
Данная статья открывает цикл публикаций, посвященных общим проблемам выбора и практического применения методов статистического анализа в клинических исследованиях. Мнения о ценности такого (статистического) подхода к оценке результатов исследования колеблются в диапазоне от «отсутствие грамотного статистического анализа приводит к утрате научной ценности исследования в целом» до «статистика — это некие «фантики», которыми принято декорировать исследование для пущей привлекательности и наукообразия». Последнее утверждение верно в той мере, в какой манипуляция статистикой или добросовестное заблуждение при выборе метода действительно могут изменить результат исследования, иногда на прямо противоположный. Однако необходимо отдавать себе отчет в том, что это проблема не статистики, а добросовестности и (или) полноты знания проблемы со стороны исследователя.
В эпоху доказательной медицины, в которую мы, хорошо ли, плохо ли, проживаем, статистический анализ, наряду с эпидемиологическим подходом к проведению исследования, стал обязательным элементом любой клинической работы, претендующей на звание научной. Раз так, а это именно так, то знание (в прагматически необходимом объеме!) статистики становится неотъемлемым элементом подготовки каждого научного сотрудника и обязательным квалификационным признаком состоявшегося специалиста. Однако на практике дела обстоят не настолько хорошо.
Последнее, к сожалению, становится все более и более заметно для авторов настоящей публикации, которые на протяжении многих лет являются рецензентами ряда ведущих отечественных журналов анестезиолого-реаниматологической тематики. Растущее количество работ с досадными, иногда нелепыми ошибками, допущенными по незнанию или недоразумению, заставляет каждый раз вновь обращаться к вопросам планирования исследования вообще и правилам проведения статистического анализа в частности.
Ряд ошибок, допущенных на этапе планирования, как мины замедленного действия, «срабатывают» в тот момент, когда менять что-либо уже поздно. Уже рекрутировано достаточное количество пациентов, и вдруг становится очевидно, что необходимо было мониторировать еще и «этот» показатель, без которого исследование «рассыпается», становится малоинформативным и бездоказательным. Рано или поздно авторы оказываются перед дилеммой: прервать исследование и начать все заново (жалко: столько сил и средств уже потрачено!) или продолжить, отдавая себе отчет в том, что цель достигнута быть не может, а единственное, что остается — это рассчитывать на получение некоего суррогата сомнительного качества. Именно поэтому крайне необходимым является проведение тщательного анализа предстоящей работы на этапе планирования, определение цели и задач, формулировка первичной, вторичной и т.д. конечных точек, адекватных поставленной цели; подбор методов не из арсенала того, «что у нас есть», а в соответствии с тем, «что необходимо, чтобы ответить на главный вопрос исследования». Жесткое соблюдение протокола и наличие CRF (Case Report Form — форма наблюдения за пациентом) являются абсолютными признаками качественного планирования. Все это в комплексе позволяет определить метод статистического анализа не «после», а еще «до» начала исследования, хотя некоторые коррективы, по-видимому, неизбежны (например, сообразно различному характеру распределения данных).
Маленькая иллюстрация вышесказанного. Допустим, вы собираетесь исследовать эффективность и безопасность разработанного Вами метода анестезии. Сделать это Вы планируете на основе анализа интраоперационных изменений уровня артериального давления (АД) и динамики активности ряда ферментов, обычно используемых для предварительной оценки функции некоторых органов и систем (аспартатаминотрансферазы — АсАТ, аланинаминотрансферазы — АлАТ, лактатдегидрогеназы — ЛДГ и т.д.). Вы справедливо полагаете, что для изучения летальности или частоты встречаемости жизнеугрожающих осложнений понадобится многосотенная, а то и многотысячная выборка, что нереально в рамках вашего учреждения, на что уйдут многие годы, и к окончанию работы либо «осел сдохнет», либо… далее по известной притче.
В итоге Вы получаете какой-то статистически значимый результат, например, тот, что уровень АД на неких, выбранных Вами, дискретных точках оказался несколько выше в контрольной группе, а значение некоторых ферментов — ниже. Радостно потирая руки, Вы пишете, что разработали более совершенный метод анестезии. Вся беда заключается в том, что полученный Вами результат говорит лишь о том, что наблюдается некоторое влияние метода на уровень АД в определенных фиксированных точках (и еще стоит подумать, положительное ли?), и уменьшается активность некоторых ферментов, что может указывать на меньший риск развития органной недостаточности, не более того. Утверждать, что предложенный Вами метод эффективнее и безопаснее существующих, без изучения частоты осложнений, летальности, времени пребывания в палате интенсивной терапии и других клинических исходов — невозможно.
Означает ли это, что проделанная Вами работа бессмысленна? Вовсе нет. Вы показали хотя бы то, что предложенный метод интересен, и следует подумать о его дальнейшем изучении. Можно ли рекомендовать предложенный Вами метод для широкого клинического применения? Увы, нет — недостаточно оснований. Таким образом, если Вы сформулировали цель исследования как «изучение эффективности и безопасности…», то Вы ее не достигли. И не могли достичь, так как выбрали методы, не отвечающие поставленной цели.
Авторы настоящей статьи осознают, насколько предложенный пример условен, ограничен и не детализирован, хотя и типичен. Тем не менее представляется, что он позволяет указать на один из многих «подводных камней», которые ждут исследователя на этапе планирования работы. В этой связи многие ученые обоснованно полагают, что время и усилия, затраченные на планирование, должны быть сопоставимы со временем и усилиями при выполнении работы. Только такой подход если и не гарантирует качество исследования, то определенно создает к тому серьезные предпосылки.
Первая, но далеко не единственная, проблема, которую необходимо решить до начала исследования — определение размера выборки. В отечественной и зарубежной литературе описано множество методик определения оптимального объема выборки, однако отсутствует четко установленная единая методология их применения.
Цель данной статьи — попытка предоставить неискушенному читателю общие сведения и один из возможных алгоритмов действия при определении размера выборки в ходе организации клинического исследования.
Варианты ошибок и их последствия
Ошибка в определении размера выборки одинаково нежелательна как в меньшую, так и в большую сторону.
При выборке меньшего объема мы с большей долей вероятности можем столкнуться с ошибками первого и второго родов. Для понимания сути таких ошибок нам необходимо ввести понятие нулевой гипотезы. Нулевая гипотеза — принимаемое по умолчанию предположение о том, что между двумя явлениями не существует никакой связи. В действительности нулевая гипотеза похожа на презумпцию невиновности. Мы всегда изначально считаем, что экспериментальная стратегия никак не может повлиять на исходы группы (то есть эффективность экспериментальной стратегии равна эффективности плацебо или отсутствию вмешательства, что зависит от дизайна исследования). Теперь вернемся к возможным ошибкам. Ошибкой первого рода называется отказ от правильной нулевой гипотезы (например, мы установили, что препарат эффективен, хотя в действительности его эффект такой же, как у плацебо). Ошибкой второго рода называется принятие неправильной нулевой гипотезы (например, мы установили, что препарат неэффективен, хотя в действительности он оказывает значительный положительный эффект).
При выборке большего объема (по сравнению с необходимым) большее количество больных будет подвергнуто неоправданному риску при испытании нового препарата или методики. А это недопустимо в соответствии со стандартами GCP (Good Clinical Practice) [1]. Кроме того, в случае избыточно большой выборки возможно обнаружение несуществующих в генеральной совокупности взаимосвязей, что вновь является ошибкой первого рода [2].
Важность определения объема выборки можно проиллюстрировать на следующем «доведенном до абсурда» примере. Скажем, Вы запланировали исследование, при котором в экспериментальной и контрольной группах по одному пациенту. Пациент контрольной группы получает плацебо, в то время как пациент экспериментальной группы получает препарат, об эффективности которого мы ничего не знаем. Если мы зададимся целью проанализировать летальность в таком исследовании, то обнаружим, что возможны 4 варианта развития событий.
Представим, что пациент контрольной группы умирает, а пациент экспериментальной группы выздоравливает. Вы даете абсолютно обоснованное заключение, что «все пациенты контрольной группы умерли, а все пациенты, которым применен тестируемый препарат, поправились, следовательно, методика эффективна». Интересно не то, что Вы с большой долей вероятности выдали ошибочное заключение, а то, что Вы, возможно, и правы. Дело в том, что объем выборки, в данном случае, не позволяет сделать никакого заключения вовсе!
Теперь представим, что оба больных поправились или оба погибли. Следуя простой логике, должно появиться заключение об отсутствии положительного эффекта у тестируемого препарата. Здесь Вы также обоснованно можете заключить, что препарат не отличается от плацебо. Но вся проблема снова в том, что объем выборки не позволяет сделать никакого заключения.
Вариант «пациент контрольной группы выжил, пациент экспериментальной группы погиб» приведет к рекомендации не использовать препарат (запрет) ввиду безусловного вреда здоровью. Но мы ведь с Вами понимаем, что ни о какой достоверности подобного заключения речи быть не может.
Остается удивительным, насколько люди не готовы допустить вероятность подобных ошибок при размере выборки в 15—20—30 человек. Мало того, иногда 100—200 и более пациентов недостаточно для обоснованного заключения. Очень многое, как будет показано далее, зависит от выбора первичной конечной точки, гетерогенности групп, возможных bias (перевод с английского — смещение в исходах, связанное с влиянием субъективного фактора) и т.д.
Пренебрегая предварительным расчетом размера выборки, авторы никогда не могут быть уверены в статистической значимости полученного результата [3]. Однако некоторые обзоры наглядно демонстрируют, что далеко не все исследователи понимают важность обозначенной проблемы [4, 5].
Определение объема выборки
Исследователь, ставящий перед собой цель определить размер выборки планируемого исследования, должен свободно оперировать следующими понятиями:
— Статистическая мощность (1-β), под которой понимают вероятность отклонить неверную нулевую гипотезу. Чем выше мощность статистического теста, тем меньше вероятность совершить ошибку второго рода. При планировании исследования желаемая мощность, как правило, принимается равной 0,8—0,9.
— Уровень статистической значимости (α) — вероятность ошибки первого рода — допускаемая исследователем вероятность ошибочного отклонения верной нулевой гипотезы (гипотезы об отсутствии различия между группами, об отсутствии взаимосвязи признаков и т.д.). Это постоянная величина, которая произвольно принимается автором за допустимую границу значимости полученных результатов. Именно с этой величиной будет производиться сравнение полученных данных. Как правило, за величину уровня значимости принимаются значения 0,05; 0,01 или 0,001.
— p-уровень значимости — рассчитанная в ходе статистического анализа вероятность ошибочного отклонения некоторой предполагаемой гипотезы. Если рассчитанный p-уровень меньше принятого уровня значимости (α), то предполагаемая гипотеза (нулевая гипотеза) отклоняется. Чем меньше p-уровень значимости, тем более значимой является тестовая статистика.
— Генеральная совокупность — совокупность всех возможных объектов данного рода, для которых будут справедливы результаты проведенного исследования. Скажем, вы исследуете эффективность препарата для лечения ишемической болезни сердца (ИБС) у пожилых пациентов. В этом случае генеральной совокупностью будут все пациенты с установленным диагнозом ИБС старшей возрастной группы.
— Выборка — часть генеральной совокупности (например, используя вышеприведенный пример, — пожилые пациенты с ИБС), полученная путем отбора. По результатам анализа выборки делают выводы о всей популяции (генеральной совокупности), что правомерно в случае, если отбор был случайным. Ввиду того, что случайный отбор из популяции осуществить практически невозможно, необходимо стремиться к тому, чтобы выборка была репрезентативна по отношению ко всей совокупности (популяции).
— Гетерогенность в таком случае относится к выборке. Гетерогенный означает неоднородный по составу (в противоположность понятию «гомогенный»). Чем менее гетерогенна выборка, тем менее выраженным является «разброс» значений изучаемого показателя в исходе, тем меньшие отличия, обнаруженные в результате исследования, могут иметь статистическую значимость. Обратная сторона этого утверждения заключается в том, что достаточно гомогенную выборку можно получить только ценой ужесточения критериев включения/исключения. Следовательно, полученный результат можно будет экстраполировать на ограниченную группу пациентов. В качестве примера: вы можете ограничить выборку пациентов, в которой планируете изучать эффективность нового препарата для лечения ИБС, вводя следующие критерии включения: возраст от 65 до 80 лет; впервые выявленная ИБС, «не получавшие ранее кардиотропной терапии». Но тогда и обнаруженный эффект (в случае его выявления) можно будет распространить только на выделенную когорту больных. Проведенное исследование не позволит вам рекомендовать тестируемый препарат у пациентов с «ИБС в анамнезе» или у пациентов в возрасте 40—50 лет и т.д.
Определение размера выборки всегда является неким компромиссом между необходимой мощностью исследования и возможностью ее практической реализации с учетом имеющихся ресурсов.
Метод расчета размера выборки во многом зависит от объема знаний о характеристиках изучаемого параметра.
Еще раз вынуждены оговориться: все примеры, иллюстрирующие данную статью, в той или иной мере условны; необходимо с пониманием отнестись к тому, что строгое и детальное описание настоящего (а не выдуманного) клинического примера займет слишком много места и, скорее всего, отвлечет от предмета обсуждения настоящей статьи.
Начнем с самого неприятного случая: нам ничего не известно ни о генеральной совокупности, ни о параметре, который мы собираемся изучать. Например, мы изобрели новый метод анестезии, который не имеет даже близкого аналога (изобретение эфирного наркоза, открытие хлороформа, более близкий пример — ксенон) и работа будет проходить в клинике, проводящей уникальные операции в гериатрии. Первичной конечной точкой исследования выбрана 28-дневная летальность. Допустим, что никто и никогда не изучал летальность после выбранного типа операций, тем более в гериатрии, т.е. Вам неизвестны характеристики основного изучаемого параметра (среднее (медиана) и разброс данных) и невозможно предположить эффективность нашего метода по сравнению с известным (т.е. какая летальность будет при применении нашего метода относительно летальности при использовании эталонного метода анестезии). Это достаточно редкая ситуация, так как:
— если неизвестна летальность при точно такой же операции, как у нас, то, скорее всего, есть какой-то очень близкий аналог;
— если неизвестна летальность, предположим, у лиц «90 лет и старше», то известна у лиц «пожилого и старческого возраста» («60 лет и старше»);
— и даже такой, несомненно, новый анестетик, как ксенон, можно как-то, в первом приближении (при оценке анальгетической активности, например), соотнести с закисью азота.
Следует иметь в виду, что всегда предпочтительнее иметь хотя бы крайне ненадежный ориентир в размере выборки, чем не иметь никакого, так как при использовании рекомендованных в этой ситуации методов объем выборки, как правило, получается завышенным.
Но, допустим, мы имеем дело с истинно «пилотным» исследованием — никто и никогда ничего похожего не изучал. В таком случае планирование объема выборки возможно исключительно с использованием табличных методов (табл. 1—4), не требующих от исследователя информации о распределении изучаемых параметров. Выбор алгоритма из предложенных четырех будет определяться особенностями исследования и/или пожеланиями авторов [6]:
— методика К.А. Отдельновой [7] требует информации о желаемом уровне значимости и «уровне точности» исследования (см. табл. 1);
— метод В.И. Паниотто [8] требует от исследователей лишь информации об объеме генеральной совокупности (см. табл. 2);
— методика N. Fox [9] определяет объем выборки в зависимости от требуемой величины возможной ошибки (см. табл. 3);
— и наиболее «продвинутый» способ определения объема выборки, предложенный S. Das, K. Mitra, M. Mandal [10], принимает на входе информацию о предполагаемой величине эффекта, мощности и уровне значимости исследования (см. табл. 4).
Таблица 1. Определение требуемого размера выборки по методике К.А. Отдельновой [7]
|
Уровень значимости |
Уровень точности |
||
|
ориентировочное знакомство |
исследование средней точности |
исследование повышенной точности |
|
|
0,05 |
44 |
100 |
400 |
|
0,01 |
100 |
225 |
900 |
Примечание. Уровень значимости: безразмерная величина, указан размер выборки как абсолютное значение количества пациентов в группе.
Таблица 2. Определение требуемого размера выборки по методике В.И. Паниотто [8]
|
Объем генеральной совокупности (единиц) |
500 |
1000 |
2000 |
3000 |
4000 |
5000 |
10000 |
100000 |
∞ |
|
Объем выборки (единиц) |
222 |
286 |
333 |
350 |
360 |
370 |
385 |
398 |
400 |
Таблица 3. Определение объема выборки по методике N. Fox [9]
|
Величина допускаемой ошибки, % |
Объем выборки, единиц |
|
10 |
88 |
|
5 |
350 |
|
3 |
971 |
|
2 |
2188 |
|
1 |
8750 |
Таблица 4. Способ определения объема выборки, предложенный S. Das, K. Mitra, M. Mandal [10]
|
Величина различий (между контрольной и основной группами) |
Мощность (1-β) |
Уровень значимости (α) |
Размер выборки, единиц |
|
0,2 |
80 |
0,5 |
586 |
|
0,2 |
80 |
0,1 |
773 |
|
0,2 |
90 |
0,5 |
746 |
|
0,4 |
80 |
0,5 |
146 |
|
0,4 |
80 |
0,1 |
193 |
|
0.4 |
90 |
0,5 |
186 |
|
0,6 |
80 |
0,5 |
65 |
|
0,6 |
80 |
0,1 |
86 |
|
0,6 |
90 |
0,5 |
83 |
Еще пример. Другая ситуация несколько лучше: операции, которые выполняются в клинике, не уникальны; летальность и ее разброс при эталонном методе анестезии известны, однако отсутствует информация о характеристиках распределения изучаемых количественных параметров, влияющих на летальность в генеральной совокупности, а предлагаемая методика действительно аналогов не имеет. В такой ситуации можно продолжать пользоваться «табличными» методами, но предпочтительнее все же взять на вооружение статистические формулы (Приложение: см. табл. 5, формулы 3—15). Последний подход позволит получить искомый показатель с большей точностью и, вероятно, использовать меньший объем выборки. Например, изучается послеоперационная летальность пациентов группы высокого риска (возраст 60 лет и старше, наличие хронических заболеваний) при применении нового метода анестезии. Необходимо определить объем выборки с принимаемым исследователем уровнем значимости 0,05 и предельно допустимой ошибкой 5%. Так как информация о распределении количественных параметров, влияющих на летальность, неизвестна, подходящей является формула 4 (см. Приложение, табл. 5). Допустим, что по данным литературы, 28-дневная летальность среди пациентов старшего возраста при применении стандартной анестезии составляет 9%, а исследователи предполагают, что предлагаемая ими методика позволит уменьшить обсуждаемый показатель в полтора раза (т.е. летальность может составить около 6%). Критическое значение нормального стандартного распределения при заданном уровне значимости α=0,05 принято равным 1,96. В соответствии с имеющимися условиями, для последующего сравнения летальности в контрольной и основной группах объем каждой выборки рассчитывается следующим образом:

Это означает, что для решения поставленной исследователем задачи достаточно сформировать выборку, включающую по 126 пациентов в основной и в контрольной группах.
Третий пример — вам известны все необходимые параметры: исходная летальность, характеристики распределения изучаемых параметров в генеральной совокупности; операции рутинные, кроме того, предлагаемый метод является близким аналогом другого, эффективность которого является секретом Полишинеля. Как и в предыдущем примере, изучается послеоперационная летальность у пациентов группы высокого риска (возраст 60 лет и старше, наличие хронических заболеваний) при применении нового метода анестезии, однако теперь исследователи имеют информацию практически обо всех влияющих на летальность факторах, распределение параметров соответствует нормальному закону, известен также объем генеральной совокупности (например, 1000 пациентов с равной вероятностью входят в группу риска в календарном году). Тогда в соответствии с формулой 17:

Как видим, в связи с появлением дополнительной информации необходимый объем выборки снизился со 126 до 112 пациентов.
Возможно, вы обратили внимание, что, в соответствии с формулой 17, при увеличении объема генеральной совокупности необходимый объем выборки также увеличивается. В этой связи бытует распространенное заблуждение, что чем больше объем генеральной совокупности, тем больше должен быть объем выборки. Проще говоря, исследователь попадает в ловушку: с одной стороны, чем больше больных с искомой патологией (или операцией) проходит через стационар, тем быстрее можно набрать достаточное количество пациентов. С другой стороны, увеличение размера генеральной совокупности (количества больных с искомой патологией, проходящих лечение или оперируемых в клинике) влечет за собой необходимость увеличения размера выборки (количества больных, рекрутируемых в исследование). Ложный вывод: чем реже встречается в клинике какая-то патология или тип оперативного вмешательства, тем быстрее можно выполнить исследование — меньшая выборка будет признана достаточной. Однако эта закономерность (чем больше генеральная совокупность, тем больше должен быть объем выборки) справедлива лишь отчасти (а вывод и вовсе вводит в заблуждение), и то лишь в ситуации, когда объем выборки сопоставим с размером генеральной совокупности. Возникает дилемма: сколько должно продолжаться проспективное исследование, чтобы объем выборки был репрезентативен по отношению ко всей совокупности пациентов, но в то же время исследование не продолжалось бы бесконечно долго.
Иными словами, как определить ту точку, когда погоня за точностью перестает реально влиять на результат и становится, скорее всего, самоцелью.
В соответствии с исследованием В.И. Паниотто [8], с ростом объема выборки значение получаемой ошибки уменьшается все медленнее (см. рисунок). Так, при объеме выборки 400 человек предельная ошибка для доли встречаемости признака 50% составит ±5%, а при объеме 1000 человек — ±3%. То есть возникает ситуация, когда при определенном объеме выборки дальнейшее ее увеличение не дает значительного выигрыша в точности.

Зависимость ошибки выборки от ее объема при 95% доверительном уровне.
Иная ситуация возникает, если изучаемая когорта пациентов имеет низкую распространенность в популяции, а критерии формирования выборки достаточно жесткие (что ограничивает подходящий контингент пациентов). Тогда все отобранные в ходе проспективного исследования пациенты, составляющие генеральную совокупность, будут попадать в исследуемую выборку, т.е. они будут сопоставимы по размеру.
В нашем примере, в соответствии с рисунком, при уровне летальности 9% и объеме выборки 50 человек предельная ошибка будет составлять примерно 10%. Для клинических исследований это недопустимо низкий уровень точности. Увеличение выборки до 200 человек приведет к уменьшению предельной ошибки до 4%, а при объеме выборки 400 пациентов ошибка составит всего 3%. Исходя из требований к клиническим исследованиям точность, при которой ошибка составляет 4%, считается допустимой, поэтому размер выборки можно ограничить 200 больными. Увеличивать объем выборки в два раза, по-видимому, в таком случае нецелесообразно.
Таким образом, в похожих ситуациях исследователи могут планировать продолжительность проспективного исследования исходя из требуемого и допустимого уровня ошибки.
Следует принять во внимание, что для медицинских исследований допустимой ошибкой считается 5%, если же удается получить результат с точностью до 1%, то исследование можно признать крайне убедительным.
Однако даже самое тщательное планирование не позволяет получить размер выборки, гарантирующий получение статистически значимого результата. Два приема используются порознь или вместе:
— автоматическое увеличение размера выборки на 10—15% по отношению к расчетному (особенно популярно при одноцентровых исследованиях небольшой мощности);
— коррекция размера выборки после получения первых данных о показателях, необходимых для более точного математического анализа.
Чем менее точно определен размер выборки при планировании (что не всегда является дефектом работы составителя плана, но, как показано выше, может быть и следствием отсутствия необходимых данных), тем насущнее становится необходимость коррекции данного показателя после появления первичных, предварительных данных, характеризующих исследуемый показатель и его изменения в результате предпринятых воздействий. Как правило, проведение повторного, уточняющего расчета размера выборки планируется до начала исследования и проводится после набора 50—75% от первоначально определенного количества больных.
Некоторые дополнительные замечания относительно определения размера выборки
Принято использовать два подхода к структурированию выборки — вероятностный и детерминированный (стратифицированный) [11]. Первый связан с формированием случайной выборки в процессе рандомизации (каждый элемент выборки включается с равной, ненулевой вероятностью); при использовании второго подхода элементы выборки отбираются субъективно в случае, если они отвечают целям исследования — выборка, основывается на неких частных предпочтениях или суждениях исследователя (например, ограничения по полу, возрасту, массе тела и т.д.).
Вероятностная выборка во многих случаях является предпочтительной, однако ее реализация в практической медицине может быть ограничена. Использование же детерминированного подхода в общем случае предполагает и использование иного математического аппарата или эмпирической методики [12].
Отдельную сложность представляет планирование объема выборки в условиях несоответствия распределения генеральной совокупности нормальному закону, а также при необходимости формирования различных по численности опытной и контрольной групп. Значительная вариабельность характеристик генеральной совокупности, а также многообразие вариантов клинических исследований предъявляют определенные требования к используемым методам планирования объема выборки.
Математический подход к определению размера выборки
Все математические методы определения объема выборки можно классифицировать на несколько групп:
— табличные методы, не требующие априорного представления об изучаемом факторе и о характеристиках генеральной совокупности (совокупности всех объектов или наблюдений, которые подлежат изучению). Описаны ранее;
— методы, требующие от исследователя некоторого представления об изучаемом признаке (количественный, порядковый (шкала), номинальный и т.д.);
— методы, требующие предварительной информации как о признаке, так и о генеральной совокупности (ее размере, нормальности распределения данных).
В медицине и анестезиологии-реаниматологии, в частности, авторы нередко сталкиваются с ситуацией, при которой невозможно оценить распределение исследуемого признака в генеральной совокупности и потому приходится использовать табличные методы при планировании объема выборки. Размер выборки может быть уточнен по мере получения предварительных результатов исследования, что сделает возможным использование математических формул. Это, в свою очередь, в некоторых случаях позволяет снизить риск необоснованного применения тестируемой методики у большего количества больных и уменьшить материальные затраты и нагрузку на медицинский персонал.
Экспертный подход к планированию объема выборки
Как отмечено ранее, в процессе набора данных возможен момент, когда большее количество данных (наблюдений) не обязательно приводит к большему количеству информации. А поскольку качественные исследования очень трудоемки, анализ значительной по размерам выборки может занять много времени, а зачастую и просто будет нецелесообразен [5]. Как правило, для непрерывной оценки размера выборки при проведении клинических исследований используется концепция насыщения выборки данными, позволяющая принимать обоснованные решения о необходимости прекращения процесса набора данных или о продолжении исследования.
Принципы определения насыщенности данных
В зарубежной литературе предложено несколько принципов, относящихся к концепции «насыщенности» в планировании исследования [13]. Согласно J. Francis и соавт., прежде всего необходимо учесть, какого размера будет выборка по завершении первого этапа исследования, чтобы определить основу для прогрессивных суждений о насыщенности данными и оценить наблюдаемую тенденцию, в том числе методами экстраполяции. Объем выборки будет зависеть от особенностей организации исследования, разнообразия выборки и способа ее формирования. Второй принцип заключается в том, что исследователи должны заранее знать продолжительность всего исследования (время набора данных). Важно также, чтобы методы насыщения данных были подробно описаны в тексте статьи, и коллеги имели возможность оценить доказательную базу исследования [13].
Концепция насыщения является в настоящее время спорной ввиду наличия более объективных методик оценки размера выборки [14]. В частности, указывается на тот факт, что для получения представления о размере выборки и мощности исследования приходится делать большое количество допущений. Информацию, необходимую для оценки объема выборки, получают либо из результатов собственных предыдущих исследований (пилотных исследований), либо из источников литературы. Возможны ситуации, при которых исследователь не имеет ни того, ни другого. Тем не менее необходимо заранее знать минимальную величину эффекта, которая в данном исследовании будет считаться достаточной, и на ее основании можно будет сделать предположение о мощности исследования.
Обсуждение
Определение размера выборки — важнейший этап планирования научной работы. Кроме того, это не просто формальный пункт, обязательный к исполнению по прихоти какого-то чиновника от науки. Это инструмент, позволяющий, с одной стороны, не делать лишнюю работу, с другой,— не сомневаться по окончании этой работы при получении отрицательного результата: «что это, реальное отсутствие эффекта или что «не хватило буквально каких-то …дцать больных»? Действительно, задача не так проста, как может показаться, но, соблюдая предложенный алгоритм, можно получить искомый результат с известной точностью [15—26].
Несколько полезных замечаний:
— при анализе пилотных исследований и сопоставимых работ других авторов необходимо обратить внимание не только на схожесть дизайна, но и на факторы, которые послужили причиной разброса данных. К таким факторам можно отнести демографические сведения о пациентах (половозрастные характеристики, прогностические факторы и т.д.), методы сбора информации, погрешности инструментальных и лабораторных методов исследования и прочее;
— необходимо помнить и о том, что мощность исследования зависит не только и не столько от объема выборки, сколько от предполагаемой величины эффекта и разброса данных. Возможно определение объема выборки исходя из априорных представлений об анализируемых параметрах, однако эмпирический подход является субъективным и проигрывает при равных условиях математическому подходу;
— возможны ситуации, при которых исследователь в силу определенных обстоятельств (финансовых, этических, организационных) не способен увеличить или изменить численность групп. В такой ситуации необходимо учитывать, что размер выборки не является единственным фактором качества исследования. И по сей день подходы к анализу объема выборки расширяются. В частности, показано использование однофакторного дисперсионного анализа ANOVA для определения объема выборки [15].
Таким образом, грамотному исследователю доступен широкий функционал математических методов определения требуемого объема выборки, руководствуясь которым в совокупности с собственным опытом и эмпирической методикой можно оптимально спланировать исследование и получить статистически обоснованные выводы.
Заключение
На современном этапе развития науки отсутствует четко установленная, единая методология определения минимально необходимого объема выборки для клинических исследований. В данной работе представлены наиболее часто применяемые методы определения необходимого объема выборки, которые могут быть применены при планировании исследований. Результатом анализа стало формирование единого алгоритма, позволяющего выбрать наиболее подходящую методику определения искомого показателя.
Приложение
Методы, требующие информации о типе анализируемого признака. Эта группа методов определения объема выборки зависит от ряда факторов: вида признаков, связанности выборок, количества предполагаемых групп и подхода к их формированию — вероятностного или детерминированного (стратифицированного). Формулы для расчетов приведены в табл. 5 (формулы 3—15). Использование приведенных формул дает значительно меньшие объемы выборок по сравнению с методами, не требующими информации о характеристиках распределения и типе анализируемого фактора, однако в некоторых случаях это может привести к неоправданному занижению необходимого объема выборки [6].
Таблица 5. Выбор метода планирования объема выборки (математический подход)
|
Нет информации о признаке/информация неполная Нет информации о генеральной совокупности |
Есть информация о признаке. Нет информации о генеральной совокупности |
Есть информация о признаке Есть информация о генеральной совокупности (распределение соответствует нормальному закону) |
Есть информация о признаке. Есть информация о генеральной совокупности (распределение не соответствует нормальному закону) |
|||||
|
Две выборки: односторонние тесты |
Две выборки: двусторонние тесты |
Одна выборка (вероятностный подход) |
Одна выборка (детерминированный подход) |
Одна выборка (погрешность измерений) |
Одна выборка (вероятностный подход) |
Одна выборка (детерминированный подход) |
||
|
Методика К.А. Отдельновой [6, 7] |
Количественный признак [24]:
|
Количественный признак [25]:
|
Количественный признак [26]: |
Количественный признак [26]: |
[20]
|
Количественный признак [26]: |
Количественный признак [26]:
|
Лог-нормальное распределение, Hale W. E. [22]:
|
|
Методика В.И. Паниотто [8] |
Качественный признак [25]:
|
Качественный признак [25]:
|
Оценка доли (частоты признака) [26]: |
Оценка доли (частоты признака) [26]: |
Номинальный/порядковый признак [26]: |
Качественный признак [26]: |
Распределение Пуассона [21]:
|
|
|
Метод Монте-Карло [23] |
||||||||
|
Методика N. Fox [9] и S. Das, K. Mitra, M. Mandal [10] |
Известна численность одной из групп [17]:
|
Примечание. * — Использовать в случае несвязанных выборок; для связанных выборок расчет обеих групп проводить по формулам 7 и 9; n — рассчитанный объем выборки; N — объем генеральной совокупности; ????2 — критическое значение критерия Стьюдента при соответствующем уровне значимости; d2 — предельно допустимая ошибка (минимальная, клинически значимая величина различий, которую необходимо обнаружить, как правило — 5%); ???? — стандартное отклонение признака, который будет изучаться в исследовании (????2 — дисперсия); ???? — доля случаев, в которых встречается анализируемый признак; Q — доля случаев, в которых не встречается анализируемый признак (100—????); Zα, — критические значения нормального стандартного распределения для заданных α и β; α/2 — желаемый уровень значимости; 1-β — желаемая мощность; p — доля признака в группе; σ(d^2 ) — средняя внутригрупповая дисперсия, pqd — средняя внутригрупповая дисперсия; X — среднее арифметическое изучаемого признака; E — погрешность измерения прибора |
||||||
|
Определение Х выборки [6]:
|
Сравнение долей (частот признаков) [24]: |
|||||||
|
Определение выборки [16]:
|
Номограммы [6, 18, 19] |
 (3)
(3)  (7)
(7)  (8)
(8)  (11)
(11)  (13)
(13)  (15)
(15)  (16)
(16)  (18)
(18)  (20)
(20)  (4)
(4)  (9)
(9) (10)
(10)  (12)
(12)  (14)
(14)  (17)
(17)  (19)
(19)  (21)
(21)  (5)
(5)  (1)
(1)  (6)
(6)  (2)
(2) Возможны ситуации, при которых оценить некоторые характеристики признака (такие как среднее арифметическое, стандартное отклонение) определить невозможно по причине отсутствия пилотного исследования или сопоставимых исследований в литературе — в данном случае возможно определение параметров с использованием расчетных формул (см. табл. 5, формулы 1—2). Эти формулы требуют наличия экспертных навыков и опыта у исследователя для предварительного определения размаха вариабельности исследуемого признака. Расчет размаха признака основывается на предположении о том, что расстояние между максимальным и минимальным значениями признака приблизительно равно шести стандартным отклонениям, что вытекает из правила трех сигм, и отсюда возможно определение стандартного отклонения (см. табл. 5, формула 2). В частности, если распределение генеральной совокупности соответствует нормальному закону, ее размах приблизительно равен 6σ, а следовательно, стандартное отклонение приблизительно равно одной шестой диапазона [16].
Весьма распространенной является задача планирования объема для последующего сравнения медианного значения определенного параметра между выборками в случае, если распределение признака уже известно, а информация о всей генеральной совокупности еще не получена. Например, необходимо определить объем выборки при сравнении уровня С-реактивного белка (СРБ) в одной группе пациентов с разлитым фибринозно-гнойным перитонитом в 1-е сутки и через 7 суток. Различия считаются статистически значимыми при уровне p<0,05, предельно допустимая ошибка равна 5%. По результатам предварительного (пилотного) исследования известно, что стандартное отклонение σ в первой группе составило 11,5, во второй — 16,2, а разница средних значений уровня СРБ в группах (X1—X2) по модулю составила 2. Так как СРБ является количественным параметром, выборки зависимы (связанные), а объем генеральной совокупности неизвестен, подходящими являются формулы 3 и 7. Однако в связи с тем, что стандартные отклонения в двух выборках различны, воспользуемся формулой 4, так как она учитывает стандартные отклонения обеих выборок.
 (4)
(4)
Отметим, что при уменьшении разницы X1—X2 (например, в пилотном исследовании ввиду неэффективной терапии уровень СРБ снизился менее чем на 1 единицу) объем выборки будет увеличиваться, что необходимо для выявления незначительных различий в уровне СРБ.
Ввиду финансовых, этических или иных соображений возможна ситуация, при которой требуется формирование различных по объему основной и контрольной групп [17]. Такое часто встречается в обсервационном исследовании или в рандомизированном контролируемом исследовании с неравной рандомизацией. Разработан математический аппарат, позволяющий оценить требуемую численность одной группы при известной фиксированной численности другой группы для формирования заключения о наличии/отсутствии статистически значимых различий между ними (см. табл. 5, формула 5).
Актуальной является задача определения объема выборки для дальнейшей оценки (сравнения) долей (частот встречаемости) признаков в одной или нескольких группах с использованием хи-квадрат критерия Пирсона — для этого случая также представлено несколько методик. Первая связана с использованием критических значений стандартного нормального распределения для оценки объема выборки (см. табл. 5, формулы 6, 12, 14). Вторая методика предполагает использование номограмм [18, 19]. Номограмма представляет собой диаграмму с двумя осями: осью стандартизованной разности и осью величины мощности; на пересечении приведенной прямой с необходимым уровнем значимости находится требуемый объем выборки. Расчет стандартизованной разности предполагает расчет отношения разности средних арифметических значений признака между группами к стандартному отклонению анализируемого признака, а уровень мощности в клинических исследованиях принимается, как правило, равным 0,8—0,9 [6]. В случае связанных выборок стандартизованная разность умножается на 2. В некоторых ситуациях может потребоваться расчет объема выборки с учетом прямой погрешности измерения прибора [20]. Тогда становится возможным заменить t-статистику Стьюдента на Z-оценку стандартного нормального распределения (см. табл. 5, формула 15).
Методы, требующие предварительной информации о виде признака и о генеральной совокупности. Наилучшая ситуация с точки зрения планирования объема выборки возникает при наличии информации о типе признака и о характеристиках распределения совокупности, при этом предпочтительно наличие нормально распределенных данных. В таком случае возможно использование статистических формул с учетом подхода к формированию выборки и использованием t-статистики (см. табл. 5, формулы 16—19). Этот математический аппарат широко описан в литературе, однако он неприменим к данным, распределение которых отлично от нормального [21]. Достаточно давно известен подход к планированию размера выборки для данных, распределение которых близко к лог-нормальному [22] (см. табл. 5, формула 20). По результатам исследования B. Cundill и N. Alexander, описанный выше подход к анализу лог-нормального распределения хорошо работал и для рассмотренных отрицательных биномиальных и гамма-распределений и превосходил по качеству методы, используемые при нормально распределенных данных [21]. Тем не менее он показал лишь незначительное преимущество для пуассоновского распределения, в связи с чем авторами предложен отдельных подход к расчету объема выборки для частного случая — Пуассоновского распределения данных (см. табл. 5, формула 21). В качестве альтернативного подхода к планированию объема выборки описано использование методов Монте-Карло, в частности, модели подтверждающего факторного анализа и модели роста [23]. В исследованиях данные генерируются из совокупности с гипотетическими значениями параметров, выбирается большое количество наблюдений и для каждого образца оценивается модель; значения параметров и стандартные ошибки усредняются по выборкам. Для определения объема выборки требуется соблюдение трех критериев. Первый критерий остановки алгоритма срабатывает в случае отклонения параметров и стандартных ошибок более 10% для любого параметра в модели. Второй критерий — стандартное смещение ошибки для параметра, для которого оценивается мощность, не превышает 5%. Третий критерий — оценка доверительных интервалов находится в интервале между 0,91 и 0,98. В случае, если эти три условия выполнены, размер выборки выбирается так, чтобы мощность была близка к 0,80. В целом такой подход может быть использован и при соответствии распределения совокупности нормальному закону.
Авторы заявляют об отсутствии конфликта интересов.
Что влияет на ширину доверительного интервала?
К этому моменту мы обсудили два фактора, которые влияют на ширину интервала:
- выбор статистики ((t) или (z)) и
- выбор степени доверия (влияющий на то, какую величину (t) или (z) мы используем).
Эти два варианта определяют фактор надежности.
Напомним, что доверительный интервал имеет следующую структуру:
Точечная оценка (pm) Фактор надежности (times) Стандартная ошибка.
Выбор размера выборки также влияет на ширину доверительного интервала. При прочих равных, больший размер выборки уменьшает ширину доверительного интервала.
Напомним формулу стандартной ошибки выборочного среднего:
( Large substack{ textbf{Стандартная ошибка} \ textbf{выборочного среднего} } = { textbf{Стандартное отклонение выборки} over sqrt { textbf{Размер выборки}}} )
Мы видим, что стандартная ошибка меняется обратно пропорционально квадратному корню из размера выборки.
По мере увеличения размера выборки, стандартная ошибка уменьшается и, следовательно, ширина доверительного интервала также уменьшается. Чем больше размер выборки, тем выше точность, с которой мы можем оценить параметр совокупности.
Существует формула для определения размера выборки, необходимого для получения доверительного интервала нужной ширины.
Определим (E) = Фактор надежности (times) Стандартная ошибка.
Чем меньше (E), тем меньше ширина доверительного интервала, так как (2E) — это ширина доверительного интервала.
Размер выборки, необходимый для получения нужного значения (E) при заданной степени уверенности ((1 — alpha) ) равен:
( Large {n = [(t_{alpha / 2}s) / E]^2} ).
При прочих равных, более крупные выборки лучше в этом смысле. На практике, однако, два соображения могут повлиять на решение против увеличения размера выборки.
- Во-первых, как мы уже видели в Примере (2) расчета коэффициента Шарпа, увеличение размера выборки может привести к выборке из более чем одной совокупности.
- Во-вторых, увеличение размера выборки может означать дополнительные затраты времени и денег, которые не окупятся благодаря дополнительной точности.
Таким образом, есть три фактора, которые финансовый аналитик должен оценить при определении размера выборки, — это:
- потребность в точности,
- риск отбора выборки из более чем одной совокупности, а также
- издержки на получение выборок различных размеров.
Пример (6) оценки инвестиционным менеджером чистого притока денежных средств клиентов.
Инвестиционный менеджер хочет построить 95-процентный доверительный интервал для притоков и оттоков денежных средств своих клиентов в течение следующих 6 месяцев.
Он начинается с обзвона случайной выборки из 10 клиентов, чтобы опросить их о планируемых взносах и изъятиях средств из инвестиционного фонда.
Затем менеджер вычисляет изменение денежного потока для каждого клиента из выборки, как процентное изменение от общего объема средств, размещенных у менеджера. Положительное процентное изменение указывает на чистый приток денежных средств на счет клиента, а отрицательное процентное изменение указывает на чистый отток денежных средств со счета клиента.
Менеджер взвешивает каждый ответ клиента по относительному размеру счета в рамках выборки, а затем вычисляет взвешенное среднее.
Проделав все это, инвестиционный менеджер вычисляет взвешенное среднее значение равное 5.5%. Таким образом, проведенная точечная оценка означает, что общая сумма средств под управлением менеджера увеличится на 5.5% в течение следующих 6 месяцев.
Стандартное отклонение наблюдений в выборке составляет 10%. Гистограмма прошлых данных выглядит довольно близко к нормальному распределению, так что менеджер предполагает, что генеральная совокупность также соответствует нормальному распределению.
1. Рассчитайте 95-процентный доверительный интервал для среднего по совокупности и интерпретируйте результаты.
Менеджер решил проанализировать, каким будет доверительный интервал, если использовать размер выборки 20 или 30, и получил то же самое среднее (5.5%) и стандартное отклонение (10%).
2. Используя выборочное среднее 5.5% и стандартное отклонение 10%, вычислите доверительный интервал для размеров выборки от 20 до 30. Для размера выборки 30 используйте Формулу 6.
3. Интерпретируйте результаты для частей 1 и 2.
Решение для части 1:
Поскольку совокупность неизвестна, а размер выборки мал, менеджер должен использовать t-статистику из Формулы 6 для расчета доверительного интервала.
Для выборки размера 10, (rm{df} = n — 1 = 10 — 1 = 9).
Для 95-процентного доверительного интервала, он должен использовать значение (t_{0.025}) для df = 9.
В соответствии с таблицами распределения Стьюдента это значение равно 2.262.
Таким образом, 95-процентный доверительный интервал для среднего значения по совокупности равен:
( begin{aligned} overline X pm t_{0.025} {s over sqrt{n}} &= 5.5% pm 2.262 {10% over sqrt {10}} \ &= 5.5% pm 2.262(3.162) \ &= 5.5% pm 7.15% end{aligned} )
Доверительный интервал для среднего по совокупности охватывает значения -1.65% до + 12,65%.
Мы предположили, что в этом примере размер выборки достаточно мал по сравнению с размером клиентской базы, поэтому мы можем пренебречь поправкой для конечной совокупности.
Менеджер может быть уверен на 95%, что этот диапазон включает в себя среднее значение по совокупности.
Решение для части 2:
В Таблице 4 приведены расчеты для выборок трех размеров.
|
Распределение |
95% доверительный интервал |
Нижняя граница |
Верхняя граница |
Относительный размер |
|---|---|---|---|---|
|
( t(n = 10) ) |
(5.5% pm 2.262(3.162) ) |
-1.65% |
12.65% |
100.0% |
|
( t(n = 20) ) |
(5.5% pm 2.093(2.236) ) |
0.82 |
10.18 |
65.5 |
|
( t(n = 30) ) |
(5.5% pm 2.045(1.826) ) |
1.77 |
9.23 |
52.2 |
Решение для части 3:
Ширина доверительного интервала уменьшается по мере увеличения размера выборки. Это уменьшение является функцией стандартной ошибки, которая становится меньше при увеличении (n).
Коэффициент надежности также становится меньше, так как число степеней свободы возрастает.
В последней колонке Таблицы 4 показан относительный размер ширины доверительных интервалов, если принять (n = 10 ) за 100%. Размер выборки 20 уменьшает ширину доверительного интервала до 65.5% от ширины интервала для размера выборки 10.
При размере выборки 30 ширина интервала сокращается почти в два раза. На основе этих данных, инвестиционный менеджер получил бы наиболее точные результаты, используя размер выборки 30.
Рассмотрев многие из фундаментальных понятий статистической выборки и оценки, мы можем сосредоточить внимание на вопросах отбора выборки, представляющих особый интерес для финансовых аналитиков. Качество выводов зависит от качества данных, а также от качества используемого плана выборки.
Финансовые данные создают особые проблемы, и планы выборки часто отражают одну или несколько систематических ошибок (смещений). В следующем разделе этого чтения обсуждаются эти вопросы.
Размер ошибки выборки прежде всего зависит от объема выборочной совокупности N. Средняя ошибка выборки обратно пропорциональна![]() (например, при увеличении объема выборки в четыре раза, ее ошибка уменьшается в только в два раза). Таким образом, увеличение объема выборки приводит к снижению ошибки выборки, но, с другой стороны, вызывает дополнительные расходы на проведение исследования.
(например, при увеличении объема выборки в четыре раза, ее ошибка уменьшается в только в два раза). Таким образом, увеличение объема выборки приводит к снижению ошибки выборки, но, с другой стороны, вызывает дополнительные расходы на проведение исследования.
При планировании выборочного наблюдения обычно заранее задают допустимую ошибку выборки и доверительную вероятность, чтобы обеспечить заданную точность результатов наблюдения.
Найдем оптимальный объем выборки для нахождения выборочной средней (случайный повторный отбор) при заданных предельной ошибке выборки ![]() и доверительной вероятности A. Согласно (5.4) и (5.8)
и доверительной вероятности A. Согласно (5.4) и (5.8)
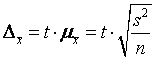 .
.
Отсюда оптимальный объем выборки N
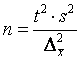 . (5.10)
. (5.10)
В таблице приведены формулы для расчета оптимального размера выборки (случайный отбор).

Эти формулы должны использоваться на этапе планирования выборочного наблюдения, однако в них необходимо указывать неизвестные нам значения выборочной дисперсии S2 и выборочной доли W. Вместо них на практике рекомендуется использовать какие-либо приближенные оценки этих характеристик (например, полученные в результате пробных выборочных наблюдений или из предыдущих обследований аналогичной совокупности). Кроме того, часто неизвестное значение W заменяют значением 0,5. Если известна примерная величина генеральной средней, то иногда используют приближенную формулу 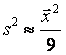 . Если известна примерная величина размаха совокупности, то можно использовать приближенную формулу
. Если известна примерная величина размаха совокупности, то можно использовать приближенную формулу 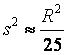 .
.
E Эти приближенные формулы можно использовать ТОЛЬКО ПРИ ОТСУТСТВИИ БОЛЕЕ ТОЧНЫХ ДАННЫХ, полученных в результате пробных выборочных обследований или из предыдущих обследований аналогичной совокупности.
E При больших размерах генеральной совокупности оптимальный объем выборки при повторном и бесповторном отборе отличаются незначительно.
| < Предыдущая | Следующая > |
|---|
Ошибка выборки — определение, типы, контроль и уменьшение ошибок
Опубликовано 2023-02-11 19:54 пользователем

Что такое ошибка выборки?
Ошибка выборки возникает, когда выборка, используемая в исследовании, не является репрезентативной для всей популяции. Ошибки выборки случаются часто, поэтому исследователи всегда рассчитывают предел ошибки при получении окончательных результатов в качестве статистической практики. Предел погрешности — это величина погрешности, допустимая при неправильном расчете, представляющая собой разницу между выборкой и реальной популяцией.
Выберите своих респондентов
Каковы наиболее распространенные ошибки выборки в маркетинговых исследованиях?
Вот четыре основные ошибки маркетинговых исследований при составлении выборки:
- Ошибка спецификации популяции: Ошибка спецификации популяции возникает, когда исследователи не знают, кого именно нужно опросить. Например, представьте себе исследование, посвященное детской одежде. Кого нужно опросить? Это могут быть оба родителя, только мать или ребенок. Родители принимают решение о покупке, но дети могут повлиять на их выбор.
- Ошибка выборочной совокупности: Ошибки выборочной совокупности возникают, когда исследователи неправильно ориентируются на субпопуляцию при отборе выборки. Например, выборка из телефонного справочника может иметь ошибочные включения, поскольку люди меняют свои города. Ошибочные исключения происходят, когда люди предпочитают не указывать свои номера. Богатые домохозяйства могут иметь более одного подключения, что приводит к многократным включениям.
- Ошибка отбора: Ошибка отбора происходит, когда респонденты сами выбирают себя для участия в исследовании. Отвечают только те, кто заинтересован. Ошибки отбора можно контролировать, если сделать дополнительный шаг и запросить ответы у всей выборки. Планирование перед опросом, последующие действия и аккуратный и чистый дизайн опроса повысят процент участия респондентов. Кроме того, попробуйте такие методы, как CATI-опросы и личные интервью, чтобы максимизировать количество ответов.
- Ошибки выборки: Ошибки выборки возникают из-за неравномерной репрезентативности респондентов. В основном это происходит, когда исследователь не планирует тщательно свою выборку. Эти ошибки выборки можно контролировать и устранять, создавая тщательный план выборки, имея достаточно большую выборку, отражающую все население, или используя для сбора ответов онлайн-выборку или аудиторию опроса.
Контроль ошибки выборки
Статистические теории помогают исследователям измерить вероятность ошибки выборки в зависимости от размера выборки и населения. Размер выборки, рассматриваемой из совокупности, в первую очередь определяет размер ошибки выборки. При больших размерах выборки вероятность ошибки ниже. Для понимания и оценки погрешности исследователи используют метрику, известную как предел погрешности. Обычно желаемым уровнем достоверности считается уровень достоверности в 95%.
Про совет: Если вам нужна помощь в расчете собственного предела погрешности, вы можете воспользоваться нашим калькулятором предела погрешности.
Каковы шаги по сокращению ошибок выборки?
Ошибки выборки легко выявить. Вот несколько простых шагов по уменьшению ошибки выборки:
- Увеличение размера выборки: Больший размер выборки дает более точный результат, поскольку исследование приближается к реальному размеру популяции.
- Разделение популяции на группы: Тестируйте группы в соответствии с их размером в популяции вместо случайной выборки. Например, если люди определенной демографической группы составляют 20% населения, убедитесь, что ваше исследование состоит из этой переменной, чтобы уменьшить смещение выборки.
- Знать свое население: Изучите свое население и поймите его демографический состав. Знайте, какие демографические группы используют ваш продукт и услугу, и убедитесь, что вы нацелены только на ту выборку, которая имеет значение.
Мы также создали инструмент, который поможет вам легко определить вашу выборку: Калькулятор размера выборки.
Ошибка выборки поддается измерению, и исследователи могут использовать ее в своих интересах, чтобы оценить точность своих выводов и оценить дисперсию.
Рубрика:
- Бизнес
Ключевые слова:
- аудитория
Автор:
- Dan Fleetwood
Источник:
- questionpro
Перевод:
- Дмитрий Л
Влияние увеличения размера выборки на точность оценок
Будем по-прежнему предполагать, что мы
исследуем случайную переменную xс неизвестным математическим ожиданием![]() и теоретической дисперсией
и теоретической дисперсией![]() и что для оценивания
и что для оценивания![]() используется
используется![]() .
.
Каким образом точность оценкиxзависит от числа наблюденийn?
При увеличении nоценка![]() ,
,
вообще говоря, становится более точной.
В единичном эксперименте большая по
размеру выборка необязательно даст
более точную оценку, чем меньшая выборка,
но общая тенденция должна быть именно
такой. Поскольку дисперсия![]() выражается формулой
выражается формулой![]() ,
,
она тем меньше, чем больше размер выборки,
и, значит, тем сильнее «сжата» функция
плотности вероятности для![]() .
.
Это показано на рис. 9. Предположим, что
xнормально распределена
со средним 25 и стандартным отклонением
50. Если размер выборки равен 25, то
стандартное отклонение величины![]() ,
,
равное![]() ,
,
составит:![]() .
.
Если размер выборки равен 100, то это
стандартное отклонение равно 5. На рис.
9 показаны соответствующие функции
плотности вероятности. Вторая (![]() )
)
выше первой в окрестности![]() ,
,
что говорит о более высокой вероятности
получения с ее помощью аккуратной
оценки. За пределами этой окрестности
вторая функция всюду ниже первой.
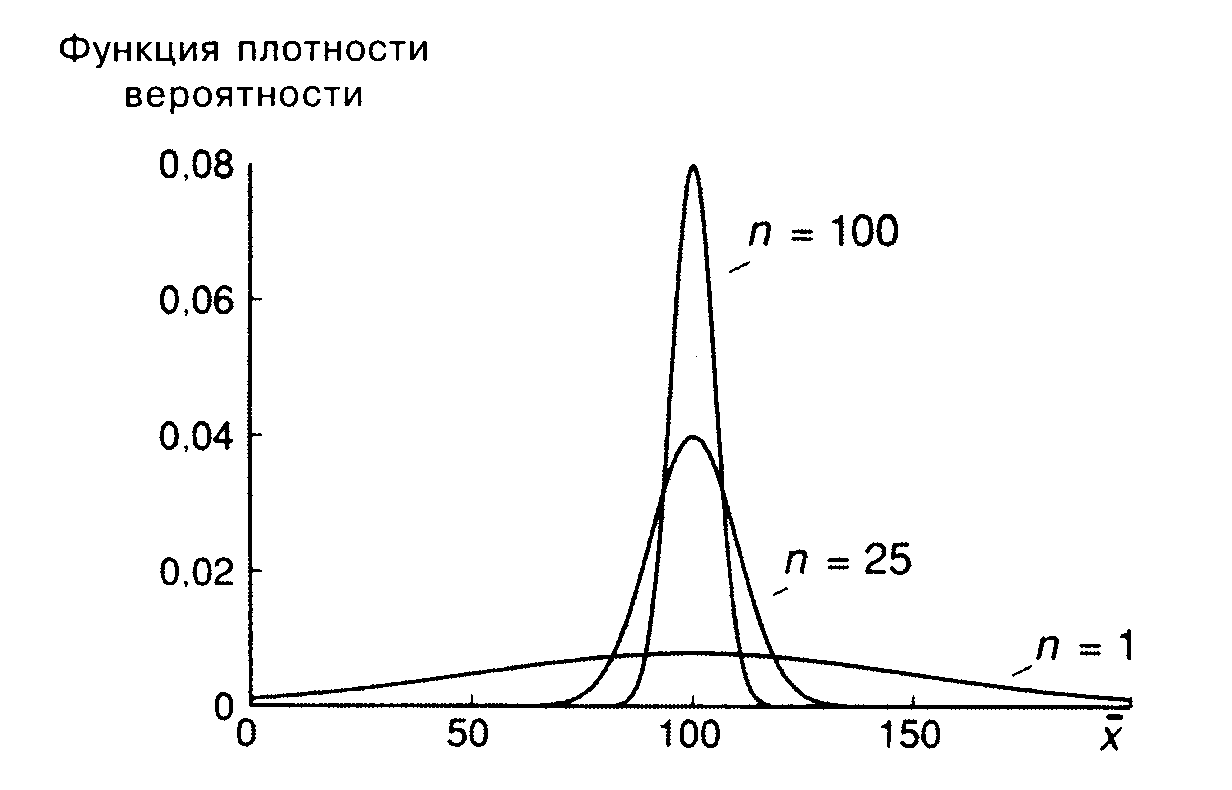
Рис. 9.
Чем больше размер выборки, тем уже и
выше будет график функции плотности
вероятности для
![]() .
.
Еслиnстановится
действительно большим, то график функции
плотности вероятности будет неотличим
от вертикальной прямой, соответствующей![]() .
.
Для такой выборки случайная составляющаяxстановится действительно
очень малой, и поэтому![]() обязательно будет очень близкой к
обязательно будет очень близкой к![]() .
.
Это вытекает из того факта, что стандартное
отклонение![]() ,
,
равное![]() ,
,
становится очень малым при большихn.
В пределе, при стремлении nк бесконечности,![]() стремится к нулю и
стремится к нулю и![]() стремится в точности к
стремится в точности к![]() .
.
Состоятельность
Вообще говоря, если предел оценки по
вероятности равен истинному значению
характеристики генеральной совокупности,
то эта оценка называется состоятельной.
Иначе говоря, состоятельной называется
такая оценка, которая дает точное
значение для большой выборки независимо
от входящих в нее конкретных наблюдений.
В большинстве конкретных случаев
несмещенная оценка является и
состоятельной.
Иногда бывает, что оценка, смещенная на
малых выборках, является состоятельной
(иногда состоятельной может быть даже
оценка, не имеющая на малых выборках
конечного математического ожидания).
На рис. 10 показано, как при различных
размерах выборки может выглядеть
распределение вероятностей. Тот факт,
что при увеличении размера выборки
распределение становится симметричным
вокруг истинного значения, указывает
на асимптотическую несмещенность. То,
что, в конечном счете, оно превращается
в единственную точку истинного значения,
говорит о состоятельности оценки.

Рис. 10.
Оценки, типа показанных на рис. 10, весьма
важны в регрессионном анализе. Иногда
невозможно найти оценку, несмещенную
на малых выборках. Если при этом вы
можете найти хотя бы состоятельную
оценку, это может быть лучше, чем не
иметь никакой оценки, особенно если вы
можете предположить направление смещения
на малых выборках.
Приложение 2