
HTML — это язык разметки сайтов. Браузеры интерпретируют этот язык и отображают в виде сайта на экране. HTML совершенствуется со временем: в него добавляются новые элементы, отвечающие современным технологиям, требованиям безопасности, параметрам новейших устройств. С каждым таким обновлением языка выпускается его новая версия. Сейчас действует пятая версия HTML, или HTML5.
Как у каждого языка, у HTML есть правила написания, которые называются спецификацией. Спецификацию устанавливают профессиональные сообщества специалистов веб-разработки.
Каждый HTML документ в интернете должен соответствовать спецификации актуальной версии языка, то есть чтобы браузеры правильно интерпретировали код сайта, он должен соблюдать правила, описанные в спецификации.
Спецификации HTML5
У HTML5 есть две разновидности спецификаций: от консорциума W3C и от WHATWG. Обе эти организации — международные сообщества специалистов веб-разработки, однако W3C появился раньше и долгое время оставался единственной авторитетной организацией вырабатывавшей стандарты для интернета.
Веб-разработчики и производители браузеров могут выбирать, какие спецификации HTML5 использовать. Но в принципе, это не имеет значения, так как поддерживаются оба стандарта языка. В статье мы будем рассматривать спецификацию W3C.
Валидность кода
Код, соответствующий спецификации называется валидным, то есть правильным. Если в коде есть ошибки, то поисковые роботы при сканировании сайта могут не найти контент, а неправильные или незакрытые теги, битые ссылки запутают роботов — в результате у сайта возникнут проблемы с индексацией. Поэтому сайт, чтобы хорошо работать и индексироваться поисковиками, должен иметь валидный HTML код.
Несоответствие кода спецификации называются ошибками W3C. Еще на этапе верстки шаблона нужно тщательно следить, чтобы в коде не содержалось этих ошибок. Исправлять код уже готового и рабочего сайта гораздо труднее и затратнее, чем изначально написать валидный код.
Как проверить валидность кода
Написать на 100% валидный код очень сложно, почти всегда сайт будет содержать какие-то недочеты, особенно если у сайта много страниц, на нем установлены виджеты от сторонних разработчиков, или сайт сделан на готовом шаблоне.
Проверить сайт на ошибки W3C можно с помощью специальных сервисов. В том числе на сайте самого консорциума W3C есть соответствующий раздел. Принцип работы все этих сервисов заключается в одном: вы вводите URL сайта и через некоторое время получаете отчет о валидности html кода.
- В отчете будет показано, какие нарушения правил спецификации W3C имеются. Нарушения бывают двух типов:
- Error — критическая ошибка w3c. Грубое нарушение правил разметки, выделяется красным цветом.
- Warning — предупреждение, небольшая погрешность в коде. Выделяется желтым и словом Warning.
Самое главное — это ошибки Error. Если в коде обнаружены критические ошибки, то нужно незамедлительно их исправить.
Предупреждения же являются скорее рекомендациями. Учитывать их или нет, решает разработчик сайта исходя из особенностей шаблона и количества таких предупреждений.
Как исправить ошибки W3C
Валидатор указывает в отчете часть кода, в котором содержится ошибка с указанием конкретной строки HTML кода и пояснение. В пояснении содержится суть ошибки и рекомендация к исправлению.
- Самые распространенные ошибки:
- Одиночный тег прописан как парный, или наоборот, парный тег не имеет закрывающего тега.
- Отсутствие в теге какого-то атрибута. Например, в теге для изображений должен быть атрибут alt. Его отсутствие валидатор отметит как критическую ошибку.
- У тега прописанные не предназначенные для него атрибуты.
- Неправильная пунктуация в коде. Например, лишняя точка с запятой, и наоборот, ее отсутствие.
- Есть тег, но нет его содержания. Например, в коде прописан заголовок H2, но самого текста заголовка нет.
- Отсутствие слеша “/ ” в самозакрывающемся теге
- Блочные элементы внутри строчных. Например, когда заголовок прописан внутри ссылки. Должно быть наоборот.
Нужен настоящий SEO-сайт и интернет-реклама? Пишите, звоните:
Наша почта:
Единая справочная: 8 (843) 2-588-132
WhatsApp: +7 (960) 048 81 32
Оставить заявку
This is usually a cascading error caused by a an undefined entity
reference or use of an unencoded ampersand (&) in an URL or body
text. See the previous message for further details.
✉
Check that you are using a proper syntax for your comments, e.g: <!— comment here —>.
This error may appear if you forget the last «—» to close one comment, therefore including the rest
of the content in your comment.
✉
Did you forget to close a (double) quote mark?
✉
This error may appear if you are using a bad syntax for your comments, such as «<!invalid comment>»
The proper syntax for comments is <!— your comment here —>.
✉
This error may appear when the validator receives an empty document. Please make sure that the document you are uploading is not empty, and report any discrepancy.
✉
You have used character data somewhere it is not permitted to appear.
Mistakes that can cause this error include:
- putting text directly in the body of the document without wrapping
it in a container element (such as a <p>aragraph</p>), or - forgetting to quote an attribute value
(where characters such as «%» and «/» are common, but cannot appear
without surrounding quotes), or - using XHTML-style self-closing tags (such as <meta … />)
in HTML 4.01 or earlier. To fix, remove the extra slash (‘/’)
character. For more information about the reasons for this, see
Empty
elements in SGML, HTML, XML, and XHTML.
✉
The element named above was found in a context where it is not allowed.
This could mean that you have incorrectly nested elements — such as a
«style» element in the «body» section instead of inside «head» — or
two elements that overlap (which is not allowed).
One common cause for this error is the use of XHTML syntax in HTML
documents. Due to HTML’s rules of implicitly closed elements, this error
can create cascading effects. For instance, using XHTML’s «self-closing»
tags for «meta» and «link» in the «head» section of a HTML document may
cause the parser to infer the end of the «head» section and the
beginning of the «body» section (where «link» and «meta» are not
allowed; hence the reported error).
✉
The mentioned element is not allowed to appear in the context in which
you’ve placed it; the other mentioned elements are the only ones that
are both allowed there and can contain the element mentioned.
This might mean that you need a containing element, or possibly that
you’ve forgotten to close a previous element.
One possible cause for this message is that you have attempted to put a
block-level element (such as «<p>» or «<table>») inside an
inline element (such as «<a>», «<span>», or «<font>»).
✉
- You forgot to close a tag, or
- you used something inside this tag that was not allowed, and the validator
is complaining that the tag should be closed before such content can be allowed.
The next message, «start tag was here»
points to the particular instance of the tag in question); the
positional indicator points to where the validator expected you to close the
tag.
✉
This is not an error, but rather a pointer to the start tag of the element
the previous error referred to.
✉
You may have neglected to close an element, or perhaps you meant to
«self-close» an element, that is, ending it with «/>» instead of «>».
✉
This is not an error, but rather a pointer to the start tag of the element
the previous error referred to.
✉
Most likely, you nested tags and closed them in the wrong order. For
example <p><em>…</p> is not acceptable, as <em>
must be closed before <p>. Acceptable nesting is:
<p><em>…</em></p>
Another possibility is that you used an element which requires
a child element that you did not include. Hence the parent element
is «not finished», not complete. For instance, in HTML the <head>
element must contain a <title> child element, lists require
appropriate list items (<ul> and <ol> require <li>;
<dl> requires <dt> and <dd>), and so on.
✉
You have used the element named above in your document, but the
document type you are using does not define an element of that name.
This error is often caused by:
- incorrect use of the «Strict» document type with a document that
uses frames (e.g. you must use the «Frameset» document type to get
the «<frameset>» element), - by using vendor proprietary extensions such as «<spacer>»
or «<marquee>» (this is usually fixed by using CSS to achieve
the desired effect instead). - by using upper-case tags in XHTML (in XHTML attributes and elements
must be all lower-case).
✉
The Validator found an end tag for the above element, but that element is
not currently open. This is often caused by a leftover end tag from an
element that was removed during editing, or by an implicitly closed
element (if you have an error related to an element being used where it
is not allowed, this is almost certainly the case). In the latter case
this error will disappear as soon as you fix the original problem.
If this error occurred in a script section of your document, you should probably
read this FAQ entry.
✉
You have used a character that is not considered a «name character» in an
attribute value. Which characters are considered «name characters» varies
between the different document types, but a good rule of thumb is that
unless the value contains only lower or upper case letters in the
range a-z you must put quotation marks around the value. In fact, unless
you have extreme file size requirements it is a very very good
idea to always put quote marks around your attribute values. It
is never wrong to do so, and very often it is absolutely necessary.
✉
An attribute name (and some attribute values) must start with one of
a restricted set of characters. This error usually indicates that
you have failed to add a closing quotation mark on a previous
attribute value (so the attribute value looks like the start of a
new attribute) or have used an attribute that is not defined
(usually a typo in a common attribute name).
✉
«VI delimiter» is a technical term for the equal sign. This error message
means that the name of an attribute and the equal sign cannot be omitted
when specifying an attribute. A common cause for this error message is
the use of «Attribute Minimization» in document types where it is not allowed,
in XHTML for instance.
How to fix: For attributes such as compact, checked or selected, do not write
e.g <option selected … but rather <option selected=»selected» …
✉
You have used the attribute named above in your document, but the
document type you are using does not support that attribute for this
element. This error is often caused by incorrect use of the «Strict»
document type with a document that uses frames (e.g. you must use
the «Transitional» document type to get the «target» attribute), or
by using vendor proprietary extensions such as «marginheight» (this
is usually fixed by using CSS to achieve the desired effect instead).
This error may also result if the element itself is not supported in
the document type you are using, as an undefined element will have no
supported attributes; in this case, see the element-undefined error
message for further information.
How to fix: check the spelling and case of the element and attribute,
(Remember XHTML is all lower-case) and/or
check that they are both allowed in the chosen document type, and/or
use CSS instead of this attribute. If you received this error when using the
<embed> element to incorporate flash media in a Web page, see the
FAQ item on valid flash.
✉
Have you forgotten the «equal» sign marking the separation
between the attribute and its declared value?
Typical syntax is attribute="value".
✉
You have specified an attribute more than once. Example: Using
the «height» attribute twice on the same
«img» tag.
✉
This error almost always means that you’ve forgotten a closing quote on an attribute value. For instance,
in:
<img src="fred.gif>
<!-- 50 lines of stuff -->
<img src="joe.gif">
The «src» value for the first
<img> is the entire
fifty lines of stuff up to the next double quote, which probably
exceeds the SGML-defined
length limit for HTML
string literals. Note that the position indicator in the error
message points to where the attribute value ended — in
this case, the "joe.gif" line.
✉
The value of an attribute contained something that is not allowed by
the specified syntax for that type of attribute. For instance, the
“selected” attribute must be
either minimized as “selected”
or spelled out in full as “selected="selected"”; the variant
“selected=""” is not allowed.
✉
It is possible that you violated the naming convention for this attribute.
For example, id and name attributes must begin with
a letter, not a digit.
✉
This attribute cannot take a space-separated list of words as a value, but only one word («token»).
This may also be caused by the use of a space for the value of an attribute which does not permit it.
✉
The value of this attribute should be a number, and you probably used a wrong syntax.
✉
It is possible that you violated the naming convention for this attribute.
For example, id and name attributes must begin with
a letter, not a digit.
✉
The attribute given above is required for an element that you’ve used,
but you have omitted it. For instance, in most HTML and XHTML document
types the «type» attribute is required on the «script» element and the
«alt» attribute is required for the «img» element.
Typical values for type are
type="text/css" for <style>
and type="text/javascript" for <script>.
✉
The value of the attribute is defined to be one of a list of possible
values but in the document it contained something that is not allowed
for that type of attribute. For instance, the “selected” attribute must be either
minimized as “selected”
or spelled out in full as “selected="selected"”; a value like
“selected="true"” is not
allowed.
✉
Check that you are using a proper syntax for your comments, e.g: <!— comment here —>.
This error may appear if you forget the last «—» to close one comment, and later open another.
✉
You have used an illegal character in your text.
HTML uses the standard
UNICODE Consortium character repertoire,
and it leaves undefined (among others) 65 character codes (0 to 31 inclusive and 127 to 159
inclusive) that are sometimes used for typographical quote marks and similar in
proprietary character sets. The validator has found one of these undefined
characters in your document. The character may appear on your browser as a
curly quote, or a trademark symbol, or some other fancy glyph; on a different
computer, however, it will likely appear as a completely different
character, or nothing at all.
Your best bet is to replace the character with the nearest equivalent
ASCII character, or to use an appropriate character
entity.
For more information on Character Encoding on the web, see Alan
Flavell’s excellent HTML Character
Set Issues reference.
This error can also be triggered by formatting characters embedded in
documents by some word processors. If you use a word processor to edit
your HTML documents, be sure to use the «Save as ASCII» or similar
command to save the document without formatting information.
✉
An «id» is a unique identifier. Each time this attribute is used in a document
it must have a different value. If you are using this attribute as a hook for
style sheets it may be more appropriate to use classes (which group elements)
than id (which are used to identify exactly one element).
✉
This error can be triggered by:
- A non-existent input, select or textarea element
- A missing id attribute
- A typographical error in the id attribute
Try to check the spelling and case of the id you are referring to.
✉
The document type could not be determined, because the document had no correct DOCTYPE declaration. The document does not look like HTML, therefore automatic fallback could not be performed, and the document was only checked against basic markup syntax.
Learn how to add a doctype to your document
from our FAQ, or use the validator’s
Document Type option to validate your document against a specific Document Type.
✉
The construct <foo<bar> is valid in HTML (it is an example of the rather obscure “Shorttags” feature)
but its use is not recommended.
In most cases, this is a typo that you will want to fix. If you really want to use shorttags,
be aware that they are not well implemented by browsers.
✉
For the current document, the validator interprets strings like
<FOO /> according to legacy rules that
break the expectations of most authors and thus cause confusing warnings
and error messages from the validator. This interpretation is triggered
by HTML 4 documents or other SGML-based HTML documents. To avoid the
messages, simply remove the «/» character in such contexts. NB: If you
expect <FOO /> to be interpreted as an
XML-compatible «self-closing» tag, then you need to use XHTML or HTML5.
This warning and related errors may also be caused by an unquoted
attribute value containing one or more «/». Example:
<a href=http://w3c.org>W3C</a>.
In such cases, the solution is to put quotation marks around the value.
✉
The construct </foo<bar> is valid in HTML (it is an example of the rather obscure “Shorttags” feature)
but its use is not recommended.
In most cases, this is a typo that you will want to fix. If you really want to use shorttags,
be aware that they are not well implemented by browsers.
✉
A DOCTYPE declares the version of the language used, as well as what the root
(top) element of your document will be. For example, if the top element
of your document is <html>, the DOCTYPE declaration
will look like: «<!DOCTYPE html».
In most cases, it is safer not to type or edit the DOCTYPE declaration at all,
and preferable to let a tool include it, or copy and paste it from a
trusted list of DTDs.
✉
This is usually a cascading error caused by a an undefined entity
reference or use of an unencoded ampersand (&) in an URL or body
text. See the previous message for further details.
✉
The construct <> is sometimes valid in HTML (it is an example of the rather obscure “Shorttags” feature)
but its use is not recommended.
In most cases, this is a typo that you will want to fix. If you really want to use shorttags,
be aware that they are not well implemented by browsers.
✉
The construct </> is valid in HTML (it is an example of the rather obscure “Shorttags” feature)
but its use is not recommended.
In most cases, this is a typo that you will want to fix. If you really want to use shorttags,
be aware that they are not well implemented by browsers.
✉
An entity reference was found in the document, but there is no reference
by that name defined. Often this is caused by misspelling the reference
name, unencoded ampersands, or by leaving off the trailing semicolon (;).
The most common cause of this error is unencoded ampersands in
URLs as described by the WDG in «Ampersands
in URLs».
Entity references start with an ampersand (&) and end with a
semicolon (;). If you want to use a literal ampersand in your document
you must encode it as «&» (even inside URLs!). Be
careful to end entity references with a semicolon or your entity
reference may get interpreted in connection with the following text.
Also keep in mind that named entity references are case-sensitive;
&Aelig; and æ are different characters.
If this error appears in some markup generated by PHP’s session handling
code, this article has
explanations and solutions to your problem.
Note that in most documents, errors related to entity references will
trigger up to 5 separate messages from the Validator. Usually these
will all disappear when the original problem is fixed.
✉
The checked page did not contain a document type («DOCTYPE») declaration.
The Validator has tried to validate with a fallback DTD,
but this is quite likely to be incorrect and will generate a large number
of incorrect error messages. It is highly recommended that you insert the
proper DOCTYPE declaration in your document — instructions for doing this
are given above — and it is necessary to have this declaration before the
page can be declared to be valid.
✉
Your document includes a DOCTYPE declaration with a public identifier
(e.g. «-//W3C//DTD XHTML 1.0 Strict//EN») but no system identifier
(e.g. «http://www.w3.org/TR/xhtml1/DTD/xhtml1-strict.dtd»). This is
authorized in HTML (based on SGML), but not in XML-based languages.
If you are using a standard XHTML document type, it is recommended to use exactly
one of the DOCTYPE declarations from the
recommended list on the W3C QA Website.
✉
This may happen if you have consecutive comments but did not close one of them properly.
The proper syntax for comments is <!— my comment —>.
✉
If you meant to include an entity that starts with «&», then you should
terminate it with «;». Another reason for this error message is that
you inadvertently created an entity by failing to escape an «&»
character just before this text.
✉
This is generally the sign of an ampersand that was not properly escaped for inclusion
in an attribute, in a href for example. You will need to escape all instances of ‘&’
into ‘&’.
✉
This message may appear in several cases:
- You tried to include the «<» character in your page: you should escape it as «<»
- You used an unescaped ampersand «&»: this may be valid in some contexts,
but it is recommended to use «&», which is always safe. - Another possibility is that you forgot to close quotes in a previous tag.
✉
This error may occur when there is a mistake in how a self-closing tag is closed, e.g ‘…/ >’.
The proper syntax is ‘… />’ (note the position of the space).
✉
You’ve included a character reference to a character that is not defined
in the document type you’ve chosen. This is most commonly caused by
numerical references to characters from vendor proprietary
character repertoires. Often the culprit will be fancy or typographical
quote marks from either the Windows or Macintosh character repertoires.
The solution is to reference UNICODE characters instead. A list of
common characters from the Windows character repertoire and their
UNICODE equivalents can be found in the document «On the use of some MS Windows characters in HTML» maintained by
Jukka Korpela
<jkorpela@cs.tut.fi>.
✉
The following validation errors do not have an explanation yet. We invite you to use the
feedback channels to send your suggestions.
0: length of name must not exceed NAMELEN (X)
✉
1: length of parameter entity name must not exceed NAMELEN less the length of the PERO delimiter (X)
✉
2: length of number must not exceed NAMELEN (X)
✉
3: length of attribute value must not exceed LITLEN less NORMSEP (X)
✉
4: a name group is not allowed in a parameter entity reference in the prolog
✉
5: an entity end in a token separator must terminate an entity referenced in the same group
✉
6: character X invalid: only Y and token separators allowed
✉
7: a parameter separator is required after a number that is followed by a name start character
✉
8: character X invalid: only Y and parameter separators allowed
✉
9: an entity end in a parameter separator must terminate an entity referenced in the same declaration
✉
10: an entity end is not allowed in a token separator that does not follow a token
✉
11: X is not a valid token here
✉
12: a parameter entity reference can only occur in a group where a token could occur
✉
13: token X has already occurred in this group
✉
14: the number of tokens in a group must not exceed GRPCNT (X)
✉
15: an entity end in a literal must terminate an entity referenced in the same literal
✉
16: character X invalid: only minimum data characters allowed
✉
18: a parameter literal in a data tag pattern must not contain a numeric character reference to a non-SGML character
✉
19: a parameter literal in a data tag pattern must not contain a numeric character reference to a function character
✉
20: a name group is not allowed in a general entity reference in a start tag
✉
21: a name group is not allowed in a general entity reference in the prolog
✉
22: X is not a function name
✉
23: X is not a character number in the document character set
✉
24: parameter entity X not defined
✉
26: RNI delimiter must be followed by name start character
✉
29: comment started here
✉
30: only one type of connector should be used in a single group
✉
31: X is not a reserved name
✉
32: X is not allowed as a reserved name here
✉
33: length of interpreted minimum literal must not exceed reference LITLEN (X)
✉
34: length of tokenized attribute value must not exceed LITLEN less NORMSEP (X)
✉
35: length of system identifier must not exceed LITLEN (X)
✉
36: length of interpreted parameter literal must not exceed LITLEN (X)
✉
37: length of interpreted parameter literal in data tag pattern must not exceed DTEMPLEN (X)
✉
39: X invalid: only Y and parameter separators are allowed
✉
40: X invalid: only Y and token separators are allowed
✉
41: X invalid: only Y and token separators are allowed
✉
43: X declaration not allowed in DTD subset
✉
44: character X not allowed in declaration subset
✉
45: end of document in DTD subset
✉
46: character X not allowed in prolog
✉
48: X declaration not allowed in prolog
✉
49: X used both a rank stem and generic identifier
✉
50: omitted tag minimization parameter can be omitted only if OMITTAG NO is specified
✉
51: element type X already defined
✉
52: entity reference with no applicable DTD
✉
53: invalid comment declaration: found X outside comment but inside comment declaration
✉
54: comment declaration started here
✉
55: X declaration not allowed in instance
✉
56: non-SGML character not allowed in content
✉
57: no current rank for rank stem X
✉
58: duplicate attribute definition list for notation X
✉
59: duplicate attribute definition list for element X
✉
60: entity end not allowed in end tag
✉
61: character X not allowed in end tag
✉
62: X invalid: only S separators and TAGC allowed here
✉
66: document type does not allow element X here; assuming missing Y start-tag
✉
67: no start tag specified for implied empty element X
✉
72: start tag omitted for element X with declared content
✉
74: start tag for X omitted, but its declaration does not permit this
✉
75: number of open elements exceeds TAGLVL (X)
✉
77: empty end tag but no open elements
✉
78: X not finished but containing element ended
✉
80: internal parameter entity X cannot be CDATA or SDATA
✉
81: character X not allowed in attribute specification list
✉
83: entity end not allowed in attribute specification list except in attribute value literal
✉
84: external parameter entity X cannot be CDATA, SDATA, NDATA or SUBDOC
✉
85: duplicate declaration of entity X
✉
86: duplicate declaration of parameter entity X
✉
87: a reference to a PI entity is allowed only in a context where a processing instruction could occur
✉
88: a reference to a CDATA or SDATA entity is allowed only in a context where a data character could occur
✉
89: a reference to a subdocument entity or external data entity is allowed only in a context where a data character could occur
✉
90: a reference to a subdocument entity or external data entity is not allowed in replaceable character data
✉
91: the number of open entities cannot exceed ENTLVL (X)
✉
92: a reference to a PI entity is not allowed in replaceable character data
✉
93: entity X is already open
✉
94: short reference map X not defined
✉
95: short reference map in DTD must specify associated element type
✉
96: short reference map in document instance cannot specify associated element type
✉
97: short reference map X for element Y not defined in DTD
✉
98: X is not a short reference delimiter
✉
99: short reference delimiter X already mapped in this declaration
✉
100: no document element
✉
102: entity end not allowed in processing instruction
✉
103: length of processing instruction must not exceed PILEN (X)
✉
104: missing PIC delimiter
✉
106: X is not a member of a group specified for any attribute
✉
109: an attribute value specification must start with a literal or a name character
✉
110: length of name token must not exceed NAMELEN (X)
✉
113: duplicate definition of attribute X
✉
114: data attribute specification must be omitted if attribute specification list is empty
✉
115: marked section end not in marked section declaration
✉
116: number of open marked sections must not exceed TAGLVL (X)
✉
117: missing marked section end
✉
118: marked section started here
✉
119: entity end in character data, replaceable character data or ignored marked section
✉
126: non-impliable attribute X not specified but OMITTAG NO and SHORTTAG NO
✉
128: first occurrence of CURRENT attribute X not specified
✉
129: X is not a notation name
✉
130: X is not a general entity name
✉
132: X is not a data or subdocument entity
✉
133: content model is ambiguous: when no tokens have been matched, both the Y and Z occurrences of X are possible
✉
134: content model is ambiguous: when the current token is the Y occurrence of X, both the a and b occurrences of Z are possible
✉
135: content model is ambiguous: when the current token is the Y occurrence of X and the innermost containing AND group has been matched, both the a and b occurrences of Z are possible
✉
136: content model is ambiguous: when the current token is the Y occurrence of X and the innermost Z containing AND groups have been matched, both the b and c occurrences of a are possible
✉
138: comment declaration started here
✉
140: data or replaceable character data in declaration subset
✉
142: ID X first defined here
✉
143: value of fixed attribute X not equal to default
✉
144: character X is not significant in the reference concrete syntax and so cannot occur in a comment in the SGML declaration
✉
145: minimum data of first minimum literal in SGML declaration must be «»ISO 8879:1986″» or «»ISO 8879:1986 (ENR)»» or «»ISO 8879:1986 (WWW)»» not X
✉
146: parameter before LCNMSTRT must be NAMING not X
✉
147: unexpected entity end in SGML declaration: only X, S separators and comments allowed
✉
148: X invalid: only Y and parameter separators allowed
✉
149: magnitude of X too big
✉
150: character X is not significant in the reference concrete syntax and so cannot occur in a literal in the SGML declaration except as the replacement of a character reference
✉
151: X is not a valid syntax reference character number
✉
152: a parameter entity reference cannot occur in an SGML declaration
✉
153: X invalid: only Y and parameter separators are allowed
✉
154: cannot continue because of previous errors
✉
155: SGML declaration cannot be parsed because the character set does not contain characters having the following numbers in ISO 646: X
✉
156: the specified character set is invalid because it does not contain the minimum data characters having the following numbers in ISO 646: X
✉
157: character numbers declared more than once: X
✉
158: character numbers should have been declared UNUSED: X
✉
159: character numbers missing in base set: X
✉
160: characters in the document character set with numbers exceeding X not supported
✉
161: invalid formal public identifier X: missing //
✉
162: invalid formal public identifier X: no SPACE after public text class
✉
163: invalid formal public identifier X: invalid public text class
✉
164: invalid formal public identifier X: public text language must be a name containing only upper case letters
✉
165: invalid formal public identifer X: public text display version not permitted with this text class
✉
166: invalid formal public identifier X: extra field
✉
167: public text class of public identifier in notation identifier must be NOTATION
✉
168: base character set X is unknown
✉
169: delimiter set is ambiguous: X and Y can be recognized in the same mode
✉
170: characters with the following numbers in the syntax reference character set are significant in the concrete syntax but are not in the document character set: X
✉
171: there is no unique character in the document character set corresponding to character number X in the syntax reference character set
✉
172: there is no unique character in the internal character set corresponding to character number X in the syntax reference character set
✉
173: the character with number X in ISO 646 is significant but has no representation in the syntax reference character set
✉
174: capacity set X is unknown
✉
175: capacity X already specified
✉
176: value of capacity X exceeds value of TOTALCAP
✉
177: syntax X is unknown
✉
178: UCNMSTRT must have the same number of characters as LCNMSTRT
✉
179: UCNMCHAR must have the same number of characters as LCNMCHAR
✉
180: number of open subdocuments exceeds quantity specified for SUBDOC parameter in SGML declaration (X)
✉
181: entity X declared SUBDOC, but SUBDOC NO specified in SGML declaration
✉
182: a parameter entity referenced in a parameter separator must end in the same declaration
✉
184: generic identifier X used in DTD but not defined
✉
185: X not finished but document ended
✉
186: cannot continue with subdocument because of previous errors
✉
188: no internal or external document type declaration subset; will parse without validation
✉
189: this is not an SGML document
✉
190: length of start-tag before interpretation of literals must not exceed TAGLEN (X)
✉
191: a parameter entity referenced in a token separator must end in the same group
✉
192: the following character numbers are shunned characters that are not significant and so should have been declared UNUSED: X
✉
193: there is no unique character in the specified document character set corresponding to character number X in ISO 646
✉
194: length of attribute value must not exceed LITLEN less NORMSEP (-X)
✉
195: length of tokenized attribute value must not exceed LITLEN less NORMSEP (-X)
✉
196: concrete syntax scope is INSTANCE but value of X quantity is less than value in reference quantity set
✉
197: public text class of formal public identifier of base character set must be CHARSET
✉
198: public text class of formal public identifier of capacity set must be CAPACITY
✉
199: public text class of formal public identifier of concrete syntax must be SYNTAX
✉
200: when there is an MSOCHAR there must also be an MSICHAR
✉
201: character number X in the syntax reference character set was specified as a character to be switched but is not a markup character
✉
202: character number X was specified as a character to be switched but is not in the syntax reference character set
✉
203: character numbers X in the document character set have been assigned the same meaning, but this is the meaning of a significant character
✉
204: character number X assigned to more than one function
✉
205: X is already a function name
✉
206: characters with the following numbers in ISO 646 are significant in the concrete syntax but are not in the document character set: X
✉
207: general delimiter X consists solely of function characters
✉
208: letters assigned to LCNMCHAR, UCNMCHAR, LCNMSTRT or UCNMSTRT: X
✉
209: digits assigned to LCNMCHAR, UCNMCHAR, LCNMSTRT or UCNMSTRT: X
✉
210: character number X cannot be assigned to LCNMCHAR, UCNMCHAR, LCNMSTRT or UCNMSTRT because it is RE
✉
211: character number X cannot be assigned to LCNMCHAR, UCNMCHAR, LCNMSTRT or UCNMSTRT because it is RS
✉
212: character number X cannot be assigned to LCNMCHAR, UCNMCHAR, LCNMSTRT or UCNMSTRT because it is SPACE
✉
213: separator characters assigned to LCNMCHAR, UCNMCHAR, LCNMSTRT or UCNMSTRT: X
✉
214: character number X cannot be switched because it is a Digit, LC Letter or UC Letter
✉
215: pointless for number of characters to be 0
✉
216: X cannot be the replacement for a reference reserved name because it is another reference reserved name
✉
217: X cannot be the replacement for a reference reserved name because it is the replacement of another reference reserved name
✉
218: replacement for reserved name X already specified
✉
219: X is not a valid name in the declared concrete syntax
✉
220: X is not a valid short reference delimiter because it has more than one B sequence
✉
221: X is not a valid short reference delimiter because it is adjacent to a character that can occur in a blank sequence
✉
222: length of delimiter X exceeds NAMELEN (Y)
✉
223: length of reserved name X exceeds NAMELEN (Y)
✉
224: character numbers assigned to both LCNMCHAR or UCNMCHAR and LCNMSTRT or UCNMSTRT: X
✉
225: when the concrete syntax scope is INSTANCE the syntax reference character set of the declared syntax must be the same as that of the reference concrete syntax
✉
226: end-tag minimization should be O for element with declared content of EMPTY
✉
227: end-tag minimization should be O for element X because it has CONREF attribute
✉
228: element X has a declared content of EMPTY and a CONREF attribute
✉
229: element X has a declared content of EMPTY and a NOTATION attribute
✉
230: declared value of data attribute cannot be ENTITY, ENTITIES, ID, IDREF, IDREFS or NOTATION
✉
231: default value of data attribute cannot be CONREF or CURRENT
✉
232: number of attribute names and name tokens (X) exceeds ATTCNT (Y)
✉
233: if the declared value is ID the default value must be IMPLIED or REQUIRED
✉
234: the attribute definition list already declared attribute X as the ID attribute
✉
235: the attribute definition list already declared attribute X as the NOTATION attribute
✉
236: token X occurs more than once in attribute definition list
✉
237: no attributes defined for notation X
✉
238: notation X for entity Y undefined
✉
239: entity X undefined in short reference map Y
✉
240: notation X is undefined but had attribute definition
✉
241: length of interpreted parameter literal in bracketed text plus the length of the bracketing delimiters must not exceed LITLEN (X)
✉
242: length of rank stem plus length of rank suffix must not exceed NAMELEN (X)
✉
243: document instance must start with document element
✉
244: content model nesting level exceeds GRPLVL (X)
✉
245: grand total of content tokens exceeds GRPGTCNT (X)
✉
249: DTDs other than base allowed only if CONCUR YES or EXPLICIT YES
✉
250: end of entity other than document entity after document element
✉
251: X declaration illegal after document element
✉
252: character reference illegal after document element
✉
253: entity reference illegal after document element
✉
254: marked section illegal after document element
✉
255: the X occurrence of Y in the content model for Z cannot be excluded at this point because it is contextually required
✉
256: the X occurrence of Y in the content model for Z cannot be excluded because it is neither inherently optional nor a member of an OR group
✉
257: an attribute value specification must be an attribute value literal unless SHORTTAG YES is specified
✉
258: value cannot be specified both for notation attribute and content reference attribute
✉
259: notation X already defined
✉
260: short reference map X already defined
✉
261: first defined here
✉
262: general delimiter role X already defined
✉
263: number of ID references in start-tag must not exceed GRPCNT (X)
✉
264: number of entity names in attribute specification list must not exceed GRPCNT (X)
✉
265: normalized length of attribute specification list must not exceed ATTSPLEN (X); length was Y
✉
266: short reference delimiter X already specified
✉
267: single character short references were already specified for character numbers: X
✉
268: default entity used in entity attribute X
✉
269: reference to entity X uses default entity
✉
270: entity X in short reference map Y uses default entity
✉
271: no DTD X declared
✉
272: LPD X has neither internal nor external subset
✉
273: element types have different link attribute definitions
✉
274: link set X already defined
✉
275: empty result attribute specification
✉
276: no source element type X
✉
277: no result element type X
✉
278: end of document in LPD subset
✉
279: X declaration not allowed in LPD subset
✉
280: ID link set declaration not allowed in simple link declaration subset
✉
281: link set declaration not allowed in simple link declaration subset
✉
282: attributes can only be defined for base document element (not X) in simple link declaration subset
✉
283: a short reference mapping declaration is allowed only in the base DTD
✉
284: a short reference use declaration is allowed only in the base DTD
✉
285: default value of link attribute cannot be CURRENT or CONREF
✉
286: declared value of link attribute cannot be ID, IDREF, IDREFS or NOTATION
✉
287: only fixed attributes can be defined in simple LPD
✉
288: only one ID link set declaration allowed in an LPD subset
✉
289: no initial link set defined for LPD X
✉
290: notation X not defined in source DTD
✉
291: result document type in simple link specification must be implied
✉
292: simple link requires SIMPLE YES
✉
293: implicit link requires IMPLICIT YES
✉
294: explicit link requires EXPLICIT YES
✉
295: LPD not allowed before first DTD
✉
296: DTD not allowed after an LPD
✉
297: definition of general entity X is unstable
✉
298: definition of parameter entity X is unstable
✉
299: multiple link rules for ID X but not all have link attribute specifications
✉
300: multiple link rules for element type X but not all have link attribute specifications
✉
301: link type X does not have a link set Y
✉
302: link set use declaration for simple link process
✉
303: no link type X
✉
304: both document type and link type X
✉
305: link type X already defined
✉
306: document type X already defined
✉
307: link set X used in LPD but not defined
✉
308: #IMPLIED already linked to result element type X
✉
309: number of active simple link processes exceeds quantity specified for SIMPLE parameter in SGML declaration (X)
✉
310: only one chain of explicit link processes can be active
✉
311: source document type name for link type X must be base document type since EXPLICIT YES 1
✉
312: only one implicit link process can be active
✉
313: sorry, link type X not activated: only one implicit or explicit link process can be active (with base document type as source document type)
✉
314: name missing after name group in entity reference
✉
315: source document type name for link type X must be base document type since EXPLICIT NO
✉
316: link process must be activated before base DTD
✉
317: unexpected entity end while starting second pass
✉
318: type X of element with ID Y not associated element type for applicable link rule in ID link set
✉
319: DATATAG feature not implemented
✉
320: generic identifier specification missing after document type specification in start-tag
✉
321: generic identifier specification missing after document type specification in end-tag
✉
322: a NET-enabling start-tag cannot include a document type specification
✉
324: invalid default SGML declaration
✉
326: entity was defined here
✉
327: content model is mixed but does not allow #PCDATA everywhere
✉
328: start or end of range must specify a single character
✉
329: number of first character in range must not exceed number of second character in range
✉
330: delimiter cannot be an empty string
✉
331: too many characters assigned same meaning with minimum literal
✉
332: earlier reference to entity X used default entity
✉
335: unused short reference map X
✉
336: unused parameter entity X
✉
337: cannot generate system identifier for public text X
✉
339: cannot generate system identifier for parameter entity X
✉
340: cannot generate system identifier for document type X
✉
341: cannot generate system identifier for link type X
✉
342: cannot generate system identifier for notation X
✉
343: element type X both included and excluded
✉
345: minimum data of AFDR declaration must be «»ISO/IEC 10744:1997″» not X
✉
346: AFDR declaration required before use of AFDR extensions
✉
347: ENR extensions were used but minimum literal was not «»ISO 8879:1986 (ENR)»» or «»ISO 8879:1986 (WWW)»»
✉
348: illegal numeric character reference to non-SGML character X in literal
✉
349: cannot convert character reference to number X because description Y unrecognized
✉
350: cannot convert character reference to number X because character Y from baseset Z unknown
✉
351: character reference to number X cannot be converted because of problem with internal character set
✉
352: cannot convert character reference to number X because character not in internal character set
✉
353: Web SGML adaptations were used but minimum literal was not «»ISO 8879:1986 (WWW)»»
✉
354: token X can be value for multiple attributes so attribute name required
✉
355: length of hex number must not exceed NAMELEN (X)
✉
356: X is not a valid name in the declared concrete syntax
✉
357: CDATA declared content
✉
358: RCDATA declared content
✉
359: inclusion
✉
360: exclusion
✉
361: NUMBER or NUMBERS declared value
✉
362: NAME or NAMES declared value
✉
363: NUTOKEN or NUTOKENS declared value
✉
364: CONREF attribute
✉
365: CURRENT attribute
✉
366: TEMP marked section
✉
367: included marked section in the instance
✉
368: ignored marked section in the instance
✉
369: RCDATA marked section
✉
370: processing instruction entity
✉
371: bracketed text entity
✉
372: internal CDATA entity
✉
373: internal SDATA entity
✉
374: external CDATA entity
✉
375: external SDATA entity
✉
376: attribute definition list declaration for notation
✉
377: rank stem
✉
379: comment in parameter separator
✉
380: named character reference
✉
381: AND group
✉
382: attribute value not a literal
✉
383: attribute name missing
✉
384: element declaration for group of element types
✉
385: attribute definition list declaration for group of element types
✉
386: empty comment declaration
✉
388: multiple comments in comment declaration
✉
389: no status keyword
✉
390: multiple status keywords
✉
391: parameter entity reference in document instance
✉
392: CURRENT attribute
✉
393: element type minimization parameter
✉
395: #PCDATA not first in model group
✉
396: #PCDATA in SEQ group
✉
397: #PCDATA in nested model group
✉
398: #PCDATA in model group that does not have REP occurrence indicator
✉
399: name group or name token group used connector other than OR
✉
400: processing instruction does not start with name
✉
401: S separator in status keyword specification in document instance
✉
402: reference to external data entity
✉
405: SGML declaration was not implied
✉
406: marked section in internal DTD subset
✉
408: entity end in different element from entity reference
✉
409: NETENABL IMMEDNET requires EMPTYNRM YES
✉
411: declaration of default entity
✉
412: reference to parameter entity in parameter separator in internal subset
✉
413: reference to parameter entity in token separator in internal subset
✉
414: reference to parameter entity in parameter literal in internal subset
✉
415: cannot generate system identifier for SGML declaration reference
✉
416: public text class of formal public identifier of SGML declaration must be SD
✉
417: SGML declaration reference was used but minimum literal was not «»ISO 8879:1986 (WWW)»»
✉
418: member of model group containing #PCDATA has occurrence indicator
✉
419: member of model group containing #PCDATA is a model group
✉
420: reference to non-predefined entity
✉
421: reference to external entity
✉
422: declaration of default entity conflicts with IMPLYDEF ENTITY YES
✉
423: parsing with respect to more than one active doctype not supported
✉
424: cannot have active doctypes and link types at the same time
✉
425: number of concurrent document instances exceeds quantity specified for CONCUR parameter in SGML declaration (X)
✉
426: datatag group can only be specified in base document type
✉
427: element not in the base document type can’t have an empty start-tag
✉
428: element not in base document type can’t have an empty end-tag
✉
429: immediately recursive element
✉
430: invalid URN X: missing «»:»»
✉
431: invalid URN X: missing «»urn:»» prefix
✉
432: invalid URN X: invalid namespace identifier
✉
433: invalid URN X: invalid namespace specific string
✉
434: invalid URN X: extra field
✉
435: prolog can’t be omitted unless CONCUR NO and LINK EXPLICIT NO and either IMPLYDEF ELEMENT YES or IMPLYDEF DOCTYPE YES
✉
436: can’t determine name of #IMPLIED document element
✉
437: can’t use #IMPLICIT doctype unless CONCUR NO and LINK EXPLICIT NO
✉
438: Sorry, #IMPLIED doctypes not implemented
✉
439: reference to DTD data entity ignored
✉
440: notation X for parameter entity Y undefined
✉
441: notation X for external subset undefined
✉
442: attribute X can’t be redeclared
✉
443: #IMPLICIT attributes have already been specified for notation X
✉
444: a name group is not allowed in a parameter entity reference in a start tag
✉
445: name group in a parameter entity reference in an end tag (SGML forbids them in start tags)
✉
446: if the declared value is NOTATION a default value of CONREF is useless
✉
447: Sorry, #ALL and #IMPLICIT content tokens not implemented
✉
Что такое валидация html кода?
Html, как известно, язык разметки, который является основой для подавляющего большинства страниц в интернете. Как у любого другого языка, у html есть правила написания — синтаксис. Валидный html-код это код, который соответствует всем рекомендациям написания кода — спецификации.
Спецификации. Что это?
Как у любого другого языка, у HTML существуют свои правила написания — синтаксис. Эти правила пишет команда профессионалов, заинтересованных в развитии html и занимающихся разработкой новых элементов, отвечающих параметрам современных устройств, актуальных современным технологиям и, самое главное, отвечающих современным требованиям безопасности. Именно правила написания элементов html, установленные разработчиками языка, называются спецификацией.
После разработки основной части нового релиза html, разработчики языка выкладывают спецификацию к нему в публичный доступ на обсуждение всех желающих вебмастеров мира, внимательно читают комментарии и, если потребуется, вносят правки. После завершения всеобщего обсуждения, новый релиз языка выходит в мир и им можно пользоваться.
Каждый документ, использующий html код, должен следовать правилам языка. Последняя опубликованная версия HTML — пятая и стала относительно сложная, так что вебмастера, не прочитавшие последнюю версию спецификации, легко могут сделать ошибки в коде.
Cколько спецификаций существует.
Начиная с HTML5, разработчики и производители браузеров могут выбирать между двумя разновидностями одного и того же языка разметки: спецификациями, разработанными консорциумом W3C, и тех, что разработаны WHATWG.
В принципе эти спецификации очень похожи, однако, с годами, между ними все больше и больше отличий. Большинству вебмастеров не стоит сильно беспокоиться по этому поводу: или эти отличия спецификаций не скажутся на их проектах, или разработчики браузеров будут поддерживать оба стандарта языка.
Однако при использовании в своих проектах только что появившихся нововведениях в одной из спецификаций, у вебмастеров могут возникнуть проблемы. Например Дэвид Бэрон из Mozilla заявил:
Если HTML-спецификации W3C и WHATWG различаются, то мы стараемся следовать спецификации WHATWG.
Зачем нужна валидация?
Поисковые роботы сканируют страницы вашего сайта для поиска релевантного контента. Поисковые роботы подчиняются стандартам HTML. Если в вашем HTML коде есть грубые ошибки, то роботы могут запутаться и не найти контенте на вашей странице. Не закрытый тег или кривая верстка сильно ударят по изучению вашего сайте роботами. Наличие битых ссылок существенно замедлит индексацию вашего ресурса. Валидный код в разы упрощает индексацию страниц вашего сайта и позволяет им быстрее оказаться в выдаче.
Разбор ошибок на примере главной страницы сайта Клондайка.
В данной части статьи разберем валидацию html5 по спецификации W3C на примере главной страницы сайта студии Клондайк.
Как проверить HTML код на валидность?
Для проверки валидации нашего HTML5 кода используем известный HTML Validator для проверки соответствия кода W3C стандартам. Не смотря на то, что не все HTML ошибки приведут к проблемам поискового ранжирования, некоторые из них могут затруднить поисковым системам успешно индексировать страницы и могут испортить все ваши SEO усилия.
Переходим на сайт валидатора от W3C, выбираем вкладку «Validate by URL», в поле «Address» вставляем адрес проверяемого сайта и жмем кнопку «Check».
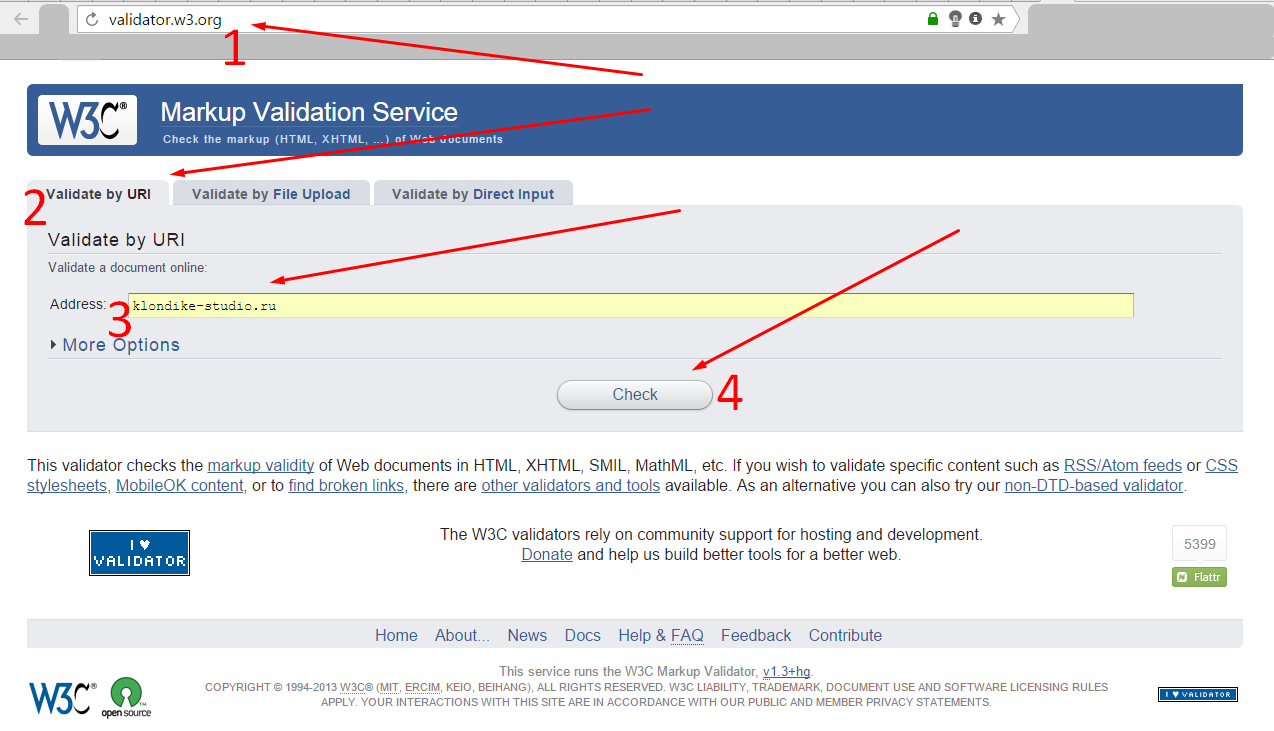
Через пару секунд получаем результат проверки.

В нашем случае было обнаружено 36 ошибок.
Рассмотрим каждую ошибку по отдельности.
Как мы сразу видим, валидатор показывает что на нашей главной странице присутствует сразу 24 однотипных ошибки — у нас не проставлен атрибут alt у картинок.
Смотрим исходный код сайта:
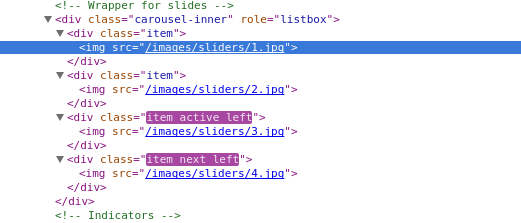
Действительно, у картинок не прописан атрибут alt.
Зачем нужен этот атрибут? Когда загружается страница, вначале загружается текст из атрибута alt, а уже после идёт смена текста на изображение. Если в браузере отключена загрузка изображений, то на месте изображения будет альтернативный текст (из атрибута alt).
Что ж, приступим к исправлению. Для каждой картинки мы пропишем соответствующий ей атрибут alt.
Далее убираем лишний закрывающий тег </section>

Валидатор показывает нам, что на проверяемой странице сразу в 4 местах использован устаревший тег nobr.
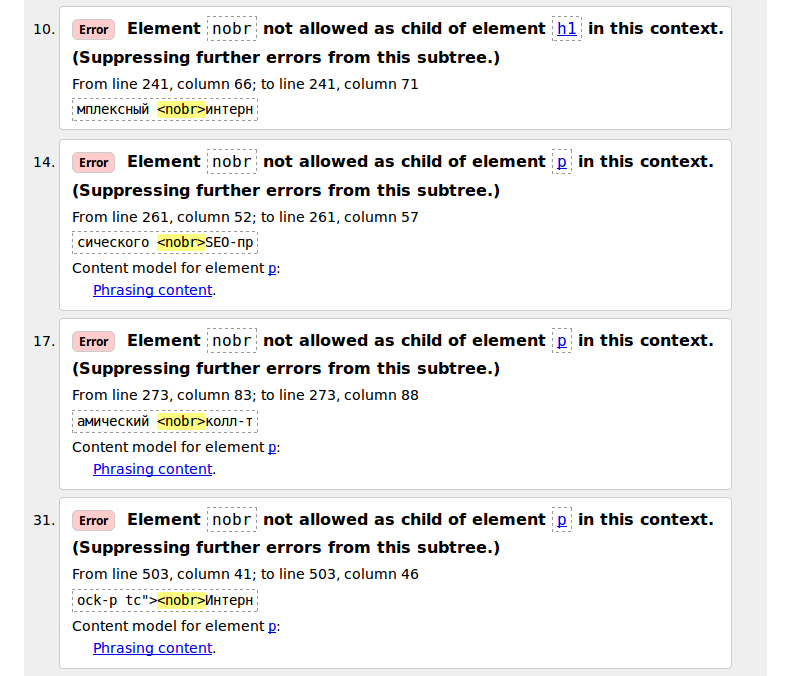
Этот тег использован у слов которые пишутся через дефис. По правилам русского языка, такие слова не следует разрывать переносом на другую строку, если слово целиком не умещается на предыдущей строке. На мобильных устройствах очень большая вероятность что такие слова будут перенесены из-за небольших размеров экранов. Поэтому, ради соответствия правилам русского языка и грамотного отображения контента, мы пожертвуем 100% валидацией и оставим тег <nobr> в коде страницы.
Переходим к следующей ошибке

Смотрим исходный код и находим искомое место:
<input type="submit" value="OK" name="OK" value="Подписаться">
Идем в шаблон компонента, находим:
<input type="submit" value="OK" name="OK" value="<?=GetMessage("subscr_form_button")?>">
Удаляем лишнее value=»<?=GetMessage(«subscr_form_button»)?>» и у нас остается:
<input type="submit" value="OK" name="OK">
Далее смотрим — валидатор обращает наше внимание на том, что тегу <nav> не обязательно прописывать атрибут role.

Однако это не является ошибкой, поэтому не будем трогать.
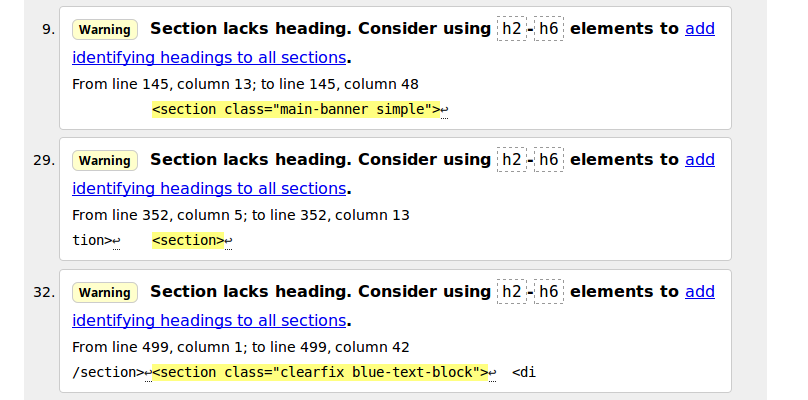
Отсутствие заголовка внутри тега <section> тоже не является ошибкой, поэтому дабы не сломать шаблон, не станем лезть в него и править то, что валидатор W3C HTML5 не указал как Error.

В данном случае валидатору не понравился значок & и предлагает нам заменить его на &. Однако, если мы глянем исходный код:
<link href='http://fonts.googleapis.com/css?family=PT+Sans:400,700&subset=latin,cyrillic' rel='stylesheet' type='text/css'>
то увидим что делать нам этого никак нельзя. Поэтому просто игнорим это и идем дальше.

В этому случае валидатор ругается на атрибуты width и height для тега <a>.
Смотрим исходный код:

и понимаем что это API Твиттра и ничего мы с ним поделать не можем. Так что пропускаем.
У нас остался один не исправленный, или хотя бы не разобранный пункт — не прописан alt у очередной картинки.
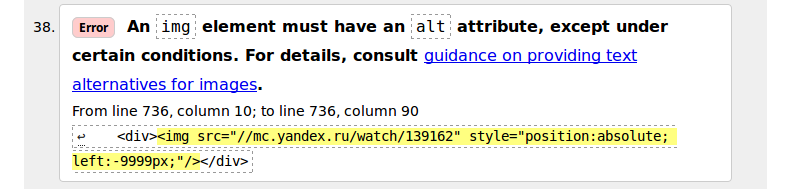
Лезем в исходный код и видим что это код Яндекс.Метрики.
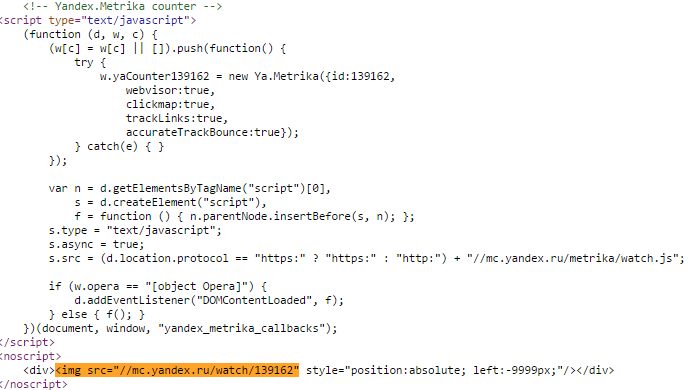
Ок. Сюда нам тоже лезть не с руки, ибо такой код генерирует сам Яндекс.
Выводы
Вот мы и прошлись по всем ошибкам которые нам показал валидатор W3C HTML5. Что мной было уяснено в ходе написания этой статьи:
- Верстка должна быть валидной уже на этапе написания шаблона сайта, ибо исправлять верстку в дальнейшем — выйдет себе дороже.
- Иногда не получится выкрутиться и написать полностью валидный шаблон сайта. Некоторые теги устарели для спецификации, однако они выполняют очень важную роль для отображения элемента или контента. Или вставляя на сайт виджеты со сторонних ресурсов мы рискуем вставить код на который будет ругаться валидатор, т.к. внешний ресурс, в силу различный обстоятельств, не позаботился о том чтобы код виджета был валидным.
- Для того чтобы код сайта был 100% валиден HTML5 по W3C разработчику сайта придется потратить в несколько раз больше времени, в то время как клиент не всегда готов оплачивать время затраченное на вылизывание шаблона.
Ну и на последок проверим на соответствие рекомендациям спецификации HTML5 по W3C несколько популярных сайтов:
- На главной странице Гугла валидатор обнаружил 32 ошибки
- На главной странице Яндекса валидатор обнаружил 106 ошибок
- На главной странице Фейсбука валидатор обнаружил 65 ошибок
- На главной странице Вконтакте валидатор обнаружил 30 ошибки
- На главной странице W3C валидатор обнаружил 7 ошибок
- На главной странице самого себя валидатор обнаружил 6 ошибок
Просмотров 8.6к. Опубликовано 19.12.2022
Обновлено 19.12.2022
Каждый сайт, который создает компания, должен отвечать принятым стандартам. В первую очередь затем, чтобы он попадал в поисковую выдачу и был удобен для пользователей. Если код страниц содержит ошибки, неточности, он становится “невалидным”, то есть не соответствующим требованиям. В результате интернет-ресурс не увидят пользователи или информация на нем будет отображаться некорректно.
В этой статье рассмотрим, что такое валидность, какие могут быть ошибки в HTML-разметке и как их устранить.
Содержание
- Что такое HTML-ошибка валидации и зачем она нужна
- Чем опасны ошибки в разметке
- Как проверить ошибки валидации
- Предупреждения
- Ошибки
- Пример прохождения валидации для страницы сайта
- Как исправить ошибку валидации
- Плагины для браузеров, которые помогут найти ошибки в коде
- Коротко о главном
Что такое HTML-ошибка валидации и зачем она нужна
Под понятием “валидация” подразумевается процесс онлайн-проверки HTML-кода страницы на соответствие стандартам w3c. Эти стандарты были разработаны Организацией всемирной паутины и стандартов качества разметки. Сама организация продвигает идею унификации сайтов по HTML-коду — чтобы каждому пользователю, вне зависимости от браузера или устройства, было удобно использовать ресурс.
Если код отвечает стандартам, то его называют валидным. Браузеры могут его прочитать, загрузить страницы, а поисковые системы легко находят страницу по соответствующему запросу.
Чем опасны ошибки в разметке
Ошибки валидации могут разными — видимыми для глаза простого пользователя или такими, которые можно засечь только с помощью специальных программ. В первом случае кроме технических проблем, ошибки в разметке приводят к негативному пользовательскому опыту.
К наиболее распространённым последствиям ошибок в коде HTML-разметки также относят сбои в нормальной работе сайта и помехи в продвижении ресурса в поисковых системах.
Рассмотрим несколько примеров, как ошибки могут проявляться при работе:
- Медленно подгружается страница
Согласно исследованию Unbounce, более четверти пользователей покидают страницу, если её загрузка занимает более 3 секунд, ещё треть уходит после 6 секунд;
- Не видна часть текстовых, фото и видео-блоков
Эта проблема делает контент для пользователей неинформативным, поэтому они в большинстве случаев уходят со страницы, не досмотрев её до конца;
- Страница может остаться не проиндексированной
Если поисковый робот распознает недочёт в разметке, он может пропустить страницу и прервать её размещение в поисковых системах;
- Разное отображение страниц на разных устройствах
Например, на компьютере или ноутбуке страница будет выглядеть хорошо, а на мобильных гаджетах половина кнопок и изображений будет попросту не видна.
Из-за этих ошибок пользователь не сможет нормально работать с ресурсом. Единственное решение для него — закрыть вкладку и найти нужную информацию на другом сайте. Так количество посетителей сайта постепенно уменьшается, он перестает попадать в поисковую выдачу — в результате ресурс становится бесполезным и пропадает в пучине Интернета.
Как проверить ошибки валидации
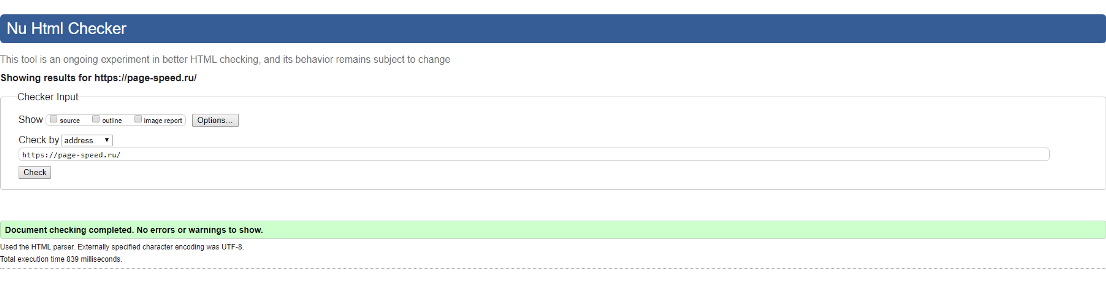
Владельцы ресурсов используют 2 способа онлайн-проверки сайтов на наличие ошибок — технический аудит или использование валидаторов.
Первый случай подходит для серьёзных проблем и масштабных сайтов. Валидаторами же пользуются ежедневно. Наиболее популярный — сервис The W3C Markup Validation Service. Он сканирует сайт и сравнивает код на соответствие стандартам W3C. Валидатор выдаёт 2 типа несоответствий разметки стандартам W3C: предупреждения и ошибки.
Давайте рассмотрим каждый из типов чуть подробнее.
Предупреждения
Предупреждения отмечают незначительные проблемы, которые не влияют на работу ресурса. Они появляются из-за расхождений написания разметки со стандартами W3C.
Тем не менее, предупреждения всё равно нужно устранять, так как из-за них сайт может работать медленнее — например, по сравнению с конкурентами с такими же сайтами.
Примером предупреждения может быть указание на отсутствие тега alt у изображения.
Ошибки
Ошибки — это те проблемы, которые требуют обязательного устранения.
Они представляют угрозу для корректной работы сайта: например, из-за них могут скрываться разные блоки — текстовые, фото, видео. А в некоторых более запущенных случаях содержимое страницы может вовсе не отображаться, и сам ресурс не будет загружаться. Поэтому после проверки уделять внимание ошибкам с красными отметками нужно в первую очередь.
Распространённым примером ошибки может быть отсутствие тега <!DOCTYPE html> в начале страницы, который помогает информации преобразоваться в разметку.
Пример прохождения валидации для страницы сайта
Рассмотрим процесс валидации на примере сайта avavax.ru, который создали на WordPress.
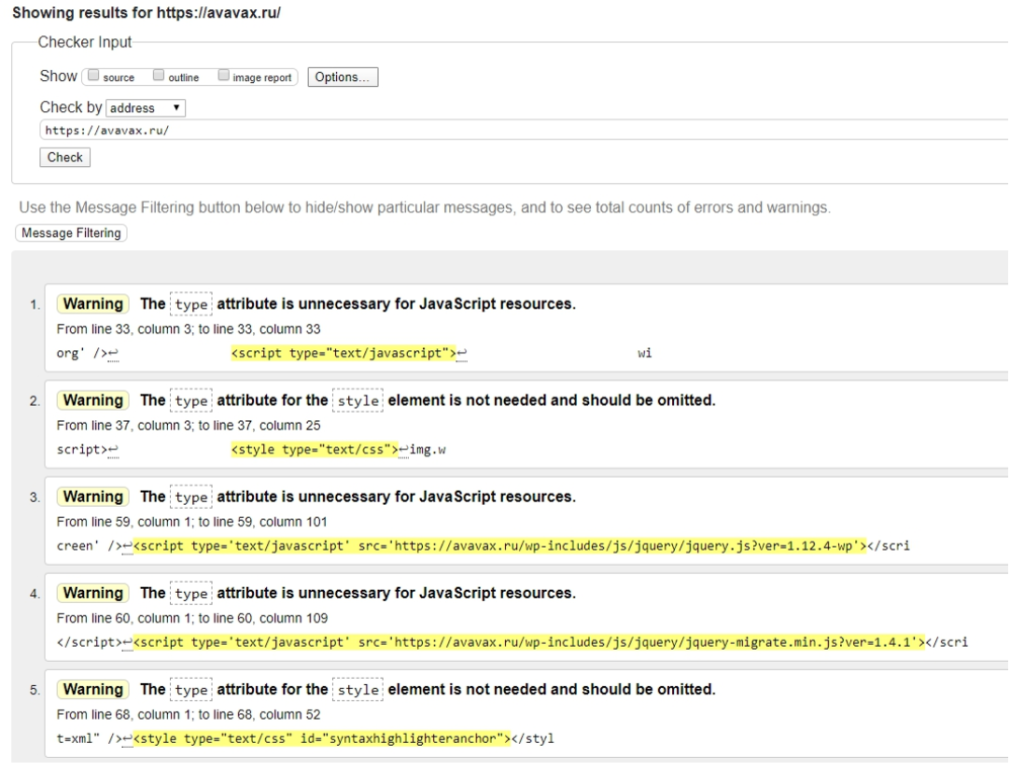
В результате проверки валидатор выдал 17 замечаний. После анализа отчета их можно свести к 3 основным:
- атрибут ‘text/javascript’ не требуется при подключении скрипта;
- атрибут ‘text/css’ не требуется при подключении стиля;
- у одного из элементов section нет внутри заголовка h1-h6.
Первое и второе замечания генерирует сам движок WordPress, поэтому разработчикам не нужно их убирать. Третье же замечание предполагает, что каждый блок текста должен иметь заголовок, даже если это не всегда необходимо или видно для читателя.
Решить проблемы с предупреждениями для стилей и скриптов можно через добавление кода в файл темы function.php.
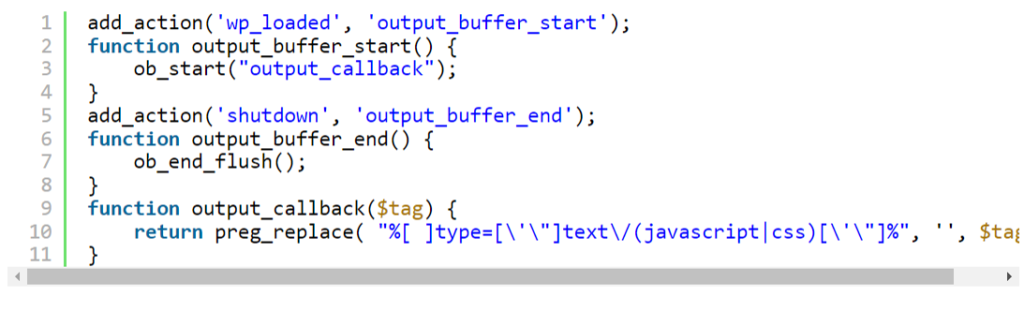
Для этого на хук wp_loaded нужно повесить функцию output_buffer_start(), которая загрузит весь генерируемый код html в буфер. При выводе в буфер вызывается функция output_callback($tag), которая просматривает все теги, находит нежелательные атрибуты с помощью регулярных выражений и заменяет их пробелами. Затем на хук ‘shutdown вешается функция output_buffer_end(), которая возвращает обработанное содержимое буфера.
Для исправления семантики на сайте нужно использовать заголовки. Валидатор выдаёт предупреждение на секцию about, которая содержит фото и краткий текст. Валидатор требует, чтобы в каждой секции был заголовок. Для исправления предупреждения нужно добавить заголовок, но сделать это так, чтобы его не было видно пользователям:
- Добавить заголовок в код: <h3>Обо мне</h3>
Отключить отображение заголовка:
1 #about h3 {
2 display: none;
3 }
После этой части заголовок будет в коде, но валидатор его увидит, а посетитель — нет.
За 3 действия удалось убрать все предупреждения, чтобы качество кода устроило валидатор. Это подтверждается зелёной строкой с надписью: “Document checking completed. No errors or warnings to show”.
Как исправить ошибку валидации
Всё зависит от того, какими техническими знаниями обладает владелец ресурса. Он может сделать это сам, вручную. Делать это нужно постепенно, разбирая ошибку за ошибкой. Но нужно понимать, что если при проверке валидатором было выявлено 100 проблем — все 100 нужно обязательно решить.
Поэтому если навыков и знаний не хватает, лучше привлечь сторонних специалистов для улучшения качества разметки. Это могут быть как фрилансеры, так и профессиональные веб-агентства. При выборе хорошего специалиста, результат будет гарантироваться в любом случае, но лучше, чтобы в договоре оказания услуг будут чётко прописаны цели проведения аудита и гарантии решения проблем с сайтом.
Если объём работ большой, выгоднее заказать профессиональный аудит сайта. С его помощью можно обнаружить разные виды ошибок, улучшить внешний вид и привлекательность интернет-ресурса для поисковых ботов, обычных пользователей, а также повысить скорость загрузки страниц, сделать качественную верстку и избавиться от переспама.
Плагины для браузеров, которые помогут найти ошибки в коде
Для поиска ошибок валидации можно использовать и встроенные в браузеры плагины. Они помогут быстро находить неточности еще на этапе создания кода.
Для каждого браузера есть свой адаптивный плагин:
- HTML Validator для браузера Firefox;
- HTML Validator for Chrome;
- HTML5 Editor для Opera.
С помощью этих инструментов можно не допускать проблем, которые помешают нормальному запуску сайта. Плагины помогут оценить качество внешней и внутренней оптимизации, контента и другие характеристики.
Коротко о главном
Валидация — процесс выявления проблем с HTML-разметкой сайта и ее соответствия стандартам W3C. Это унифицированные правила, с помощью которых сайт может нормально работать и отображаться и для поисковых роботов, и для пользователей.
Проверку ресурса можно проводить тремя путями: валидаторами, специалистам полномасштабного аудита и плагинами в браузере. В большинстве случаев валидатор — самое удобное и быстрое решение для поиска проблем. С его помощью можно выявить 2 типа проблем с разметкой — предупреждения и ошибки.
Работать необходимо сразу с двумя типами ошибок. Даже если предупреждение не приведет к неисправности сайта, оставлять без внимания проблемные блоки нельзя, так как это снизит привлекательность ресурса в глазах пользователя. Ошибки же могут привести к невозможности отображения блоков на сайте, понижению сайта в поисковой выдаче или полному игнорированию ресурса со стороны поискового бота.
Даже у крупных сайтов с миллионной аудиторией, например, Яндекс.Дзен или ВКонтакте, есть проблемы с кодом. Но комплексный подход к решению проблем помогает устранять серьёзные моменты своевременно. Нужно развивать сайт всесторонне, чтобы получить результат от его существования и поддержки. Если самостоятельно разобраться с проблемами не получается, не стоит “доламывать” — лучше обратиться за помощью к профессионалам, например, агентствам по веб-аудиту.
Что такое валидация HTML?
Валидация HTML является одним из основных факторов, влияющих на качество веб-дизайна.
Консорциум Всемирной паутины (W3C) — это международное сообщество, которое де-факто определило стандарты написания HTML кода на вашем веб-сайте. Эти правила были созданы для того, чтобы браузеры могли корректно обрабатывать код и правильно отображать веб-страницы. Было много версий стандартов HTML, последней версией является HTML5. Она добавила интересные функции, такие как хранение данных локально в браузерах пользователей, встроенная поддержка аудио и видео, поддержка векторной графики и прочее.
В Интернете доступно множество инструментов, которые специально созданы для проверки кода в соответствии со стандартами W3C. Для HTML5 самым популярным является Nu HTML Checker, а для вашего удобства вы можете им воспользоваться на нашем сайте.
На что влияет валидность кода
- Поддержка кроссбраузерности.
- Если ваш HTML-код валиден, он будет корректно отображаться во всех основных веб-браузерах (Chrome, Safari, Firefox, Opera, Edge/Explorer), а также будет выглядеть одинаково или почти одинаково в каждом из них.
- Оптимизация в поисковых системах.
- Это повысит вероятность правильной индексации содержимого вашей страницы поисковыми системами. Ваш контент должен соответствовать семантической верстке, и один из способов обеспечить это является проверка кода. Валидатор поможет убедиться, что все HTML-теги закрыты и вы их правильно используете, а так же покажет другие важные и распространенные проблемы, которые могут помешать нормальной индексации поисковыми роботами. По утверждению Google, правильность кода не влияет на позиции в поисковиках. Но при этом наличие ошибок в коде способно негативно повлиять на сканирование микроразметки и адаптивность под мобильные устройства.
- Возникновение ошибок в браузере.
- Бывают ситуации, когда владелец сайта недоумевает, почему один блок «съехал». Или почему в одном браузере все в порядке, а в другом верстка плывет. И пытается решить это при помощи CSS. Вместо этого в первую очередь следует проверить код на ошибки – высока вероятность того, что проблема кроется именно в этом.
- Чистый HTML-код.
- Если ваш код проверен и написан правильно, он сделает задачу по его обновлению и внесению изменений намного проще. Это значительно снизит шансы, что редактирование CSS или добавление фрагмента кода HTML приведет к нарушению вашей веб-страницы.
- Поддержка новейших версий веб-браузера.
- Браузеры часто обновляются и, как правило, стараются поддерживать и соблюдать стандарты HTML W3C. Если ваш код соответствует требованиям W3C, он должен снизить шансы на появление «сломанной» страницы в будущих версиях.
Частые вопросы
- Валидатор показывает ошибки на моем сайте, но он отображается нормально.
- Условно ошибки можно разделить на две категории: критические и не критические. И, несмотря на то, что современные браузеры стараются понимать такой код – это не дает гарантии корректного отображения во всех браузерах и устройствах. Помимо этого, некоторые из ваших материалов могут не индексироваться должным образом поисковыми системами.
- Валидатор ругается на нестандартные атрибуты.
- Атрибуты, которые не задокументированы W3C считаются ошибочными. Однако, в некоторых случаях их удаление может привести к потере функционала. Например, атрибуты flag и price служат для связки целей. Я бы не стал считать это ошибкой, которая может навредить сайту и удалять их не нужно.
- На моем сайте тысячи страниц с ошибками.
- Большинство сайтов и интернет-магазинов работают на различных CMS (система управления сайтом). Это означает, что страницы выводятся с помощью шаблона. Как правило, для того чтобы избавиться от ошибок на типовых страницах – достаточно исправить их в шаблоне. Но иногда код находится в базе данных – в этом случае нужно работать индивидуально над каждой страницей. Такой же вариант работы, если у вас сайт на чистом html.
Как исправить ошибки кода
Если вы обладаете навыками программирования и верстки, то исправить большинство ошибок для вас не составит особого труда – достаточно понимать смысл ошибки, на которую указывает валидатор.
Владельцам сайтов, не обладающим такими навыками без посторонней помощи не обойтись. На нашем сайте вы можете заполнить заявку на бесплатный анализ и оценку стоимости работ. А при одновременном заказе исправления ошибок кода и ускорения сайта вы получите 10% скидку.
Если вы не знаете, как исправить ту или иную ошибку – спрашивайте в комментариях, постараюсь помочь.
Как проверить CSS и HTML-код на валидность и зачем это нужно.
В статье:
-
Что такое валидность кода
-
Чем ошибки в HTML грозят сайту
-
Как проверить код на валидность
-
HTML и CSS валидаторы — онлайн-сервисы для проверки кода
Разберем, насколько критическими для работы сайта и его продвижения могут быть ошибки в HTML-коде, и зачем нужны общие стандарты верстки.
Что такое валидность кода
После разработки дизайна программисты верстают страницы сайта — приводят их к единой структуре в формате HTML. Задача верстальщика — сделать так, чтобы страницы отображались корректно у всех пользователей на любых устройствах и браузерах. Такая верстка называется кроссплатформенной и кроссбраузерной — это обязательное требование при разработке любых сайтов.
Для этого есть специальные стандарты: если им следовать, страницу будут корректно распознавать все браузеры и гаджеты. Такой стандарт разработал Консорциумом всемирной паутины — W3C (The World Wide Web Consortium). HTML-код, который ему соответствует, называют валидным.
Валидность также касается файлов стилей — CSS. Если в CSS есть ошибки, визуальное отображение элементов может нарушиться.
Разработчикам рекомендуется следовать критериям этих стандартов при верстке — это поможет избежать ошибок в коде, которые могут навредить сайту.
Чем ошибки в HTML грозят сайту
Типичные ошибки кода — незакрытые или дублированные элементы, неправильные атрибуты или их отсутствие, отсутствие кодировки UTF-8 или указания типа документа.
Какие проблемы могут возникнуть из-за ошибок в HTML-коде
- страницы загружаются медленно;
- сайт некорректно отображается на разных устройствах или в браузерах;
- посетители видят не весь контент;
- программист не замечает скрытую рекламу и вредоносный код.
Как валидность кода влияет на SEO
Валидность не является фактором ранжирования в Яндекс или Google, так что напрямую она не влияет на позиции сайта в выдаче поисковых систем. Но она влияет на мобилопригодность сайта и на то, как поисковые боты воспринимают разметку, а от этого косвенно могут пострадать позиции или трафик.
Почитать по теме:
Главное о микроразметке: подборка знаний для веб-мастеров
Представитель Google Джон Мюллер говорил о валидности кода:
«Мы упомянули использование правильного HTML. Является ли фактором ранжирования валидность HTML стандарту W3C?
Это не прямой фактор ранжирования. Если ваш сайт использует HTML с ошибками, это не значит, что мы удалим его из индекса — я думаю, что тогда у нас будут пустые результаты поиска.
Но есть несколько важных аспектов:— Если у сайта действительно битый HTML, тогда нам будет очень сложно его отсканировать и проиндексировать.
— Иногда действительно трудно подобрать структурированную разметку, если HTML полностью нарушен, поэтому используйте валидатор разметки.
— Другой аспект касается мобильных устройств и поддержки кроссбраузерности: если вы сломали HTML, то сайт иногда очень трудно рендерить на новых устройствах».
Итак, критические ошибки в HTML мешают
- сканированию сайта поисковыми ботами;
- определению структурированной разметки на странице;
- рендерингу на мобильных устройствах и кроссбраузерности.
Даже если вы уверены в своем коде, лучше его проверить — ошибки могут возникать из-за установки тем, сторонних плагинов и других элементов, и быть незаметными. Не все программисты ориентируются на стандарт W3C, так что среди готовых решений могут быть продукты с ошибками, особенно среди бесплатных.
Как проверить код на валидность
Не нужно вычитывать код и считать символы — для этого есть сервисы и инструменты проверки валидности HTML онлайн.
Что они проверяют:
- Синтаксис
Синтаксические ошибки: пропущенные символы, ошибки в написании тегов. - Вложенность тэгов
Незакрытые и неправильно закрытые теги. По правилам теги закрываются также, как их открыли, но в обратном порядке. Частая ошибка — нарушенная вложенность.
- DTD (Document Type Definition)
Соответствие кода указанному DTD, правильность названий тегов, вложенности, атрибутов. Наличие пользовательских тегов и атрибутов — то, чего нет в DTD, но есть в коде.
Обычно сервисы делят результаты на ошибки и предупреждения. Ошибки — опечатки в коде, пропущенные или лишние символы, которые скорее всего создадут проблемы. Предупреждения — бессмысленная разметка, лишние символы, какие-то другие ошибки, которые скорее всего не навредят сайту, но идут вразрез с принятым стандартом.
Валидаторы не всегда правы — некоторые ошибки не мешают браузерам воспринимать код корректно, зато, к примеру, минификация сокращает длину кода, удаляя лишние пробелы, которые не влияют на его отображение.
Почитать по теме:
Уменьшить вес сайта с помощью gzip, brotli, минификации и других способов
Поэтому анализируйте предложения сервисов по исправлениям и ориентируйтесь на здравый смысл.
Перед исправлением ошибок не забудьте сделать резервное копирование. Если вы исправите код, но что-то пойдет не так и он перестанет отображаться, как должен, вы сможете откатить все назад.
HTML и CSS валидаторы — онлайн-сервисы для проверки кода
Есть довольно много валидаторов, выберите тот, в котором вам удобнее работать. Мы рекомендуем использовать известные сервисы от создателей стандартов. Если пояснения на английском воспринимать сложно, можно использовать автоматический перевод страницы.
Валидатор от W3C
Англоязычный сервис, онлайн проверяет соответствие HTML стандартам: можно проверить код по URL, залить файл или вставить код в окошко.
Инструмент покажет список ошибок и предупреждений с пояснениями — описанием ошибки и ее типом, а также укажет номер строки, в которой нужно что-то исправить. Цветом отмечены типы предупреждений и строчки с кодом.

Валидатор CSS от W3C
Инструмент от W3C для проверки CSS, есть русский язык. Работает по такому же принципу, анализирует стили на предмет ошибок и предупреждений. Первым идет блок ошибок, предупреждения собраны ниже отдельно.

Исправления ошибок и валидации HTML и CSS может быть недостаточно: всегда есть другие возможности испортить отображение сайта. Если что-то не работает, как надо, проведите полноценный аудит, чтобы найти ошибки.
С другой стороны, не зацикливайтесь на поиске недочетов в HTML — если код работает, а контент отображается корректно, лучше направить ресурсы на что-то другое — оптимизацию и ускорение загрузки, например.

При проверке релевантности контента поисковые боты большое внимание уделяют вопросу соответствия стандартам html.
Даже одного пропущенного знака, битой ссылки или неправильной верстки достаточно, чтобы алгоритм не пропустил такой контент и не проиндексировал веб-страницу.
Некоторые функциональные элементы уже морально устарели, но многие до сих пор являются жизненно необходимыми для развития.
Безусловно, все это негативно скажется на позициях сайта.
Поэтому чтобы ресурс успешно прошел индексацию, необходимо провести валидацию.
Это процесс проверки на соблюдение установленных норм, корректности проставления кода страницы.
Валидация позволяет проанализировать сайт и выявить те ошибки, которые необходимо исправить для дальнейшего продвижения.
Проверка W3C html – это анализ кода веб-сайтов для определения соответствия стандартам форматирования.
В этой статье мы подробно остановимся на стандартах W3С, преимуществах их использования и расскажем про наиболее эффективные и удобные сервисы проверки.
Что означает W3C?
Аббревиатура W3C (World Wide Web) обозначает сообщество единых стандартов.
Еще со времен зарождения Всемирной паутины этот консорциум определил единые стандарты для всех веб-страниц с целью правильного отображения их различными браузерами.
С развитием Сети между создателями различных браузеров постоянно ведется ожесточенная борьба за первенство.
И были времена, когда разработчики даже пытались внедрить свои собственные стандарты.
Однако первоисточнику удалось сохранить стандарты таких веб-страниц, какими мы видим их сейчас.
И сегодня веб-мастерам остается лишь придерживаться этих правил при создании ресурсов.
Проведение такого исследования является важным этапом работы с целью обеспечения высокого качества страниц любого сайта при отображении на различных устройствах.
В этой статье мы будем много говорить о стандартах HTML, и в связи с этим возникает резонный вопрос: а для чего вообще они были введены?
Первоочередной задачей таких стандартов является обеспечение совместимости.
До их введения разработчики особо не заботились о том, как сайты будут отображаться на других устройствах.
Как правило, веб-ресурс создавался под конкретный браузер, устройство.
Но с развитием технологий пришло понимание необходимости создать единый стандарт языка разметки веб-страниц.
Это делает работу в Сети удобной для большинства пользователей, независимо от того, в какой части света они находятся и какой браузер используют.
Итак, целью утверждения стандартов html является:
- доставить максимальную пользу наибольшему количеству веб-пользователей;
- обеспечить долгосрочную жизнеспособность любого веб-документа;
- упростить код и снизить стоимость производства;
- предоставлять сайты, которые доступны большему количеству людей и большему числу типов электронных устройств;
- продолжать работать корректно по мере развития браузеров и появления новых устройств на рынке.
Преимущества валидатора W3C
W3C-валидатор призван проверить, насколько сайт соответствует единым стандартам и, при обнаружении неточностей, указывает на них.
Если игнорировать данный анализ, то может оказаться, что плохой трафик, проблемы с продвижением возникают из-за банальных неточностей кода.
Бывает достаточно одной опечатки, неправильно закрытой скобки, чтобы сайт неверно прогружался в браузере.
А, как известно, проблемы с загрузкой сайта или неправильным его отображением приводят к тому, что пользователи быстро покидают эту веб-страницу.
Поэтому использование сервисов проверки дает массу преимуществ:
1. Поднятие рейтинга в поисковых системах
Проверка html-кода поможет избежать неточностей или ошибок в коде, облегчая работу СЕО сайта.
Алгоритмы поисковиков настроены таким образом, что при индексации боты проверяют код гипертекста на предмет его соответствия единым стандартам.
При обнаружении ошибок они попросту игнорируют страницу (или ее часть), оставляя ее непроиндексированной.
Вообще вокруг темы взаимосвязи валидации сайта и его дальнейшего продвижения существует множество мифов, и мнения экспертов на этот счет разнятся.
Идеально прописанный код страницы еще не является гарантом ее дальнейшего высокого рейтинга.
Об этом свидетельствует тот факт, что, например, у Google в ходе проверки было обнаружено около 30 ошибок в коде, а у Яндекса – целых 75 неточностей.
Здесь важно увидеть и проанализировать ошибки, обнаруженные сервисами, и понять, какие из них отразятся на производительности и работоспособности веб-ресурса.
2. Улучшение эффективности сайта
Проверенные сайты становятся доступными для просмотра в любом браузере, что сказывается на производительности проекта.
Работая над уменьшением ошибок и прописывая верный код, специалист постепенно уменьшает вес страницы, что улучшает скорость загрузки.
Безусловно, все эти нюансы положительно отражаются на дальнейшем СЕО сайта.
И наоборот, непроверенные сайты могут не только плохо прогружаться на различных видах браузеров, но и значительно снижать трафик из-за элементарных ошибок в разметке.
3. Универсальность для любого браузера
Одной из главных причин создания стандартов W3C стало правильное отображение веб-страниц на любом браузере.
Без подобных правил сложно представить, насколько была бы усложнена работа в интернете.
Сайты, не прошедшие валидацию, могут хорошо отображаться в каком-то одном браузере, но при этом выдавать ошибки в другом.
Проверка кода позволяет следить за правильностью отображения сайта в разных программах.
Стоит мастеру допустить неточность, не закрыть тег или сделать ошибку в коде, как это приводит к тому, что сайт начинает отображаться в браузерах по-разному.
4. Адаптивность для разных видов устройств
Статистика показывает, что все большее количество юзеров предпочитают просматривать сайты со своих смартфонов.
А значит, адаптация ресурса под все виды электронных гаджетов – это обязательный этап работы над сайтом.
И без использования W3C-технологий этого будет сложно добиться.
Ведь проверка сразу укажет на те ошибки, которые не позволяют нормально отображаться сайту на том или ином устройстве.
Поэтому при разработке сайта важным этапом внедрения продукта является проверка его с помощью валидатора и дальнейший тест-драйв на различных гаджетах.
5. Упрощение технического обслуживания сайта
Проверка значительно упрощает работу веб-мастеру, делает ее эффективнее при разработке следующих проектов.
Сервис исследует сайт, указывает на ошибки и позволяет создать некий шаблон, по которому в дальнейшем можно выполнять аналогичные проекты.
Это значительно снижает трудозатраты и экономит ресурсы.
Сервисы по проверке – простые и удобные.
При обнаружении ошибок в разметке страницы инструменты подчеркивают этот фрагмент соответствующим цветом.
При этом «важность» ошибки ранжируется по цвету.
Таким образом, веб-мастер может проанализировать эти недочеты и устранить наиболее грубые неточности в разметке.
Практика показывает, что не стоит исправлять все ошибки.
Можно сосредоточить внимание только на грубых, которые действительно влияют на отображение сайта в браузере, скорости загрузки и т. д.
Зачем проверять HTML- и CSS-код?
Существует ряд причин, по которым следует проверить страницу.
Во-первых, это помогает при определении браузерной совместимости.
Да, можно создать страницу, которая идеально отображается на любимом браузере даже при наличии грубых ошибок.
Но вот эти самые недочеты не позволят ей нормально отобразиться на другом браузере.
Также более поздние, усовершенствованные версии все того же любимого браузера могут исказить картину и привести к тому, что сайт уже будет отображаться некорректно.
Сегодня разработчики браузеров ориентируются на единые стандарты HTML и CSS, поэтому валидатор W3C – это своеобразная страховка от будущих версий браузеров, которые могут находить ошибки и вступать с ними в конфликт.
При наличии ошибок браузеры пытаются компенсировать это различными способами.
Одни стараются игнорировать, другие — как бы «доработать» недочеты, пытаясь представить, что именно хотел сказать разработчик.
Как правило, это негативно сказывается на скорости загрузки и отображении ресурса.
Это касается и работы алгоритмов поисковиков при индексации страницы.
При обнаружении недочетов в коде одни поисковики пытаются обойти их стороной, другие полностью останавливают работу.
В результате целые страницы остаются непроиндексированными.
Самый безопасный способ убедиться, что поисковые системы видят страницу в том виде, в котором она была задумана — это представить им страницу без ошибок.
И помочь добиться такого совершенства призваны различные сервисы по онлайн-проверке html-кода.
Ограничения: что не делает валидация?
Важно понимать рабочие ресурсы подобных сервисов и осознавать, что они всего лишь проверяют веб-страницу на наличие конкретных ошибок html-кода.
Проверка ресурса не гарантирует, что она будет выглядеть так, как задумал веб-мастер.
Это просто гарантирует, что код не будет содержать ошибок HTML или CSS.
Здесь можно провести некую аналогию с русским языком, в котором могут быть допущены синтаксические и грамматические ошибки.
Так вот сервисы по валидации призваны выявить именно синтаксические недочеты на странице.
А вот логичность, понятность для браузеров они не оценивают.
Чтобы убедиться, что код выполняет то, что от него требует разработчик, необходимо его протестировать в веб-браузере.
В идеале – произвести такую проверку в разных браузерах, чтобы убедиться, что все они действительно правильно отображают страницу.
Это поможет исключить вероятность того, что при написании были использованы те коды, которые доступны только определенным браузерам.
Рекомендуем для чтения:
- Sitemap.xml: создание карты сайта — полный курс
- Коды ответов HTTP: ТОП-10 ошибок сервера и клиента
Бесплатные сервисы для проверки кода
Предполагается, что идеально спроектированная веб-страница выполнена безупречно и дает ожидаемые результаты.
Но что, если допущены некоторые синтаксические ошибки в коде?
Ну, синтаксическая ошибка — это очень распространенная практика, ее может допустить каждый.
Прежде чем запустить веб-страницу, лучше провести тест-драйв и проверить код на наличие ошибок, опечаток.
На рынке доступны различные инструменты, которые помогут быстро и эффективно провести такой анализ.
Удобными, эффективными, а главное, бесплатными сервисами являются HTML и CSS валидатор.
Хочешь знать, есть ли на твоем сайте ошибки в верстке CSS/HTML?
Наличие этих ошибок негативно влияет на SEO.
Напиши мне и я проведу качественный анализ сайта при помощи валидаторов.
HTML VALIDATOR
Валидатор HTML – это служба, которая проверяет разметку HTML и синтаксис XHTML-кода.
Причем проверку можно проводить тремя различными способами: путем добавления файла, фрагмента текста или адреса ресурса.
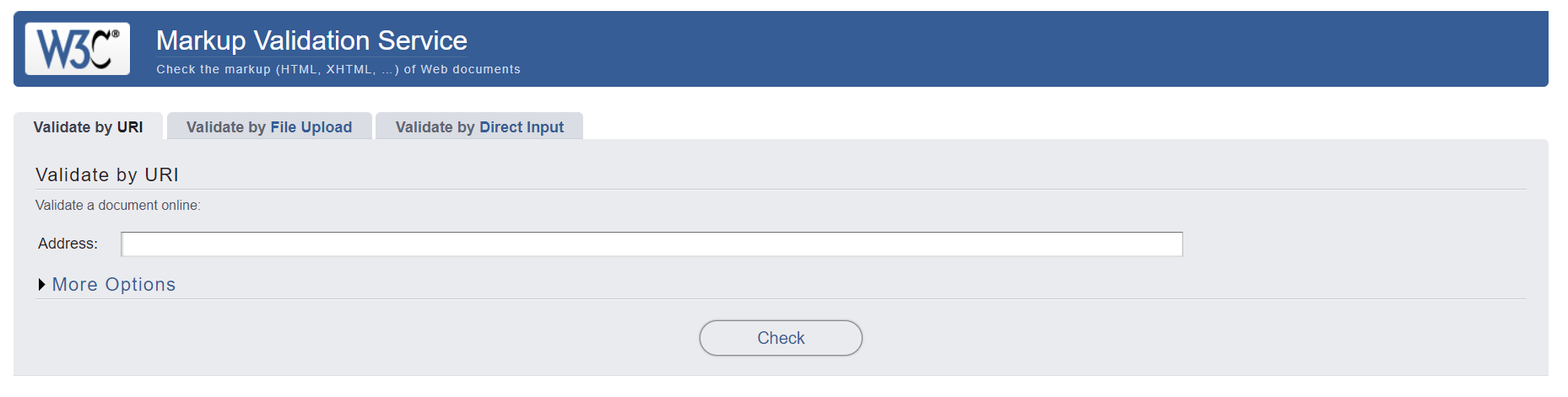
Сервис дополнительно позволяет установить набор инструментов для исследования кодировки документа, его типа.
Такие недочеты, как открытые теги, пропущенные кавычки, лишние пробелы и т. д., могут привести к тому, что веб-страница будет выглядеть совершенно иначе, чем планировалось.
Следует понимать, что служба проверяет сайт или часть текста исключительно на предмет наличия синтаксических ошибок, но не исследует семантику кода.
В рамки проверки входит:
- проверка незакрытых тегов;
- анализ синтаксиса;
- наличие лишних ненужных элементов.
CSS VALIDATOR
Удобный бесплатный сервис, позволяющий разработчикам и дизайнерам при анализе и правке CSS.
Для проверки просто вводим в строку url адрес страницы и запускаем процесс.
После исследования появится надпись об отсутствии ошибок либо же будут указаны недочеты при невалидном коде.
Дальше уже веб-мастер отрабатывает все эти недочеты и проводит повторную проверку.
Последняя вкладка позволяет сразу исследовать онлайн-часть набранного текста непосредственно в HTML.

Кроме самостоятельных сервисов проверки, существуют и встроенные плагины, призванные автоматически обнаруживать неточности в разметке.
Но эти инструменты-плагины скорее удобное дополнение, нежели полная замена валидатору.
Одним из таких плагинов является Tidy.
Он быстро сканирует страницу и выделяет неточности, которые можно классифицировать в группы:
- Предупреждения. Они содержат сведения об ошибках, которые можно устранять в автоматическом режиме.
- Ошибки. Отдельным цветом плагин подчеркивает те ошибки, которые разработчику нужно исправлять вручную.
Одним из плюсов плагина Tidy является автоматическая проверка страницы сразу в браузере.
Не нужно переключать свое внимание и загружать страницу в онлайн-проверку html-кода.
При просмотре ресурса значок в строке состояния указывает количество неточностей на странице.
Это лучшее бесплатное расширение для валидатора HTML работает на основе Tidy и OpenSP.
Оба этих алгоритма были, в первую очередь, созданы W3C.
Сервис дает возможность проводить проверку на 17 разных языках.
ЗАКЛЮЧЕНИЕ
Соответствие ресурса принятым в W3C стандартам гарантирует:
- совместимость сайта с различными браузерами;
- правильное отображение на различных устройствах (в том числе и мобильных);
- снижение возможности появления багов с различными платформами;
- эффективное продвижение сайта.
Поэтому W3C-валидатор следует включить в свой список обязательных инструментов при работе над созданием новых веб-проектов или сопровождении уже разработанных сайтов.

Что, опять? Упал трафик и нет продаж? Так SEOquick тебе поможет всё вернуть
Привлечем органический SEO-трафик на ваш сайт из поисковых систем Google и Яндекс
Проведем работы по внутренней оптимизации и SEO-продвижению. Улучшим репутацию, контент. Сделаем аудит и нарастим ссылочную массу.
Никакой черной магии – только белые методы SEO!
From Wikipedia, the free encyclopedia


Tag certifying that a website has been checked for well-formed XHTML (above) and CSS (below) markup
The Markup Validation Service is a validator by the World Wide Web Consortium (W3C) that allows Internet users to check pre-HTML5 HTML and XHTML documents for well-formed markup against a document type definition. Markup validation is an important step towards ensuring the technical quality of web pages. However, it is not a complete measure of web standards conformance.[1] Though W3C validation is important for browser compatibility and site usability, it has not been confirmed what effect it has on search engine optimization.
As HTML5 has removed the use of DTD in favor of a «Living Standard», the traditional Markup Validation Service is not applicable to these formats. Validation is instead performed using an open-source «Nu Validator», an instance of which is provided by W3C.[2]
History[edit]
The Markup Validation Service began as The Kinder, Gentler HTML Validator, a project by Gerald Oskoboiny.[1] It was developed to be a more intuitive version of the first online HTML validator written by Dan Connolly and Mark Gaither, which was announced on July 13, 1994.[3]
In September 1997, Oskoboiny began working for the W3C, and on December 18, 1997, the W3C announced its W3C HTML Validator based upon his works.[4] In November 2008, the W3C released the validator.nu HTML5 engine and the ability to check documents for conformance to HTML5.[5]
W3C also offers validation tools for web technologies other than HTML/XHTML, such as CSS, XML schemas, and MathML.[6]
Browser accommodation[edit]
Many major web browsers are often tolerant of certain types of error, and may display a document successfully even if it is not syntactically correct. Certain other XML documents can also be validated if they refer to an internal or external DTD.
Limitations[edit]
Mark-up validators cannot see the «big picture» on a web page,[clarification needed] but they excel at picking up missed closing tags and other technicalities.[6][7]
DTD-based validators are also limited in their ability to check attribute values according to many specification documents. For example, using an HTML 4.01 DOCTYPE, bgcolor="fffff" is accepted as valid for the «body» element even though the value «fffff» is missing a preceding ‘#’ character and contains only five (instead of six) hexadecimal digits. Also, for the «img» element, width=»really wide» is also accepted as valid. DTD-based validators are technically not able to test for these types of attribute value problems.
Pages may not display as intended in all browsers, even in the absence of validation errors and successful display in other browsers. The only way to ensure that pages always display as intended is to test them in all browsers expected to render them correctly.[7]
CSS validation[edit]
While the W3C and other HTML and XHTML validators will assess pages coded in those formats, a separate validator like the W3C CSS validator can check that there are no errors in the associated Cascading Style Sheet. CSS validators apply current CSS standards to referenced CSS documents.[7]
See also[edit]
- HTML Tidy, an offline markup validation program developed by Dave Raggett of W3C
- CSE HTML Validator, an offline HTML and CSS validator
- World Wide Web Consortium (W3C)
References[edit]
- ^ a b «About the W3C Markup Validation Service». W3C Markup Validation Service. World Wide Web Consortium. Retrieved 2011-05-20.
- ^ «Ready to check — Nu Html Checker». validator.w3.org.
- ^ Connolly, Dan (1994-07-13). «ANNOUNCE: HaL Interactive HTML Validation Service». www-html (Mailing list). Retrieved 2008-06-28.
- ^ Oskoboiny, Gerald (2003-03-22). «History of the Kinder, Gentler HTML Validator». Retrieved 2008-06-28.
- ^ «What’s New at The W3C Markup Validation Service». validator.w3.org. Retrieved 2016-05-31.
- ^ a b «About the CSS Validator». World Wide Web Consortium. Retrieved 2012-06-24.
- ^ a b c Castro, Elisabeth: HTML, XHTML & CSS, Sixth Edition, page 345–346. Visual Quickstart Guides, Peachpit Press, 2007. ISBN 0-321-43084-0
External links[edit]
- The W3C Markup Validation Service
- The W3C CSS Validation Service
- The W3C Monitoring Service
Рассказываем, как валидатор помогает избавиться от ошибок, которые мешают пользователям, браузерам и поисковикам.

Ошибки HTML-кода создают вагон проблем: поисковики отказываются продвигать сайт, а пользователи грустно закрывают вкладку браузера, потому что ничего не работает. Профессиональные программисты всегда проверяют код на ошибки, причем находят их за несколько секунд.
Рассказываем, как самостоятельно проверить сайт и что с ним случится, если код невалидный.
Что такое HTML-валидация и зачем она нужна
Валидация — это проверка HTML-кода: соответствует ли он общепринятым правилам и нет ли в нём ошибок. Хороший код называют валидным. Он быстро загружается, браузеры корректно обрабатывают его синтаксис, а поисковикам кажется, что сайт просто замечательный, и его позиции растут.
Стандарты качества кода придумала и поддерживает W3C. Эта организация предлагает унифицировать сайты: сделать их быстрыми, одинаково удобными и доступными для всех.

Тим Бернерс-Ли — помимо прочего, создатель HTML, Всемирной паутины и стандартов качества разметки. (Фото: w3.org)
Чем опасны ошибки в разметке
Ошибки портят впечатление о сайте, мешают ему нормально работать и продвигаться в поисковых системах. Вот конкретные примеры:
- Страницы загружаются слишком медленно. По данным Unbounce, почти 27% пользователей закрывают страницу, если она грузится больше трех секунд. Еще 32,3% уходят после шести секунд загрузки.
- Посетители видят только часть текстов и иллюстраций. А значит, контент для них почти бесполезный — и посетитель, скорее всего, уйдет к конкуренту.
- Если поисковый робот запнется хотя бы об одну ошибку — битую ссылку, пропущенный знак в коде или неправильную верстку, — он может не проиндексировать страницу.
- Сайт некорректно отображается на разных устройствах. Он может хорошо выглядеть на экране компьютера, а с телефона не будут видны тексты, кнопки или весь контент «съедет».
- На сайте много скрытой рекламы и вирусов, а разработчик или владелец сайта не в курсе.

Веб-разработчик: новая работа через 9 месяцев
Получится, даже если у вас нет опыта в IT
Узнать больше
В результате пользователь не может нормально взаимодействовать с сайтом и закрывает вкладку браузера. Сайт теряет посетителя, а поисковик отмечает ухудшение поведенческих факторов и понижает позиции в выдаче.
Почему в коде появляются ошибки. Ошибки в разметке появляются, если разработчик, например, забыл закрыть тег, случайно продублировал элемент или указал неправильный атрибут.
В валидном коде не бывает лишних скобок или знаков препинания, но сложно уследить за всем самому. Поэтому придумали валидатор, который поможет найти все ошибки за несколько секунд.
Как пользоваться валидатором
Валидатор — это сервис проверки валидности HTML, который быстро находит ошибки в коде и помогает их исправить. Подобных сервисов несколько, но разработчики часто используют официальный валидатор W3C. В нём можно найти ошибки тремя способами: указать URL сайта, загрузить HTML-документ или HTML-код.
Валидатор не сделает сайт идеальным, но поможет избавиться от ошибок, которые мешают пользователям, браузерам и поисковикам.
Что проверяет валидатор
Сервис проверяет синтаксис кода: например, верно ли указаны тип документа и кодировка, нет ли в коде пропущенных элементов. Также происходит проверка соответствию DTD (Document Type Definition) — валидатор смотрит, соответствует ли код типу документа.
DTD — это инструкция для браузера, которая помогает ему правильно отображать HTML-документ.
Как интерпретировать результат
Валидатор делит проблемные части кода на предупреждения и ошибки. Для удобства они выделены разными цветами, чтобы сразу было понятно, каким проблемам стоит уделить особое внимание.
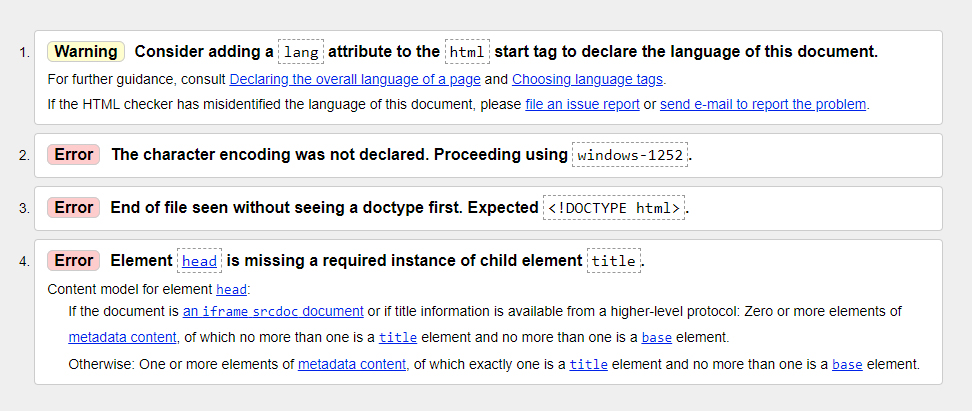
Пример результатов проверки, который наглядно показывает, что такое ошибка валидации. Предупреждения выделены желтым, ошибки — красным. (Скриншот: validator.w3.org)
Предупреждения
Незначительные проблемы. Сайт, скорее всего, не сломается, но всё равно не соответствует спецификациям W3C.
Это означает, что при прочих равных сайты конкурентов будут лучше работать на разных устройствах и эффективнее продвигаться в поисковых системах.
Ошибки
Серьезные проблемы. Есть риск, что сайт будет отображаться некорректно, часть контента окажется скрытой или пользователь вообще не сможет просматривать страницы.
Ошибки следует исправлять в первую очередь, но хорошим тоном будет избавиться вообще от всех проблем: это поможет сайту работать нормально.

Зеленая строка — то, что хочет увидеть разработчик, когда проверяет качество кода. (Скриншот: validator.w3.org)
Как проверять верстку с помощью хинтера
Хинтер — инструмент, который подсвечивает проблемный синтаксис прямо в редакторе кода.
Проверять верстку можно прямо во время разработки сайта. В этом поможет хинтер, который будет подчеркивать проблемные элементы, пока вы пишете код.
Обычно хинтер выглядит как плагин для текстового редактора, в котором вы пишете код. Это как проверка орфографии в Word, только для HTML и CSS.

Проблемный код подсвечивается красным в режиме онлайн. По желанию можно отключить автопроверку и запускать валидацию вручную. (Скриншот: github.com)
Заключение
Перед тем как сдать сайт заказчику или опубликовать в интернете, следует проверить код на валидность. Что нужно запомнить:
- Код бывает валидным и невалидным. Нужен валидный.
- Добиться валидности бывает непросто даже опытному разработчику, потому что кода много. Профессионалы используют валидатор.
- В валидаторе можно проверить сайт, HTML-документ или кусок кода.
- В помощь валидатору можно установить хинтер — подсветку проблемного синтаксиса прямо в вашем текстовом редакторе.
- Сайт с хорошим кодом лучше продвигается в поисковиках и радует пользователей скоростью и функционалом, с какого устройства они бы ни заходили.
Здравствуйте, друзья! Сегодня очень важная тема на повестке дня: как произвести проверку сайта на ошибки, которая подразумевает проверку валидности (соответствия стандартам) html кода, c помощью сервиса W3C validator.

Почему это так важно? Прежде всего, потому, что корректность кода html помогает достигнуть такой важной части оптимизации сайта как кроссбраузерность, то есть тождественному отображению вашего ресурса во всех популярных вэб-обозревателях, что, естественно, помогает его оптимизации и раскрутке. Потому как посетители пользуются различными браузерами, в том числе разными модификациями, и то, что сайт выглядит в них одинаково, придает дополнительных вистов вебмастеру в глазах потенциальных читателей. Кстати, можете выбрать для себя, какой браузер лучше, здесь ознакомившись с соответствующим материалом.
Валидность, то есть соответствие html кода определенным стандартам, задает Международный Консорциум W3C (World Wide Web Consortium). Все интернет-разработчики в большинстве своем обязательно учитывают эти нормы в своих творениях. Согласитесь, без этого в интернет-пространстве, программировании в частности, воцарит хаос и анархия. Кроме контроля HTML кода очень важно осуществить проверку валидности CSS с помощью W3C валидатора.
В заключение добавлю, что незначительных деталей в продвижении ресурса быть не может и даже мелкая, казалось бы, деталь (например, favicon для сайта) способна дать положительный импульс наряду с такой важнейшей частью SEO оптимизации как, например, использование google nofollow и яндекс noindex.
Очень полезный сервис-подсказка всем вебмастерам в деле проверки и поддержания валидности html — это W3C validator. Для начала перейдем на главную страницу W3C:

Как видите, уже есть разделение по регионам и вы можете просмотреть русскоязычный вариант главной страницы, выбрав в выпадающем меню с правом верхнем углу соответствующий регион и нажав кнопку «GO». К сожалению, результаты проверки валидности html пока возможны только на английском языке, поэтому для того чтобы перейти непосредственно к проверке сайта на ошибки, кликайте по ссылке «HTML and markup validator» в правом нижнем углу:

Для проверки валидности html можно поступить тремя способами:
1. Validate by URI — проверка по URL адресу документа
2. Validate by File Upload — проверка валидности html по загружаемому файлу
3. Validate by Direct Input — можно непосредственно вставить html код и осуществить проверку на валидность.
Для того, чтобы проверить правильность html кода страницы сайта или блога на ошибки, выбираем первый вариант. Затем вводим адрес ресурса в соответствующее поле «Address» и нажимаем «Check». Вполне возможно, вам откроется следующая картина, в моем случае было именно так первый раз, когда я затеял проверку своего блога с помощью W3C validator:

Вердикт W3C validator неутешителен: невозможно осуществить проверку сайта на ошибки html кода, поскольку был обнаружен недопустимый символ на строке 298. Что же, будем искать этот символ, благо подсказка есть. Если вы пользуетесь Google Chrome (тут мануал, описывающий этот браузер), то нажимайте правую кнопку мышки и выбирайте «Просмотр кода страницы» из контекстного меню (либо используйте комбинацию клавиш Ctrl+U), в результате чего откроется страница с HTML кодом на соседней вкладке.
В случае других браузеров: если вы пользователь Internet Explorer (тут об Эксплорере статья) выбираете «Просмотр HTML кода», Mozilla Firefox (об этом браузере подробнее) — «Исходный код страницы», Opera (здесь о том, как скачать, установить, настроить и обновить браузер Опера) — «Исходный код».

Смотрим, что здесь не устраивает W3C validator. Как видно из скриншота, эта строчка соответствует одному из комментариев, моему ответу на один из комментариев. Здесь мною был случайно использован символ амперсанда &, это отрывок из ”последних комментариев” на главной странице:

Отредактировав это место, снова проверяем сайт на ошибки, используя повторно W3C validator (для исправления я зашел в раздел «Комментарии» админ панели WordPress и заменил & на букву н):

Как видно из вышеприведенного скриншота, на этот раз валидатор смог осуществить проверку и выдал 8 ошибок и 2 предупреждения. Это на самом деле очень мало и с этим вполне можно жить. Многие вполне приличные, пользующиеся доверием Яндекс и Гугл сайты имеют на порядок больше ошибок по валидности html.
Внимание! W3C validator осуществляет проверку валидности только той страницы, адрес которой вы вводите, а не всего сайта. Если введен адрес главной страницы, то получите данные только по этому документу.
Даже главная страница Yandex, если для примера вы решитесь ее проверить, содержит несколько десятков ошибок. Но это и понятно, очень трудно постоянно следить за корректировкой кода, поскольку документы (читай: страницы сайта) постоянно обновляются. Например, мы на блоге WordPress постоянно используем плагины для тех или иных целей, которые также вносят хаос в html код.
Если вы даже ”подчистите” все косяки, все равно могут появиться новые в силу вышеописанных причин. Важно, чтобы этих ошибок не было слишком много. Если, конечно, вы добьетесь полной их ликвидации, то честь вам и хвала. Конечно, для этого необходимо знать хотя бы основы html, чтобы знать алгоритм исправления ошибок сайта в коде.
В последующих публикациях я постараюсь вновь поднять эту тему и более подробно рассказать на примерах, какие конкретно действия предпринять для их ликвидации; чтобы не пропустить свежую информацию, подписывайтесь на обновления блога по RSS. Еще раз напоминаю, что слишком большое количество ошибок в html коде может помешать правильному отображению сайта в различных браузерах. Кроме того, что-то мне подсказывает, что вскоре поисковые системы могут внести коррективы в порядок ранжирования ресурсов и учитывать валидность html кода. В дополнение привожу разъяснения некоторых настроек на странице проверки валидации W3C validator:

- Show Source — показывает исходный код
- Show Outline — отображает строку,содержащую ошибку
- Validate error pages — осуществляет проверку валидности html страницы с ошибкой, например, error 404 (page not found) — страница 404
- List Messages Sequently — отображает ошибки и предупреждения обычным списком
- Group Error Messages by Type — классифицирует ошибки по определенным признакам
- Clean up Markup with HTML TIdy — выводит правильный код, исправленный программой HTML Tidy. В аннотации указано, что эта программа не входит в состав W3C validator, поэтому они не гарантируют корректность ее работы.
Ну, вот, пожалуй, на сегодня достаточно. Надеюсь, вы уяснили для себя необходимость проверки сайта на ошибки и осуществите проверку валидности html своего сайта с помощью W3C validator.