
Один из механизмов Active Directory (AD), с которым могут быть связаны всевозможные затруднения, это репликация. Репликация – критически важный процесс в работе одного или более доменов или контроллеров домена (DC), и не важно, находятся они на одном сайте или на разных. Неполадки с репликацией могут привести к проблемам с аутентификацией и доступом к сетевым ресурсам. Обновления объектов AD реплицируются на контроллеры домена, чтобы все разделы были синхронизированы. В крупных компаниях использование большого количества доменов и сайтов – обычное дело. Репликация должна происходить внутри локального сайта, так же как дополнительные сайты должны сохранять данные домена и леса между всеми DC.
В этой статье речь пойдет о методах выявления проблем с репликацией в AD. Кроме того, я покажу, как находить и устранять неисправности и работать с четырьмя наиболее распространенными ошибками репликации AD:
- Error 2146893022 (главное конечное имя неверно);
- Error 1908 (не удалось найти контроллер домена);
- Error 8606 (недостаточно атрибутов для создания объекта);
- Error 8453 (доступ к репликации отвергнут).
Вы также узнаете, как анализировать метаданные репликации с помощью таких инструментов, как AD Replication Status Tool, встроенная утилита командной строки RepAdmin.exe и Windows PowerShell.
Для всестороннего рассмотрения я буду использовать лес Contoso, который показан на рисунке. В таблице 1 перечислены роли, IP-адреса и настройки DNS-клиента для компьютеров данного леса.
 |
| Рисунок. Архитектура леса |
Для обнаружения неполадок с репликацией AD запустите AD Replication Status Tool на рабочей станции администратора в корневом домене леса. Например, вы открываете этот инструмент из системы Win8Client, а затем нажимаете кнопку Refresh Replication Status для уверенности в четкой коммуникации со всеми контроллерами домена. В таблице Discovery Missing Domain Controllers на странице Configuration/Scope Settings инструмента можно увидеть два недостающих контроллера домена, как показано на экране 1.
|
|
| Экран 1. Два недостающих контроллера домена |
В таблице Replication Status Collection Details вы можете проследить статус репликации контроллеров домена, которые никуда не пропадали, как показано на экране 2.
|
|
| Экран 2. Статус репликации контроллеров домена |
Пройдя на страницу Replication Status Viewer, вы обнаружите некоторые ошибки в репликации. На экране 3 видно, что возникает немалое число ошибок репликации, возникающих в лесу Contoso. Из пяти контроллеров домена два не могут видеть другие DC, а это означает, что репликация не будет происходить на контроллерах домена, которые не видны. Таким образом, пользователи, подключающиеся к дочерним DC, не будут иметь доступ к самой последней информации, что может привести к проблемам.
|
|
| Экран 3. Ошибки репликации, возникающие в лесу Contoso |
Поскольку ошибки репликации все же возникают, полезно задействовать утилиту командной строки RepAdmin.exe, которая помогает получить отчет о состоянии репликации по всему лесу. Чтобы создать файл, запустите следующую команду из Cmd.exe:
Repadmin /showrel * /csv > ShowRepl.csv
Проблема с двумя DC осталась, соответственно вы увидите два вхождения LDAP error 81 (Server Down) Win32 Err 58 на экране, когда будет выполняться команда. Мы разберемся с этими ошибками чуть позже. А теперь откройте ShowRepl.csv в Excel и выполните следующие шаги:
- Из меню Home щелкните Format as table и выберите один из стилей.
- Удерживая нажатой клавишу Ctrl, щелкните столбцы A (Showrepl_COLUMNS) и G (Transport Type). Правой кнопкой мыши щелкните в этих столбцах и выберите Hide.
- Уменьшите ширину остальных столбцов так, чтобы был виден столбец K (Last Failure Status).
- Для столбца I (Last Failure Time) нажмите стрелку вниз и отмените выбор 0.
- Посмотрите на дату в столбце J (Last Success Time). Это последнее время успешной репликации.
- Посмотрите на ошибки в столбце K (Last Failure Status). Вы увидите те же ошибки, что и в AD Replication Status Tool.
Таким же образом вы можете запустить средство RepAdmin.exe из PowerShell. Для этого сделайте следующее:
1. Перейдите к приглашению PowerShell и введите команду
Repadmin /showrepl * /csv | ConvertFrom-Csv | Out-GridView
2. В появившейся сетке выберите Add Criteria, затем Last Failure Status и нажмите Add.
3. Выберите подчеркнутое слово голубого цвета contains в фильтре и укажите does not equal.
4. Как показано на экране 4, введите 0 в поле, так, чтобы отфильтровывалось все со значением 0 (успех) и отображались только ошибки.
|
|
| Экран 4. Задание фильтра |
Теперь, когда вы знаете, как проверять статус репликации и обнаруживать ошибки, давайте посмотрим, как выявлять и устранять четыре наиболее распространенные неисправности.
Исправление ошибки AD Replication Error -2146893022
Итак, начнем с устранения ошибки -2146893022, возникающей между DC2 и DC1. Из DC1 запустите команду Repadmin для проверки статуса репликации DC2:
Repadmin /showrepl dc2
На экране 5 показаны результаты, свидетельствующие о том, что репликация перестала выполняться, поскольку возникла проблема с DC2: целевое основное имя неверно. Тем не менее, описание ошибки может указать ложный путь, поэтому приготовьтесь копать глубже.
|
|
| Экран 5. Проблема с DC2 — целевое основное имя неверно |
Во-первых, следует определить, есть ли базовое подключение LDAP между системами. Для этого запустите следующую команду из DC2:
Repadmin /bind DC1
На экране 5 видно, что вы получаете сообщение об ошибке LDAP. Далее попробуйте инициировать репликацию AD с DC2 на DC1:
Repadmin /replicate dc2 dc1 «dc=root,dc=contoso,dc=com»
И на этот раз отображается та же ошибка с главным именем, как показано на экране 5. Если открыть окно Event Viewer на DC2, вы увидите событие с Event ID 4 (см. экран 6).
|
|
| Экран 6. Сообщение о событии с Event ID 4 |
Выделенный текст в событии указывает на причину ошибки. Это означает, что пароль учетной записи компьютера DC1 отличается от пароля, который хранится в AD для DC1 в Центре распределения ключей – Key Distribution Center (KDC), который в данном случае запущен на DC2. Значит, следующая наша задача – определить, соответствует ли пароль учетной записи компьютера DC1 тому, что хранится на DC2. В командной строке на DC1 введите две команды:
Repadmin /showobjmeta dc1 «cn=dc1,ou=domain controllers, dc=root,dc=contoso,dc=com» > dc1objmeta1.txt
Repadmin /showobjmeta dc2 «cn=dc1,ou=domain controllers, dc=root,dc=contoso,dc=com» > dc1objmeta2.txt
Далее откройте файлы dc1objmeta1.txt и dc1objmeta2.txt, которые были созданы, и посмотрите на различия версий для dBCSPwd, UnicodePWD, NtPwdHistory, PwdLastSet и lmPwdHistory. В нашем случае файл dc1objmeta1.txt показывает версию 19, тогда как версия в файле dc1objmeta2.txt – 11. Таким образом, сравнивая эти два файла, мы видим, что DC2 содержит информацию о старом пароле для DC1. Операция Kerberos не удалась, потому что DC1 не смог расшифровать билет службы, представленный DC2.
KDC, запущенный на DC2, не может быть использован для Kerberos вместе с DC1, так как DC2 содержит информацию о старом пароле. Чтобы решить эту проблему, вы должны заставить DC2 использовать KDC на DC1, чтобы завершить репликацию. Для этого вам, в первую очередь, необходимо остановить службу KDC на DC2:
Net stop kdc
Теперь требуется начать репликацию корневого раздела Root:
Repadmin /replicate dc2 dc1 «dc=root,dc=contoso,dc=com»
Следующим вашим шагом будет запуск двух команд Repadmin /showobjmeta снова, чтобы убедиться в том, что версии совпадают. Если все хорошо, вы можете перезапустить службу KDC:
Net start kdc
Обнаружение и устранение ошибки AD Replication Error 1908
Теперь, когда мы устранили ошибку -2146893022, давайте перейдем к ошибке репликации AD 1908, где DC1, DC2 и TRDC1 так и не удалось выполнить репликацию из ChildDC1. Решить проблему можно следующим образом. Используйте Nltest.exe для создания файла Netlogon.log, чтобы выявить причину ошибки 1908. Прежде всего, включите расширенную регистрацию на DC1, запустив команду:
Nltest /dbflag:2080fff
Теперь, когда расширенная регистрация включена, запустите репликацию между DC – так все ошибки будут зарегистрированы. Этот шаг поможет запустить три команды для воспроизведения ошибок. Итак, во-первых, запустите следующую команду на DC1:
Repadmin /replicate dc1 childdc1 dc=child,dc=root, dc=contoso,dc=com
Результат, показанный на экране 7, говорит о том, что репликация не состоялась, потому что DC домена не может быть найден.
|
|
| Экран 7. Репликация не состоялась, потому что DC домена не может быть найден |
Во-вторых, из DC1 попробуйте определить местоположение KDC в домене child.root.contoso.com с помощью команды:
Nltest /dsgetdc:child /kdc
Результаты на экране 7 свидетельствуют, что такого домена нет. В-третьих, поскольку вы не можете найти KDC, попытайтесь установить связь с любым DC в дочернем домене, используя команду:
Nltest /dsgetdc:child
В очередной раз результаты говорят о том, что нет такого домена, как показано на экране 7.
Теперь, когда вы воспроизвели все ошибки, просмотрите файл Netlogon.log, созданный в папке C:Windowsdebug. Откройте его в «Блокноте» и найдите запись, которая начинается с DSGetDcName function called. Обратите внимание, что записей с таким вызовом будет несколько. Вам нужно найти запись, имеющую те же параметры, что вы указали в команде Nltest (Dom:child и Flags:KDC). Запись, которую вы ищете, будет выглядеть так:
DSGetDcName function called: client PID=2176, Dom:child Acct:(null) Flags:KDC
Вы должны просмотреть начальную запись, равно как и последующие, в этом потоке. В таблице 2 представлен пример потока 3372. Из этой таблицы следует, что поиск DNS записи KDC SRV в дочернем домене был неудачным. Ошибка 1355 указывает, что заданный домен либо не существует, либо к нему невозможно подключиться.
Поскольку вы пытаетесь подключиться к Child.root.contoso.com, следующий ваш шаг – выполнить для него команду ping из DC1. Скорее всего, вы получите сообщение о том, что хост не найден. Информация из файла Netlogon.log и ping-тест указывают на возможные проблемы в делегировании DNS. Свои подозрения вы можете проверить, сделав тест делегирования DNS. Для этого выполните следующую команду на DC1:
Dcdiag /test:dns /dnsdelegation > Dnstest.txt
На экране 8 показан пример файла Dnstest.txt. Как вы можете заметить, это проблема DNS. Считается, что IP-адрес 192.168.10.1 – адрес для DC1.
|
|
| Экран 8. Пример файла Dnstest.txt |
Чтобы устранить проблему DNS, сделайте следующее:
1. На DC1 откройте консоль управления DNS.
2. Разверните Forward Lookup Zones, разверните root.contoso.com и выберите child.
3. Щелкните правой кнопкой мыши (как в родительской папке) на записи Name Server и выберите пункт Properties.
4. Выберите lamedc1.child.contoso.com и нажмите кнопку Remove.
5. Выберите Add, чтобы можно было добавить дочерний домен сервера DNS в настройки делегирования.
6. В окне Server fully qualified domain name (FQDN) введите правильный сервер childdc1.child.root.contoso.com.
7. В окне IP Addresses of this NS record введите правильный IP-адрес 192.168.10.11.
8. Дважды нажмите кнопку OK.
9. Выберите Yes в диалоговом окне, где спрашивается, хотите ли вы удалить связующую запись (glue record) lamedc1.child.contoso.com [192.168.10.1]. Glue record – это запись DNS для полномочного сервера доменных имен для делегированной зоны.
10. Используйте Nltest.exe для проверки, что вы можете найти KDC в дочернем домене. Примените опцию /force, чтобы кэш Netlogon не использовался:
Nltest /dsgetdc:child /kdc /force
11. Протестируйте репликацию AD из ChildDC1 на DC1 и DC2. Это можно сделать двумя способами. Один из них – выполнить команду
Repadmin /replicate dc1 childdc1 «dc=child,dc=root, dc=contoso,dc=com»
Другой подход заключается в использовании оснастки Active Directory Sites и Services консоли Microsoft Management Console (MMC), в этом случае правой кнопкой мыши щелкните DC и выберите Replicate Now, как показано на экране 9. Вам нужно это сделать для DC1, DC2 и TRDC1.
|
|
| Экран 9. Использование оснастки Active Directory Sites и?Services |
После этого вы увидите диалоговое окно, как показано на экране 10. Не учитывайте его, нажмите OK. Я вкратце расскажу об этой ошибке.
|
|
| Экран 10. Ошибка при репликации |
Когда все шаги выполнены, вернитесь к AD Replication Status Tool и обновите статус репликации на уровне леса. Ошибки 1908 больше быть не должно. Ошибка, которую вы видите, это ошибка 8606 (недостаточно атрибутов для создания объекта), как отмечалось на экране 10. Это следующая трудность, которую нужно преодолеть.
Устранение ошибки AD Replication Error 8606
Устаревший объект (lingering object) – это объект, который присутствует на DC, но был удален на одном или нескольких других DC. Ошибка репликации AD 8606 и ошибка 1988 в событиях Directory Service – хорошие индикаторы устаревших объектов. Важно учитывать, что можно успешно завершить репликацию AD и не регистрировать ошибку с DC, содержащего устаревшие объекты, поскольку репликация основана на изменениях. Если объекты не изменяются, то реплицировать их не нужно. По этой причине, выполняя очистку устаревших объектов, вы допускаете, что они есть у всех DC (а не только DCs logging errors).
Чтобы устранить проблему, в первую очередь убедитесь в наличии ошибки, выполнив следующую команду Repadmin на DC1:
Repadmin /replicate dc1 dc2 «dc=root,dc=contoso,dc=com»
Вы увидите сообщение об ошибке, как показано на экране 11. Кроме того, вы увидите событие с кодом в Event Viewer DC1 (см. экран 12). Обратите внимание, что событие с кодом 1988 только дает отчет о первом устаревшем объекте, который вам вдруг встретился. Обычно таких объектов много.
|
|
| Экран 11. Ошибка из-за наличия устаревшего объекта |
|
|
| Экран 12. Событие с кодом 1988 |
Вы должны скопировать три пункта из информации об ошибке 1988 в событиях: идентификатор globally unique identifier (GUID) устаревшего объекта, сервер-источник (source DC), а также уникальное, или различающееся, имя раздела – distinguished name (DN). Эта информация позволит определить, какой DC имеет данный объект.
Прежде всего, используйте GUID объекта (в данном случае 5ca6ebca-d34c-4f60-b79c-e8bd5af127d8) в следующей команде Repadmin, которая отправляет результаты в файл Objects.txt:
Repadmin /showobjmeta * «e8bd5af127d8>» > Objects.txt
Если вы откроете файл Objects.txt, то увидите, что любой DC, который возвращает метаданные репликации для данного объекта, содержит один или более устаревших объектов. DC, не имеющие копии этого объекта, сообщают статус 8439 (уникальное имя distinguished name, указанное для этой операции репликации, недействительно).
Затем вам нужно, используя GUID объект Directory System Agent (DSA) DC1, идентифицировать все устаревшие объекты в разделе Root на DC2. DSA предоставляет доступ к физическому хранилищу информации каталога, находящейся на жестком диске. В AD DSA – часть процесса Local Security Authority. Для этого выполните команду:
Repadmin /showrepl DC1 > Showrepl.txt
В Showrepl.txt GUID объект DSA DC1 появляется вверху файла и выглядит следующим образом:
DSA object GUID: 70ff33ce-2f41-4bf4-b7ca-7fa71d4ca13e
Ориентируясь на эту информацию, вы можете применить следующую команду, чтобы удостовериться в существовании устаревших объектов на DC2, сравнив его копию раздела Root с разделом Root DC1.
Repadmin /removelingeringobjects DC2 70ff33ce-2f41-4bf4- b7ca-7fa71d4ca13e «dc=root,dc=contoso,dc=com» /Advisory_mode
Далее вы можете просмотреть журнал регистрации событий Directory Service на DC2, чтобы узнать, есть ли еще какие-нибудь устаревшие объекты. Если да, то о каждом будет сообщаться в записи события 1946. Общее число устаревших объектов для проверенного раздела будет отмечено в записи события 1942.
Вы можете удалить устаревшие объекты несколькими способами. Предпочтительно использовать ReplDiag.exe. В качестве альтернативы вы можете выбрать RepAdmin.exe.
Используем ReplDiag.exe. С вашей рабочей станции администратора в корневом домене леса, а в нашем случае это Win8Client, вы должны выполнить следующие команды:
Repldiag /removelingeringobjects Repadmin /replicate dc1 dc2 «dc=root,dc=contoso,dc=com»
Первая команда удаляет объекты. Вторая команда служит для проверки успешного завершения репликации (иными словами, ошибка 8606 больше не регистрируется). Возвращая команды Repadmin /showobjmeta, вы можете убедиться в том, что объект был удален из всех, что объект был удален DC. Если у вас есть контроллер только для чтения read-only domain controller (RODC) и он содержал данный устаревший объект, вы заметите, что он все еще там находится. Дело в том, что текущая версия ReplDiag.exe не удаляет объекты из RODC. Для очистки RODC (в нашем случае, ChildDC2) выполните команду:
Repadmin /removelingeringobjects childdc2.child.root. contoso.com 70ff33ce-2f41-4bf4-b7ca-7fa71d4ca13e «dc=root,dc=contoso,dc=com» /Advisory_mode
После этого просмотрите журнал событий Directory Service на ChildDC2 и найдите событие с кодом 1939. На экране 13 вы видите уведомление о том, что устаревшие объекты были удалены.
|
|
| Экран 13. Сообщение об удалении устаревших объектов |
Используем RepAdmin.exe. Другой способ, позволяющий удалить устаревшие объекты – прибегнуть к помощи RepAdmin.exe. Сначала вы должны удалить устаревшие объекты главных контроллеров домена (reference DC) с помощью кода, который видите в листинге 1. После этого необходимо удалить устаревшие объекты из всех остальных контроллеров домена (устаревшие объекты могут быть показаны или на них могут обнаружиться ссылки на нескольких контроллерах домена, поэтому убедитесь, что вы удалили их все). Необходимые для этой цели команды приведены в листинге 2.
Как видите, использовать ReplDiag.exe гораздо проще, чем RepAdmin.exe, поскольку вводить команд вам придется намного меньше. Ведь чем больше команд, тем больше шансов сделать опечатку, пропустить команду или допустить ошибку в командной строке.
Устранение ошибки AD Replication Error 8453
Предыдущие ошибки репликации AD были связаны с невозможностью найти другие контроллеры домена. Ошибка репликации AD с кодом состояния 8453 возникает, когда контроллер домена видит другие DC, но не может установить с ними связи репликации.
Например, предположим, что ChildDC2 (RODC) в дочернем домене не уведомляет о себе как о сервере глобального каталога – Global Catalog (GC). Для получения статуса ChildDC2 запустите следующие команды на ChildDC2:
Repadmin /showrepl childdc2 > Repl.txt
Данная команда отправляет результаты Repl.txt. Если вы откроете этот текстовый файл, то увидите вверху следующее:
BoulderChildDC2 DSA Options: IS_GC DISABLE_OUTBOUND_REPL IS_RODC WARNING: Not advertising as a global catalog
Если вы внимательно посмотрите на раздел Inbound Neighbors, то увидите, что раздел DC=treeroot,DC=fabrikam,DC=com отсутствует, потому что он не реплицируется. Взгляните на кнопку файла – вы увидите ошибку:
Source: BoulderTRDC1 ******* 1 CONSECTUTIVE FAILURES since 2014-01-12 11:24:30 Last error: 8453 (0x2105): Replication access was denied Naming Context: DC=treeroot,DC=fabrikam,DC=com
Эта ошибка означает, что ChildDC2 не может добавить связь репликации (replication link) для раздела Treeroot. Как показано на экране 14, данная ошибка также записывается в журнал регистрации событий Directory Services на ChildDC2 как событие с кодом 1926.
|
|
| Экран 14. Отсутствие связи репликации |
Здесь вам нужно проверить, нет ли проблем, связанных с безопасностью. Для этого используйте DCDiag.exe:
Dcdiag /test:checksecurityerror
На экране 15 показан фрагмент вывода DCDiag.exe.
|
|
| Экран 15. Фрагмент вывода DCDiag.exe |
Как видите, вы получаете ошибку 8453, потому что группа безопасности Enterprise Read-Only Domain Controllers не имеет разрешения Replicating Directory Changes.
Чтобы решить проблему, вам нужно добавить отсутствующую запись контроля доступа – missing access control entry (ACE) в раздел Treeroot. В этом вам помогут следующие шаги:
1. На TRDC1 откройте оснастку ADSI Edit.
2. Правой кнопкой мыши щелкните DC=treeroot,DC=fabrikam,DC=com и выберите Properties.
3. Выберите вкладку Security.
4. Посмотрите разрешения на этот раздел. Отметьте, что нет записей для группы безопасности Enterprise Read-Only Domain Controllers.
5. Нажмите Add.
6. В окне Enter the object names to select наберите ROOTEnterprise Read-Only Domain Controllers.
7. Нажмите кнопку Check Names, затем выберите OK, если указатель объектов (object picker) разрешает имя.
8. В диалоговом окне Permissions для Enterprise Read-Only Domain Controllers снимите флажки Allow для следующих разрешений
*Read
*Read domain password & lockout policies («Чтение политики блокировки и пароля домена»)
*Read Other domain parameters
9. Выберите флажок Allow для разрешения Replicating Directory Changes, как показано на экране 16. Нажмите OK.
10. Вручную запустите Knowledge Consistency Checker (KCC), чтобы немедленно сделать перерасчет топологии входящей репликации на ChildDC2, выполнив команду
Repadmin /kcc childdc2
|
|
| Экран 16. Включение разрешения Replicating Directory Change |
Данная команда заставляет KCC на каждом целевом сервере DC незамедлительно делать перерасчет топологии входящей репликации, добавляя снова раздел Treeroot.
Состояние репликации критически важно
Репликация во всех отношениях в лесу AD имеет решающее значение. Следует регулярно проводить ее диагностику, чтобы изменения были видны всем контроллерам домена, иначе могут возникать различные проблемы, в том числе связанные с аутентификацией. Проблемы репликации нельзя обнаружить сразу. Поэтому если вы пренебрегаете мониторингом репликации (в крайнем случае, периодически делайте проверку), то рискуете столкнуться с трудностями в самый неподходящий момент. Моей задачей было показать вам, как проверять статус репликации, обнаруживать ошибки и в то же время как справиться с четырьмя типичными проблемами репликации AD.
Листинг 1. Команды для удаления устаревших объектов из Reference DC
REM Команды для удаления устаревших объектов REM из раздела Configuration. Repadmin /removelingeringobjects childdc1.child.root. contoso.com 70ff33ce-2f41-4bf4-b7ca-7fa71d4ca13e «cn=configuration,dc=root,dc=contoso,dc=com» Repadmin /removelingeringobjects childdc1.child.root. contoso.com 3fe45b7f-e6b1-42b1-bcf4-2561c38cc3a6 «cn=configuration,dc=root,dc=contoso,dc=com» Repadmin /removelingeringobjects childdc1.child.root. contoso.com 0b457f73-96a4-429b-ba81-1a3e0f51c848 «cn=configuration,dc=root,dc=contoso,dc=com» REM Команды для удаления устаревших объектов REM из раздела ForestDNSZones. Repadmin /removelingeringobjects childdc1.child.root. contoso.com 70ff33ce-2f41-4bf4-b7ca-7fa71d4ca13e «dc=forestdnszones,dc=root,dc=contoso,dc=com» Repadmin /removelingeringobjects childdc1.child.root. contoso.com 3fe45b7f-e6b1-42b1-bcf4-2561c38cc3a6 «dc=forestdnszones,dc=root,dc=contoso,dc=com» Repadmin /removelingeringobjects childdc1.child. root.contoso.com 0b457f73-96a4-429b-ba81- 1a3e0f51c848 «dc=forestdnszones,dc=root, dc=contoso,dc=com» REM Команды для удаления устаревших объектов REM из раздела домена Root. Repadmin /removelingeringobjects dc1.root. contoso.com 3fe45b7f-e6b1-42b1-bcf4-2561c38cc3a6 «dc=root,dc=contoso,dc=com» REM Команды для удаления устаревших объектов REM из раздела DomainDNSZones. Repadmin /removelingeringobjects dc1.root. contoso.com 3fe45b7f-e6b1-42b1-bcf4-2561c38cc3a6 «dc=root,dc=contoso,dc=com»
Листинг 2. Команды для удаления устаревших объектов из остальных DC
REM Команды для удаления устаревших объектов REM из раздела Configuration. Repadmin /removelingeringobjects dc1.root. contoso.com 0c559ee4-0adc-42a7-8668-e34480f9e604 «cn=configuration,dc=root,dc=contoso,dc=com» Repadmin /removelingeringobjects dc2.root. contoso.com 0c559ee4-0adc-42a7-8668-e34480f9e604 «cn=configuration,dc=root,dc=contoso,dc=com» Repadmin /removelingeringobjects childdc2.child.root. contoso.com 0b457f73-96a4-429b-ba81-1a3e0f51c848 «cn=configuration,dc=root,dc=contoso,dc=com» Repadmin /removelingeringobjects trdc1.treeroot. fabrikam.com 0c559ee4-0adc-42a7-8668-e34480f9e604 «cn=configuration,dc=root,dc=contoso,dc=com» REM Команды для удаления устаревших объектов REM из раздела ForestDNSZones. Repadmin /removelingeringobjects dc1.root.contoso. com 0c559ee4-0adc-42a7-8668-e34480f9e604 «dc=forestdnszones,dc=root,dc=contoso,dc=com» Repadmin /removelingeringobjects dc2.root.contoso. com 0c559ee4-0adc-42a7-8668-e34480f9e604 «dc=forestdnszones,dc=root,dc=contoso,dc=com» Repadmin /removelingeringobjects childdc2.child.root. contoso.com 0b457f73-96a4-429b-ba81-1a3e0f51c848 «dc=forestdnszones,dc=root,dc=contoso,dc=com» Repadmin /removelingeringobjects trdc1.treeroot. fabrikam.com 0c559ee4-0adc-42a7-8668-e34480f9e604 «dc=forestdnszones,dc=root,dc=contoso,dc=com» REM Команды для удаления устаревших объектов REM из раздела DomainDNSZones–Root. Repadmin /removelingeringobjects dc2.child.root. contoso.com 70ff33ce-2f41-4bf4-b7ca-7fa71d4ca13e «dc=domaindnszones,dc=root,dc=contoso,dc=com» REM Команды для удаления устаревших объектов REM из раздела домена Child. Repadmin /removelingeringobjects dc1.root.contoso. com 0c559ee4-0adc-42a7-8668-e34480f9e604 «dc=child,dc=root,dc=contoso,dc=com» Repadmin /removelingeringobjects dc2.root.contoso. com 0c559ee4-0adc-42a7-8668-e34480f9e604 «dc=child,dc=root,dc=contoso,dc=com» Repadmin /removelingeringobjects childdc2.child.root. contoso.com 0b457f73-96a4-429b-ba81-1a3e0f51c848 «dc=child,dc=root,dc=contoso,dc=com» Repadmin /removelingeringobjects trdc1.treeroot. fabrikam.com 0c559ee4-0adc-42a7-8668-e34480f9e604 «dc=child,dc=root,dc=contoso,dc=com» REM Команды для удаления устаревших объектов REM из раздела DomainDNSZones-Child. Repadmin /removelingeringobjects childdc2.child.root. contoso.com 0c559ee4-0adc-42a7-8668-e34480f9e604 «dc=domaindnszones,dc=child,dc=root,dc=contoso,dc=com» REM Команды для удаления устаревших объектов REM из раздела домена TreeRoot. Repadmin /removelingeringobjects childdc1.child.root. contoso.com 0b457f73-96a4-429b-ba81-1a3e0f51c848 «dc=treeroot,dc=fabrikam,dc=com» Repadmin /removelingeringobjects childdc2.child.root. contoso.com 0b457f73-96a4-429b-ba81-1a3e0f51c848 «dc=treeroot,dc=fabrikam,dc=com» Repadmin /removelingeringobjects dc1.root.contoso.com 0b457f73-96a4-429b-ba81-1a3e0f51c848 «dc=treeroot,dc=fabrikam,dc=com» Repadmin /removelingeringobjects dc2.root.contoso.com 0b457f73-96a4-429b-ba81-1a3e0f51c848 «dc=treeroot,dc=fabrikam,dc=com»
Что такое Repadmin?
Repadmin — это cmd-приложение для диагностики проблем с репликацией AD. С помощью Repadmin можно легко просмотреть топологию репликации для каждого контроллера домена и использовать эти знания, чтобы вручную изменить ее и инициировать репликацию между контроллерами. С помощью Repadmin можно легко проверить метаданные репликации и векторы релевантности (up-to-dateness (UTDVEC)).
Repadmin.exe является встроенной функцией в среде Windows Server, начиная с версии 2008. Она поставляется с ролью AD Directory Services, а также может быть настроена в клиентских ОС, таких как Windows 10 с RSAT.
Список команд
Repadmin.exe имеет множество команд, давайте остановимся на самых популярных:
- /syncall – используется для синхронизации определенного DC с другими
- /prp – если у вас есть политика репликации паролей (PRP), эта команда помогает управлять ею
- /queue – показывает текущую очередь репликации
- /replicate – эта команда помогает выполнить репликацию с одного DC на другой
- /replsingleobj – эта команда удобна, если вам нужно реплицировать только один определенный объект между доменными контроллерами
- /replsummary – показывает отчет о текущем состоянии репликации и доступности AD
- /showattr – используется, когда вам нужно просмотреть атрибуты объекта
- /showbackup – этот параметр отображает время последнего резервного копирования
- /showrepl – если вам нужно знать текущее состояние репликации, используйте этот параметр.
Как просмотреть общее состояние репликации
Для того чтобы смотреть состояние репликации у вас она должна быть настроена, как минимум, между двумя доменными контроллерами. Начнем с общего состояния репликации, запустите cmd.exe (start->run->cmd.exe) и введите следующую команду:
repadmin /replsummary
В результате вы увидите все сбои репликации, которые существуют в вашей среде AD.
Как принудительно выполнить репликацию
Предположим, у вас есть сбои в репликации, и вам нужно принудительно выполнить репликацию после устранения сбоя в сети. В командной строке (cmd.exe) с админскими правами на любом DC запустите:
repadmin.exe /syncall /Aped
В дополнение к команде /syncall у нас есть несколько флагов, которые позволят синхронизировать все разделы (/A), использовать push-уведомления для того, чтобы админ мог прервать выполнение команды на каждом этапе (/p), через все сайты Active Directory (/e) используя имена хостов (/d).
Как управлять входящей и исходящей репликацией
Вы можете отключить входящую и/или исходящую репликацию с возможностью повторного включения позже. Для этого выполните следующие команды в командной строке, запущенной под администратором (cmd.exe):
repadmin.exe /options DC01 +DISABLE_INBOUND_REPL
Отключает входящую репликацию на контроллере домена DC01
repadmin.exe /options DC01 +DISABLE_OUTBOUND_REPL
Отключает исходящую репликацию на контроллере домена DC01
repadmin.exe /options DC01 -DISABLE_INBOUND_REPL
Включает входящую репликацию на контроллере домена DC01
repadmin.exe /options DC01 -DISABLE_OUTBOUND_REPL
Включает исходящую репликацию на контроллере домена DC01.
Например, опция отключения исходящей репликации — это хороший способ выполнить обновление схемы без необходимости перестраивать весь лес Active Directory.
191028
Санкт-Петербург
Литейный пр., д. 26, Лит. А
+7 (812) 403-06-99
![]()
700
300
ООО «ИТГЛОБАЛКОМ ЛАБС»
191028
Санкт-Петербург
Литейный пр., д. 26, Лит. А
+7 (812) 403-06-99
![]()
700
300
ООО «ИТГЛОБАЛКОМ ЛАБС»
| description | ms.assetid | title | author | ms.author | manager | ms.date | ms.topic |
|---|---|---|---|---|---|---|---|
|
Learn more about: Troubleshooting Active Directory Replication Problems |
b11f7a65-ec7b-4c11-8dc4-d7cabb54cd94 |
Troubleshooting Active Directory Replication Problems |
iainfoulds |
daveba |
daveba |
05/31/2017 |
article |
Applies to: Windows Server 2022, Windows Server 2019, Windows Server 2016, Windows Server 2012 R2, Windows Server 2012
Try our Virtual Agent — It can help you quickly identify and fix common Active Directory replication issues
Active Directory replication problems can have several different sources. For example, Domain Name System (DNS) problems, networking issues, or security problems can all cause Active Directory replication to fail.
The rest of this topic explains tools and a general methodology to fix Active Directory replication errors. The following subtopics cover symptoms, causes, and how to resolve specific replication errors:
Introduction and resources for troubleshooting Active Directory replication
Inbound or outbound replication failure causes Active Directory objects that represent the replication topology, replication schedule, domain controllers, users, computers, passwords, security groups, group memberships, and Group Policy to be inconsistent between domain controllers. Directory inconsistency and replication failure cause either operational failures or inconsistent results, depending on the domain controller that is contacted for the operation, and can prevent the application of Group Policy and access control permissions. Active Directory Domain Services (AD DS) depends on network connectivity, name resolution, authentication and authorization, the directory database, the replication topology, and the replication engine. When the root cause of a replication problem is not immediately obvious, determining the cause among the many possible causes requires systematic elimination of probable causes.
For a UI-based tool to help monitor replication and diagnose errors, download and run the Microsoft Support and Recovery Assistant tool, or use the Active Directory Replication Status Tool if you only want to analyze the replication status.
For a comprehensive document that describes how you can use the Repadmin tool to troubleshoot Active Directory replication is available; see Monitoring and Troubleshooting Active Directory Replication Using Repadmin.
For information about how Active Directory replication works, see the following technical references:
- Active Directory Replication Model Technical Reference
- Active Director Replication Topology Technical Reference
Event and tool solution recommendations
Ideally, the red (Error) and yellow (Warning) events in the Directory Service event log suggest the specific constraint that is causing replication failure on the source or destination domain controller. If the event message suggests steps for a solution, try the steps that are described in the event. The Repadmin tool and other diagnostic tools also provide information that can help you resolve replication failures.
For detailed information about using Repadmin for troubleshooting replication problems, see Monitoring and Troubleshooting Active Directory Replication Using Repadmin.
Ruling out intentional disruptions or hardware failures
Sometimes replication errors occur because of intentional disruptions. For example, when you troubleshoot Active Directory replication problems, rule out intentional disconnections and hardware failures or upgrades first.
Intentional disconnections
If replication errors are reported by a domain controller that is attempting replication with a domain controller that has been built in a staging site and is currently offline awaiting its deployment in the final production site (a remote site, such as a branch office), you can account for those replication errors. To avoid separating a domain controller from the replication topology for extended periods, which causes continuous errors until the domain controller is reconnected, consider adding such computers initially as member servers and using the install from media (IFM) method to install Active Directory Domain Services (AD DS). You can use the Ntdsutil command-line tool to create installation media that you can store on removable media (CD, DVD, or other media) and ship to the destination site. Then, you can use the installation media to install AD DS on the domain controllers at the site, without the use of replication.
Hardware failures or upgrades</title>
If replication problems occur as a result of hardware failure (for example, failure of a motherboard, disk subsystem, or hard drive), notify the server owner so that the hardware problem can be resolved.
Periodic hardware upgrades can also cause domain controllers to be out of service. Ensure that your server owners have a good system of communicating such outages in advance.
Firewall configuration
By default, Active Directory replication remote procedure calls (RPCs) occur dynamically over an available port through the RPC Endpoint Mapper (RPCSS) on port 135. Make sure that Windows Firewall with Advanced Security and other firewalls are configured properly to allow for replication. For information about specifying the port for Active Directory replication and port settings, see article 224196 in the Microsoft Knowledge Base.
For information about the ports that Active Directory replication uses, see Active Directory Replication Tools and Settings.
For information about managing Active Directory replication over firewalls, see Active Directory Replication over Firewalls.
Responding to failure of an outdated server running Windows 2000 Server
If a domain controller running Windows 2000 Server has failed for longer than the number of days in the tombstone lifetime, the solution is always the same:
- Move the server from the corporate network to a private network.
- Either forcefully remove Active Directory or reinstall the operating system.
- Remove the server metadata from Active Directory so that the server object cannot be revived.
You can use a script to clean up server metadata on most Windows operating systems. For information about using this script, see Remove Active Directory Domain Controller Metadata.
By default, NTDS Settings objects that are deleted are revived automatically for a period of 14 days. Therefore, if you do not remove server metadata (use Ntdsutil or the script mentioned previously to perform metadata cleanup), the server metadata is reinstated in the directory, which prompts replication attempts to occur. In this case, errors will be logged persistently as a result of the inability to replicate with the missing domain controller.
Root causes
If you rule out intentional disconnections, hardware failures, and outdated Windows 2000 domain controllers, the remainder of replication problems almost always have one of the following root causes:
- Network connectivity: The network connection might be unavailable, or network settings are not configured properly.
- Name resolution: DNS misconfigurations are a common cause of replication failures.
- Authentication and authorization: Authentication and authorization problems cause «Access denied» errors when a domain controller tries to connect to its replication partner.
- Directory database (store): The directory database might not be able to process transactions fast enough to keep up with replication time-outs.
- Replication engine: If intersite replication schedules are too short, replication queues might be too large to process in the time that is required by the outbound replication schedule. In this case, replication of some changes can be stalled indefinitely potentially, long enough to exceed the tombstone lifetime.
- Replication topology: Domain controllers must have intersite links in AD DS that map to real wide area network (WAN) or virtual private network (VPN) connections. If you create objects in AD DS for the replication topology that are not supported by the actual site topology of your network, replication that requires the misconfigured topology fails.
General approach to fixing problems
Use the following general approach to fixing replication problems:
-
Monitor replication health daily, or use Repadmin.exe to retrieve replication status daily.
-
Attempt to resolve any reported failure in a timely manner by using the methods that are described in event messages and this guide. If software might be causing the problem, uninstall the software before you continue with other solutions.
-
If the problem that is causing replication to fail cannot be resolved by any known methods, remove AD DS from the server and then reinstall AD DS. For more information about reinstalling AD DS, see Decommissioning a Domain Controller.
-
If AD DS cannot be removed normally while the server is connected to the network, use one of the following methods to resolve the problem:
- Force AD DS removal in Directory Services Restore Mode (DSRM), clean up server metadata, and then reinstall AD DS.
- Reinstall the operating system, and rebuild the domain controller.
For more information about forcing removal of AD DS, see Forcing the Removal of a Domain Controller.
Using Repadmin to retrieve replication status</title>
Replication status is an important way for you to evaluate the status of the directory service. If replication is working without errors, you know the domain controllers that are online. You also know that the following systems and services are working:
- DNS infrastructure
- Kerberos authentication protocol
- Windows Time service (W32time)
- Remote procedure call (RPC)
- Network connectivity
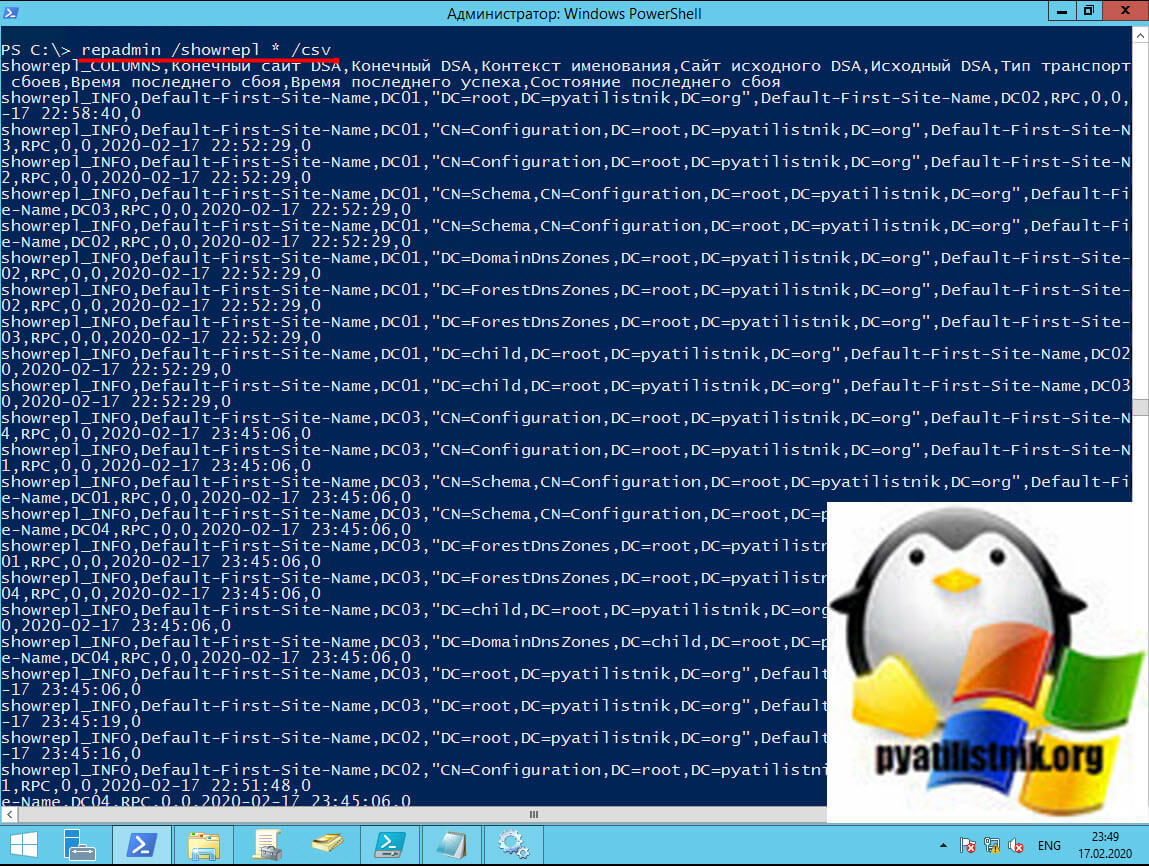
Use Repadmin to monitor replication status daily by running a command that assesses the replication status of all the domain controllers in your forest. The procedure generates a .csv file that you can open in Microsoft Excel and filter for replication failures.
You can use the following procedure to retrieve the replication status of all domain controllers in the forest.
Requirements
Membership in Enterprise Admins, or equivalent, is the minimum required to complete this procedure.
Tools:
- Repadmin.exe
- Excel (Microsoft Office)
To generate a repadmin /showrepl spreadsheet for domain controllers
-
Open a Command Prompt as an administrator: On the Start menu, right-click Command Prompt, and then click Run as administrator. If the User Account Control dialog box appears, provide Enterprise Admins credentials, if required, and then click Continue.
-
At the command prompt, type the following command, and then press ENTER:
repadmin /showrepl * /csv > showrepl.csv -
Open Excel.
-
Click the Office button, click Open, navigate to showrepl.csv, and then click Open.
-
Hide or delete column A as well as the Transport Type column, as follows:
-
Select a column that you want to hide or delete.
- To hide the column, right-click the column, and then click Hide.
- To delete the column, right-click the selected column, and then click Delete.
-
Select row 1 beneath the column heading row. On the View tab, click Freeze Panes, and then click Freeze Top Row.
-
Select the entire spreadsheet. On the Data tab, click Filter.
-
In the Last Success Time column, click the down arrow, and then click Sort Ascending.
-
In the Source DC column, click the filter down arrow, point to Text Filters, and then click Custom Filter.
-
In the Custom AutoFilter dialog box, under Show rows where, click does not contain. In the adjacent text box, type
delto eliminate from view the results for deleted domain controllers. -
Repeat step 11 for the Last Failure Time column, but use the value does not equal, and then type the value 0.
-
Resolve replication failures.
For every domain controller in the forest, the spreadsheet shows the source replication partner, the time that replication last occurred, and the time that the last replication failure occurred for each naming context (directory partition). By using Autofilter in Excel, you can view the replication health for working domain controllers only, failing domain controllers only, or domain controllers that are the least or most current, and you can see the replication partners that are replicating successfully.
Replication problems and resolutions
Replication problems are reported in event messages and in various error messages that occur when an application or service attempts an operation. Ideally, these messages are collected by your monitoring application or when you retrieve replication status.
Most replication problems are identified in the event messages that are logged in the Directory Service event log. Replication problems might also be identified in the form of error messages in the output of the repadmin /showrepl command.
repadmin /showrepl error messages that indicate replication problems
To identify Active Directory replication problems, use the repadmin /showrepl command, as described in the previous section. The following table shows error messages that this command generates, along with the root causes of the errors and links to topics that provide solutions for the errors.
| Repadmin error | Root Cause | Solution |
|---|---|---|
| The time since last replication with this server has exceeded the tombstone lifetime. | A domain controller has failed inbound replication with the named source domain controller long enough for a deletion to have been tombstoned, replicated, and garbage-collected from AD DS. | Event ID 2042: It has been too long since this machine replicated |
| No inbound neighbors. | If no items appear in the «Inbound Neighbors» section of the output that is generated by repadmin /showrepl, the domain controller was not able to establish replication links with another domain controller. | Fixing Replication Connectivity Problems (Event ID 1925) |
| Access is denied. | A replication link exists between two domain controllers, but replication cannot be performed properly as a result of an authentication failure. | Fixing Replication Security Problems |
| Last attempt at <date — time> failed with the «Target account name is incorrect.» | This problem can be related to connectivity, DNS, or authentication issues. If this is a DNS error, the local domain controller could not resolve the globally unique identifier (GUID)-based DNS name of its replication partner. | Fixing Replication DNS Lookup Problems (Event IDs 1925, 2087, 2088) Fixing Replication Security Problems Fixing Replication Connectivity Problems (Event ID 1925) |
| LDAP Error 49. | The domain controller computer account might not be synchronized with the Key Distribution Center (KDC). | Fixing Replication Security Problems |
| Cannot open LDAP connection to local host | The administration tool could not contact AD DS. | Fixing Replication DNS Lookup Problems (Event IDs 1925, 2087, 2088) |
| Active Directory replication has been preempted. | The progress of inbound replication was interrupted by a higher-priority replication request, such as a request that was generated manually with the repadmin /sync command. | Wait for replication to complete. This informational message indicates normal operation. |
| Replication posted, waiting. | The domain controller posted a replication request and is waiting for an answer. Replication is in progress from this source. | Wait for replication to complete. This informational message indicates normal operation. |
The following table lists common events that might indicate problems with Active Directory replication, along with root causes of the problems and links to topics that provide solutions for the problems.
| Event ID and source | Root cause | Solution |
|---|---|---|
| 1311 NTDS KCC | The replication configuration information in AD DS does not accurately reflect the physical topology of the network. | Fixing Replication Topology Problems (Event ID 1311) |
| 1388 NTDS Replication | Strict replication consistency is not in effect, and a lingering object has been replicated to the domain controller. | Fixing Replication Lingering Object Problems (Event IDs 1388, 1988, 2042) |
| 1925 NTDS KCC | The attempt to establish a replication link for a writable directory partition failed. This event can have different causes, depending on the error. | Fixing Replication Connectivity Problems (Event ID 1925) Fixing Replication DNS Lookup Problems (Event IDs 1925, 2087, 2088) |
| 1988 NTDS Replication | The local domain controller has attempted to replicate an object from a source domain controller that is not present on the local domain controller because it may have been deleted and already garbage-collected. Replication does not proceed for this directory partition with this partner until the situation is resolved. | Fixing Replication Lingering Object Problems (Event IDs 1388, 1988, 2042) |
| 2042 NTDS Replication | Replication has not occurred with this partner for a tombstone lifetime, and replication cannot proceed. | Fixing Replication Lingering Object Problems (Event IDs 1388, 1988, 2042) |
| 2087 NTDS Replication | AD DS could not resolve the DNS host name of the source domain controller to an IP address, and replication failed. | Fixing Replication DNS Lookup Problems (Event IDs 1925, 2087, 2088) |
| 2088 NTDS Replication | AD DS could not resolve the DNS host name of the source domain controller to an IP address, but replication succeeded. | Fixing Replication DNS Lookup Problems (Event IDs 1925, 2087, 2088) |
| 5805 Net Logon | A machine account failed to authenticate, which is usually caused by either multiple instances of the same computer name or the computer name not replicating to every domain controller. | Fixing Replication Security Problems |
For more information about replication concepts, see Active Directory Replication Technologies.
Next steps
For more information, including support articles specific to error codes see the support article: How to troubleshoot common Active Directory replication errors
Обновлено 04.05.2022
![]() Добрый день! Уважаемые читатели и гости одного из лучших IT блогов Pyatilistnik.org. Не так давно я вам подробно рассказывал из каких компонентов и служб состоит Active Directory. Сегодня я хочу дополнить данную публикацию и подробно рассказать про утилиту командной строки Repadmin, благодаря ей я вас научу диагностировать репликацию между контроллерами домена, покажу как находить и решать проблемы в вашей доменной инфраструктуре. Каждый системный администратор, просто обязан ее знать и уметь ей пользоваться, если вы еще не из их числа, то давайте это исправлять.
Добрый день! Уважаемые читатели и гости одного из лучших IT блогов Pyatilistnik.org. Не так давно я вам подробно рассказывал из каких компонентов и служб состоит Active Directory. Сегодня я хочу дополнить данную публикацию и подробно рассказать про утилиту командной строки Repadmin, благодаря ей я вас научу диагностировать репликацию между контроллерами домена, покажу как находить и решать проблемы в вашей доменной инфраструктуре. Каждый системный администратор, просто обязан ее знать и уметь ей пользоваться, если вы еще не из их числа, то давайте это исправлять.
Что такое Repadmin?
Если вы работаете с несколькими доменами Active Directory или сайтами AD, то вы обязательно столкнетесь с проблемами в какой-то момент, особенно в процессе репликации. Репликация, это самый важный жизненный цикл в доменных службах. Эта репликация важна, так как ее отсутствие может вызвать проблемы с аутентификацией. В свою очередь, это может создать проблемы с доступом к ресурсам в сети. Компания Microsoft это понимает, как никто другой и создала для этих задач отдельную утилиту Repadmin.
Repadmin — это инструмент командной строки, для диагностики и устранения проблем репликации Active Directory. Repadmin можно использовать для просмотра топологии репликации с точки зрения каждого контроллера домена. Кроме того, вы можете использовать Repadmin, чтобы вручную создать топологию репликации, инициировать события репликации между контроллерами домена и просматривать метаданные репликации и векторы актуальности (UTDVEC). Вы также можете использовать Repadmin.exe для мониторинга относительной работоспособности леса доменных служб Active Directory (AD DS).
Как установить Repadmin?
Repadmin.exe встроен в Windows Server 2008 и выше, вы легко найдете его и на Windows Server 2019. Он доступен, если у вас установлена роль AD DS или сервера AD LDS. Он также доступен в клиентских ОС, таких как Windows 10, если вы устанавливаете инструменты доменных служб Active Directory, которые являются частью средств удаленного администрирования сервера (RSAT).
Требования для использования Repadmin
использование Repadmin требует учетных данных администратора на каждом контроллере домена, на который нацелена команда. Члены группы «Администраторы домена» имеют достаточные разрешения для запуска repadmin на контроллерах домена в этом домене. Члены группы «Администраторы предприятия» по умолчанию имеют права в каждом домене леса. Если вы запустите утилиту без необходимых прав, то вы получите сообщение:
Ошибка функции DsBindWithCred для компьютера, состояние ошибки 1753 (0x6d9):
В системе отображения конечных точек не осталось доступных конечных точек.
Вы также можете делегировать конкретные разрешения, необходимые для просмотра и управления состоянием репликации.
Основные ключи Repadmin
Запустите командную строку от имени администратора или откройте PowerShell в режиме администратора и выполните команду:
В результате вы получите справку по утилите.
Теперь опишу вам за что отвечает каждый ключ:
- /kcc — Принудительно проверяет согласованность (Knowledge Consistency Checker (KCC)) на целевых контроллерах домена, чтобы немедленно пересчитать топологию входящей репликации.
- /prp — Можно просматривать и изменять политику репликации паролей (PRP) для контроллеров домена только для чтения (RODC).
- /queue — Отображает запросы входящей репликации, которые необходимо обработать контроллеру домена, чтобы получить последние данные от партнеров по репликации, у которых более свежие данные.
- /replicate — Запускает немедленную репликацию указанного раздела каталога на целевой контроллер домена с исходного контроллера домена.
- /replsingleobj — Реплицирует один (отдельный) объект между любыми двумя контроллерами домена, которые имеют общие разделы каталога.
- /replsummary — Операция replsummary быстро и кратко обобщает состояние репликации и относительную работоспособность леса. Определяет контроллеры домена, которые не выполняют входящую или исходящую репликацию, и суммирует результаты в отчете.
- /rodcpwdrepl — Запускает репликацию паролей для заданных пользователей с источника (контроллера домена концентратора) на один или более доступных только для чтения контроллер домена.
- /showattr — Отображает атрибуты объекта.
- /showobjmeta — Отображает метаданные репликации для указанного объекта, хранящиеся в Active Directory, например, идентификатор атрибута, номер версии, исходящий и локальный USN, а также глобальный уникальный идентификатор GUID исходящего сервера (сервера-отправителя) и метку даты и времени.
- /showrepl — Отображает состояние репликации, когда указанный контроллер домена последний раз пытался выполнить входящую репликацию разделов Active Directory.
- /showutdvec — Отображает наибольший поддерживаемый последовательный номер обновления (USN), который в указанной копии контроллера домена Active Directory показан как поддерживаемый для этой копии и транзитивных партнеров.
- /syncall Синхронизирует указанный контроллер домена со всеми партнерами репликации.
Дополнительные параметры
- /u: — Указание домена и имени пользователя с обратной косой чертой в качестве разделителя {доменпользователь}, у которого имеются разрешения на выполнение операций Active Directory. UPN-вход не поддерживается.
- /pw:— Задание пароля для пользователя, указанного в параметре /u.
- /retry — Этот параметр вызывает повтор попытки создать привязку к конечному контроллеру домена, когда при первой попытке произошел сбой с одним из следующих состояний ошибки ( 1722 0x6ba : «Сервер RPC недоступен» или 1753 / 0x6d9 : «Отсутствуют конечные точки, доступные из сопоставителя конечных точек»)
- /csv — Применяется с параметром /showrepl для вывода результатов в формате значений, разделенных запятыми (CSV).
Просмотр общего состояния репликации
Эта команда быстро покажет вам общее состояние репликации.
В результате вы увидите присутствуют ли у вас сбои при репликации. временные дельты, количество ошибок. Вы можете заметите, что отчет разделен на два основных раздела — DSA-источник и DSA-адресат.
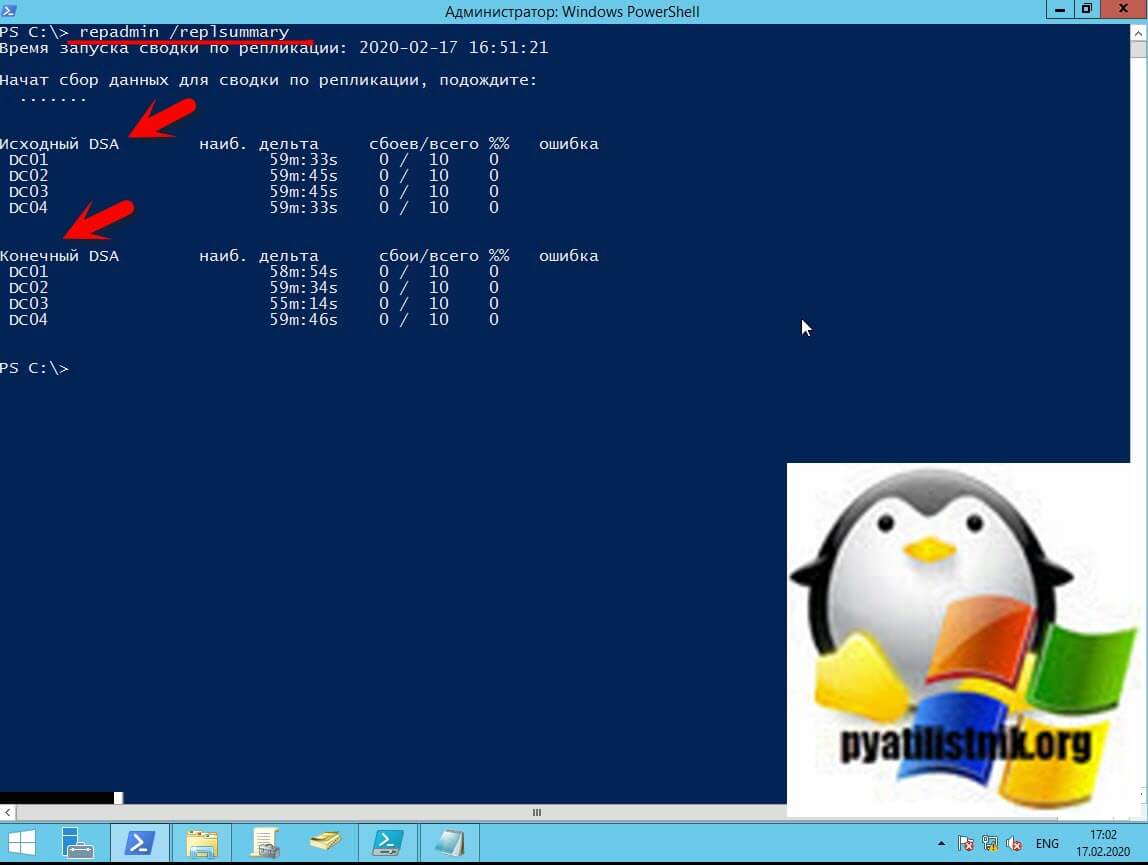
Обратите внимание, что одни и те же серверы перечислены в обоих разделах. Причина этого заключается в том, что Active Directory использует модель с несколькими основными доменами. Другими словами, обновления Active Directory могут быть записаны на любой контроллер домена (с заметными исключениями контроллеры домена только для чтения). Эти обновления затем реплицируются на другие контроллеры домена в домене. По этой причине вы видите одинаковые контроллеры домена в списке как DSA-источника, так и получателя. Если бы мой домен содержал какие-либо контроллеры домена только для чтения, они были бы перечислены только в разделе DSA назначения.
Сводный отчет о репликации не просто перечисляет контроллеры домена, в нем также перечислены самые большие дельты репликации. Вы также можете просмотреть общее количество попыток репликации, которые были недавно предприняты, а также количество неудачных попыток и увидеть процент попыток, которые привели к ошибке.
repadmin /replsummary /bysrc
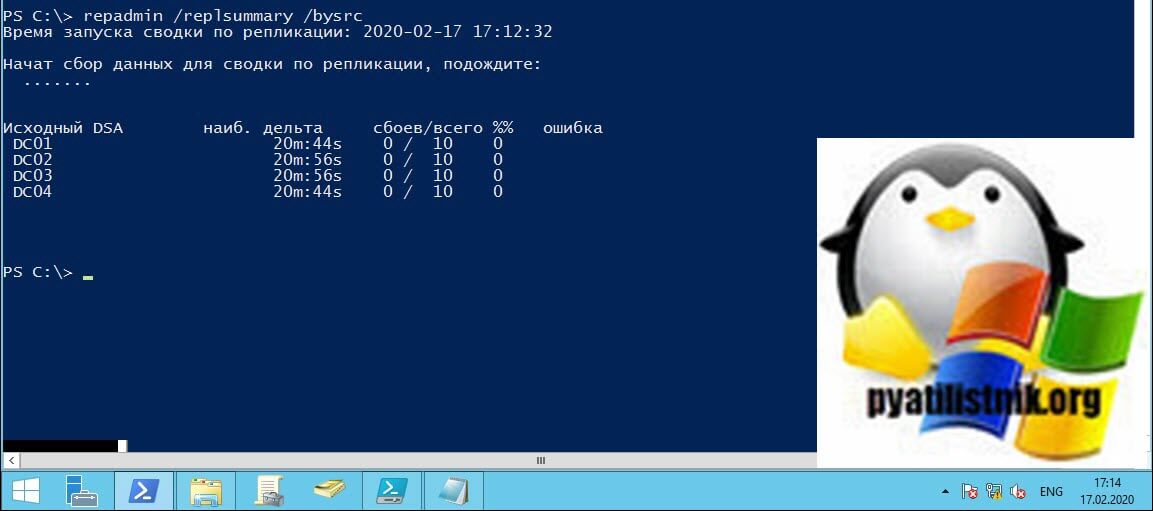
Ключ /bysrc — Суммирует состояние репликации для всех контроллеров домена, на которые реплицирует данный исходный контроллер домена. В отчете вы получите данные только по исходному DSA.
repadmin /replsummary /bydest
Ключ /bydest — Суммирует состояние репликации для всех контроллеров домена, с которых реплицирует данный целевой контроллер домена. Отображает только конечный DSA.
Ключ /sort — Сортирует выходные данные по столбцам.
- delta: сортирует результаты в соответствии с наименьшим значением дельта для каждого контроллера домена источника или назначения.
- partners: сортирует список результатов по количеству партнеров по репликации для каждого контроллера домена.
- failures: сортирует список результатов по количеству сбоев репликации партнеров для каждого контроллера домена.
- error: сортирует список результатов по последнему результату репликации (коду ошибки), который блокирует репликацию для каждого контроллера домена. Это поможет вам устранить причину сбоя для контроллеров домена, которые выходят из строя с общими ошибками.
- percent: сортирует список результатов по проценту ошибок репликации партнера для каждого контроллера домена. (Это рассчитывается путем деления количества отказов на общее количество попыток, а затем умножения на 100; то есть отказы/общее число попыток *100.) Это поможет вам расставить приоритеты в работе по устранению неполадок путем определения контроллеров домена, которые испытывают самую высокую частота ошибок репликации.
- unresponsive: сортирует список результатов по именам партнеров, которые не отвечают на запросы репликации для каждого контроллера домена.
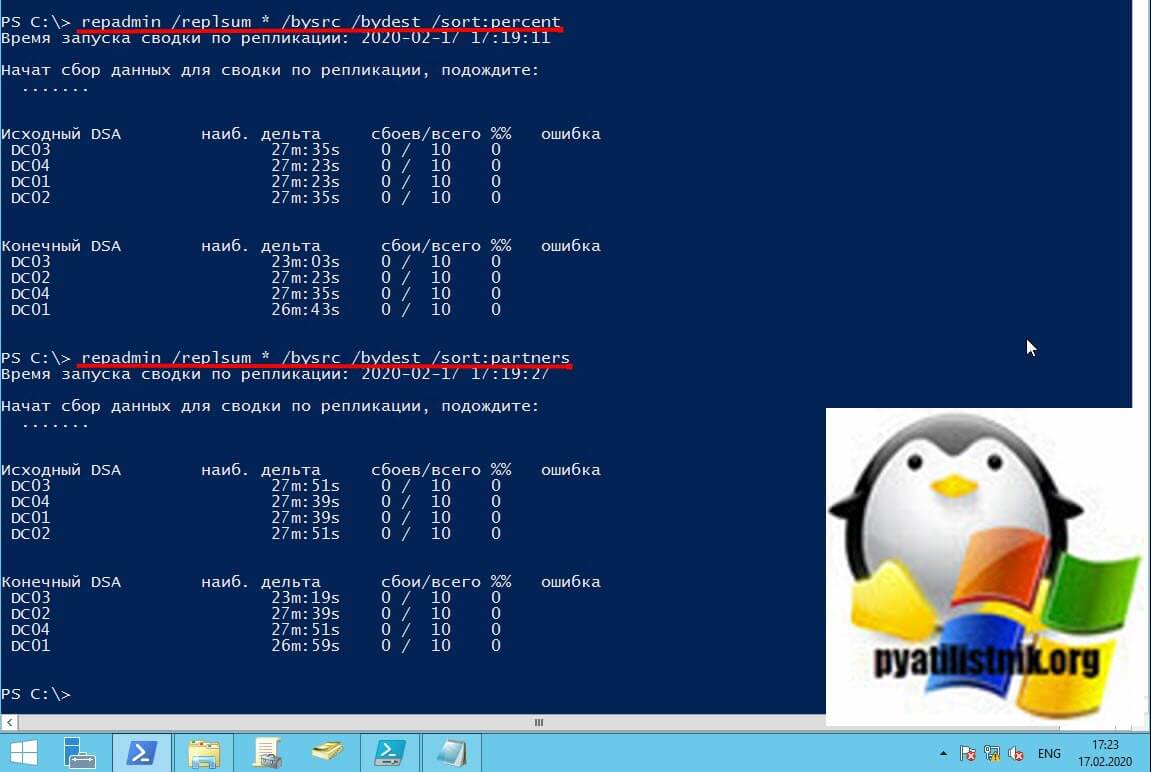
Пример применения дополнительных ключей
repadmin /replsummary /bysrc /bydest /sort:delta
Вы можете указать параметры /bysrc и /bydest одновременно. В этом случае Repadmin сначала отображает таблицу параметров /bysrc, а затем таблицу параметров /bydest. Если оба параметра / bysrc и /bydest отсутствуют, то Repadmin отображает параметр с наименьшим количеством ошибок партнеров.
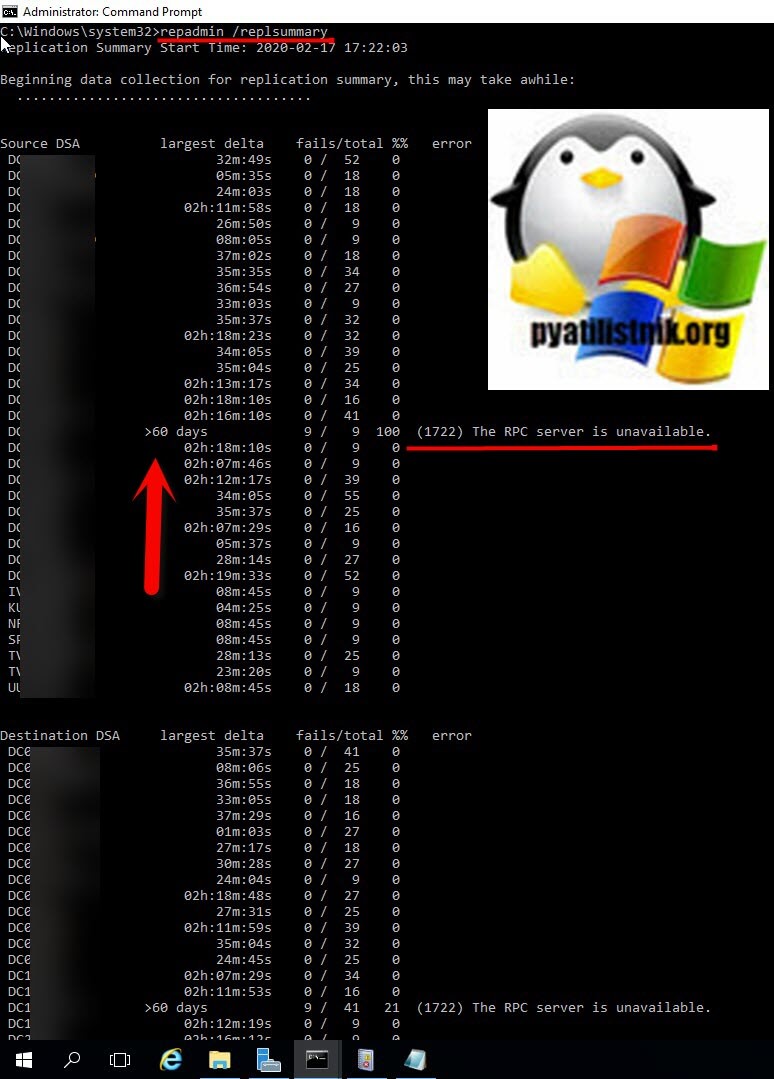
Вот пример ошибки «1722: The RPC server is unavailable», которую может показать repadmin с ключом replsummary.
Просмотр топологии репликации и ошибки
Команда repadmin /showrepl помогает понять топологию и ошибки репликации. Он сообщает, о состоянии каждого исходного контроллера домена, с которого у получателя есть объект входящего соединения. Отчет о состоянии делится на разделы каталога.
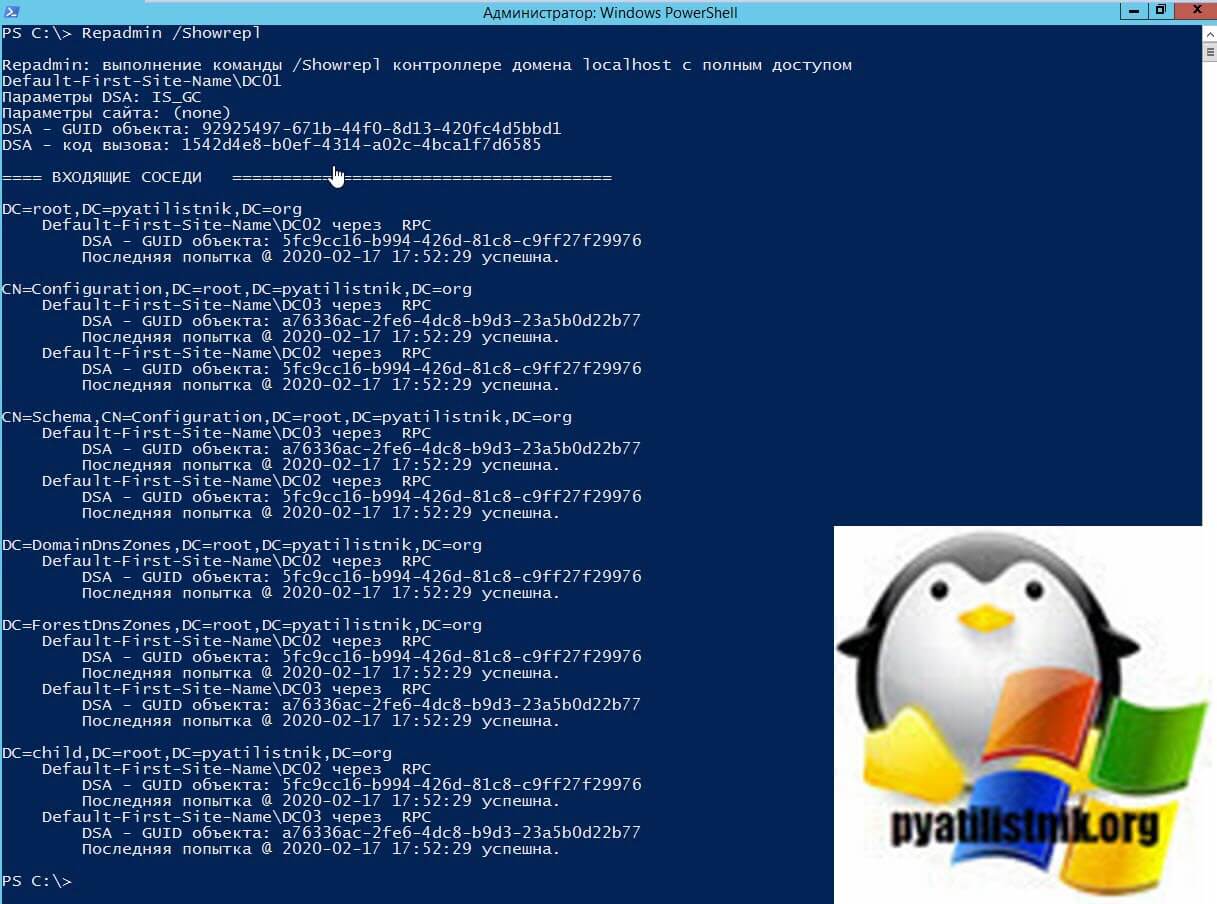
Административная рабочая станция, на которой вы запускаете Repadmin, должна иметь сетевое подключение удаленного вызова процедур (RPC) ко всем контроллерам домена, на которые нацелен параметр DSA_LIST. Ошибки репликации могут быть вызваны исходным контроллером домена, контроллером домена назначения или любым компонентом процесса репликации, включая базовую сеть.
Команда отображает GUID каждого объекта, который был первоначально реплицирован, а также результат репликации. Это полезно, чтобы обнаружить возможные проблемы. Как видите в моем примере, все репликации успешно пройдены. Если хотите получить максимально подробную информацию, о топологии репликации, то добавьте ключ «*».
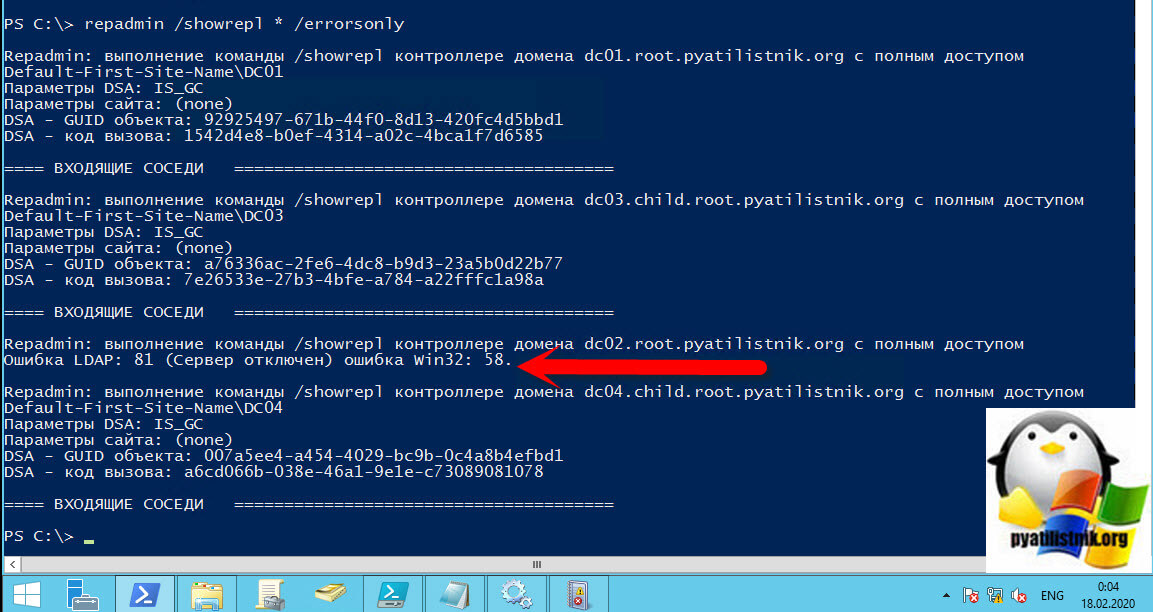
В моем примере вы можете увидеть ошибку:
Repadmin: выполнение команды /Showrepl контроллере домена dc03.child.root.pyatilistnik.org с полным доступом
Ошибка LDAP: 82 (Локальная ошибка) ошибка Win32: 8341. (The target principal name is incorrect)
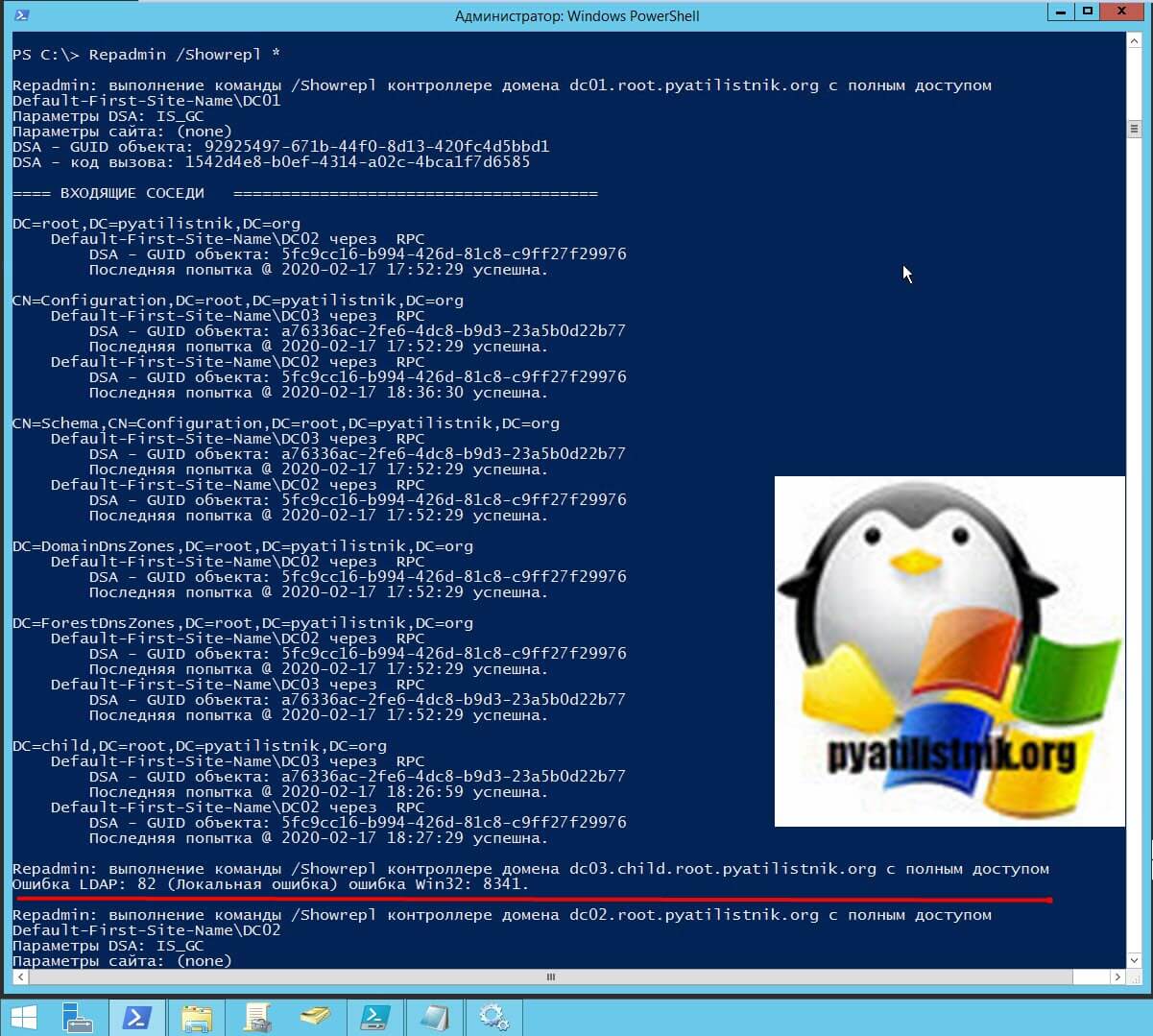
В приведенном выше примере решение проблемы заключается в остановке службы «Центр распространения ключей Kerberos (Kerberos key distribution center)«. Запустите ее. В редких случаях может потребоваться перезапустить службу «Доменные службы Active Directory«. Затем перезапустите процесс репликации через сайты и службы Active Directory. Проверьте свои журналы, и репликация должна быть успешной. Так же вы можете использовать и дополнительные ключи:
- DSA_LIST — Задает имя хоста контроллера домена или списка контроллеров домена, разделенных в списке одним пробелом.
- Source DSA object GUID — GUID исходного объекта DSA. Указывает уникальное шестнадцатеричное число, которое идентифицирует объект, чьи события репликации перечислены.
- Naming Context (Контекст именования) — Определяет отличительное имя раздела каталога для репликации.
- /verbose — Отображает дополнительную информацию об исходных партнерах, от которых контроллер домена назначения выполняет входящую репликацию. Информация включает в себя полностью уточненное CNAME, идентификатор вызова, флаги репликации и значения порядкового номера обновления (USN) для исходных обновлений и реплицированных обновлений.
- /NoCache — Указывает, что глобально уникальные идентификаторы (GUID) остаются в шестнадцатеричной форме. По умолчанию GUID переводятся в строки.
- /repsto — Перечисляет контроллеры домена-партнера, с которыми целевые контроллеры домена используют уведомление об изменении для выполнения исходящей репликации. (Контроллеры домена-партнера в этом случае являются контроллерами домена на том же сайте Active Directory, что и исходный контроллер домена, и контроллеры домена, которые находятся на удаленных сайтах, на которых включено уведомление об изменениях.) Этот список добавляется в разделе СОБСТВЕННЫЕ СОСЕДИ ДЛЯ УВЕДОМЛЕНИЙ ОБ ИЗМЕНЕНИЯХ (OUTBOUND NEIGHBORS FOR CHANGE NOTIFICATIONS ).
- /conn — Добавляет раздел KCC CONNECTION OBJECTS в Repadmin, в котором перечислены все соединения и причины их создания.
- /all — Запускается как /repsto и Conn параметры.
- /errorsonly — Отображает состояние репликации только для исходных контроллеров домена, с которыми конечный контроллер домена сталкивается с ошибками репликации.
- /intersite — Отображает состояние репликации для подключений от контроллеров домена на удаленных сайтах, с которых контроллер домена, указан в параметре DSA_LIST, выполняет входящую репликацию.
- /CSV — Экспорт или вывод результатов в формате с разделителями-запятыми (CSV).
Просмотр очереди репликации
Бывают ситуации при которых у вас может возникать очередь на входящие запросы репликации. Основными причинами могут выступать:
- Слишком много одновременных партнеров по репликации
- Высокая скорость изменения объектов в доменных службах Active Directory (AD DS), предположим что у вас одновременно с помощью скрипта было сформировано 1000 новых групп или создано 1000 пользователей.
- Недостаточная пропускная способность CPU или сети, которые реплицирует контроллер домена
Чтобы посмотреть очередь репликации на контроллере домена, вам нужно воспользоваться ключом /Queue:
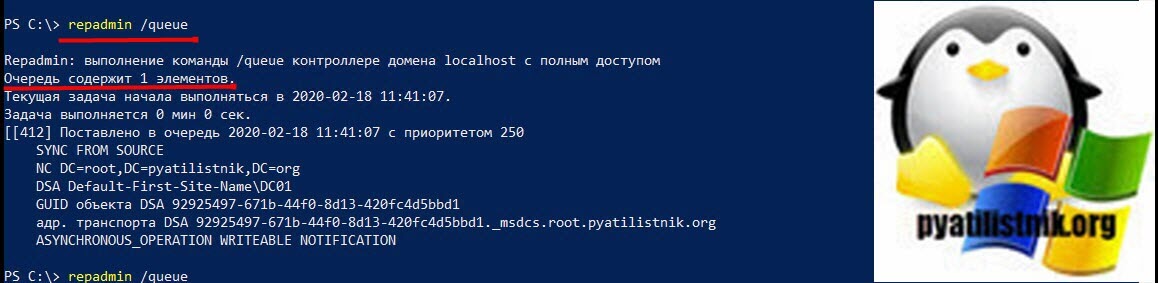
Чаще всего у вас количество объектов в очереди будет нулевым, но если сайтов много, то могут быть небольшие очереди. Если вы заметили элементы, стоящие в очереди, и они никак не очищаются, у вас есть проблема. Вот пример сообщения, где очередь репликации не равна нулю.
Repadmin: выполнение команды /queue контроллере домена localhost с полным доступом
Очередь содержит 1 элементов.
Текущая задача начала выполняться в 2020-02-18 11:41:07.
Задача выполняется 0 мин 0 сек.
[[412] Поставлено в очередь 2020-02-18 11:41:07 с приоритетом 250
SYNC FROM SOURCE
NC DC=root,DC=pyatilistnik,DC=org
DSA Default-First-Site-NameDC01
GUID объекта DSA 92925497-671b-44f0-8d13-420fc4d5bbd1
адр. транспорта DSA 92925497-671b-44f0-8d13-420fc4d5bbd1._msdcs.root.pyatilistnik.org
ASYNCHRONOUS_OPERATION WRITEABLE NOTIFICATION
Принудительная проверка топологии репликации
Repadmin умеет принудительно проверять топологию репликации на каждом целевом контроллере домена, чтобы немедленно пересчитать топологию входящей репликации.
По умолчанию каждый контроллер домена выполняет этот пересчет каждые 15 минут и если есть проблемы вы можете видеть в логах Windows событие с кодом 1311.
Выполните эту команду для устранения ошибок KCC или для повторной оценки необходимости создания новых объектов подключения от имени целевых контроллеров домена.
так же можно запустить для определенного сайта для этого используется параметр site:
Repadmin: выполнение команды /kcc контроллере домена dc01.root.pyatilistnik.org с полным доступом
Root
Текущий Параметры сайта: (none)
Проверка согласованности на dc01.root.pyatilistnik.org выполнена успешно.
Repadmin: выполнение команды /kcc контроллере домена dc03.child.root.pyatilistnik.org с полным доступом
Default-First-Site-Name
Текущий Параметры сайта: (none)
Проверка согласованности на dc03.child.root.pyatilistnik.org выполнена успешно.
Repadmin: выполнение команды /kcc контроллере домена dc02.root.pyatilistnik.org с полным доступом
Root
Текущий Параметры сайта: (none)
Проверка согласованности на dc02.root.pyatilistnik.org выполнена успешно.
Repadmin: выполнение команды /kcc контроллере домена dc04.child.root.pyatilistnik.org с полным доступом
Default-First-Site-Name
Текущий Параметры сайта: (none)
Проверка согласованности на dc04.child.root.pyatilistnik.org выполнена успешно.
У /kcc есть дополнительный ключ /async — Указывает, что репликация является асинхронной. То есть Repadmin запускает событие репликации, но не ожидает немедленного ответа от контроллера домена назначения. Используйте этот параметр для запуска KCC, если вы не хотите ждать окончания работы KCC. Repadmin /kcc обычно запускается без параметра /async.
Как принудительно запустить репликацию Active Directory
Бывают ситуации, когда вам необходимо произвести форсированное обновление на контроллере домена. Для этого есть специальный ключ /syncall. Для того, чтобы выполнить синхронизацию нужного контроллера домена со всеми его партнерами по репликации, вам необходимо на нем выполнить команду:
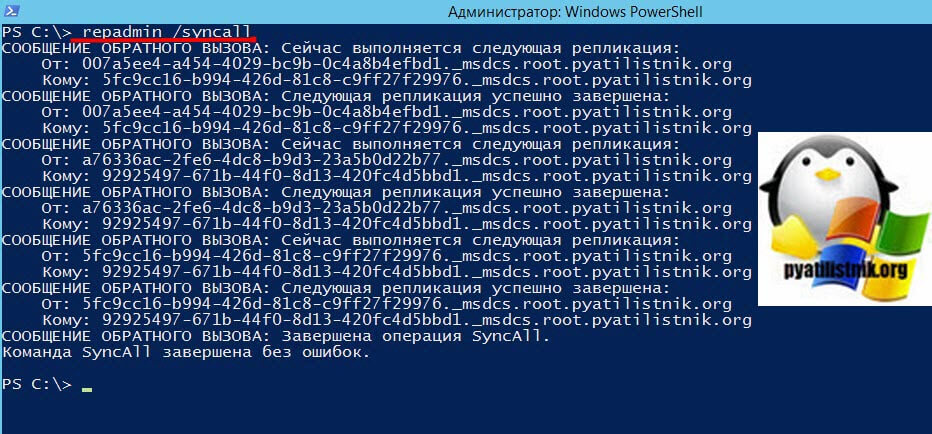
На выходе вы получите статус репликации и количество ошибок, выглядит это вот так:
СООБЩЕНИЕ ОБРАТНОГО ВЫЗОВА: Сейчас выполняется следующая репликация:
От: 007a5ee4-a454-4029-bc9b-0c4a8b4efbd1._msdcs.root.pyatilistnik.org
Кому: 5fc9cc16-b994-426d-81c8-c9ff27f29976._msdcs.root.pyatilistnik.org
СООБЩЕНИЕ ОБРАТНОГО ВЫЗОВА: Следующая репликация успешно завершена:
От: 007a5ee4-a454-4029-bc9b-0c4a8b4efbd1._msdcs.root.pyatilistnik.org
Кому: 5fc9cc16-b994-426d-81c8-c9ff27f29976._msdcs.root.pyatilistnik.org
СООБЩЕНИЕ ОБРАТНОГО ВЫЗОВА: Сейчас выполняется следующая репликация:
От: a76336ac-2fe6-4dc8-b9d3-23a5b0d22b77._msdcs.root.pyatilistnik.org
Кому: 92925497-671b-44f0-8d13-420fc4d5bbd1._msdcs.root.pyatilistnik.org
СООБЩЕНИЕ ОБРАТНОГО ВЫЗОВА: Следующая репликация успешно завершена:
От: a76336ac-2fe6-4dc8-b9d3-23a5b0d22b77._msdcs.root.pyatilistnik.org
Кому: 92925497-671b-44f0-8d13-420fc4d5bbd1._msdcs.root.pyatilistnik.org
СООБЩЕНИЕ ОБРАТНОГО ВЫЗОВА: Сейчас выполняется следующая репликация:
От: 5fc9cc16-b994-426d-81c8-c9ff27f29976._msdcs.root.pyatilistnik.org
Кому: 92925497-671b-44f0-8d13-420fc4d5bbd1._msdcs.root.pyatilistnik.org
СООБЩЕНИЕ ОБРАТНОГО ВЫЗОВА: Следующая репликация успешно завершена:
От: 5fc9cc16-b994-426d-81c8-c9ff27f29976._msdcs.root.pyatilistnik.org
Кому: 92925497-671b-44f0-8d13-420fc4d5bbd1._msdcs.root.pyatilistnik.org
СООБЩЕНИЕ ОБРАТНОГО ВЫЗОВА: Завершена операция SyncAll.
Команда SyncAll завершена без ошибок.
Если имеются какие-то проблемы, то вы можете увидеть подобного рода ошибки:
Функция SyncAll сообщает о следующих ошибках:
Ошибка обращения к серверу 5fc9cc16-b994-426d-81c8-c9ff27f29976._msdcs.root.pyatilistnik.org (сетевая ошибка): 17
ba):
Сервер RPC недоступен.
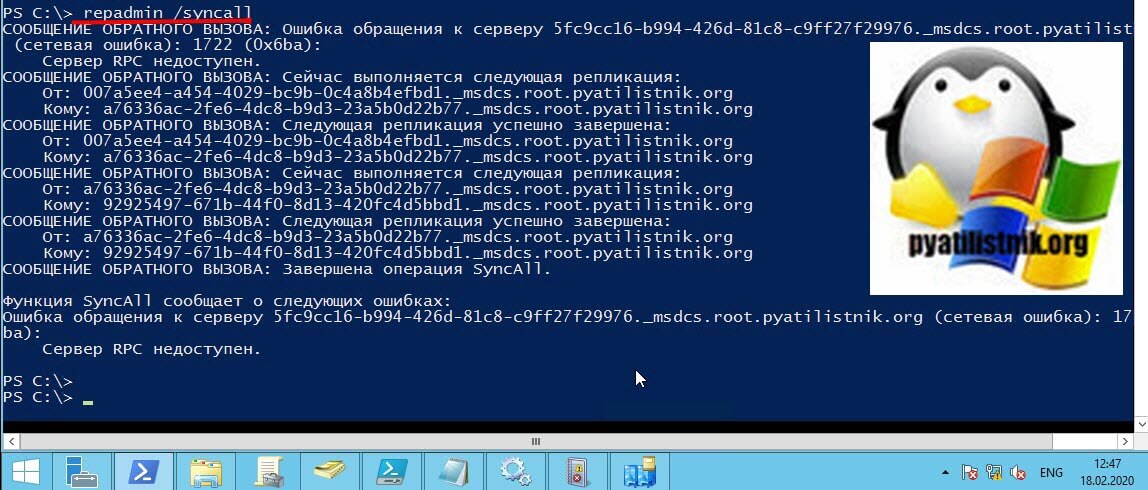
так же repadmin /syncall имеет ряд флагов:
- /a — прерывается, если какой-либо сервер недоступен.
- /A — Синхронизирует все контексты именования, хранящиеся на домашнем сервере
- /d — Идентифицирует серверы по отличительным именам в сообщениях.
- /e — Синхронизирует контроллеры домена на всех сайтах предприятия. По умолчанию эта команда не синхронизирует контроллеры домена на других сайтах.
- /h — Отображение справки.
- /i — запускает бесконечный цикл синхронизации
- /I — Запускает команду repadmin /showrepl на каждой паре серверов вместо синхронизации.
- /j — Синхронизирует только соседние серверы.
- /p — Пауза после каждого сообщения, чтобы пользователь мог прервать выполнение команды.
- /P — Выдвигает изменения наружу от указанного контроллера домена.
- /q — Работает в тихом режиме, который подавляет сообщения обратного вызова.
- /Q — Работает в очень тихом режиме, который сообщает только о фатальных ошибках.
- /s — не синхронизируется.
- /S — Пропускает начальную проверку ответа сервера.
Предположим, что вы внесли важное изменение в AD и хотите его максимально быстро распространить. для этого запустите на актуальном контроллере:
Экспорт результатов в текстовый файл
Иногда Repadmin отображает много информации. Вы можете экспортировать любой из приведенных выше примеров в текстовый файл, это немного упрощает последующее рассмотрение или сохранение для документации. Для этого используется инструкция «> путь до файла». Вот пример команд:
@echo off
chcp 855
repadmin /replsummary > c:tempreplsummary.log
repadmin /syncall > c:tempsyncall.txt
repadmin /Queue > c:tempQueue.txt
repadmin /istg * /verbose > c:tempistg.txt
repadmin /bridgeheads * /verbose > c:tempbridgeheads.txt
chcp 855 используется, чтобы у вас не было кракозябр вместо русского текста.
Как посмотреть количество изменений атрибутов
Хотя команда repadmin /showobjmeta отображает количество изменений атрибутов объекта и контроллер домена, которые вносили эти изменения, команда repadmin /showattr отображает фактические значения для объекта. Команда repadmin /showattr также может отображать значения для объектов, которые возвращаются запросом LDAP-протокола.
На объект может ссылаться его distinguished name или глобальный уникальный идентификатор объекта (GUID).
По умолчанию repadmin /showattr использует порт 389 LDAP для запроса доступных для записи разделов каталога. Однако repadmin /showattr может дополнительно использовать порт 3268 LDAP для запроса разделов, доступных только для чтения, на сервере глобального каталога. (Советую освежить в памяти какие порты использует Active Directory).
Основные параметры команды:
- <DSA_LIST> — Задает имя хоста контроллера домена или списка контроллеров домена, разделенных в списке одним пробелом.
- <OBJ_LIST> — Определяет различающееся имя или GUID объекта для объекта, атрибуты которого вы хотите перечислить. Когда вы выполняете запрос LDAP из командной строки, этот параметр формирует базовый путь различаемого имени для поиска. Заключите в кавычки отличительные имена, содержащие пробелы.
- /atts — Возвращает значения только для указанных атрибутов. Вы можете отображать значения для нескольких атрибутов, разделяя их запятыми.
- /allvalues — Отображает все значения атрибутов. По умолчанию этот параметр отображает только 20 значений атрибута для атрибута.
- /gc — Указывает использование TCP-порта 3268 для запроса разделов глобального каталога только для чтения.
- /long — Отображает одну строку для каждого значения атрибута.
- /dumpallblob — Отображает все двоичные значения атрибута. Эта команда похожа на /allvalues, но отображает двоичные значения атрибутов.
В следующем примере выполняется запрос к конкретному контроллеру домена.
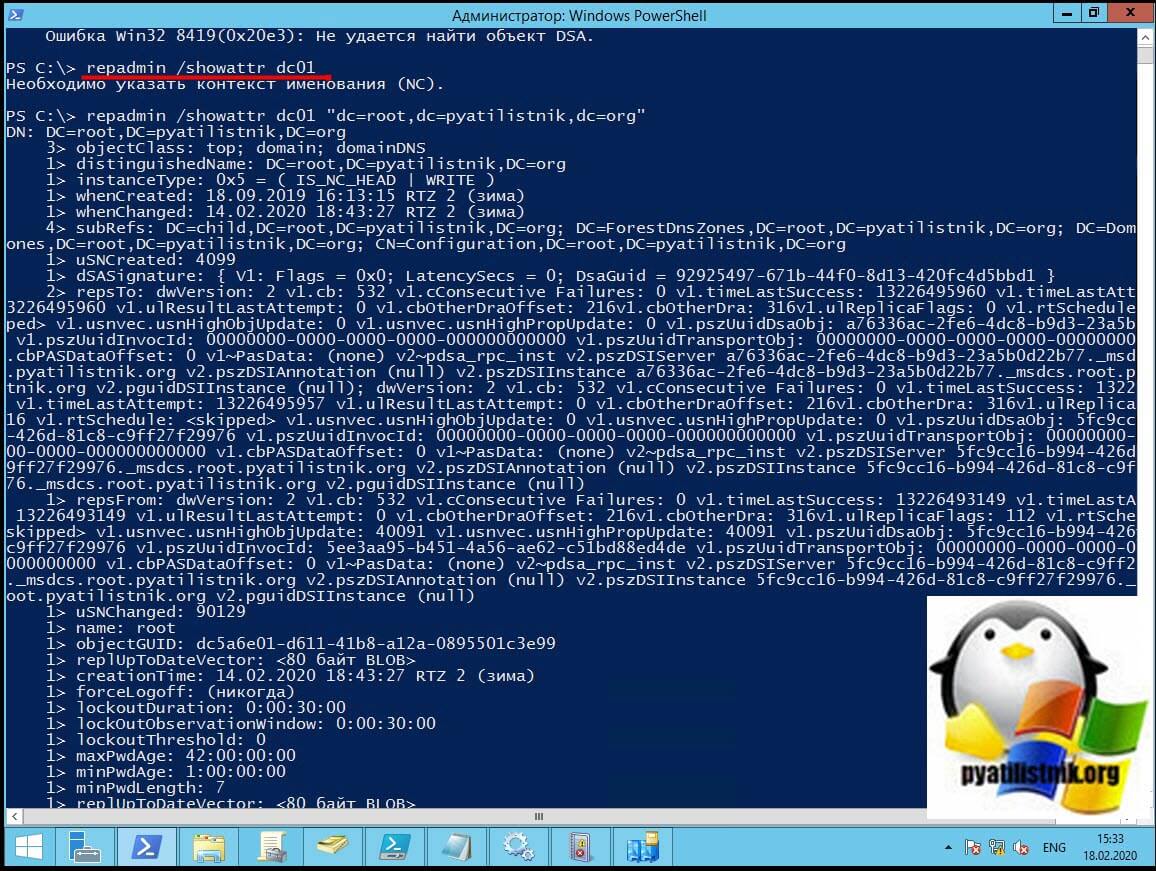
repadmin /showattr dc01 «dc=root,dc=pyatilistnik,dc=org»
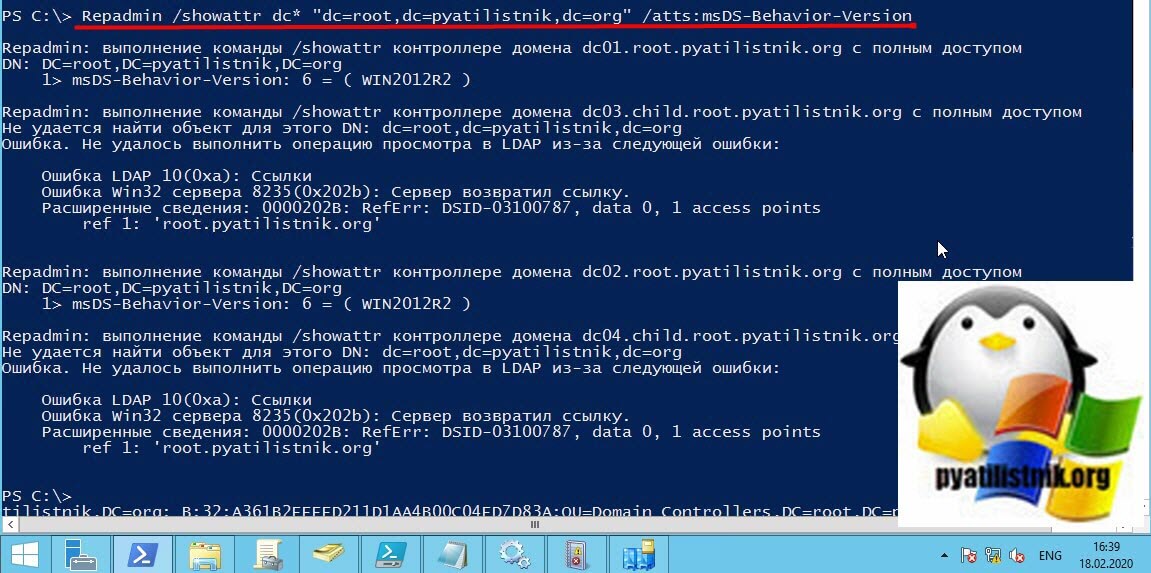
В следующем примере запрашиваются все контроллеры домена, имена компьютеров которых начинаются с dc, и показывает значение для определенного атрибута msDS-Behavior-Version, который обозначает функциональный уровень домена.
Repadmin /showattr dc* «dc=root,dc=pyatilistnik,dc=org» /atts:msDS-Behavior-Version
В следующем примере запрашивается один контроллер домена с именем dc01 и возвращается версия операционной системы и версия пакета обновления для всех компьютеров с целевым идентификатором основной группы = 516.
repadmin /showattr dc01 ncobj:domain: /filter:»(&(objectCategory=computer)(primaryGroupID=516))» /subtree /atts:
operatingSystem,operatingSystemVersion,operatingSystemServicePack

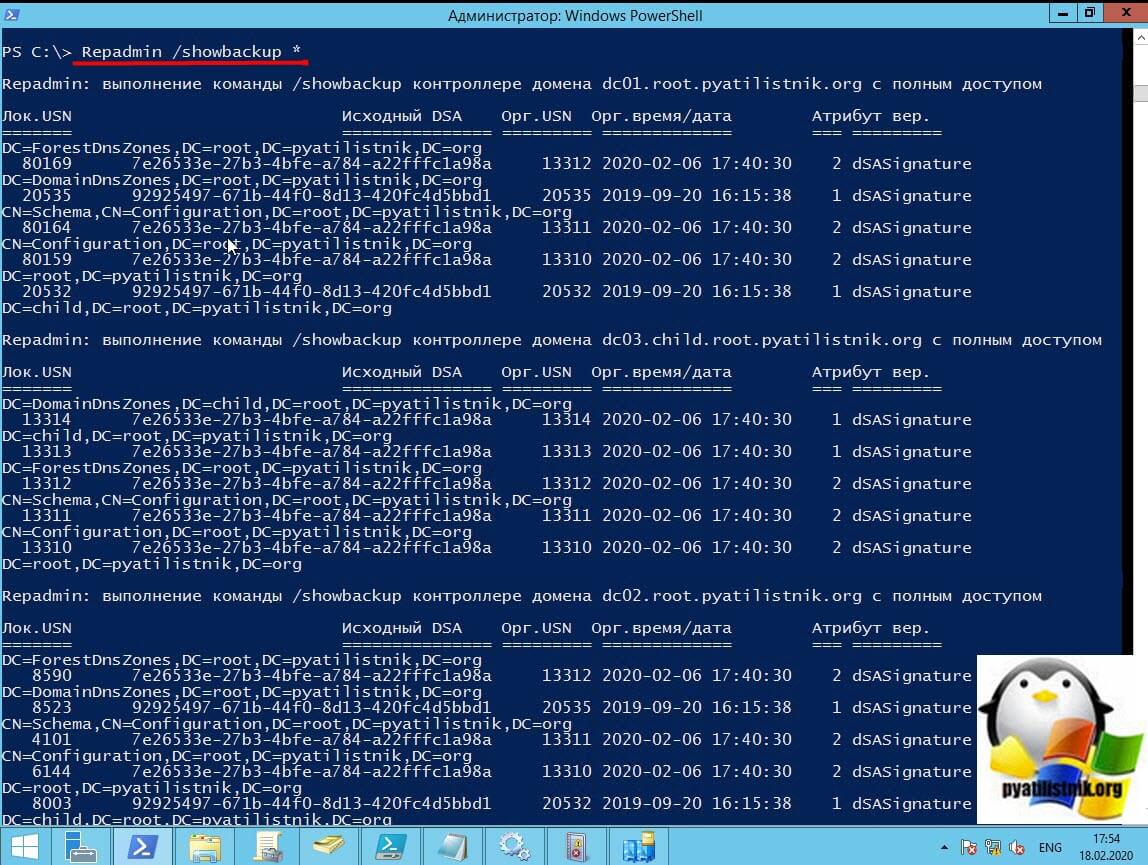
Как посмотреть время последней резервной копирования Active Directory
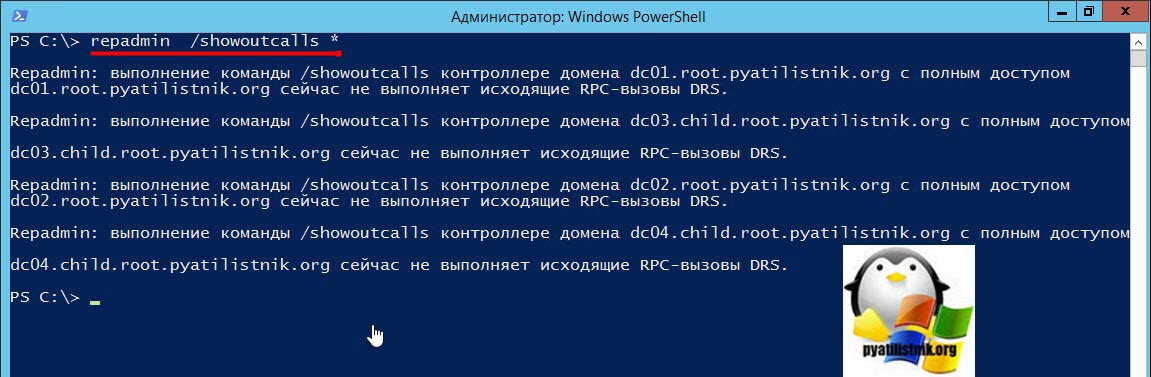
Как посмотреть RPC-вызовы, на которые еще не ответили
Как посмотреть топологию репликации
repadmin /bridgeheads * /verbose

Если есть проблемы с репликацией, то можете получать ошибку «The remote system is not available. For information about network troubleshooting, see Windows Help.»
Как сгенерировать топологию сайтов Active Directory
repadmin /istg * /verbose
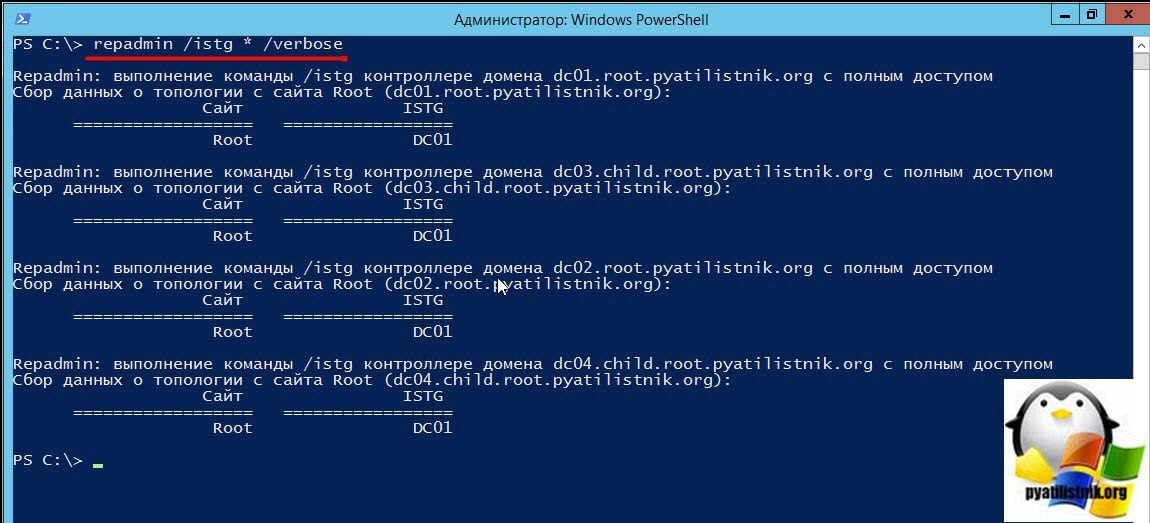
Если есть проблемы с репликацией, то тут вы можете видеть ошибки: LDAP error 81 (Server Down) Win32 Err 58.
На этом у меня все, мы с вами разобрали очень полезную утилиту, которая позволит вам быть в курсе статуса репликации вашей Active Directory. С вами был Иван Семин, автор и создатель IT портала Pyatilistnik.org.
Потоковая репликация, которая появилась в 2010 году, стала одной из прорывных фич PostgreSQL и в настоящее время практически ни одна инсталляция не обходится без использования потоковой репликации. Она надежна, легка в настройке, нетребовательна к ресурсам. Однако при всех своих положительных качествах, при её эксплуатации могут возникать различные проблемы и неприятные ситуации.
Алексей Лесовский (@lesovsky) на Highload++ 2017 рассказал, как с помощью встроенных и сторонних инструментов, диагностировать различные типы проблем и как устранять их. Под катом расшифровка этого доклада, построенного по спиральному принципу: сначала мы перечислим все возможные средства диагностики, потом перейдем к перечислению типовых проблем и их диагностике, далее посмотрим, какие экстренные меры можно принять, и наконец как радикально справиться с задачей.
О спикере: Алексей Лесовский администратор баз данных в компании Data Egret. Одной из любимых тем Алексея в PostgreSQL является потоковая репликация и работа со статистикой, поэтому доклад на Highload++ 2017 был посвящен тому, как помощью статистики искать проблемы, и какие использовать методы для их устранения.
План
- Немного теории, или как работает репликация в PostgreSQL
- Troubleshooting tools или что есть у PostgreSQL и сообщества
- Troubleshooting cases:
- проблемы: их симптомы и диагностика
- решения
- меры, которые нужно принимать, чтобы этих проблем не возникало.
Зачем всё это? Эта статья поможет вам лучше разбираться в потоковой репликации, научиться быстро находить и устранять проблемы, чтобы сократить время реакции на неприятные инциденты.
Немного теории
В PostgreSQL есть такая сущность, как Write-Ahead Log (XLOG) — это журнал транзакций. Почти все изменения, которые происходят с данными и метаданными внутри базы данных, записываются в этом журнале. Если вдруг произошла какая-то авария, PostgreSQL запускается, читает журнал транзакций и восстанавливает записанные изменения на данных. Так обеспечивается надежность — одно из важнейших свойств любой СУБД и PostgreSQL в том числе.
Журнал транзакций может заполнятся двумя способами:
- По умолчанию, когда бэкенды делают какие-то изменения в базе (INSERT, UPDATE, DELETE и т.д.), все изменения фиксируются в журнале транзакций синхронно:
- Клиент отправил команду COMMIT на подтверждение данных.
- Данные фиксируются в журнале транзакций.
- Как только фиксация произошла, управление отдается бэкенду, и он может дальше принимать команды от клиента.
- Второй вариант — это асинхронная запись в журнал транзакций, когда отдельный выделенный процесс WAL writer с определенным интервалом времени пишет изменения в журнал транзакций. За счет этого достигается увеличение производительности бэкендов, поскольку не нужно ждать, когда завершится команда COMMIT.
Самое важное то, что потоковая репликация основана на этом журнале транзакций. У нас есть несколько участников потоковой репликации:
- мастер, где происходят все изменения;
- несколько реплик, которые принимают журнал транзакций от мастера и воспроизводят все эти изменения на своих локальных данных. Это — потоковая репликация.
Стоит помнить, что все эти журналы транзакций, хранятся в каталоге pg_xlog в $DATADIR — каталоге с основными файлами данных СУБД. В 10-й версии PostgreSQL этот каталог был переименован в pg_wal/, потому что нередки случаи когда pg_xlog/ занимает много места, и разработчики или администраторы, по незнанию путая его с логами, беспечно удаляют и становится все плохо.
В PostgreSQL есть несколько фоновых служб которые задействованы в потоковой репликации. Посмотрим на них с точки зрения операционной системы.
- Со стороны мастера — WAL Sender process. Это процесс, который отправляет журналы транзакций репликам, на каждую реплику будет свой WAL Sender.
- На реплике в свою очередь запущен WAL Receiver process, который по сетевому соединению от WAL Sender принимает журналы транзакций и передает их Startup process.
- Startup process читает журналы и воспроизводит на каталоге с данными все те изменения, которые записаны в журнале транзакций.
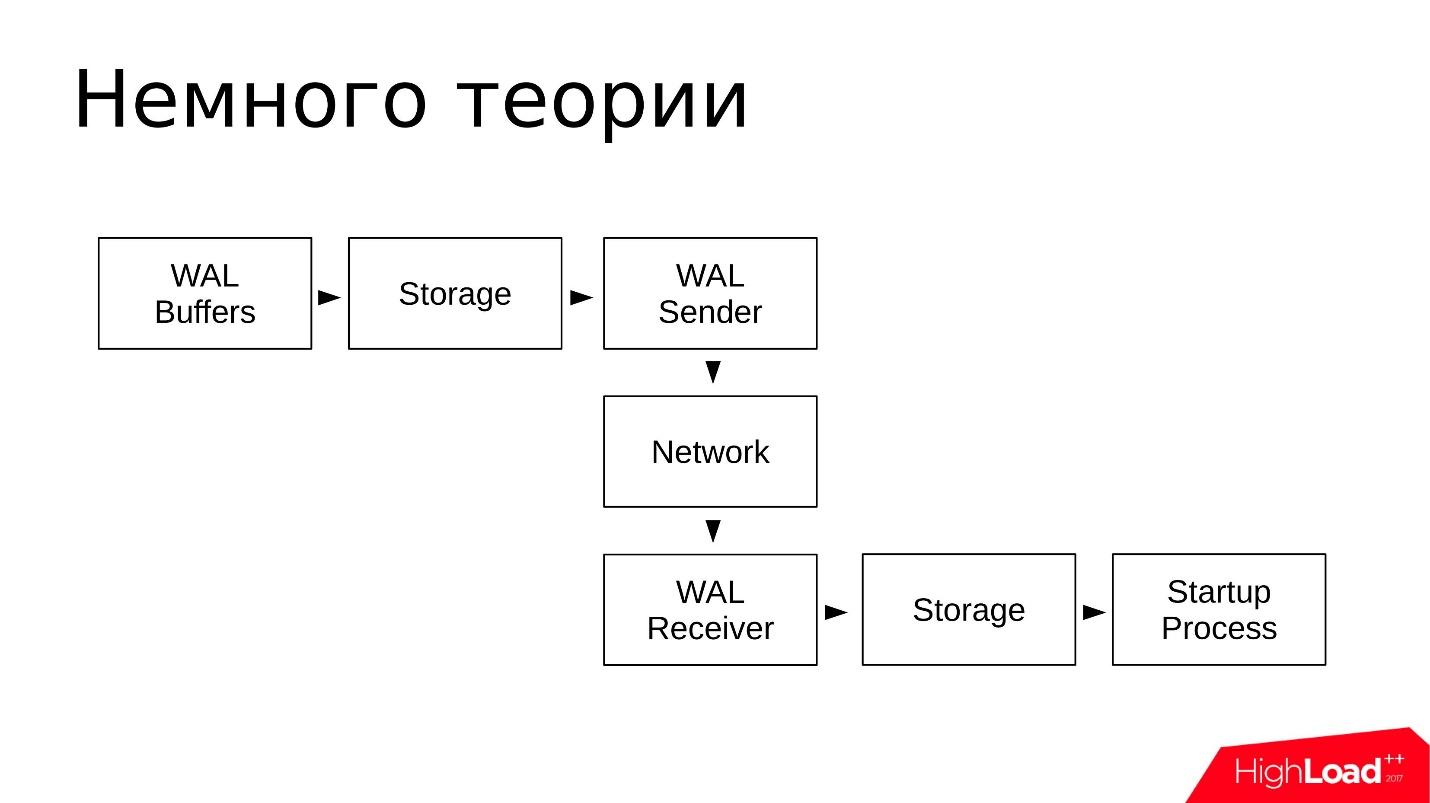
Схематично это выглядит примерно так:
- В WAL Buffers записываются изменения, которые потом будут записаны в журнал транзакций;
- Журналы находятся в хранилище (Storage) в каталоге pg_wal/;
- WAL Sender читает из хранилища журнал транзакций и передает их по сети;
- WAL Receiver принимает и сохраняет у себя в Storage — в локальном для себя pg_wal/;
- Startup Process читает все, что принято, и воспроизводит.
Схема простая. Потоковая репликация работает довольно надежно и много лет прекрасно эксплуатируется.
Troubleshooting tools
Посмотрим, какие средства и утилиты предлагает сообщество и PostgreSQL для того, чтобы расследовать проблемы, возникающие с потоковой репликацией.
Сторонние инструменты
Начнем со сторонних инструментов. Это утилиты довольно универсального плана, ими можно пользоваться не только при расследовании инцидентов, связанных с потоковой репликацией. Это вообще утилиты любого системного администратора.
- top из пакета procps. В качестве замены top можно использовать любые утилиты типа atop, htop и подобные им. Они предлагают похожую функциональность.
С помощью top смотрим: утилизацию процессоров (CPU), среднюю нагрузку (load average) и использование памяти и области подкачки.
- iostat из пакета sysstat и iotop. Эти утилиты показывают утилизацию дисковых устройств и какое I/O создается процессами в операционной системе.
С помощью iostat смотрим: утилизацию хранилища, сколько iops в данный момент, какая пропускная способность (throughput) на устройствах, какие задержки при обработке запросов на I/O (latency). Эта довольно подробная информация берется из файловой системы procfs и предоставляется пользователю уже в наглядном виде.
- nicstat — это аналог iostat, только для сетевых интерфейсов. В этой утилите можно смотреть утилизацию интерфейсов.
С помощью nicstat смотрим: аналогично — утилизацию интерфейсов, какие-то ошибки, которые возникают на интерфейсах, пропускную способность — тоже очень полезная утилита.
- pgCenter — это утилита для работы только с PostgreSQL. Она показывает статистику PostgreSQL в top-подобном интерфейсе, и в ней также можно смотреть статистику, связанную с потоковой репликацией.
С помощью pgCenter смотрим: статистику по репликации. Можно смотреть лаг репликации, как-то оценивать его, и прогнозировать дальнейшие работы.
- perf — это утилита для более глубокого расследования причин «подземных стуков», когда в эксплуатации происходят непонятные проблемы на уровне кода PostgreSQL.
С помощью perf ищем: подземные стуки. Для полноценной работы perf c PostgreSQL, последний должен быть собран с debug символами, таким образом можно смотреть стек функций в процессах и какие функции занимают больше всего процессорного времени.
Все эти утилиты нужны, чтобы проверять гипотезы, возникающие при устранении неполадок — где и что тормозит, где и что нужно исправить, проверить. Эти утилиты помогают удостовериться, на правильном ли мы пути.
Встроенные средства
Что предлагает сам PostgreSQL?
Системные представления
Вообще средств для работы с PostgreSQL довольно много. Каждая компания-вендор, которая предоставляет поддержку PostgreSQL, предлагает свои средства. Но, как правило, эти средства основаны на внутренней статистике PostgreSQL. В этом плане PostgreSQL предоставляет системные представления (views), в которых можно делать различные select’ы и получать нужную информацию. То есть c помощью обычного клиента, как правило psql, мы можем делать запросы и смотреть, что происходит в статистике.
Существует довольно много системных представлений. Для того, чтобы работать с потоковой репликацией и исследовать проблемы, нам нужны лишь: pg_stat_replication, pg_stat_wal_receiver, pg_stat_databases, pg_stat_databases_conflicts, и вспомогательные pg_stat_activitу и pg_stat_archiver.
Их немного, но этого набора достаточно, чтобы проверить, нет ли каких-либо проблем.
Вспомогательные функции
С помощью вспомогательных функций можно брать данные из статистических системных представлений и преобразовывать их в более удобный для себя вид. Вспомогательных функций тоже всего несколько штук.
- pg_current_wal_lsn() (старый аналог pg_current_xlog_location()) — самая нужная функция, которая позволяет посмотреть текущую позицию в журнале транзакций. Журнал транзакций — это непрерывная последовательность данных. С помощью этой функции можно посмотреть последнюю точку, получить позицию, где сейчас журнал транзакций остановился.
- pg_last_wal_receive_lsn(), pg_last_xlog_receive_location() — это аналогичная функция вышеупомянутой, только для реплик. Реплика получает журнал транзакций, и можно посмотреть последнюю полученную позицию журнала транзакций;
- pg_wal_lsn_diff(), pg_xlog_location_diff() — другая полезная функция. Мы передаем ей две позиции из журнала транзакций, и она показывает diff — дистанцию между этими двумя точками в байтах. Эта функция всегда полезна для определения лага между мастером и репликами в байтах.
Полный список функций можно получить psql мета-командой: df *(wal|xlog|lsn|location)*.
Ее можно набрать в psql и посмотреть все функции, которые содержат в себе wal, xlog, Isn, location. Таких функций будет порядка 20-30, и они тоже предоставляют различную информацию по журналу транзакций. Рекомендую ознакомиться.
Утилита pg_waldump
До версии 10.0 она называлась pg_xlogdump. Утилита pg_waldump нужна, когда мы хотим заглянуть в сегменты журнала транзакций, узнать какие ресурсные записи туда попали, и что PostgreSQL туда записал, то есть для более детального исследования.
В версии 10.0 все системные представления, функции и утилиты которые включали в себя слово xlog были переименованы. Все вхождения слов xlog и location были заменены соответственно на слова wal и lsn. Тоже самое было сделано и с каталогом pg_xlog который стал каталогом pg_wal.
Утилита pg_waldump просто декодирует содержимое XLOG сегментов в человеко-понятный формат. Можно посмотреть, какие так называемые ресурсные записи попадают в процессе работы PostgreSQL в журналы сегмента, какие индексы и heap-файлы были изменены, какая информация, предназначенная для stand-by, туда попала. Таким образом, очень много информации можно смотреть с помощью pg_waldump.
Но есть оговорка, которая написана в официальной документации: pg_waldump может показывать чуть-чуть неверные данные при работающем PostgreSQL (Can give wrong results when the server is running — что бы это не означало )
Можно воспользоваться командой:
pg_waldump -f -р /wal_10
$(psql -qAtX -с "select pg_walfile_name(pg_current_wal_lsn())")
Это аналог команды tail -f только для журналов транзакций. Эта команда показывает хвост журнала транзакций, которые прямо сейчас происходит. Можно запустить эту команду, она найдет последний сегмент с самой последней записью журнала транзакций, подключится к нему и начнет показывать содержимое журнала транзакций. Немного хитрая команда, но, тем не менее, она работает. Я часто ей пользуюсь.
Troubleshooting cases
Здесь мы рассмотрим самые частые проблемы, которые возникают в практике консалтеров, какие могут быть симптомы и как их диагностировать:
Лаги репликации — это наиболее частая проблема. Совсем недавно у нас была переписка с заказчиком:
— У нас сломалась репликация master-slave между двумя серверами.
— Обнаружил лаг 2 часа, запущен pg_dump.
— ОК, понятно. Какой у нас допустимый лаг?
— 16 часов в max_standby_streaming_delay.
— Что случится, когда этот лаг будет превышен? Взвоет сирена?
— Нет, прибьются транзакции, и накатка WAL возобновится.
Проблемы с лагами репликаций у нас бывают постоянно, и чуть ли не каждую неделю мы их решаем.
Распухание каталога pg_wal/, где хранятся сегменты журнала транзакций — это проблема, которая возникает реже. Но в этом случае необходимо предпринимать немедленные действия, чтобы проблема не превратилась в аварийную ситуацию, когда реплики отваливаются.
Долгие запросы, которые выполняются на реплике, приводят к конфликтам при восстановлении. Это ситуация, когда мы на реплику пускаем какую-то нагрузку, на репликах можно выполнять читающие запросы, и в этот момент эти запросы мешают воспроизведению журнала транзакций. Возникает конфликт, и PostgreSQL нужно решить, ждать завершение запроса или завершить его и продолжить воспроизведение журнала транзакций. Это конфликт репликации или конфликт восстановления.
Recovery process: 100% CPU usage —процесс восстановления журнала транзакций на репликах занимает 100% процессорного времени. Это тоже редкая ситуация, но она довольно неприятная, т.к. приводит к росту лага репликации и в целом её сложно расследовать.
Лаги репликации
Лаги репликации — это когда один и тот же запрос, выполненный на мастере и на реплике, возвращает разные данные. Это значит, что данные неконсистентны между мастером и репликами, и есть какое-то отставание. Реплике нужно воспроизвести часть журналов транзакций, чтобы догнать мастера. Основной симптом выглядит именно так: есть запрос, и они возвращают разные результаты.
Как искать такие проблемы?
- Есть основное представление на мастере и на репликах — pg_stat_replication. Оно показывает информацию по всем WAL Sender, то есть по процессам, которые занимаются отправкой журнала транзакций. Для каждой реплики будет отдельная строчка, которая показывает статистику именно по этой реплике.
- Вспомогательная функция pg_wal_lsn_diff() позволяет сравнивать разные позиции в журнале транзакций и вычислять тот самый лаг. С её помощью мы можем получить конкретные цифры и определить, где у нас большой лаг, где маленький и уже как-то отреагировать на проблему.
- Функция pg_last_xact_replay_timestamp() работает только на реплике и позволяет посмотреть время, когда была выполнена последняя проигранная транзакция. Есть всем известная функция now(), которая показывает текущее время, мы из функции now() вычитаем время, которое нам показывается функцией pg_last_xact_replay_timestamp() и получаем лаг во времени.
В 10 версии pg_stat_replication появились дополнительные поля, которые показывают временной лаг уже на мастере, поэтому этот способ уже устаревший, но, тем не менее, его можно использовать.
Есть небольшой подводный камень. Если на мастере долгое время нет транзакций, и он не генерирует журналы транзакций, то последняя функция будет показывать увеличивающийся лаг. На самом деле система просто простаивает, на ней нет никакой активности, но в мониторинге мы можем увидеть, что лаг растет. Про этот подводный камень стоит помнить.
Представление выглядит следующим образом.

Оно содержит информацию по каждому WAL Sender и несколько важных для нас полей. Это в первую очередь client_addr — сетевой адрес подключенной реплики (как правило, IP адрес) и набор полей lsn (в старых версиях он называется location), про них я расскажу чуть дальше.
В 10-й версии появились поля lag — это отставание, выраженное во времени, то есть более человеко-понятный формат. Лаг может выражаться либо в байтах, либо во времени — можно выбрать, что больше нравится.
Как правило, я пользуюсь таким запросом.

Это не самый сложный запрос, который выводит pg_stat_replication в более удобном, понятном формате. Здесь я использую следующие функции:
- pg_wal_lsn_diff(), чтобы считать diff’ы. Но между чем я считаю diff’ы? У нас есть несколько полей — sent_lsn, write_lsn, flush_lsn, replay_lsn. Высчитывая diff между текущим и предыдущим полем, мы можем точно понять, где у нас произошло отставание, где конкретно происходит лаг.
- pg_current_wal_lsn(), которая показывает текущую позицию журнала транзакций. Здесь мы смотрим расстояние между текущей позицией в журнале и отправленной — сколько журналов транзакций сгенерировано, но не отправлено.
- sent_lsn, write_lsn — это сколько отправлено реплике, но не записано. То есть это то, что сейчас находится где-то в сети, либо оно получено репликой, но еще не записано из сетевых буферов на дисковое хранилище.
- write_lsn, flush_lsn — это записано, но не было выпущено командой fsync — как бы записано, но может находиться где-нибудь в оперативной памяти, в page-cache операционной системы. Как только мы делаем fsync, данные синхронизируются с диском, попадают на персистентное хранилище и вроде бы все надежно.
- replay_lsn, flush_lsn — данные сброшены, выполнен fsync, но не воспроизведены репликой.
- current_wal_lsn и replay_lsn — это некий суммарный лаг, который включает в себя все предыдущие позиции.
Немного примеров

Выше цветом выделена реплика 10.6.6.8. У нее pending-лаг, она нагенерировала какие-то журналы транзакций, но они все еще не отправлены и лежат на мастере. Вероятнее всего, здесь какая-то проблема с сетевой производительностью. Мы будем это проверять с помощью утилиты nicstat.
Мы запустим nicstat, посмотрим утилизацию интерфейсов, нет ли там проблем и ошибок. Так мы сможем проверить эту гипотезу.

Выше отмечен write лаг. На самом деле этот лаг довольно редкий, я практически не вижу, чтобы он был большим. Проблема может быть с дисками, и мы используем утилиту iostat или iotop — смотрим утилизацию дисковых хранилищ, какой I/O создается процессами, и дальше уже выясняем, почему.

Flush и replay Лаги — чаще всего лаг бывает именно там, когда дисковое устройство на реплике не успевает просто проиграть все те изменения, которые прилетают с мастера.
Также утилитами iostat и iotop мы смотрим, что происходит с дисковой утилизацией и почему тормоза.
И последний total_lag — полезная метрика для систем мониторинга. Если у нас порог total_lag превышен, в мониторинге поднимается флажок, и мы начинаем расследовать, что же там происходит.
Проверка гипотезы
Теперь нужно разобраться, как дальше исследовать ту или иную проблему. Я уже сказал, если это сетевой лаг, то нужно проверить, все ли у нас в порядке с сетью.
Сейчас практически все хостеры предоставляют 1 Гб/с или даже 10 Гб/с, поэтому забитая полоса пропускания — это самый маловероятный сценарий. Как правило, нужно смотреть на ошибки. nicstat содержит информацию по ошибкам на интерфейсах, можно разобраться, что там — проблемы с драйверами, либо с самой сетевой картой, либо с кабелями.
Проблемы в хранилище мы исследуем с помощью iostat и iotop. iostat нужен для просмотра общей картины, связанной с дисковыми хранилищами: утилизация устройств, пропускная способность устройств, latency. iotop — для более точных исследований, когда нам нужно выявить, какой из процессов грузит дисковую подсистему. Если это какой-то сторонний процесс, его можно просто обнаружить, завершить и, возможно, проблема исчезнет.
Задержки восстановления и конфликты репликации мы прежде всего смотрим через top или pg_stat_activity: какие процессы запущены, какие запросы работают, время их выполнения, как долго они работают. Если это какие-то долгие запросы, мы смотрим, почему они долго работают, отстреливаем их, разбираемся и оптимизируем их — исследуем уже сами запросы.
Если это большой объем журналов транзакций, который генерируется мастером, мы можем это обнаружить по pg_stat_activity. Может быть, там какие-то бэкапные процессы запущены, запущены какие-то вакуумы (pg_stat_progress_vacuum), либо выполняется checkpoint. То есть если генерируется слишком большой объем журналов транзакций, и реплика просто не успевает его обработать, в какой-то момент она может просто отвалиться, и это будет уже проблемой для нас.
И конечно pg_wal_lsn_diff() для определения лага и определения, где у нас конкретно лаг находится — в сети, на дисках, либо на процессорах.
Варианты решения
Проблемы на уровне сети/хранения
Тут довольно все просто, но с точки зрения конфигурации это, как правило, не решается. Можно подкрутить некоторые гайки, но в целом есть 2 варианта:
- Проверить workload
Проверяем какие выполняются запросы. Может быть, запущены какие-то миграции, которые генерируют много журналов транзакций, либо это может быть перенос, удаление или вставка данных. Любой процесс, который генерирует журналы транзакций, может приводить к лагу транзакций. Все данные на мастере генерируются как можно быстрее, мы внесли изменение данных, отправили на реплику, а справится реплика или не справится — это уже мастера не волнует. Здесь может появиться лаг и нужно что-то с ним делать.
- Upgrade hardware
Самый тупой вариант — возможно, мы уперлись в производительность железа, и нужно его просто менять. Это могут быть старые диски либо некачественные SSD, либо затык в производительности RAID контроллера. Здесь мы исследуем уже не саму базу, а проверяем производительность наших железок.
Задержки восстановления
Если у нас возникли какие-то конфликты репликации из-за долгих запросов в результате чего увеличивается replay lag, мы первым делом отстреливаем долгие запросы, которые работают на реплике, потому что они задерживают воспроизведение журналов транзакций.
Если долгие запросы связаны с неоптимальностью самого SQL запроса (выясняем это с помощью EXPLAIN ANALYZE), нужно просто подходить по-другому к этому запросу и переписывать его. Либо есть вариант настройки отдельной реплики для отчетных запросов. Если мы делаем какие-то отчеты, которые долго работают, их нужно выносить на отдельную реплику.
Еще остается вариант просто ждать. Если у нас какой-то лаг на уровне нескольких килобайт или даже десятков мегабайт, но мы считаем, что это приемлемо, мы просто ждем, когда запрос выполнится и лаг сам рассосется. Это тоже вариант, и часто бывает, что он приемлем.
Большой объем WAL
Если мы генерируем большой объем журнала транзакций, нужно уменьшить этот объем в единицу времени, сделать так, чтобы реплике было нужно прожевывать меньше журналов транзакций.
Как правило, это делается с помощью конфигурации. Частичное решение в задании параметра full_page_writes = off. Этот параметр выключает/выключает запись полных образов изменяющихся страниц в журнал транзакций. Это означает, что, когда у нас произошла служебная операция записи контрольной точки (CHECKPOINT), при последующем изменении какого-то блока данных в области shared buffers, в журнал транзакций уйдет полный образ этой страницы, а не только само изменение. При всех последующих изменениях этой же самой страницы, в журнал транзакций будут попадать только изменения. И так до следующей контрольной точки.
После чекпоинта мы записываем полный образ страницы, и это сказывается на объеме записываемого журнала транзакций. Если чекпоинтов в единицу времени довольно много, допустим, в час делается 4 чекпоинта, и полных образов страниц будет записываться тоже очень много, это будет проблемой. Можно отключить запись полных образов и это скажется на объеме WAL. Но опять же это полумера.
Примечание: К рекомендации отключения full_page_writes, стоит отнестись вдумчиво, так как автор в ходе доклада забыл уточнить, что отключение параметра может, при некотором стечение обстоятельств в аварийных ситуациях (повреждение файловой системы или ее журнала, частичная запись в блоки и т.п.) потенциально привести к повреждению файлов базы данных. Поэтому будьте внимательны, отключение параметра может увеличить риск повреждения данных в аварийных ситуациях.
Другая полумера — это увеличить интервал между чекпоинтами. По умолчанию чекпоинт делается каждые 5 минут, и это довольно часто. Как правило, этот интервал увеличивают до 30–60 минут — это вполне приемлемое время, за которое все грязные страницы успевают стать синхронизированными на диск.
Но основной вариант решения — это, конечно же, посмотреть наш workload — какие там сейчас идут тяжелые операции, связанные с изменением данных, и, возможно, постараться эти операции по изменению делать пачками.
Допустим, у нас есть таблица, мы хотим удалить из нее несколько миллионов записей. Оптимальным вариантом будет не удалять эти миллионы разом одним запросом, а разбить их на пачки по 100–200 тысяч, чтобы, во-первых, генерировались небольшие объемы WAL, во-вторых, vacuum успевал проходить по удаленным данным, и следовательно лаг не был таким большим и критичным.
Распухание pg_wal/
Теперь, давайте поговорим, как можно обнаружить, что распух каталог pg_wal/.
По идее PostgreSQL всегда поддерживает его в оптимальном для себя состоянии на уровне определенных файлов конфигурации, и, как правило, он не должен расти выше определенных пределов.
Есть параметр max_wal_size, который определяет максимальное значение. Плюс есть параметр wal_keep_segments — дополнительное количество сегментов, которые мастер хранит для реплики, если вдруг реплика недоступна продолжительное время.
Посчитав сумму max_wal_size и wal_keep_segments, мы можем примерно оценить, сколько места будет занимать каталог pg_wal/. Если он быстро растет и занимает гораздо больше места, чем рассчитанное значение, это значит, что есть какая-то проблема, и нужно с этим что-то делать.
Как обнаружить такие проблемы?
В операционной системе Linux есть команда du -csh. Мы можем просто в мониторинг загнать значение и смотреть, сколько у нас там журналов транзакций; держать посчитанную метку, сколько он должен и сколько он по факту занимает, и как-то реагировать на изменение цифр.
Другое место, где мы смотрим, это представления pg_replication_slots и pg_stat_archiver. Наиболее частыми причинами, почему pg_wal/ занимает много места являются забытые слоты репликации или сломанная архивация. Другие причины также имеют место быть, но на моей практике встречались очень редко.
И, конечно же, всегда бывают ошибки в логах PostgreSQL, связанные именно с архивной командой. Других причин, которые связаны с переполнением pg_wal/, там, к сожалению, не будет. Мы можем там отловить только ошибки архивации.
Варианты проблем:
Тяжелый CRUD — тяжелые операции обновления данных — тяжелые INSERT, DELETE, UPDATE, связанные с изменением нескольких миллионов строк. Если PostgreSQL нужно сделать такую операцию, понятно, что будет генерироваться большой объем журнала транзакций. Он будет храниться в pg_wal/, и это приведет к увеличению занимаемого места. То есть опять же, как я сказал раньше, хорошей практикой является просто разбивать их на пачки, и делать обновление не всего массива, а по 100, 200, 300 тысяч.
Забытый или неиспользуемый слот репликации — другая частая проблема. Люди часто используют логическую репликацию для каких-то своих задач: настраивают шины, которые отправляют данные в Kafka, отправляют данные в стороннее приложение, которое делает декодинг логической репликации в другой формат и как-то их обрабатывают. Логическая репликация, как правило, работает через слоты. Бывает так, что мы настроили слот репликации, поигрались с приложением, поняли, что нам это приложение не подходит, выключили приложение, удалили, а слоты репликации продолжают жить.
PostgreSQL для каждого слота репликации сохраняет сегменты журнала транзакций на случай, если удаленное приложение или реплика снова подключатся к этому слоту, и тогда мастер сможет ему эти журналы транзакций отдать.
Но идет время, к слоту никто не подключается, журналы транзакций копятся, и в какой-то момент занимают 90% места. Нужно выяснять, что же там такое, почему занято так много места. Как правило, этот забытый и неиспользуемый слот нужно просто удалить, и проблема будет решена. Но об этом чуть дальше.
Другим вариантом может быть сломанная archive_command. Когда у нас есть какое-то внешнее хранилище журналов транзакций, которое мы держим для задач аварийного восстановления, обычно настраивается архивная команда, реже настраивается pg_receivexlog. Команда прописанная в аrchive_command — это очень часто, либо отдельная команда, либо какой-то скрипт, который берет сегменты журнала транзакций из pg_wal/ и копирует в архивное хранилище.
Бывает так, что провели какой-то апгрейд системных пакетов, допустим, в rsync версия поменялась, флаги обновились или изменились, либо в какой-то другой команде, которая использовалась в архивной команде, тоже поменялся формат — и скрипт или сама программа которая указана в archive_command ломается. Следовательно архивы перестают копироваться.
Если архивная команда отработала с выходом не 0, то в лог запишется сообщение об этом, а сегмент останется в каталоге pg_wal/. Пока мы не обнаружим, что у нас архивная команда сломалась, сегменты будут копиться, и место также в какой-то момент закончится.
Набор экстренных мер (100% used space):
1. Отстрелить все долгие CRUD запросы, которые выполняются на данный момент на мастере — pg_terminate_backend().
Это могут быть какие-то копии запросов, выполняющиеся бэкапы, апдейты, которые обновляют миллион строк и т.д. Первым делом нам нужно отстрелить эти запросы, чтобы предотвратить дальнейший рост каталога pg_wal/, чтобы новые сегменты не генерировались.
2. Уменьшить так называемое резервируемое место для файлов пользователя root — reserved space ratio (ext filesystems).
Это относится к файловым системам семейства ext и по умолчанию файловая система ext создается с резервным местом 5%. Представьте себе, что у вас файловая система на несколько сотен гигабайт, и 5% — довольно значительно. Поэтому, когда мы видим, что у нас остался 1% свободного места, мы быстро делаем команду tune2fs -m 1. Резервное место сразу становится доступным пользователю PostgreSQL и появляется время для того, чтобы исследовать проблему дальше. Таким образом есть мы откладываем 100% лимит заполненности на некоторое время.
3. Добавить еще места (LVM, ZFS,…).
В случае использования LVM или ZFS, когда администратор резервирует свободное место в пуле LVM или ZFS, он может из этого резервного пула выделить свободное дополнительное место на том, где лежит база, и опять же с помощью команды файловой системы растянуть файловую систему. Таким методом можно экстренно отреагировать на то, что место заканчивается.
4. И самое главное — НИКОГДА, НИЧЕГО, HE УДАЛЯТЬ РУКАМИ ИЗ pg_wal/.
Об этом говорят все постгресисты на всех конференциях и докладах, но люди все равно удаляют, удаляют и удаляют, а базы ломаются. Никогда ничего оттуда удалять нельзя! PostgreSQL сам оттуда периодически удаляет файлы, когда считает нужным. У него есть свои функции, свои алгоритмы, он сам определяет, когда это нужно сделать.
Кстати, pg_xlog/ переименовали в pg_wal/ именно по той причине — слово log сбивает с толку администраторов, и они думают, что, наверное, там какие-то ненужный логи — удалим их!
Что делать дальше
После того, как мы приняли экстренные меры и отложили наступление 100% заполнение CPU, можно перейти к устранению источников проблем.
Сначала нужно проверить workload и миграции. Что у нас там, что команда разработки запустила на этот раз? Может быть, они там хотели обновить какие-то данные, сделать загрузку данных или еще что-то. И на основании этого уже можно принимать архитектурное решение: добавить дополнительный диск, добавить новый tablespace, перенести данные между tablespace.
Дальше проверяем состояние репликации. Если у нас сгенерировалось много журналов транзакций, вполне вероятно, что мог образоваться лаг, и если образовался лаг, то, вполне возможно, что реплика не успела прожевать все журналы транзакций и могла попросту отвалиться. Нужно проверить реплики — все ли с ними в порядке.
Дальше нужно проверить настройки checkpoints_segments/max_wal_size, wal_keep_segments. Вполне возможно, что при конфигурации система, были выбраны слишком большие значения — 10-20 тысяч для wal_keep_segments, либо десятки гигабайт для max_wal_size. Может быть, есть смысл пересмотреть эти настройки и уменьшить их. Тогда PostgreSQL необходимые сегменты просто удалит и каталог pg_wal/ станет меньше.
Нужно проверить слоты репликации через представление pg_replication_slots — нет ли там неактивных слотов. Если они есть, то нужно проверить подписчика, который должен быть подписан на этот слот — все ли с ним в порядке. Если подписчика нет, он был давно удален, нужно слот просто удалить. Тогда проблема легко решается.
Если ошибки связаны с архивированием WAL, мы можем посмотреть эти ошибки в логе, либо посмотреть счетчик ошибок в pg_stat_archiver, там все это есть. Конечно, нужно починить архивную команду, разобраться, почему она не работает, и архивация не происходит.
После всех мер желательно вызывать команду checkpoint. Именно в этой команде зашита функция определения, какие сегменты журнала транзакций уже не нужны постгресу, и он может их спокойно удалить. Подчеркиваю, PostgreSQL сам определяет эти сегменты и сам их удаляет. Ничего не удаляем руками, только через команду checkpoint.
Долгие запросы и конфликты при восстановлении
Как я уже говорил, конфликты при восстановлении, конфликты репликации — это когда выполняющийся запрос на реплике выполняется долго. Он запросил какие-то данные и в этот момент с мастера прилетает изменение этих же самых данных, и репликация входит в конфликт с запросом. И вроде бы запрос нужно продолжить, но и эти данные на реплике тоже нужно изменить.
Основные симптомы — ошибки в логах PostgreSQL или приложения:
- User was holding shared bufer pin for too long.
- User query might have needed to see row versions that must be removed.
- User was holding a relation lock for too long.
- User was or might have been using table space that must be dropped.
- User transaction caused bufer deadlock with recovery.
- User was connected to a database that must be dropped.
Первые 2 пункта — это наиболее частые причины, когда запрос идет именно на те данные, которые должны быть обновлены по репликации. Происходит следующий сценарий: есть параметр, который определяет задержку, которая будет отсчитываться при обнаружении конфликта. Как только эта задержка превысила заданный порог (по умолчанию 30 с), то PostgreSQL завершает запрос и репликация продолжает восстанавливать данные — все супер.
Следующая проблема возникает реже. Как правило, она связана с тем, что репликация с мастера передаёт некоторую информацию о блокировках на мастере в реплику. Если выполняющиеся запросы как-то конфликтуют с этими блокировками, то запрос также через timeout отстреливается и возникает эта ошибка. Такое бывает на миграциях — когда мы делаем ALTER, добавляем индексы в таблицы, такая ошибка может возникать.
Следующие ошибки возникают еще реже. Они обычно связаны с тем, что tablespace или база удалена на мастере, а запрос был запущен и работал с данными этой базы или tablespace. Это возникает редко, и обычно все знают, когда кто-то удаляет базу — мне так кажется.
Как обнаружить?
Для обнаружения у нас есть представления pg_stat_databases, pg_stat_databases_conflicts. В этих представлениях у нас есть информация о конфликтах, и их нужно мониторить. Если у нас есть конфликты, мы начинаем разбираться дальше.
Это действительно становится проблемой, если запросы отстреливаются по конфликту репликации очень часто. Мы считаем, что запросы очень важны нашим пользователям. Пользователи начинают страдать, и это уже проблема. Либо, когда возникает большой лаг репликации вследствие того, что запрос держит репликацию, и это тоже проблема.
Что делать?
Есть несколько вариантов, но все они — выбор наименьшего из зол:
- Увеличить max_standby_streaming_delay (риск лага репликации). Это именно та самая задержка, которая будет отсчитываться при обнаружении конфликта репликации. Тем самым мы увеличиваем риск лага репликации.
- Включить hot_staпdby_feedback (риск распухания таблиц/индексов). Это вариант, когда vacuum нужно почистить какие-то строки, но эти строки пользуются транзакцией на реплике. В этом случае есть риск bloat таблицы индексов. Это тоже одно из зол, которое нужно либо принять, либо понять, нужно включать hot_staпdby_feedback или нет.
- Самый просто вариант для DBA и непростой для разработчика — это переписать долгие запросы. Нужно проверить все запросы, которые выполняются на реплике. Может быть, они написаны не оптимально, для них нет соответствующих индексов, и можно как-то их переписать и пересмотреть, добавить индексы.
- Последний вариант, который, как правило, устраивает и разработчика, и DBA — это настроить выделенную реплику для долгих запросов, например, для отчетных. В таком случае max_standby_streaming_delay задирается максимально. Такая реплика может выполнять долгие отчетные запросы, которые работают часами. При этом она может накапливать лаг, но то, что эта реплика отстает, всех устраивает. Это компромиссный для всех вариант — и отчетные запросы работают, и лаг никому не мешает.
Recovery process: 100% CPU usage
Бывает так, что процесс, который накатывает журнал транзакций, использует 100% ресурсов одного ядра. Он однопоточный, сидит только на одном ядре процессора, и полностью утилизирует его на 100%. Как правило, если посмотреть в pg_stat_replication, можно увидеть, что там большой лаг replay, то есть очень много данных нужно воспроизвести, и реплика не успевает.
Обнаруживаем это через:
- top — это очень быстро и легко проверяется — вы просто увидите 100% CPU usage на recovery process;
- pg_stat_replication — в мониторинге, если он настроен, мы это все быстро увидим.
Что и как искать
Это одна из самых нетривиальных проблем, алгоритмов поиска не сформировано. Как правило, мы прибегаем к использованию утилит:
- perf top/record/report (требуются debug—пакеты);
- GDB;
- Реже pg_waldump.
Нужно посмотреть, какой стек функций, и где функции тратят больше всего времени. Типичным примером может быть workload, связанный с созданием и удалением временных либо обычных таблиц на мастере. Такое бывает, и чтобы удалить таблицу, PostgreSQL нужно просканировать все имеющиеся shared buffers и ссылки на эту таблицу удалить (очень упрощенно). Это довольно трудоемкая операция при воспроизведении журнала транзакций.
Решение
Как решать такие проблемы, тоже не всегда очевидно и зависит от результатов расследования. Где-то можно поменять workload, что-то поправить, где-то нужно написать патч разработчикам: «Я поковырялся в исходном коде и обнаружил, что то-то не оптимально».
Это можно писать в списках рассылки pgsql-hackers, pgsql-bugs, постить и ждать, когда разработчики отреагируют. К счастью, обычно это происходит быстро.
Но еще раз повторюсь — каких-то гарантированных решений здесь, к сожалению, нет.
Итоги
Проблемы потоковой репликации всегда распределены между хостами. Это значит, что причины проблем нужно искать на нескольких узлах и быть готовым к тому, что это распределенная проблема, которая находится не на одном узле.
Источниками проблем часто бывает пользовательская нагрузка. Я имею в виду, что, как правило, источником проблем являются запросы, которые генерирует приложение, и реже — оборудование.
Конечно же, нужно использовать мониторинг, без него — никуда. Добавьте нужные счетчики, которые я упоминал, в мониторинг, и тогда время реакции на проблему будет гораздо меньше.
Встроенные средства, про которые я рассказывал, желательно знать и использовать — тогда времени, которое вы тратите на поиск проблем, потребуется гораздо меньше.
Полезные ссылки
- PostgreSQL official documentation — The Statistics Collector
- PostgreSQL Mailing Lists ( general, performance, hackers)
- PostgreSQL-Consulting company blog
В этом году мы запланировали две конференции для разработчиков высоконагруженных систем и ближайшая, Highload++ Siberia, пройдет уже 25 и 26 июня в Новосибирске. Судя по заявкам, она обещает быть даже круче, чем московская.
- Владислав Клименко и Валерий Панов представят утилиту репликации данных из MySQL в ClickHouse.
- Иван Шаров и Константин Полуэктов расскажут, какие проблемы возникают при миграциях продукта на новые версии базы данных Oracle.
- Николай Голов расскажет как можно реализовать транзакции, если деньги в одном сервисе, услуги — в другом, и у каждого сервиса своя изолированная база.
- Юрий Насретдинов подробно объяснит, для чего VK нужен ClickHouse, сколько хранится данных, и многое другое.