
Причина:
STOP 0×0000000A показывает, что процесс ядра или драйвер пытались обратиться к памяти, к которой у них нет разрешения обращаться. Самая распространенная причина — это некорректный или повреждённый указатель (pointer), который указывает на неправильный участок в памяти. Указатель (pointer) — это переменная, которая используется программой, для указания на блок в памяти. Если переменная имеет неправильное значение, тогда программа пытается обратиться к памяти, к которой у неё нет прав обращаться. Когда это происходит в программе пользователя, она генерирует нарушение доступа. Когда это происходит в режиме ядра, она генерирует STOP 0×0000000A сообщение.
Решение:
1. Проверьте совместимость вашего оборудования с устанавливаемой системой. Для этого обратитесь к последней версии Списка Совместимости Оборудования (Hardware Compatibility List (HCL).
2. Вовремя установки, когда на экране появиться сообщение о проверке аппаратной конфигурации компьютера (Setup is inspecting your computer`s hardware configuration), нажмите F5. После приглашения, укажите подходящую конфигурацию компьютера и hardware abstraction layer (HAL). Например, для компьютера с одним процессором укажите «Стандартный компьютер» (Standard PC).
3. Отключите следующие функции в CMOS установках вашего компьютера:
— Любое кэшироване, включая кэширование второго уровня процессора (L2), кэш BIOS, внутреннее и внешнее кэширование и кэш записи на контроллерах диска;
— Любую «теневую» память (shadowing);
— Plug and Play;
— Любое антивирусное обеспечение на уровне BIOS.
4. Отсоедините все адаптеры и оборудование, которое не является необходимым для установки Windows, включая:
— сетевой адаптер (network adapter);
— Внутренний модем;
— Звуковую карту;
— Лишние жесткие диски и CD-ROM.
5. Если вы используете SCSI адаптер, воспользуйтесь следующими методами:
— Убедитесь, что вы используете новейшие версии драйверов;
— Отключите синхронную передачу данных (sync negotiation) на SCSI контроллере;
— Отключите всё SCSI устройства, за исключением жёсткого диска, на который осуществляется установка.
6. Если вы используете IDE устройства, то воспользуетесь следующими методами:
— Установите встроенный IDE канал на Первичный (Primary only);
— Убедитесь, что Master/Slave/Only установки верны для IDE устройств на вашем компьютере;
— Отключите всё IDE устройства, за исключением жёсткого диска, на который осуществляется установка.
7. Проверьте модули оперативной памяти (RAM) на компьютере:
— Удалите все несоответствующие чипы О.П., так чтобы все чипы работали на одной скорости (например на 60ns или 70ns наносекундах);
— Протестируйте модули памяти специальными программами и удалите неисправные;
— Замените модули на рабочие.
8. Обратитесь к производителю компьютера или материнской платы для помощи в следующих ситуациях:
При диагностике проблем работы системы обновления Windows довольно часто приходится встречаться с различными кодами ошибок. Как правило, натыкаясь на новую ошибку в логе windowsupdate.log, журнале установки или панели управления приходится идти в Google и собирать по крупицам всю возможную информацию о нужном коде ошибки.
Например, администратор встретился в журнале с ошибкой 0x80070422. Что она означает? Из цифрового кода это абсолютно не понятно. А что если бы вы, получив данную ошибку моментально сконвертировали ее в более человеческий вид ERROR_SERVICE_DISABLED? Т.е. уже четко видно, что проблема связана с одной из отключённых служб Windows, из-за которых клиент не может закачать обновления. И практически сразу приходит на ум проверка статуса службы BITS.
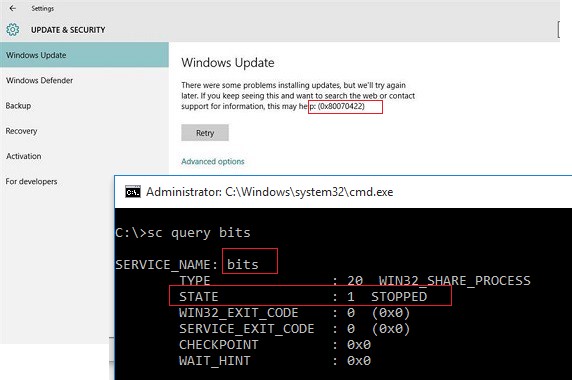 Как вы видите, служба BITS действительно остановлена, из-за чего агент Windows Update не может скачать обновления. Диагностика ошибки обновления довольно сильно упростилась, не так ли?
Как вы видите, служба BITS действительно остановлена, из-за чего агент Windows Update не может скачать обновления. Диагностика ошибки обновления довольно сильно упростилась, не так ли?
В следующей таблице перечислен список всех ошибок обновления Windows, с расшифровкой их кодов и кратким описанием, собранный из Windows SDK. Надеюсь, использование этих данных существенно упростит вам диагностику ошибок Windows Update.
На все сервера установлены последние обновления. Перезагружался много раз. Framework установлен на всех узлах кластера. Вот куски из логов с ошибками:
Добрый день, решил спросить в отдельной теме. Ставлю SQL сервер 2019 в режиме отказоустойчивого кластера. Есть три виртуальные машины у каждой свой системный диск и к каждой приделан один и тот же LUN как диск E:. Как в данном случае выбирать каталоги экземпляра? По задумке хочется что бы базы данных были на E: диске. Где это выбрать при установке ? Это корневой каталог экземпляра ?Последнее редактирование модератором: 12. 2020
Путь MSSQL15. CLUSTERDBMSSQLDATA имеет неправильный формат или не является абсолютным.
Все разобрался сам, надо было добавить диск в кластер
ЗАГОЛОВОК: Сведения о сообщении
Отсутствует учетная запись системного администратора. Чтобы продолжить, укажите как минимум одну учетную запись Windows для подготовки в качестве системного администратора SQL Server.
А какой Ip адрес надо указывать при кластерной установке SQL ?
Группа кластера “SQL Server (MSSQLSERVER)” находится вне сети. Чтобы продолжить, переведите группу в режим “в сети”. ——————————
Группа кластера “SQL Server (MSSQLSERVER)” содержит ресурс “SQL IP Address 1 (CLUSTERDB)” типа “IP Address”, наличие которого не допускается в группе ресурсов SQL Server. Убедитесь, что в группе кластера отсутствуют ресурсы SQL Server из другого экземпляра или ресурсы, имеющие типы общей службы.
Не удалось обновить объект-компьютер, связанный с ресурсом сетевого имени “SQL Network Name (CLUSTERDB)” кластера. Текст для связанного кода ошибки: Unable to protect the Virtual Computer Object (VCO) from accidental deletion
Возможно, у удостоверения кластера “DOR-DB$” нет разрешений, необходимых для обновления объекта. Обратитесь к администратору домена, чтобы убедиться, что удостоверение кластера может обновлять объекты-компьютеры в домене.
Проверка правила “Число узлов кластера, поддерживаемое этим выпуском” окончилось неудачно. Этот выпуск не поддерживает установленное число узлов кластера. Что бы продолжить, удалите узлы, а затем завершите установку в кластере.
Еще раз спасибо, можно закрыть топик.
Столкнулись с проблемой, которую уже с месяц или более не можем решить. Костыли, да и только. Вот и обращаюсь к сообществу впервые, за помощью.
Общая картина следующая – есть 3 офиса, соответственно 3 разные клиентские сети (и 3 разных внешних IP), в каждой от 4 до 20 ПК.
В каждом офисе по одному МФУ – Brother MFC-L2720DWR, сетевой. В третьем еще есть принтер, которые по USB подключен, но это не столь важно сейчас.
Есть терминал – точнее говоря виртуалка, на ней стоит Windows Server 2016 Standart. Долго не обновлялся, но после возникновения ошибки обновляли – не помогло.
Эти три офиса пользуются одним и тем же сервером, разграничений особых нет.
Работали ранее просто по RDP подключению, напрямую к серверу. Сейчас работают по VPN туннелям, но не суть – проблема возникла еще при прямом подключении.
И вот теперь суть – раз в n-ое количество времени, какого-то конкретного промежутка нет, вылезает в журнале приложений следующая ошибка:
“Имя сбойного приложения: svchost. exe_ScDeviceEnum, версия: 10. 14393. 0, метка времени: 0x57899b1c
Имя сбойного модуля: ntdll. dll, версия: 10. 14393. 4530, метка времени: 0x60e33cac
Код исключения: 0xc0000005
Смещение ошибки: 0x00000000000661f3
Идентификатор сбойного процесса: 0x1d4
Время запуска сбойного приложения: 0x01d78a564bdf6139
Путь сбойного приложения: C:WindowsSystem32svchost. exe”
Иногда сбойный модуль не ntdll. dll, а cfgmgr32. dll.
Это журнал приложений. Буквально через 2 секунды в журнале системы сыпятся следующие ошибки:
1)Служба Network Connection Broker была неожиданно завершена. Это произошло 1 раз(а). Следующее корректирующее действие будет предпринято через 5000 мсек: Restart the service.
2)Служба Program Compatibility Assistant Service была неожиданно завершена. Это произошло 1 раз(а). Следующее корректирующее действие будет предпринято через 60000 мсек: Restart the service.
3)Служба Smart Card Device Enumeration Service была неожиданно завершена. Это произошло 1 раз(а). Следующее корректирующее действие будет предпринято через 120000 мсек: Restart the service.
4)Служба Windows Audio Endpoint Builder была неожиданно завершена. Это произошло 1 раз(а). Следующее корректирующее действие будет предпринято через 60000 мсек: Restart the service.
5)Служба Device Association Service была неожиданно завершена. Это произошло 1 раз(а). Следующее корректирующее действие будет предпринято через 60000 мсек: Restart the service.
6)Служба Data Sharing Service была неожиданно завершена. Это произошло 1 раз(а). Следующее корректирующее действие будет предпринято через 10000 мсек: Restart the service.
8)Служба Перенаправитель портов пользовательского режима служб удаленных рабочих столов была неожиданно завершена. Это произошло 1 раз(а). Следующее корректирующее действие будет предпринято через 60000 мсек: Restart the service.
И дальше еще штук 8-10 служб внезапно останавливаются, связанные с Hyper-V и прочим.
После этого обращаются сотрудники компании, с просьбой восстановить работу принтера. То есть сама служба по себе работает, но из-за сбоя службы, принтеры, проброшенные по RDP-соединению, отваливаются. И на сервере их не видно.
Сами принтеры локально в это время спокойно печатают.
Пока что временно помогает полностью погасить сеанс пользователя и заходить под ним заново, тогда принтер по умолчанию снова пробрасывается на сервер и можно дальше работать.
Сразу напишу, что было опробовано для решения проблемы:
1) Обновление Windows server 2016 и для теста пару клиентских ПК (там установлены в основном Windows 10).
2) chkdsk на терминале
3) sfc scannow на терминале
4) DISM check и restore health на терминале
5) Настроена изоляция драйверов и включение/отключение easy print (пробовали разные варианты)
6) Удалены лишние (не понятно откуда взявшиеся) драйвера на самом сервере
7) Проверено на вирусы Drweb CureIT
Ничего из вышеперечисленного не помогло.
Что-то еще я в мучительных попытках делал, находил на просторах интернета, но уже не вспомню.
К слову, не знаю, поможет или нет это – сейчас настроено автоматическое отключение неактивных пользователей спустя 6 часов. Это для того, чтобы пользователи, забывшие отключится от сервера полноценно, отключились автоматом.
Очень прошу помощи, не можем найти решение!
Знаем про ScrewDrivers, однако хотелось бы найти и решить в корне проблему, а не обходится другими утилитами (к тому же платными).
Заранее благодарю за помощь.

The System Error Codes are very broad. Each one can occur in one of many hundreds of locations in the system. Consequently the descriptions of these codes cannot be very specific. Use of these codes requires some amount of investigation and analysis. You need to note both the programmatic and the run-time context in which these errors occur. Because these codes are defined in WinError. h for anyone to use, sometimes the codes are returned by non-system software. Sometimes the code is returned by a function deep in the stack and far removed from your code that is handling the error.
WINS encountered an error while processing the command.
The local WINS cannot be deleted.
The importation from the file failed.
The backup failed. Was a full backup done before?
The backup failed. Check the directory to which you are backing the database.
The name does not exist in the WINS database.
Replication with a nonconfigured partner is not allowed.
The version of the supplied content information is not supported.
The supplied content information is malformed.
The requested data cannot be found in local or peer caches.
No more data is available or required.
The supplied object has not been initialized.
The supplied object has already been initialized.
A shutdown operation is already in progress.
The supplied object has already been invalidated.
An element already exists and was not replaced.
Can not cancel the requested operation as it has already been completed.
Can not perform the reqested operation because it has already been carried out.
An operation accessed data beyond the bounds of valid data.
The requested version is not supported.
A configuration value is invalid.
The SKU is not licensed.
PeerDist Service is still initializing and will be available shortly.
The DHCP client has obtained an IP address that is already in use on the network. The local interface will be disabled until the DHCP client can obtain a new address.
The GUID passed was not recognized as valid by a WMI data provider.
The instance name passed was not recognized as valid by a WMI data provider.
The data item ID passed was not recognized as valid by a WMI data provider.
The WMI request could not be completed and should be retried.
The WMI data provider could not be located.
The WMI data provider references an instance set that has not been registered.
The WMI data service is not available.
The WMI data provider failed to carry out the request.
The WMI MOF information is not valid.
The WMI registration information is not valid.
This operation is only valid in the context of an app container.
This application can only run in the context of an app container.
This functionality is not supported in the context of an app container.
The length of the SID supplied is not a valid length for app container SIDs.
The media identifier does not represent a valid medium.
The library identifier does not represent a valid library.
The media pool identifier does not represent a valid media pool.
The drive and medium are not compatible or exist in different libraries.
The medium currently exists in an offline library and must be online to perform this operation.
The operation cannot be performed on an offline library.
The library, drive, or media pool is empty.
The library, drive, or media pool must be empty to perform this operation.
No media is currently available in this media pool or library.
A resource required for this operation is disabled.
The media identifier does not represent a valid cleaner.
The drive cannot be cleaned or does not support cleaning.
The object identifier does not represent a valid object.
Unable to read from or write to the database.
The database is full.
The medium is not compatible with the device or media pool.
The resource required for this operation does not exist.
The operation identifier is not valid.
The media is not mounted or ready for use.
The device is not ready for use.
The drive identifier does not represent a valid drive.
Library is full. No slot is available for use.
The transport cannot access the medium.
Unable to load the medium into the drive.
Unable to retrieve the drive status.
Unable to retrieve the slot status.
Unable to retrieve status about the transport.
Cannot use the transport because it is already in use.
Unable to open or close the inject/eject port.
Unable to eject the medium because it is in a drive.
A cleaner slot is already reserved.
A cleaner slot is not reserved.
The cleaner cartridge has performed the maximum number of drive cleanings.
Unexpected on-medium identifier.
The last remaining item in this group or resource cannot be deleted.
The message provided exceeds the maximum size allowed for this parameter.
The volume contains system or paging files.
The media type cannot be removed from this library since at least one drive in the library reports it can support this media type.
This offline media cannot be mounted on this system since no enabled drives are present which can be used.
A cleaner cartridge is present in the tape library.
Cannot use the inject/eject port because it is not empty.
This file is currently not available for use on this computer.
The remote storage service is not operational at this time.
The remote storage service encountered a media error.
The file or directory is not a reparse point.
The reparse point attribute cannot be set because it conflicts with an existing attribute.
The data present in the reparse point buffer is invalid.
The tag present in the reparse point buffer is invalid.
There is a mismatch between the tag specified in the request and the tag present in the reparse point.
Fast Cache data not found.
Fast Cache data expired.
Fast Cache data corrupt.
Fast Cache data has exceeded its max size and cannot be updated.
Fast Cache has been ReArmed and requires a reboot until it can be updated.
Secure Boot detected that rollback of protected data has been attempted.
The value is protected by Secure Boot policy and cannot be modified or deleted.
The Secure Boot policy is invalid.
A new Secure Boot policy did not contain the current publisher on its update list.
The Secure Boot policy is either not signed or is signed by a non-trusted signer.
Secure Boot is not enabled on this machine.
Secure Boot requires that certain files and drivers are not replaced by other files or drivers.
The copy offload read operation is not supported by a filter.
The copy offload write operation is not supported by a filter.
The copy offload read operation is not supported for the file.
The copy offload write operation is not supported for the file.
Single Instance Storage is not available on this volume.
The operation cannot be completed because other resources are dependent on this resource.
The cluster resource dependency cannot be found.
The cluster resource cannot be made dependent on the specified resource because it is already dependent.
The cluster resource is not online.
A cluster node is not available for this operation.
The cluster resource is not available.
The cluster resource could not be found.
The cluster is being shut down.
A cluster node cannot be evicted from the cluster unless the node is down or it is the last node.
The object already exists.
The object is already in the list.
The cluster group is not available for any new requests.
The cluster group could not be found.
The operation could not be completed because the cluster group is not online.
The operation failed because either the specified cluster node is not the owner of the resource, or the node is not a possible owner of the resource.
The operation failed because either the specified cluster node is not the owner of the group, or the node is not a possible owner of the group.
The cluster resource could not be created in the specified resource monitor.
The cluster resource could not be brought online by the resource monitor.
The operation could not be completed because the cluster resource is online.
The cluster resource could not be deleted or brought offline because it is the quorum resource.
The cluster could not make the specified resource a quorum resource because it is not capable of being a quorum resource.
The cluster software is shutting down.
The group or resource is not in the correct state to perform the requested operation.
The properties were stored but not all changes will take effect until the next time the resource is brought online.
The cluster resource could not be deleted since it is a core resource.
The quorum resource failed to come online.
The quorum log could not be created or mounted successfully.
The cluster log is corrupt.
The record could not be written to the cluster log since it exceeds the maximum size.
The cluster log exceeds its maximum size.
No checkpoint record was found in the cluster log.
The minimum required disk space needed for logging is not available.
The cluster node failed to take control of the quorum resource because the resource is owned by another active node.
A cluster network is not available for this operation.
All cluster nodes must be running to perform this operation.
A cluster resource failed.
The cluster node is not valid.
The cluster node already exists.
A node is in the process of joining the cluster.
The cluster node was not found.
The cluster local node information was not found.
The cluster network already exists.
The cluster network was not found.
The cluster network interface already exists.
The cluster network interface was not found.
The cluster request is not valid for this object.
The cluster network provider is not valid.
The cluster node is down.
The cluster node is not reachable.
The cluster node is not a member of the cluster.
A cluster join operation is not in progress.
The cluster network is not valid.
The cluster node is up.
The cluster IP address is already in use.
The cluster node is not paused.
No cluster security context is available.
The cluster network is not configured for internal cluster communication.
The cluster node is already up.
The cluster node is already down.
The cluster network is already online.
The cluster network is already offline.
The cluster node is already a member of the cluster.
The cluster network is the only one configured for internal cluster communication between two or more active cluster nodes. The internal communication capability cannot be removed from the network.
One or more cluster resources depend on the network to provide service to clients. The client access capability cannot be removed from the network.
This operation cannot be performed on the cluster resource as it the quorum resource. You may not bring the quorum resource offline or modify its possible owners list.
The cluster quorum resource is not allowed to have any dependencies.
The cluster node is paused.
The cluster resource cannot be brought online. The owner node cannot run this resource.
The cluster node is not ready to perform the requested operation.
The cluster node is shutting down.
The cluster join operation was aborted.
The cluster join operation failed due to incompatible software versions between the joining node and its sponsor.
This resource cannot be created because the cluster has reached the limit on the number of resources it can monitor.
The system configuration changed during the cluster join or form operation. The join or form operation was aborted.
The specified resource type was not found.
The specified node does not support a resource of this type. This may be due to version inconsistencies or due to the absence of the resource DLL on this node.
The specified resource name is not supported by this resource DLL. This may be due to a bad (or changed) name supplied to the resource DLL.
No authentication package could be registered with the RPC server.
You cannot bring the group online because the owner of the group is not in the preferred list for the group. To change the owner node for the group, move the group.
The join operation failed because the cluster database sequence number has changed or is incompatible with the locker node. This may happen during a join operation if the cluster database was changing during the join.
The resource monitor will not allow the fail operation to be performed while the resource is in its current state. This may happen if the resource is in a pending state.
A non locker code got a request to reserve the lock for making global updates.
The quorum disk could not be located by the cluster service.
The backed up cluster database is possibly corrupt.
A DFS root already exists in this cluster node.
An attempt to modify a resource property failed because it conflicts with another existing property.
An operation was attempted that is incompatible with the current membership state of the node.
The quorum resource does not contain the quorum log.
The membership engine requested shutdown of the cluster service on this node.
The join operation failed because the cluster instance ID of the joining node does not match the cluster instance ID of the sponsor node.
A matching cluster network for the specified IP address could not be found.
The actual data type of the property did not match the expected data type of the property.
The cluster node was evicted from the cluster successfully, but the node was not cleaned up. To determine what cleanup steps failed and how to recover, see the Failover Clustering application event log using Event Viewer.
Two or more parameter values specified for a resource’s properties are in conflict.
This computer cannot be made a member of a cluster.
This computer cannot be made a member of a cluster because it does not have the correct version of Windows installed.
A cluster cannot be created with the specified cluster name because that cluster name is already in use. Specify a different name for the cluster.
The cluster configuration action has already been committed.
The cluster configuration action could not be rolled back.
The drive letter assigned to a system disk on one node conflicted with the drive letter assigned to a disk on another node.
One or more nodes in the cluster are running a version of Windows that does not support this operation.
The name of the corresponding computer account doesn’t match the Network Name for this resource.
No network adapters are available.
The cluster node has been poisoned.
The group is unable to accept the request since it is moving to another node.
The resource type cannot accept the request since is too busy performing another operation.
The call to the cluster resource DLL timed out.
The address is not valid for an IPv6 Address resource. A global IPv6 address is required, and it must match a cluster network. Compatibility addresses are not permitted.
An internal cluster error occurred. A call to an invalid function was attempted.
A parameter value is out of acceptable range.
A network error occurred while sending data to another node in the cluster. The number of bytes transmitted was less than required.
An invalid cluster registry operation was attempted.
An input string of characters is not properly terminated.
An input string of characters is not in a valid format for the data it represents.
An internal cluster error occurred. A cluster database transaction was attempted while a transaction was already in progress.
An internal cluster error occurred. There was an attempt to commit a cluster database transaction while no transaction was in progress.
An internal cluster error occurred. Data was not properly initialized.
An error occurred while reading from a stream of data. An unexpected number of bytes was returned.
An error occurred while writing to a stream of data. The required number of bytes could not be written.
An error occurred while deserializing a stream of cluster data.
One or more property values for this resource are in conflict with one or more property values associated with its dependent resource(s).
A quorum of cluster nodes was not present to form a cluster.
The cluster network is not valid for an IPv6 Address resource, or it does not match the configured address.
The cluster network is not valid for an IPv6 Tunnel resource. Check the configuration of the IP Address resource on which the IPv6 Tunnel resource depends.
Quorum resource cannot reside in the Available Storage group.
The dependencies for this resource are nested too deeply.
The call into the resource DLL raised an unhandled exception.
The RHS process failed to initialize.
The Failover Clustering feature is not installed on this node.
The resources must be online on the same node for this operation.
A new node can not be added since this cluster is already at its maximum number of nodes.
This cluster can not be created since the specified number of nodes exceeds the maximum allowed limit.
An attempt to use the specified cluster name failed because an enabled computer object with the given name already exists in the domain.
This cluster cannot be destroyed. It has non-core application groups which must be deleted before the cluster can be destroyed.
Eviction of this node is invalid at this time. Due to quorum requirements node eviction will result in cluster shutdown. If it is the last node in the cluster, destroy cluster command should be used.
Only one instance of this resource type is allowed in the cluster.
Only one instance of this resource type is allowed per resource group.
The resource failed to come online due to the failure of one or more provider resources.
The resource has indicated that it cannot come online on any node.
The current operation cannot be performed on this group at this time.
The Security Descriptor does not meet the requirements for a cluster.
The cluster watchdog is terminating.
A resource vetoed a move between two nodes because they are incompatible.
The request is invalid either because node weight cannot be changed while the cluster is in disk-only quorum mode, or because changing the node weight would violate the minimum cluster quorum requirements.
The resource vetoed the call.
Resource could not start or run because it could not reserve sufficient system resources.
A resource vetoed a move between two nodes because the destination currently does not have enough resources to complete the operation.
A resource vetoed a move between two nodes because the source currently does not have enough resources to complete the operation.
The requested operation can not be completed because the group is queued for an operation.
The requested operation can not be completed because a resource has locked status.
A node drain is already in progress.
This value was also named ERROR_CLUSTER_NODE_EVACUATION_IN_PROGRESS
Clustered storage is not connected to the node.
The disk is not configured in a way to be used with CSV. CSV disks must have at least one partition that is formatted with NTFS.
The resource must be part of the Available Storage group to complete this action.
CSVFS failed operation as volume is in redirected mode.
CSVFS failed operation as volume is not in redirected mode.
Cluster properties cannot be returned at this time.
The operation cannot be completed because the resource is in maintenance mode.
The operation cannot be completed because of cluster affinity conflicts.
The operation cannot be completed because the resource is a replica virtual machine.
If you have additional suggestions regarding the System Error Codes documentation, given the constraints enumerated at the top of the page, please click the link labeled “Send comments about this topic to Microsoft” below. We appreciate the input.
About the OS-STORE
Best Worldwide wholesale electronics, consumer electronics supplier–OS-STORE (Worldwide Wholesale online). You can buy a cheap discount electronics and PC Accessories, include: cell phone, apple parts accessories, tablet pc, iphone, ipad, camera, flash card, MP3/MP4 player, car electronics, video game accessories etc,of course, we also provide the driver for your download, more details, please pay attention to us.
By OS-STORE.
Устранение неполадок кластеров
В случае возникновения
ошибок при работе с Backup Exec в кластерной среде просмотрите
вопросы и ответы, представленные в этом разделе.
Табл. : Устранение неполадок кластеров –
вопросы и ответы
Вопрос
Ответ
После восстановления кластера и всех общих дисков служба
кластера не запускается. Почему она не запускается и что необходимо
сделать, чтобы запустить ее?
Служба кластера может не запускаться потому, что сигнатура диска
на диске кворума отличается то исходной сигнатуры. Если у вас есть
Microsoft 2000 Resource Kit, запустите программу Dumpcfg. exe или
программу Clusterrecovery из Microsoft 2003 Resource Kit, чтобы
заменить диск. Например, введите:dumpcfg. exe /s 12345678 0Замените 12345678 на сигнатуру диска, а 0 – на номер диска. Сигнатуру диска и номер диска можно найти в журнале событий. Если у вас нет Microsoft 2000 Resource Kit, то для изменения
сигнатуры диска кворума можно воспользоваться параметром
-Fixquorum. Изменение сигнатуры диска
кворума. Для создания резервных копий я использовал перезапуск с
контрольной точки. Во время одного из заданий резервного
копирования произошло переключение кластера Microsoft. Было создано
несколько наборов данных резервного копирования. При попытке
проверки или восстановления с помощью этих наборов данных
резервного копирования, созданных до переключения, выдается
сообщение “Неожиданный конец данных”. С чем связано такое
поведение? Защищены ли мои данные?
Эта ошибка связана с тем, что переключение произошло во время
резервного копирования ресурса, поэтому набор данных резервного
копирования не был полностью записан на носитель. Однако для
объектов, резервные копии которых были частично созданы в первом
наборе данных резервного копирования, были созданы полные резервные
копии во время перезапуска, тем самым была обеспечены целостность
данных. Таким образом, необходимо восстановить и проверить все
объекты на носителе для данного набора данных резервного
копирования. Я объединил первичный сервер SAN со вторичным сервером SAN. После этого служба устройств и носителей на вторичном сервере
выдает ошибку. Почему?
Такое поведение связано с тем, что вторичный сервер стал
активным узлом и попытался подключиться к базе данных Backup Exec
на первичном сервере, который сейчас недоступен. Для исправления
этой ситуации воспользуйтесь программой Backup Exec Utility
(BEUTILITY. EXE) или заново установите вторичный сервер в качестве
первичного сервера. Произошел сбой резервного копирования Advanced Disk Based Backup
в результате переключения виртуального сервера приложений. Как
очистить Veritas Storage Foundation для групп дисков кластера
Windows и связанные с ними тома?
Если при использовании источника моментальных копий Veritas
Storage Foundation for Windows (SFW) для выполнения расширенного
резервного копирования на диск произошел сбой виртуального сервера
приложения, задание восстановления не может быть запущено. Исходная
группа дисков кластера, которой принадлежат поврежденные тома,
перемещена из исходного узла во вторичный узел, восстановление
синхронизации поврежденных томов с исходным томами будет
невозможно. Ниже перечислены шаги для расширенного резервного
копирования на диск:
Поврежденные тома отделяются от исходных томов. Отделенные поврежденные тома помещаются в новую группу дисков
кластера. Новая группа дисков кластера удаляется из физического узла, в
котором работает виртуальный сервер, а затем добавляются на сервер
резервного копирования Symantec Backup Exec. Новая группа дисков кластера будет в результате удалена с
сервера резервного копирования и возвращена на физический узел, на
котором она находилась прежде, независимо от текущего расположения
виртуального сервера. Новая группа дисков кластера присоединяется к исходной группе
дисков кластера, если она расположена в том же узле. Поврежденные тома синхронизируются с исходными томами. В случае переключения сервера с текущего активного узла на
вторичный узел, новая группа дисков кластера не может повторно
присоединиться к исходной группе дисков кластера. Соединение двух групп дисков кластера вручную и восстановление
синхронизации томов. После выполнения ручного переключения ресурса кластера Veritas
произошло зависание заданий резервного копирования. Почему
невозможно завершить задания резервного копирования?
Во время переключения ресурса кластера Veritas вручную сервер
Veritas Cluster Server не отключает ресурсы MountV, если есть
открытые указатели. Перед выполнением переключения вручную
рекомендуется завершить все задания резервного копирования. В
случае зависания задания восстановления необходимо вручную отменить
это задание перед процедурой очистки вручную.
- Remove From My Forums
-
Вопрос
-
Добрый день.
Пару недель назад установил Windows Server Essentials 2016 на новый сервер Supermicro.
Помимо ОСи стоит MS SQL Server 2016 Standard, в связке с ним — программа для лабораторных данных и (для разработчиков этой программы) удаленный доступ
по TeamViewer, установленному в системе как служба.Почти каждый день сервер выдает ошибку 1001 BugCheck следующего содержания:
«Компьютер был перезагружен после критической ошибки. Код ошибки: 0x000000ef (0xffff8b8eeafb6840, 0x0000000000000000, 0x0000000000000000, 0x0000000000000000). Дамп памяти
сохранен в….»Последний раз не выключался 3 дня, но потом снова появилась эта проблема.
Подскажите, пожалуйста, как с этим можно разобраться?
Обновлено 08.12.2022
![]() Добрый день! Уважаемые читатели и гости, IT блога Pyatilistnik.org. В прошлый раз мы с вами поговорили, про отложенный запуск служб в Windows, сегодня я хочу вам показать еще один не приятный момент в работе терминальных служб удаленного рабочего стола, а именно ошибка подключения «Произошла внутренняя ошибка«, после чего подключение разрывается. Такое я встречал уже в Windows Server 2012 R2 и 2016. Давайте разбираться в чем дело.
Добрый день! Уважаемые читатели и гости, IT блога Pyatilistnik.org. В прошлый раз мы с вами поговорили, про отложенный запуск служб в Windows, сегодня я хочу вам показать еще один не приятный момент в работе терминальных служб удаленного рабочего стола, а именно ошибка подключения «Произошла внутренняя ошибка«, после чего подключение разрывается. Такое я встречал уже в Windows Server 2012 R2 и 2016. Давайте разбираться в чем дело.
Описание проблемы
Есть сервер с операционной системой Windows Server 2012 R2, сотрудник пытается к нему подключиться, через классическую утилиту «Подключение к удаленному рабочему столу», в момент авторизации, выскакивает окно с ошибкой «Произошла внутренняя ошибка».
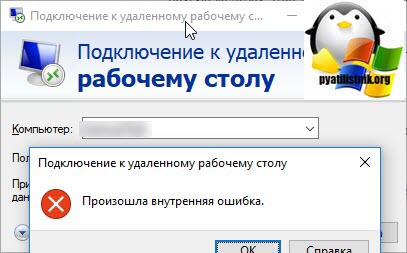
В английском варианте ошибка звучит вот так:
An internal error has occurred
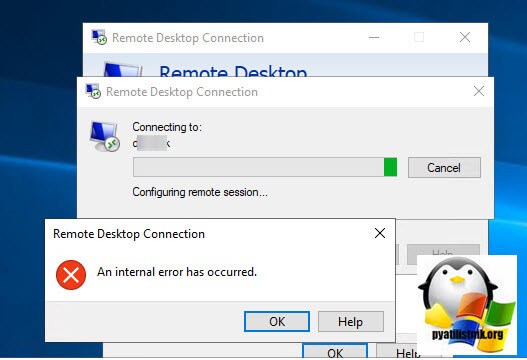
После этого у вас разрывается соединение. Когда мы видели моргающий экран по RDP, там хотя бы вы попадали на сервер и могли открыть диспетчер устройств, тут сразу все обрубается на корню. Давайте смотреть, что можно сделать.
🆘 Что есть в логах?
Если посмотреть журналы событий на удаленном сервере, куда вы пытаетесь подключиться, то там порядок событий будет такой:
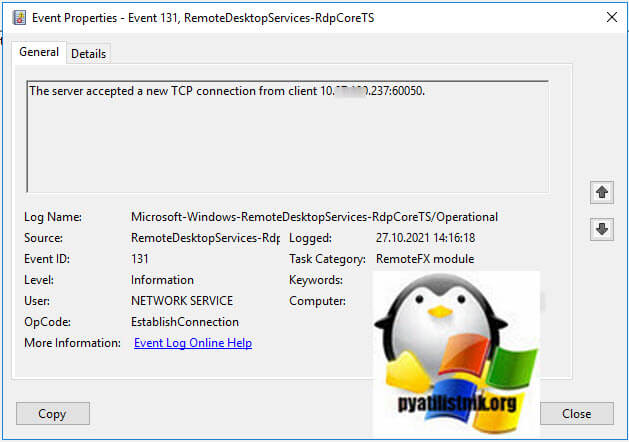
События нужно искать в журнале Microsoft-Windows-RemoteDesktopServices-RdpCoreTS/Operational
- 1️⃣ Первым будет идти событие ID 131 «The server accepted a new TCP connection from client IP-адрес:60050.». Тут вы увидите IP-адрес с которого идет попытка входа.
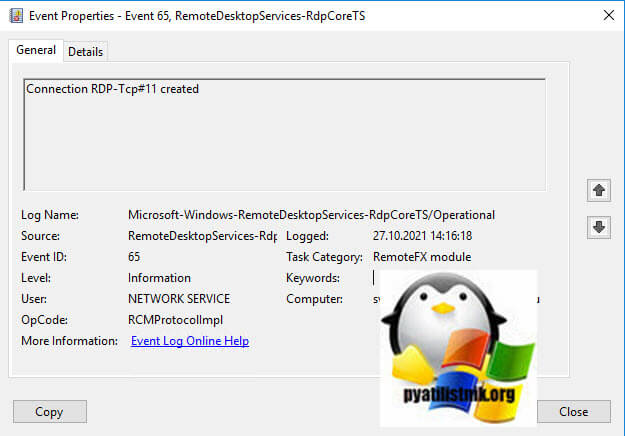
- 2️⃣ Далее событие ID 65 «Connection RDP-Tcp#11 created «.
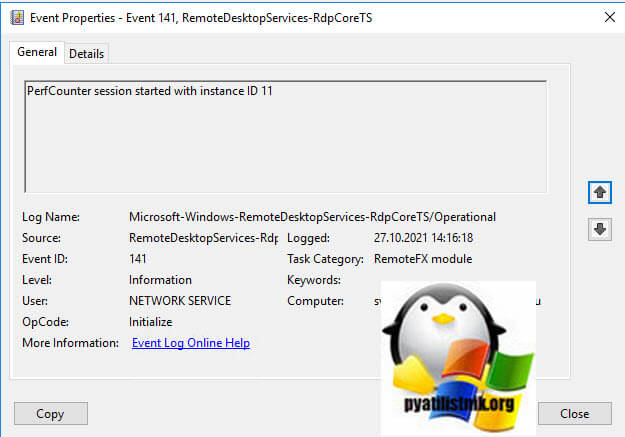
- 3️⃣ Затем событие 141 «PerfCounter session started with instance ID 11». Тут сессии будет назначен ID.
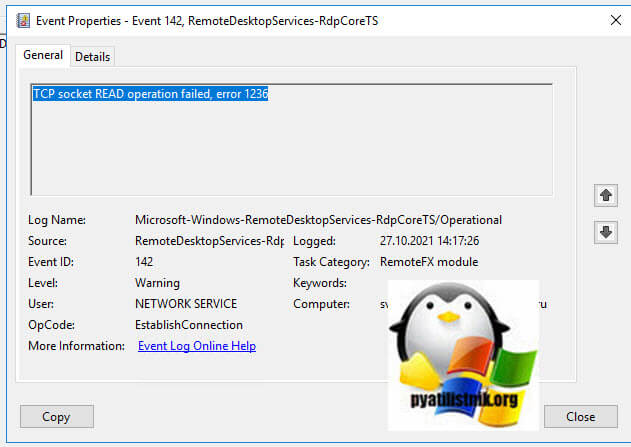
- 4️⃣ За ним будет идти ID 142 «TCP socket READ operation failed, error 1236».
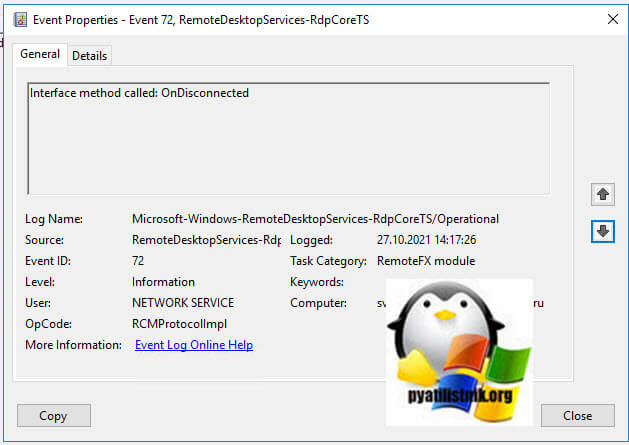
- 5️⃣ Потом вы увидите ID 72 «Interface method called: OnDisconnected»
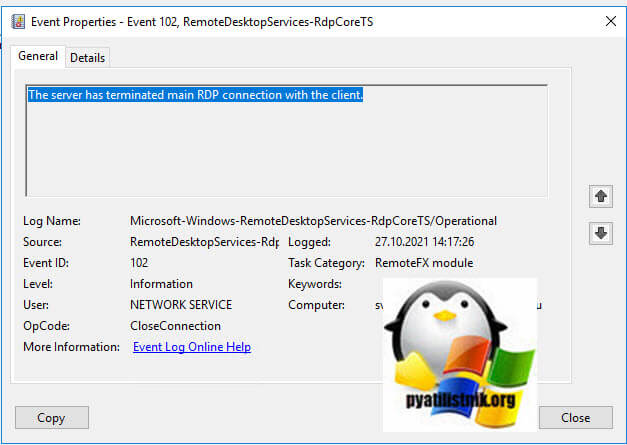
- 6️⃣ И же после этого вам покажут, что сервер разорвал подключение: «ID 102 The server has terminated main RDP connection with the client.»
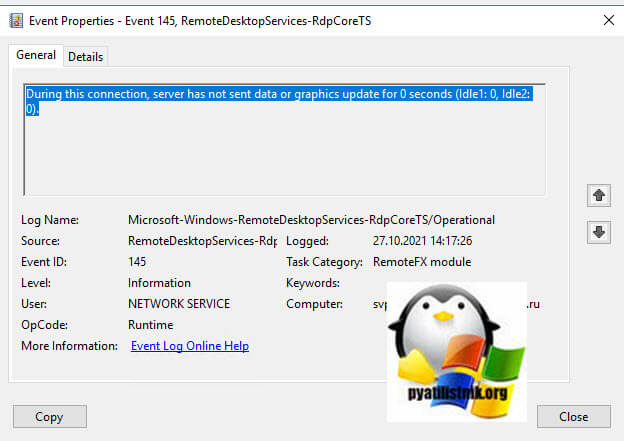
- 7️⃣ В событии ID 145 так же появляются подробности «During this connection, server has not sent data or graphics update for 0 seconds (Idle1: 0, Idle2: 0).».
- 8️⃣ Могут быть события с ID 148 «Channel rdpinpt has been closed between the server and the client on transport tunnel: 0.» или «Channel rdpcmd has been closed between the server and the client on transport tunnel: 0.» или «Channel rdplic has been closed between the server and the client on transport tunnel: 0.»
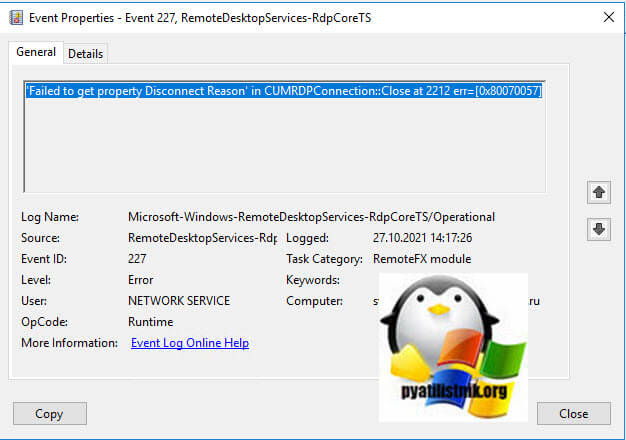
- 9️⃣ Ну и вишенка на торте, ошибка ID 227 «‘Failed to get property Disconnect Reason’ in CUMRDPConnection::Close at 2212 err=[0x80070057]»
Исправляем ошибку «Произошла внутренняя ошибка»
Так как по RDP подключиться не получается, то первым делом нужно проверить отвечает ли порт, по умолчанию это 3389. О том, как проверить порт на удаленном сервере я вам описывал, там все сводилось к выполнению команды Telnet, ознакомьтесь. Если порт отвечает, то делаем следующее.
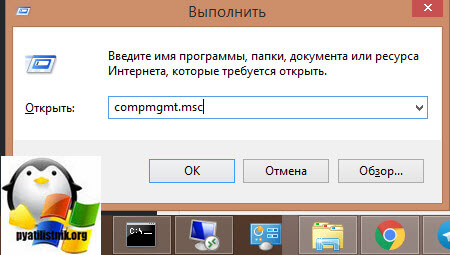
Нужно удаленно перезапустить службу на этом сервере, чтобы сам сервер не перезагружать, так как в этот момент, он может выполнять важные задачи, можно использовать утилиту «Управление компьютером». Открыть ее можно через команду вызова оснастки, вызываем окно «Выполнить», через одновременное нажатие клавиш WIN и R, в котором пишем:
В открывшейся оснастке, щелкните в самом верху по пункту «Управление компьютером» правым кликом мыши, и выберите пункт «Подключиться к удаленному компьютеру».
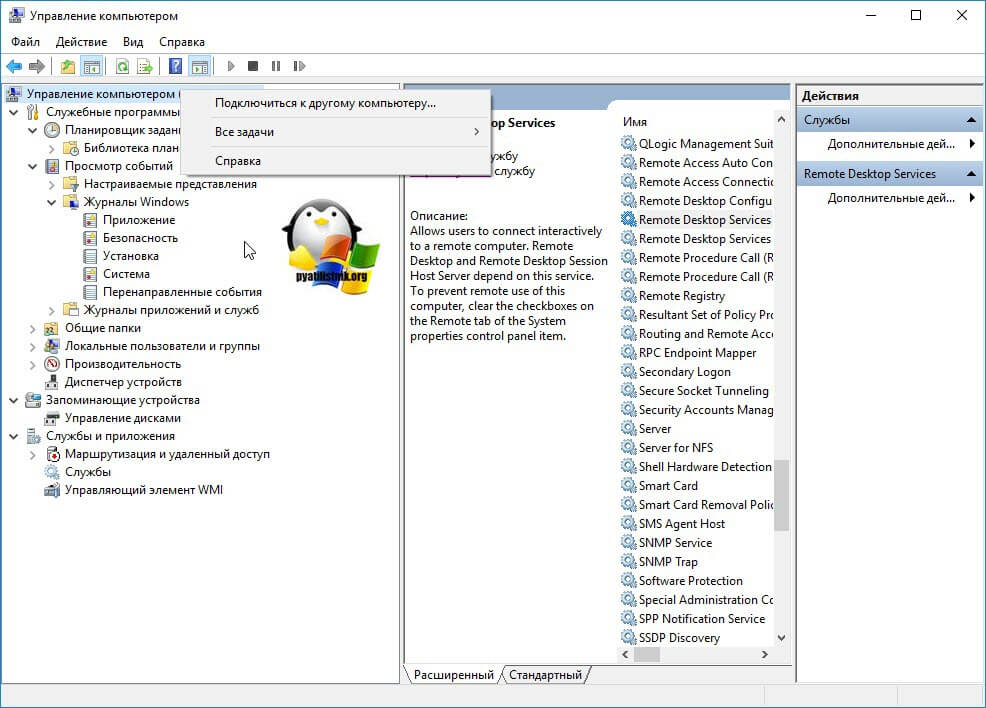
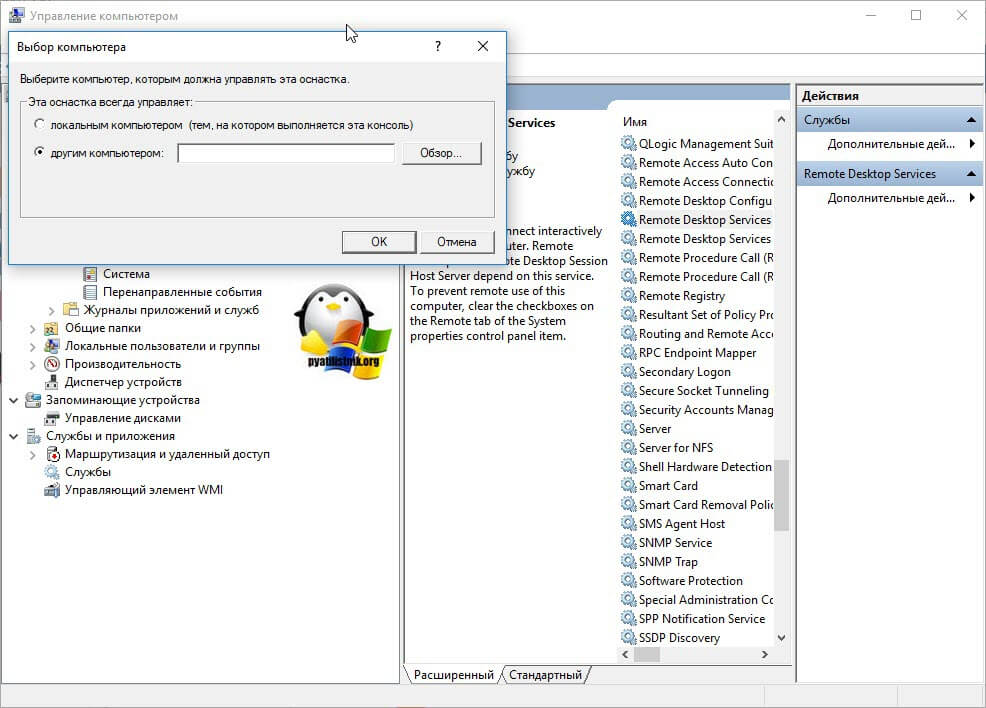
Выберите пункт «Другим компьютером» и укажите его DNS имя, или найдите его через кнопку обзор.
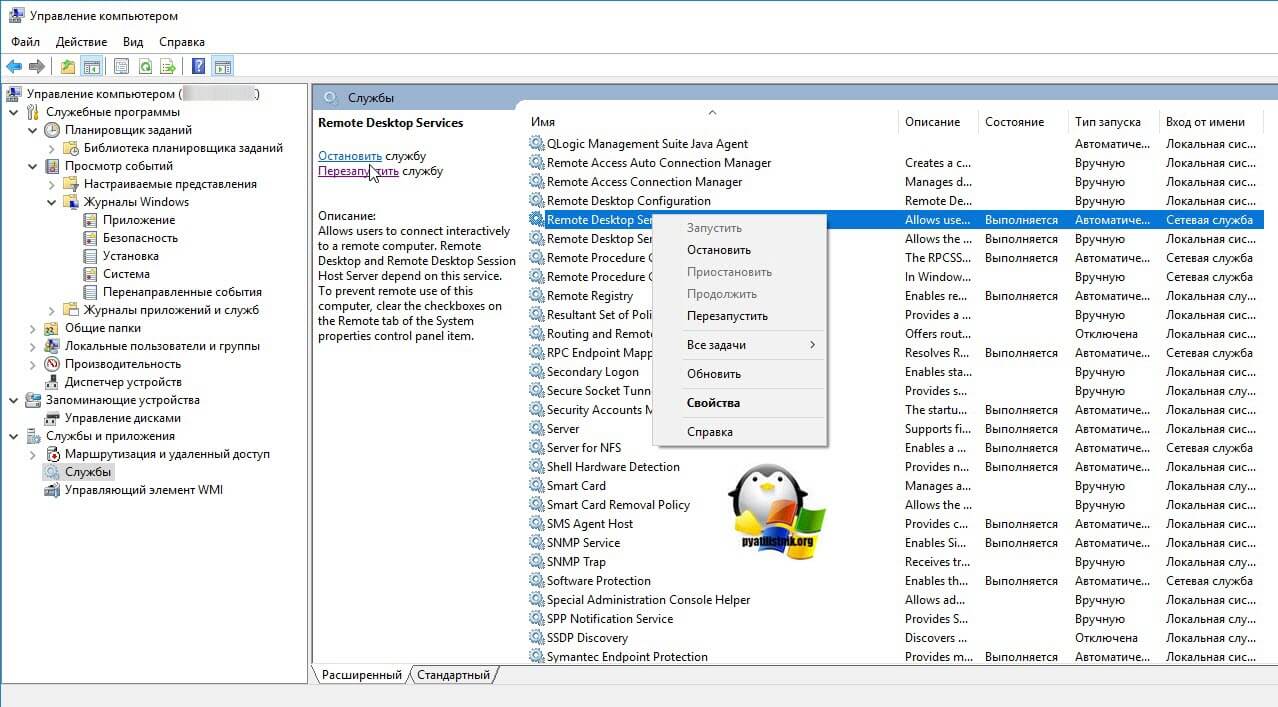
Когда вы подключитесь к нужному серверу, перейдите в пункт «Службы и приложения — Службы», в списке сервисов найдите службу удаленных рабочих столов (Remote Desktop Services), и перезапускаем ее. После этого ошибка подключения по RDP «Произошла внутренняя ошибка», у вас должна пропасть.
Так же вы можете использовать оболочку PowerShell запущенную от имени пользователя, у которого есть права на удаленный сервер, где будет перезапускаться служба RDP. Выполните:
Get-Service TermService -ComputerName Имя сервера | Restart-Service –force –verbose
Дополнительные методы решения
Если вам не помог первый метод, перезапускающий службу удаленных рабочих столов, то можно попробовать выполнить правку реестра. Открываете редактор реестра Windows, если у вас физического доступа к серверу нет или он далеко и вам лень до него идти, то можно попробовать подключиться к реестру удаленного сервера.
Для этого в окне «Редактор реестра» пункт меню «Файл — Подключить сетевой реестр».
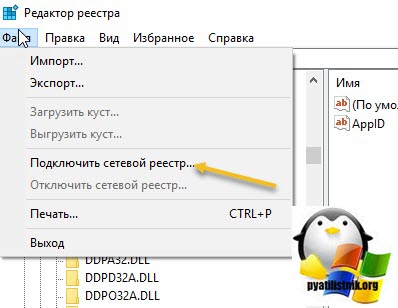
В открывшемся окне «Выбор компьютера» указываем его DNS-имя или ip-адрес и нажимаем ок. У вас будет установлено подключение к удаленному реестру сервера, что испытывает проблемы.
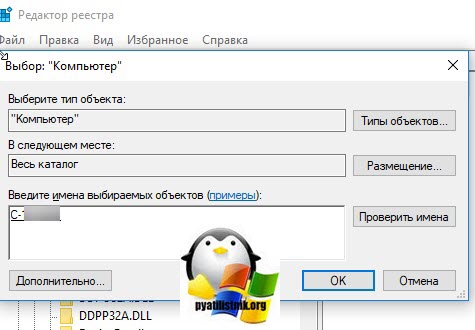
Находим ключ CheckMode по пути
HKEY_LOCAL_MACHINESYSTEMCurrentControlSetControl Session ManagerCProIntegrityCheckMode
Перед любыми правками реестра, обязательно сделайте выгрузку нужной ветки, чтобы можно было восстановить все в оперативном режиме
Выставляем ему значение о, чтобы отключить у программы КриптоПРО CSP проверку контрольных сумм. Еще один важный момент, если у вас старая версия КриптоПРО, то это так же может быть источником, проблем, недавний пример, это ошибка «Windows installer service could not be accessed». Для этого удаляем правильно КриптоПРО CSP и ставим последнюю доступную версию.
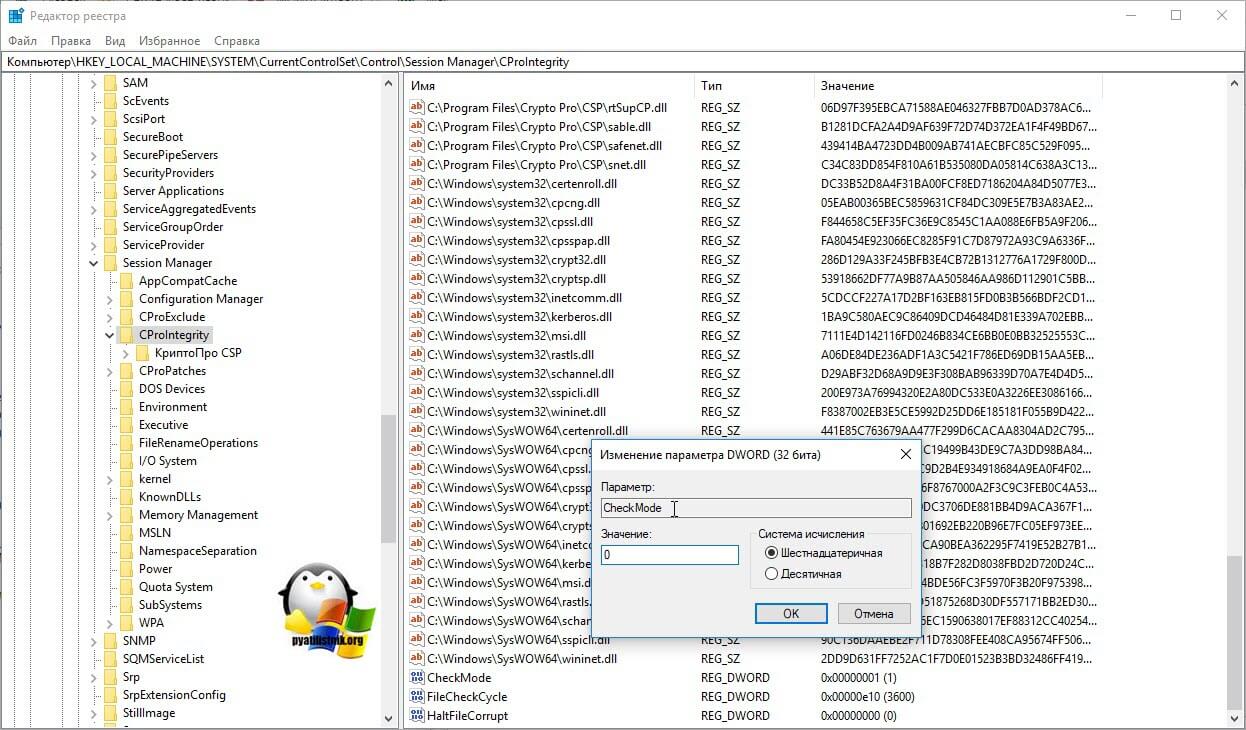
Еще можно попробовать изменить значение вот такого ключа реестра:
HKEY_LOCAL_MACHINESYSTEMCurrentControlSetControl Session ManagerMemory ManagementSessionImageSize
Найдите ключ SessionImageSize и задайте ему значение 0x00000020.
Дополнительные настройки RDP клиента
Например ошибка «An internal error has occurred» у меня встретилась на Windows Server 2022 и там мне помогло в настройках клиента RDP отключение некой опции. Перейдите в дополнительные настройки клиента для удаленного подключения, где н вкладке «Experiens (Взаимодействие)» вам нужно убрать галку с опции «Восстановить подключение при разрыве (Reconnect if the connection is droped)«
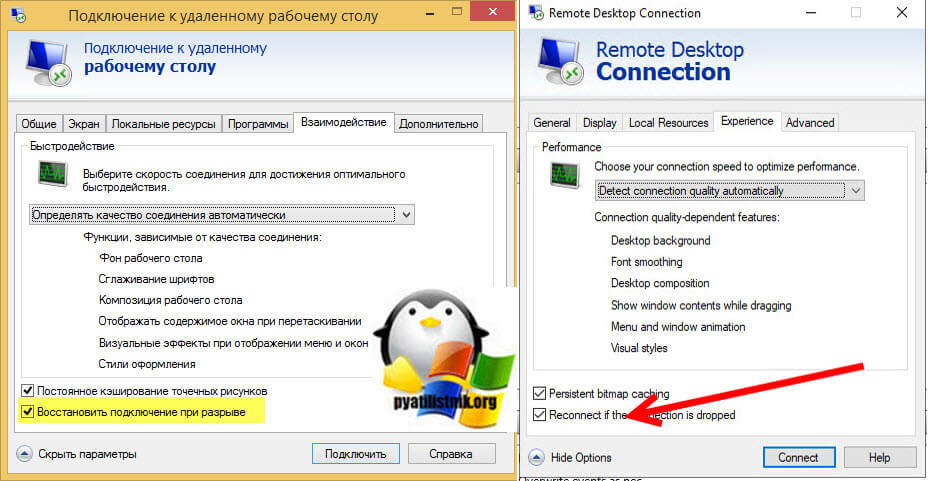
На каких-то сайтах предлагалось именно активировать данный пункт.
Удаление кэша подключений
Еще одним методом решения внутренней ошибки подключения по RDP может выступать поврежденный кэш, который хранится на локальном компьютере пользователя. Для его отображения вам необходимо включить отображение скрытых папок и удалить содержимое папки:
C:Usersимя пользователяAppDataLocalMicrosoftTerminal Server Client
Обновление 07.12.2022
В декабре я вновь столкнулся с внутренней ошибкой, она еще стала проявлять себя вот так:
Не удается подключиться к удаленному компьютеру
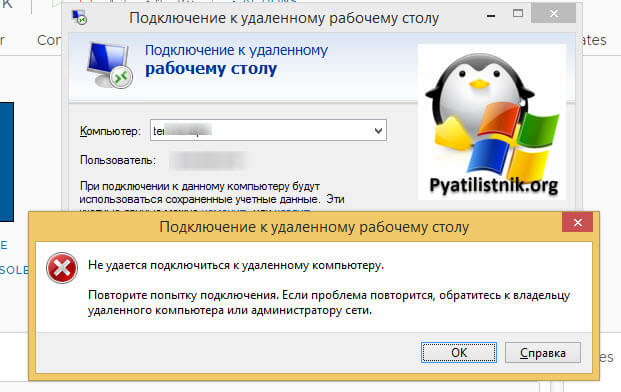
Произошла внутренняя ошибка. Код ошибки: 0x4. Расширенный код ошибки: 0x0
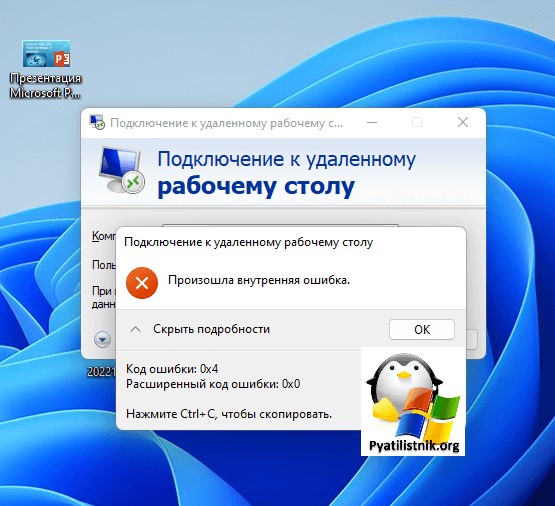
В логах сервера очень много ошибок:
Она возникает, при каждой попытке войти на рабочий стол, это и есть проблема в моем конкретном случае. Устраните ее, и ошибка с подключекнием уйдет. Перезагрузка не нужна.
Данная ошибка говорит, что на тот сертификат, что использует удаленный сервер, нет прав у самого сервера, подробности выше по ссылке
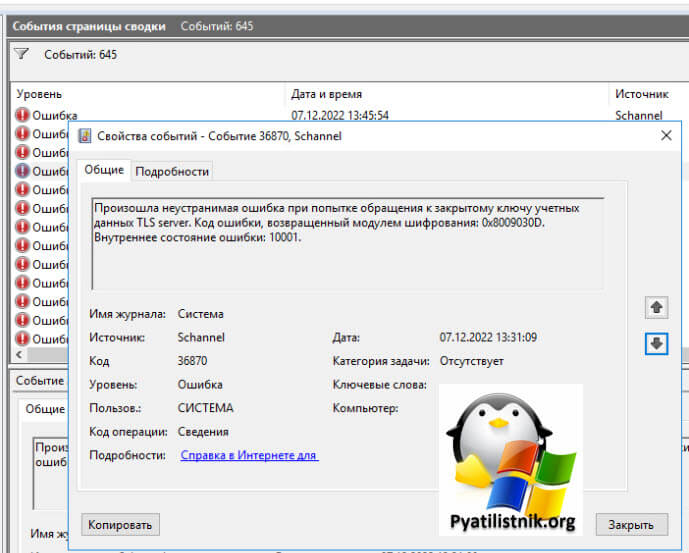
На клиентской машине откуда я пытался произвести подключение было три события:
ID 1024: Выполняется подключение RDP ClientActiveX к серверу (ter104)

ID 1105: Мультитранспортное подключение разорвано.
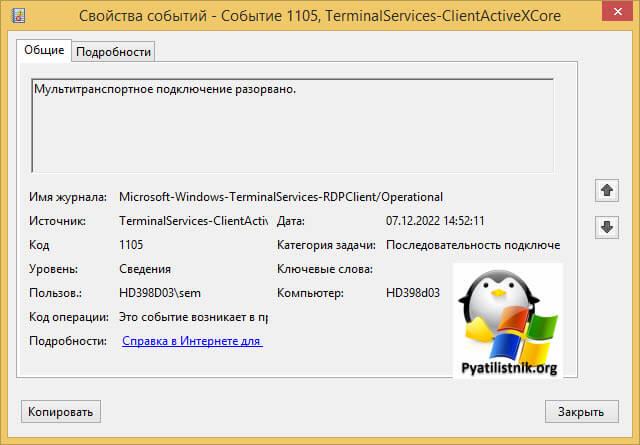
ID 1028: Отключение RDP ClientActiveX (Причина= 2308)
Код 2808 — Ваш сеанс служб удаленных рабочих столов завершен. Соединение с удаленным компьютером было потеряно, возможно, из-за проблем с сетевым подключением. Попробуйте снова подключиться к удаленному компьютеру. Если проблема не исчезнет, обратитесь к сетевому администратору или в службу технической поддержки.
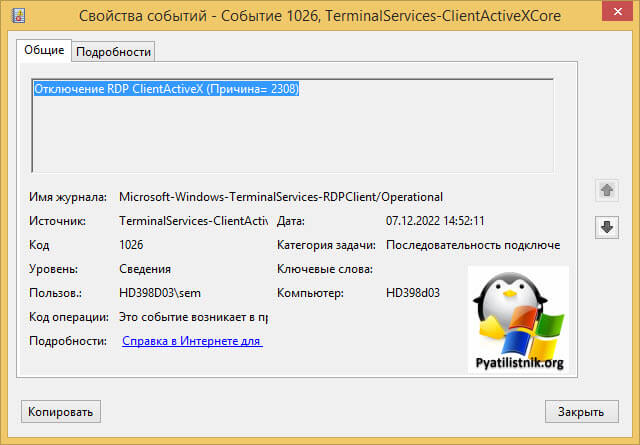
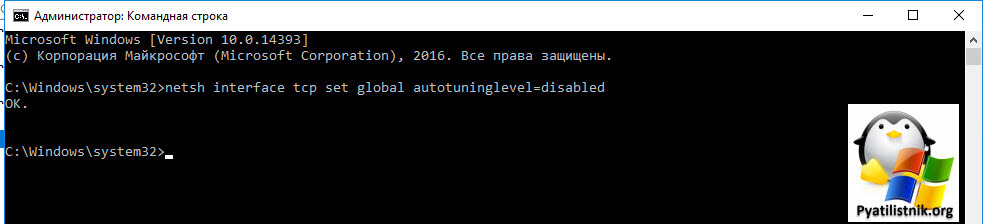
Так как у меня это была виртуальная машина, то я смог легко подключиться через консоль. В случае с ошибкой «Отключение RDP ClientActiveX (Причина= 2308)«, я отключил на сервере и клиенте autotuninglevel:
netsh interface tcp set global autotuninglevel=disabled
Не забываем перезагрузиться.
Это не помогло, далее я выполнил еще несколько рекомендаций. Я установил на сервер валидный SSL сертификат для RDP сессии. В ошибке 0x907, RDP соединение разрывалось, так как клиентская система не доверяла самоподписному сертификату удаленного сервера. Это нужно поправить, ссылку я указал, обязательно проверьте, кто сейчас выступает в роли активного:
Get-WmiObject «Win32_TSGeneralSetting» -Namespace rootcimv2terminalservices -Filter «TerminalName=’RDP-tcp'»
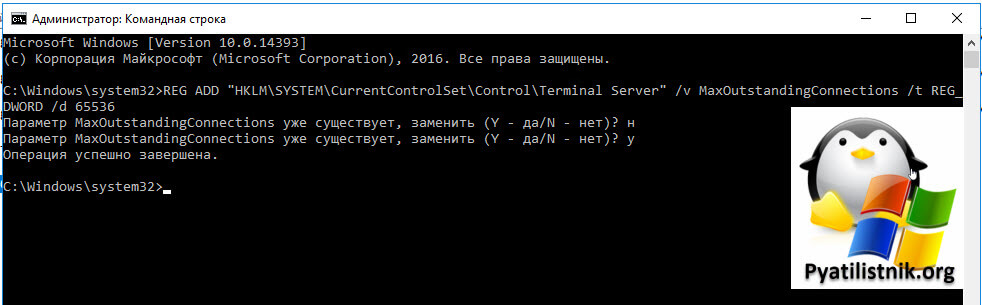
Еще я создал параметр реестра MaxOutstandingConnections. В Windows по умолчанию есть ограничения на количество сетевых подключений, так например в серверной версии, это параметр равен 3000, в десктопной 100. Из-за нестабильной сети, они могут быстро забиваться. Одно из решений проблемы с внутренней ошибкой подключения, является увеличение этого значения. В командной строке в режиме администратора выполните:
REG ADD «HKLMSYSTEMCurrentControlSetControlTerminal Server» /v MaxOutstandingConnections /t REG_DWORD /d 65536
New-ItemProperty -Path «HKLM:SYSTEMCurrentControlSetControlTerminal Server»
-Name MaxOutstandingConnections -Value 10000 -PropertyType DWORD -Force
После этого нужно перезагрузиться.
Временное решение
Пока вы не уберете ошибку «Код ошибки, возвращенный модулем шифрования: ошибка 0x8009030D», описанную выше, вы можете понизить уровень безопасности вот такими манипуляциями, это устранит «An internal error has occurred».
На обычном сервере все это помогло, а вот на ноде RDSH ошибка оставалась. Тут я решил проверить догадку с уровнем безопасности «Configure security settings». На моей ферме был уровень «Согласования (Negotiate)«
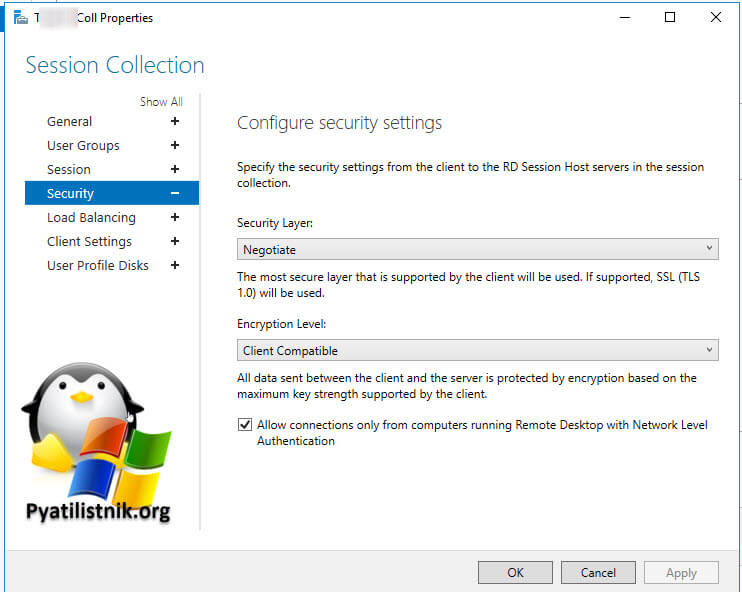
Я пошел на сервер, где были проблемы подключения и решил проверить один параметр локальной политики gpedit.msc.
Конфигурация компьютера — Административные шаблоны- Компоненты Windows — Службы удаленных рабочих столов — Узел сеансов удаленных рабочих столов — Безопасность — Требовать использование специального уровня безопасности для удаленных подключений по протоколу RDP
Тут попробуйте выставить уровень RDP. В результате у меня после этих настроек все заработало. Теперь нужно понять, что изменилось. В настройках RDS фермы указано, что мы используем уровень согласование:
* Согласование: метод согласования принудительно применяет самый безопасный метод, поддерживаемый клиентом. Если поддерживается протокол TLS версии 1.0, то он используется для проверки подлинности сервера узла сеансов удаленных рабочих столов. Если протокол TLS не поддерживается, то для обеспечения безопасности взаимодействий используется собственное шифрование протокола удаленного рабочего стола (RDP), но проверка подлинности сервера узла сеансов удаленных рабочих столов не выполняется. В отличие от SSL-шифрования, использовать собственное шифрование RDP не рекомендуется.
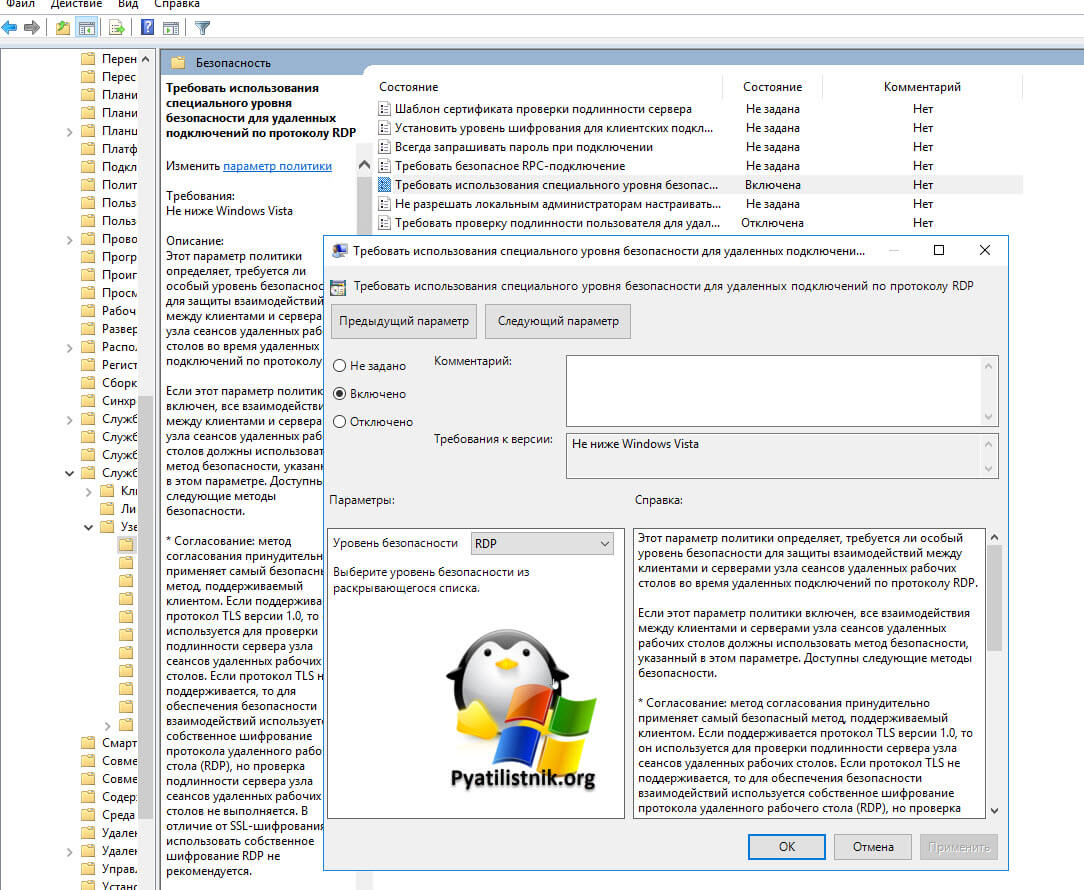
Если и это вам не помогло, то нужно смотреть вариант в сторону обновления или переустановки драйверов на сетевую карту, тут вы определяете модель вашей карты или материнской платы, если в нее все интегрировано и обновляете. С вами был Иван Семин, автор и создатель IT портала Pyatilistnik.org.
Дополнительные ссылки
- https://serverfault.com/questions/934026/windows-10-pro-rdp-server-an-internal-error-has-occurred
- https://social.technet.microsoft.com/Forums/en-US/e1d60cc0-0096-4859-a0e7-eb7f11905737/remote-desktop-v10-error-0x4-from-mac?forum=winRDc
- https://learn.microsoft.com/en-us/answers/questions/108219/can-not-rdp-to-2012-r2-standard-server-after-septe.html
- https://serverfault.com/questions/541364/how-to-fix-rdp-on-windows-server-2012