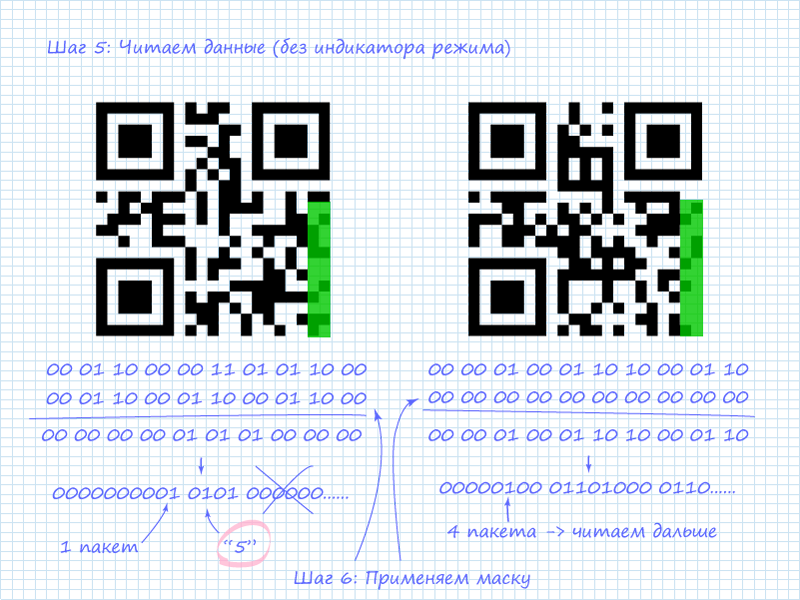
На рисунке видно, что в левом QR коде, как и отмечалось, записана цифра 5. Это видно по указателю количества символов и последующим после него 4 битам. В числовом режиме наряду с 10-битными блоками используются 4-х битные блоки для экономии места, если в 10-битном объёме нет необходимости. В правом коде зашифровано 4 символа. На данный момент неизвестно что зашифровано в нём. Поэтому необходимо перейти к чтению следующего столбца для извлечения всех 4-х блоков информации.

На рисунке видно, все 4 пакета представляют собой коды ASCII латинских букв, образующие слово «habr»
Естественно наилучшим способом остаётся достать телефон из кармана и, наведя камеру на QR-картинку, считать всю информацию. Однако в экстренных случаях может пригодиться и описанная методика. Конечно, в голове не удержишь все указатели режимов и типов масок, а также ASCII символы, но популярные комбинации запомнить (хотя бы те, что рассмотрены в статье) под силу.
Спецификация:
BS ISO/IEC 18004:2006. Information technology. Automatic identification and data capture techniques. QR Code 2005 bar code symbology specification. London: BSI. 2007. p. 126. ISBN 978-0-580-67368-9.
P.S. Соблюдайте правила ресурса и условия Creative Commons Attribution 3.0 Unported (CC BY 3.0)
P.P.S. Если ошибся блогом, то подскажите куда — перенесу.
QR-код также известен как QR-код, QR-код обозначает Quick Response. Это очень популярный метод кодирования на мобильных устройствах в последние годы. Он может хранить больше информации и отображать больше данных, чем традиционный штрих-код штрих-кода. Тип: например: символы, цифры, японский, китайский и т. Д. В последние два дня я изучил детали генерации изображения QR-кода и думаю, что это криптографический алгоритм. Я напишу здесь статью, чтобы разоблачить его. Для образованных учиться вместе.
Для спецификации QR-кода, пожалуйста, обратитесь к этому PDF:http://raidenii.net/files/datasheets/misc/qr_code.pdf
Базовые знания
Прежде всего, давайте поговорим о 40 размерах QR-кодов. Официальная версия называется Версия. Версия 1 — это матрица 21 x 21, Версия 2 — это матрица 25 x 25, а Версия 3 — размер 29. Каждая дополнительная версия увеличивает размер 4. Формула: (V-1) * 4 + 21 ( V — номер версии) Наивысшая версия 40, (40-1) * 4 + 21 = 177, поэтому наивысшая — это квадрат 177 x 177.
Давайте посмотрим на образец QR-кода:

Шаблон позиционирования
- Шаблон определения местоположения — это шаблон определения местоположения, используемый для обозначения прямоугольного размера двумерного кода. Эти три шаблона позиционирования имеют белые границы, называемые разделителями для шаблонов определения положения. Причина трех вместо четырех означает, что три могут идентифицировать прямоугольник.
- Шаблоны синхронизации также используются для позиционирования. Причина в том, что QR-код имеет 40 размеров, и если размер слишком велик, требуется стандартная строка, в противном случае она может быть перекошена при сканировании.
- Эти шаблоны требуются только для QR-кодов выше Версии 2 (включая Версию 2), которая также используется для позиционирования.
Функциональные данные
- Информация о формате существует во всех размерах и используется для хранения некоторых форматированных данных.
- Информация о версии выше> = Версия 7, две области 3 x 6 должны быть зарезервированы для хранения некоторой информации о версии.
Код данных и код исправления ошибок
- За исключением упомянутых выше мест, в остальных местах хранятся код данных и код исправления ошибок.
Кодировка данных
Давайте сначала поговорим о кодировании данных. QR-код поддерживает следующую кодировку:
Numeric modeЦифровое кодирование, от 0 до 9. Если количество кодируемых цифр не кратно 3, то оставшиеся 1 или 2 цифры будут преобразованы в 4 или 7 битов, а все остальные 3 цифры будут скомпилированы в 10, 12, 14 битов. Длина зависит от размера QR-кода (ниже приведена таблица 3 для иллюстрации)
Alphanumeric modeКодировка символов. Включите от 0 до 9, прописные буквы от A до Z (без строчных букв) и символ $% * + -. /: Включая пробелы. Эти символы будут отображены в таблицу индексов символов. Как показано ниже: (где SP — это пробел, Char — это символ, а Value — его значение индекса) Процесс кодирования состоит в том, чтобы сгруппировать символы два по два, а затем преобразовать их в 45 шестнадцатеричное в приведенной ниже таблице, а затем преобразовать в двоичный 11-битный код, если Если есть заказ, он будет преобразован в двоичный 6-битный. Режим кодирования и количество символов должны быть скомпилированы в 9, 11 или 13 двоичных файлов в соответствии с различными размерами версии (таблица 3 в следующей таблице)

Byte modeБайтовая кодировка, может быть ISO-8859-1, символы 0-255. Некоторые сканеры двумерного кода могут автоматически определять, является ли это кодировкой UTF-8.
Kanji modeЭто японская кодировка и двухбайтовая кодировка. Точно так же это может также использоваться для китайского кодирования. Кодировка японских и китайских символов вычтет значение. Например: символы от 0X8140 до 0X9FFC вычтут 8140, символы от 0XE040 до 0XEBBF должны вычесть 0XC140, затем взять первые две цифры и умножить на 0XC0, затем добавить последние две цифры и, наконец, преобразовать в 13 бит кодирование. Пример, как показано ниже:

Extended Channel Interpretation (ECI) modeОн в основном используется для специальных наборов символов. Не все сканеры поддерживают эту кодировку.
Structured Append modeИспользуется для смешанного кодирования, то есть этот QR-код содержит несколько форматов кодирования.
FNC1 modeЭтот метод кодирования в основном используется для некоторых специальных отраслей или отраслей. Например, GS1 штрих-код и тому подобное.
Для простоты последние три не будут обсуждаться в этой статье.
В следующих двух таблицах
- Таблица 2 — это «число» каждого формата кодирования, которое должно быть записано в информации о формате. Примечание: китайский — 1101
- В таблице 3 показаны двумерные коды разных версий (размеров) для цифр, символов, байтов и режима кандзи для двоичного двоичного кода. (Существуют различные таблицы спецификаций кодирования в спецификациях QR-кодов, которые будут упомянуты позже)

Ниже мы рассмотрим несколько примеров,
Пример 1: Цифровое кодирование
В размере версии 1, когда уровень исправления ошибок равен H, код: 01234567
- Разделите вышеуказанные цифры на три группы: 012 345 67
- Преобразуйте их в двоичные: от 012 до 0000001100; от 345 до 0101011001; от 67 до 1000011.
- Строка этих трех двоичных файлов: 0000001100 0101011001 1000011
- Преобразовать количество цифр в двоичный код (версия 1-H — 10 бит): двоичный код из 8 цифр — 0000001000.
- Добавьте в цифровую форму логотип 0001 и код шага 4 на лицевой стороне: 0001 0000001000 0000001100 0101011001 1000011
Пример 2: Кодировка символов
В размере версии 1, когда уровень исправления ошибок равен H, кодирование: AC-42
1. Найдите индекс пяти записей AC-42 из таблицы индексов символов (10,12,41,4,2)
2. Сгруппировать по два: (10,12) (41,4) (2)
3. Преобразуйте каждую группу в 11-битный двоичный файл:
(10,12) 10 * 45 + 12 равно 462 до 00111001110
(41,4) 41 * 45 + 4 равняется 1849 — 11100111001
(2) равно от 2 до 000010
4. Подключите эти двоичные файлы: 00111001110 11100111001 000010
5. Преобразуйте количество символов в двоичное (версия 1-H — 9 бит): 5 символов, от 5 до 000000101.
6. Добавьте идентификатор кода 0010 и цифровой код шага 5 к заголовку: 0010 000000101 00111001110 11100111001 000010
Терминатор и дополнение
Если у нас есть строка HELLO WORLD для кодирования, согласно второму примеру выше, мы можем получить следующую кодировку:
| кодирование | Количество символов | Кодировка HELLO WORLD |
|---|---|---|
| 0010 | 000001011 | 01100001011 01111000110 10001011100 10110111000 10011010100 001101 |
Нам также нужно добавить терминатор:
| кодирование | Количество символов | Кодировка HELLO WORLD | конец |
|---|---|---|---|
| 0010 | 000001011 | 01100001011 01111000110 10001011100 10110111000 10011010100 001101 | 0000 |
Переставить на 8 бит
Если все кодировки не кратны 8, мы должны добавить достаточно 0 в конце, например, всего 78 битов, поэтому мы должны добавить 2 0, а затем разделить группы на 8 бит:
00100000 01011011 00001011 01111000 11010001 01110010 11011100 01001101 01000011 01000000
Заполнение байтов
Наконец, если мы не достигли предела максимального количества битов, мы должны добавить несколько кодов заполнения (байтов заполнения), байты заполнения должны повторить следующие два байта: 11101100 00010001 (двоичный двоичный код, преобразованный в десятичное число, равен 236). И 17, я не знаю, почему, я знаю только то, что оно написано в спецификации). Максимальный битовый предел для каждого уровня исправления ошибок в каждой версии см. В Таблице 7 на стр. 28–32 спецификации QR-кода. Стол.
Предполагая, что нам нужно закодировать уровень коррекции ошибок Q в Версии 1, тогда ему нужно максимум 104 бита, а у нас всего 80 бит выше, поэтому нам нужно 24 бита, то есть нам нужно 3 байта заполнения, мы добавляем Три, так что получите следующий код:
00100000 01011011 00001011 01111000 11010001 01110010 11011100 01001101 01000011 01000000 11101100 00010001 11101100
Код исправления ошибок
Выше мы говорили о некоторых уровнях исправления ошибок, уровне кода исправления ошибок, в QR-коде есть четыре уровня исправления ошибок, поэтому QR-код можно сканировать по дефекту, поэтому кто-то находится в центре QR-кода. Присоединиться к иконке.
| Возможность исправления ошибок | |
|---|---|
| Уровень L | 7% кода может быть изменено |
| Уровень М | 15% кода может быть изменено |
| Уровень Q | 25% кода может быть изменено |
| Уровень H | 30% кода может быть изменено |
Итак, как QR добавляет код исправления ошибок в код данных? Во-первых, нам нужно сгруппировать коды данных, то есть по разным блокам, а затем выполнить кодирование с исправлением ошибок для каждого блока. Таблица определения 22. Обратите внимание на последние два столбца:
- Number of Error Code Correction Blocks: Сколько блоков нужно разделить
- Error Correction Code Per Blocks: Количество кодов в каждом блоке, так называемое количество кодов, то есть сколько 8-битных байтов.

Например: вышеуказанный уровень исправления ошибок версии 5 + Q: требуется 4 блока (2 блока в группе, всего две группы), 15 бит данных в каждом из первых двух блоков + 9 бит каждого Код с исправлением ошибок (Примечание. Кодовые слова в таблице представляют собой 8-битный байт). (Renote: формула (c, k, r) в последнем примере: c = k + 2 * r, поскольку сноска объясняет: исправление. Емкость кода ошибки составляет менее половины кода исправления ошибок)
На следующем рисунке приведен пример 5-Q (поскольку запись в двоичном виде сделает таблицу слишком большой, поэтому я использовал десятичную)
| группа | блок | данные | Код исправления ошибок для каждого блока |
|---|---|---|---|
| 1 | 1 | 67 85 70 134 87 38 85 194 119 50 6 18 6 103 38 | 213 199 11 45 115 247 241 223 229 248 154 117 154 111 86 161 111 39 |
| 2 | 246 246 66 7 118 134 242 7 38 86 22 198 199 146 6 | 87 204 96 60 202 182 124 157 200 134 27 129 209 17 163 163 120 133 | |
| 2 | 1 | 182 230 247 119 50 7 118 134 87 38 82 6 134 151 50 7 | 148 116 177 212 76 133 75 242 238 76 195 230 189 10 108 240 192 141 |
| 2 | 70 247 118 86 194 6 151 50 16 236 17 236 17 236 17 236 | 235 159 5 173 24 147 59 33 106 40 255 172 82 2 131 32 178 236 |
Примечание. Код коррекции ошибок двумерного кода в основном реализуется с помощью коррекции ошибок Рида-Соломона (алгоритм коррекции ошибок Рида-Соломона). Для этого алгоритма он довольно сложен для меня, есть много математических вычислений, таких как: полиномиальное деление, число 1-255 отображается в степени n от 2 (0 <= n <= 255) Подобные Богу вещи, такие как Поле Галуа и математические формулы для исправления ошибок, основанные на этих основах, потому что мое основание данных плохое, оно слишком сложное для меня, поэтому я некоторое время не понимал его. В обучении, поэтому, я не буду говорить об этих вещах здесь. Пожалуйста, прости меня. (Конечно, если есть друг, который хорошо понимает, я бы тоже посоветовался со мной)
Окончательное кодирование
Вперемежку размещение
Если вы думаете, что мы можем начать рисовать, вы не правы. Хаотическая технология двумерного кода еще не закончена, она также попеременно объединяет кодовые слова кода данных и кода исправления ошибок. Как чередовать, правила таковы:
Для кодов данных: вынуть первые кодовые слова каждого блока и расположить их по порядку, затем взять второй из первого блока и так далее. Например: Кодовые слова данных в приведенном выше примере:
| Блок 1 | 67 | 85 | 70 | 134 | 87 | 38 | 85 | 194 | 119 | 50 | 6 | 18 | 6 | 103 | 38 | |
| Блок 2 | 246 | 246 | 66 | 7 | 118 | 134 | 242 | 7 | 38 | 86 | 22 | 198 | 199 | 146 | 6 | |
| Блок 3 | 182 | 230 | 247 | 119 | 50 | 7 | 118 | 134 | 87 | 38 | 82 | 6 | 134 | 151 | 50 | 7 |
| Блок 4 | 70 | 247 | 118 | 86 | 194 | 6 | 151 | 50 | 16 | 236 | 17 | 236 | 17 | 236 | 17 | 236 |
Сначала мы берем первый столбец: 67, 246, 182, 70
Затем возьмите второй столбец: 67, 246, 182, 70, 85, 246, 230, 247
И так далее: 67, 246, 182, 70, 85, 246, 230, 247 ………, 38, 6, 50, 17, 7, 236
То же самое верно для кодов исправления ошибок:
| Блок 1 | 213 | 199 | 11 | 45 | 115 | 247 | 241 | 223 | 229 | 248 | 154 | 117 | 154 | 111 | 86 | 161 | 111 | 39 |
| Блок 2 | 87 | 204 | 96 | 60 | 202 | 182 | 124 | 157 | 200 | 134 | 27 | 129 | 209 | 17 | 163 | 163 | 120 | 133 |
| Блок 3 | 148 | 116 | 177 | 212 | 76 | 133 | 75 | 242 | 238 | 76 | 195 | 230 | 189 | 10 | 108 | 240 | 192 | 141 |
| Блок 4 | 235 | 159 | 5 | 173 | 24 | 147 | 59 | 33 | 106 | 40 | 255 | 172 | 82 | 2 | 131 | 32 | 178 | 236 |
Аналогично коду данных, получите: 213, 87, 148, 235, 199, 204, 116, 159, … 39 133 141 236
Затем соедините эти две группы (код исправления ошибок ставится после кода данных), чтобы получить:
67, 246, 182, 70, 85, 246, 230, 247, 70, 66, 247, 118, 134, 7, 119, 86, 87, 118, 50, 194, 38, 134, 7, 6, 85, 242, 118, 151, 194, 7, 134, 50, 119, 38, 87, 16, 50, 86, 38, 236, 6, 22, 82, 17, 18, 198, 6, 236, 6, 199, 134, 17, 103, 146, 151, 236, 38, 6, 50, 17, 7, 236, 213, 87, 148, 235, 199, 204, 116, 159, 11, 96, 177, 5, 45, 60, 212, 173, 115, 202, 76, 24, 247, 182, 133, 147, 241, 124, 75, 59, 223, 157, 242, 33, 229, 200, 238, 106, 248, 134, 76, 40, 154, 27, 195, 255, 117, 129, 230, 172, 154, 209, 189, 82, 111, 17, 10, 2, 86, 163, 108, 131, 161, 163, 240, 32, 111, 120, 192, 178, 39, 133, 141, 236
Remainder Bits
Наконец, добавьте биты напоминания. Для некоторых версий QR вышеупомянутое недостаточно, но также добавьте биты остатка, например: вышеприведенная версия QR-кода 5Q плюс 7 битов, биты остатка плюс ноль Просто отлично Информацию о версии и количестве битов остатка см. В таблице определения в таблице 1 на стр. 15 спецификации QR-кода.
Нарисуйте QR-код
Position Detection Pattern
Сначала нарисуйте шаблон определения местоположения по трем углам.

Alignment Pattern
Затем нарисуйте шаблон выравнивания снова

Для определения местоположения Выравнивания вы можете проверить таблицу определений Таблицы E.1 на стр. 81 спецификации QR Code (следующая таблица является неполной таблицей)

На следующем рисунке приведен пример, основанный на версии 8 в приведенной выше таблице (6, 24, 42).

Timing Pattern
Далее идет линия Timing Pattern (это само собой разумеется)

Format Information
Далее идет информация о формации, синяя часть на рисунке ниже.

Информация о формате — это 15-битная информация, положение каждого бита показано на следующем рисунке: (обратите внимание на темный модуль на рисунке, он всегда появляется)

Эти 15 бит включают в себя:
- 5 битов данных: среди них 2 бита используются для указания того, какой уровень исправления ошибок используется, а 3 бита используются для указания того, какой тип маски используется
- 10 бит исправления ошибок. В основном рассчитывается по коду БЧХ
Затем 15 битов XORed с 101010000010010. Таким образом, мы гарантируем, что мы не сделаем уровень коррекции ошибок 00 и Маску 000 полностью белым, что увеличит сложность распознавания изображений нашим сканером.
Вот пример:

Уровень исправления ошибок показан в следующей таблице:

Шаблон маски показан в таблице 23 ниже.
Version Information
Далее идет информация о версии (этот код требуется после версии 7), синяя часть на рисунке ниже.
Информация о версии — всего 18 бит, включая номер версии 6 бит и код исправления ошибок 12 бит. Ниже приведен пример:

И его позиция заполнения выглядит следующим образом:

Данные и коды исправления ошибок данных
Затем мы заполняем наш окончательный код, который заполняется следующим образом: из левого нижнего угла заполняем наши биты вдоль красной линии, 1 — черный, 0 — белый. Если обнаружена вышеуказанная область без данных, пропустите или пропустите.

Шаблон маски
Таким образом, наша картинка заполняется, но, возможно, эти точки не сбалансированы, поэтому нам все еще нужно выполнить операцию маскировки (полагайте, это не слишком сложно). QR Spec говорит, что QR имеет 8 масок, которые вы можете Используйте следующим образом: среди них формула каждой маски ниже каждой фигуры. Говоря прямо, так называемая маска — это операция XOR с изображением выше. Маска будет только XOR с областью данных и не повлияет на функциональную область.

Идентификационный код маски выглядит следующим образом: (где i, j соответствуют x, y на рисунке выше)

Ниже приведены некоторые из появлений после Mask, мы можем видеть, что данные XOR, определенные некоторыми Mask, стали более разбросанными.

QR-код после маски становится окончательной картиной.
Что такое QR-код и где его использовать
QR-код – это двухмерный штрих-код, который состоит из контрастных по цвету (чаще всего черных и белых) блоков и позволяет кодировать до нескольких сотен символов. Сохраненную в коде информацию можно быстро распознать и посмотреть при помощи смартфона или планшета.

Здесь закодирована ссылка на главную страницу mobizon.ua.
При помощи QR-кода вы можете закодировать любую информацию, например: ссылку на сайт, визитку, номер телефона, email, адрес или текст.
Как создать QR-код
- Вызовите Конструктор QR-кодов в Панели управления.

- Откроется окно конструктора.
Выберите тип данных, которые требуется зашифровать: ссылка, визитка, номер телефона, email, географические координаты, текст, параметры Wi-Fi, SMS-сообщение. Введите эти данные в соответствующие поля. - QR-код будет показан в окне предварительного просмотра. Нажмите кнопку Скачать QR-код.
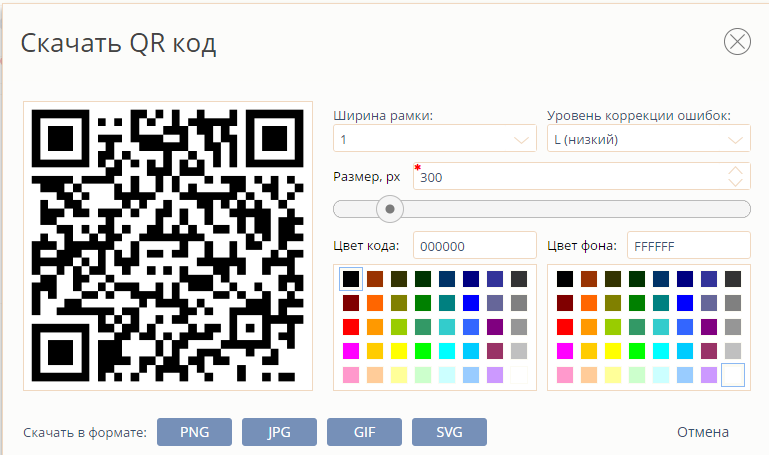
- Настройте параметры скачиваемого изображения в открывшемся окне.
Параметры:
Ширина рамки — расстояние от края изображения до кода.
Уровень коррекции ошибок — количество информации, после утраты которого код прекращает распознаваться (подробнее см. подраздел Уровни коррекции ошибок ниже).
Размер, px — ширина и высота изображения (в пикселях). Не более 1500 px.Цвет кода и цвет фона — цвет соответствующих элементов QR-кода. Выберите на палитре или задайте в виде шестнадцатеричного кода цвета. Рекомендуем выбирать наиболее контрастирующие друг с другом цвета. Следует учесть, что многие программы и устройства не поддерживают распознавание цветных QR-кодов, поэтому, прежде чем размещать такие коды на печатной продукции, тщательно тестируйте их.
Скачать в формате — выбор формата файла изображения. - Нажмите на кнопку с требуемым форматом изображения — PNG, JPG, GIF или SVG. Начнется скачивание файла.

Печать QR-кодов
Рекомендуется использовать форматы печати с высоким разрешением: растровые JPG и PNG, векторные форматы EPS и SVG. Они подходят, прежде всего, для крупноформатной печати, так как изображения в этих форматах возможно увеличить без потери качества. Перед публикацией кодов следует проверить их считываемость при помощи различных смартфонов и приложений.
Стоит учитывать и другие параметры печати помимо формата файла. Размер оттиска кода выбирайте в зависимости от количества зашифрованных символов. Чем больше информации шифруется, тем больше требуется места.
Делайте размер оттиска не менее, чем 2х2 см.
Размещайте QR-код только на ровных поверхностях.
Как сканировать QR-коды
Для сканирования требуется мобильный телефон и установленное приложение для сканирования QR-кодов (QR ридер). Такие приложения доступны для бесплатной загрузки в магазинах приложений.
Чтобы отсканировать код:
- Откройте QR-ридер на своем устройстве.
- Поднесите камеру к QR-коду. Сканирование выполняется мгновенно.
Уровни коррекции ошибок
У QR-кода есть специальный механизм, который позволяет увеличить надежность хранения зашифрованной информации — коррекция ошибок. С помощью него становится возможным распознавать даже коды, часть которых была испорчена или затерта.
У кодов с самым высоким уровнем надежности (H) могут быть искажены до 30% поверхности, тем не менее информация сохранится и её будет возможно корректно прочитать.
Всего существует 4 уровня коррекции ошибок: L — низкий, M — средний, Q — выше среднего и H — высокий. Чем выше уровень, тем надежнее код, но вместе с уровнем возрастает и размер файла изображения.
Источник Habrahabr

Иногда возникают такие ситуации, когда нужно прочитать QR код, а смартфона под рукой нет. Что же делать? В голову приходит лишь попробовать прочитать вручную. Если кто-нибудь сталкивался с такими ситуациями или кому просто интересно как же читается QR код машинами, то данная статья поможет вам разобраться в этой проблеме.
В статье рассмотрены базовые особенности QR кодов и методика дешифрирования информации без использования вычислительных машин.
Решение задачи непосредственного чтения информации с QR-картинки рассмотрим на примере двух кодов.

Чтобы понять, как извлечь данные из кода, нужно разобраться в алгоритме. Существует несколько стандартов в семействе QR кодов, с их базовыми принципами можно ознакомиться в спецификациях. Кратко поясню: данные, которые необходимо закодировать, разбиваются на блоки в зависимости от режима кодирования. К разбитым по блокам данным прибавляется заголовок, указывающий режим и количество блоков. Существуют и такие режимы, в которых используется более сложная структура размещения информации. Данные режимы рассматривать не будем, в виду того, что извлекать вручную из них информацию нецелесообразно. Однако, основываясь на тех принципах, что описаны ниже, можно адаптироваться и к этим режимам.
На случай некорректного чтения данных в QR применяются специальные коды, которые способны исправить недочёты при чтении. Это так называемые коды Рида-Соломона. Принцип вычисления кодов, а также исправление ошибок в блоках информации рассматривать не будем, это тема отдельной статьи. Корректирующие ошибки коды Рида-Соломона (RS) записываются после всех информационных данных. Это очень упрощает задачу непосредственного чтения информации: можно просто считать данные, не трогая коды. Как показывает практика, обычно бОльшую часть QR -матрицы занимают корректирующие RS-коды.
По стандарту, данные с RS-кодами перед записью в картинку «перемешиваются». Для этих целей используют специальные маски. Существует 8 алгоритмов, среди которых выбирается наилучший. Критерии выбора основаны на системе штрафов, о которых можно также почитать в спецификации.
«Перемешанные» данные записываются в особой последовательности на шаблонную картинку, куда добавляется техническая информация для декодирующих устройств. Исходя из описанного алгоритма, можно выделить схему извлечения данных из QR кода:

Здесь зелёным фломастером подчёркнуты пункты, которые нужно будет реализовать при непосредственном чтении кода. Остальные пункты можно опустить в виду того, что считывание производит человек.
Шаг 0. QR код

Взглянув на картинки, можно заметить несколько отчётливых областей. Эти области используются для детектирования QR кода. Эти данные не представляют интереса с точки зрения записанной информации, но их нужно вычеркнуть или просто запомнить их расположение, чтобы они не мешали. Всё остальное поле кода несёт уже полезную информацию. Её можно разбить на две части: системная информация и данные. Также существует информация о версии кода. От версии кода зависит максимальный объём данных, которые могут быть записаны в код. При повышении версии – добавляются специальные блоки, например как здесь:

По ним можно сориентироваться и понять какая версия QR перед вами. Коды высоких версий обычно также нецелесообразно считывать вручную.
Размещение системной информации показано на рисунке:

Системная информация дублируется, что позволяет значительно понизить вероятность возникновения ошибок при детектировании кода и считывании. Системная информация – это 15 бит данных, среди которых первые 5 — это полезная информация, а остальные 10 – это BCH (15,5) код, который позволяет исправлять ошибки в системных данных. К классу BCH кодов относят и RS коды. Обратите внимание, что на рисунке две полоски по 15 бит не пересекаются.
Шаг 1. Чтение 5 бит системной информации
Как уже говорилось, интерес представляют только первые 5 бит.
Из которых 2 бита показывают уровень коррекции ошибок, а остальные 3 бита показывают какая маска из доступных 8 применяется к данным. В рассматриваемых QR кодах системная информация содержит:

Шаг 2. Маска для системной информации
Кроме уже озвученных схем зашиты системной информации, в добавок, используется статическая маска, которая применяется к любой системной информации.
Она имеет вид: 101010000010010.
Так как имеет интерес только первые 5 бит, то маску можно сократить и легко запомнить: 10101 (десять-сто один).
После применения операции «исключающего или» (xor) получаем информацию.
Возможные уровни коррекции ошибок:
Возможные маски:
| 000 | (i + j) mod 2 = 0 |
| 001 | i mod 2 = 0 |
| 010 | j mod 3 = 0 |
| 011 | (i + j) mod 3 = 0 |
| 100 | ((i div 2) + (j div 3)) mod 2 = 0 |
| 101 | (i j) mod 2 + (i j) mod 3 = 0 |
| 110 | ((i j) mod 2 + (i j) mod 3) mod 2 = 0 |
| 111 | ((i+j) mod 2 + (i j) mod 3) mod 2 = 0 |

Шаг 3. Чтение заголовка данных
Чтобы понять с какими данными предстоит иметь дело, необходимо изначально прочитать 4-х битный заголовок, который содержит в себе информацию о режиме. Специфика чтения данных изображена на картинке:

Список возможных режимов:
| ECI | 0111 |
| Числовые | 0001 |
| Буквенно-числовые | 0010 |
| 8-битный (байтный) | 0100 |
| Kanji | 1000 |
| Структурированное дополнение | 0011 |
| FNC1 | 0101 (1-я позиция) 1001 (2-я позиция) |
Шаг 4. Применение маски к заголовку
После извлечения 4-х бит, описывающих режим, необходимо к ним применить маску.
В нашем случае для двух кодов используются разные маски. Маска определяется выражением, приведённым в таблице выше. Если данное выражение сводится к TRUE (верное) для бита с координатами (i,j), то бит инвертируется, иначе всё остаётся без изменений. Начало координат в левом верхнем углу (0,0). Взглянув на выражения, можно заметить в них закономерности. Для рассматриваемых QR кодов, маски будут выглядеть так:


Получим режимы:

Шаг 5. Чтение данных
После получения данных о режиме можно приступать к чтению информации. Надо оговорить, что наиболее интересно считывать числовые и буквенно-числовые данные, так как они легко интерпретируются. Но также не стоит бояться 8-битных. Это может быть также легко интерпретируемая информация. Например, многие онлайн генераторы QR текст кодируют в этом режиме, используя ASCII. Ещё одна причина, почему следует изначально прочитать режим это то, что от него зависит количество пакетов данных. Которая также зависит и от версии кода. Для версий с первой по девятую длины блоков для более читабельных режимов:
| Числовые | 10 бит / 4 бита |
| Буквенно-числовые | 9 бит |
| 8-битный (байтный) | 8 бит |
Первый блок после указателя режима – это количество символов. Для числового режима количество закодировано в 10 следующих битах, а для 8-битного режима в 8 битах (прошу прощения за тавтологию).

На рисунке видно, что в левом QR коде, как и отмечалось, записана цифра 5. Это видно по указателю количества символов и последующим после него 4 битам. В числовом режиме наряду с 10-битными блоками используются 4-х битные блоки для экономии места, если в 10-битном объёме нет необходимости. В правом коде, зашифровано 4 символа. На данный момент неизвестно, что зашифровано в нём. Поэтому необходимо перейти к чтению следующего столбца для извлечения всех 4-х блок информации.

На рисунке видно, все 4 пакета представляют собой коды ASCII латинских букв, образующие слово «habr»
Естественно наилучшим способом остаётся достать телефон из кармана и, наведя камеру на QR-картинку, считать всю информацию. Однако в экстренных случаях может пригодиться и описанная методика. Конечно, в голове не удержишь все указатели режимов и типов масок, а также ASCII символы, но популярные комбинации запомнить (хотя бы те, что рассмотрены в статье) под силу.
Спецификация:
BS ISO/IEC 18004:2006. Information technology. Automatic identification and data capture techniques. QR Code 2005 bar code symbology specification. London: BSI. 2007. p. 126. ISBN 978-0-580-67368-9.
P.S. Соблюдайте правила ресурса и условия Creative Commons Attribution 3.0 Unported (CC BY 3.0)
О QR коде
Делаем QR код
Генератор QR кода у нас
Генератор QR кода в векторе
Google QR код
Необычный QR код
Читаем QR код
QR сканеры

Художественный QR-код. Несмотря на дополнительную информацию, этот код остаётся читаемым



QR-код, используемый на большом рекламном щите в Японии, ссылающийся на сайт sagasou.mobi в Сибуя, Токио.

QR-код используется и печатается на железнодорожных билетах в Китае с 2010 года.[1]
QR-код[a] (англ. Quick Response code — код быстрого отклика[2]; сокр. QR code) — тип матричных штриховых кодов (или двухмерных штриховых кодов), изначально разработанных для автомобильной промышленности Японии. Его создателем считается Масахиро Хара[3]. Сам термин является зарегистрированным товарным знаком японской компании «Denso». Штрихкод — считываемая машиной оптическая метка, содержащая информацию об объекте, к которому она привязана. QR-код использует четыре стандартизированных режима кодирования (числовой, буквенно-цифровой, двоичный и кандзи) для эффективного хранения данных; могут также использоваться расширения[4].
Система QR-кодов стала популярной за пределами автомобильной промышленности благодаря возможности быстрого считывания и большей ёмкости по сравнению со штрихкодами стандарта UPC. Расширения включают отслеживание продукции, идентификацию предметов, отслеживание времени, управление документами и общий маркетинг[5].
QR-код состоит из чёрных квадратов, расположенных в квадратной сетке на белом фоне, которые могут считываться с помощью устройств обработки изображений, таких как камера, и обрабатываться с использованием кодов Рида — Соломона до тех пор, пока изображение не будет надлежащим образом распознано. Затем необходимые данные извлекаются из шаблонов, которые присутствуют в горизонтальных и вертикальных компонентах изображения[5].
Описание
В те дни, когда не было QR-кода, компонентное сканирование проводилось на заводе-изготовителе Denso разными штрихкодами. Однако из-за того, что их было около 10, эффективность работы была крайне низкой, и работники жаловались, что они быстро устают, а также просили, чтобы был создан код, который может содержать больше информации, чем обычный штрихкод. Чтобы ответить на этот запрос работников, Denso-Wave была поставлена цель создать код, который может включать больше информации, чтобы позволить высокоскоростное компонентное сканирование.[6] Для этого Масахиро Хара, который работал в отделе разработки, начал разработку нового кода с 1992 года.[7] Вдохновением для создания QR-кода послужила игра го, в которую Масахиро Хара играл во время обеденного перерыва.[7] Он решил, что цель разработки состоит не только в увеличении объема кодовой информации, но и в «точном и быстром чтении», а также в том, чтобы сделать код читаемым и устойчивым к масляным пятнам, грязи и повреждениям, предполагая, что он будет использоваться на соответствующих производствах. QR-код был представлен японской компанией Denso-Wave, в 1994 году после двухлетнего периода разработки.[8][9][10] Он был разработан с учетом производственной системы компании «Toyota» «Канбан» (точно в срок) для использования на заводах по производству автозапчастей и в распределительных центрах. Однако, поскольку он обладает высокой способностью обнаружения и исправления ошибок и сделан с открытым исходным кодом, он вышел из узкой сферы производственных цепочек поставок компании «Toyota» и начал использоваться в других сферах, что привело к тому, что теперь он широко используется не только в Японии, но и во всем мире. Огромная популярность штрихкодов в Японии привела к тому, что объём информации, зашифрованной в них, вскоре перестал устраивать промышленность. Японцы начали экспериментировать с новыми современными способами кодирования небольших объёмов информации в графической картинке. QR-код стал одним из наиболее часто используемых типов двумерного кода в мире.[11]
Спецификация QR-кода не описывает формат данных.
В отличие от старого штрих-кода, который сканируют тонким лучом, QR-код определяется датчиком или камерой как двумерное изображение. Три квадрата в углах изображения и меньшие синхронизирующие квадратики по всему коду позволяют нормализовать размер изображения и его ориентацию, а также угол, под которым датчик расположен к поверхности изображения. Точки переводятся в двоичные числа с проверкой по контрольной сумме.
Основное достоинство QR-кода — это лёгкое распознавание сканирующим оборудованием, что даёт возможность использования в торговле, производстве, логистике.
Хотя обозначение «QR code» является зарегистрированным товарным знаком «DENSO Corporation», использование кодов не облагается никакими лицензионными отчислениями, а сами они описаны и опубликованы в качестве стандартов ISO.

Наиболее популярные программы просмотра QR-кодов поддерживают такие форматы данных: URL, закладка в браузер, Email (с темой письма), SMS на номер (c темой), MeCard, vCard, географические координаты, подключение к сети Wi-Fi.
Также некоторые программы могут распознавать файлы GIF, JPG, PNG или MID меньше 4 КБ и зашифрованный текст, но эти форматы не получили популярности.[13]
Применение
QR-коды больше всего распространены в Японии. Уже в начале 2000 года QR-коды получили столь широкое распространение в стране, что их можно было встретить на большом количестве плакатов, упаковок и товаров, там подобные коды наносятся практически на все товары, продающиеся в магазинах, их размещают в рекламных буклетах и справочниках. С помощью QR-кода даже организовывают различные конкурсы и ролевые игры. Ведущие японские операторы мобильной связи совместно выпускают под своим брендом мобильные телефоны со встроенной поддержкой распознавания QR-кода[14].
В настоящее время QR-код также широко распространён в странах Азии, постепенно развивается в Европе и Северной Америке. Наибольшее признание он получил среди пользователей мобильной связи — установив программу-распознаватель, абонент может моментально заносить в свой телефон текстовую информацию, подключаться к сети Wi-Fi, отправлять письма по электронной почте, добавлять контакты в адресную книгу, переходить по web-ссылкам, отправлять SMS-сообщения и т. д.
Как показало исследование, проведённое компанией comScore[en] в 2011 году, 20 млн жителей США использовали мобильные телефоны для сканирования QR-кодов[15].
В Японии, Австрии и России QR-коды также используются на кладбищах и содержат информацию об усопшем[16][17][18].
В китайском городе Хэфэй пожилым людям были розданы значки с QR-кодами, благодаря которым прохожие могут помочь потерявшимся старикам вернуться домой[19].
QR-коды активно используются музеями[20], а также и в туризме, как вдоль туристических маршрутов, так и у различных объектов. Таблички, изготовленные из металла, более долговечны и устойчивы к вандализму.
Использование QR-кодов для подтверждения вакцинации
Одновременно с началом массовой вакцинации против COVID-19 весной 2021 года почти во всех странах мира началась выдача документов о вакцинации — цифровых или бумажных сертификатов, на которые повсеместно помещали QR-коды. К 9 ноября 2021 года QR-коды для подтверждения вакцинации или перенесённого заболевания (COVID-19) были введены в 77 субъектах Российской Федерации (в некоторых из них начало действия QR-кодов было отсрочено, чтобы дать населению возможность привиться). В Татарстане введение QR-кодов привело к столпотворениям на входах в метро и многочисленным конфликтам между пассажирами и кондукторами общественного транспорта[21].
Общая техническая информация
Самый маленький QR-код (версия 1) имеет размер 21×21 пиксель (без учёта полей), самый большой (версия 40) — 177×177 пикселей. Связь номера версии с количеством модулей простая — QR-код последующей версии больше предыдущего строго на 4 модуля по горизонтали и по вертикали.
Существует четыре основные кодировки QR-кодов:
- Цифровая: 10 битов на три цифры, до 7089 цифр.
- Алфавитно-цифровая: поддерживаются 10 цифр, буквы от A до Z и несколько спецсимволов. 11 битов на два символа, до 4296 символов
- Байтовая: данные в любой подходящей кодировке (по умолчанию ISO 8859-1), до 2953 байт.
- Кандзи: 13 битов на иероглиф, до 1817 иероглифов.
Также существуют «псевдокодировки»: задание способа кодировки в данных, разбиение длинного сообщения на несколько кодов и т. д.
Для исправления ошибок применяется код Рида — Соломона с 8-битным кодовым словом. Есть четыре уровня избыточности: 7, 15, 25 и 30 %. Благодаря исправлению ошибок удаётся нанести на QR-код рисунок и всё равно оставить его читаемым.
Чтобы в коде не было элементов, способных запутать сканер, область данных складывается по модулю 2 со специальной маской. Корректно работающий кодер должен перепробовать все варианты масок, посчитать штрафные очки для каждой по особым правилам и выбрать самую удачную.
-

1 – Введение
-
2 – Структура
-
3 – Кодирование
-
4 – Уровни
-
5 – Протоколы





Micro QR


Функциональные области Micro QR-кода
Отдельно существует микро QR-код ёмкостью до 35 цифр.
Эффективность хранения данных по сравнению с традиционным QR кодом значительно улучшена благодаря использованию всего одной метки позиционирования, по сравнению с тремя метками в обычном QR коде. Из-за этого освобождается определённое пространство, которое может быть использовано под данные. Кроме того, QR код требует свободного поля вокруг кода шириной минимум в 4 модуля (минимальной единицы построения QR-кода), в то время как Micro QR код требует поля в два модуля шириной. Из-за большей эффективности хранения данных, размер Micro QR кода увеличивается не столь значительно с увеличением объёма закодированных данных по сравнению с традиционным QR кодом.
По аналогии с уровнями коррекции ошибок в QR кодах, Micro QR код бывает четырёх версий, М1-М4[22][23].
| Версия кода | Количество модулей | Уровень коррекции ошибок | Цифры | Цифры и буквы | Двоичные данные | Кандзи |
|---|---|---|---|---|---|---|
| M1 | 11 | — | 5 | — | — | — |
| M2 | 13 | L (7 %) | 10 | 6 | — | — |
| M (15 %) | 8 | 5 | — | — | ||
| M3 | 15 | L (7 %) | 23 | 14 | 9 | 6 |
| M (15 %) | 18 | 11 | 7 | 4 | ||
| M4 | 17 | L (7 %) | 35 | 21 | 15 | 9 |
| M (15 %) | 30 | 18 | 13 | 8 | ||
| Q (25 %) | 21 | 13 | 9 | 5 |
Кодирование данных
Закодировать информацию в QR-код можно несколькими способами, а выбор конкретного способа зависит от того, какие символы используются. Если используются только цифры от 0 до 9, то можно применить цифровое кодирование, если кроме цифр необходимо зашифровать буквы латинского алфавита, пробел и символы $%*+-./:, используется алфавитно-цифровое кодирование. Ещё существует кодирование кандзи, которое применяется для шифрования китайских и японских иероглифов, и побайтовое кодирование. Перед каждым способом кодирования создаётся пустая последовательность бит, которая затем заполняется.
Цифровое кодирование
Этот тип кодирования требует 10 бит на 3 символа. Вся последовательность символов разбивается на группы по 3 цифры, и каждая группа (трёхзначное число) переводится в 10-битное двоичное число и добавляется к последовательности бит. Если общее количество символов не кратно 3, то если в конце остаётся 2 символа, полученное двузначное число кодируется 7 битами, а если 1 символ, то 4 битами.
Например, есть строка «12345678», которую надо закодировать. Последовательность разбивается на числа: 123, 456 и 78, затем каждое число переводится в двоичный вид: 0001111011, 0111001000 и 1001110, и объединяется это в один битовый поток: 000111101101110010001001110.
Буквенно-цифровое кодирование
В отличие от цифрового кодирования, для кодирования 2 символов требуется 11 бит информации. Последовательность символов разбивается на группы по 2, в группе каждый символ кодируется согласно таблице «Значения символов в буквенно-цифровом кодировании». Значение первого символа умножается на 45, затем к этому произведению прибавляется значение второго символа. Полученное число переводится в 11-битное двоичное число и добавляется к последовательности бит. Если в последней группе остаётся один символ, то его значение кодируется 6-битным числом.
Рассмотрим на примере: «PROOF». Разбиваем последовательность символов на группы: PR, OO, F. Находим соответствующие значения символам к каждой группе (смотрим в таблицу): PR — (25,27), OO — (24,24), F — (15). Находим значения для каждой группы: 25 × 45 + 27 = 1152, 24 × 45 + 24 = 1104, 15 = 15. Переводим каждое значение в двоичный вид: 1152 = 10010000000, 1104 = 10001010000, 15 = 001111. Объединяем в одну последовательность: 1001000000010001010000001111.
Байтовое кодирование
Таким способом кодирования можно закодировать любые символы. Входной поток символов кодируется в любой кодировке (рекомендовано в UTF-8), затем переводится в двоичный вид, после чего объединяется в один битовый поток.
Например, слово «Мир» кодируем в Unicode (HEX) в UTF-8:
М — D09C; и — D0B8; р — D180. Переводим каждое значение в двоичную систему счисления: D0 = 11010000, 9C = 10011100, D0 = 11010000, B8 = 10111000, D1 = 11010001 и 80 = 10000000; объединяем в один поток битов: 11010000 10011100 11010000 10111000 11010001 10000000.
Кандзи
В основе кодирования иероглифов (как и прочих символов) лежит визуально воспринимаемая таблица или список изображений иероглифов с их кодами. Такая таблица называется «character set». Для японского языка основное значение имеют две таблицы символов: JIS 0208:1997 и JIS 0212:1990. Вторая из них служит в качестве дополнения по отношению к первой. JIS 0208:1997 разбита на 94 страницы по 94 символа. К примеру, страница 4 — хирагана, 5 — катакана, 7 — кириллица, 16—43 — кандзи уровня 1, 48—83 — кандзи уровня 2. Кандзи уровня 1 («JIS дайити суйдзюн кандзи») упорядочены по онам. Кандзи уровня 2 («JIS дайни суйдзюн кандзи») упорядочены по ключам, и внутри них — по количеству черт.
Добавление служебной информации
После определения версии кода и кодировки необходимо определиться с уровнем коррекции ошибок. В таблице представлены максимальные значения уровней коррекции для различных версий QR-кода. Для исправления ошибок применяется код Рида — Соломона с 8-битным кодовым словом.
Таблица. Максимальное количество информации.
Строка — уровень коррекции, столбец — номер версии.
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 | 19 | 20 | |
| L | 152 | 272 | 440 | 640 | 864 | 1088 | 1248 | 1552 | 1856 | 2192 | 2592 | 2960 | 3424 | 3688 | 4184 | 4712 | 5176 | 5768 | 6360 | 6888 |
| M | 128 | 224 | 352 | 512 | 688 | 864 | 992 | 1232 | 1456 | 1728 | 2032 | 2320 | 2672 | 2920 | 3320 | 3624 | 4056 | 4504 | 5016 | 5352 |
| Q | 104 | 176 | 272 | 384 | 496 | 608 | 704 | 880 | 1056 | 1232 | 1440 | 1648 | 1952 | 2088 | 2360 | 2600 | 2936 | 3176 | 3560 | 3880 |
| H | 72 | 128 | 208 | 288 | 368 | 480 | 528 | 688 | 800 | 976 | 1120 | 1264 | 1440 | 1576 | 1784 | 2024 | 2264 | 2504 | 2728 | 3080 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 | 28 | 29 | 30 | 31 | 32 | 33 | 34 | 35 | 36 | 37 | 38 | 39 | 40 | |
| L | 7456 | 8048 | 8752 | 9392 | 10208 | 10960 | 11744 | 12248 | 13048 | 13880 | 14744 | 15640 | 16568 | 17528 | 18448 | 19472 | 20528 | 21616 | 22496 | 23648 |
| M | 5712 | 6256 | 6880 | 7312 | 8000 | 8496 | 9024 | 9544 | 10136 | 10984 | 11640 | 12328 | 13048 | 13800 | 14496 | 15312 | 15936 | 16816 | 17728 | 18672 |
| Q | 4096 | 4544 | 4912 | 5312 | 5744 | 6032 | 6464 | 6968 | 7288 | 7880 | 8264 | 8920 | 9368 | 9848 | 10288 | 10832 | 11408 | 12016 | 12656 | 13328 |
| H | 3248 | 3536 | 3712 | 4112 | 4304 | 4768 | 5024 | 5288 | 5608 | 5960 | 6344 | 6760 | 7208 | 7688 | 7888 | 8432 | 8768 | 9136 | 9776 | 10208 |
После определения уровня коррекции ошибок необходимо добавить служебные поля, они записываются перед последовательностью бит, полученной после этапа кодирования. В них указывается способ кодирования и количество данных. Значение поля способа кодирования состоит из 4 бит, оно не изменяется, а служит знаком, который показывает, какой способ кодирования используется. Оно имеет следующие значения:
- 0001 для цифрового кодирования,
- 0010 для буквенно-цифрового и
- 0100 для побайтового
Пример:
Ранее в примере байтового кодирования кодировалось слово «Мир», при этом получилась следующая последовательность двоичного кода:
11010000 10011100 11010000 10111000 11010001 10000000, содержащая 48 бит информации.
Пусть необходим уровень коррекции ошибок Н, позволяющий восстанавливать 30 % утраченной информации. По таблице максимальное количество информации выбирается оптимальная версия QR-кода (в данном случае 1 версия, которая позволяет закодировать 72 бита полезной информации при уровне коррекции ошибок Н).
Информация о способе кодирования: побайтовому кодированию соответствует поле 0100.
Указание количества данных (для цифрового и буквенно-цифрового кодирования — количество символов, для побайтового — количество байт): данная последовательность содержит 6 байт данных (в двоичной системе счисления: 110).
По таблице определяется необходимая длина двоичного числа — 8 бит. Дописываются недостающие нули: 00000110.
| Версия 1-9 | Версия 10-26 | Версия 27-40 | |
|---|---|---|---|
| Цифровое | 10 бит | 12 бит | 14 бит |
| Буквенно-цифровое | 9 бит | 11 бит | 13 бит |
| Побайтовое | 8 бит | 16 бит | 16 бит |
Вся информация записывается в порядке <способ кодирования> <количество данных> <данные>, получается последовательность бит:
0100 00000110 11010000 10011100 11010000 10111000 11010001 10000000.
Разделение на блоки
Последовательность байт разделяется на определённое для версии и уровня коррекции количество блоков, которое приведено в таблице «Количество блоков». Если количество блоков равно одному, то этот этап можно пропустить. А при повышении версии — добавляются специальные блоки.
Сначала определяется количество байт (данных) в каждом из блоков. Для этого надо разделить всё количество байт на количество блоков данных. Если это число не целое, то надо определить остаток от деления. Этот остаток определяет, сколько блоков из всех дополнены (такие блоки, количество байт в которых больше на один, чем в остальных). Вопреки ожиданию, дополненными блоками должны быть не первые блоки, а последние. Затем идёт последовательное заполнение блоков.
Пример: для версии 9 и уровня коррекции M количество данных — 182 байта, количество блоков — 5. Поделив количество байт данных на количество блоков, получаем 36 байт и 2 байта в остатке. Это значит, что блоки данных будут иметь следующие размеры: 36, 36, 36, 37, 37 (байт). Если бы остатка не было, то все 5 блоков имели бы размер по 36 байт.
Блок заполняется байтами из данных полностью. Когда текущий блок полностью заполняется, очередь переходит к следующему. Байтов данных должно хватить ровно на все блоки, не больше и не меньше.
Создание байтов коррекции
Процесс основан на алгоритме Рида — Соломона. Он должен быть применён к каждому блоку информации QR-кода. Сначала определяется количество байт коррекции, которые необходимо создать, а затем, с ориентиром на эти данные, создаётся многочлен генерации. Количество байтов коррекции на один блок определятся по выбранной версии кода и уровню коррекции ошибок (приведено в таблице).
Таблица. Количество байтов коррекции на один блок
Строка — уровень коррекции, столбец — номер версии.
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 | 19 | 20 | 21 | 22 | 23 | 24 | 25 | 26 | 27 | 28 | 29 | 30 | 31 | 32 | 33 | 34 | 35 | 36 | 37 | 38 | 39 | 40 | |
| L | 7 | 10 | 15 | 20 | 26 | 18 | 20 | 24 | 30 | 18 | 20 | 24 | 26 | 30 | 22 | 24 | 28 | 30 | 28 | 28 | 28 | 28 | 30 | 30 | 26 | 28 | 30 | 30 | 30 | 30 | 30 | 30 | 30 | 30 | 30 | 30 | 30 | 30 | 30 | 30 |
| M | 10 | 16 | 26 | 18 | 24 | 16 | 18 | 22 | 22 | 26 | 30 | 22 | 22 | 24 | 24 | 28 | 28 | 26 | 26 | 26 | 26 | 28 | 28 | 28 | 28 | 28 | 28 | 28 | 28 | 28 | 28 | 28 | 28 | 28 | 28 | 28 | 28 | 28 | 28 | 28 |
| Q | 13 | 22 | 18 | 26 | 18 | 24 | 18 | 22 | 20 | 24 | 28 | 26 | 24 | 20 | 30 | 24 | 28 | 28 | 26 | 30 | 28 | 30 | 30 | 30 | 30 | 28 | 30 | 30 | 30 | 30 | 30 | 30 | 30 | 30 | 30 | 30 | 30 | 30 | 30 | 30 |
| H | 17 | 28 | 22 | 16 | 22 | 28 | 26 | 26 | 24 | 28 | 24 | 28 | 22 | 24 | 24 | 30 | 28 | 28 | 26 | 28 | 30 | 24 | 30 | 30 | 30 | 30 | 30 | 30 | 30 | 30 | 30 | 30 | 30 | 30 | 30 | 30 | 30 | 30 | 30 | 30 |
По количеству байтов коррекции определяется генерирующий многочлен (приведено в таблице).
Таблица. Генерирующие многочлены.
| Количество байт коррекции | Генерирующий многочлен |
|---|---|
| 7 | 87, 229, 146, 149, 238, 102, 21 |
| 10 | 251, 67, 46, 61, 118, 70, 64, 94, 32, 45 |
| 13 | 74, 152, 176, 100, 86, 100, 106, 104, 130, 218, 206, 140, 78 |
| 15 | 8, 183, 61, 91, 202, 37, 51, 58, 58, 237, 140, 124, 5, 99, 105 |
| 16 | 120, 104, 107, 109, 102, 161, 76, 3, 91, 191, 147, 169, 182, 194, 225, 120 |
| 17 | 43, 139, 206, 78, 43, 239, 123, 206, 214, 147, 24, 99, 150, 39, 243, 163, 136 |
| 18 | 215, 234, 158, 94, 184, 97, 118, 170, 79, 187, 152, 148, 252, 179, 5, 98, 96, 153 |
| 20 | 17, 60, 79, 50, 61, 163, 26, 187, 202, 180, 221, 225, 83, 239, 156, 164, 212, 212, 188, 190 |
| 22 | 210, 171, 247, 242, 93, 230, 14, 109, 221, 53, 200, 74, 8, 172, 98, 80, 219, 134, 160, 105, 165, 231 |
| 24 | 229, 121, 135, 48, 211, 117, 251, 126, 159, 180, 169, 152, 192, 226, 228, 218, 111, 0, 117, 232, 87, 96, 227, 21 |
| 26 | 173, 125, 158, 2, 103, 182, 118, 17, 145, 201, 111, 28, 165, 53, 161, 21, 245, 142, 13, 102, 48, 227, 153, 145, 218, 70 |
| 28 | 168, 223, 200, 104, 224, 234, 108, 180, 110, 190, 195, 147, 205, 27, 232, 201, 21, 43, 245, 87, 42, 195, 212, 119, 242, 37, 9, 123 |
| 30 | 41, 173, 145, 152, 216, 31, 179, 182, 50, 48, 110, 86, 239, 96, 222, 125, 42, 173, 226, 193, 224, 130, 156, 37, 251, 216, 238, 40, 192, 180 |
Расчёт производится исходя из значений исходного массива данных и значений генерирующего многочлена, причём для каждого шага цикла отдельно.
Объединение информационных блоков
На данном этапе имеется два готовых блока: исходных данных и блоков коррекции (из прошлого шага), их необходимо объединить в один поток байт. По очереди необходимо брать один байт информации из каждого блока данных, начиная от первого и заканчивая последним. Когда же очередь доходит до последнего блока, из него берётся байт и очередь переходит к первому блоку. Так продолжается до тех пор, пока в каждом блоке не закончатся байты. Есть исключения, когда текущий блок пропускается, если в нём нет байт (ситуация, когда обычные блоки уже пусты, а в дополненных ещё есть по одному байту). Так же поступается и с блоками байтов коррекции. Они берутся в том же порядке, что и соответствующие блоки данных.
В итоге получается следующая последовательность данных: <1-й байт 1-го блока данных><1-й байт 2-го блока данных>…<1-й байт n-го блока данных><2-й байт 1-го блока данных>…<(m — 1)-й байт 1-го блока данных>…<(m — 1)-й байт n-го блока данных><m-й байт k-го блока данных>…<m-й байт n-го блока данных><1-й байт 1-го блока байтов коррекции><1-й байт 2-го блока байтов коррекции>…<1-й байт n-го блока байтов коррекции><2-й байт 1-го блока байтов коррекции>…<l-й байт 1-го блока байтов коррекции>…<l-й байт n-го блока байтов коррекции>.
Здесь n — количество блоков данных, m — количество байтов на блок данных у обычных блоков, l — количество байтов коррекции, k — количество блоков данных минус количество дополненных блоков данных (тех, у которых на 1 байт больше).
Этап размещения информации на поле кода
На QR-коде есть обязательные поля, они не несут закодированной информации, а содержат информацию для декодирования. Это:
- Поисковые узоры
- Выравнивающие узоры
- Полосы синхронизации
- Код маски и уровня коррекции
- Код версии (с 7-й версии)
а также обязательный отступ вокруг кода. Отступ — это рамка из белых модулей, её ширина — 4 модуля.
Поисковые узоры — это 3 квадрата по углам кроме правого нижнего. Используются для определения расположения кода. Они состоят из квадрата 3×3 из чёрных модулей, вокруг рамка из белых модулей шириной 1, потом ещё одна рамка из чёрных модулей, так же шириной 1, и ограждение от остальной части кода — половина рамки из белых модулей шириной 1. Итого эти объекты имеют размер 8×8 модулей.
Выравнивающие узоры — появляются, начиная со второй версии, используются для дополнительной стабилизации кода, более точном его размещении при декодировании. Состоят они из 1 чёрного модуля, вокруг которого стоит рамка из белых модулей шириной 1, а потом ещё одна рамка из чёрных модулей, также шириной 1. Итоговый размер выравнивающего узора — 5×5. Стоят такие узоры на разных позициях в зависимости от номера версии. Выравнивающие узоры не могут накладываться на поисковые узоры. Ниже представлена таблица расположения центрального чёрного модуля, там указаны цифры — это возможные координаты, причём как по горизонтали, так и по вертикали. Эти модули стоят на пересечении таких координат. Отсчёт ведётся от верхнего левого узла, его координаты (0,0).
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| — | 18 | 22 | 26 | 30 | 34 | 6, 22, 38 | 6, 24, 42 | 6, 26, 46 | 6, 28, 50 | 6, 30, 54 | 6, 32, 58 | 6, 34, 62 | 6, 26, 46, 66 | 6, 26, 48, 70 | 6, 26, 50, 74 | 6, 30, 54, 78 | 6, 30, 56, 82 | 6, 30, 58, 86 | 6, 34, 62, 90 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 | 28 | 29 | 30 | 31 | 32 | 33 | 34 | 35 | 36 | 37 | 38 | 39 | 40 |
| 6, 28, 50, 72, 94 | 6, 26, 50, 74, 98 | 6, 30, 54, 78, 102 | 6, 28, 54, 80, 106 | 6, 32, 58, 84, 110 | 6, 30, 58, 86, 114 | 6, 34, 62, 90, 118 | 6, 26, 50, 74, 98, 122 | 6, 30, 54, 78, 102, 126 | 6, 26, 52, 78, 104, 130 | 6, 30, 56, 82, 108, 134 | 6, 34, 60, 86, 112, 138 | 6, 30, 58, 86, 114, 142 | 6, 34, 62, 90, 118, 146 | 6, 30, 54, 78, 102, 126, 150 | 6, 24, 50, 76, 102, 128, 154 | 6, 28, 54, 80, 106, 132, 158 | 6, 32, 58, 84, 110, 136, 162 | 6, 26, 54, 82, 110, 138, 166 | 6, 30, 58, 86, 114, 142, 170 |
Полосы синхронизации — используются для определения размера модулей. Располагаются они уголком, начинается одна от левого нижнего поискового узора (от края чёрной рамки, но переступив через белую), идёт до левого верхнего, а оттуда начинается вторая, по тому же правилу, заканчивается она у правого верхнего. При наслоении на выравнивающий модуль он должен остаться без изменений. Выглядят полосы синхронизации как линии чередующихся между собой чёрных и белых модулей.
Код маски и уровня коррекции — расположен рядом с поисковыми узорами: под правым верхним (8 модулей) и справа от левого нижнего (7 модулей), и дублируются по бокам левого верхнего, с пробелом на 7 ячейке — там, где проходят полосы синхронизации, причём горизонтальный код в вертикальную часть, а вертикальный — в горизонтальную.
Код версии — нужен для определения версии кода. Находятся слева от верхнего правого и сверху от нижнего левого, причём дублируются. Дублируются они так — зеркальную копию верхнего кода поворачивают против часовой стрелки на 90 градусов. Ниже представлена таблица кодов, 1 — чёрный модуль, 0 — белый.
| Версия | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 | 19 | 20 | 21 | 22 | 23 |
| Код версии | 000010 011110 100110 | 010001 011100 111000 | 110111 011000 000100 | 101001 111110 000000 | 001111 111010 111100 | 001101 100100 011010 | 101011 100000 100110 | 110101 000110 100010 | 010011 000010 011110 | 011100 010001 011100 | 111010 010101 100000 | 100100 110011 100100 | 000010 110111 011000 | 000000 101001 111110 | 100110 101101 000010 | 111000 001011 000110 | 011110 001111 111010 |
| 24 | 25 | 26 | 27 | 28 | 29 | 30 | 31 | 32 | 33 | 34 | 35 | 36 | 37 | 38 | 39 | 40 | |
| 001101 001101 100100 | 101011 001001 011000 | 110101 101111 011100 | 010011 101011 100000 | 010001 110101 000110 | 110111 110001 111010 | 101001 010111 111110 | 001111 010011 000010 | 101000 011000 101101 | 001110 011100 010001 | 010000 111010 010101 | 110110 111110 101001 | 110100 100000 001111 | 010010 100100 110011 | 001100 000010 110111 | 101010 000110 001011 | 111001 000100 010101 |
Занесение данных
Оставшееся место делят на столбики шириной в 2 модуля и заносят туда информацию, причём делают это «змейкой». Сначала в правый нижний квадратик заносят первый бит информации, потом в его левого соседа, потом в тот, который был над первым и так далее. Заполнение столбцов ведётся снизу вверх, а потом сверху вниз и т. д., причём по краям заполнение битов ведётся от крайнего бита одного столбца до крайнего бита соседнего столбца, что задаёт «змейку» на столбцы с направлением вниз.
Если информации окажется недостаточно, то поля просто оставляют пустыми (белые модули). При этом на каждый модуль накладывается маска.
-

Описание полей QR-кода.
-

Код маски и уровня коррекции, возможные XOR-маски
-

-
-

8-цветный код JAB, содержащий текст «Добро пожаловать в Википедию, бесплатную энциклопедию, которую может редактировать каждый».
-

Примеры цветного двухмерного кода большой емкости (HCC2D): (a) 4-цветный код HCC2D и (b) 8-цветный код HCC2D.
-
Версия 1
-
Функциональные области QR-кода версии 1
-
Версия 40
-

IQR-код









См. также
- Q-код
- Сравнение характеристик штрихкодов
- Data Matrix
- Semacode
- PDF417
- Aztec Code
- Microsoft Tag
- QRpedia
- Перфокарта
Примечания
- ↑ Специалист по словообразованию М. А. Осадчий предлагает использовать в качестве русскоязычного эквивалента словосочетание «графический код»[2].
- ↑ QR codes on China’s train tickets may leak personal information. Архивировано 12 декабря 2013 года. Дата обращения 16 марта 2013.
- ↑ 2,0 2,1 В Институте имени Пушкина предложили переименовать QR-код Архивная копия от 10 февраля 2022 на Wayback Machine // Радио Sputnik, 10.02.2022
- ↑ История QR-кода Эту технологию придумал японский инженер во время игры в го на работе. Дата обращения: 8 ноября 2021. Архивировано 8 ноября 2021 года.
- ↑ QR Code features (англ.). Denso-Wave. Дата обращения: 27 августа 2017. Архивировано 29 января 2013 года.
- ↑ 5,0 5,1 QR Code Essentials (англ.) (недоступная ссылка). Denso ADC (2011). Дата обращения: 28 августа 2017. Архивировано 12 мая 2013 года.
- ↑ Borko Furht. Handbook of Augmented Reality. — Springer, 2011. — С. 341. — ISBN 9781461400646.
- ↑ 7,0 7,1 ヒントは休憩中の“囲碁”だった…『QRコード』開発秘話 生みの親が明かす「特許オープンにした」ワケ, 東海テレビ放送 (29 ноября 2019). Архивировано 30 сентября 2020 года. Дата обращения 29 ноября 2019.
- ↑ NHKビジネス特集 「QRコード」生みの親に聞いてみた Архивная копия от 20 мая 2019 на Wayback Machine 、2019年5月20日
- ↑ 2D Barcodes. NHK World-Japan (26 марта 2020). Дата обращения: 24 апреля 2020. Архивировано 7 апреля 2020 года.
- ↑ Сайт компании Denso-Wave. Дата обращения: 18 сентября 2012. Архивировано 16 октября 2012 года.
- ↑ QR Code—About 2D Code (недоступная ссылка). Denso-Wave. Дата обращения: 27 мая 2016. Архивировано 5 июня 2016 года.
- ↑ «Евгений Онегин» — теперь и в QR-коде (недоступная ссылка). Дата обращения: 23 ноября 2020. Архивировано 27 ноября 2020 года.
- ↑ Популярность QR-кодов. Дата обращения: 8 января 2022. Архивировано 8 января 2022 года.
- ↑ QR-код: использование. Дата обращения: 14 марта 2010. Архивировано 6 июня 2014 года.
- ↑ Леонид Бугаев. 2012, стр. 167
- ↑ QR коды на кладбищах. Дата обращения: 24 апреля 2020. Архивировано 15 мая 2021 года.
- ↑ QR коды на кладбищах (недоступная ссылка). Дата обращения: 24 октября 2012. Архивировано 6 июня 2014 года.
- ↑ Внук Юрия Никулина рассказывает про интерактивный мемориал (недоступная ссылка). Цифровое наследие (21 августа 2017). Дата обращения: 27 августа 2017. Архивировано 23 августа 2017 года.
- ↑ Бейджи с QR-кодами для поиска дороги домой. Дата обращения: 15 октября 2014. Архивировано 19 ноября 2014 года.
- ↑ Реклама «Дня музеев — 2012». Дата обращения: 2 марта 2012. Архивировано 24 апреля 2014 года.
- ↑ Что известно о законопроекте о введении QR-кодов в общественных местах Архивная копия от 20 декабря 2021 на Wayback Machine // ТАСС, 16.12.2021.
- ↑ Описание Micro QR кода | QR коды нового поколения. qrcc.ru. Дата обращения: 9 июня 2018. Архивировано 12 июня 2018 года.
- ↑ Micro QR Code | QRcode.com | DENSO WAVE (англ.). www.qrcode.com. Дата обращения: 31 мая 2019. Архивировано 31 мая 2019 года.
Литература
- Бугаев Л. Мобильный маркетинг. Как зарядить свой бизнес в мобильном мире. — М.: Альпина Паблишер, 2012. — 214 с. — ISBN 978-5-9614-2222-1.
- ГОСТ Р ИСО/МЭК 18004-2015 Информационные технологии. Технологии автоматической идентификации и сбора данных. Спецификация символики штрихового кода QR Code
Ссылки
- Сайт компании Denso Wave, посвящённый QR-кодам (англ.)
Шаблон:Штриховые коды
Чтобы самостоятельно получить закодированную в QR код информацию, нужно, прежде всего знать алгоритм и этапы ее получения. Для каждого отдельного типа кодирования существуют свои этапы и порядок преобразования информации о которых мы расскажем в этой статье.
Для получения QR матрицы, то есть самого изображения QR-кода, состоящего из квадратных модулей, необходимо произвести преобразование исходной информации в QR код. QR-кодирование происходит в несколько этапов, ни один из которых нельзя пропустить или исключить из процесса шифрования. Чтобы не ошибиться с порядком кодирования, все этапы в статье пронумерованы. Каждый из них рассмотрен более подробно, для того чтобы лучше понять необходимость действий выполняемых в нем. После прочтения этой статьи, зная какой-либо из языков программирования, можно попробовать написать свой собственный алгоритм для создания QR-кода.
Этап 1. Выбор метода шифрования данных
Метод шифрования зависит от типа кодируемых символов. Иначе говоря, на этом этапе осуществляется выбор одного из типов кодирования.
- цифровой;
- буквенно-цифровой;
- байтовый;
- кандзи.
После этого выбирается версия кода, именно она определяет размер получаемого изображения. Минимальный размер – 21х21 пиксель — можно получить при использовании первой версии. Максимальный размер QR-кода – 177х177 пикселей – получается если используется 40-я версия.Чем выше версия, тем больше символов можно зашифровать. В размерностях версий не учитываются поля матрицы.
Этап 2. Выбор уровня коррекции ошибок
Коррекционные данные относятся к служебной информации, без которой не обходится ни один QR-код.В качестве кода коррекции используются различные вариации кодов Рида-Соломона, длина кодового слова в которых равняется 8.
Существует 4 коррекционных уровня: L, M, Q и H.Каждый из нихимеет свое максимально допустимоеколичество повреждений изображения, выражаемое в процентах. При использовании уровня L, изображение может быть повреждено максимум на 7%от всей емкости, при Mи Q– 15 и 25 % соответственно. В случаях, когда к QR-изображению добавляется рисунок, рекомендуется применять наивысший коррекционный уровень – H, который сможет скорректировать до 30% поврежденного изображения.
У каждой версии QR-кода существуют свои наибольшие значения коррекционных уровней, выражаемые в количестве символов. Это связано с тем, что размерность матрицы имеет прямую зависимость от ее версии. Чем она выше, тем крупнее изображение, и тем большую площадь займут на нем закодированная информация и коррекционные данные. Максимальный объем полезных данных, в том числе служебных, можно узнать из специальных таблиц.
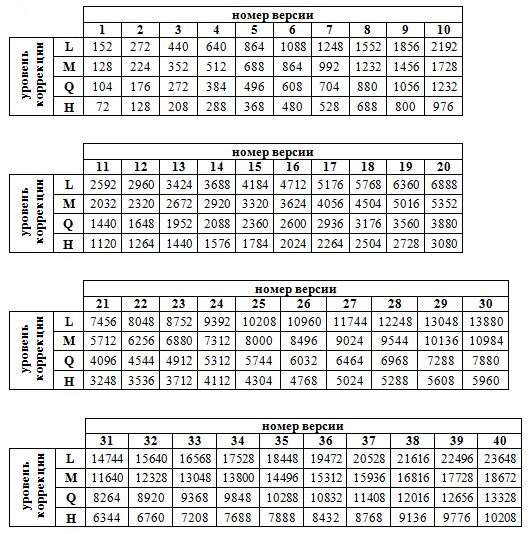
На этом же этапе записывается служебная информация. Она располагается перед закодированными символами, чтобы при считывании QR-кода, еще до прочтения закодированной информации, можно было узнать метод шифрования, и какое количество информации содержится в коде.
Количество информации представляется двоичным числом, длина которого зависит от версии и типа кодировки. Это число обозначает, сколько символов или байт зашифровано в коде.
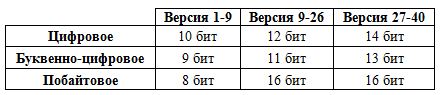
Поле, предназначенное для добавления метода кодирования всегда имеет неизменную размерность 4 бита. Меняются только значения указываемые в нем, согласно которым определяется метод кодирования при считывании:
- 0001 –цифровое;
- 0010 – буквенно-цифровое;
- 0100 –побайтовое.
По завершению этого этапа, должна сформироваться битовая последовательность. Биты в ней должны быть расположены в таком порядке: метод шифрования, количество данных, зашифрованная информация.
Пример. При кодировании слова «Дом» побайтовым методом, в Unicode (HEX) в UTF-8, символы слова имеют значения:
- «Д» — D094;
- «о» — D0BE;
- «м» — D0BC.
При переводе полученных 16-ричных значений в 2-ичную систему счисления:
- D0=11010000;
- 94=10010100;
- D0=11010000;
- BE=10111110;
- D0=11010000;
- BC=10111100.
После объединения в единую последовательность, она будет иметь вид: 11010000 10010100 11010000 10111110 11010000 10111100. Этот двоичный код содержит 48 бит данных.
При необходимости использования уровня Q, позволяющего восстанавливать 25% данных, согласно таблицам для определения максимального количества полезных данных, самой оптимальной версией QR-кода будет первая версия (позволяющая зашифровать 104 символа полезных данных, при коррекционном уровне Q).
Так как в качестве метода кодирования был выбран побайтовый, то в поле метода кодирования будет стоять значение 0100. При переводе его в 2-ичную систему счисления, он станет выглядеть как 110 и содержать 6 байт информации.
Согласно таблице для определения длины 2-ичного числа, его длина должна быть 8 бит. Поэтому последовательность 110 превращается в 00000110, путем дописывания к ней нулей.
По завершению этих этапов, поток бит выглядит следующим образом: 0100 00000110 11010000 10010100 11010000 10111110 11010000 10111100
Этап 3. Разбиение битового потока на блоки
Полученный на втором этапе поток бит разделяется на блоки, в соответствии со специальной таблицей. Из нее берутся значения согласно выбранным версии и коррекционным уровнем.
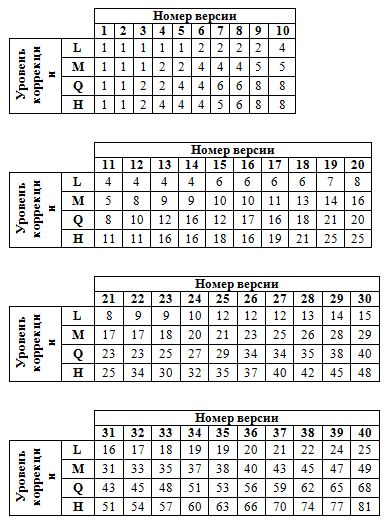
Если блок оказывается всего один, данный этап можно считать пройденным. Если их два и больше, то необходимо добавить специальные блоки.
Вначале определяется, сколько данных (в байтах) находится в каждом отдельном блоке. Чтобы это сделать, следует поделить число всех байт на число полученных при разбиении блоков. Полученные в результате этой операции остаточные байты показывают число дополненных блоков(число байт в них на единицу больше чем в других). Такие блоки могут находиться в различных частях последовательности, в том числе ими могут оказаться последние блоки.
После этого все полученные блоки последовательно заполняются байтами данных. После полного заполнения одного блока, происходит переход к следующему блоку.
Например, при использовании 8 версии и коррекционного уровня H:
- число данных — 688 символов (по таблице для определения наибольшего количества полезных данных), или86 байт (1 символ это один бит данных, в одном байте – 8 бит).
- число блоков равно 6 (по таблице выбора числа блоков).
При делении 86 на 6 получится 14 байт и 2 остаточных. Следовательно, размер блоков в байтах 14, 14, 14, 14, 15, 15 (при без остаточном делении, размер всех блоков был бы по 15 байт).В полученные блоки заносятся данные.
Этап 4. Создание корректирующих байтов
После того, как исходные данные были разбиты на блоки, для них создаются корректирующие байты. Этот этап основывается она алгоритме Рида-Соломона, применяемого ко всем без исключения блокам данных (даже если был получен всего один блок).
Из таблицы для определения числа корректирующих байт узнается, сколько таких байт понадобится создать. После этого создается генерирующий многочлен.
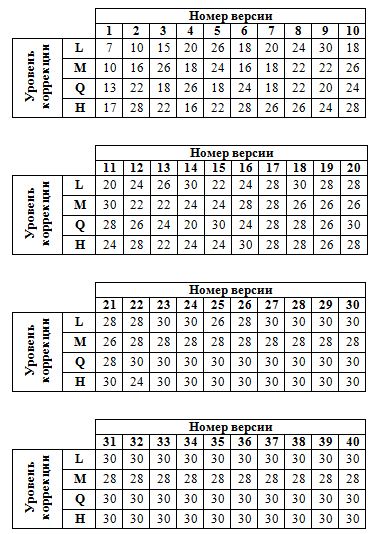
Для многочленов так же есть своя таблица. Каждое существующее число байт коррекции меет свой многочлен.
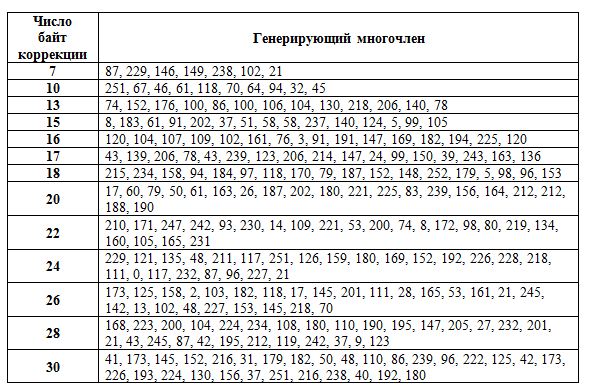
До того как начнется цикл создания байтов коррекции, подготавливается массив с длиной соответствующей максимальному числу байт в блоке. Байты блока заносятся в начало, а конец заполняется нулями.
Далее процедура повторяется до конца байт в блоке. По завершению всего цикла, каждый блок получит свои корректирующие байты.
Так же для работы с массивами данных понадобятся таблицы со значениями для поля Галуа и обратного поля Галуа, длинами 256.
Подробная работа цикла описана в примере ниже, байты представлены в 10-ричной системе от 0 до 255.
В качестве примера взят произвольный исходный блок данных: 32 197 133 85 197, все байты которого представлены десятичными числами от 0 до 255.
Используемая версия – 1, с уровнем M. Число создаваемых корректирующих байт – 7, им соответствует многочлен генерации: 87, 229, 146, 149, 238, 102, 21.
Создается массив на 7 элементов, в него заносятся байты данных: 32 197 133 85 197 0 0.
Первое действие цикла.По таблице обратного поля Галуа находится соответствие для первого элементаблока. Числу 32 соответствует число 5, оно складывается по модулю 255со всеми членами многочлена:92 234 151 154 243 107 26.
Для получения результата такого сложения, нужно сложить числа, и если их сумма меньше модульного числа, то это и есть сумма по модулю. Если же больше, то сумма по модулю вычисляется как остаток от деления суммы чисел на модуль.
Например, сложение чисел 5 и 87 по модулю 255, записывается как: 5mod 255 + 87 mod 255 = (5+87) mod 255 = 92mod255 = 92. Так как 92 меньше чем 255, то это и есть искомая сумма.
Если бы по модулю 255 складывались числа 187 и 95, то запись была бы следующая: 187mod 255 + 95mod 255 = (187+95) mod 255 = 282 mod 255 = 27. Так как 282 больше 255, поделив первое число на второе, получим целочисленный остаток 27.
Для всех полученных в результате сложения чисел находятся соответствия в таблице поле Галуа: 91 251 170 57 125 104 6.
Элементы массива сдвигаются, к нему дописывается ноль (197 133 85 197 0 0 0) и побитово складывается по модулю 2 с членами массива: 158 126 255 252 125 104 6. Этот массив и есть корректирующие байты.
Далее цикл повторяется. Всего в цикле из этого примера должно быть 5 действий.
Побитовое сложение по модулю во многих языках программирования представляется операцией xor (исключающее или). Например, 197+91 будет записано как 197xor91. В битах будет выглядеть как 11000101xor1011011, что в сумме даст 10011110 или 158 в десятичном виде. Результат вычисляется согласно существующим соотношениям:
- 0+0=0;
- 0+1=1;
- 1+0=1;
- 1+1=0.
Этап 5. Объединение блоков данных
По завершению первых четырех этапов получается пара информационных блоков: блок исходных данных и данные коррекции. Они и объединяются в единый байтовый поток. Объединение, аналогично третьему этапу, носит цикличный характер.
Из первого блока берется 1 байт. Затем тоже самое делается во втором блоке. Действия повторяются, пока не закончатся все байты в последовательностях. После того, как взят байт из блока стоящего в самом конце, переходят обратно к первому.
Полученный массив байт выглядит следующим образом:
<первый байт первого БД><первый байт второго БД>…<первый байт n-го БД><второй байт первого БД>…<(m-1)-ый байт первого БД><(m-1)-ый байт n-го БД><m-ый байт k-го БД>…<m-ый байт n-го БД><первый байт первого БК><первый байт второго БК>…<первый байт n-го БК><второй байт первого БК>…<p-ый байт первого БК>…<p-ый байт n-го БК>
В его начале стоят байты исходных данных (БД), а в конце байты коррекции (БК).
Обозначения:
- n – число БД;
- m – число байтов на один БД;
- p – число БК;
- k–это то же n, только за вычетом числа БД имеющих на 1 байт больше.
Этап 6. Размещение байтов данных на матрице QR-кода
QR-матрица имеет обязательные поля и отступ. В них не содержится никакой зашифрованной информации. Эти поля служат для позиционирования и несут в себе данные необходимые для декодирования.

Поисковые узоры и отступ.
Любое QR-изображение имеет три поисковых узора, размерами 8х8 модулей каждый (один модуль – это один черный или белый квадрат), располагаемых в трех его углах (за исключением нижнего право). Поисковые узоры имеют квадратный вид, в центре размещается черный квадрат 3х3 модуля, его окружает белая и черная рамки (шириной в один модуль каждая). С внутренней стороны располагается еще половина белой рамки, так же шириной в 1 модуль. Для наглядности, поисковые узоры отмечены на картинке красным цветом.
Вокруг всей QR-матрицы проходит белая рамка (шириной 4 модуля). Поисковые узоры и рамка необходимы для успешного позиционирования изображения. Эти поля присутствуют на всех QR-кодах.
Выравнивающие узоры
Выравнивающие узоры имеются у всех версий QR-кода, кроме первой. Они служат в качестве дополнительного стабилизатора кода при его дешифрировании. Выравнивающих узоров может быть несколько, равно, как и не быть совсем (у кодов первой версии). Внешне они напоминают поисковый узор, только с размерами 5х5 модулей. Центромузора является единственный черный модуль, окруженный рамками обоих цветов (шириной в 1 модуль).
Полосы синхронизации
Так же имеются у всех версий кода. Эти полосы необходимы, чтобы определить модульный размер при считывании. Всего таких полосы две. Одна полоса находится между левым и правым поисковым узором, вторая между верхним и нижним левыми поисковыми узорами. Полосы синхронизации начинаются с черного цвета, затем цвета чередуются через один. Если на их пути попадаются выравнивающие узоры, то вид узора не меняется, а происходит его наслоение на полосу.
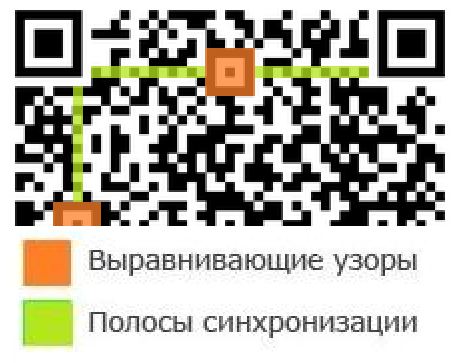
Код маски и уровня коррекции
Эти поля располагаются вдоль всех поисковых узоров. Поле, соприкасающееся с нижним краем верхнего правого узора идентично тому, что соприкасается с правым краем верхнего левого узора. Размеры этих полей 8 модулей. Точно так же идентичны поля соприкасающиеся с правым краем левого нижнего поискового узора и нижним краем левого верхнего узора. У них размеры 7 модулей.
Код версии тоже дублируется. С верхнего края правого поискового узора на левый край правого узора. Причем нижний код представляет собой копию того что снизу, только в зеркальном отображении иперевернутую на 90 градусов влево.
Оставшееся свободное место
Вся остальная поверхность изображения служит для занесения данных. Для этого свободное пространство разделяется на двухмодульные столбики. Начиная с правого нижнего угла матрицы, ее заполняют битами из байтов данных, двигаясь змейкой. Черные модули это единицы, а белые – нули. Первым будет правый нижний модуль, затем модуль слева от него, затем модуль над правым нижним, модуль над левым нижним и так далее, пока не дойдет до самого верха. От нее движение пойдет в обратном порядке – вниз, и затем опять вверх. И так пока не будет заполнено все пространство QR-матрицы.
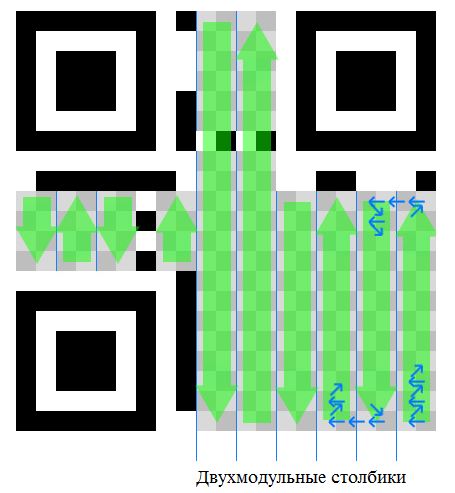
При недостаточности данных, модули заполнятся нулями и останутся белыми (пустыми). На каждый модуль при размещении его на матрицу, накладываетсяодна из 8 масок:
- 0 – (А + В) % 2;
- 1 – В % 2;
- 2 – А % 3;
- 3 – (А + В) % 3;
- 4 – (А/3 + В/2) % 2;
- 5 – (А *В) % 2 + (А*В) % 3;
- 6 – ((А*В) % 2 + (А*В) % 3) % 2;
- 7 — ((А*В) % 3 + (А*В) % 2) % 2;
А обозначает столбец, В – строку, % — остаток от деления, / — целочисленное деление.
Если в результате вычисления выражение получается равным нулю, цвет модуля для которого производилось вычисление, изменяется. То есть, если изначально модуль был белого цвета, и в результате вычислений был получен ноль, то этот модуль станет черного цвета. Аналогично и для модулей с черным цветом.
Для каждого модуля выбирается своя оптимальная маска. Но нередко для упрощения ее делают единой для всех модулей.
Все вышеперечисленные этапы представляют собой алгоритм шифрования QR-кода, менять их последовательность нельзя, так как это приведет к не читаемости кода. Если все этапы пройдены верно, то в результате получается полноценный QR-код.
Читать дальше:

Возможности QR кода
Основные возможности и структура QR-кода, необходимые для корректного шифрования и дешифрирования QR-изображений.

Использование QR-кодов маркетингом
При грамотном использовании QR-код может стать отличным помощником в деле продвижения товара на рынке.

Алгоритм QR-кода
Бывают случаи, когда просто необходимо прочесть QR-код, а телефона с необходимым для прочтения приложением нет. Читаем QR-код самостоятельно.
Последнее обновление: 12/06/2011
Штрихкод совершенствовался многократно. Основной задачей модификаций является увеличение объёма шифруемой информации с уменьшением площади самого кода. Если полосковый штрихкод использует одномерную систему кодирования, то двухмерный расшифровывается в по горизонтали и по вертикали. Перед обычным штрихкодом, у двухмерного есть пара весомых преимуществ: существенно больший объём хранимой информации и возможность восстановления до 30% повреждённых данных.
Наибольшее распространение в настоящее время получили стандарты DataMatrix, изобретённый в 1989 году, и QR-код («QuickResponse», т.е. «Быстрый отклик»),разработанный в 1994 году Японской компанией Denso Wave Inc. Ключевое отличие QR над Data Matrix — умение работать с кана символами японского языка.
Двухмерный код может быть нанесен различными способами — струйной печатью, гравировкой, лазером, электролитическими способами и т.д. В зависимости от метода нанесения, код может оставаться на элементе на протяжении всего его цикла использования.




QR-код

QR код — это разновидность матричного кода (2D-barcode), созданная Японской корпорацией Denso-Wave в 1994 году. «QR» — это сокращение от»Quick Response», «Быстрый отклик», этим названием создатели хотели показать, что QR-код позволяет быстро доносить свое содержание до пользователя. QR коды очень распространены в Японии, там они являются самым популярным видом 2D-кодов.
Уже в начале 2000 года QR-коды получили широкое распространение в Японии и других азиатских странах. Вы можете найти их на визитках,журналах, газетах, листовках, плакатах, досках объявлений, продуктах питания, сайтах и т. д. В Европе и Америке тоже стараются не отставать.
Несмотря на то, что QR коды изначально использовались для учета деталей в машиностроении, сейчас они используются более широко, как для коммерческих систем учета, так и для быстрой доставки информации пользователям мобильных телефонов. QR коды могут хранить контактную информацию, текст, телефонные номера, адреса e-mail и гипертекстовые ссылки. Пользователи с телефоном, оснащенным камерой и с соответствующим программным обеспечением могут сосканировать QR-код,при этом откроется закодированная в QR гиперссылка, или закодированный контакт добавится в адресную книгу. Удобство использования QR-кода очевидно — вместо запоминания длинной ссылки или адреса e-mail достаточно навести камеру телефона на QR-код, и ссылка будет добавлена в избранное.
Емкость QR-кода
На первый взгляд может показаться, что QR-код не способен хранить много информации, и подходит лишь для кодирования коротких строк, например, URL или e-mail. На самом деле емкость QR-кода не так уж мала:
| Только цифры | 7,089 символов |
| Цифры+латинские буквы | 4,296 символов |
Как вы можете увидеть, в QR-коде может быть закодировано более 2 Кб текста, что сильно расширяет спектр его применений, особенно учитывая удобство и скорость доставки информации конечному пользователю.
Коррекция ошибок в QR кодах
QR коды используют алгоритм Рида-Соломона(Reed-Solomon) для коррекции ошибок. Это позволяет без проблем считывать коды, которые каким-то образом повреждены — затерты, перечеркнуты, и т.п. QR коды имеют 4 уровня коррекции ошибок, которые отличаются количеством информации для восстановления и соответственно количеством полезной информации,которую можно восстановить при повреждении кода. Уровни коррекции и соответствующие проценты информации, которые возможно восстановить,следующие:
DataMatrix код

Штрихкод DataMatrix, в свою очередь, на 30-60% меньше по площади, чемQR, содержащий идентичные данные.
DataMatrix — типичный представитель семейства 2D-баркодов, позволяющий закодировать до 3Кб информации. DataMatrix, как и все другие подобные баркоды, содержит информацию для восстановления, которая позволяет восстановить закодированную информацию при частичном повреждении кода.
Каждый код DataMatrix содержит две сплошные пересекающиеся линии в виде буквы L, для ориентации считывающего устройства, две другие границы кода состоят из перемежающихся черных и белых точек и служат для указания размеров кода считывающему устройству.
Особенности DataMatrix кода:
- Стандартизация (принят международный стандарт ISO/IES16022, готовится российский стандарт)
- Большая информационная емкость (более 2000 букв или 3000цифр)
- Высокая скорость распознавания и декодирования
- Низкие требования к качеству поверхности, на которуюнаносится метка
- Распознавание не зависит от фона изображения
- У символа допускается две формы — квадрат и прямоугольник,это облегчает вписывание метки в имеющееся на изделии пространство
Наиболее распространенное применение DataMatrix — это маркировка небольших объектов, например микросхем, поскольку DataMatrix позволяет закодировать 50 символов в изображении размером 2-3 мм2, который может быть считан без проблем. В общем-то размер кода ограничен только технологически, как и в случае любого другого 2D кода, но поскольку DataMatrix — это открытый стандартизованный код, многие компании его используют для своих целей. Этим можно объяснить его широкое распространение.
Коды DataMatrix состоят из модулей, состыкованных друг с другом. Всегос использованием DataMatrix можно закодировать до 3116 символов ASCII.Коды должны содержать четное количество модулей по вертикали и горизонтали. Большинство DataMatrix-ов квадратные, но в целом можно использовать и прямоугольные коды. Все коды используют коррекцию ошибок стандарта ECC200, который, в свою очередь, использует алгоритм Рида-Соломона(Reed-Solomon) для кодирования/декодирования данных. Это позволяет восстановить в случае повреждения кода до 30% полезной информации. DataMatrix коды постепенно становятся привычным явлением на конвертах и посылках. Код может быть быстро прочитан сканером, что позволяет отслеживать корреспонденцию довольно эффективно
В промышленности DataMatrix применяют для маркировки различных элементов.
Microsoft Tag
Microsoft Tag представляет собой двухмерный цветной штрихкод (High Capacity Color Barcode). В отличии от QR и DataMatrix-кодов, этот тип гораздо лучше распознается. Даже расфокусированный код (часто камеры мобильных телефонов без автофокуса) можно прочесть.
Microsoft Tag хранит собственный номер длиной 13 байт + 1 контрольный бит. Программа распознавания отправляет этот номер на сервер, которые выдает хранимую в этом коде информацию.
Плюсы Microsoft Tag, по сравнению с QR и DataMatrix-кодами
- Хранят больше информации на том же физическом размере
- Информацию содержат только небольшие кружочки в центрах треугольников и концы синхронизационных линий. Поэтому возможны Microsoft Tag и с рисунками.
- Можно проследить сколько пользователей «прочли» код (благодаря статистике Live)
Минусы Microsoft Tag, по сравнению с QR и DataMatrix-кодами
- Требуется подключение к интернету (т.к вся информация, зашифрованная в коде, находится на серверах Microsoft Tag)
- Необходимо цветное печатающее устройство (хотя возможно создать и черно-белый код)
Создание своего кода доступно здесь(необходима учетная запись Windows Live).
Скачать программу-распознаватель для мобильных устройств можно тут
Создание своего кода
Создать QR-код с любой текстовой информацией можно несколькими способами:
1) Через онлайн-сервисы
Наиболее простой и удобный способ. Просто заходите на специальный сайт, выбираете тип кода (QR или DataMatrix), выбираете,что будет содержать код (просто текст, адрес интернета, адрес e-mail, визитную карточку, размер кода).
QR и DataMatrix
http://mobilecodes.nokia.com/create.jsp
http://www.tag.cx/ — сразу видны и QR и DataMatrix коды нескольких размеров: легко протестировать, как будут сканироваться
http://www.beetagg.com/en/generator/
Только QR
http://qrcoder.ru — русскоязычный сервис. Очень подробная визитная карточка. Выбор одного из 6-и размеров кода + поддержка русского языка (ввод и распознавание)
http://qrcode.kaywa.com/
Только DataMatrix
http://datamatrix.kaywa.com/
Только Microsoft Tag
http://tag.microsoft.com/ManageAds.aspx
2) Через программы для ПК
Только QR (+Quick Code)
QuickMarkPC [ЛОГИН=stjung ПАРОЛЬ=gabriele] — очень простая программа,бесплатная. Размер ~7,5 Мб
QR и DataMatrix
BatchBarcode Maker v3.50
QRdrawPro
DataMatrixRecognizer
Чтение кода
Расшифровать двухмерный код можно:
1) Через мобильный телефон
Для платформы Symbian 9.x (.sis приложения):
NokiaBarCode Reader (Nokia N79, N82, N93, N93i, N95, E66, E71,E90, 6220 Classic, Nokia N78, 6210 Navigator, N96 и другие)
QuickMarkreader [ЛОГИН и ПАРОЛЬ = 4PDA]
UpCode Reader
i-Nigma Reader
KAYWAReader
TagReader(только MicrosoftTag)
Для платформы JAVA (.jar приложения):
KAYWAReader (только QR)
TagReader (только MicrosoftTag)
Для всех платформ (включая Android, Windows Mobile)
QuickMarkreader [ЛОГИН и ПАРОЛЬ = 4PDA]
BeeTagg QR Reader
2) Через программы на ПК
QuickMarkPC [ЛОГИН и ПАРОЛЬ = 4PDA]
DataMatrixRecognizer
bcTester
Как правильно прочесть код через мобильный телефон?
1) Запустить программу на сотовом.
2) Когда активируется камера, навести ее на двухмерный код. Рекомендуемое расстояние (для небольших кодов) — 15 см!
3) Используя цифровой зум, приблизьте код, чтобы он четко и полностью был виден на дисплее (цифр.зум лучше работает, чем уменьшение расстояния до кода)
4) Программа автоматически распознаст код и выдаст результат
Если не получилось с первого раза — попробуйте еще, меняя расстояние и увеличение до кода
Советы:
1) Сканируйте при хорошем освещении.
2) Не допускайте сильной тряски телефона при сканировании.
3) Располагайте код под углом 90′ к телефону, т.е одной из четырех сторон квадрата (не важно, какой).
4) Старайтесь располагать телефон на одной высоте с кодом.
Как создать хорошо читаемый код?
1) Старайтесь создавать код, не перегружая его лишней информацией(особенно код небольшого размера)
2) Если нужно закодировать много информации — делайте код большего размера.
3) Печатайте код с максимальным качеством — чтобы был наиболее четким(особенно важно для струйных принтеров).
4) Если напечатали код и хотите его вырезать с листа, оставляйте поля -где-то 2 мм с каждой стороны (на qrcoder.ru поля встраиваются автоматически)
5) После создания готового варианта — проверьте его несколькими программами с мобильного.
Источник 1
Источник 2
Источник 3
This article addresses the issue of the use of QR-codes in marketing. The characteristics of QR-codes. Algorithms of creation and reading of QR-codes. An example of changing the appearance of QR-codes and how it used by advertising companies. Positive and negative aspects of using this technology.
Keywords: QR-code, information, coding and decoding of QR-codes, marketing.
С каждым новым этапом становления человеческого общества, информация становится более востребованным и наиболее важным ресурсом. Информация нуждается в защите, для этого информация, чаще всего, подвергается кодировке со стороны отправителя и дешифрации со стороны получателя. QR-код является промежуточным закодированным состоянием информации, которую может расшифровать любой человек, обладающий сканирующим устройством. На QR-код не возлагается обязанность строгой защиты информации, для этого созданы другие технологии (например, электронные ключи, способные использовать сложные математические функции для кодирования информации [3]).
Огромная популярность штрихкода в Японии привела к тому, что объем информации, закодированной в нем, перестал устраивать индустрию. Тогда японцы начали экспериментировать с кодированием небольшого количества информации в одной картинке. Основным достоинством QR-кода стало то, что он быстро и легко считывается при помощи сканирующего оборудования.
QR-код (англ. quickresponse — быстрый отклик) — матричный код, разработанный и предоставленный японской компанией “Denso-Wave” в 1994 году [2].QR-код является двумерным представлением обычного штрихкода, помещаемого практически на любую производимую продукцию».QR» символизирует мгновенный доступ к информации, хранимой в коде [1]. На первый взгляд может показаться, что QR-код не способен вместить в себя большое количество информации, но на самом деле вместимость такого кода достаточно велика и зависит от того, в каком виде информацию в него хотят закодировать.Максимальное число символов, которое можно внести в QR-код (версия 40, 177×177 модулей):
‒ Цифры — 7089;
‒ Цифры и буквы латинского алфавита — 4296;
‒ Иероглифы — 1817;
‒ Двоичный код — 2953 байта (следовательно, около 2953 букв кириллицы в кодировке windows-1251 или 1450 букв кириллицы в utf-8);
«Код должен легко считываться» — это стало главной целью компании-разработчика QR-кода в 1994 году. Действительно, код можно считывать даже в перевернутом состоянии. Такое действие достигается благодаря трем угловым квадратам привязки, расположенным в углах кода. Благодаря им, QR-код правильно разворачивается в памяти программы-сканера [4]. После сканирования программа запускает алгоритм считывания QR-кода:
‒ Распознавание черных и белых областей;
‒ Декодирование формата информации (цифровой, буквенно-цифровой, иероглифы, двоичный код);
‒ Определение версии кода;
‒ Применение маски (с функцией xor, исключающее «или»);
‒ Извлечение данных (и корректировка с использованием корректирующих кодов;
‒ Декодирование информации;
Для воплощения данного алгоритмы было написано множество программ, способных распознать и дешифровать QR-код. Например, для мобильных устройств были созданы такие приложения как QRCodeReader, KaywaReader, UpCode и многие другие. Практически все они находятся в свободном доступе.
Этот же алгоритм можно использовать для декодирования информации вручную, без технических средств. При этом сначала расшифровывают системные зоны кода — уровень коррекции ошибок и используемую маску, и уже потом переходят к декодированию полезной информации. Ручная расшифровка кода не является целесообразной, особенно если версия кода достаточно высокая.
Помимо полезной информации, закодированной в коде, необходимо учитывать коррекцию ошибок. Всего QR-коды имеют 4 уровня коррекции ошибок, которые отличаются количеством информации для восстановления и, соответственно, количеством полезной информации, которую можно восстановить при повреждении кода [5]:
‒ L–уровень коррекции. При его использовании можно восстановить 7 % информации.
‒ M–уровень коррекции. Восстановление 15 % информации.
‒ Q–уровень коррекции. Восстановление 25 % информации.
‒ H–уровень коррекции. Восстановление 30 % информации.
Для исправления ошибок используется алгоритм Рида-Соломона. Данный алгоритм используется как при создании QR-кода, так и при его дешифрации.
Сегодня, когдаQR-кодыдостаточно распространены, их создание занимает очень мало времени и не требует каких-либо специальных знаний.Чтобы создать QR-код, необходимо зайти на один из множества сайтов, позволяющих создавать такие коды. После чего выбрать тип кода (статический или динамический) и в специальное поле ввести информацию, которую вы хотите зашифровать, и сайт выдаст готовыйграфическийQR-код, сканируя который, например, мобильным устройством, адресат получит зашифрованную в коде информацию.
Сайт не позволяет пользователю увидеть, что происходит с информацией и как она становится QR-кодом, но алгоритм шифрования давно известен. QR-код формируется по строго определенному алгоритму, который в упрощенном виде можно разделить на несколько этапов:
- Кодирование данных. Закодировать информацию можно несколькими способами, все зависит от того, какую информацию необходимо внести в QR-код. Если будут использованы только цифры, то используется цифровой формат кодирования, а если будет использован алфавит, то алфавитно-цифровой и т. д. Перед каждым способом кодирования создается пустая последовательность бит, которая потом заполняется.
- Добавление служебной информации. На данной стадии формирования QR-кода определяется уровень коррекции ошибок и версия кода, а также происходит добавление служебных полей, в которых указывается способ кодирования и количество данных.
- Разделение информации на блоки. Полученная на предыдущих этапах последовательность байт разбивается на блоки, количество которых напрямую зависит от версии кода и уровня коррекции ошибок. Сначала определяется количество байт в каждом из блоков, затем идет их последовательное заполнение. Важно, чтобы данные заполнили все блоки.
- Создание байтов коррекции. Данный процесс основан на алгоритме Рида-Соломона и должен быть применен к каждому блоку информации. Сначала определяется количество байтов коррекции, потом, ориентируясь по этим данным, создается многочлен генерации.
- Объединение блоков. Все созданные блоки (блоки данных и блоки коррекции ошибок) необходимо свести в один поток байт. Поочередно из каждого блока берется один байт информации, пока блоки не станут пустыми.
- Размещение информации на QR-коде. Созданная в предыдущем пункте последовательность байт размещается в строгом порядке. При этом QR-код имеет базовые модули и элементы, занимающие определенные места, которые нельзя заполнять созданным потоком. Заполнение QR-кода данными начинается с правого нижнего угла, снизу вверх, бит за битом.
В основном QR-коды используют производственные компании для рекламирования своей продукции. Такая реклама требует меньшего финансирования, но в то же время нацелена на более узкую аудиторию, которая знакома с понятием QR-кода и имеет возможность его прочесть.
Привычное изображение QR-кода представляет собой совокупность маленьких черных и белых квадратов, что не вызывает какого-либо интереса у потенциального клиента. Чтобы добавить своеобразность QR-коду, можно изменить его дизайн. Среди возможных внешних модификаций можно использовать:
‒ Разноцветные квадраты. Можно использовать все цвета радуги для заполнения QR-кода. Не рекомендуется использовать бледно-желтые цвета, если используется белый фон, так как при сканировании код может быть не прочитан, либо прочитан не верно. Использование всей палитры цветов обеспечивает больший интерес к QR-коду у потенциальных покупателейклиентов.
‒ Внедрение картинки или фотографии в код. Относительно большая часть QR-кода может быть закрашена или скрыта за каким-либо рисунком, он остается читаемым. Например, можно разместить на коде фотографию продукта или иллюстрацию к текстовому содержимому QR-кода. Компании могут распространять QR-коды со своими логотипами, благодаря этому клиенты могут понять, от кого исходит то или иное рекламное предложение.
После того, как QR-коды будут напечатаны и распространены, с помощью системы управления QR-кодами можно следить за продуктивностью каждого кода с точностью до одного сканирования [1]. Производитель может получать доступ к различным данным, относящимся к распространенным QR-кодам. Помимо частоты считываний кодов, можно получить число уникальных сканирований, тем самым определить, сколько человек считало код. Более того, можно получить информацию о месте, дате, времени, об используемом устройстве и его операционной системе при каждом сканировании. Определить место, где был прочитан код, можно по IP-адресу оборудования. И хотя местоположение будет определено не точно, этих данных вполне достаточно для анализа и статистики. Все эти данные поступают в режиме реального времени (on-line), то есть каждое новое сканирование отображается в течение нескольких секунд. Такая возможность позволяет всегда иметь актуальную картину QR-маркетинга. По всем собранным и обработанным данным, компания-заказчик может узнать, где ее компания протекает наиболее успешно и усилить распространение своих QR-кодов в этих регионах.
Как и другие технологии, QR-коды имеют свои плюсы и недостатки.
Положительные стороны QR-кода:
‒ Данный код относится к открытым технологиям, то есть технологиям, доступным каждому, потому он и получил быстрое распространение, особенно в среде маркетинга;
‒ По сравнению с обычным штрихкодом, QR-код вмещает в себя намного больше информации и более устойчив к повреждениям графического рисунка (например, часть графического рисунка можно закрасить или вовсе удалить, код останется читаемым);
Недостатки QR-кода:
‒ При использовании QR-кода необходимо быть уверенным, что адресат сможет его прочесть. Для чтения такого кода необходимы гаджеты, умеющие распознавать изображение QR-кода и расшифровывать его;
‒ Вмещает в себя относительно мало информации, например, закодировать целую книгу в один стандартный QR-код не представляется возможным;
‒ QR-код является общедоступной технологией, следовательно, нельзя хранить важную информацию в виде QR-кода, так как код не предоставляет соответствующий уровень защиты информации;
QR-код первой версии имел размеры 21×21 модулей, на данный момент существует код 40 версии с размерами 177×177 модулей. Различия между кодами разных версий заключаются в их размерах и объемах максимальной вместимости. Но развитие QR-кода — не только увеличение числа внутренних модулей. Кроме использования различных цветов и логотипов на QR-коде, его можно развернуть на 45 градусов, что придаст ему некоторую оригинальность. Но самое привлекательное преобразование над кодом — это его анимирование. Картинка становится подвижной, что в наибольшей степени привлекает внимание потенциальных клиентов. Но с использованием анимирования, сфера использования QR-кодов резко уменьшается. Такие коды можно использовать только в интернете и на телевидении [6]. Но прогресс не стоит на месте и развитие QR-кодов так же продолжается.
Литература:
- Электронная книга о QR-кодах. Полное руководство по маркетингу с применением QR-кодов. — [Электронный ресурс]. — http://ru.qr-code-generator.com/qr-code-marketing/qr-codes-basics/. — [дата обращения: 29.04.2016].
- Wikipedia — свободная энциклопедия [Электронный ресурс]. -https://ru.wikipedia.org. — [дата обращения: 29.04.2016].
- Ковалёв А. И. Защита информации с помощью электронных ключей // Информационные технологии и прикладная математика. 2015. № 5. С. 57–65.
- Технология QR-кодов // Технические характеристики QR-кодов. — [Электронный ресурс]. — http://qr-code.creambee.ru/blog/post/qr-specification/. — [дата обращения: 29.04.2016].
- QR-коды. — [Электронный ресурс]. — http://qrcc.ru [дата обращения: 29.04.2016].
- Технология QR-кодов // НестандартныеQR-коды — создание и считывание. — [Электронный ресурс]. — qr-code.creambee.ru/blog/post/cleate-nonstandard-qr-code/. — [дата обращения: 29.04.2016].
Основные термины (генерируются автоматически): информация, код, версия кода, уровень коррекции, уровень коррекции ошибок, данные, полезная информация, графический рисунок, двоичный код, обычный штрихкод.
В отличие от традиционных штрих-кодов, 2D-коды поддерживают комплексную функцию исправления ошибок QR-кода по сравнению с аналогом.
В цифровую эпоху совершение ошибки в бизнес-индустрии может привести к тому, что компании потеряют миллионы прибыли.
Из-за этого маркетологи ищут решение для цифрового маркетинга, которое уменьшает количество ошибок, которые оно совершает, например.особенно при выборе инструмента хранения данных, такого как штрих-коды.
Поскольку сложно определить, какие штрих-коды имеют встроенную систему исправления ошибок, специалисты по QR-коду представляют технологию QR-кода.
Благодаря алгоритму исправления ошибок Ирвинга Рида и Гюстава Соломона Рида-Соломона QR-коды можно сканировать, даже если они загрязнились или изношены.
Из-за этого информация, которую человек хранит в QR-коде, является надежной и полезной в течение длительного времени.
Пока срок действия контента, например URL-адреса, не истекает и не перенаправляется на другой домен, проблем не будет.
Как и в случае любого технологического прогресса, понимание того, как оно работает, становится частью технологического обучения человека.
Если вы хотите узнать больше о том, как работает функция исправления ошибок QR-кода и какой генератор QR-кода лучше всего использовать, вот следующие концепции.

Функция исправления ошибок работает за счет использованияАлгоритм исправления ошибок Рида-Соломона к исходным данным.
Этот алгоритм исправления ошибок работает путем дублирования исходных данных для оптимальной возможности сканирования.
Таким образом, он все еще будет сканироваться, даже еслиQR код испытать разрыв или повреждение из-за экстремальных погодных условий.
До того, как алгоритм исправления ошибок Рида-Соломона использовался для таких технологий, как компакт-диски и DVD-диски.
Этот тип кода измеряет шум связи, создаваемый искусственными спутниками и планетарными зондами. Производители CD и DVD используют этот код для исправления данных на уровне байтов и других пакетных ошибок.
При различных видах разрывов или повреждений возможны следующие уровни исправления ошибок QR-кода. Начиная с уровня L до уровня H.
Уровень L
Это самый низкий уровень скорости исправления ошибок, который может иметь QR-код. Программное обеспечение QR-кода использует этот уровень, если пользователь намеревается создать менее плотное изображение QR-кода.
Уровень L имеет самую высокую скорость исправления ошибок QR-кода примерно семь процентов (7%).
Уровень М
Уровень M — это средний уровень исправления ошибок, который эксперты QR-кода рекомендуют для использования в маркетинге. Из-за этого маркетологи могут корректировать свои QR-коды на среднем уровне. Уровень M имеет самую высокую скорость исправления ошибок примерно пятнадцать процентов (15%).
Уровень Q
Этот уровень является вторым после самого высокого уровня исправления ошибок. Этот уровень исправления ошибок имеет самую высокую скорость исправления ошибок приблизительно двадцать пять процентов (25%).
Уровень Н
Уровень H — это самый высокий уровень исправления ошибок, который может выдержать экстремальный уровень повреждения их QR-кода.
Уровни исправления ошибок уровня Q и H наиболее рекомендуются для промышленных и производственных компаний.
Эти коды могут испытывать экологические и техногенные условия, что приводит к неизбежному повреждению.
Этот уровень имеет самую высокую скорость исправления ошибок примерно тридцать процентов (30%).
Зная эти следующие уровни, вы можете определитьуровень исправления ошибок QR-кода без необходимости запуска программного обеспечения для декодирования.
Эти уровни можно найти, ища следующие знаки на кодах.
Как определить эти уровни исправления ошибок?
Существует четыре различных символа уровня исправления ошибок, которые вы можете увидеть на этих черных и клетчатых полях.
Эти символы позволяют определить, какой тип QR-кода генерирует пользователь.
Эти символы уровня следующие. Вот следующие способы, как их обнаружить.
1. Просмотрите копию своего QR-кода и найдите область исправления ошибок.
Первый шаг, который нужно сделать при просмотре области исправления ошибок, — найти QR-код, который вы можете найти в своей комнате.
Эти коды можно найти в вашей электронике или гаджетах. Как только вы его найдете, посмотрите на нижнюю левую часть кода рядом с нижним глазом.
Эта нижняя левая часть кода рядом с нижним глазом — это область, где вы можете увидеть скорость исправления ошибок.
2. Знайте, какой у него уровень исправления ошибок.
После того, как вы нашли область исправления ошибок, вы можете определить уровень исправления ошибок, взглянув на характер кода.
Если код полностью заштрихован, его уровень равен L.
Когда код заштрихован наполовину внизу, он имеет уровень M. Если он заштрихован наполовину в верхней части, то он имеет скорость исправления ошибок уровня Q.
Наконец, когда код в нижней левой части рядом с нижним глазом не виден, он имеет самый высокий уровень исправления ошибок, уровень H.
3. Протестируйте создание QR-кода и решите, какой генератор QR-кода имеет высокий уровень исправления ошибок.
Лучший способ создать QR-код, который предлагает безопасные и надежные QR-коды, — это найти лучшийГенератор QR-кодакоторый генерирует QR-коды с высоким уровнем исправления ошибок.
Благодаря этому вы гарантируете, что генератор QR-кода, который вы используете, обеспечивает безопасные и надежные QR-коды для вашего личного, промышленного и производственного использования.
Одним из известных генераторов QR-кода, который создает QR-коды с уровнем исправления ошибок уровня H, является QR TIGER.
QR TIGER — это безопасный и надежный генератор QR-кода, в котором вы также можете генерировать креативный дизайн QR-кодаи сделать их более привлекательными по сравнению с традиционными черно-белыми QR-кодами.
Благодаря простому в использовании интерфейсу без рекламы пользователи могут безопасно и легко выполнять генерацию QR-кода.
Преимущества просмотра области исправления ошибок QR-кода
Чтобы узнать цель использования QR-кода
Одним из его преимуществ является знание цели его использования.
Таким образом, люди будут знать, с какой скоростью исправления ошибок предназначен для защиты QR-код.
Благодаря этому они могут определить, предназначен ли этот QR-код для личного, маркетингового или промышленного использования.
Измерьте его устойчивость к повреждениям
Глядя на область исправления ошибок кода, люди могут определить и измерить его устойчивость к любым повреждениям или загрязнениям.
Из-за этого компании и маркетологи могут сэкономить средства, выбрав правильную функцию исправления ошибок, которую они хотят внедрить в свои QR-коды.
Позвольте пользователям экономить деньги
Поскольку компании и маркетологи знают, какую функцию исправления ошибок кода они хотят добавить в свой QR-код, они экономят деньги, которые они тратят на долгосрочную маркетинговую кампанию. Благодаря этому они могут сэкономить деньги и ресурсы на будущее.
Сохраняет окружающую среду
Функция исправления ошибок помогает маркетологам и компаниям экономить деньги и ресурсы. Из-за этого им больше не нужно будет печатать больше QR-кодов, поскольку они могут противостоять любым повреждениям.
Благодаря его использованию они могут сократить использование бумаги и помочь сохранить окружающую среду.
Расскажите людям, как работает исправление ошибок QR-кода.
Если вы любите технологии и хотите поделиться своими знаниями о тривиальных технологиях, таких как QR-коды, использование обнаружения его чуда при исправлении ошибок может помочь просветить людей.
Из-за этого они могут расширить знания других людей об этом и стать экспертом по QR-коду в процессе.
Люди могут понять, какой генератор исправления ошибок QR-кода они хотят использовать при создании этих кодов.
Коррекция ошибок QR-кода — максимально сохраняет и защищает информацию
Сегодня технические специалисты используют для улучшения и улучшения структуры QR-кода, чтобы обеспечить возможность его сканирования. Из-за этого одной из улучшенных функций является возможность исправления ошибок.
Пользователи могутгенерировать бесплатные QR-коды не беспокоясь о каких-либо ошибках сканирования.
Создайте свой QR-код прямо сейчас с помощью QR TIGER — самого передового программного обеспечения для создания QR-кодов с высоким уровнем функции исправления ошибок.
QR TIGER используется такими брендами, как Cartier, Vaynermedia, Hilton и многими другими из-за высокого уровня исправления ошибок.
Это онлайн-генератор QR-кода, который Сертификат ISO 27001 так вы можете быть уверены, что данные ваших QR-кодов надежно защищены.
png_800_75.jpeg)
 Иногда возникают такие ситуации, когда нужно прочитать QR код, а смартфона под рукой нет. Что же делать? В голову приходит лишь попробовать прочитать вручную. Если кто-нибудь сталкивался с такими ситуациями или кому просто интересно как же читается QR код машинами, то данная статья поможет вам разобраться в этой проблеме.
Иногда возникают такие ситуации, когда нужно прочитать QR код, а смартфона под рукой нет. Что же делать? В голову приходит лишь попробовать прочитать вручную. Если кто-нибудь сталкивался с такими ситуациями или кому просто интересно как же читается QR код машинами, то данная статья поможет вам разобраться в этой проблеме.
В статье рассмотрены базовые особенности QR кодов и методика дешифрирования информации без использования вычислительных машин.
Иллюстраций: 14, символов: 8 510.
Для тех, кто не в курсе что такое QR код, есть неплохая статья в английской Wikipedia. Также можно почитать тематический блог на Хабре и несколько хороших статей по смежной тематике, которые можно найти поиском.
Решение задачи непосредственного чтения информации с QR-картинки рассмотрим на примере двух кодов. Информация была закодирована в online-генераторе QR Coder.ru.
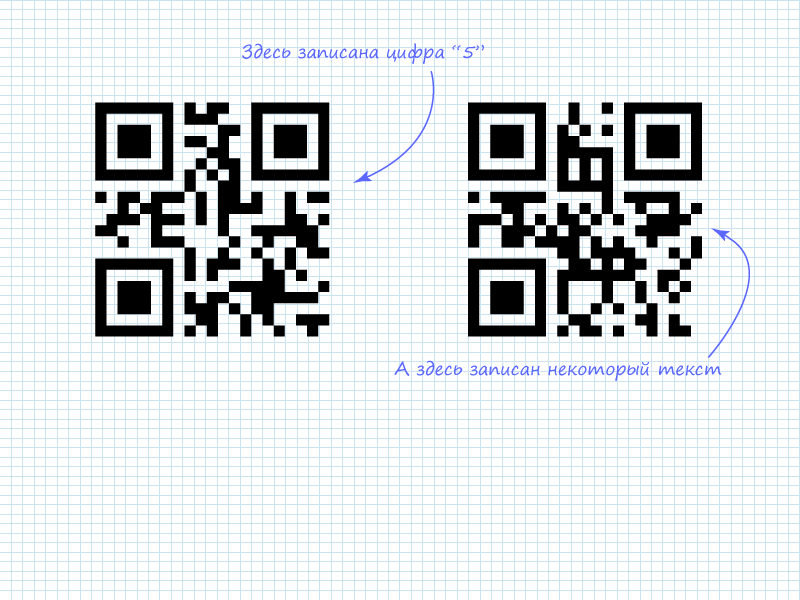
Чтобы понять, как извлечь данные из кода, нужно разобраться в алгоритме. Существует несколько стандартов в семействе QR кодов, с их базовыми принципами можно ознакомиться в спецификациях. Кратко поясню: данные, которые необходимо закодировать, разбиваются на блоки в зависимости от режима кодирования. К разбитым по блокам данным прибавляется заголовок, указывающий на режим и количество блоков. Существуют и такие режимы, в которых используется более сложная структура размещения информации. Данные режимы рассматривать не будем ввиду того, что извлекать вручную из них информацию нецелесообразно. Однако, основываясь на тех принципах, которые описаны ниже, можно адаптироваться и к этим режимам.
На случай некорректного чтения данных, в QR применяются специальные коды, которые способны исправить недочёты при чтении. Это так называемые коды Рида-Соломона. Принцип вычисления кодов, а также исправление ошибок в блоках информации рассматривать не будем, это тема отдельной статьи. Корректирующие ошибки коды Рида-Соломона (RS) записываются после всех информационных данных. Это очень упрощает задачу непосредственного чтения информации: можно просто считать данные, не трогая коды. Как показывает практика, обычно бОльшую часть QR -матрицы занимают корректирующие RS-коды.
По стандарту, данные с RS-кодами перед записью в картинку «перемешиваются». Для этих целей используют специальные маски. Существует 8 алгоритмов, среди которых выбирается наилучший. Критерии выбора основаны на системе штрафов, о которых можно также почитать в спецификации.
«Перемешанные» данные записываются в особой последовательности на шаблонную картинку, куда добавляется техническая информация для декодирующих устройств. Исходя из описанного алгоритма, можно выделить схему извлечения данных из QR кода:

Здесь зелёным фломастером подчёркнуты пункты, которые нужно будет выполнить при непосредственном чтении кода. Остальные пункты можно опустить ввиду того, что считывание производит человек.
Шаг 0. QR код

Взглянув на картинки, можно заметить несколько отчётливых областей. Эти области используются для детектирования QR кода. Эти данные не представляют интереса с точки зрения записанной информации, но их нужно вычеркнуть или просто запомнить их расположение, чтобы они не мешали. Всё остальное поле кода несёт уже полезную информацию. Её можно разбить на две части: системная информация и данные. Также существует информация о версии кода. От версии кода зависит максимальный объём данных, которые могут быть записаны в код. При повышении версии – добавляются специальные блоки, например как здесь:

По ним можно сориентироваться и понять какая версия QR перед вами. Коды высоких версий обычно также нецелесообразно считывать вручную.
Размещение системной информации показано на рисунке:

Системная информация дублируется, что позволяет значительно понизить вероятность возникновения ошибок при детектировании кода и считывании. Системная информация – это 15 бит данных, среди которых первые 5 — это полезная информация, а остальные 10 — это BCH(15,5) код, который позволяет исправлять ошибки в системных данных. К классу BCH кодов относят и RS коды. Обратите внимание, что на рисунке две полоски по 15 бит не пересекаются.
Шаг 1. Чтение 5 бит системной информации
Как уже говорилось, интерес представляют только первые 5 бит. Из которых 2 бита показывают уровень коррекции ошибок, а остальные 3 бита показывают какая маска из доступных 8 применяется к данным. В рассматриваемых QR кодах системная информация содержит:

Шаг 2. Маска для системной информации
Кроме уже озвученных схем защиты системной информации, вдобавок, используется статическая маска, которая применяется к любой системной информации. Она имеет вид: 101010000010010. Так как имеет интерес только первые 5 бит, то маску можно сократить и легко запомнить: 10101 (десять — сто один). После применения операции «исключающего или» (xor) получаем информацию.
Возможные уровни коррекции ошибок:
Возможные маски:
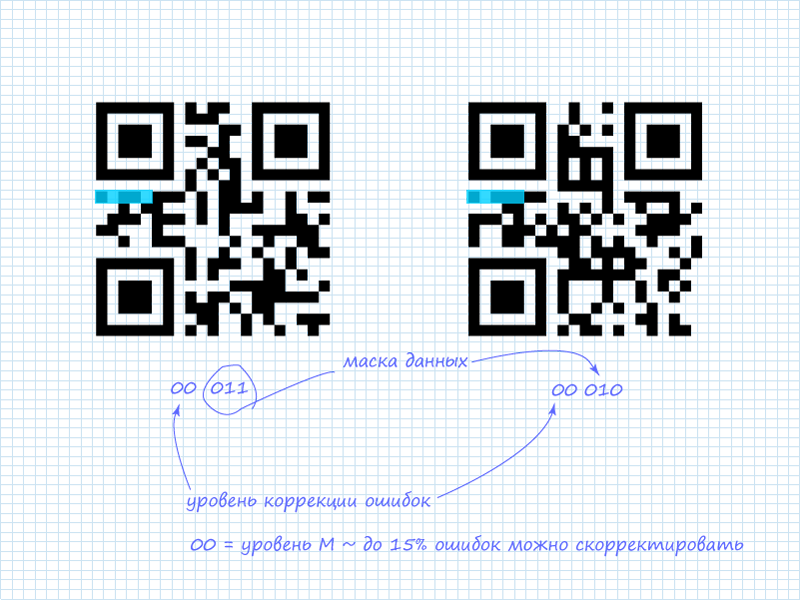
Шаг 3. Чтение заголовка данных
Чтобы понять с какими данными предстоит иметь дело, необходимо изначально прочитать 4-х битный заголовок, который содержит в себе информацию о режиме. Специфика чтения данных изображена на картинке:

Список возможных режимов:
Шаг 4. Применение маски к заголовку
После извлечения 4-х бит, описывающих режим, необходимо к ним применить маску.
В нашем случае для двух кодов используются разные маски. Маска определяется выражением, приведённым в таблице выше. Если данное выражение сводится к TRUE (верное) для бита с координатами (i,j), то бит инвертируется, иначе всё остаётся без изменений. Начало координат в левом верхнем углу (0,0). Взглянув на выражения, можно заметить в них закономерности. Для рассматриваемых QR кодов, маски будут выглядеть так:
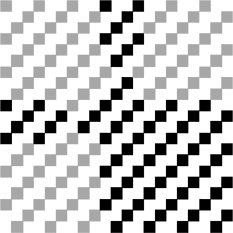

Получим режимы:

Шаг 5. Чтение данных
После получения данных о режиме можно приступать к чтению информации. Надо оговорить, что наиболее интересно считывать числовые и буквенно-числовые данные, так как они легко интерпретируются. Но также не стоит бояться 8-битных. Это может быть также легко интерпретируемая информация. Например, многие онлайн генераторы QR текст кодируют в этом режиме, используя ASCII. Ещё одна причина, почему следует изначально прочитать режим, это то, что от него зависит количество пакетов данных. Которая также зависит и от версии кода. Для версий с первой по девятую длины блоков для более читабельных режимов:
Первый блок после указателя режима — это количество символов. Для числового режима количество закодировано в 10 следующих битах, а для 8-битного режима в 8 битах (прошу прощения за тавтологию).

На рисунке видно, что в левом QR коде, как и отмечалось, записана цифра 5. Это видно по указателю количества символов и последующим после него 4 битам. В числовом режиме наряду с 10-битными блоками используются 4-х битные блоки для экономии места, если в 10-битном объёме нет необходимости. В правом коде зашифровано 4 символа. На данный момент неизвестно что зашифровано в нём. Поэтому необходимо перейти к чтению следующего столбца для извлечения всех 4-х блоков информации.

На рисунке видно, все 4 пакета представляют собой коды ASCII латинских букв, образующие слово «habr»
Естественно наилучшим способом остаётся достать телефон из кармана и, наведя камеру на QR-картинку, считать всю информацию. Однако в экстренных случаях может пригодиться и описанная методика. Конечно, в голове не удержишь все указатели режимов и типов масок, а также ASCII символы, но популярные комбинации запомнить (хотя бы те, что рассмотрены в статье) под силу.
Спецификация:
BS ISO/IEC 18004:2006. Information technology. Automatic identification and data capture techniques. QR Code 2005 bar code symbology specification. London: BSI. 2007. p. 126. ISBN 978-0-580-67368-9.
P.S. Соблюдайте правила ресурса и условия Creative Commons Attribution 3.0 Unported (CC BY 3.0)
P.P.S. Если ошибся блогом, то подскажите куда — перенесу.
Источник Habrahabr
Иногда возникают такие ситуации, когда нужно прочитать QR код, а смартфона под рукой нет. Что же делать? В голову приходит лишь попробовать прочитать вручную. Если кто-нибудь сталкивался с такими ситуациями или кому просто интересно как же читается QR код машинами, то данная статья поможет вам разобраться в этой проблеме.
В статье рассмотрены базовые особенности QR кодов и методика дешифрирования информации без использования вычислительных машин.
Решение задачи непосредственного чтения информации с QR-картинки рассмотрим на примере двух кодов.
Чтобы понять, как извлечь данные из кода, нужно разобраться в алгоритме. Существует несколько стандартов в семействе QR кодов, с их базовыми принципами можно ознакомиться в спецификациях. Кратко поясню: данные, которые необходимо закодировать, разбиваются на блоки в зависимости от режима кодирования. К разбитым по блокам данным прибавляется заголовок, указывающий режим и количество блоков. Существуют и такие режимы, в которых используется более сложная структура размещения информации. Данные режимы рассматривать не будем, в виду того, что извлекать вручную из них информацию нецелесообразно. Однако, основываясь на тех принципах, что описаны ниже, можно адаптироваться и к этим режимам.
На случай некорректного чтения данных в QR применяются специальные коды, которые способны исправить недочёты при чтении. Это так называемые коды Рида-Соломона. Принцип вычисления кодов, а также исправление ошибок в блоках информации рассматривать не будем, это тема отдельной статьи. Корректирующие ошибки коды Рида-Соломона (RS) записываются после всех информационных данных. Это очень упрощает задачу непосредственного чтения информации: можно просто считать данные, не трогая коды. Как показывает практика, обычно бОльшую часть QR -матрицы занимают корректирующие RS-коды.
По стандарту, данные с RS-кодами перед записью в картинку «перемешиваются». Для этих целей используют специальные маски. Существует 8 алгоритмов, среди которых выбирается наилучший. Критерии выбора основаны на системе штрафов, о которых можно также почитать в спецификации.
«Перемешанные» данные записываются в особой последовательности на шаблонную картинку, куда добавляется техническая информация для декодирующих устройств. Исходя из описанного алгоритма, можно выделить схему извлечения данных из QR кода:
Здесь зелёным фломастером подчёркнуты пункты, которые нужно будет реализовать при непосредственном чтении кода. Остальные пункты можно опустить в виду того, что считывание производит человек.
Шаг 0. QR код
Взглянув на картинки, можно заметить несколько отчётливых областей. Эти области используются для детектирования QR кода. Эти данные не представляют интереса с точки зрения записанной информации, но их нужно вычеркнуть или просто запомнить их расположение, чтобы они не мешали. Всё остальное поле кода несёт уже полезную информацию. Её можно разбить на две части: системная информация и данные. Также существует информация о версии кода. От версии кода зависит максимальный объём данных, которые могут быть записаны в код. При повышении версии – добавляются специальные блоки, например как здесь:
По ним можно сориентироваться и понять какая версия QR перед вами. Коды высоких версий обычно также нецелесообразно считывать вручную.
Размещение системной информации показано на рисунке:
Системная информация дублируется, что позволяет значительно понизить вероятность возникновения ошибок при детектировании кода и считывании. Системная информация – это 15 бит данных, среди которых первые 5 — это полезная информация, а остальные 10 – это BCH (15,5) код, который позволяет исправлять ошибки в системных данных. К классу BCH кодов относят и RS коды. Обратите внимание, что на рисунке две полоски по 15 бит не пересекаются.
Шаг 1. Чтение 5 бит системной информации
Как уже говорилось, интерес представляют только первые 5 бит.
Из которых 2 бита показывают уровень коррекции ошибок, а остальные 3 бита показывают какая маска из доступных 8 применяется к данным. В рассматриваемых QR кодах системная информация содержит:
Шаг 2. Маска для системной информации
Кроме уже озвученных схем зашиты системной информации, в добавок, используется статическая маска, которая применяется к любой системной информации.
Она имеет вид: 101010000010010.
Так как имеет интерес только первые 5 бит, то маску можно сократить и легко запомнить: 10101 (десять-сто один).
После применения операции «исключающего или» (xor) получаем информацию.
Возможные уровни коррекции ошибок:
Возможные маски:
| 000 | (i + j) mod 2 = 0 |
| 001 | i mod 2 = 0 |
| 010 | j mod 3 = 0 |
| 011 | (i + j) mod 3 = 0 |
| 100 | ((i div 2) + (j div 3)) mod 2 = 0 |
| 101 | (i j) mod 2 + (i j) mod 3 = 0 |
| 110 | ((i j) mod 2 + (i j) mod 3) mod 2 = 0 |
| 111 | ((i+j) mod 2 + (i j) mod 3) mod 2 = 0 |
Шаг 3. Чтение заголовка данных
Чтобы понять с какими данными предстоит иметь дело, необходимо изначально прочитать 4-х битный заголовок, который содержит в себе информацию о режиме. Специфика чтения данных изображена на картинке:
Список возможных режимов:
| ECI | 0111 |
| Числовые | 0001 |
| Буквенно-числовые | 0010 |
| 8-битный (байтный) | 0100 |
| Kanji | 1000 |
| Структурированное дополнение | 0011 |
| FNC1 | 0101 (1-я позиция) 1001 (2-я позиция) |
Шаг 4. Применение маски к заголовку
После извлечения 4-х бит, описывающих режим, необходимо к ним применить маску.
В нашем случае для двух кодов используются разные маски. Маска определяется выражением, приведённым в таблице выше. Если данное выражение сводится к TRUE (верное) для бита с координатами (i,j), то бит инвертируется, иначе всё остаётся без изменений. Начало координат в левом верхнем углу (0,0). Взглянув на выражения, можно заметить в них закономерности. Для рассматриваемых QR кодов, маски будут выглядеть так:
Получим режимы:
Шаг 5. Чтение данных
После получения данных о режиме можно приступать к чтению информации. Надо оговорить, что наиболее интересно считывать числовые и буквенно-числовые данные, так как они легко интерпретируются. Но также не стоит бояться 8-битных. Это может быть также легко интерпретируемая информация. Например, многие онлайн генераторы QR текст кодируют в этом режиме, используя ASCII. Ещё одна причина, почему следует изначально прочитать режим это то, что от него зависит количество пакетов данных. Которая также зависит и от версии кода. Для версий с первой по девятую длины блоков для более читабельных режимов:
| Числовые | 10 бит / 4 бита |
| Буквенно-числовые | 9 бит |
| 8-битный (байтный) | 8 бит |
Первый блок после указателя режима – это количество символов. Для числового режима количество закодировано в 10 следующих битах, а для 8-битного режима в 8 битах (прошу прощения за тавтологию).
На рисунке видно, что в левом QR коде, как и отмечалось, записана цифра 5. Это видно по указателю количества символов и последующим после него 4 битам. В числовом режиме наряду с 10-битными блоками используются 4-х битные блоки для экономии места, если в 10-битном объёме нет необходимости. В правом коде, зашифровано 4 символа. На данный момент неизвестно, что зашифровано в нём. Поэтому необходимо перейти к чтению следующего столбца для извлечения всех 4-х блок информации.
На рисунке видно, все 4 пакета представляют собой коды ASCII латинских букв, образующие слово «habr»
Естественно наилучшим способом остаётся достать телефон из кармана и, наведя камеру на QR-картинку, считать всю информацию. Однако в экстренных случаях может пригодиться и описанная методика. Конечно, в голове не удержишь все указатели режимов и типов масок, а также ASCII символы, но популярные комбинации запомнить (хотя бы те, что рассмотрены в статье) под силу.
Спецификация:
BS ISO/IEC 18004:2006. Information technology. Automatic identification and data capture techniques. QR Code 2005 bar code symbology specification. London: BSI. 2007. p. 126. ISBN 978-0-580-67368-9.
P.S. Соблюдайте правила ресурса и условия Creative Commons Attribution 3.0 Unported (CC BY 3.0)
О QR коде
Делаем QR код
Генератор QR кода у нас
Генератор QR кода в векторе
Google QR код
Необычный QR код
Читаем QR код
QR сканеры