
Текст должен быть в формате UTF-8. Не используйте двойное кодирование.
В Merchant Center поддерживаются такие стандарты кодировки, как UTF-8, UTF-16, Latin-1 и ASCII. Если вы не знаете, какой именно тип кодировки используется в вашем файле, выберите параметр Определять автоматически.
Если вы сохраняете файл в программе «Блокнот», нажмите Сохранить как и выберите ANSI или UTF-8 в поле Кодировка. Если формат кодировки файла отличается от указанных выше, файл не будет обработан.
Важное примечание. Если в XML-файле используется кодировка Latin-1 или UTF-16, необходимо указать это в нем. Для этого в первой строке фида замените фрагмент <?xml version=" 1.0"?> на одно из следующих значений:
- для Latin-1:
<?xml version="1.0" encoding="ISO-8859-1"?>; - для UTF-16:
<?xml version="1.0" encoding="UTF-16"?>.
Инструкции
Шаг 1. Проверьте список товаров с ошибками
- Войдите в аккаунт Merchant Center.
- Перейдите на вкладку Товары в меню навигации и выберите Диагностика.
- Нажмите Проблемы с товарами. Откроется список затронутых позиций.
Как скачать список всех затронутых товаров (в формате .csv)
Как скачать список всех товаров с конкретной проблемой (в формате .csv)
- Найдите проблему в одноименном столбце и нажмите на значок скачивания
 в конце строки.
в конце строки.
Как посмотреть 50 самых популярных товаров с определенной проблемой
- Найдите проблему в одноименном столбце и нажмите Посмотреть примеры в столбце «Затронутые товары».
Шаг 2. Задайте для текста формат UTF-8
- Отфильтруйте данные так, чтобы в столбце Issue title (Название проблемы) отображались только значения Invalid UTF-8 encoding (Недопустимая кодировка UTF-8).
- Проверьте сведения, указанные для товаров с этой проблемой. Исправьте данные в фиде так, чтобы для значений основных атрибутов был использован формат UTF-8.
Шаг 3. Повторно загрузите фид
- После изменения данных о товаре отправьте их повторно, выбрав один из перечисленных ниже способов.
- Добавить фид напрямую
- Как отправить данные с помощью Content API
- Как импортировать данные с платформы электронной торговли
- Перейдите на страницу «Диагностика» и убедитесь, что проблема решена.
Обратите внимание, что изменения на этой странице могут появиться не сразу.
Эта информация оказалась полезной?
Как можно улучшить эту статью?
При запуске скрипта выдается ошибка:
UnicodeDecodeError: 'utf-8' codec can't decode byte 0xc7 in position 0: invalid continuation byte
Все работало на винде, но сейчас перешел на убунту и словил ошибку. IDE PyCharm.
#!/usr/bin/python
# -*- coding: utf8 -*-
import vk
import time
token = "8723b7"
session = vk.Session(access_token=token)
api = vk.api.API(session, v='5.80', land='ru')
adres2 = '//home//sergey//Рабочий стол//Alfa-Forex MetaTrader
4//MQL4//Files//text.txt' #открытая группа
position2 = 0 #открытая группа
with open(adres2) as fh2:
while True:
fh2.seek(position2) #открытая группа
data2 = fh2.read() #открытая группа
position2 = fh2.tell() #открытая группа
if data2:
api.wall.post(owner_id='-11', message=data2)# открытая
группа
time.sleep(3)
ошибка:
/usr/bin/python3.6 /home/sergey/bin/Signal.py Traceback (most recent call last): File "/home/sergey/bin/Signal.py", line 39, in <module> data2 = fh2.read() #открытая группа File "/usr/lib/python3.6/codecs.py", line 321, in decode (result, consumed) = self._buffer_decode(data, self.errors, final) UnicodeDecodeError: 'utf-8' codec can't decode byte 0xc7 in position 0: invalid continuation byte
Объясните как это исправить?
If you need to store UTF8 data in your database, you need a database that accepts UTF8. You can check the encoding of your database in pgAdmin. Just right-click the database, and select «Properties».
But that error seems to be telling you there’s some invalid UTF8 data in your source file. That means that the copy utility has detected or guessed that you’re feeding it a UTF8 file.
If you’re running under some variant of Unix, you can check the encoding (more or less) with the file utility.
$ file yourfilename
yourfilename: UTF-8 Unicode English text
(I think that will work on Macs in the terminal, too.) Not sure how to do that under Windows.
If you use that same utility on a file that came from Windows systems (that is, a file that’s not encoded in UTF8), it will probably show something like this:
$ file yourfilename
yourfilename: ASCII text, with CRLF line terminators
If things stay weird, you might try to convert your input data to a known encoding, to change your client’s encoding, or both. (We’re really stretching the limits of my knowledge about encodings.)
You can use the iconv utility to change encoding of the input data.
iconv -f original_charset -t utf-8 originalfile > newfile
You can change psql (the client) encoding following the instructions on Character Set Support. On that page, search for the phrase «To enable automatic character set conversion».
If you need to store UTF8 data in your database, you need a database that accepts UTF8. You can check the encoding of your database in pgAdmin. Just right-click the database, and select «Properties».
But that error seems to be telling you there’s some invalid UTF8 data in your source file. That means that the copy utility has detected or guessed that you’re feeding it a UTF8 file.
If you’re running under some variant of Unix, you can check the encoding (more or less) with the file utility.
$ file yourfilename
yourfilename: UTF-8 Unicode English text
(I think that will work on Macs in the terminal, too.) Not sure how to do that under Windows.
If you use that same utility on a file that came from Windows systems (that is, a file that’s not encoded in UTF8), it will probably show something like this:
$ file yourfilename
yourfilename: ASCII text, with CRLF line terminators
If things stay weird, you might try to convert your input data to a known encoding, to change your client’s encoding, or both. (We’re really stretching the limits of my knowledge about encodings.)
You can use the iconv utility to change encoding of the input data.
iconv -f original_charset -t utf-8 originalfile > newfile
You can change psql (the client) encoding following the instructions on Character Set Support. On that page, search for the phrase «To enable automatic character set conversion».
Зачем эта статья?
Об обработке текстов на естественном языке сейчас знают все. Все хоть раз пробовали задавать вопрос Сири или Алисе, пользовались Grammarly (это не реклама), пробовали генераторы стихов, текстов… или просто вводили запрос в Google. Да, вот так просто. На самом деле Google понимает, что вы от него хотите, благодаря штукам, которые умеют обрабатывать и анализировать естественную речь в вашем запросе.
При анализе текста мы можем столкнуться с ситуациями, когда текст содержит специфические символы, которые необходимо проанализировать наравне с «простым текстом» (взять даже наши горячо любимые вставки на французском из «Война и мир») или формулы, например. В таком случае обработка текста может усложниться.
Вы можете заметить, что если ввести в поисковую строку запрос с символами с ударением (так называемый модифицирующий акут), к примеру «ó», поисковая система может показать результаты, содержащие слова из вашего запроса, символы с ударением уже выглядят как обычные символы.
Обратите внимание на следующий запрос:

Запрос содержит символ с модифицирующим акутом, однако во втором результате мы можем заметить, что выделено найденное слово из запроса, только вот оно не содержит вышеупомянутый символ, просто букву «о».
Конечно, уже есть много готовых инструментов, которые довольно неплохо справляются с обработкой текстов и могут делать разные крутые вещи, но я не об этом хочу вам поведать. Я не буду рассказывать про nltk, стемминг, лемматизацию и т.п. Я хочу опуститься на несколько ступенек ниже и обсудить некоторые тонкости кодировок, байтов, их обработки.
Откуда взялась статья?
Одним из важных составляющих в области ИИ является обработка текстов на естественном языке. В процессе изучения данной тематики я начал задавать себе вопросы, которые в конечном итоге привели меня к изучению кодировок, представлению текстов в памяти, как они преобразуются, приводятся к нормальной форме. Я плохо понимал эту тему в начале, потребовалось немало времени и мозгового ресурса, чтобы понять, принять и запомнить некоторые вещи. Написанием данной статьи я хочу облегчить жизнь людям, которые столкнутся с необходимостью чтения и обработки текстов на Python и самому закрепить изученное. А некоторыми полезными поинтами своего изучения я постараюсь поделиться в данной статье.
Важная ремарка: я не являюсь специалистом в области обработки текстов. Изложенный материал является результатом исключительно любительского изучения.
Проблема чтения файлов
Допустим, у нас есть файл с текстом. Нам нужно этот текст прочитать. Казалось бы, пиши себе такой вот скрипт для чтения из файла да и радуйся:
with open("some_text.txt", "r") as file:
content = file.read()
print(content)В файле содержится вот такое вот изречение:
pitónчто переводится с испанского как питон. Однако консоль OC Windows 10 покажет нам немного другой результат:
C:myhabrTextsInPython> python .script1.py
pitónСейчас мы разберёмся, что именно пошло не так и по какой причине.
Кодировка
Думаю, это не будет сюрпризом, если я скажу, что любой символ, который заносится в память компьютера, хранится в виде числа, а не в виде литерала. Это число определяется как идентификатор или кодовая позиция символа. Кодировка определяет, какое именно число будет ассоциировано с символом.
Предположим, у нас есть некоторый файл с неизвестным содержимым, и нам нужно его прочитать, однако мы не знаем, какая у файла кодировка. Попробуем декодировать содержимое файла.
with open("simple_text.txt", "r") as file:
text = file.read()
print(text)Посмотрим на результат:
C:myhabrTextsInPython> python .script2.py
ÿþ<♦8♦@♦Очень интересно, ничего непонятно. По умолчанию Python использует кодировку utf-8, но видимо запись в файл происходила не с её помощью. Здесь нам придёт на помощь дополнительный параметр функции open — параметр encoding, который позволяет указать конкретную кодировку, в которой следует прочитать файл (или записывать в него). Попробуем перебрать несколько кодировок и найти подходящую.
codecs = ["cp1252", "cp437", "utf-16be", "utf-16"]
for codec in codecs:
with open("simple_text.txt", "r", encoding=codec) as file:
text = file.read()
print(codec.rjust(12), "|", text)Результат:
C:myhabrTextsInPython> python .script3.py
cp1252 | ÿþ<8@
cp437 | ■<8@
utf-16be | 㰄㠄䀄
utf-16 | мирРазные кодировки расшифровывают байты из файла по-разному, то есть разным кодовым позициям могут соотвествовать разные символы. Пример примитивный, несложно догадаться, что истинная кодировка файла — это utf-16.
Важный поинт: при записи и чтении из файлов следует указывать конкретную кодировку, это позволит избежать путаницы в дальнейшем.
Ошибки, связанные с кодировками
При возникновении ошибки, связанной с кодировками, интерпретатор выдаст одно из следующих исключений:
-
UnicodeError. Это общее исключение для ошибок кодировки. -
UnicodeDecodeError. Данное исключение возбуждается, если встречается кодовая позиция, которая отсутствует в кодировке. -
UnicodeEncodeError. А это исключение возбуждается, когда символ, который необходимо закодировать, незнаком для кодировки.
Попытка выполнения вот такого кода (в файле всё ещё содержится испанский питон):
with open("some_text.txt", "r", encoding="ascii") as file:
file.read()даст нам следующий результат:
UnicodeDecodeError: 'ascii' codec can't decode byte 0xc3 in position 3: ordinal not in range(128)Кодировка ASCII не поддерживает никакой алфавит, кроме английского. Поэтому декодирование символа «ó» вызывает у ASCII сложности. Однако Python всемогущ и есть механизм, который позволяет обработать ошибки кодировок. Это дополнительный параметр методов encode и decode — параметр errors. Он может принимать следующие значения:
Для обеих функций:
|
Обозначение |
Суть |
|
|
Значение по умолчанию. Несоотвествующие кодировке символы возбуждают исключения |
|
|
Несоответсвующие символы пропускаются без возбуждения исключений. |
Только для метода encode:
|
Обозначение |
Суть |
|---|---|
|
|
Несоотвествующие символы заменяются на символ |
|
|
Несоответствующие символы заменяются на соответсвующие значения XML. |
|
|
Несоответствующие символы заменяются на определённые последовательности с обратным слэшем. |
|
|
Несоответствующие символы заменяются на имена этих символов, которые берутся из базы данных Unicode. |
Также отдельно выделены значения surrogatepass и surrogateescape.
Приведём пример использования таких обработчиков:
>>> text = "pitón"
>>> text.encode("ascii", errors="ignore")
b'pitn'
>>> text.encode("ascii", errors="replace")
b'pit?n'
>>> text.encode("ascii", errors="xmlcharrefreplace")
b'pitón'
>>> text.encode("ascii", errors="backslashreplace")
b'pitxf3n'
>>> text.encode("ascii", errors="namereplace")
b'pitN{LATIN SMALL LETTER O WITH ACUTE}n'Важный поинт: если в текстах могут встретиться неожиданные для кодировки символы, во избежание возбуждения исключений можно использовать обработчики.
Cворачивание регистра
Сворачивание регистра — это попытка унифицировать текст любого представления к канонической форме. Например, приведение всего текста в нижний регистр. Также над текстом производятся некоторые преобразования (например, немецкая «эсцет» — «ß» — преобразуется в «ss»). В Python 3.3 появился метод str.casefold(), который как раз выполняет сворачивание регистра. Если текст содержит только символы кодировки latin1, результат применения этого метода будет аналогичен методу str.lower().
И по классике приведём пример:
>>> text = "Die größte Stadt der Welt liegt in China"
>>> text.casefold()
'die grösste stadt der welt liegt in china'В результате применённый метод не только привёл весь текст к нижнему регистру, но и преобразовал специфический немецкий символ.
Важный поинт: привести текст можно не только методом str.lower(), но и методом str.casefold(), который может выполнить дополнительные преобразования текста.
Нормализация
Нормализация — это полноценное приведение текста к единому представлению.
Чтобы обозначить важность нормализации, приведём простой пример:
letter1 = "µ"
letter2 = "μ"Внешне два этих символа выглядят абсолютно одинаково. Однако если мы попытаемся вывести имена этих символов, как их видит интерпретатор Python’a, результат нас порядком удивит.
В Python есть отличный встроенный модуль, который содержит данные о символах Unicode, их имена, являются ли они цифрамии и т.п. (методы по типу str.isdigit() берут информацию из этих данных). Воспользуемся данным модулем, чтобы вывести имена символов, исходя из информации, которая содержится в базе данных Unicode.
import unicodedata
letter1 = "µ"
letter2 = "μ"
print(unicodedata.name(letter1))
print(unicodedata.name(letter2))Результат выполнения данного кода:
C:myhabrTextsInPython> python .script7.py
MICRO SIGN
GREEK SMALL LETTER MUИтак, интерпретатор Python’a видит эти символы как два разных, но в стандарте Unicode они имеют одинаковое отображение.Такие символы называют каноническими эквивалентами. Приложения будут считать два этих символа одинаковыми, но не интерпретатор.
Посмотрим на ещё один пример:
>>> s1 = 'café'
>>> s2 = 'cafeu0301'
>>> s1, s2
('café', 'café')
>>> s1 == s2
False
>>> len(s1), len(s2)
(4, 5)
Данные символы также будут являться каноническими эквивалентами. Из примера мы видим, что символ «é» в стандарте Unicodeможет быть представлен двумя способами, которые к тому же имеют разную длину. Символ «é» может быть представлен одним или двумя байтами.
Решением таких конфликтов занимается нормализация. Она реализована в Python в функции unicodedata.normalize.Первым аргумент является так называемая форма нормализации — нормализации строк Unicode, которые позволяют определить, эквивалентны ли какие-либо две строки Unicode друг другу. Всего предлагается четыре формы:
|
Форма |
Описание |
|---|---|
|
Normalization Form D (NFD) |
Canonical Decomposition |
|
Normalization Form C (NFC) |
Canonical Decomposition, следующая за Canonical Composition |
|
Normalization Form KD (NFKD) |
Compatibility Decomposition |
|
Normalization Form KC (NFKC) |
Compatibility Decomposition, следующая за Canonical Composition |
Разберём каждую форму немного подробнее.
-
NFC
При указании данной формы нормализации происходит каноническая композиция (как, собственно, и гласит название) кодовых позиций с целью получения самой короткой эквивалентной строки.
>>> unicodedata.normalize("NFC", s1), unicodedata.normalize("NFC", s2)
('café', 'café')
>>> len(unicodedata.normalize("NFC", s1)), len(unicodedata.normalize("NFC", s2))
(4, 4)
>>> unicodedata.normalize("NFC", s1) == unicodedata.normalize("NFC", s2)
True
>>> len(unicodedata.normalize("NFC", s1)) == len(unicodedata.normalize("NFC", s2))
TrueИтак, нормализация обеих строк внешне их не изменила, однако длина строки s2 стала равной 4 (т.е. на один байт меньше). Была произведена композиция байтов eu0301, которые являлись отображением «é». Данная последовательность была заменена на минимальное представление символа, т.е. теперь представление этого символа для интерпретатора выглядит как в строке s1. Как результат, мы видим, что длина нормализованных строк стала равной, и сами строки также стали равны.
-
NFD
С этой формой ситуация аналогичная, только происходит декомпозиция байтов, т.е. разложение символа на несколько байт.
>>> unicodedata.normalize("NFD", s1), unicodedata.normalize("NFD", s2)
('café', 'café')
>>> len(unicodedata.normalize("NFD", s1)), len(unicodedata.normalize("NFD", s2))
(5, 5)
>>> unicodedata.normalize("NFD", s1) == unicodedata.normalize("NFD", s2)
True
>>> len(unicodedata.normalize("NFD", s1)) == len(unicodedata.normalize("NFD", s2))
TrueЗдесь мы видим, что длина строки s1 увеличилась на один байт. Думаю, уже несложно догадаться, почему.
На данном этапе настал момент ввести понятие символа совместимости. Символы совместимости (compatibility characters) были введены в Unicode ради совместимости с другими стандартами, в частности, стандарты, которые предшествовали Unicode. Это означает, что некоторые символы могут встречаться в стандарте несколько раз. Мы уже могли наблюдать это явление в начале этого раздела на примере с символом «мю». Он считается символом совместимости.
-
NFKC и NFKD
При данных формах нормализации символы совместимости заменяются на его более предпочтительное представление, что также называется совместимой декомпозицией. Однако при данных формах нормализации может быть потеряно форматирование.
Немного модифицируем наш пример из начала раздела. Выведем кодовые позиции символов до и после нормализации:
import unicodedata
letter1 = "µ"
letter2 = "μ"
print("Before normalizing:", ord(letter1), ord(letter2))
letter1 = unicodedata.normalize("NFKC", letter1)
letter2 = unicodedata.normalize("NFKC", letter2)
print("After normalizing:", ord(letter1), ord(letter2))И результат выполнения кода:
Before normalizing: 181 956
After normalizing: 956 956Итак, мы видим, что первый символ (который являлся знаком «микро») был заменён на греческую «мю», т.е. более предпочтительное представление символа. Таким образом, если необходимо, например, провести частотный анализ текста, формы нормализации, которые затрагивают символы совместимости, могут помочь с этим, приводя символы совместимости к единому представлению.
Важный поинт: нормализация может очень помочь для поиска валидных документов или индексирования текста. Если вы занимаетесь разработкой таких систем, не стоит сбрасывать алгоритмы нормализации со счетов.
Дополнительные материалы: что использовалось в статье и что почитать по теме
«Fluent Python», Лучано Ромальо
В этой книге целая глава посвящена изучению строк, байтов и Unicode (Глава 4. Тексты и байты). Она есть на русском и английском языках, но в русском переводе допущено немало ошибок, так что открывайте русский вариант на свой страх и риск. Материал статьи в большей степени опирается на данную книгу. Некоторые примеры также взяты оттуда.
Документация для Unicode на официальном сайте Python
Куда ж без неё, родимой. Там тоже можно найти немало полезной информации, если вам понадобится работать с текстами и делать больше, чем просто считывание из файла. Хотя в некоторых случаях и на этом можно споткнуться.
Unicode® Standard Annex
Это части стандарта Unicode, которые выложены в открытый доступ в виде отдельных статей. Почитать их можно вот здесь.
Когда я только начинал изучать тему разработки сайтов, кракозябры были одной из моих постоянных проблем. Создал HTML-страницу — в браузере кракозябры, установил денвер и попробовал создать сайт на PHP — снова вместо букв кракозябры. Скачал иностранную тему, подключился к базе данных — та же проблема.
На своих сайтах я обычно использую UTF-8 (это такая кодировка текста, она ещё называется юникод), соответственно она будет присутствовать во всех примерах в этой статье.
1. UTF-8 без BOM
Начнём с самой простой проблемы. Вы создали какой-то HTML-файл, открыли его в браузере и получили:
")
Проблема актуальна в основном для пользователей Windows, на маке я с таким ни разу не сталкивался.
Решение проблемы зависит в основном от того, каким редактором вы пользуетесь. Для пользователей Windows я рекомендую бесплатный офигительный Notepad++.
Значит, открываем файл в Notepad++ и переходим в Кодировки > Преобразовать в UTF-8 без BOM. Вопрос — почему без BOM? Потому что с BOM у вас будут постоянно вставляться пустые символы (на самом деле они не пустые, у них тоже есть своя функция, но нам она в данном случае не нужна) куда не надо, а для PHP это уже критично.

2. Мета тег charset
Если вы сделали то, что я описывал в предыдущем шаге и ваша проблема не разрешилась, тогда самое время испробовать второй метод устранения кракозябров.
Всё, что нам требуется, это вставить следующий код между тегами <head> сайта. Прежде всего проверьте, возможно этот метатег у вас уже присутствует. Если да, то посмотрите какое у него стоит значение параметра charset.
В темах WordPress обычно этот тег уже имеется по умолчанию и выглядит следующим образом:
<meta charset="<?php bloginfo('charset'); ?>" />
3. .htaccess
Если русские буквы до сих пор отображаются кракозябрами, тогда открываем ваш .htaccess, который лежит в корне сайта и вставляем туда с новой строки это:
4. Заголовки сервера через header()
Ещё один способ определения кодировки. На этот раз через PHP. На WordPress никогда не приходилось им пользоваться.
header('Content-Type: text/html; charset=utf-8');
Важно! Этот код должен вставляться до того, как будет что-либо выведено на странице сайта, иначе — ошибка.
5. Проблемы с последним символом при обрезке строки
На многих сайтах встречаются блоки с популярными записями, последними комментариями, отзывами и так далее. Обычно в таких обзорных блоках выводится часть записи/комментария/отзыва и кнопка «читать далее». Так вот, для того, чтобы вывести первые несколько предложений или первые несколько слов текста, используется функция PHP substr(). Конечно же в основном я имею ввиду англоязычные темы, которых так много в интернете. Даже если у этих тем есть локализация — то есть вроде бы она на русском — переведена админка, переведён практически весь сайт, но при этом мы встречаем такие вот косяки:
")
Как решить эту проблему?
Легко — всё что нам нужно, это найти функцию substr() в коде и поменять её на mb_substr().
Если после этого у вас полезут ошибки на сайт, то скорее всего multibyte-функции не поддерживаются вашим хостингом, первое, что вам следует сделать, это написать в супорт и спросить, нельзя ли их подключить на ваш аккаунт. Если нет, меняем хостинг, например на тот, которым пользуюсь я.
6. MySQL
У меня не раз бывало такое, что я подключался к MySQL, вытаскивал какие-нибудь данные, и при их выводе на сайте, текст отображался кракозябрами.
Такое может произойти, если кодировка вашего сайта не совпадает с кодировкой базы данных, к которой вы подключаетесь. В WordPress обычно таких проблем не бывает.
Для того, чтобы исправить это, после подключения к БД, делаем следующее:
mysql_query("SET NAMES 'UTF8'");
Если ни один из вышеперечисленных методов вам не помог, оставляйте комментарий и попробуем вместе разобраться.

Миша
Впервые познакомился с WordPress в 2009 году. Организатор и спикер на конференциях WordCamp. Преподаватель в школе Нетология.
Пишите, если нужна помощь с сайтом или разработка с нуля.
Здравствуйте, уважаемые читатели блога KtoNaNovenkogo.ru. Сегодня мы поговорим с вами про то, откуда берутся кракозябры на сайте и в программах, какие кодировки текста существуют и какие из них следует использовать. Подробно рассмотрим историю их развития, начиная от базовой ASCII, а также ее расширенных версий CP866, KOI8-R, Windows 1251 и заканчивая современными кодировками консорциума Юникод UTF 16 и 8.

Кому-то эти сведения могут показаться излишними, но знали бы вы, сколько мне приходит вопросов именно касаемо вылезших кракозябров (не читаемого набора символов). Теперь у меня будет возможность отсылать всех к тексту этой статьи и самостоятельно отыскивать свои косяки. Ну что же, приготовьтесь впитывать информацию и постарайтесь следить за ходом повествования.
ASCII — базовая кодировка текста для латиницы
Развитие кодировок текстов происходило одновременно с формированием отрасли IT, и они за это время успели претерпеть достаточно много изменений. Исторически все начиналось с довольно-таки не благозвучной в русском произношении EBCDIC, которая позволяла кодировать буквы латинского алфавита, арабские цифры и знаки пунктуации с управляющими символами.
Но все же отправной точкой для развития современных кодировок текстов стоит считать знаменитую ASCII (American Standard Code for Information Interchange, которая по-русски обычно произносится как «аски»). Она описывает первые 128 символов из наиболее часто используемых англоязычными пользователями — латинские буквы, арабские цифры и знаки препинания.
Еще в эти 128 знаков, описанных в ASCII, попадали некоторые служебные символы навроде скобок, решеток, звездочек и т.п. Собственно, вы сами можете увидеть их:
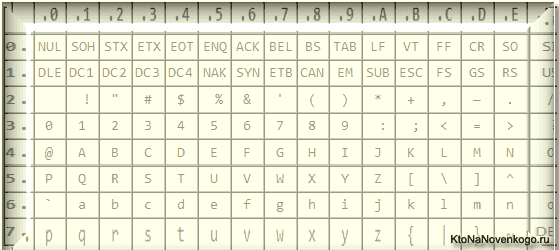
Именно эти 128 символов из первоначального вариант ASCII стали стандартом, и в любой другой кодировке вы их обязательно встретите и стоять они будут именно в таком порядке.
Но дело в том, что с помощью одного байта информации можно закодировать не 128, а целых 256 различных значений (двойка в степени восемь равняется 256), поэтому вслед за базовой версией Аски появился целый ряд расширенных кодировок ASCII, в которых можно было кроме 128 основных знаков закодировать еще и символы национальной кодировки (например, русской).
Тут, наверное, стоит еще немного сказать про системы счисления, которые используются при описании. Во-первых, как вы все знаете, компьютер работает только с числами в двоичной системе, а именно с нулями и единицами («булева алгебра», если кто проходил в институте или в школе). Один байт состоит из восьми бит, каждый из которых представляет из себя двойку в степени, начиная с нулевой, и до двойки в седьмой:
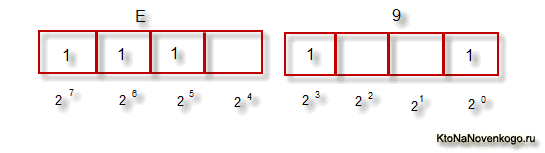
Не трудно понять, что всех возможных комбинаций нулей и единиц в такой конструкции может быть только 256. Переводить число из двоичной системы в десятичную довольно просто. Нужно просто сложить все степени двойки, над которыми стоят единички.
В нашем примере это получается 1 (2 в степени ноль) плюс 8 (два в степени 3), плюс 32 (двойка в пятой степени), плюс 64 (в шестой), плюс 128 (в седьмой). Итого получает 233 в десятичной системе счисления. Как видите, все очень просто.
Но если вы присмотритесь к таблице с символами ASCII, то увидите, что они представлены в шестнадцатеричной кодировке. Например, «звездочка» соответствует в Аски шестнадцатеричному числу 2A. Наверное, вам известно, что в шестнадцатеричной системе счисления используются кроме арабских цифр еще и латинские буквы от A (означает десять) до F (означает пятнадцать).
Ну так вот, для перевода двоичного числа в шестнадцатеричное прибегают к следующему простому и наглядному способу. Каждый байт информации разбивают на две части по четыре бита, как показано на приведенном выше скриншоте. Т.о. в каждой половинке байта двоичным кодом можно закодировать только шестнадцать значений (два в четвертой степени), что можно легко представить шестнадцатеричным числом.
Причем, в левой половине байта считать степени нужно будет опять начиная с нулевой, а не так, как показано на скриншоте. В результате, путем нехитрых вычислений, мы получим, что на скриншоте закодировано число E9. Надеюсь, что ход моих рассуждений и разгадка данного ребуса вам оказались понятны. Ну, а теперь продолжим, собственно, говорить про кодировки текста.
Расширенные версии Аски — кодировки CP866 и KOI8-R с псевдографикой
Итак, мы с вами начали говорить про ASCII, которая являлась как бы отправной точкой для развития всех современных кодировок (Windows 1251, юникод, UTF 8).
Изначально в нее было заложено только 128 знаков латинского алфавита, арабских цифр и еще чего-то там, но в расширенной версии появилась возможность использовать все 256 значений, которые можно закодировать в одном байте информации. Т.е. появилась возможность добавить в Аски символы букв своего языка.
Тут нужно будет еще раз отвлечься, чтобы пояснить — зачем вообще нужны кодировки текстов и почему это так важно. Символы на экране вашего компьютера формируются на основе двух вещей — наборов векторных форм (представлений) всевозможных знаков (они находятся в файлах со шрифтами, которые установлены на вашем компьютере) и кода, который позволяет выдернуть из этого набора векторных форм (файла шрифта) именно тот символ, который нужно будет вставить в нужное место.
Понятно, что за сами векторные формы отвечают шрифты, а вот за кодирование отвечает операционная система и используемые в ней программы. Т.е. любой текст на вашем компьютере будет представлять собой набор байтов, в каждом из которых закодирован один единственный символ этого самого текста.
Программа, отображающая этот текст на экране (текстовый редактор, браузер и т.п.), при разборе кода считывает кодировку очередного знака и ищет соответствующую ему векторную форму в нужном файле шрифта, который подключен для отображения данного текстового документа. Все просто и банально.
Значит, чтобы закодировать любой нужный нам символ (например, из национального алфавита), должно быть выполнено два условия — векторная форма этого знака должна быть в используемом шрифте и этот символ можно было бы закодировать в расширенных кодировках ASCII в один байт. Поэтому таких вариантов существует целая куча. Только лишь для кодирования символов русского языка существует несколько разновидностей расширенной Аски.
Например, изначально появилась CP866, в которой была возможность использовать символы русского алфавита и она являлась расширенной версией ASCII.
Т.е. ее верхняя часть полностью совпадала с базовой версией Аски (128 символов латиницы, цифр и еще всякой лабуды), которая представлена на приведенном чуть выше скриншоте, а вот уже нижняя часть таблицы с кодировкой CP866 имела указанный на скриншоте чуть ниже вид и позволяла закодировать еще 128 знаков (русские буквы и всякая там псевдографика):

Видите, в правом столбце цифры начинаются с 8, т.к. числа с 0 до 7 относятся к базовой части ASCII (см. первый скриншот). Т.о. русская буква «М» в CP866 будет иметь код 9С (она находится на пересечении соответствующих строки с 9 и столбца с цифрой С в шестнадцатеричной системе счисления), который можно записать в одном байте информации, и при наличии подходящего шрифта с русскими символами эта буква без проблем отобразится в тексте.
Откуда взялось такое количество псевдографики в CP866? Тут все дело в том, что эта кодировка для русского текста разрабатывалась еще в те мохнатые года, когда не было такого распространения графических операционных систем как сейчас. А в Досе, и подобных ей текстовых операционках, псевдографика позволяла хоть как-то разнообразить оформление текстов и поэтому ею изобилует CP866 и все другие ее ровесницы из разряда расширенных версий Аски.
CP866 распространяла компания IBM, но кроме этого для символов русского языка были разработаны еще ряд кодировок, например, к этому же типу (расширенных ASCII) можно отнести KOI8-R:

Принцип ее работы остался тот же самый, что и у описанной чуть ранее CP866 — каждый символ текста кодируется одним единственным байтом. На скриншоте показана вторая половина таблицы KOI8-R, т.к. первая половина полностью соответствует базовой Аски, которая показана на первом скриншоте в этой статье.
Среди особенностей кодировки KOI8-R можно отметить то, что русские буквы в ее таблице идут не в алфавитном порядке, как это, например, сделали в CP866.
Если посмотрите на самый первый скриншот (базовой части, которая входит во все расширенные кодировки), то заметите, что в KOI8-R русские буквы расположены в тех же ячейках таблицы, что и созвучные им буквы латинского алфавита из первой части таблицы. Это было сделано для удобства перехода с русских символов на латинские путем отбрасывания всего одного бита (два в седьмой степени или 128).
Windows 1251 — современная версия ASCII и почему вылезают кракозябры
Дальнейшее развитие кодировок текста было связано с тем, что набирали популярность графические операционные системы и необходимость использования псевдографики в них со временем пропала. В результате возникла целая группа, которая по своей сути по-прежнему являлись расширенными версиями Аски (один символ текста кодируется всего одним байтом информации), но уже без использования символов псевдографики.
Они относились к так называемым ANSI кодировкам, которые были разработаны американским институтом стандартизации. В просторечии еще использовалось название кириллица для варианта с поддержкой русского языка. Примером такой может служить Windows 1251.
Она выгодно отличалась от используемых ранее CP866 и KOI8-R тем, что место символов псевдографики в ней заняли недостающие символы русской типографики (окромя знака ударения), а также символы, используемые в близких к русскому славянских языках (украинскому, белорусскому и т.д.):
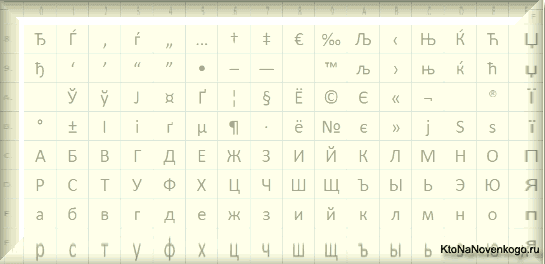
Из-за такого обилия кодировок русского языка, у производителей шрифтов и производителей программного обеспечения постоянно возникала головная боль, а у нас с вам, уважаемые читатели, зачастую вылезали те самые пресловутые кракозябры, когда происходила путаница с используемой в тексте версией.
Очень часто они вылезали при отправке и получении сообщений по электронной почте, что повлекло за собой создание очень сложных перекодировочных таблиц, которые, собственно, решить эту проблему в корне не смогли, и зачастую пользователи для переписки использовали транслит латинских букв, чтобы избежать пресловутых кракозябров при использовании русских кодировок подобных CP866, KOI8-R или Windows 1251.
По сути, кракозябры, вылазящие вместо русского текста, были результатом некорректного использования кодировки данного языка, которая не соответствовала той, в которой было закодировано текстовое сообщение изначально.
Допустим, если символы, закодированные с помощью CP866, попробовать отобразить, используя кодовую таблицу Windows 1251, то эти самые кракозябры (бессмысленный набор знаков) и вылезут, полностью заменив собой текст сообщения.

Аналогичная ситуация очень часто возникает при создании сайтов на WordPress и Joomla, форумов или блогов, когда текст с русскими символами по ошибке сохраняется не в той кодировке, которая используется на сайте по умолчанию, или же не в том текстовом редакторе, который добавляет в код отсебятину не видимую невооруженным глазом.
В конце концов такая ситуация с множеством кодировок и постоянно вылезающими кракозябрами многим надоела, появились предпосылки к созданию новой универсальной вариации, которая бы заменила собой все существующие и решила бы, наконец, на корню проблему с появлением не читаемых текстов. Кроме этого существовала проблема языков подобных китайскому, где символов языка было гораздо больше, чем 256.
Юникод (Unicode) — универсальные кодировки UTF 8, 16 и 32
Эти тысячи знаков языковой группы юго-восточной Азии никак невозможно было описать в одном байте информации, который выделялся для кодирования символов в расширенных версиях ASCII. В результате был создан консорциум под названием Юникод (Unicode — Unicode Consortium) при сотрудничестве многих лидеров IT индустрии (те, кто производит софт, кто кодирует железо, кто создает шрифты), которые были заинтересованы в появлении универсальной кодировки текста.
Первой вариацией, вышедшей под эгидой консорциума Юникод, была UTF 32. Цифра в названии кодировки означает количество бит, которое используется для кодирования одного символа. 32 бита составляют 4 байта информации, которые понадобятся для кодирования одного единственного знака в новой универсальной кодировке UTF.
В результате чего, один и тот же файл с текстом, закодированный в расширенной версии ASCII и в UTF-32, в последнем случае будет иметь размер (весить) в четыре раза больше. Это плохо, но зато теперь у нас появилась возможность закодировать с помощью ЮТФ число знаков, равное двум в тридцать второй степени (миллиарды символов, которые покроют любое реально необходимое значение с колоссальным запасом).
Но многим странам с языками европейской группы такое огромное количество знаков использовать в кодировке вовсе и не было необходимости, однако при задействовании UTF-32 они ни за что ни про что получали четырехкратное увеличение веса текстовых документов, а в результате и увеличение объема интернет трафика и объема хранимых данных. Это много, и такое расточительство себе никто не мог позволить.
В результате развития Юникода появилась UTF-16, которая получилась настолько удачной, что была принята по умолчанию как базовое пространство для всех символов, которые у нас используются. Она использует два байта для кодирования одного знака. Давайте посмотрим, как это дело выглядит.
В операционной системе Windows вы можете пройти по пути «Пуск» — «Программы» — «Стандартные» — «Служебные» — «Таблица символов». В результате откроется таблица с векторными формами всех установленных у вас в системе шрифтов. Если вы выберете в «Дополнительных параметрах» набор знаков Юникод, то сможете увидеть для каждого шрифта в отдельности весь ассортимент входящих в него символов.
Кстати, щелкнув по любому из них, вы сможете увидеть его двухбайтовый код в формате UTF-16, состоящий из четырех шестнадцатеричных цифр:
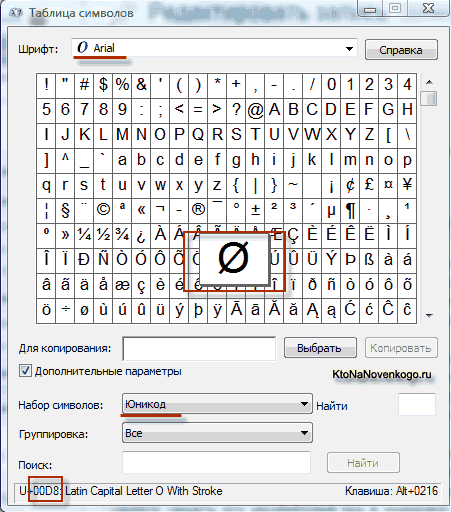
Сколько символов можно закодировать в UTF-16 с помощью 16 бит? 65 536 (два в степени шестнадцать), и именно это число было принято за базовое пространство в Юникоде. Помимо этого существуют способы закодировать с помощью нее и около двух миллионов знаков, но ограничились расширенным пространством в миллион символов текста.
Но даже эта удачная версия кодировки Юникода не принесла особого удовлетворения тем, кто писал, допустим, программы только на английском языке, ибо у них, после перехода от расширенной версии ASCII к UTF-16, вес документов увеличивался в два раза (один байт на один символ в Аски и два байта на тот же самый символ в ЮТФ-16).
Вот именно для удовлетворения всех и вся в консорциуме Unicode было решено придумать кодировку переменной длины. Ее назвали UTF-8. Несмотря на восьмерку в названии, она действительно имеет переменную длину, т.е. каждый символ текста может быть закодирован в последовательность длиной от одного до шести байт.
На практике же в UTF-8 используется только диапазон от одного до четырех байт, потому что за четырьмя байтами кода ничего уже даже теоретически не возможно представить. Все латинские знаки в ней кодируются в один байт, так же как и в старой доброй ASCII.
Что примечательно, в случае кодирования только латиницы, даже те программы, которые не понимают Юникод, все равно прочитают то, что закодировано в ЮТФ-8. Т.е. базовая часть Аски просто перешла в это детище консорциума Unicode.
Кириллические же знаки в UTF-8 кодируются в два байта, а, например, грузинские — в три байта. Консорциум Юникод после создания UTF 16 и 8 решил основную проблему — теперь у нас в шрифтах существует единое кодовое пространство. И теперь их производителям остается только исходя из своих сил и возможностей заполнять его векторными формами символов текста. Сейчас в наборы даже эмодзи смайлики добавляют.
В приведенной чуть выше «Таблице символов» видно, что разные шрифты поддерживают разное количество знаков. Некоторые насыщенные символами Юникода шрифты могут весить очень прилично. Но зато теперь они отличаются не тем, что они созданы для разных кодировок, а тем, что производитель шрифта заполнил или не заполнил единое кодовое пространство теми или иными векторными формами до конца.
Кракозябры вместо русских букв — как исправить
Давайте теперь посмотрим, как появляются вместо текста кракозябры или, другими словами, как выбирается правильная кодировка для русского текста. Собственно, она задается в той программе, в которой вы создаете или редактируете этот самый текст, или же код с использованием текстовых фрагментов.
Для редактирования и создания текстовых файлов лично я использую очень хороший, на мой взгляд, Html и PHP редактор Notepad++. Впрочем, он может подсвечивать синтаксис еще доброй сотни языков программирования и разметки, а также имеет возможность расширения с помощью плагинов. Читайте подробный обзор этой замечательной программы по приведенной ссылке.
В верхнем меню Notepad++ есть пункт «Кодировки», где у вас будет возможность преобразовать уже имеющийся вариант в тот, который используется на вашем сайте по умолчанию:
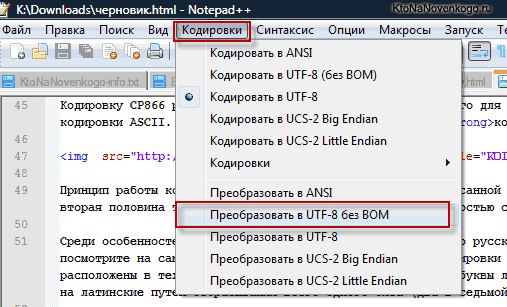
В случае сайта на Joomla 1.5 и выше, а также в случае блога на WordPress следует во избежании появления кракозябров выбирать вариант UTF 8 без BOM. А что такое приставка BOM?
Дело в том, что когда разрабатывали кодировку ЮТФ-16, зачем-то решили прикрутить к ней такую вещь, как возможность записывать код символа, как в прямой последовательности (например, 0A15), так и в обратной (150A). А для того, чтобы программы понимали, в какой именно последовательности читать коды, и был придуман BOM (Byte Order Mark или, другими словами, сигнатура), которая выражалась в добавлении трех дополнительных байтов в самое начало документов.
В кодировке UTF-8 никаких BOM предусмотрено в консорциуме Юникод не было и поэтому добавление сигнатуры (этих самых пресловутых дополнительных трех байтов в начало документа) некоторым программам просто-напросто мешает читать код. Поэтому мы всегда при сохранении файлов в ЮТФ должны выбирать вариант без BOM (без сигнатуры). Таким образом, вы заранее обезопасите себя от вылезания кракозябров.
Что примечательно, некоторые программы в Windows не умеют этого делать (не умеют сохранять текст в ЮТФ-8 без BOM), например, все тот же пресловутый Блокнот Windows. Он сохраняет документ в UTF-8, но все равно добавляет в его начало сигнатуру (три дополнительных байта). Причем эти байты будут всегда одни и те же — читать код в прямой последовательности. Но на серверах из-за этой мелочи может возникнуть проблема — вылезут кракозябры.
Поэтому ни в коем случае не пользуйтесь обычным блокнотом Windows для редактирования документов вашего сайта, если не хотите появления кракозябров. Лучшим и наиболее простым вариантом я считаю уже упомянутый редактор Notepad++, который практически не имеет недостатков и состоит из одних лишь достоинств.
В Notepad ++ при выборе кодировки у вас будет возможность преобразовать текст в кодировку UCS-2, которая по своей сути очень близка к стандарту Юникод. Также в Нотепаде можно будет закодировать текст в ANSI, т.е. применительно к русскому языку это будет уже описанная нами чуть выше Windows 1251. Откуда берется эта информация?
Она прописана в реестре вашей операционной системы Windows — какую кодировку выбирать в случае ANSI, какую выбирать в случае OEM (для русского языка это будет CP866). Если вы установите на своем компьютере другой язык по умолчанию, то и эти кодировки будут заменены на аналогичные из разряда ANSI или OEM для того самого языка.
После того, как вы в Notepad++ сохраните документ в нужной вам кодировке или же откроете документ с сайта для редактирования, то в правом нижнем углу редактора сможете увидеть ее название:
![]()
Чтобы избежать кракозябров, кроме описанных выше действий, будет полезным прописать в его шапке исходного кода всех страниц сайта информацию об этой самой кодировке, чтобы на сервере или локальном хосте не возникло путаницы.
Вообще, во всех языках гипертекстовой разметки кроме Html используется специальное объявление xml, в котором указывается кодировка текста.
<?xml version="1.0" encoding="windows-1251"?>
Прежде, чем начать разбирать код, браузер узнает, какая версия используется и как именно нужно интерпретировать коды символов этого языка. Но что примечательно, в случае, если вы сохраняете документ в принятом по умолчанию юникоде, то это объявление xml можно будет опустить (кодировка будет считаться UTF-8, если нет BOM или ЮТФ-16, если BOM есть).
В случае же документа языка Html для указания кодировки используется элемент Meta, который прописывается между открывающим и закрывающим тегом Head:
<head> ... <meta charset="utf-8"> ... </head>
Эта запись довольно сильно отличается от принятой в стандарте в Html 4.01, но полностью соответствует новому внедряемому потихоньку стандарту Html 5, и она будет стопроцентно правильно понята любыми используемыми на текущий момент браузерами.
По идее, элемент Meta с указание кодировки Html документа лучше будет ставить как можно выше в шапке документа, чтобы на момент встречи в тексте первого знака не из базовой ANSI (которые правильно прочитаются всегда и в любой вариации) браузер уже должен иметь информацию о том, как интерпретировать коды этих символов.
Back to top
Toggle table of contents sidebar
Ошибки при конвертации#
При конвертации между строками и байтами очень важно точно знать, какая
кодировка используется, а также знать о возможностях разных кодировок.
Например, кодировка ASCII не может преобразовать в байты кириллицу:
In [32]: hi_unicode = 'привет' In [33]: hi_unicode.encode('ascii') --------------------------------------------------------------------------- UnicodeEncodeError Traceback (most recent call last) <ipython-input-33-ec69c9fd2dae> in <module>() ----> 1 hi_unicode.encode('ascii') UnicodeEncodeError: 'ascii' codec can't encode characters in position 0-5: ordinal not in range(128)
Аналогично, если строка «привет» преобразована в байты, и попробовать
преобразовать ее в строку с помощью ascii, тоже получим ошибку:
In [34]: hi_unicode = 'привет' In [35]: hi_bytes = hi_unicode.encode('utf-8') In [36]: hi_bytes.decode('ascii') --------------------------------------------------------------------------- UnicodeDecodeError Traceback (most recent call last) <ipython-input-36-aa0ada5e44e9> in <module>() ----> 1 hi_bytes.decode('ascii') UnicodeDecodeError: 'ascii' codec can't decode byte 0xd0 in position 0: ordinal not in range(128)
Еще один вариант ошибки, когда используются разные кодировки для
преобразований:
In [37]: de_hi_unicode = 'grüezi' In [38]: utf_16 = de_hi_unicode.encode('utf-16') In [39]: utf_16.decode('utf-8') --------------------------------------------------------------------------- UnicodeDecodeError Traceback (most recent call last) <ipython-input-39-4b4c731e69e4> in <module>() ----> 1 utf_16.decode('utf-8') UnicodeDecodeError: 'utf-8' codec can't decode byte 0xff in position 0: invalid start byte
Наличие ошибок — это хорошо. Они явно говорят, в чем проблема.
Хуже, когда получается так:
In [40]: hi_unicode = 'привет' In [41]: hi_bytes = hi_unicode.encode('utf-8') In [42]: hi_bytes Out[42]: b'xd0xbfxd1x80xd0xb8xd0xb2xd0xb5xd1x82' In [43]: hi_bytes.decode('utf-16') Out[43]: '뿐胑룐닐뗐苑'
Обработка ошибок#
У методов encode и decode есть режимы обработки ошибок, которые
указывают, как реагировать на ошибку преобразования.
Параметр errors в encode#
По умолчанию encode использует режим strict — при возникновении ошибок
кодировки генерируется исключение UnicodeError. Примеры такого поведения
были выше.
Вместо этого режима можно использовать replace, чтобы заменить символ
знаком вопроса:
In [44]: de_hi_unicode = 'grüezi' In [45]: de_hi_unicode.encode('ascii', 'replace') Out[45]: b'gr?ezi'
Или namereplace, чтобы заменить символ именем:
In [46]: de_hi_unicode = 'grüezi' In [47]: de_hi_unicode.encode('ascii', 'namereplace') Out[47]: b'gr\N{LATIN SMALL LETTER U WITH DIAERESIS}ezi'
Кроме того, можно полностью игнорировать символы, которые нельзя
закодировать:
In [48]: de_hi_unicode = 'grüezi' In [49]: de_hi_unicode.encode('ascii', 'ignore') Out[49]: b'grezi'
Параметр errors в decode#
В методе decode по умолчанию тоже используется режим strict и
генерируется исключение UnicodeDecodeError.
Если изменить режим на ignore, как и в encode, символы будут просто
игнорироваться:
In [50]: de_hi_unicode = 'grüezi' In [51]: de_hi_utf8 = de_hi_unicode.encode('utf-8') In [52]: de_hi_utf8 Out[52]: b'grxc3xbcezi' In [53]: de_hi_utf8.decode('ascii', 'ignore') Out[53]: 'grezi'
Режим replace заменит символы:
In [54]: de_hi_unicode = 'grüezi' In [55]: de_hi_utf8 = de_hi_unicode.encode('utf-8') In [56]: de_hi_utf8.decode('ascii', 'replace') Out[56]: 'gr��ezi'
Пишу в PyCharm и вроде как там с кодировкой проблем не должно возникать, однако удача меня обошла стороной.
При запуске локального сервера возникает следующая ошибка:
Unhandled exception in thread started by .wrapper at 0x035B1B28>
Traceback (most recent call last):
File «C:UsersTonyAppDataLocalProgramsPythonPython36-32libsite-packagesdjangoutilsautoreload.py», line 227, in wrapper
fn(*args, **kwargs)
File «C:UsersTonyAppDataLocalProgramsPythonPython36-32libsite-packagesdjangocoremanagementcommandsrunserver.py», line 149, in inner_run
ipv6=self.use_ipv6, threading=threading, server_cls=self.server_cls)
File «C:UsersTonyAppDataLocalProgramsPythonPython36-32libsite-packagesdjangocoreserversbasehttp.py», line 164, in run
httpd = httpd_cls(server_address, WSGIRequestHandler, ipv6=ipv6)
File «C:UsersTonyAppDataLocalProgramsPythonPython36-32libsite-packagesdjangocoreserversbasehttp.py», line 74, in __init__
super(WSGIServer, self).__init__(*args, **kwargs)
File «C:UsersTonyAppDataLocalProgramsPythonPython36-32libsocketserver.py», line 453, in __init__
self.server_bind()
File «C:UsersTonyAppDataLocalProgramsPythonPython36-32libwsgirefsimple_server.py», line 50, in server_bind
HTTPServer.server_bind(self)
File «C:UsersTonyAppDataLocalProgramsPythonPython36-32libhttpserver.py», line 138, in server_bind
self.server_name = socket.getfqdn(host)
File «C:UsersTonyAppDataLocalProgramsPythonPython36-32libsocket.py», line 673, in getfqdn
hostname, aliases, ipaddrs = gethostbyaddr(name)
UnicodeDecodeError: ‘utf-8’ codec can’t decode byte 0xcf in position 5: invalid continuation byte
Заморочился и пересохранил все файлы в UTF-8 — не помогло. Пересмотрел кодировку каждого файла в самом PyCharm’e — везде UTF-8. Нашел на некоторых форумах такую же проблему — в качестве решения предлагалось переименовать имя компьютера в ASCII кодировку (на латинице короче говоря). Весь путь на латинице — ноль изменений. В каждом файле писал комментарий с кодировкой:
# coding: utf8
и вот так, что одно и то же
# -*- coding: utf-8 -*- .
Результата как не было, так и нет. Весь день копаюсь, так до сих пор и без понятия в чем дело.
Использую фреймворк Django (может что на нем завязано).
Надеюсь на вашу помощь. Заранее спасибо!