
-
Sbyrd
- Novice
- Posts: 8
- Liked: 2 times
- Joined: Jul 12, 2021 2:25 pm
- Contact:
Veeam Community Edition — Cannot restore backups
I recently setup the free Community edition as a test environment and it is backing up around 6 VMs.
The backup server is itself running on one of the ESX servers and All my backup jobs complete successfully.
Today I went to test a restore of one of my smallest VMs and each time it fails when restoring the disk with an error similar to this.
Code: Select all
7/12/2021 10:22:03 AM Error Restore job failed Error: Failed to decompress LZ4 block: Bad crc (original crc: ace48749, current crc: 6e30e205).
Failed to download disk 'Device '\.PhysicalDrive2''.
Agent failed to process method {DataTransfer.SyncDisk}.
Exception from server: Shared memory connection was closed.
Failed to upload disk. Skipped arguments: [Ubn-GestioIP-flat.vmdk];I then deleted the backups and successfully did a new full backup and when I did the restore I got the same error.
Previously I was using Unitrends Free and it would backup fine but would also fail to restore any backups while transferring the disk to the Host. However it’s logs were less clear.
I thought maybe it was the application so I decided to setup Veeam instead to see if it would work.
Any help would be appreciated.
-
veremin
- Product Manager
- Posts: 20004
- Liked: 2186 times
- Joined: Oct 26, 2012 3:28 pm
- Full Name: Vladimir Eremin
- Contact:
Re: Veeam Community Edition — Cannot restore backups
Post
by veremin » Jul 12, 2021 2:43 pm
Typically this type of errors indicates problems with underlying storage (that backups reside on). But you can try to reach our support team to double check it. Thanks!
-
Sbyrd
- Novice
- Posts: 8
- Liked: 2 times
- Joined: Jul 12, 2021 2:25 pm
- Contact:
Re: Veeam Community Edition — Cannot restore backups
Post
by Sbyrd » Jul 12, 2021 3:27 pm
So by underlying storage do you mean the VMware datastore or the virtual disk of the virtual server?
Backup server is a VM with an OS NTFS disk and a separate NTFS disk used as the backup location. The VM server then «resides» on an ISCSI datastore attached to the ESXI host. Datastore is a small Qnap NAS.
-
Gostev
- Chief Product Officer
- Posts: 30534
- Liked: 6209 times
- Joined: Jan 01, 2006 1:01 am
- Location: Baar, Switzerland
- Contact:
Re: Veeam Community Edition — Cannot restore backups
Post
by Gostev » Jul 12, 2021 3:43 pm
By «underlying storage» he means storage where your backup files are stored. In your case, it returns a different data comparing to what was written to it back when a backup file was created. Such reliability issues are not uncommon for low end NAS devices: they are prone to data loss due to not using enterprise-grade RAID controllers with battery-backed write cache.
-
Sbyrd
- Novice
- Posts: 8
- Liked: 2 times
- Joined: Jul 12, 2021 2:25 pm
- Contact:
Re: Veeam Community Edition — Cannot restore backups
Post
by Sbyrd » Jul 12, 2021 4:20 pm
Thanks. I’ll try to investigate. Your explanation makes sense but I guess I did not expect Veeam to make a full backup and then the backup is corrupt as soon as it is done.
I guess I have to find out if the corruption is happening on write or read.
-
Gostev
- Chief Product Officer
- Posts: 30534
- Liked: 6209 times
- Joined: Jan 01, 2006 1:01 am
- Location: Baar, Switzerland
- Contact:
Re: Veeam Community Edition — Cannot restore backups
Post
by Gostev » Jul 12, 2021 7:01 pm
Identifying a storage-based corruption would require re-reading the entire full backup back immediately after creation.
We actually do provide a health check functionality that does this, you can find it in the advanced job settings. But it’s not scheduled to run daily by default, as it would double the backup window. While enterprise-grade storage rarely has these issues, they may only appear after the hardware gets really «tired» and worn out ICs start getting so called «sticky bits».
-
Sbyrd
- Novice
- Posts: 8
- Liked: 2 times
- Joined: Jul 12, 2021 2:25 pm
- Contact:
Re: Veeam Community Edition — Cannot restore backups
Post
by Sbyrd » Jul 12, 2021 7:53 pm
So I just ran a new full job and immediately after running it I ran the command line validator and it failed when validating the vmdk with the same LZ4 error. So does that mean it is corrupting it on write or read?
Storage path: E:BackupsInformation BackupInformation BackupD2021-07-12T154348_945D.vbk
File 1: Ubn-GestioIP.vmx (2.9 KB)
File 2: Ubn-GestioIP.vmxf (150.0 B)
File 3: Ubn-GestioIP.nvram (8.5 KB)
File 4: Ubn-GestioIP.vmdk (614.0 B)
File 5: Ubn-GestioIP-flat.vmdk (16.0 GB)
File 6: FsAwareMeta:89f6c957-da07-4975-b609-cae991b2ac5f:2000 (0.0 B)
Validation progress
Ubn-GestioIP.vmx 100%
Ubn-GestioIP.vmxf 100%
Ubn-GestioIP.nvram 100%
Ubn-GestioIP.vmdk 100%
Ubn-GestioIP-flat.vmdk 23%
Statistics
VM count: Incomplete VM count: Failed VM count: Files count: Total size: Details:
1 0 1 5 16.0 GB Validation failed.
The following VMs are corrupted:
1. ‘Ubn-GestioIP’: File «Ubn-GestioIP-flat.vmdk» is corrupted. Failed to decompress LZ4 block: Incorrect decompression result or length (result: ‘-626428’, expected length: ‘1048576’). —tr:Failed to calculate [md5] digest for the block. Source block size: [626468]. —tr:Client failed to process the command. Command: [checkFile]. —tr:event:3:
-
Gostev
- Chief Product Officer
- Posts: 30534
- Liked: 6209 times
- Joined: Jan 01, 2006 1:01 am
- Location: Baar, Switzerland
- Contact:
Re: Veeam Community Edition — Cannot restore backups
Post
by Gostev » Jul 12, 2021 8:31 pm
This is actually impossible to say for sure, because it depends on the type of malfunction that is causing this. However, does it even matter? The storage is clearly unusable regardless.
By the way, you’d probably never know about the issue if your NAS was used to store images or videos, and perhaps even documents, because a few broken bytes are quite hard to notice in the media content, and there are no checksums for the corresponding applications to validate. Veeam is one of a few application that does not «trust» the storage and checksums everything that is being written, so that data could then be validated when it is read back by health check or restore processes.
-
Sbyrd
- Novice
- Posts: 8
- Liked: 2 times
- Joined: Jul 12, 2021 2:25 pm
-
Contact:
Re: Veeam Community Edition — Cannot restore backups
Post
by Sbyrd » Jul 13, 2021 12:40 pm
No that is not the exact setup. I have two ESXI hosts and two datastores. Host 1 houses all the production servers with the servers living on datastore 1. Host 2 has the veeam server and is running off datastore 2.
This is a very small non-enterprise setup.
The idea is that if datastore 2 or host 2 fails it will not impact the production servers. If host 1 or datastore 1 fails then I use host 2 and/or datastore 2 to restore the servers while I get the «main» host and datastore back online.
-
veremin
- Product Manager
- Posts: 20004
- Liked: 2186 times
- Joined: Oct 26, 2012 3:28 pm
- Full Name: Vladimir Eremin
- Contact:
Re: Veeam Community Edition — Cannot restore backups
Post
by veremin » Jul 13, 2021 12:55 pm
But the backups are still located on VMFS, correct? So to get access to restore points you will always need an ESXi host and VMFS datastore configured, which might bring additional complexity to restoration procedure.
I understand the budget restrictions here, but if you have a decommissioned physical server, you can simply stuff it with bunch of directly attached disks — and this would make it a better backup target compared to VMFS datastore configured on top of malfunctioning NAS device.
Thanks!
-
Sbyrd
- Novice
- Posts: 8
- Liked: 2 times
- Joined: Jul 12, 2021 2:25 pm
- Contact:
Re: Veeam Community Edition — Cannot restore backups
Post
by Sbyrd » Jul 13, 2021 3:47 pm
So I decided to test this theory as I have 2 Qnap NAS devices and two datastores and any backups written to either fail with the LZ4 error.
I decided then to create a new disk for the Veeam VM server but have this disk attached to the local storage datastore of the HP Proliant G6 server. Disks are 15k SAS 72GB drives in Raid 1.
If this succeeds on validation then I assume that the Qnaps are the issue. However if it fails with the same error then it is not my storage and must be something else. The QNAPs are connected via IP so could it be my network that is causing the corruption? This setup has been active and in use for over 3 years.
I was just struggling to see how I can have multiple Linux and Windows servers run just fine off the Qnaps and backups are written, but only the validation of the backups fails.
Anyway I did a backup of one server to the drive that lives on the host’s local storage and it backed up and restored just fine. So either both my Qnap NAS work just fine for running servers but fail at making backup? So could the network itself be the source of my issues and not actually the drives of the NAS? Just wanting to know if that is possible.
-
Sbyrd
- Novice
- Posts: 8
- Liked: 2 times
- Joined: Jul 12, 2021 2:25 pm
- Contact:
Re: Veeam Community Edition — Cannot restore backups
Post
by Sbyrd » Jul 13, 2021 7:25 pm
2 people like this post
Well for now so I at least have working backups I have attached a large HDD drive via eSATA to one of the esx hosts and created a drive for the veeam server that is on that HDD.
Backups are written and validated successfully on that drive.
In the next 1-2 months I will be migrating off my existing vm environment to new hosts and an enterprise level SAN array.
-
veremin
- Product Manager
- Posts: 20004
- Liked: 2186 times
- Joined: Oct 26, 2012 3:28 pm
- Full Name: Vladimir Eremin
-
Contact:
Re: Veeam Community Edition — Cannot restore backups
Post
by veremin » Jul 14, 2021 1:13 pm
Sounds like a solid move, but it still might be worth connecting HDD drives to separate physical machine and using it as a target repository instead of connecting it to ESXi host — should remove additional complexity during restore process. Thanks!
-
guitarfish
- Enthusiast
- Posts: 93
- Liked: 11 times
- Joined: Mar 06, 2013 4:12 pm
- Contact:
Re: Veeam Community Edition — Cannot restore backups
Post
by guitarfish » Jul 19, 2021 4:47 pm
Sbyrd wrote: ↑Jul 12, 2021 3:27 pm
So by underlying storage do you mean the VMware datastore or the virtual disk of the virtual server?Backup server is a VM with an OS NTFS disk and a separate NTFS disk used as the backup location. The VM server then «resides» on an ISCSI datastore attached to the ESXI host. Datastore is a small Qnap NAS.
I’m curious what model QNAP you are using? I have been using some TS-439 & 469 for years and I am able to restore without issue.
Who is online
Users browsing this forum: No registered users and 31 guests
В этой заметке рассказано, что делать, если появилась подобная ошибка в Veeam Backup & Replication при выполнения задания репликации или резервного копирования.
Вот так выглядит эта ошибка:

Эту ошибку также можно было увидеть в vCenter:
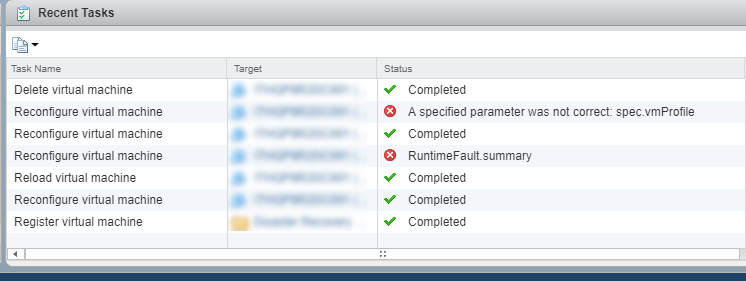
После некоторого копания я смог лучше понять, почему это происходило. Каждый раз, когда происходил этот сбой, я видел сообщение “Failed to set story profile VM Encryption Policy…”
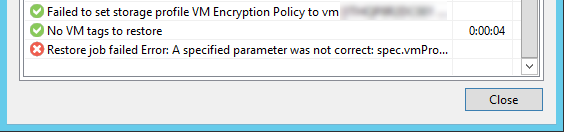
Но я не использую политики шифрования!
Это новинка начиная с vSphere 6.5, которая позволяет шифровать хранилище, в котором будет находиться виртуальная машина.
Чтобы обойти это, мне нужно было просмотреть дерево хранилища данных в поисках нужного хранилища, а не искать по имени; То, что я делал раньше.
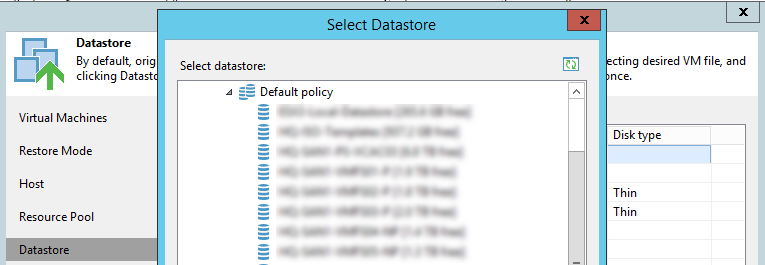
Вы можете увидеть это как раздел “Default policy”. Выберите хранилище и продолжайте бэкапить и восстанавливать как обычно.
Оригинал статьи
Veeam Backup & Replication 9.5 Update 4. Столкнулся с ошибкой при восстановлении базы MSSQL на не оригинальный сервер. После нескольких десятков минут копирования данных (база более 2 ТБ) задание завершалось с ошибкой:
Database restore failed: Failed to read block from file: C:WindowsTEMPo1p4abst.bwjMSSQL.1MSSQLDatawork_data.mdf The system cannot find the file specified.
Database restore failed: Failed to read block from file: C:WindowsTEMPo1p4abst.bwjMSSQL.1MSSQLDatawork_data.mdf The system cannot find the file specified.
Если глянуть логи на сервере, куда данные восстанавливаются, то там будет следующий текст:
dpl| ERR |Failed to execute DoRpcWithBinary. Command name: 'DoSerialRpc'.
dpl| >> |[NO_SESSION_ERROR] Cannot find session
dpl| >> |--tr:Failed to get session with id {e59b788f-ccea-4656-b68d-3392c8176097}
dpl| >> |--tr:Failed to call DoRpc. CmdName: [DoSerialRpc] inParam: [<InputArguments/>].
dpl| >> |An exception was thrown from thread [3876].
В системном логе была найдена такая ошибка:
Log Name: System
Source: Microsoft-Windows-NDIS
Date: 28.09.2020 17:17:15
Event ID: 10400
Task Category: None
Level: Warning
Keywords:
User: N/A
Description:
The network interface "vmxnet3 Ethernet Adapter" has begun resetting. There will be a momentary disruption in network connectivity while the hardware resets.
Reason: The network driver detected that its hardware has stopped responding to commands.
This network interface has reset 3 time(s) since it was last initialized.
Последний лог и подтолкнул сделать обновление драйверов на виртуальную сетевую карту vmware, т.к. vmware tools были очень древние. И, о чудо, обновление помогло. Следующий раз восстановление прошло успешно!
![]() Резервное копирование виртуальной машины с SharePoint Server 2019 в Veeam Backup & Replication v12 выполнялось успешно до тех пор, пока в SharePoint не была настроена и запущена служба поиска Search Service Application. Каждое последующее задание резервного копирования ВМ стало завершаться ошибкой создания контрольной точки Hyper-V production checkpoint следующего вида:
Резервное копирование виртуальной машины с SharePoint Server 2019 в Veeam Backup & Replication v12 выполнялось успешно до тех пор, пока в SharePoint не была настроена и запущена служба поиска Search Service Application. Каждое последующее задание резервного копирования ВМ стало завершаться ошибкой создания контрольной точки Hyper-V production checkpoint следующего вида:
Failed to create VM recovery checkpoint (mode: Veeam application-aware processing) Details: Failed to create VM (ID: ba7b4b0c-3fbd-4c51-8737-2ae39aee005f) recovery checkpoint. Job failed ('Checkpoint operation for 'KOM-WEB01' failed. (Virtual machine ID BA7B4B0C-3FBD-4C51-8737-2AE39AEE005F) 'KOM-WEB01' could not initiate a checkpoint operation: %%2147754996 (0x800423F4). (Virtual machine ID BA7B4B0C-3FBD-4C51-8737-2AE39AEE005F)'). Error code: '32768'.
Retrying snapshot creation attempt (Failed to create production checkpoint.)
Task has been rescheduled
Unable to allocate processing resources. Error: Failed to create production checkpoint.
Анализ логов на сервере SharePoint в момент выполнения задания в VBR показал наличие ошибки с кодом Event ID 8194:
Log Name: Application
Source: VSS
Date: 29.04.2023 3:12:51
Event ID: 8194
Level: Error
Keywords: Classic
Computer: KOM-WEB01.holding.com
Description: Volume Shadow Copy Service error: Unexpected error querying for the IVssWriterCallback interface. hr = 0x80070005, Access is denied. This is often caused by incorrect security settings in either the writer or requestor process.
Operation: PrepareForSnapshot Event
Context:
Execution Context: Writer
Writer Class Id: {0ff1ce16-0201-0000-0000-000000000000}
Writer Name: OSearch16 VSS Writer
Writer Instance Name: OSearch Replication Service
Writer Instance ID: {4ce2a6c6-2cf2-4f58-872f-9ce95adf804a}
Попытка создать контрольную точку ВМ вручную в консоли Hyper-V Manager также приводила к ошибке «could not initiate a checkpoint operation: %%2147754996 (0x800423F4)«
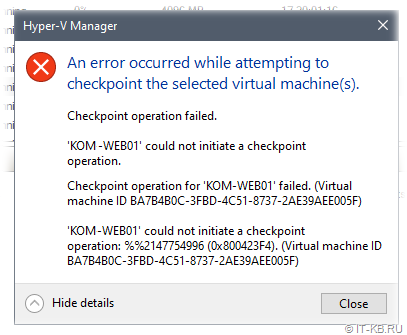
При этом в логе Application фиксировалась аналогичная ошибка с кодом 8194.
Команда листинга модулей записи теневого копирования на сервере SharePoint показала ошибочное состояние модуля «OSearch16 VSS Writer«:
vssadmin list writers
...
Writer name: 'OSearch16 VSS Writer'
Writer Id: {0ff1ce16-0201-0000-0000-000000000000}
Writer Instance Id: {268f99a2-1231-41d2-81e2-8f3ee565ee8e}
State: [8] Failed
Last error: Non-retryable error
...
Так как в тексте ошибки в event-логе фигурирует информация о нехватке прав («…0x80070005, Access is denied…»), в первую очередь нужно понять о какой учётной записи идёт речь.
Если посмотреть на стандартные поля в событии об ошибке, то в поле User мы не увидим информации о пользователе:
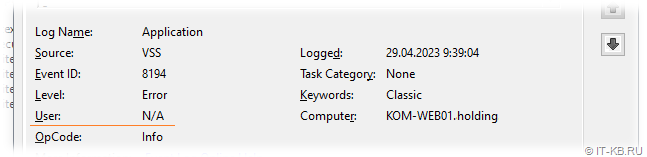
Однако, если переключиться на отображение подробностей на вкладке Details, то в варианте просмотра Friendly View в разделе с листингом бинарных данных мы сможем увидеть имя учётной записи, в контексте которой возникла шибка:
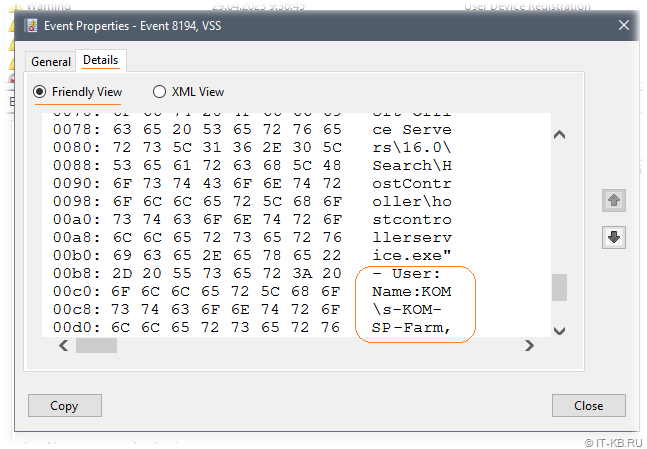
В нашем случае, это учётная запись фермы SharePoint (Farm account). И в контексте именно этой учётной записи у нас выполняется служба поиска SharePoint. При этом данная учётная запись не имеет полных административных прав на сервере.
Теперь относительного того, куда именно не может получить доступ учётная запись.
При проблемах с резервным копированием службы поиска SharePoint, в качестве одного из моментов, на который стоит обращать внимание, является состояние ключа реестра для службы «Volume Shadow Copy» (VSS):
HKEY_LOCAL_MACHINESYSTEMCurrentControlSetServicesVSS
Как минимум, в этом ключе:
1) В под-ключе VssAccessControl должен присутствовать параметр REG_DWORD с именем учётной записи, в контексте которой работает ферма/служба поиска, и значением «1»;
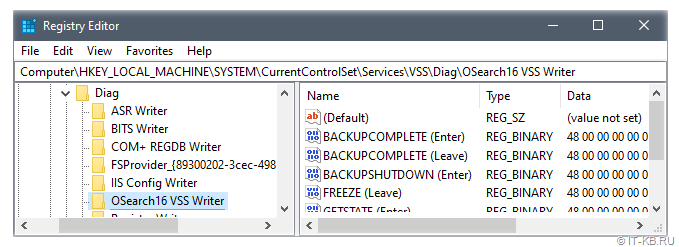
2) В под-ключе Diag должен присутствовать под-ключ с именем VSS модуля для службы поиска SharePoint (в нашем случае должен быть под-ключ с именем «OSearch16 VSS Writer«):
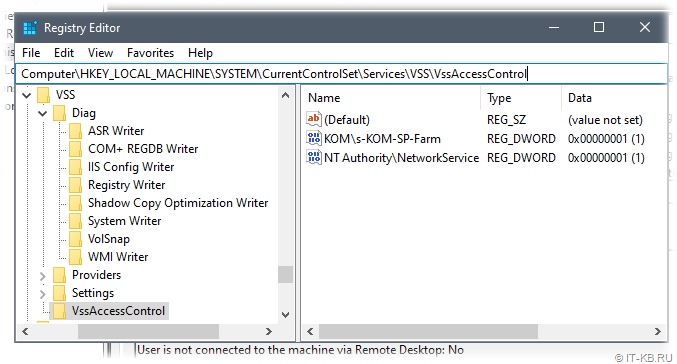
В нашем случае обнаружилось, что под-ключа «OSearch16 VSS Writer» нет.
В такой ситуации некоторые граждане предлагают выдать полные права доступа для учётной записи фермы/службы поиска на под-ключ Diag. Однако, если присмотреться к действующим разрешениям на этот ключ реестра, то можно заметить, что запись в него разрешена локальной группе безопасности «Backup Operators«.
Включаем учётную запись фермы/службы поиска в эту группу на нашем виртуальном сервере SharePoint со службой поиска и перезагружаем этот сервер.
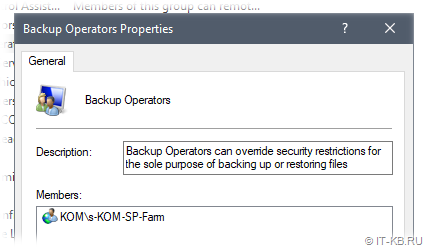
После перезагрузки удостоверимся в наличии ключа реестра «OSearch16 VSS Writer» и увидим, что владельцем этого ключа является учётная запись, включенная нами ранее в группу «Backup Operators».
После этого снова попробуем создать контрольную точку виртуальной машины в оснастке Hyper-V Manager.
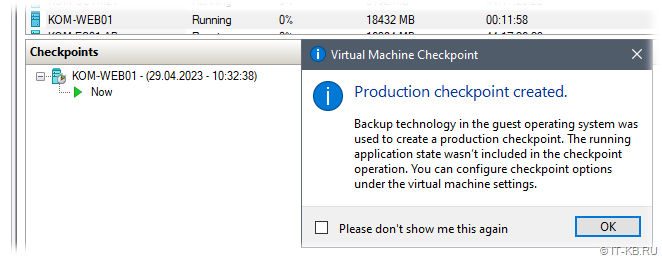
В нашем случае контрольная точка создалась успешно и в гостевой системе виртуального сервера SharePoint ошибка с кодом 8194 больше не появляется.
Теперь можно проверить, как изменилась ситуация в Veeam Backup & Replication. Убеждаемся в том, что в ходе выполнения задания резервного копирования для ВМ успешно создаётся, а затем автоматически удаляется временная контрольная точка, и, как следствие задание VBR отрабатывает без ошибок.

Стоит отметить, что описанная проблема является не проблемой VBR, а проблемой корректной настройки прав доступа для сервисных учётных записей SharePoint. При этом в официальном документе «Plan for administrative and service accounts in SharePoint Server» мне не удалось найти каких-либо явных указаний по включению сервисных учётных записей SharePoint в группу «Backup Operators» или каких-либо схожих по смыслу рекомендаций.
Обновлено 04.09.2016

Ошибка Error-Channel Error-Connection Reset при резервном копировании Veeam 8
Всем привет сегодня расскажу как решается ошибка Error: Channel Error: Connection Reset при резервном копировании Veeam Backup & Replication 8. Задание резервного копирования виртуальных машин vSphere 5.5 с помощью Veeam Backup & Replication 8.0 заканчивалось ошибкой «Error: ChannelError: ConnectionReset«. Причем проявлялось это очень выборочно, у одной-двух машин в задании. Но если прилипала это ошибка, то уже насовсем.
В логах выполнения задания было следующее:
«Hot add is not supported for source disk, failing over to network mode«.
Помогла рекомендация из KB1054 отключить на сервере с ролью backup proxy автомонтирование дисков. Набираем в командной строке:
C:Windowssystem32>diskpart
DISKPART> automount disable
DISKPART> automount scrub
Вот так вот просто решается ошибка Error: Channel Error: Connection Reset при резервном копировании Veeam Backup & Replication 8.
Материал сайта pyatilistnik.org
Сен 4, 2016 02:19
I had to restore one of the VM machines from backup, fortunately a test machine and I am getting errors no matter which restore point I try. Errors below. Anyone saw anything similar? I am quite new to Veeam.
Error: Failed to decompress LZ4 block: incorrect block header. Failed to download disk. Agent failed to process method {DataTransfer.SyncDisk}. Exception from server: Shared memory connection was closed. Failed to upload disk.
Error Restore job failed Error: Failed to decompress LZ4 block: incorrect block header. Failed to download disk. Agent failed to process method {DataTransfer.SyncDisk}. Exception from server: Shared memory connection was closed. Failed to upload disk.
У вас в логах следующие ошибки в задаче:
[30.04.2020 07:05:27] <36> Info [AP] (0225) output: —asyncNtf:disk_capacity: ‘161061273600’
[30.04.2020 07:05:27] <20> Info [AP] (f771) output: —asyncNtf:disk_capacity: ‘161061273600’
[30.04.2020 07:05:27] <19> Info [AP] (a0b9) output: —asyncNtf:disk_capacity: ‘161061273600’
[30.04.2020 07:05:28] <24> Info [AP] (0225) output: —size: 161061273600
[30.04.2020 07:05:28] <18> Info [AP] (0225) output: —pex:0;267386880;0;0;0;32;97;0;0;0;0;0;132326931287340000
[30.04.2020 07:05:42] <30> Error (4fd5) error: ChannelError: ConnectionReset
[30.04.2020 07:05:42] <38> Info [RemoteAgentSystemSession] Performing reconnection…
[30.04.2020 07:05:42] <38> Info Reconnecting backup client, host ‘192.168.11.5’.
[30.04.2020 07:05:42] <38> Info [ProxyAgent] Starting client agent session, id ‘8605ed3c-b173-445c-a644-0d757e1ee3a9’, host ‘192.168.11.5’, agent id ‘ea3e9510-c2f5-4c35-86ab-d3511b558ea3’, IPs ‘192.168.11.5:2507’, PID ‘6756’
[30.04.2020 07:05:42] <38> Info [SocketAgentService] Connecting to agent ‘192.168.11.5’ (‘192.168.11.5:2507’)
[30.04.2020 07:05:42] <38> Info [NetSocket] Connecting to ‘192.168.11.5:2507’.
[30.04.2020 07:05:42] <62> Error [ReconnectableSocket][PacketAsyncReceiver] Exception on [2d0656ab-85e0-4cc6-b3db-8b51f964e732].
[30.04.2020 07:05:42] <62> Error Удаленный хост принудительно разорвал существующее подключение (System.Net.Sockets.SocketException)
[30.04.2020 07:05:42] <62> Error в Veeam.Backup.Common.Reconnect.CPacketAsyncReceiver.PushData(CSocketAsyncEventArgsEx e)
[30.04.2020 07:05:42] <62> Info [ReconnectableSocket] Retryable error on [2d0656ab-85e0-4cc6-b3db-8b51f964e732].
[30.04.2020 07:05:42] <62> Info [ReconnectableSocket] Reconnecting [2d0656ab-85e0-4cc6-b3db-8b51f964e732] (retryable error)…
[30.04.2020 07:05:42] <62> Info [NetSocket] Connecting to ‘192.168.11.5:2507’.
[30.04.2020 07:05:43] <38> Error Failed to connect to agent’s endpoint ‘192.168.11.5:2507’. Host: ‘192.168.11.5’.
[30.04.2020 07:05:43] <38> Error Подключение не установлено, т.к. конечный компьютер отверг запрос на подключение 192.168.11.5:2507 (System.Net.Sockets.SocketException)
[30.04.2020 07:05:43] <38> Error в System.Net.Sockets.Socket.DoConnect(EndPoint endPointSnapshot, SocketAddress socketAddress)
[30.04.2020 07:05:43] <38> Error в System.Net.Sockets.Socket.Connect(EndPoint remoteEP)
[30.04.2020 07:05:43] <38> Error в Veeam.Backup.Common.CNetSocket.Connect(IPEndPoint remoteEp)
[30.04.2020 07:05:43] <38> Error в Veeam.Backup.AgentProvider.CAgentEndpointConnecter.ConnectToAgentEndpoint(ISocket socket, IAgentEndPoint endPoint)
[30.04.2020 07:05:43] <38> Info Disposing BaseAgentProtocol [0x1361a0e]
[30.04.2020 07:05:43] <38> Info Disposing CSocketAgentService [0x22dfb24], sessionId []
[30.04.2020 07:05:43] <38> Error [RemoteAgentSystemSession] Keep-alive thread has failed.
[30.04.2020 07:05:43] <38> Error Unable to reestablish connection to agent. (System.Exception)
[30.04.2020 07:05:43] <38> Error в Veeam.Backup.AgentProvider.CRemoteAgentSystemSession.ReconnectCycle(CancellationToken token)
[30.04.2020 07:05:43] <38> Error в Veeam.Backup.AgentProvider.CRemoteAgentSystemSession.KeepAliveThreadProc()
Получается, соединение было внезапно разорвано. Кроме того, перед тем, как соединение разорвалось, в логе Target Agent, я нашел следующие ошибки:
[30.04.2020 07:04:23] < 2480> srv| ERR |bad allocation
[30.04.2020 07:04:23] < 2480> srv| >> |—tr:Failed to unserialize buffer with data.
[30.04.2020 07:04:23] < 2480> srv| >> |—tr:Failed to unserialize data block.
[30.04.2020 07:04:23] < 2480> srv| >> |—tr:Failed to unserialize FIB block.
[30.04.2020 07:04:23] < 2480> srv| >> |—tr:Failed to receive data block with multi-channel download stream.
[30.04.2020 07:04:23] < 2480> srv| >> |Unable to retrieve next block transmission command. Number of already processed blocks: [128].
Ошибка bad allocation обычно возникает из-за нехватки памяти на одном из серверов, на котором поднялся агент.
В вашем случае, ошибка возникла на сервере, где был target agent. Согласно логам, он поднялся на сервере «REMOTE-DC2»:
[30.04.2020 07:01:03] <36> Info Initializing shared repository client for repository ‘REMOTE-DC2’.
[30.04.2020 07:01:03] <36> Info Starting target agent ( sharing mode: ‘SharedAgent’, host: ‘on repository’.).
[30.04.2020 07:01:12] <36> Info Setting repository ‘REMOTE-DC2’ (‘7f1aef43-231d-43fb-a5d7-854e49542ff5’) credentials for backup client.
который является Windows сервером:
[29.04.2020 22:19:32] <01> Info RepositoryID: 7f1aef43-231d-43fb-a5d7-854e49542ff5, Type: WinLocal, TotalSpace: 32212118396928, FreeSpace: 21094426656768, ConcurrentTaskLimit: {Enabled: True, Number: «4»}, RWrateLimit: {Enabled: False, MBs: «0»}, OnRotatedDrive: False, AlignFileBlocks: False, DecompressBeforeStoring: False, PerVMbackup: False, vPowerNFS: True, ProxyAffinitySet: False, IsReFsSytheticEnabled: True, IsReFsSytheticAvailable: False, ClusterSize: 8192, IsDedupEnabled: False, ServerID: a8ad2735-7961-41fd-9a67-7a744350bc50, OS Name: Microsoft Windows Server 2016 Standard 64-bit, OS version: 10.0.14393 build:14393, CoresCount: 2, CPUCount: 2, RAMTotalSize: 2146947072
На момент запуска задания, на сервере «REMOTE-DC2» оставалось меньше 1 ГБ памяти, в то время как общая память составляет 2 Гб:
[30.04.2020 07:01:07] < 4312> Total physical memory installed: [2047 MB], available: [856 MB].
Минимальное количество памяти для Veeam — репозитория составляет 4 ГБ + 2 ГБ (или 4 Гб, если 64-битная ОС установлена) за каждую дополнительную задачу, выполняющуюся параллельно.
Как я вижу, у вас 4 ядра на репозитории и стоит выполнение 4 параллельных заданий. В таком случае, рекомендуемая память 4 + 2*4 = 12 Гб (или 4 + 4*4 = 20 Гб, если 64-битная ОС установлена).
В итоге — на сервере «REMOTE-DC2» надо увеличить память как минимум до 12 Гб (или 20 Гб). Можно конечно попробовать поиграть со SWAP, но не думаю что поможет.
Так же советую посмотреть вот эту статью
Время на прочтение
4 мин
Количество просмотров 9.4K
Привет, с вами сегодня команда техподдержки Veeam Support Team. Мы уже рассказывали читателям Хабра о
фантастических тварях
разнообразных клиентах и где они обитают, и о том, чем и как занимается наш отдел.
А в новом сезоне мы решили начать публикацию технических постов с разбором реальных кейсов, с которыми к нам обращаются пользователи. Хочется верить, что эти материалы помогут кому-то разобраться в тонкостях работы с нашим продуктом без звонка в саппорт – а мы используем сэкономленное таким образом время для написания новых полезных статей.
Итак, сегодня разбираем кейс «Проблема с восстановлением на уровне файлов – ошибка при развертывании Linux FLR appliance», который стал одним из наиболее популярных за прошедшие месяцы.

Суть вопроса
При нормальной работе для восстановления файлов гостевой ОС (не Windows) забэкапленной виртуальной машины выполняется монтирование (mount) дисков этой самой забэкапленной машины на вспомогательную линуксовую ВМ (Linux FLR appliance). После этого можно просматривать содержимое файловой системы с помощью Veeam Backup Browser, выбирать необходимые файлы и восстанавливать их в нужное местоположение. Подробнее см. здесь (на англ. языке) или здесь (на русском).
Вспомогательная ВМ временно развертывается на ESXi-хосте исключительно с целью поддержки восстановления, а затем убирается. Однако при ее развертывании в консоли Veeam Backup & Replication может появиться сообщение об ошибке вот такого вида: “Linux FLR appliance deploy failed: Module ‘MonitorLoop’ power on failed.”
Как понять, что что-то пошло не так
Нюанс в том, что проблема происходит на довольно специфическом этапе – только при восстановлении файлов гостевой ОС, отличной от Windows, и конкретно при развертывании вспомогательной ВМ.
Сообщение об ошибке выглядит в консоли вот так:

Мы видим, что проблема связана с модулем MonitorLoop. Об этом же говорит и журнал соответствующей сессии FLR-восстановления, который хранится в файле с именем вида year_month_day_hour_minute_second.log. В нем мы обнаруживаем следующие записи:
[05.07.2017 17:16:49] <06> Info Mounting restore point. VM: [fileserver], BackupDate: [09.01.2017 18:31:12], Oib: [aa6038d3-bf68-42d6-86c0-de3a48784066]
[05.07.2017 17:17:49] <06> Error Failed to mount oib «aa6038d3-bf68-42d6-86c0-de3a48784066»
[05.07.2017 17:17:49] <06> Error Linux FLR appliance deploy failed: Module ‘MonitorLoop’ power on failed. (Veeam.Backup.Common.CAppException)
Кроме того, поскольку за развертывание вспомогательной ВМ (FLR appliance) отвечает сервис монтирования VeeamMountSvc, то в его журнале Svc.VeeamMount log тоже будет сделана подобная запись (правда, в ней не будет фигурировать проблемный модуль):
[05.07.2017 17:16:49] <23> Error Recreating WCF proxy…
[05.07.2017 17:16:49] <23> Error Linux FLR appliance deploy failed (System.ServiceModel.FaultException`1[Veeam.Backup.Interaction.MountService.CRemoteInvokeExceptionInfo])
«Кто виноват?»
Продолжая наше расследование, выясняем, что имеется статья VMware KB, из которой явствует, что модуль MonitorLoop контролирует ресурсы, выделяемые виртуальной машине. Конкретно же наша ошибка генерируется VMkernel, и ее можно обнаружить в журнале VMkernel:

Первопричиной является тот факт, что у хоста ESXi недостаточно ресурсов для работы вспомогательной ВМ. Естественно, процесс восстановления файлов без нее даст сбой. Чтобы выяснить, чего не хватает, можно углубиться в анализ логов VMkernel, а можно оценить необходимые ресурсы, основываясь на здравом смысле. А он утверждает, что критичные ресурсы – это, скорее всего, CPU и RAM, доступные для работы ВМ на данном хосте, а также свободное место для хранения файла подкачки. Недостаток последнего встречается довольно часто, так что если вы уверены, что ресурсами оперативной памяти и процессора все в порядке, то причина возникающей ошибки почти наверняка — недостаток места для хранения файлов вспомогательной ВМ и ее файла подкачки.
«Что делать?»
Для того, чтобы уяснить, что конкретно нужно поправить, запускаем мастер восстановления File-Level Restore и идем в настройки вспомогательной ВМ (FLR Helper Appliance).

Здесь для хоста, указанного в поле Host, нужно проверить две вещи:
- Достаточно ли у хоста ресурсов памяти и ЦПУ для работы ВМ. Вспомогательная машина потребляет минимум этих ресурсов, так что главное, чтобы они были доступны на момент ее развертывания. Если нужно, выберите другой хост, где эти ресурсы гарантированно будут в наличии.
- По умолчанию Veeam сохраняет файл подкачки вспомогательной ВМ на хранилище, указанное как NFS datastore – это обычная Windows-папка на сервере монтирования (mount server). Однако так бывает не всегда.
На картинке ниже показана настройка хоста ESXi, отвечающая за дефолтное место хранения файлов подкачки виртуальных машин: host → Configuration → Virtual Machines → Swap File Location.

Есть вероятность, что дефолтная настройка – Virtual machine directory (хранить в каталоге ВМ) – была изменена, а на вновь указанной для этой цели СХД закончилось место. В результате развернуть новые ВМ, включая вспомогательные, невозможно. Проверьте, не ваш ли это случай.

Аналогичая ошибка может произойти со вспомогательной ВМ в ходе SureBackup – причиной будет все та же нехватка ресурсов.
Бонус-трек
А знаете ли вы, что подробнее о работе продуктов Veeam всегда можно почитать в онлайн-справке, которая открывается по нажатию клавиши F1 из любого диалога в консоли продукта, включая главное окно?
Это относится и к шагам разнообразных мастеров настроек – нажимаете F1 на любом шаге мастера, и в вашем дефолтном браузере открывается соответствующий параграф документации в справочной онлайн-системе Help Center.
Профит!

Мы собираемся и дальше выкладывать разборы популярных кейсов из числа тех, которые поступают к нам в саппорт. Cвои пожелания можно высказывать в комментариях. До новых встреч!
Ссылки к сегодняшнему посту:
• Документ «Базовые сценарии использования Veeam Backup & Replication 9.5» на русском языке
• Описание процесса восстановления файлов гостевой ОС (FLR)
• Статья базы знаний VMware
Hello,
Ive just setup a new Server for Veeam Backup.
The backups run fine, but when i try to restore guest files from a NAS located on a offsite office. I get the error below. I also run a Backup Copy Job to site where the Veeam Server is located. With those backups i can restore guest files.

Connection to this offsite office is pretty slow, is this the issue?
Best Regards
Mattias
Read these next…
Where are they in Windows 11?
Windows
Quick and I hope easy question, I have figured out ways to do this in W11 but just wondering if there is an easier way.Where are the following in «Windows 11″1. Map Network Drive2. Add PC to a Domain3. This PC (Option)Thank you.
Tape library
Data Storage, Backup & Recovery
HI I am trying to learn my self how to connect a Dell R720 server with a LTO 7 tape library. Can someone advise and guide me with the best practice? because to begin with I have these questions.1. Can I connect the tape Libary directly to the server? if …
Raspberry Pi uses? As a desktop?
Hardware
I saw this post:https://twitter.com/mysterybiscuit5/status/1663271923063685121I like the form factor. Got me thinking — are any of the Raspberry Pi offerings a viable replacement for a windows 10 PC? For general work — surfing, document writing? spreadsh…
Spark! Pro series – 2nd June 2023
Spiceworks Originals
Today in History marks the Passing of Lou Gehrig who died of
ALS or Lou Gehrig’s Disease. I have a
friend suffering from this affliction, so this hits close to home. If you get the opportunity, or are feeling
g…
Snap! — AI Camera, Android Malware, Space, and more Space
Spiceworks Originals
Your daily dose of tech news, in brief.
Welcome to the Snap!
Flashback: June 2, 1966: The US «Soft Lands» on Moon (Read more HERE.)
Bonus Flashback: June 2, 1961: IBM Releases 1301 Disk Storage System (Read more HERE.)
You need to hear…




