
Задача 1
Напишите функцию what_weather() (англ. «какая погода?»), которую затем будете использовать в коде Анфисы:
- Выполните HTTP-запрос, поместив вызов функции
get()внутрь блокаtry. - Значения URL и параметров получите из функций
make_url()(в неё нужно передать нужный город как аргументcity) иmake_parameters(). - При «выбрасывании» исключения типа
requests.ConnectionError(от англ. «ошибка соединения») — функцияwhat_weather()должна возвращать сообщение об ошибке'<сетевая ошибка>'. - Если код HTTP-ответа равен 200 (всё хорошо), верните из функции текст ответа. В противном случае функция должна вернуть строку
'<ошибка на сервере погоды>'.
Код:
import requests
cities = [
'Омск',
'Калининград',
'Челябинск',
'Владивосток',
'Красноярск',
'Москва',
'Екатеринбург'
]
def make_url(city):
# в URL задаём город, в котором узнаем погоду
return f'http://wttr.in/{city}'
def make_parameters():
params = {
'format': 2, # погода одной строкой
'M': '' # скорость ветра в "м/с"
}
return params
def what_weather(city):
# Напишите тело этой функции.
# Не изменяйте остальной код!
try:
request = requests.get(make_url(city), params=make_parameters())
#print(request.status_code)
if request.status_code == 200: return request.text
else: return '<ошибка на сервере погоды>'
except requests.ConnectionError : return '<сетевая ошибка>'
print('Погода в городах:')
for city in cities:
print(city, what_weather(city))Результат:
Погода в городах: Омск ? ?️-7°C ?️↖4.2 m/s Калининград ⛅️ ?️+2°C ?️↖6.1 m/s Челябинск ? ?️-3°C ?️↘6.1 m/s Владивосток ☀️ ?️-3°C ?️↓7.2 m/s Красноярск ⛅️ ?️-10°C ?️→8.3 m/s Москва ☀️ ?️-2°C ?️↑4.2 m/s Екатеринбург ? ?️-2°C ?️↘4.2 m/s
Задача 2
Это задание — финальное.
В нём вы сделаете Анфису мастером на все руки.
Анфиса будет знать всё про ваших друзей — где они, сколько у них времени, и какая у них погода.В список запросов queries в функции runner() добавлены новые запросы про погоду:
- Коля, как погода?
- Соня, как погода?
- Антон, как погода?
Научите Анфису отвечать на вопросы такого вида.
Для этого:
- Добавьте в функцию
process_friend()обработку ещё одного запроса'как погода?'. Для получения ответа на этот вопрос используйте значениеcity— это город, в котором живёт друг. - Затем вызовите функцию
what_weather()— вы написали на прошлом уроке почти такую же. Она уже доступна в коде этого задания. - Верните результат выполнения этой функции как результат
process_friend().
Код:
import datetime as dt
import requests
DATABASE = {
'Сергей': 'Омск',
'Соня': 'Москва',
'Алексей': 'Калининград',
'Миша': 'Москва',
'Дима': 'Челябинск',
'Алина': 'Красноярск',
'Егор': 'Пермь',
'Коля': 'Красноярск',
'Артём': 'Владивосток',
'Петя': 'Михайловка'
}
UTC_OFFSET = {
'Москва': 3,
'Санкт-Петербург': 3,
'Новосибирск': 7,
'Екатеринбург': 5,
'Нижний Новгород': 3,
'Казань': 3,
'Челябинск': 5,
'Омск': 6,
'Самара': 4,
'Ростов-на-Дону': 3,
'Уфа': 5,
'Красноярск': 7,
'Воронеж': 3,
'Пермь': 5,
'Волгоград': 4,
'Краснодар': 3,
'Калининград': 2,
'Владивосток': 10
}
def format_count_friends(count_friends):
if count_friends == 1:
return '1 друг'
elif 2 <= count_friends <= 4:
return f'{count_friends} друга'
else:
return f'{count_friends} друзей'
def what_time(city):
offset = UTC_OFFSET[city]
city_time = dt.datetime.utcnow() + dt.timedelta(hours=offset)
f_time = city_time.strftime("%H:%M")
return f_time
def what_weather(city):
url = f'http://wttr.in/{city}'
weather_parameters = {
'format': 2,
'M': ''
}
try:
response = requests.get(url, params=weather_parameters)
except requests.ConnectionError:
return '<сетевая ошибка>'
if response.status_code == 200:
return response.text.strip()
else:
return '<ошибка на сервере погоды>'
def process_anfisa(query):
if query == 'сколько у меня друзей?':
count_string = format_count_friends(len(DATABASE))
return f'У тебя {count_string}'
elif query == 'кто все мои друзья?':
friends_string = ', '.join(DATABASE.keys())
return f'Твои друзья: {friends_string}'
elif query == 'где все мои друзья?':
unique_cities = set(DATABASE.values())
cities_string = ', '.join(unique_cities)
return f'Твои друзья в городах: {cities_string}'
else:
return '<неизвестный запрос>'
def process_friend(name, query):
if name in DATABASE:
city = DATABASE[name]
if query == 'ты где?':
return f'{name} в городе {city}'
elif query == 'который час?':
if city not in UTC_OFFSET:
return f'<не могу определить время в городе {city}>'
time = what_time(city)
return f'Там сейчас {time}'
elif query == 'как погода?':
return what_weather(city)
else:
return '<неизвестный запрос>'
else:
return f'У тебя нет друга по имени {name}'
def process_query(query):
tokens = query.split(', ')
name = tokens[0]
if name == 'Анфиса':
return process_anfisa(tokens[1])
else:
return process_friend(name, tokens[1])
def runner():
queries = [
'Анфиса, сколько у меня друзей?',
'Анфиса, кто все мои друзья?',
'Анфиса, где все мои друзья?',
'Анфиса, кто виноват?',
'Коля, ты где?',
'Соня, что делать?',
'Антон, ты где?',
'Алексей, который час?',
'Артём, который час?',
'Антон, который час?',
'Петя, который час?',
'Коля, как погода?',
'Соня, как погода?',
'Антон, как погода?'
]
for query in queries:
print(query, '-', process_query(query))
runner()Результат:
Анфиса, сколько у меня друзей? - У тебя 10 друзей Анфиса, кто все мои друзья? - Твои друзья: Сергей, Соня, Алексей, Миша, Дима, Алина, Егор, Коля, Артём, Петя Анфиса, где все мои друзья? - Твои друзья в городах: Омск, Калининград, Михайловка, Красноярск, Москва, Челябинск, Владивосток, Пермь Анфиса, кто виноват? - <неизвестный запрос> Коля, ты где? - Коля в городе Красноярск Соня, что делать? - <неизвестный запрос> Антон, ты где? - У тебя нет друга по имени Антон Алексей, который час? - Там сейчас 15:50 Артём, который час? - Там сейчас 23:50 Антон, который час? - У тебя нет друга по имени Антон Петя, который час? - <не могу определить время в городе Михайловка> Коля, как погода? - ⛅️ ?️-10°C ?️→7.2 m/s Соня, как погода? - ☀️ ?️-3°C ?️↑4.2 m/s Антон, как погода? - У тебя нет друга по имени Антон
import requests
cities = [
'Омск',
'Калининград',
'Челябинск',
'Владивосток',
'Красноярск',
'Москва',
'Екатеринбург'
]
def make_url(city):
# в URL задаём город, в котором узнаем погоду
return f'http://wttr.in/{city}'
def make_parameters():
params = {
'format': 2, # погода одной строкой
'M': '' # скорость ветра в "м/с"
}
return params
def what_weather(city):
# Напишите тело этой функции.
# Не изменяйте остальной код!
try:
request = requests.get(make_url(city), params=make_parameters())
if request.status_code == 200: return request.text
else: return '<ошибка на сервере погоды>'
except requests.ConnectionError : return '<сетевая ошибка>'
print('Погода в городах:')
for city in cities:
print(city, what_weather(city))Задача 1
Напишите функцию what_weather() (англ. «какая погода?»), которую затем будете использовать в коде Анфисы:
- Выполните HTTP-запрос, поместив вызов функции
get()внутрь блокаtry. - Значения URL и параметров получите из функций
make_url()(в неё нужно передать нужный город как аргументcity) иmake_parameters(). - При «выбрасывании» исключения типа
requests.ConnectionError(от англ. «ошибка соединения») — функцияwhat_weather()должна возвращать сообщение об ошибке'<сетевая ошибка>'. - Если код HTTP-ответа равен 200 (всё хорошо), верните из функции текст ответа. В противном случае функция должна вернуть строку
'<ошибка на сервере погоды>'.
Код:
import requests
cities = [
'Омск',
'Калининград',
'Челябинск',
'Владивосток',
'Красноярск',
'Москва',
'Екатеринбург'
]
def make_url(city):
# в URL задаём город, в котором узнаем погоду
return f'http://wttr.in/{city}'
def make_parameters():
params = {
'format': 2, # погода одной строкой
'M': '' # скорость ветра в "м/с"
}
return params
def what_weather(city):
# Напишите тело этой функции.
# Не изменяйте остальной код!
try:
request = requests.get(make_url(city), params=make_parameters())
#print(request.status_code)
if request.status_code == 200: return request.text
else: return '<ошибка на сервере погоды>'
except requests.ConnectionError : return '<сетевая ошибка>'
print('Погода в городах:')
for city in cities:
print(city, what_weather(city))Результат:
Погода в городах: Омск ? ?️-7°C ?️↖4.2 m/s Калининград ⛅️ ?️+2°C ?️↖6.1 m/s Челябинск ? ?️-3°C ?️↘6.1 m/s Владивосток ☀️ ?️-3°C ?️↓7.2 m/s Красноярск ⛅️ ?️-10°C ?️→8.3 m/s Москва ☀️ ?️-2°C ?️↑4.2 m/s Екатеринбург ? ?️-2°C ?️↘4.2 m/s
Задача 2
Это задание — финальное.
В нём вы сделаете Анфису мастером на все руки.
Анфиса будет знать всё про ваших друзей — где они, сколько у них времени, и какая у них погода.В список запросов queries в функции runner() добавлены новые запросы про погоду:
- Коля, как погода?
- Соня, как погода?
- Антон, как погода?
Научите Анфису отвечать на вопросы такого вида.
Для этого:
- Добавьте в функцию
process_friend()обработку ещё одного запроса'как погода?'. Для получения ответа на этот вопрос используйте значениеcity— это город, в котором живёт друг. - Затем вызовите функцию
what_weather()— вы написали на прошлом уроке почти такую же. Она уже доступна в коде этого задания. - Верните результат выполнения этой функции как результат
process_friend().
Код:
import datetime as dt
import requests
DATABASE = {
'Сергей': 'Омск',
'Соня': 'Москва',
'Алексей': 'Калининград',
'Миша': 'Москва',
'Дима': 'Челябинск',
'Алина': 'Красноярск',
'Егор': 'Пермь',
'Коля': 'Красноярск',
'Артём': 'Владивосток',
'Петя': 'Михайловка'
}
UTC_OFFSET = {
'Москва': 3,
'Санкт-Петербург': 3,
'Новосибирск': 7,
'Екатеринбург': 5,
'Нижний Новгород': 3,
'Казань': 3,
'Челябинск': 5,
'Омск': 6,
'Самара': 4,
'Ростов-на-Дону': 3,
'Уфа': 5,
'Красноярск': 7,
'Воронеж': 3,
'Пермь': 5,
'Волгоград': 4,
'Краснодар': 3,
'Калининград': 2,
'Владивосток': 10
}
def format_count_friends(count_friends):
if count_friends == 1:
return '1 друг'
elif 2 <= count_friends <= 4:
return f'{count_friends} друга'
else:
return f'{count_friends} друзей'
def what_time(city):
offset = UTC_OFFSET[city]
city_time = dt.datetime.utcnow() + dt.timedelta(hours=offset)
f_time = city_time.strftime("%H:%M")
return f_time
def what_weather(city):
url = f'http://wttr.in/{city}'
weather_parameters = {
'format': 2,
'M': ''
}
try:
response = requests.get(url, params=weather_parameters)
except requests.ConnectionError:
return '<сетевая ошибка>'
if response.status_code == 200:
return response.text.strip()
else:
return '<ошибка на сервере погоды>'
def process_anfisa(query):
if query == 'сколько у меня друзей?':
count_string = format_count_friends(len(DATABASE))
return f'У тебя {count_string}'
elif query == 'кто все мои друзья?':
friends_string = ', '.join(DATABASE.keys())
return f'Твои друзья: {friends_string}'
elif query == 'где все мои друзья?':
unique_cities = set(DATABASE.values())
cities_string = ', '.join(unique_cities)
return f'Твои друзья в городах: {cities_string}'
else:
return '<неизвестный запрос>'
def process_friend(name, query):
if name in DATABASE:
city = DATABASE[name]
if query == 'ты где?':
return f'{name} в городе {city}'
elif query == 'который час?':
if city not in UTC_OFFSET:
return f'<не могу определить время в городе {city}>'
time = what_time(city)
return f'Там сейчас {time}'
elif query == 'как погода?':
return what_weather(city)
else:
return '<неизвестный запрос>'
else:
return f'У тебя нет друга по имени {name}'
def process_query(query):
tokens = query.split(', ')
name = tokens[0]
if name == 'Анфиса':
return process_anfisa(tokens[1])
else:
return process_friend(name, tokens[1])
def runner():
queries = [
'Анфиса, сколько у меня друзей?',
'Анфиса, кто все мои друзья?',
'Анфиса, где все мои друзья?',
'Анфиса, кто виноват?',
'Коля, ты где?',
'Соня, что делать?',
'Антон, ты где?',
'Алексей, который час?',
'Артём, который час?',
'Антон, который час?',
'Петя, который час?',
'Коля, как погода?',
'Соня, как погода?',
'Антон, как погода?'
]
for query in queries:
print(query, '-', process_query(query))
runner()Результат:
Анфиса, сколько у меня друзей? - У тебя 10 друзей Анфиса, кто все мои друзья? - Твои друзья: Сергей, Соня, Алексей, Миша, Дима, Алина, Егор, Коля, Артём, Петя Анфиса, где все мои друзья? - Твои друзья в городах: Омск, Калининград, Михайловка, Красноярск, Москва, Челябинск, Владивосток, Пермь Анфиса, кто виноват? - <неизвестный запрос> Коля, ты где? - Коля в городе Красноярск Соня, что делать? - <неизвестный запрос> Антон, ты где? - У тебя нет друга по имени Антон Алексей, который час? - Там сейчас 15:50 Артём, который час? - Там сейчас 23:50 Антон, который час? - У тебя нет друга по имени Антон Петя, который час? - <не могу определить время в городе Михайловка> Коля, как погода? - ⛅️ ?️-10°C ?️→7.2 m/s Соня, как погода? - ☀️ ?️-3°C ?️↑4.2 m/s Антон, как погода? - У тебя нет друга по имени Антон
Сегодня говорим про обработку ошибок и отказоустойчивость программ. Это продолжение статьи про исключения, но применительно к нашему проекту под кодовым названием «Воруй, убивай, цепи Маркова». Мы учимся забирать текст с чужих сайтов и генерировать на основе этого текста собственные.
В предыдущих версиях у нас были идеальные условия: заготовленный список веб-страниц одинакового формата, с одинаковой кодировкой и одинаковой разметкой заголовков.
В реальном парсинге условия неидеальные: чаще всего нужно парсить не свой сайт, а чужой. И на этом чужом сайте может быть что угодно: не открываются адреса, нет заголовка на странице, разные кодировки на разных страницах. Для компьютера это непреодолимые трудности.
Чтобы такого не происходило, нам нужно научить наш алгоритм обрабатывать нештатные ситуации — то есть исключения.
Что делаем
Идея для сегодняшнего проекта — спарсить часть текста и заголовков с сайта «Коммерсанта» для учебных целей. Потом мы их отдадим нашему алгоритму на цепях Маркова и получим новые тексты в духе «Коммерсанта».
Мы выбрали «Коммерсант» из-за его удобной структуры URL-адреса. Вот как выглядят типичные адреса новостей оттуда:
https://www.kommersant.ru/doc/4815427
https://www.kommersant.ru/doc/4803922
Видно, что каждая новость или статья просто опубликована под каким-то своим номером и есть ощущение, что эти номера идут по порядку. Поэтому сделаем так:
- Выберем стартовый номер у новости.
- Будем отнимать от этого номера единичку, подставлять его в адрес и смотреть на результат.
- Если страница откроется, сохраним заголовок и текст новости, а если нет — пойдём дальше.
- Повторим это 500 раз и посмотрим, что получится.
Адаптируем старый проект под новую задачу
Чтобы не писать всё с нуля, мы возьмём наш парсер из прошлого проекта и выкинем оттуда громадный кусок с массивом URL-адресов.
# подключаем urlopen из модуля urllib
from urllib.request import urlopen
# подключаем библиотеку BeautifulSout
from bs4 import BeautifulSoup
# открываем текстовый файл, куда будем добавлять заголовки
file = open("zag.txt", "a")
# перебираем все адреса из списка
for x in url:
# получаем исходный код очередной страницы из списка
html_code = str(urlopen(x).read(),'utf-8')
# отправляем исходный код страницы на обработку в библиотеку
soup = BeautifulSoup(html_code, "html.parser")
# находим название страницы с помощью метода find()
s = soup.find('title').text
# выводим его на экран
print(s)
# сохраняем заголовок в файле и переносим курсор на новую строку
file.write(s + '. ')
# закрываем файл
file.close()
Теперь добавим в этот код нашу логику. Для этого мы пропишем общую часть URL-адреса, запомним стартовый номер новости, а потом в цикле будем вычитать из него единичку и смотреть, что получилось.
👉 Мы вычитаем единицы из стартового числа, чтобы получить доступ к предыдущим материалам, потому что у новых статей номер в адресе «Коммерсанта» всегда больше, чем у старых. Ещё мы теперь ищем заголовок самой новости, а не всей страницы, потому что в заголовке страницы много лишнего текста.
# подключаем urlopen из модуля urllib
from urllib.request import urlopen
# подключаем библиотеку BeautifulSout
from bs4 import BeautifulSoup
# общая часть URL-адреса
url = "https://www.kommersant.ru/doc/"
# стартовый номер, с которого начинаем парсинг
start_id = 4804129
# открываем файл, куда будем добавлять заголовки
file_zag = open("komm_zag.txt", "a")
# открываем файл, куда будем добавлять текст
file_text = open('komm_text.txt','a')
# перебираем предыдущие 500 адресов
for x in range(0,500):
# формируем новый адрес из общей части и номера материала
# на каждом шаге номер уменьшается на единицу, чтобы обратиться к более старым материалам
work_url = url + str(start_id - x)
# получаем исходный код очередной страницы из списка
html_code = str(urlopen(work_url).read(),'utf-8')
# отправляем исходный код страницы на обработку в библиотеку
soup = BeautifulSoup(html_code, "html.parser")
# находим заголовок материала с помощью метода find()
s = soup.find('h1').text
# выводим его на экран
print(s)
# сохраняем заголовок в файле и переносим курсор на новую строку
file_zag.write(s + '. ')
# находим все абзацы с текстом
content = soup.find_all('p')
# перебираем все найденные абзацы
for item in content:
# сохраняем каждый абзац в другой файл
file_text.write(item.text + ' ')
print(item.text)
# закрываем файл
file.close()После запуска мы видим две проблемы. Первая: у нас собирается много лишних абзацев с текстом, который не относится к новости. Все эти «Читать далее», «Архив» и «просмотров» нам не нужны:

Вторая проблема: оказывается, не на всех страницах наш парсер может найти заголовок <h1>. Например, такое случается, если по текущему адресу материал доступен только по подписке или там находится служебная страница:

Находим только текст новости
Чтобы не собирать со страницы все абзацы, а брать только нужный текст, давайте посмотрим на структуру любой подобной страницы в инспекторе:

В коде видно, что содержимое статьи помечается абзацем с классом «b-article__text» , значит, нам нужно забирать со страницы только абзацы с таким классом. Поменяем нашу команду на такое:
content = soup.find_all('p', class_ = "b-article__text")
Теперь мы найдём на странице только те абзацы, у которых будет нужный нам класс, а остальные проигнорируем.
Добавляем исключение для обработки заголовков
👉 В этом проекте мы варварски отнеслись к исключениям и не проверяли тип ошибки, зато быстро получили рабочий код. В следующий раз мы исправимся, а пока будем работать на скорость.
Мы уже рассказывали про то, что такое исключения и как они помогают программистам. Если коротко, то исключения позволяют обработать заранее известную ошибку так, чтобы программа не прекращала работу, а продолжала делать что-то своё.
Мы будем использовать самый простой вариант обработки исключений: когда исключение обрабатывается в общем виде, без уточнения ошибки. Вот как это будет работать:
- Мы добавляем обработчик исключений к команде нахождения заголовка.
- Если всё нашлось нормально и ошибки нет, то обработчик будет сидеть тихо и ничего не делать.
- Если после команды поиска заголовка случилась ошибка, то мы сразу прекращаем дальнейшие команды и переходим к следующему адресу.
Плюсы такого решения — простота и скорость внедрения. Нам не нужно задумываться о том, какая именно ошибка случилась: при любой ошибке мы бросаем этот адрес и переходим к следующему.
Минус у этого способа тоже есть: мы не знаем, что именно произошло, и реагируем на всё одинаково. В простом учебном проекте это можно сделать, а в настоящем коммерческом коде — нет. Там нужно чётко всегда знать, что за ошибка случилась, чтобы проект более гибко и правильно реагировал на происходящее.
# включаем обработчик исключений для команды поиска
try:
# находим название страницы с помощью метода find()
s = soup.find('h1').text
# если случилась любая ошибка
except Exception as e:
print("Заголовок не найден")
# прерываем этот шаг цикла и переходим к следующему
continueОбрабатываем ситуацию, когда страница не найдена
После того как мы исправили два предыдущих замечания и снова запустили программу, компьютер выдал ошибку 404 — страница с таким адресом не найдена:

Это значит, что мы отправили запрос на такую страницу, которой нет на сервере. Так бывает, когда проверяешь адреса простым перебором — часть вариантов окажется нерабочими.
Чтобы эта ошибка не мешала работать программе, снова добавим исключение с обработкой любой ошибки. Как только на этой команде встретили ошибку, то делаем как и раньше — бросаем всё и начинаем цикл с нового адреса.
# включаем обработчик исключений для запроса содержимого страницы
try:
# получаем исходный код страницы в виде байт-строки
html_code = urlopen(work_url).read()
# если случилась любая ошибка
except Exception as e:
print('Страница не найдена')
# прерываем этот шаг цикла и переходим к следующему
continueТак, шаг за шагом, мы отлавливаем все ошибки и получаем код, который сможет обработать хоть 50 000 страниц и не упасть во время работы. В этом и есть смысл исключений — сделать так, чтобы программа продолжала работать, когда что-то пошло не по плану. Главное — предусмотреть возможные нештатные ситуации.
# подключаем urlopen из модуля urllib
from urllib.request import urlopen
# подключаем библиотеку BeautifulSout
from bs4 import BeautifulSoup
# общая часть URL-адреса
url = "https://www.kommersant.ru/doc/"
# стартовый номер, с которого начинаем парсинг
start_id = 4804129
# открываем файл, куда будем добавлять заголовки
file_zag = open("komm_zag.txt", "a")
# открываем файл, куда будем добавлять текст
file_text = open('komm_text.txt','a')
# перебираем предыдущие 500 адресов
for x in range(0,500):
# формируем новый адрес из общей части и номера материала
# на каждом шаге номер уменьшается на единицу, чтобы обратиться к более старым материалам
work_url = url + str(start_id - x)
# включаем обработчик исключений для запроса содержимого страницы
try:
# получаем исходный код страницы в виде байт-строки
html_code = urlopen(work_url).read()
# если случилась любая ошибка
except Exception as e:
print('Страница не найдена')
# прерываем этот шаг цикла и переходим к следующему
continue
# отправляем исходный код страницы на обработку в библиотеку
soup = BeautifulSoup(html_code, "html.parser")
# включаем обработчик исключений для команды поиска
try:
# находим название страницы с помощью метода find()
s = soup.find('h1').text
# если случилась любая ошибка
except Exception as e:
print("Заголовок не найден")
# прерываем этот шаг цикла и переходим к следующему
continue
# выводим его на экран
print(s)
# сохраняем заголовок в файле и переносим курсор на новую строку
file_zag.write(s + '. ')
# находим все абзацы с текстом новости
content = soup.find_all('p', class_ = "b-article__text")
# перебираем все найденные абзацы
for item in content:
# сохраняем каждый абзац в другой файл
file_text.write(item.text + ' ')
print(item.text)
# закрываем файл
file.close()Что дальше
У нас есть 500 заголовков и столько же новостей — можно собрать новости в стиле «Коммерсанта». Если не знаете, как это сделать, — почитайте нашу статью про генератор на цепях Маркова
Здравствуйте все! Прохожу бесплатный курс на Яндекс Практикуме по Питону и застрял на одной задаче. Прошу не пугаться, что ниже такой длинный код, на самом деле тут всё просто, изменения нужны небольшие, только я уже 2 часа не могу понять, почему код не работает )). Просмотрел уже не один раз, ну ведь должен он работать )).
В общем суть в том, что программа должна выдать такой результат:
Анфиса, сколько у меня друзей? — У тебя 7 друзей
Анфиса, кто все мои друзья? — Твои друзья: Сергей, Соня, Миша, Дима, Алина, Егор, Коля
Анфиса, где все мои друзья? — Твои друзья в городах: Омск, Москва, Красноярск, Пермь, Челябинск
Анфиса, кто виноват? — <неизвестный запрос>
Коля, ты где? — Коля в городе Красноярск
Соня, что делать? — <неизвестный запрос>
Антон, ты где? — У тебя нет друга по имени Антон
Уберу в спойлер формулировку задания:
2.
А. Напишите функцию process_friend(name, query), принимающую имя друга name и запрос query.
- Если друга с указанным именем ‘Н’ нет в списке, то функция должна вернуть сообщение об ошибке У тебя нет друга по имени Н.
- Если запрос — «ты где?», то функция должна вернуть сообщения ‘Н в городе Г’, где Г определяется по данным словаря DATABASE.
- Если запрос не «ты где?», а какой-то другой, то функция должна вернуть сообщение об ошибке <неизвестный запрос>.
Б. Допишите функцию process_query(). Если запрос начинается не с «Анфиса», а с другого имени, то вызовите функцию process_friend(name, query), передав в неё имя друга и тело запроса. И верните результат выполнения этой функции.
В. Добавьте в список queries новые запросы вида:
- Коля, ты где?
- Соня, что делать?
- Антон, ты где?
Что-то неправильно написано в функции process_friend или в функции process_query. У меня получается такой результат (последние строки почему-то выводятся все в одну строку):
Анфиса, сколько у меня друзей? — У тебя 7 друзей
Анфиса, кто все мои друзья? — Твои друзья: Сергей, Соня, Миша, Дима, Алина, Егор, Коля
Анфиса, где все мои друзья? — Твои друзья в городах: Омск, Москва, Красноярск, Пермь, Челябинск
Анфиса, кто виноват?Коля, ты где?Соня, что делать?Антон, ты где? — <неизвестный запрос>
А вот код:
Python:
DATABASE = {
'Сергей': 'Омск',
'Соня': 'Москва',
'Миша': 'Москва',
'Дима': 'Челябинск',
'Алина': 'Красноярск',
'Егор': 'Пермь',
'Коля': 'Красноярск'
}
def format_count_friends(count_friends):
if count_friends == 1:
return '1 друг'
elif 2 <= count_friends <= 4:
return f'{count_friends} друга'
else:
return f'{count_friends} друзей'
def process_anfisa(query):
if query == 'сколько у меня друзей?' or query == 'колько у меня друзей?': # был какой-то глюк тренажера и пришлось добавить фразу 'колько у меня друзей?'
count_string = format_count_friends(len(DATABASE))
return f'У тебя {count_string}'
elif query == 'кто все мои друзья?':
friends_string = ', '.join(DATABASE.keys())
return f'Твои друзья: {friends_string}'
elif query == 'где все мои друзья?':
unique_cities = set(DATABASE.values())
cities_string = ', '.join(unique_cities)
return f'Твои друзья в городах: {cities_string}'
else:
return '<неизвестный запрос>'
def process_query(query):
tokens = query.split(', ')
name = tokens[0]
if name == 'Анфиса':
query = query.strip('Анфиса, ')
return process_anfisa(query)
else:
query = query.strip('Коля, ')
return process_friend(name, query)
def process_friend(name, query):
if name in DATABASE:
if query == 'ты где?':
city = DATABASE[name]
return f'{name} в городе {city}'
else:
return '<неизвестный запрос>'
else:
return f'У тебя нет друга по имени {name}'
def runner():
queries = [
'Анфиса, сколько у меня друзей?',
'Анфиса, кто все мои друзья?',
'Анфиса, где все мои друзья?',
'Анфиса, кто виноват?'
'Коля, ты где?'
'Соня, что делать?'
'Антон, ты где?'
]
for query in queries:
print(query + ' - ' + process_query(query))
runner()Или как мы потеряли 120 000 рублей (60 000 каждый) на обучении.
Update 1:
Мы созвонились с Дианой, из команды Практикума.
В звонке нам удалось во всем разобраться и решить вопрос. Хочется поблагодарить всех людей, которые помогли нам в этой проблеме! Ребята, вы — сила 💪
В ближайшее время мы, наконец, получим дипломы. Когда это случится, сообщу в следующем апдейте.
Также нам предложили скидку 50% на два курса или 100% на один. Выбрали второе (для жены). Если в этот раз курс пройдет успешно и Яндекс действительно сделал работу над ошибками, то ждите похвальную статью уже от жены 💕
Вступление. Немного о нас.
В конце прошлого года я со своей девушкой, а ныне женой, приняли решение пройти курсы тестировщика на Яндекс.Практикум. Долго сомневались, стоит ли, хватит ли у нас терпения и не окажется ли всё это тратой денег. Спойлер: оказалось.
Учились мы на одном потоке примерно полгода. По началу было просто — всё как по маслу, и даже нравилось. Курсы с 3 по 6 (6 курс — диплом) уже тяжеловато, так как совмещали работу и учёбу. Работаем мы в одной крупной компании техническими специалистами, и, конечно же, хотим двигаться дальше. Начитавших хваленых отзывов в интернете и по советам коллег двинулись в Практикум на тестировщика.
Формат учёбы
Учёба происходила в формате спринтов с мягким и жестким дедлайном. Нам предоставили доступ в Slack, где распределили в группу с куратором и парой наставников.
Всю учёбу можно поделить на 3 блока:
- Тренажер — он же портал Яндекс.Практикум.
- Slack — с наставниками, вебинарами и флудилкой.
- Ревьюверы — с которыми особо нет взаимодействий (помимо проектов), но они играют ключевую роль.
Тренажер
Практикум пытается уместить большой объем информации в максимально сжатом виде. Причиной служит малое количество времени на обучение. Тебя постоянно подгоняют дедлайном, обосновывая это тем, что на работе так же.
Сам тренажер работает с ошибками. Студенты даже шутили на эту тему, мол, дополнительная проверка на тестировщика. Проблема с тренажером особо ощущается под конец курсов. Идеально написанный код может сработать только после обновления страницы. В некоторых случаях необходимо поставить/убрать символ там, где это не требуется в задании. Тогда всё заработает.
Старые разделы в тренажере могут обновить прямо в процессе обучения. Чаще всего это выходит боком, создавая путаницу. Быстро вернуться к пройденной теме не получится.
Slack
Толку от наставников было весьма мало, так как к вебинару они приходили чаще всего не подготовленными. Как оказалось, по причине наличия другой «основной» работы. На вопросы в группе Slack тебе отвечали в течение дня — и это в лучшем случае, иногда вообще забывали ответить.
Ревьюверы
Основная боль. Бардак и хаос.
Да, можно стерпеть сжатый тренажер с багами, редко отвечающих наставников с не информативными вебинарами. Но тебе нужно закрыть спринт, а для этого отправить работу на проверку ревьюверу. Напрямую общаться с ревьюверами не дают, что вызывает боль и недопонимание. Видимо из-за того, что они и так завалены работами (экономия на сотрудниках от Яндекса).
Время на проверку у ревьювера: ~96 часов, которое почти регулярно нарушается. Ревьюверы разные: один может не заметить ошибку в работе, а другой попросить сделать как-то иначе. В нашем потоке ревьюверы требовали от тебя того, что даже не было в тренажере или вебинаре. Опять обоснования: «А что вы хотели? Так есть и на реальной работе. Заказчик может потребовать выполнить работу другим образом». Мы поняли, это удобная отговорка от не налаженного процесса между разными отделами.
Финальная часть. Диплом.
Тотально выгоревшие. С горем пополам дошли до диплома. Их было два: первый и второй (альтернативный), но об этом чуть позже. Главная наша ошибка — мучить себя в ужасных условиях и не уйти раньше, когда была такая возможность. Этот урок был выучен на отлично.
Никаких индивидуальных созвонов с наставниками, адекватного обсуждения дипломного проекта нет и в помине. Выдали задание — разбирайтесь сами. Исходя из флудилки, даже у студентов-отличников, которые раньше щёлкали спринты как орешки, не было мотивации разбираться во всем этом месиве.
Первую дипломную работу проверяли долго. ОЧЕНЬ. ДОЛГО. Нервы у жены не выдержали, поэтому она написала в паблик потока. Куратор ответил в ЛС. Прикладываю скриншоты переписки (хорошо, что сохранили, ибо аккаунты в Slack уже удалены).
Куратор сливает работу ЧУЖОГО студента. Практически полностью готовый диплом. Спустя пару дней нам приходит ответ, что мы списали работу друг у друга 🤦♂
Скажу честно, первый дипломный проект другу друга и чужого (слитого) студента мы посмотрели, но выполняли всё самостоятельно.
Мы были в стрессе и на нервах. Нам предлагали либо уйти, либо остаться на второй (альтернативный) диплом. Выбрали второе. Ситуация повторилась, но на этот раз чужие работы мы не видели. Чуть ниже скриншот от поддержки, затем идут наши ответы.
Мой ответ был тотально проигнорирован и на просьбу детально предоставить доказательства — игнор.
Альтернативный диплом был выполнен самостоятельно. Это касается меня и моей жены. Мы в глаза не видели работы друг друга.
Увы, потраченное время и нервные клетки уже не вернуть.
TL;DR
Я с женой заплатили за курсы тестировщика в Яндекс.Практикум 120 тысяч рублей (60 каждый). Учёба была на отвратительном уровне, но мы продолжали учиться. Куратор слил работу другого студента. После сдачи дипломного проекта меня и мою жену обвинили в списывании (дважды). На просьбу детально предоставить доказательства и пересмотреть дело — игнор. Нас отчислили без возврата денег.
Предисловие
Недавно для себя открыл сервис Яндекса — Практикум. Мне очень понравилась идея, и я прошёл серию бесплатных уроков курса Python beckend-разработчик. Бесплатный курс называется «Основы Python»
Хоть я и не новичок в Python-е, но курс для меня оказался очень полезным. Он учит не только основам программированию, но и правильному подходу к работе для новичков.
У меня отец хотел научиться. Ему, между прочим, 75 лет. Он попробовал, но у него не получилось. Камнем преткновения оказалось развернуть и пользоваться у себя на компьютере какую-нибудь IDE. Он начал изучать по книжке, а в книжке ничего про это не было.
Ему просто хотелось попрактиковаться программированию, понять вообще что это такое, приобщиться к новому опыту. И самое главное, просто понять, что это за программирование такое. Я разбираться в новом и непонятном редакторе IDE ему не хотелось.
Я как только натолкнулся на этот практикум, сразу вспомнил про отца. Это действительно то, что нужно, чтобы вникнуть в суть программирования без лишних заморочек и просто понять, твоё это или нет.
На данный момент, отец прошёл несколько уроков и втянулся. Посмотрим, чем это всё закончится.
Что я хочу сделать
Курс Яндекса устроен таким образом, что тебя как будто берут стажёром в IT-компанию. Там тебе дают в разработку небольшой проект, и ты постепенно его разрабатываешь начиная с самых азов и довольно глубоко.
Всё это происходит онлайн и соответственно весь этот проект остаётся на серверах Яндекса. А мне хочется получить этот проект, сначала, локально, затем, с ним поэкспериментировать и, наконец, выложить на Github-е.
Установка Python, Django и IDE PyCharm
У меня стоит совершенно новая система UBUNTU MATE 20.04, и все установки и настройки буду описывать именно для неё.
Установка Python
На самом деле в Ubuntu 20.04 уже стоит Python 3.8.2 и его устанавливать не надо. Но в будущем потребуется устанавливать различные модули, а для этого нужен менеджер пакетов pip.
sudo apt-get install python3-pip
Указанная выше команда установит пакетный менеджер и Python теперь полностью готов для работы.
Установка Django
Проект курса Яндекса использует Framework Django, а значит установить его нужно обязательно.
Вообще, насколько мне известно, установить Django можно тремя разными способами: в проект, текущему пользователю и в систему.
При установке локальному пользователю, консольные команды Django не попадают в пути по умолчанию $PATH, и вызывать их приходиться прописывая полный путь: ‘~/.local/bin/django-admin.
Часто вызывать такую команду не очень удобно, поэтому я решил установить Django в систему:
sudo python3 -m pip install django --system
Установка PyCharm
Конечно PyCharm не единственная IDE для разработки на Python, но я к ней уже привык.
Установить бесплатную версию PyCharm можно командой:
sudo snap install pycharm-community --classic
При первом запуске PyCharm можно выбрать светлую или тёмную тему. Я выбираю тёмную тему.
Резюме
Подводя итоги, нам понадобилось всего три команды:
sudo apt-get install python3-pip # Установка # менеджера пакетов Питона sudo python3 -m pip install django --system # Установка Django sudo snap install pycharm-community --classic # Установка # PyCharm
Знакомство с Django
Знакомство с Django на курсе Яндекс начинается уже с подготовленного проекта.

Так обычно и бывает в жизни. Редко когда бывает, что ты устраиваешься на работу и сразу начинаешь новый проект. Ты, как правило, продолжаешь вести какой-то уже начатый другими проект.
Однако, мне нужно, чтобы всё заработало на моём локальном компьютере. А для этого нужно создать проект. Проект будет называться «Anfisa for Friends». Это аналог Алисы Яндекса.
Создание Python-проекта в PyCharm
Сперва наперво, мы создаём пустой проект со следующими установками:

Создание Django-проекта
Теперь заходим в директорию нашего проекта и создаем каркас приложения на Django:
django-admin startproject anfisa4friends
В результате получаем структуру нового проекта:

Структура получилась не совсем такая, как в курсе Яндекса.
Во-первых, нужно было запустить ‘django-admin’ не в папке проекта, а в папке проектов. Я это переделаю.
Запуск Django-проекта
Остальными переделками я займусь позже, а сейчас нужно проверить работает ли Django. Для этого в папке проекта запускаем:
python3 manage.py runserver
Теперь нужно перейти в браузер и набрать в строке адреса: http://127.0.0.1:8000/.
Если всё работает, то в окне браузера должно появиться следующее:

Ура! Ура! Ура-а-а-а! Всё работает!
Резюме
Как выяснилось для работы с Django нет необходимости сначала создавать Python-проект.
Для знакомства с Django мы используем две команды:
django-admin startproject anfisa4friends # создание проекта python3 manage.py runserver # запуск проекта
Проверить работу сайта проекта можно по адресу: http://127.0.0.1:8000/
Все ошибки или предупреждения можно прочитать в терминале.
Следующая команда обновляет базу данных и все предупреждения исчезают.
python3 manage.py migrate # Обновление базы данных проекта
И так, у нас есть каркас Django-проекта, который работает, и что-то там печатает в окне браузера.
Знакомство с Git
Однако, нам хотелось бы, чтобы проект печатал не абы какой текст, а наш текст. К тому же в терминале, при запуске проекта, выскакивает предупреждение, суть которого в том, что проект может работать неправильно, до запуска python3 manage.py migrate.
Чтобы всё это исправить, нужно внести изменения. Самый простой способ это сделать — это удалить лишние файлы, а содержимой оставшихся файлов заменить содержимым файлов из курса Яндекс практикума.
Однако, в этом случае мы не поймём, какие изменения были сделаны и нечему не научимся. Нам необходимо сравнить файлы в нашем проекте с файлами в проекте Яндекса, а ключевые изменения понять и запомнить.
Для контроля всех изменений в проекте, и особенно изменений в файле с одинаковым названием, существует система контроля версий Git.
Установка Git
В моей версии Ubuntu Git не установлен по умолчанию. Установить Git можно следующей командой:
sudo apt install git # Установка утилиты Git
Создание git-репозитория
Для сравнения различных версий, нам нужно сохранить состояние До и состояние После. Все эти состояние проекта будут хранится в git-репозитории. Для его создания нужно в корне проекта запустить команду:
git init # Создания git-репозитория
Для того, чтобы убедиться, что репозиторий создан, и посмотреть его статус, существует специальная команда:
git status
Если репозиторий успешно создан, мы увидим следующий вывод в терминале:

Сообщение «Ещё нет коммитов» говорит о том, что в репозитории ещё ничего не сохранено. А красным выделены файлы и папки, которые могут быть сохранены.
Настройка git-репозитория
Для правильной работы git-репозитория требуются учётные данные. Они задаются следующими командами.
git config --global user.email "deviur@yandex.ru" git config --global user.name "Deviur"
Добавляем файл .gitignore
Если теперь запустить проект, то в проекте автоматически будут созданы две папки.

Эти папки нам не нужно сохранять в проект.
Для того чтобы исключить папки и файлы из проекта используется файл ‘.gitignore’. В этот файл записывается всё, что не нужно включать в проект.
.idea/ anfisa4friends/__pycache__/
Сохранение текущего состояния проекта
Прежде всего нам нужно выбрать какие файлы и папки добавить в репозиторий.
Чтобы добавить все доступные файлы используется следующая команда:
git add . # добавить файлы для сохранения в git-репозиторий
Теперь вывод `git status` показывает все изменения, которые произошли с файлами, которые мы добавили.

Как видно, коммитов ещё нет. Это значит текущее состояние мы ещё не сохранили. Мы только отметили, какие изменения и какие файлы сохранить.
Теперь сохраняем текущее состояние проекта в репозиторий:
git commit -m'Start Django-project'
Ура! Проект сохранён в git-репозитории. Теперь он имеет следующую структуру.

k
Резюме
Для начала работы с Git и сохранения нашего проекта мы использовали следующие команды:
sudo apt install git # установка Git git init # создание git-репозитория git status # проверка состояние git-репозитория # Настройка учётных данных git-репозитория: git config --global user.email "deviur@yandex.ru" git config --global user.name "Deviur" git add . # добавить файлы для сохранения в git-репозиторий git commit -m'Start Django-project' # сохранить проект # в репозиторий
Пишем проект anfisa4friends
Минимальные изменения
Ниже привожу минимум изменений, которые необходимо сделать в файлах нашего проекта, чтобы всё заработало, как требуется на курсе Яндекса.
Ниже красным обозначено, то что нужно удалить, а синим то, что нужно вставить.
- Удаляем все файлы, которых не должно быть в проекте.
- В файле ‘
settings.py‘ удаляем строку:WSGI_APPLICATION = 'anfisa4friends.wsgi.application'
(остальное можно не менять). - В файле ‘
urls.py‘ после строкиfrom django.contrib import admin
вставляемfrom homepage import views as home_views,
а также, ниже изменяем списокurlpatternsна следующий:urlpatterns = [
path('', home_views.index),
] - Создаём папку ‘
homepage‘. - Создаём в этой папке файл ‘views.py’ со следующим кодом:
from django.http import HttpResponse
def index(request):
return HttpResponse('Anfisa for Friends -- Hello, world! -- ¯(°:°)/¯')
Теперь запускаем проект и смотрим. Всё должно работать!
Что я не стал менять
У нас получилось три версии проекта anfisa4friends:
- Версия сохранённая на Яндекс-практикуме.
- Версия созданная Django, которую мы сохранили в git-репозитории.
- И последняя версия, с изменениями, которые мы сделали в предыдущем разделе.
Часть кода я умышленно не стал делать в точности как на курсе Яндекс-практикума. Код созданный Django мне показался более изящным. Посудите сами:
# Код созданный Django BASE_DIR = Path(__file__).resolve().parent.parent # Код с курса Яндекс-практикума BASE_DIR = os.path.dirname( os.path.dirname(os.path.abspath(__file__)) )
Эти два куска кода делают одно и тоже, но используют две разные библиотеки.
На самом деле, проект Яндекс-практикума не использует базы данных, и не совсем понятно, зачем вообще этот кусок кода в проекте. Я не стал ничего удалять, но закомментировал.
Знакомство с Github.com
Структура git-репозитория
Я планирую повторно пройти курс Яндекс-практикума, но уже на локальном компьютере. Поэтому в git-репозитории проекта будет три ветки:
- tasks (задания) — здесь будет код, который дан, как условие в Яндекс-практикуме.
- solutions (решения) — здесь мой код, который я предложил в качестве решения и Яндекс его принял, как правильный.
- master — основная ветка, в которой вы можете экспериментировать или пройти курс самостоятельно.
Создание структуры веток git-репозитория
У меня Яндекс-практикум уже пройден и сохранены только решения, поэтому начну с ветки solutions.
Для создания ветки и переключения на неё используется следующая команда:
git branch solutions # создание ветки solutions git checkout # переключение на ветку solutions
Теперь сохраню в это ветку последовательно решения всех уроков Яндекс-практикума. В первый коммит будет сохранено моё решение на задачу из темы (topic) №9 урока (lesson) №4.
git commit -m'Solution: topic 9 lesson 4'
Ошибка проверки CSRF. Запрос отклонён.
При прохождении темы 11 на уроке 4 «POST-запросы» на Яндекс-практикуме стала выскакивать эта ошибка. В среде Яндекс-практикума всё работает, а на локальном компьютере, когда нажимаешь кнопку «Угостить» вылетает эта ошибка.
Пришлось покопаться в документации. В результате я внёс небольшие изменения в шаблон ‘index.html‘
Строку<form action="/" method="post">,
я заменил на<form action="/" method="post">{% csrf_token %}
Теперь всё заработало!
Выкладываем наш проект на Github
Для того, чтобы выложить проект на GitHub, у вас должен быть зарегистрированный аккаунт на github.com. У меня аккаунт зарегистрирован под именем «deviur«
Затем вы должны в интерфейсе GitHub создать свой проект. В нашем случае проект будет называться «anfisa4friends«
Далее на нашем локальном компьютере, нужно добавить в git-репозиторий адрес удалённого репозитория.
# Добавляем удалённый репозиторий git remote add origin https://github.com/deviur/anfisa4friends.git # Здесь deviur - моё имя пользователя на GitHub. Не забудьте заменить на своё.А anfisa4friends - это название проекта, который был создан на GitHub.
Теперь остаётся только отправить наш проект на GitHub. Для этого используются следующие команды:
# Отправляем на удалённый репозиторий ветку master git push -u origin master # Отправляем на удалённый репозиторий ветку solutions git push origin solutions
Вот и готово! Теперь наш проект на GitHub-е. Теперь его всегда можно восстановить у себя на компьютере с помощью команды:
git clone https://github.com/deviur/anfisa4friends.git
А ознакомиться с проектом можно по адресу: https://github.com/deviur/anfisa4friends
Задавайте вопросы, пишите пожелания и замечания в комментариях.
Нужно написать код по заданию, вроде как всё сделал но выдает ошибку «код работает, но сделал что то лишнее или что то не так»
Задание вот:
Напишите функцию what_weather() (англ. «какая погода?»), которую затем будете использовать в коде Анфисы:
- Выполните HTTP-запрос, поместив вызов функции get() внутрь блока try.
- Значения URL и параметров получите из функций make_url() (в неё нужно передать нужный город как аргумент city) и make_parameters().
- При «выбрасывании» исключения типа requests.ConnectionError (от англ. «ошибка соединения») — функция what_weather() должна возвращать сообщение об ошибке ‘<сетевая ошибка>’.
- Если код HTTP-ответа равен 200 (всё хорошо), верните из функции текст ответа. В противном случае функция должна вернуть строку ‘<ошибка на сервере погоды>’.
Скрин ошибки: https://pastenow.ru/7486809761d967f85c31e2849cc5160c
Сам код вот:
import requests
cities = [
'Омск',
'Калининград',
'Челябинск',
'Владивосток',
'Красноярск',
'Москва',
'Екатеринбург'
]
def make_url(city):
# в URL задаём город, в котором узнаем погоду
return f'http://wttr.in/{city}'
def make_parameters():
params = {
'format': 2, # погода одной строкой
'M': '' # скорость ветра в "м/с"
}
return params
def what_weather(city):
try:
response = requests.get(make_url(city), params=make_parameters())
if response.status_code == 200:
return response
elif response.status_code != 200:
return '<ошибка на сервере погоды>'
except requests.ConnectionError:
return '<сетевая ошибка>'
print('Погода в городах:')
for city in cities:
print(city, what_weather(city))
задан 7 окт 2019 в 14:37
![]()
7
import requests
cities = [
'Омск',
'Калининград',
'Челябинск',
'Владивосток',
'Красноярск',
'Москва',
'Екатеринбург'
]
def make_url(city):
# в URL задаём город, в котором узнаем погоду
return f'http://wttr.in/{city}'
def make_parameters():
params = '0TMq&lang=ru'
return params
def what_weather(city):
try:
r = requests.get(make_url(city), params=make_parameters())
r.encoding = 'utf-8'
if r.status_code == 200:
return r.text
else:
return '<ошибка на сервере погоды>'
except requests.ConnectionError:
return '<сетевая ошибка>'
print('Погода в городах:')
for city in cities:
print(what_weather(city))
Список доступных параметров сервера погоды можно посмотреть здесь: https://wttr.in/:help
![]()
insolor
45.9k16 золотых знаков54 серебряных знака95 бронзовых знаков
ответ дан 8 окт 2019 в 12:48
![]()
anshapanshap
5353 серебряных знака6 бронзовых знаков
Сегодня говорим про обработку ошибок и отказоустойчивость программ. Это продолжение статьи про исключения, но применительно к нашему проекту под кодовым названием «Воруй, убивай, цепи Маркова». Мы учимся забирать текст с чужих сайтов и генерировать на основе этого текста собственные.
В предыдущих версиях у нас были идеальные условия: заготовленный список веб-страниц одинакового формата, с одинаковой кодировкой и одинаковой разметкой заголовков.
В реальном парсинге условия неидеальные: чаще всего нужно парсить не свой сайт, а чужой. И на этом чужом сайте может быть что угодно: не открываются адреса, нет заголовка на странице, разные кодировки на разных страницах. Для компьютера это непреодолимые трудности.
Чтобы такого не происходило, нам нужно научить наш алгоритм обрабатывать нештатные ситуации — то есть исключения.
Что делаем
Идея для сегодняшнего проекта — спарсить часть текста и заголовков с сайта «Коммерсанта» для учебных целей. Потом мы их отдадим нашему алгоритму на цепях Маркова и получим новые тексты в духе «Коммерсанта».
Мы выбрали «Коммерсант» из-за его удобной структуры URL-адреса. Вот как выглядят типичные адреса новостей оттуда:
https://www.kommersant.ru/doc/4815427
https://www.kommersant.ru/doc/4803922
Видно, что каждая новость или статья просто опубликована под каким-то своим номером и есть ощущение, что эти номера идут по порядку. Поэтому сделаем так:
- Выберем стартовый номер у новости.
- Будем отнимать от этого номера единичку, подставлять его в адрес и смотреть на результат.
- Если страница откроется, сохраним заголовок и текст новости, а если нет — пойдём дальше.
- Повторим это 500 раз и посмотрим, что получится.
Адаптируем старый проект под новую задачу
Чтобы не писать всё с нуля, мы возьмём наш парсер из прошлого проекта и выкинем оттуда громадный кусок с массивом URL-адресов.
# подключаем urlopen из модуля urllib
from urllib.request import urlopen
# подключаем библиотеку BeautifulSout
from bs4 import BeautifulSoup
# открываем текстовый файл, куда будем добавлять заголовки
file = open("zag.txt", "a")
# перебираем все адреса из списка
for x in url:
# получаем исходный код очередной страницы из списка
html_code = str(urlopen(x).read(),'utf-8')
# отправляем исходный код страницы на обработку в библиотеку
soup = BeautifulSoup(html_code, "html.parser")
# находим название страницы с помощью метода find()
s = soup.find('title').text
# выводим его на экран
print(s)
# сохраняем заголовок в файле и переносим курсор на новую строку
file.write(s + '. ')
# закрываем файл
file.close()
Теперь добавим в этот код нашу логику. Для этого мы пропишем общую часть URL-адреса, запомним стартовый номер новости, а потом в цикле будем вычитать из него единичку и смотреть, что получилось.
👉 Мы вычитаем единицы из стартового числа, чтобы получить доступ к предыдущим материалам, потому что у новых статей номер в адресе «Коммерсанта» всегда больше, чем у старых. Ещё мы теперь ищем заголовок самой новости, а не всей страницы, потому что в заголовке страницы много лишнего текста.
# подключаем urlopen из модуля urllib
from urllib.request import urlopen
# подключаем библиотеку BeautifulSout
from bs4 import BeautifulSoup
# общая часть URL-адреса
url = "https://www.kommersant.ru/doc/"
# стартовый номер, с которого начинаем парсинг
start_id = 4804129
# открываем файл, куда будем добавлять заголовки
file_zag = open("komm_zag.txt", "a")
# открываем файл, куда будем добавлять текст
file_text = open('komm_text.txt','a')
# перебираем предыдущие 500 адресов
for x in range(0,500):
# формируем новый адрес из общей части и номера материала
# на каждом шаге номер уменьшается на единицу, чтобы обратиться к более старым материалам
work_url = url + str(start_id - x)
# получаем исходный код очередной страницы из списка
html_code = str(urlopen(work_url).read(),'utf-8')
# отправляем исходный код страницы на обработку в библиотеку
soup = BeautifulSoup(html_code, "html.parser")
# находим заголовок материала с помощью метода find()
s = soup.find('h1').text
# выводим его на экран
print(s)
# сохраняем заголовок в файле и переносим курсор на новую строку
file_zag.write(s + '. ')
# находим все абзацы с текстом
content = soup.find_all('p')
# перебираем все найденные абзацы
for item in content:
# сохраняем каждый абзац в другой файл
file_text.write(item.text + ' ')
print(item.text)
# закрываем файл
file.close()После запуска мы видим две проблемы. Первая: у нас собирается много лишних абзацев с текстом, который не относится к новости. Все эти «Читать далее», «Архив» и «просмотров» нам не нужны:
Вторая проблема: оказывается, не на всех страницах наш парсер может найти заголовок <h1>. Например, такое случается, если по текущему адресу материал доступен только по подписке или там находится служебная страница:
Находим только текст новости
Чтобы не собирать со страницы все абзацы, а брать только нужный текст, давайте посмотрим на структуру любой подобной страницы в инспекторе:
В коде видно, что содержимое статьи помечается абзацем с классом «b-article__text» , значит, нам нужно забирать со страницы только абзацы с таким классом. Поменяем нашу команду на такое:
content = soup.find_all('p', class_ = "b-article__text")
Теперь мы найдём на странице только те абзацы, у которых будет нужный нам класс, а остальные проигнорируем.
Добавляем исключение для обработки заголовков
👉 В этом проекте мы варварски отнеслись к исключениям и не проверяли тип ошибки, зато быстро получили рабочий код. В следующий раз мы исправимся, а пока будем работать на скорость.
Мы уже рассказывали про то, что такое исключения и как они помогают программистам. Если коротко, то исключения позволяют обработать заранее известную ошибку так, чтобы программа не прекращала работу, а продолжала делать что-то своё.
Мы будем использовать самый простой вариант обработки исключений: когда исключение обрабатывается в общем виде, без уточнения ошибки. Вот как это будет работать:
- Мы добавляем обработчик исключений к команде нахождения заголовка.
- Если всё нашлось нормально и ошибки нет, то обработчик будет сидеть тихо и ничего не делать.
- Если после команды поиска заголовка случилась ошибка, то мы сразу прекращаем дальнейшие команды и переходим к следующему адресу.
Плюсы такого решения — простота и скорость внедрения. Нам не нужно задумываться о том, какая именно ошибка случилась: при любой ошибке мы бросаем этот адрес и переходим к следующему.
Минус у этого способа тоже есть: мы не знаем, что именно произошло, и реагируем на всё одинаково. В простом учебном проекте это можно сделать, а в настоящем коммерческом коде — нет. Там нужно чётко всегда знать, что за ошибка случилась, чтобы проект более гибко и правильно реагировал на происходящее.
# включаем обработчик исключений для команды поиска
try:
# находим название страницы с помощью метода find()
s = soup.find('h1').text
# если случилась любая ошибка
except Exception as e:
print("Заголовок не найден")
# прерываем этот шаг цикла и переходим к следующему
continueОбрабатываем ситуацию, когда страница не найдена
После того как мы исправили два предыдущих замечания и снова запустили программу, компьютер выдал ошибку 404 — страница с таким адресом не найдена:
Это значит, что мы отправили запрос на такую страницу, которой нет на сервере. Так бывает, когда проверяешь адреса простым перебором — часть вариантов окажется нерабочими.
Чтобы эта ошибка не мешала работать программе, снова добавим исключение с обработкой любой ошибки. Как только на этой команде встретили ошибку, то делаем как и раньше — бросаем всё и начинаем цикл с нового адреса.
# включаем обработчик исключений для запроса содержимого страницы
try:
# получаем исходный код страницы в виде байт-строки
html_code = urlopen(work_url).read()
# если случилась любая ошибка
except Exception as e:
print('Страница не найдена')
# прерываем этот шаг цикла и переходим к следующему
continueТак, шаг за шагом, мы отлавливаем все ошибки и получаем код, который сможет обработать хоть 50 000 страниц и не упасть во время работы. В этом и есть смысл исключений — сделать так, чтобы программа продолжала работать, когда что-то пошло не по плану. Главное — предусмотреть возможные нештатные ситуации.
# подключаем urlopen из модуля urllib
from urllib.request import urlopen
# подключаем библиотеку BeautifulSout
from bs4 import BeautifulSoup
# общая часть URL-адреса
url = "https://www.kommersant.ru/doc/"
# стартовый номер, с которого начинаем парсинг
start_id = 4804129
# открываем файл, куда будем добавлять заголовки
file_zag = open("komm_zag.txt", "a")
# открываем файл, куда будем добавлять текст
file_text = open('komm_text.txt','a')
# перебираем предыдущие 500 адресов
for x in range(0,500):
# формируем новый адрес из общей части и номера материала
# на каждом шаге номер уменьшается на единицу, чтобы обратиться к более старым материалам
work_url = url + str(start_id - x)
# включаем обработчик исключений для запроса содержимого страницы
try:
# получаем исходный код страницы в виде байт-строки
html_code = urlopen(work_url).read()
# если случилась любая ошибка
except Exception as e:
print('Страница не найдена')
# прерываем этот шаг цикла и переходим к следующему
continue
# отправляем исходный код страницы на обработку в библиотеку
soup = BeautifulSoup(html_code, "html.parser")
# включаем обработчик исключений для команды поиска
try:
# находим название страницы с помощью метода find()
s = soup.find('h1').text
# если случилась любая ошибка
except Exception as e:
print("Заголовок не найден")
# прерываем этот шаг цикла и переходим к следующему
continue
# выводим его на экран
print(s)
# сохраняем заголовок в файле и переносим курсор на новую строку
file_zag.write(s + '. ')
# находим все абзацы с текстом новости
content = soup.find_all('p', class_ = "b-article__text")
# перебираем все найденные абзацы
for item in content:
# сохраняем каждый абзац в другой файл
file_text.write(item.text + ' ')
print(item.text)
# закрываем файл
file.close()Что дальше
У нас есть 500 заголовков и столько же новостей — можно собрать новости в стиле «Коммерсанта». Если не знаете, как это сделать, — почитайте нашу статью про генератор на цепях Маркова
При выполнении заданий к главам вы скорее всего нередко сталкивались с возникновением различных ошибок. На этой главе мы изучим подход, который позволяет обрабатывать ошибки после их возникновения.
Напишем программу, которая будет считать обратные значения для целых чисел из заданного диапазона и выводить их в одну строку с разделителем «;». Один из вариантов кода для решения этой задачи выглядит так:
print(";".join(str(1 / x) for x in range(int(input()), int(input()) + 1)))
Программа получилась в одну строчку за счёт использования списочных выражений. Однако при вводе диапазона чисел, включающем в себя 0 (например, от -1 до 1), программа выдаст следующую ошибку:
ZeroDivisionError: division by zero
В программе произошла ошибка «деление на ноль». Такая ошибка, возникающая при выполнении программы и останавливающая её работу, называется исключением.
Попробуем в нашей программе избавиться от возникновения исключения деления на ноль. Пусть при попадании 0 в диапазон чисел, обработка не производится и выводится сообщение «Диапазон чисел содержит 0». Для этого нужно проверить до списочного выражения наличие нуля в диапазоне:
interval = range(int(input()), int(input()) + 1)
if 0 in interval:
print("Диапазон чисел содержит 0.")
else:
print(";".join(str(1 / x) for x in interval))
Теперь для диапазона, включающего в себя 0, например, от -2 до 2, исключения ZeroDivisionError не возникнет. Однако при вводе строки, которую невозможно преобразовать в целое число (например, «a»), будет вызвано другое исключение:
ValueError: invalid literal for int() with base 10: 'a'
Произошло исключение ValueError. Для борьбы с этой ошибкой нам придётся проверить, что строка состоит только из цифр. Сделать это нужно до преобразования в число. Тогда наша программа будет выглядеть так:
start = input()
end = input()
# Метод lstrip("-"), удаляющий символы "-" в начале строки, нужен для учёта
# отрицательных чисел, иначе isdigit() вернёт для них False
if not (start.lstrip("-").isdigit() and end.lstrip("-").isdigit()):
print("Необходимо ввести два числа.")
else:
interval = range(int(start), int(end) + 1)
if 0 in interval:
print("Диапазон чисел содержит 0.")
else:
print(";".join(str(1 / x) for x in interval))
Теперь наша программа работает без ошибок и при вводе строк, которые нельзя преобразовать в целое число.
Подход, который был нами применён для предотвращения ошибок, называется «Look Before You Leap» (LBYL), или «посмотри перед прыжком». В программе, реализующей такой подход, проверяются возможные условия возникновения ошибок до исполнения основного кода.
Подход LBYL имеет недостатки. Программу из примера стало сложнее читать из-за вложенного условного оператора. Проверка условия, что строка может быть преобразована в число, выглядит даже сложнее, чем списочное выражение. Вложенный условный оператор не решает поставленную задачу, а только лишь проверяет входные данные на корректность. Легко заметить, что решение основной задачи заняло меньше времени, чем составление условий проверки корректности входных данных.
Существует другой подход для работы с ошибками: «Easier to Ask Forgiveness than Permission» (EAFP) или «проще извиниться, чем спрашивать разрешение». В этом подходе сначала исполняется код, а в случае возникновения ошибок происходит их обработка. Подход EAFP реализован в Python в виде обработки исключений.
Исключения в Python являются классами ошибок. В Python есть много стандартных исключений. Они имеют определённую иерархию за счёт механизма наследования классов. В документации Python версии 3.10.8 приводится следующее дерево иерархии стандартных исключений:
BaseException
+-- SystemExit
+-- KeyboardInterrupt
+-- GeneratorExit
+-- Exception
+-- StopIteration
+-- StopAsyncIteration
+-- ArithmeticError
| +-- FloatingPointError
| +-- OverflowError
| +-- ZeroDivisionError
+-- AssertionError
+-- AttributeError
+-- BufferError
+-- EOFError
+-- ImportError
| +-- ModuleNotFoundError
+-- LookupError
| +-- IndexError
| +-- KeyError
+-- MemoryError
+-- NameError
| +-- UnboundLocalError
+-- OSError
| +-- BlockingIOError
| +-- ChildProcessError
| +-- ConnectionError
| | +-- BrokenPipeError
| | +-- ConnectionAbortedError
| | +-- ConnectionRefusedError
| | +-- ConnectionResetError
| +-- FileExistsError
| +-- FileNotFoundError
| +-- InterruptedError
| +-- IsADirectoryError
| +-- NotADirectoryError
| +-- PermissionError
| +-- ProcessLookupError
| +-- TimeoutError
+-- ReferenceError
+-- RuntimeError
| +-- NotImplementedError
| +-- RecursionError
+-- SyntaxError
| +-- IndentationError
| +-- TabError
+-- SystemError
+-- TypeError
+-- ValueError
| +-- UnicodeError
| +-- UnicodeDecodeError
| +-- UnicodeEncodeError
| +-- UnicodeTranslateError
+-- Warning
+-- DeprecationWarning
+-- PendingDeprecationWarning
+-- RuntimeWarning
+-- SyntaxWarning
+-- UserWarning
+-- FutureWarning
+-- ImportWarning
+-- UnicodeWarning
+-- BytesWarning
+-- EncodingWarning
+-- ResourceWarning
Для обработки исключения в Python используется следующий синтаксис:
try:
<код , который может вызвать исключения при выполнении>
except <классисключения_1>:
<код обработки исключения>
except <классисключения_2>:
<код обработки исключения>
...
else:
<код выполняется, если не вызвано исключение в блоке try>
finally:
<код , который выполняется всегда>
Блок try содержит код, в котором нужно обработать исключения, если они возникнут. При возникновении исключения интерпретатор последовательно проверяет в каком из блоков except обрабатывается это исключение. Исключение обрабатывается в первом блоке except, обрабатывающем класс этого исключения или базовый класс возникшего исключения. Необходимо учитывать иерархию исключений для определения порядка их обработки в блоках except. Начинать обработку исключений следует с более узких классов исключений. Если начать с более широкого класса исключения, например, Exception, то всегда при возникновении исключения будет срабатывать первый блок except. Сравните два следующих примера. В первом порядок обработки исключений указан от производных классов к базовым, а во втором – наоборот.
try:
print(1 / int(input()))
except ZeroDivisionError:
print("Ошибка деления на ноль.")
except ValueError:
print("Невозможно преобразовать строку в число.")
except Exception:
print("Неизвестная ошибка.")
При вводе значений «0» и «a» получим ожидаемый соответствующий возникающим исключениям вывод:
Невозможно преобразовать строку в число.
и
Ошибка деления на ноль.
Второй пример:
try:
print(1 / int(input()))
except Exception:
print("Неизвестная ошибка.")
except ZeroDivisionError:
print("Ошибка деления на ноль.")
except ValueError:
print("Невозможно преобразовать строку в число.")
При вводе значений «0» и «a» получим в обоих случаях неинформативный вывод:
Неизвестная ошибка.
Необязательный блок else выполняет код в случае, если в блоке try не вызвано исключение. Добавим блок else в пример для вывода сообщения об успешном выполнении операции:
try:
print(1 / int(input()))
except ZeroDivisionError:
print("Ошибка деления на ноль.")
except ValueError:
print("Невозможно преобразовать строку в число.")
except Exception:
print("Неизвестная ошибка.")
else:
print("Операция выполнена успешно.")
Теперь при вводе корректного значения, например, «5», вывод программы будет следующим:
2.0 Операция выполнена успешно.
Блок finally выполняется всегда, даже если возникло какое-то исключение, не учтённое в блоках except или код в этих блоках сам вызвал какое-либо исключение. Добавим в нашу программу вывод строки «Программа завершена» в конце программы даже при возникновении исключений:
try:
print(1 / int(input()))
except ZeroDivisionError:
print("Ошибка деления на ноль.")
except ValueError:
print("Невозможно преобразовать строку в число.")
except Exception:
print("Неизвестная ошибка.")
else:
print("Операция выполнена успешно.")
finally:
print("Программа завершена.")
Перепишем код, созданный с применением подхода LBYL, для первого примера из этой главы с использованием обработки исключений:
try:
print(";".join(str(1 / x) for x in range(int(input()), int(input()) + 1)))
except ZeroDivisionError:
print("Диапазон чисел содержит 0.")
except ValueError:
print("Необходимо ввести два числа.")
Теперь наша программа читается намного легче. При этом создание кода для обработки исключений не заняло много времени и не потребовало проверки сложных условий.
Исключения можно принудительно вызывать с помощью оператора raise. Этот оператор имеет следующий синтаксис:
raise <класс исключения>(параметры)
В качестве параметра можно, например, передать строку с сообщением об ошибке.
В Python можно создавать свои собственные исключения. Синтаксис создания исключения такой же, как и у создания класса. При создании исключения его необходимо наследовать от какого-либо стандартного класса-исключения.
Напишем программу, которая выводит сумму списка целых чисел, и вызывает исключение, если в списке чисел есть хотя бы одно чётное или отрицательное число. Создадим свои классы исключений:
- NumbersError – базовый класс исключения;
- EvenError – исключение, которое вызывается при наличии хотя бы одного чётного числа;
- NegativeError – исключение, которое вызывается при наличии хотя бы одного отрицательного числа.
class NumbersError(Exception):
pass
class EvenError(NumbersError):
pass
class NegativeError(NumbersError):
pass
def no_even(numbers):
if all(x % 2 != 0 for x in numbers):
return True
raise EvenError("В списке не должно быть чётных чисел")
def no_negative(numbers):
if all(x >= 0 for x in numbers):
return True
raise NegativeError("В списке не должно быть отрицательных чисел")
def main():
print("Введите числа в одну строку через пробел:")
try:
numbers = [int(x) for x in input().split()]
if no_negative(numbers) and no_even(numbers):
print(f"Сумма чисел равна: {sum(numbers)}.")
except NumbersError as e: # обращение к исключению как к объекту
print(f"Произошла ошибка: {e}.")
except Exception as e:
print(f"Произошла непредвиденная ошибка: {e}.")
if __name__ == "__main__":
main()
Обратите внимание: в программе основной код выделен в функцию main. А код вне функций содержит только условный оператор и вызов функции main при выполнении условия __name__ == "__main__". Это условие проверяет, запущен ли файл как самостоятельная программа или импортирован как модуль.
Любая программа, написанная на языке программирования Python может быть импортирована как модуль в другую программу. В идеологии Python импортировать модуль – значит полностью его выполнить. Если основной код модуля содержит вызовы функций, ввод или вывод данных без использования указанного условия __name__ == "__main__", то произойдёт полноценный запуск программы. А это не всегда удобно, если из модуля нужна только отдельная функция или какой-либо класс.
При изучении модуля itertools, мы говорили о том, как импортировать модуль в программу. Покажем ещё раз два способа импорта на примере собственного модуля.
Для импорта модуля из файла, например example_module.py, нужно указать его имя, если он находится в той же папке, что и импортирующая его программа:
import example_module
Если требуется отдельный компонент модуля, например функция или класс, то импорт можно осуществить так:
from example_module import some_function, ExampleClass
Обратите внимание: при втором способе импортированные объекты попадают в пространство имён новой программы. Это означает, что они будут объектами новой программы, и в программе не должно быть других объектов с такими же именами.
Задача 1
Напишите функцию what_weather() (англ. «какая погода?»), которую затем будете использовать в коде Анфисы:
- Выполните HTTP-запрос, поместив вызов функции
get()внутрь блокаtry. - Значения URL и параметров получите из функций
make_url()(в неё нужно передать нужный город как аргументcity) иmake_parameters(). - При «выбрасывании» исключения типа
requests.ConnectionError(от англ. «ошибка соединения») — функцияwhat_weather()должна возвращать сообщение об ошибке'<сетевая ошибка>'. - Если код HTTP-ответа равен 200 (всё хорошо), верните из функции текст ответа. В противном случае функция должна вернуть строку
'<ошибка на сервере погоды>'.
Код:
import requests
cities = [
'Омск',
'Калининград',
'Челябинск',
'Владивосток',
'Красноярск',
'Москва',
'Екатеринбург'
]
def make_url(city):
# в URL задаём город, в котором узнаем погоду
return f'http://wttr.in/{city}'
def make_parameters():
params = {
'format': 2, # погода одной строкой
'M': '' # скорость ветра в "м/с"
}
return params
def what_weather(city):
# Напишите тело этой функции.
# Не изменяйте остальной код!
try:
request = requests.get(make_url(city), params=make_parameters())
#print(request.status_code)
if request.status_code == 200: return request.text
else: return '<ошибка на сервере погоды>'
except requests.ConnectionError : return '<сетевая ошибка>'
print('Погода в городах:')
for city in cities:
print(city, what_weather(city))Результат:
Погода в городах: Омск ? ?️-7°C ?️↖4.2 m/s Калининград ⛅️ ?️+2°C ?️↖6.1 m/s Челябинск ? ?️-3°C ?️↘6.1 m/s Владивосток ☀️ ?️-3°C ?️↓7.2 m/s Красноярск ⛅️ ?️-10°C ?️→8.3 m/s Москва ☀️ ?️-2°C ?️↑4.2 m/s Екатеринбург ? ?️-2°C ?️↘4.2 m/s
Задача 2
Это задание — финальное.
В нём вы сделаете Анфису мастером на все руки.
Анфиса будет знать всё про ваших друзей — где они, сколько у них времени, и какая у них погода.В список запросов queries в функции runner() добавлены новые запросы про погоду:
- Коля, как погода?
- Соня, как погода?
- Антон, как погода?
Научите Анфису отвечать на вопросы такого вида.
Для этого:
- Добавьте в функцию
process_friend()обработку ещё одного запроса'как погода?'. Для получения ответа на этот вопрос используйте значениеcity— это город, в котором живёт друг. - Затем вызовите функцию
what_weather()— вы написали на прошлом уроке почти такую же. Она уже доступна в коде этого задания. - Верните результат выполнения этой функции как результат
process_friend().
Код:
import datetime as dt
import requests
DATABASE = {
'Сергей': 'Омск',
'Соня': 'Москва',
'Алексей': 'Калининград',
'Миша': 'Москва',
'Дима': 'Челябинск',
'Алина': 'Красноярск',
'Егор': 'Пермь',
'Коля': 'Красноярск',
'Артём': 'Владивосток',
'Петя': 'Михайловка'
}
UTC_OFFSET = {
'Москва': 3,
'Санкт-Петербург': 3,
'Новосибирск': 7,
'Екатеринбург': 5,
'Нижний Новгород': 3,
'Казань': 3,
'Челябинск': 5,
'Омск': 6,
'Самара': 4,
'Ростов-на-Дону': 3,
'Уфа': 5,
'Красноярск': 7,
'Воронеж': 3,
'Пермь': 5,
'Волгоград': 4,
'Краснодар': 3,
'Калининград': 2,
'Владивосток': 10
}
def format_count_friends(count_friends):
if count_friends == 1:
return '1 друг'
elif 2 <= count_friends <= 4:
return f'{count_friends} друга'
else:
return f'{count_friends} друзей'
def what_time(city):
offset = UTC_OFFSET[city]
city_time = dt.datetime.utcnow() + dt.timedelta(hours=offset)
f_time = city_time.strftime("%H:%M")
return f_time
def what_weather(city):
url = f'http://wttr.in/{city}'
weather_parameters = {
'format': 2,
'M': ''
}
try:
response = requests.get(url, params=weather_parameters)
except requests.ConnectionError:
return '<сетевая ошибка>'
if response.status_code == 200:
return response.text.strip()
else:
return '<ошибка на сервере погоды>'
def process_anfisa(query):
if query == 'сколько у меня друзей?':
count_string = format_count_friends(len(DATABASE))
return f'У тебя {count_string}'
elif query == 'кто все мои друзья?':
friends_string = ', '.join(DATABASE.keys())
return f'Твои друзья: {friends_string}'
elif query == 'где все мои друзья?':
unique_cities = set(DATABASE.values())
cities_string = ', '.join(unique_cities)
return f'Твои друзья в городах: {cities_string}'
else:
return '<неизвестный запрос>'
def process_friend(name, query):
if name in DATABASE:
city = DATABASE[name]
if query == 'ты где?':
return f'{name} в городе {city}'
elif query == 'который час?':
if city not in UTC_OFFSET:
return f'<не могу определить время в городе {city}>'
time = what_time(city)
return f'Там сейчас {time}'
elif query == 'как погода?':
return what_weather(city)
else:
return '<неизвестный запрос>'
else:
return f'У тебя нет друга по имени {name}'
def process_query(query):
tokens = query.split(', ')
name = tokens[0]
if name == 'Анфиса':
return process_anfisa(tokens[1])
else:
return process_friend(name, tokens[1])
def runner():
queries = [
'Анфиса, сколько у меня друзей?',
'Анфиса, кто все мои друзья?',
'Анфиса, где все мои друзья?',
'Анфиса, кто виноват?',
'Коля, ты где?',
'Соня, что делать?',
'Антон, ты где?',
'Алексей, который час?',
'Артём, который час?',
'Антон, который час?',
'Петя, который час?',
'Коля, как погода?',
'Соня, как погода?',
'Антон, как погода?'
]
for query in queries:
print(query, '-', process_query(query))
runner()Результат:
Анфиса, сколько у меня друзей? - У тебя 10 друзей Анфиса, кто все мои друзья? - Твои друзья: Сергей, Соня, Алексей, Миша, Дима, Алина, Егор, Коля, Артём, Петя Анфиса, где все мои друзья? - Твои друзья в городах: Омск, Калининград, Михайловка, Красноярск, Москва, Челябинск, Владивосток, Пермь Анфиса, кто виноват? - <неизвестный запрос> Коля, ты где? - Коля в городе Красноярск Соня, что делать? - <неизвестный запрос> Антон, ты где? - У тебя нет друга по имени Антон Алексей, который час? - Там сейчас 15:50 Артём, который час? - Там сейчас 23:50 Антон, который час? - У тебя нет друга по имени Антон Петя, который час? - <не могу определить время в городе Михайловка> Коля, как погода? - ⛅️ ?️-10°C ?️→7.2 m/s Соня, как погода? - ☀️ ?️-3°C ?️↑4.2 m/s Антон, как погода? - У тебя нет друга по имени Антон
В этом руководстве мы расскажем, как обрабатывать исключения в Python с помощью try и except. Рассмотрим общий синтаксис и простые примеры, обсудим, что может пойти не так, и предложим меры по исправлению положения.
Зачастую разработчик может предугадать возникновение ошибок при работе даже синтаксически и логически правильной программы. Эти ошибки могут быть вызваны неверными входными данными или некоторыми предсказуемыми несоответствиями.
Для обработки большей части этих ошибок как исключений в Python есть блоки try и except.
Для начала разберем синтаксис операторов try и except в Python. Общий шаблон представлен ниже:
try:
# В этом блоке могут быть ошибки
except <error type>:
# Сделай это для обработки исключения;
# выполняется, если блок try выбрасывает ошибку
else:
# Сделай это, если блок try выполняется успешно, без ошибок
finally:
# Этот блок выполняется всегда
Давайте посмотрим, для чего используются разные блоки.
Блок try
Блок try — это блок кода, который вы хотите попробовать выполнить. Однако во время выполнения из-за какого-нибудь исключения могут возникнуть ошибки. Поэтому этот блок может не работать должным образом.
Блок except
Блок except запускается, когда блок try не срабатывает из-за исключения. Инструкции в этом блоке часто дают некоторый контекст того, что пошло не так внутри блока try.
Если собираетесь перехватить ошибку как исключение, в блоке except нужно обязательно указать тип этой ошибки. В приведенном выше сниппете место для указания типа ошибки обозначено плейсхолдером <error type> .
except можно использовать и без указания типа ошибки. Но лучше так не делать. При таком подходе не учитывается, что возникающие ошибки могут быть разных типов. То есть вы будете знать, что что-то пошло не так, но что именно произошло, какая была ошибка — вам будет не известно.
При попытке выполнить код внутри блока try также существует вероятность возникновения нескольких ошибок.
Например, вы можете попытаться обратиться к элементу списка по индексу, выходящему за пределы допустимого диапазона, использовать неправильный ключ словаря и попробовать открыть несуществующий файл – и все это внутри одного блока try.
В результате вы можете столкнуться с IndexError, KeyError и FileNotFoundError. В таком случае нужно добавить столько блоков except, сколько ошибок ожидается – по одному для каждого типа ошибки.
Блок else
Блок else запускается только в том случае, если блок try выполняется без ошибок. Это может быть полезно, когда нужно выполнить ещё какие-то действия после успешного выполнения блока try. Например, после успешного открытия файла вы можете прочитать его содержимое.
Блок finally
Блок finally выполняется всегда, независимо от того, что происходит в других блоках. Это полезно, когда вы хотите освободить ресурсы после выполнения определенного блока кода.
Примечание: блоки else и finally не являются обязательными. В большинстве случаев вы можете использовать только блок try, чтобы что-то сделать, и перехватывать ошибки как исключения внутри блока except.
[python_ad_block]
Итак, теперь давайте используем полученные знания для обработки исключений в Python. Приступим!
Обработка ZeroDivisionError
Рассмотрим функцию divide(), показанную ниже. Она принимает два аргумента – num и div – и возвращает частное от операции деления num/div.
def divide(num,div):
return num/div
Вызов функции с разными аргументами возвращает ожидаемый результат:
res = divide(100,8) print(res) # Output # 12.5 res = divide(568,64) print(res) # Output # 8.875
Этот код работает нормально, пока вы не попробуете разделить число на ноль:
divide(27,0)
Вы видите, что программа выдает ошибку ZeroDivisionError:
# Output
---------------------------------------------------------------------------
ZeroDivisionError Traceback (most recent call last)
<ipython-input-19-932ea024ce43> in <module>()
----> 1 divide(27,0)
<ipython-input-1-c98670fd7a12> in divide(num, div)
1 def divide(num,div):
----> 2 return num/div
ZeroDivisionError: division by zero
Можно обработать деление на ноль как исключение, выполнив следующие действия:
- В блоке
tryпоместите вызов функцииdivide(). По сути, вы пытаетесь разделитьnumнаdiv(try в переводе с английского — «пытаться», — прим. перев.). - В блоке
exceptобработайте случай, когдаdivравен 0, как исключение. - В результате этих действий при делении на ноль больше не будет выбрасываться ZeroDivisionError. Вместо этого будет выводиться сообщение, информирующее пользователя, что он попытался делить на ноль.
Вот как все это выглядит в коде:
try:
res = divide(num,div)
print(res)
except ZeroDivisionError:
print("You tried to divide by zero :( ")
При корректных входных данных наш код по-прежнему работает великолепно:
divide(10,2) # Output # 5.0
Когда же пользователь попытается разделить на ноль, он получит уведомление о возникшем исключении. Таким образом, программа завершается корректно и без ошибок.
divide(10,0) # Output # You tried to divide by zero :(
Обработка TypeError
В этом разделе мы разберем, как использовать try и except для обработки TypeError в Python.
Рассмотрим функцию add_10(). Она принимает число в качестве аргумента, прибавляет к нему 10 и возвращает результат этого сложения.
def add_10(num):
return num + 10
Вы можете вызвать функцию add_10() с любым числом, и она будет работать нормально, как показано ниже:
result = add_10(89) print(result) # Output # 99
Теперь попробуйте вызвать функцию add_10(), передав ей в качестве аргумента не число, а строку.
add_10 ("five")
Ваша программа вылетит со следующим сообщением об ошибке:
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
<ipython-input-15-9844e949c84e> in <module>()
----> 1 add_10("five")
<ipython-input-13-2e506d74d919> in add_10(num)
1 def add_10(num):
----> 2 return num + 10
TypeError: can only concatenate str (not "int") to str
Сообщение об ошибке TypeError: can only concatenate str (not "int") to str говорит о том, что можно сложить только две строки, а не добавить целое число к строке.
Обработаем TypeError:
- В блок try мы помещаем вызов функции
add_10()с my_num в качестве аргумента. Если аргумент допустимого типа, исключений не возникнет. - В противном случае срабатывает блок
except, в который мы помещаем вывод уведомления для пользователя о том, что аргумент имеет недопустимый тип.
Это показано ниже:
my_num = "five"
try:
result = add_10(my_num)
print(result)
except TypeError:
print("The argument `num` should be a number")
Поскольку теперь вы обработали TypeError как исключение, при передаче невалидного аргумента ошибка не возникает. Вместо нее выводится сообщение, что аргумент имеет недопустимый тип.
The argument `num` should be a number
Обработка IndexError
Если вам приходилось работать со списками или любыми другими итерируемыми объектами, вы, вероятно, сталкивались с IndexError.
Это связано с тем, что часто бывает сложно отслеживать все изменения в итерациях. И вы можете попытаться получить доступ к элементу по невалидному индексу.
В этом примере список my_list состоит из 4 элементов. Допустимые индексы — 0, 1, 2 и 3 и -1, -2, -3, -4, если вы используете отрицательную индексацию.
Поскольку 2 является допустимым индексом, вы видите, что элемент с этим индексом (C++) распечатывается:
my_list = ["Python","C","C++","JavaScript"] print(my_list[2]) # Output # C++
Но если вы попытаетесь получить доступ к элементу по индексу, выходящему за пределы допустимого диапазона, вы столкнетесь с IndexError:
print(my_list[4])
---------------------------------------------------------------------------
IndexError Traceback (most recent call last)
<ipython-input-7-437bc6501dea> in <module>()
1 my_list = ["Python","C","C++","JavaScript"]
----> 2 print(my_list[4])
IndexError: list index out of range
Теперь вы уже знакомы с шаблоном, и вам не составит труда использовать try и except для обработки данной ошибки.
В приведенном ниже фрагменте кода мы пытаемся получить доступ к элементу по индексу search_idx.
search_idx = 3
try:
print(my_list[search_idx])
except IndexError:
print("Sorry, the list index is out of range")
Здесь search_idx = 3 является допустимым индексом, поэтому в результате выводится соответствующий элемент — JavaScript.
Если search_idx находится за пределами допустимого диапазона индексов, блок except перехватывает IndexError как исключение, и больше нет длинных сообщений об ошибках.
search_idx = 4
try:
print(my_list[search_idx])
except IndexError:
print("Sorry, the list index is out of range")
Вместо этого отображается сообщение о том, что search_idx находится вне допустимого диапазона индексов:
Sorry, the list index is out of range
Обработка KeyError
Вероятно, вы уже сталкивались с KeyError при работе со словарями в Python.
Рассмотрим следующий пример, где у нас есть словарь my_dict.
my_dict ={"key1":"value1","key2":"value2","key3":"value3"}
search_key = "non-existent key"
print(my_dict[search_key])
В словаре my_dict есть 3 пары «ключ-значение»: key1:value1, key2:value2 и key3:value3.
Теперь попытаемся получить доступ к значению, соответствующему несуществующему ключу non-existent key.
Как и ожидалось, мы получим KeyError:
---------------------------------------------------------------------------
KeyError Traceback (most recent call last)
<ipython-input-2-2a61d404be04> in <module>()
1 my_dict ={"key1":"value1","key2":"value2","key3":"value3"}
2 search_key = "non-existent key"
----> 3 my_dict[search_key]
KeyError: 'non-existent key'
Вы можете обработать KeyError почти так же, как и IndexError.
- Пробуем получить доступ к значению, которое соответствует ключу, определенному
search_key. - Если
search_key— валидный ключ, мы распечатываем соответствующее значение. - Если ключ невалиден и возникает исключение — задействуется блок except, чтобы сообщить об этом пользователю.
Все это можно видеть в следующем коде:
try:
print(my_dict[search_key])
except KeyError:
print("Sorry, that's not a valid key!")
# Output:
# Sorry, that's not a valid key!
Если вы хотите предоставить дополнительный контекст, например имя невалидного ключа, это тоже можно сделать. Возможно, ключ оказался невалидным из-за ошибки в написании. Если вы укажете этот ключ в сообщении, это поможет пользователю исправить опечатку.
Вы можете сделать это, перехватив невалидный ключ как <error_msg> и используя его в сообщении, которое печатается при возникновении исключения:
try:
print(my_dict[search_key])
except KeyError as error_msg:
print(f"Sorry,{error_msg} is not a valid key!")
Обратите внимание, что теперь в сообщении об ошибки указано также и имя несуществующего ключа:
Sorry, 'non-existent key' is not a valid key!
Обработка FileNotFoundError
При работе с файлами в Python часто возникает ошибка FileNotFoundError.
В следующем примере мы попытаемся открыть файл my_file.txt, указав его путь в функции open(). Мы хотим прочитать файл и вывести его содержимое.
Однако мы еще не создали этот файл в указанном месте.
my_file = open("/content/sample_data/my_file.txt")
contents = my_file.read()
print(contents)
Поэтому, попытавшись запустить приведенный выше фрагмент кода, мы получим FileNotFoundError:
---------------------------------------------------------------------------
FileNotFoundError Traceback (most recent call last)
<ipython-input-4-4873cac1b11a> in <module>()
----> 1 my_file = open("my_file.txt")
FileNotFoundError: [Errno 2] No such file or directory: 'my_file.txt'
А с помощью try и except мы можем сделать следующее:
- Попробуем открыть файл в блоке
try. - Обработаем
FileNotFoundErrorв блокеexcept, сообщив пользователю, что он попытался открыть несуществующий файл. - Если блок
tryзавершается успешно и файл действительно существует, прочтем и распечатаем содержимое. - В блоке
finallyзакроем файл, чтобы не терять ресурсы. Файл будет закрыт независимо от того, что происходило на этапах открытия и чтения.
try:
my_file = open("/content/sample_data/my_file.txt")
except FileNotFoundError:
print(f"Sorry, the file does not exist")
else:
contents = my_file.read()
print(contents)
finally:
my_file.close()
Обратите внимание: мы обработали ошибку как исключение, и программа завершает работу, отображая следующее сообщение:
Sorry, the file does not exist
Теперь рассмотрим случай, когда срабатывает блок else. Файл my_file.txt теперь присутствует по указанному ранее пути.
Вот содержимое этого файла:
Теперь повторный запуск нашего кода работает должным образом.
На этот раз файл my_file.txt присутствует, поэтому запускается блок else и содержимое распечатывается, как показано ниже:
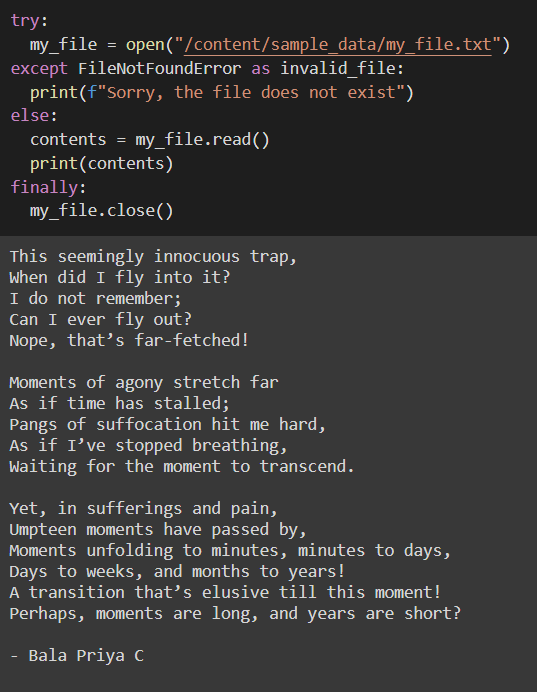
Надеемся, теперь вы поняли, как обрабатывать исключения при работе с файлами.
Заключение
В этом руководстве мы рассмотрели, как обрабатывать исключения в Python с помощью try и except.
Также мы разобрали на примерах, какие типы исключений могут возникать и как при помощи except ловить наиболее распространенные ошибки.
Надеемся, вам понравился этот урок. Успехов в написании кода!
Перевод статьи «Python Try and Except Statements – How to Handle Exceptions in Python».
Содержание:развернуть
- Как устроен механизм исключений
- Как обрабатывать исключения в Python (try except)
-
As — сохраняет ошибку в переменную
-
Finally — выполняется всегда
-
Else — выполняется когда исключение не было вызвано
-
Несколько блоков except
-
Несколько типов исключений в одном блоке except
-
Raise — самостоятельный вызов исключений
-
Как пропустить ошибку
- Исключения в lambda функциях
- 20 типов встроенных исключений в Python
- Как создать свой тип Exception
Программа, написанная на языке Python, останавливается сразу как обнаружит ошибку. Ошибки могут быть (как минимум) двух типов:
- Синтаксические ошибки — возникают, когда написанное выражение не соответствует правилам языка (например, написана лишняя скобка);
- Исключения — возникают во время выполнения программы (например, при делении на ноль).
Синтаксические ошибки исправить просто (если вы используете IDE, он их подсветит). А вот с исключениями всё немного сложнее — не всегда при написании программы можно сказать возникнет или нет в данном месте исключение. Чтобы приложение продолжило работу при возникновении проблем, такие ошибки нужно перехватывать и обрабатывать с помощью блока try/except.
Как устроен механизм исключений
В Python есть встроенные исключения, которые появляются после того как приложение находит ошибку. В этом случае текущий процесс временно приостанавливается и передает ошибку на уровень вверх до тех пор, пока она не будет обработано. Если ошибка не будет обработана, программа прекратит свою работу (а в консоли мы увидим Traceback с подробным описанием ошибки).
💁♂️ Пример: напишем скрипт, в котором функция ожидает число, а мы передаём сроку (это вызовет исключение «TypeError»):
def b(value):
print("-> b")
print(value + 1) # ошибка тут
def a(value):
print("-> a")
b(value)
a("10")
> -> a
> -> b
> Traceback (most recent call last):
> File "test.py", line 11, in <module>
> a("10")
> File "test.py", line 8, in a
> b(value)
> File "test.py", line 3, in b
> print(value + 1)
> TypeError: can only concatenate str (not "int") to str
В данном примере мы запускаем файл «test.py» (через консоль). Вызывается функция «a«, внутри которой вызывается функция «b«. Все работает хорошо до сточки print(value + 1). Тут интерпретатор понимает, что нельзя конкатенировать строку с числом, останавливает выполнение программы и вызывает исключение «TypeError».
Далее ошибка передается по цепочке в обратном направлении: «b» → «a» → «test.py«. Так как в данном примере мы не позаботились обработать эту ошибку, вся информация по ошибке отобразится в консоли в виде Traceback.
Traceback (трассировка) — это отчёт, содержащий вызовы функций, выполненные в определенный момент. Трассировка помогает узнать, что пошло не так и в каком месте это произошло.
Traceback лучше читать снизу вверх ↑
В нашем примере Traceback содержится следующую информацию (читаем снизу вверх):
TypeError— тип ошибки (означает, что операция не может быть выполнена с переменной этого типа);can only concatenate str (not "int") to str— подробное описание ошибки (конкатенировать можно только строку со строкой);- Стек вызова функций (1-я линия — место, 2-я линия — код). В нашем примере видно, что в файле «test.py» на 11-й линии был вызов функции «a» со строковым аргументом «10». Далее был вызов функции «b».
print(value + 1)это последнее, что было выполнено — тут и произошла ошибка. most recent call last— означает, что самый последний вызов будет отображаться последним в стеке (в нашем примере последним выполнилсяprint(value + 1)).
В Python ошибку можно перехватить, обработать, и продолжить выполнение программы — для этого используется конструкция try ... except ....
Как обрабатывать исключения в Python (try except)
В Python исключения обрабатываются с помощью блоков try/except. Для этого операция, которая может вызвать исключение, помещается внутрь блока try. А код, который должен быть выполнен при возникновении ошибки, находится внутри except.
Например, вот как можно обработать ошибку деления на ноль:
try:
a = 7 / 0
except:
print('Ошибка! Деление на 0')
Здесь в блоке try находится код a = 7 / 0 — при попытке его выполнить возникнет исключение и выполнится код в блоке except (то есть будет выведено сообщение «Ошибка! Деление на 0»). После этого программа продолжит свое выполнение.
💭 PEP 8 рекомендует, по возможности, указывать конкретный тип исключения после ключевого слова except (чтобы перехватывать и обрабатывать конкретные исключения):
try:
a = 7 / 0
except ZeroDivisionError:
print('Ошибка! Деление на 0')
Однако если вы хотите перехватывать все исключения, которые сигнализируют об ошибках программы, используйте тип исключения Exception:
try:
a = 7 / 0
except Exception:
print('Любая ошибка!')
As — сохраняет ошибку в переменную
Перехваченная ошибка представляет собой объект класса, унаследованного от «BaseException». С помощью ключевого слова as можно записать этот объект в переменную, чтобы обратиться к нему внутри блока except:
try:
file = open('ok123.txt', 'r')
except FileNotFoundError as e:
print(e)
> [Errno 2] No such file or directory: 'ok123.txt'
В примере выше мы обращаемся к объекту класса «FileNotFoundError» (при выводе на экран через print отобразится строка с полным описанием ошибки).
У каждого объекта есть поля, к которым можно обращаться (например если нужно логировать ошибку в собственном формате):
import datetime
now = datetime.datetime.now().strftime("%d-%m-%Y %H:%M:%S")
try:
file = open('ok123.txt', 'r')
except FileNotFoundError as e:
print(f"{now} [FileNotFoundError]: {e.strerror}, filename: {e.filename}")
> 20-11-2021 18:42:01 [FileNotFoundError]: No such file or directory, filename: ok123.txt
Finally — выполняется всегда
При обработке исключений можно после блока try использовать блок finally. Он похож на блок except, но команды, написанные внутри него, выполняются обязательно. Если в блоке try не возникнет исключения, то блок finally выполнится так же, как и при наличии ошибки, и программа возобновит свою работу.
Обычно try/except используется для перехвата исключений и восстановления нормальной работы приложения, а try/finally для того, чтобы гарантировать выполнение определенных действий (например, для закрытия внешних ресурсов, таких как ранее открытые файлы).
В следующем примере откроем файл и обратимся к несуществующей строке:
file = open('ok.txt', 'r')
try:
lines = file.readlines()
print(lines[5])
finally:
file.close()
if file.closed:
print("файл закрыт!")
> файл закрыт!
> Traceback (most recent call last):
> File "test.py", line 5, in <module>
> print(lines[5])
> IndexError: list index out of range
Даже после исключения «IndexError», сработал код в секции finally, который закрыл файл.
p.s. данный пример создан для демонстрации, в реальном проекте для работы с файлами лучше использовать менеджер контекста with.
Также можно использовать одновременно три блока try/except/finally. В этом случае:
- в
try— код, который может вызвать исключения; - в
except— код, который должен выполниться при возникновении исключения; - в
finally— код, который должен выполниться в любом случае.
def sum(a, b):
res = 0
try:
res = a + b
except TypeError:
res = int(a) + int(b)
finally:
print(f"a = {a}, b = {b}, res = {res}")
sum(1, "2")
> a = 1, b = 2, res = 3
Else — выполняется когда исключение не было вызвано
Иногда нужно выполнить определенные действия, когда код внутри блока try не вызвал исключения. Для этого используется блок else.
Допустим нужно вывести результат деления двух чисел и обработать исключения в случае попытки деления на ноль:
b = int(input('b = '))
c = int(input('c = '))
try:
a = b / c
except ZeroDivisionError:
print('Ошибка! Деление на 0')
else:
print(f"a = {a}")
> b = 10
> c = 1
> a = 10.0
В этом случае, если пользователь присвоит переменной «с» ноль, то появится исключение и будет выведено сообщение «‘Ошибка! Деление на 0′», а код внутри блока else выполняться не будет. Если ошибки не будет, то на экране появятся результаты деления.
Несколько блоков except
В программе может возникнуть несколько исключений, например:
- Ошибка преобразования введенных значений к типу
float(«ValueError»); - Деление на ноль («ZeroDivisionError»).
В Python, чтобы по-разному обрабатывать разные типы ошибок, создают несколько блоков except:
try:
b = float(input('b = '))
c = float(input('c = '))
a = b / c
except ZeroDivisionError:
print('Ошибка! Деление на 0')
except ValueError:
print('Число введено неверно')
else:
print(f"a = {a}")
> b = 10
> c = 0
> Ошибка! Деление на 0
> b = 10
> c = питон
> Число введено неверно
Теперь для разных типов ошибок есть свой обработчик.
Несколько типов исключений в одном блоке except
Можно также обрабатывать в одном блоке except сразу несколько исключений. Для этого они записываются в круглых скобках, через запятую сразу после ключевого слова except. Чтобы обработать сообщения «ZeroDivisionError» и «ValueError» в одном блоке записываем их следующим образом:
try:
b = float(input('b = '))
c = float(input('c = '))
a = b / c
except (ZeroDivisionError, ValueError) as er:
print(er)
else:
print('a = ', a)
При этом переменной er присваивается объект того исключения, которое было вызвано. В результате на экран выводятся сведения о конкретной ошибке.
Raise — самостоятельный вызов исключений
Исключения можно генерировать самостоятельно — для этого нужно запустить оператор raise.
min = 100
if min > 10:
raise Exception('min must be less than 10')
> Traceback (most recent call last):
> File "test.py", line 3, in <module>
> raise Exception('min value must be less than 10')
> Exception: min must be less than 10
Перехватываются такие сообщения точно так же, как и остальные:
min = 100
try:
if min > 10:
raise Exception('min must be less than 10')
except Exception:
print('Моя ошибка')
> Моя ошибка
Кроме того, ошибку можно обработать в блоке except и пробросить дальше (вверх по стеку) с помощью raise:
min = 100
try:
if min > 10:
raise Exception('min must be less than 10')
except Exception:
print('Моя ошибка')
raise
> Моя ошибка
> Traceback (most recent call last):
> File "test.py", line 5, in <module>
> raise Exception('min must be less than 10')
> Exception: min must be less than 10
Как пропустить ошибку
Иногда ошибку обрабатывать не нужно. В этом случае ее можно пропустить с помощью pass:
try:
a = 7 / 0
except ZeroDivisionError:
pass
Исключения в lambda функциях
Обрабатывать исключения внутри lambda функций нельзя (так как lambda записывается в виде одного выражения). В этом случае нужно использовать именованную функцию.
20 типов встроенных исключений в Python
Иерархия классов для встроенных исключений в Python выглядит так:
BaseException
SystemExit
KeyboardInterrupt
GeneratorExit
Exception
ArithmeticError
AssertionError
...
...
...
ValueError
Warning
Все исключения в Python наследуются от базового BaseException:
SystemExit— системное исключение, вызываемое функциейsys.exit()во время выхода из приложения;KeyboardInterrupt— возникает при завершении программы пользователем (чаще всего при нажатии клавиш Ctrl+C);GeneratorExit— вызывается методомcloseобъектаgenerator;Exception— исключения, которые можно и нужно обрабатывать (предыдущие были системными и их трогать не рекомендуется).
От Exception наследуются:
1 StopIteration — вызывается функцией next в том случае если в итераторе закончились элементы;
2 ArithmeticError — ошибки, возникающие при вычислении, бывают следующие типы:
FloatingPointError— ошибки при выполнении вычислений с плавающей точкой (встречаются редко);OverflowError— результат вычислений большой для текущего представления (не появляется при операциях с целыми числами, но может появиться в некоторых других случаях);ZeroDivisionError— возникает при попытке деления на ноль.
3 AssertionError — выражение, используемое в функции assert неверно;
4 AttributeError — у объекта отсутствует нужный атрибут;
5 BufferError — операция, для выполнения которой требуется буфер, не выполнена;
6 EOFError — ошибка чтения из файла;
7 ImportError — ошибка импортирования модуля;
8 LookupError — неверный индекс, делится на два типа:
IndexError— индекс выходит за пределы диапазона элементов;KeyError— индекс отсутствует (для словарей, множеств и подобных объектов);
9 MemoryError — память переполнена;
10 NameError — отсутствует переменная с данным именем;
11 OSError — исключения, генерируемые операционной системой:
ChildProcessError— ошибки, связанные с выполнением дочернего процесса;ConnectionError— исключения связанные с подключениями (BrokenPipeError, ConnectionResetError, ConnectionRefusedError, ConnectionAbortedError);FileExistsError— возникает при попытке создания уже существующего файла или директории;FileNotFoundError— генерируется при попытке обращения к несуществующему файлу;InterruptedError— возникает в том случае если системный вызов был прерван внешним сигналом;IsADirectoryError— программа обращается к файлу, а это директория;NotADirectoryError— приложение обращается к директории, а это файл;PermissionError— прав доступа недостаточно для выполнения операции;ProcessLookupError— процесс, к которому обращается приложение не запущен или отсутствует;TimeoutError— время ожидания истекло;
12 ReferenceError — попытка доступа к объекту с помощью слабой ссылки, когда объект не существует;
13 RuntimeError — генерируется в случае, когда исключение не может быть классифицировано или не подпадает под любую другую категорию;
14 NotImplementedError — абстрактные методы класса нуждаются в переопределении;
15 SyntaxError — ошибка синтаксиса;
16 SystemError — сигнализирует о внутренне ошибке;
17 TypeError — операция не может быть выполнена с переменной этого типа;
18 ValueError — возникает когда в функцию передается объект правильного типа, но имеющий некорректное значение;
19 UnicodeError — исключение связанное с кодирование текста в unicode, бывает трех видов:
UnicodeEncodeError— ошибка кодирования;UnicodeDecodeError— ошибка декодирования;UnicodeTranslateError— ошибка переводаunicode.
20 Warning — предупреждение, некритическая ошибка.
💭 Посмотреть всю цепочку наследования конкретного типа исключения можно с помощью модуля inspect:
import inspect
print(inspect.getmro(TimeoutError))
> (<class 'TimeoutError'>, <class 'OSError'>, <class 'Exception'>, <class 'BaseException'>, <class 'object'>)
📄 Подробное описание всех классов встроенных исключений в Python смотрите в официальной документации.
Как создать свой тип Exception
В Python можно создавать свои исключения. При этом есть одно обязательное условие: они должны быть потомками класса Exception:
class MyError(Exception):
def __init__(self, text):
self.txt = text
try:
raise MyError('Моя ошибка')
except MyError as er:
print(er)
> Моя ошибка
С помощью try/except контролируются и обрабатываются ошибки в приложении. Это особенно актуально для критически важных частей программы, где любые «падения» недопустимы (или могут привести к негативным последствиям). Например, если программа работает как «демон», падение приведет к полной остановке её работы. Или, например, при временном сбое соединения с базой данных, программа также прервёт своё выполнение (хотя можно было отловить ошибку и попробовать соединиться в БД заново).
Вместе с try/except можно использовать дополнительные блоки. Если использовать все блоки описанные в статье, то код будет выглядеть так:
try:
# попробуем что-то сделать
except (ZeroDivisionError, ValueError) as e:
# обрабатываем исключения типа ZeroDivisionError или ValueError
except Exception as e:
# исключение не ZeroDivisionError и не ValueError
# поэтому обрабатываем исключение общего типа (унаследованное от Exception)
# сюда не сходят исключения типа GeneratorExit, KeyboardInterrupt, SystemExit
else:
# этот блок выполняется, если нет исключений
# если в этом блоке сделать return, он не будет вызван, пока не выполнился блок finally
finally:
# этот блок выполняется всегда, даже если нет исключений else будет проигнорирован
# если в этом блоке сделать return, то return в блоке
Подробнее о работе с исключениями в Python можно ознакомиться в официальной документации.

When coding in Python, you can often anticipate runtime errors even in a syntactically and logically correct program. These errors can be caused by invalid inputs or some predictable inconsistencies.
In Python, you can use the try and the except blocks to handle most of these errors as exceptions all the more gracefully.
In this tutorial, you’ll learn the general syntax of try and except. Then we’ll proceed to code simple examples, discuss what can go wrong, and provide corrective measures using try and except blocks.
Syntax of Python Try and Except Blocks
Let’s start by understanding the syntax of the try and except statements in Python. The general template is shown below:
try:
# There can be errors in this block
except <error type>:
# Do this to handle exception;
# executed if the try block throws an error
else:
# Do this if try block executes successfully without errors
finally:
# This block is always executed
Let’s look at what the different blocks are used for:
- The
tryblock is the block of statements you’d like to try executing. However, there may be runtime errors due to an exception, and this block may fail to work as intended. - The
exceptblock is triggered when thetryblock fails due to an exception. It contains a set of statements that often give you some context on what went wrong inside thetryblock. - You should always mention the type of error that you intend to catch as exception inside the
exceptblock, denoted by the placeholder<error type>in the above snippet. - You might as well use
exceptwithout specifying the<error type>. But, this is not a recommended practice as you’re not accounting for the different types of errors that can occur.
In trying to execute the code inside the
tryblock, there’s also a possibility for multiple errors to occur.
For example, you may be accessing a list using an index that’s way out of range, using a wrong dictionary key, and trying to open a file that does not exist — all inside the try block.
In this case, you may run into IndexError, KeyError, and FileNotFoundError. And you have to add as many except blocks as the number of errors that you anticipate, one for each type of error.
- The
elseblock is triggered only if thetryblock is executed without errors. This can be useful when you’d like to take a follow-up action when thetryblock succeeds. For example, if you try and open a file successfully, you may want to read its content. - The
finallyblock is always executed, regardless of what happens in the other blocks. This is useful when you’d like to free up resources after the execution of a particular block of code.
Note: The
elseandfinallyblocks are optional. In most cases, you can use only thetryblock to try doing something, and catch errors as exceptions inside theexceptblock.
Over the next few minutes, you’ll use what you’ve learned thus far to handle exceptions in Python. Let’s get started.
How to Handle a ZeroDivisionError in Python
Consider the function divide() shown below. It takes two arguments – num and div – and returns the quotient of the division operation num/div.
def divide(num,div):
return num/div▶ Calling the function with different numbers returns results as expected:
res = divide(100,8)
print(res)
# Output
12.5
res = divide(568,64)
print(res)
# Output
8.875
This code works fine until you try dividing by zero:
divide(27,0)
You see that the program crashes throwing a ZeroDivisionError:
# Output
---------------------------------------------------------------------------
ZeroDivisionError Traceback (most recent call last)
<ipython-input-19-932ea024ce43> in <module>()
----> 1 divide(27,0)
<ipython-input-1-c98670fd7a12> in divide(num, div)
1 def divide(num,div):
----> 2 return num/div
ZeroDivisionError: division by zero
You can handle this division by zero as an exception by doing the following:
- In the
tryblock, place a call to thedivide()function. In essence, you’re trying to dividenumbydiv. - Handle the case when
divis0as an exception inside theexceptblock. - In this example, you can except
ZeroDivisionErrorby printing a message informing the user that they tried dividing by zero.
This is shown in the code snippet below:
try:
res = divide(num,div)
print(res)
except ZeroDivisionError:
print("You tried to divide by zero :( ")
With a valid input, the code still works fine.
divide(10,2)
# Output
5.0
When you try diving by zero, you’re notified of the exception that occurs, and the program ends gracefully.
divide(10,0)
# Output
You tried to divide by zero :(
How to Handle a TypeError in Python
In this section, you’ll see how you can use try and except to handle a TypeError in Python.
▶ Consider the following function add_10() that takes in a number as the argument, adds 10 to it, and returns the result of this addition.
def add_10(num):
return num + 10You can call the function add_10() with any number and it’ll work fine, as shown below:
result = add_10(89)
print(result)
#Output
99Now try calling add_10() with "five" instead of 5.
add_10("five")You’ll notice that your program crashes with the following error message:
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
<ipython-input-15-9844e949c84e> in <module>()
----> 1 add_10("five")
<ipython-input-13-2e506d74d919> in add_10(num)
1 def add_10(num):
----> 2 return num + 10
TypeError: can only concatenate str (not "int") to strThe error message TypeError: can only concatenate str (not "int") to str explains that you can only concatenate two strings, and not add an integer to a string.
Now, you have the following:
- Given a number
my_num, try calling the functionadd_10()withmy_numas the argument. If the argument is of valid type, there’s no exception - Otherwise, the
exceptblock corresponding to theTypeErroris triggered, notifying the user that the argument is of invalid type.
This is explained below:
my_num = "five"
try:
result = add_10(my_num)
print(result)
except TypeError:
print("The argument `num` should be a number")Since you’ve now handled TypeError as an exception, you’re only informed that the argument is of invalid type.
The argument `num` should be a numberHow to Handle an IndexError in Python
If you’ve worked with Python lists, or any Python iterable before, you’ll have probably run into IndexError.
This is because it’s often difficult to keep track of all changes to iterables. And you may be trying to access an item at an index that’s not valid.
▶ In this example, the list my_list has 4 items. The valid indices are 0, 1, 2, and 3, and -1, -2, -3, -4 if you use negative indexing.
As 2 is a valid index, you see that the item at index 2, which is C++, is printed out:
my_list = ["Python","C","C++","JavaScript"]
print(my_list[2])
#Output
C++If you try accessing an item at index that’s outside the range of valid indices, you’ll run into an IndexError:
print(my_list[4])---------------------------------------------------------------------------
IndexError Traceback (most recent call last)
<ipython-input-7-437bc6501dea> in <module>()
1 my_list = ["Python","C","C++","JavaScript"]
----> 2 print(my_list[4])
IndexError: list index out of rangeIf you’re familiar with the pattern, you’ll now use try and except to handle index errors.
▶ In the code snippet below, you try accessing the item at the index specified by search_idx.
search_idx = 3
try:
print(my_list[search_idx])
except IndexError:
print("Sorry, the list index is out of range")Here, the search_idx (3) is a valid index, and the item at the particular index is printed out:
JavaScriptIf the search_idx is outside the valid range for indices, the except block catches the IndexError as an exception, and there are no more long error messages. 🙂
search_idx = 4
try:
print(my_list[search_idx])
except IndexError:
print("Sorry, the list index is out of range")Rather, the message that the search_idx is out of the valid range of indices is displayed:
Sorry, the list index is out of rangeHow to Handle a KeyError in Python
You have likely run into KeyError when working with Python dictionaries
▶ Consider this example where you have a dictionary my_dict.
my_dict ={"key1":"value1","key2":"value2","key3":"value3"}
search_key = "non-existent key"
print(my_dict[search_key])- The dictionary
my_dicthas 3 key-value pairs,"key1:value1","key2:value2", and"key3:value3" - Now, you try to tap into the dictionary and access the value corresponding to the key
"non-existent key".
As expected, you’ll get a KeyError:
---------------------------------------------------------------------------
KeyError Traceback (most recent call last)
<ipython-input-2-2a61d404be04> in <module>()
1 my_dict ={"key1":"value1","key2":"value2","key3":"value3"}
2 search_key = "non-existent key"
----> 3 my_dict[search_key]
KeyError: 'non-existent key'You can handle KeyError in almost the same way you handled IndexError.
- You can try accessing the value corresponding to the key specified by the
search_key. - If
search_keyis indeed a valid key, the corresponding value is printed out. - If you run into an exception because of a non-existent key, you use the
exceptblock to let the user know.
This is explained in the code snippet below:
try:
print(my_dict[search_key])
except KeyError:
print("Sorry, that's not a valid key!")Sorry, that's not a valid key!▶ If you want to provide additional context such as the name of the invalid key, you can do that too. It’s possible that the key was misspelled which made it invalid. In this case, letting the user know the key used will probably help them fix the typo.
You can do this by catching the invalid key as <error_msg> and use it in the message printed when the exception occurs:
try:
print(my_dict[search_key])
except KeyError as error_msg:
print(f"Sorry,{error_msg} is not a valid key!")▶ Notice how the name of the key is also printed out:
Sorry,'non-existent key' is not a valid key!How to Handle a FileNotFoundError in Python
Another common error that occurs when working with files in Python is the FileNotFoundError.
▶ In the following example, you’re trying to open the file my_file.txt by specifying its path to the function open(). And you’d like to read the file and print out the contents of the file.
However, you haven’t yet created the file in the specified location.
If you try running the code snippet below, you’ll get a FileNotFoundError:
my_file = open("/content/sample_data/my_file.txt")
contents = my_file.read()
print(contents)---------------------------------------------------------------------------
FileNotFoundError Traceback (most recent call last)
<ipython-input-4-4873cac1b11a> in <module>()
----> 1 my_file = open("my_file.txt")
FileNotFoundError: [Errno 2] No such file or directory: 'my_file.txt'And using try and except, you can do the following:
- Try opening the file in the
tryblock. - Handle
FileNotFoundErrorin theexceptblock by letting the user know that they tried to open a file that doesn’t exist. - If the
tryblock succeeds, and the file does exist, read and print out the contents of the file. - In the
finallyblock, close the file so that there’s no wastage of resources. Recall how the file will be closed regardless of what happens in the file opening and reading steps.
try:
my_file = open("/content/sample_data/my_file.txt")
except FileNotFoundError:
print(f"Sorry, the file does not exist")
else:
contents = my_file.read()
print(contents)
finally:
my_file.close()Notice how you’ve handled the error as an exception and the program ends gracefully displaying the message below:
Sorry, the file does not exist▶ Let’s consider the case in which the else block is triggered. The file my_file.txt is now present at the path mentioned earlier.
And here’s what the file my_file.txt contains:
Now, re-running the earlier code snippet works as expected.
This time, the file my_file.txt is present, the else block is triggered and its contents are printed out, as shown below:
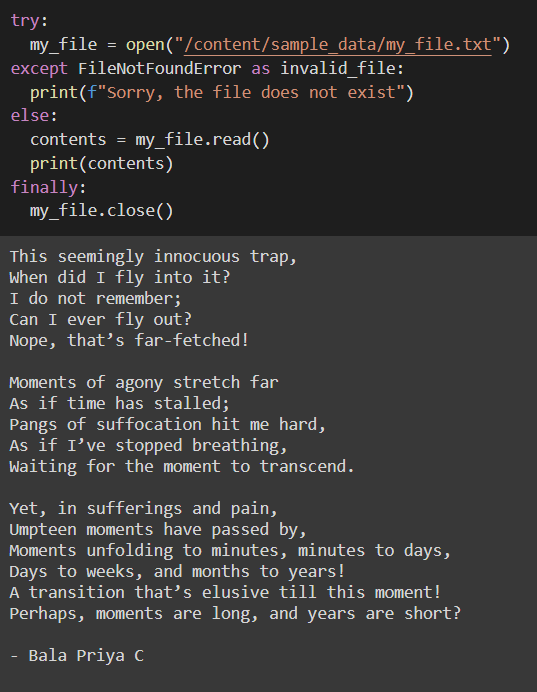
I hope this clarifies how you can handle exceptions when working with files.
Conclusion
In this tutorial, you’ve learned how you can use try and except statements in Python to handle exceptions.
You coded examples to understand what types of exception may occur and how you can use except to catch the most common errors.
Hope you enjoyed this tutorial. Happy coding! Until next time
Learn to code for free. freeCodeCamp’s open source curriculum has helped more than 40,000 people get jobs as developers. Get started
When coding in Python, you can often anticipate runtime errors even in a syntactically and logically correct program. These errors can be caused by invalid inputs or some predictable inconsistencies.
In Python, you can use the try and the except blocks to handle most of these errors as exceptions all the more gracefully.
In this tutorial, you’ll learn the general syntax of try and except. Then we’ll proceed to code simple examples, discuss what can go wrong, and provide corrective measures using try and except blocks.
Syntax of Python Try and Except Blocks
Let’s start by understanding the syntax of the try and except statements in Python. The general template is shown below:
try:
# There can be errors in this block
except <error type>:
# Do this to handle exception;
# executed if the try block throws an error
else:
# Do this if try block executes successfully without errors
finally:
# This block is always executed
Let’s look at what the different blocks are used for:
- The
tryblock is the block of statements you’d like to try executing. However, there may be runtime errors due to an exception, and this block may fail to work as intended. - The
exceptblock is triggered when thetryblock fails due to an exception. It contains a set of statements that often give you some context on what went wrong inside thetryblock. - You should always mention the type of error that you intend to catch as exception inside the
exceptblock, denoted by the placeholder<error type>in the above snippet. - You might as well use
exceptwithout specifying the<error type>. But, this is not a recommended practice as you’re not accounting for the different types of errors that can occur.
In trying to execute the code inside the
tryblock, there’s also a possibility for multiple errors to occur.
For example, you may be accessing a list using an index that’s way out of range, using a wrong dictionary key, and trying to open a file that does not exist — all inside the try block.
In this case, you may run into IndexError, KeyError, and FileNotFoundError. And you have to add as many except blocks as the number of errors that you anticipate, one for each type of error.
- The
elseblock is triggered only if thetryblock is executed without errors. This can be useful when you’d like to take a follow-up action when thetryblock succeeds. For example, if you try and open a file successfully, you may want to read its content. - The
finallyblock is always executed, regardless of what happens in the other blocks. This is useful when you’d like to free up resources after the execution of a particular block of code.
Note: The
elseandfinallyblocks are optional. In most cases, you can use only thetryblock to try doing something, and catch errors as exceptions inside theexceptblock.
Over the next few minutes, you’ll use what you’ve learned thus far to handle exceptions in Python. Let’s get started.
How to Handle a ZeroDivisionError in Python
Consider the function divide() shown below. It takes two arguments – num and div – and returns the quotient of the division operation num/div.
def divide(num,div):
return num/div▶ Calling the function with different numbers returns results as expected:
res = divide(100,8)
print(res)
# Output
12.5
res = divide(568,64)
print(res)
# Output
8.875
This code works fine until you try dividing by zero:
divide(27,0)
You see that the program crashes throwing a ZeroDivisionError:
# Output
---------------------------------------------------------------------------
ZeroDivisionError Traceback (most recent call last)
<ipython-input-19-932ea024ce43> in <module>()
----> 1 divide(27,0)
<ipython-input-1-c98670fd7a12> in divide(num, div)
1 def divide(num,div):
----> 2 return num/div
ZeroDivisionError: division by zero
You can handle this division by zero as an exception by doing the following:
- In the
tryblock, place a call to thedivide()function. In essence, you’re trying to dividenumbydiv. - Handle the case when
divis0as an exception inside theexceptblock. - In this example, you can except
ZeroDivisionErrorby printing a message informing the user that they tried dividing by zero.
This is shown in the code snippet below:
try:
res = divide(num,div)
print(res)
except ZeroDivisionError:
print("You tried to divide by zero :( ")
With a valid input, the code still works fine.
divide(10,2)
# Output
5.0
When you try diving by zero, you’re notified of the exception that occurs, and the program ends gracefully.
divide(10,0)
# Output
You tried to divide by zero :(
How to Handle a TypeError in Python
In this section, you’ll see how you can use try and except to handle a TypeError in Python.
▶ Consider the following function add_10() that takes in a number as the argument, adds 10 to it, and returns the result of this addition.
def add_10(num):
return num + 10You can call the function add_10() with any number and it’ll work fine, as shown below:
result = add_10(89)
print(result)
#Output
99Now try calling add_10() with "five" instead of 5.
add_10("five")You’ll notice that your program crashes with the following error message:
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
<ipython-input-15-9844e949c84e> in <module>()
----> 1 add_10("five")
<ipython-input-13-2e506d74d919> in add_10(num)
1 def add_10(num):
----> 2 return num + 10
TypeError: can only concatenate str (not "int") to strThe error message TypeError: can only concatenate str (not "int") to str explains that you can only concatenate two strings, and not add an integer to a string.
Now, you have the following:
- Given a number
my_num, try calling the functionadd_10()withmy_numas the argument. If the argument is of valid type, there’s no exception - Otherwise, the
exceptblock corresponding to theTypeErroris triggered, notifying the user that the argument is of invalid type.
This is explained below:
my_num = "five"
try:
result = add_10(my_num)
print(result)
except TypeError:
print("The argument `num` should be a number")Since you’ve now handled TypeError as an exception, you’re only informed that the argument is of invalid type.
The argument `num` should be a numberHow to Handle an IndexError in Python
If you’ve worked with Python lists, or any Python iterable before, you’ll have probably run into IndexError.
This is because it’s often difficult to keep track of all changes to iterables. And you may be trying to access an item at an index that’s not valid.
▶ In this example, the list my_list has 4 items. The valid indices are 0, 1, 2, and 3, and -1, -2, -3, -4 if you use negative indexing.
As 2 is a valid index, you see that the item at index 2, which is C++, is printed out:
my_list = ["Python","C","C++","JavaScript"]
print(my_list[2])
#Output
C++If you try accessing an item at index that’s outside the range of valid indices, you’ll run into an IndexError:
print(my_list[4])---------------------------------------------------------------------------
IndexError Traceback (most recent call last)
<ipython-input-7-437bc6501dea> in <module>()
1 my_list = ["Python","C","C++","JavaScript"]
----> 2 print(my_list[4])
IndexError: list index out of rangeIf you’re familiar with the pattern, you’ll now use try and except to handle index errors.
▶ In the code snippet below, you try accessing the item at the index specified by search_idx.
search_idx = 3
try:
print(my_list[search_idx])
except IndexError:
print("Sorry, the list index is out of range")Here, the search_idx (3) is a valid index, and the item at the particular index is printed out:
JavaScriptIf the search_idx is outside the valid range for indices, the except block catches the IndexError as an exception, and there are no more long error messages. 🙂
search_idx = 4
try:
print(my_list[search_idx])
except IndexError:
print("Sorry, the list index is out of range")Rather, the message that the search_idx is out of the valid range of indices is displayed:
Sorry, the list index is out of rangeHow to Handle a KeyError in Python
You have likely run into KeyError when working with Python dictionaries
▶ Consider this example where you have a dictionary my_dict.
my_dict ={"key1":"value1","key2":"value2","key3":"value3"}
search_key = "non-existent key"
print(my_dict[search_key])- The dictionary
my_dicthas 3 key-value pairs,"key1:value1","key2:value2", and"key3:value3" - Now, you try to tap into the dictionary and access the value corresponding to the key
"non-existent key".
As expected, you’ll get a KeyError:
---------------------------------------------------------------------------
KeyError Traceback (most recent call last)
<ipython-input-2-2a61d404be04> in <module>()
1 my_dict ={"key1":"value1","key2":"value2","key3":"value3"}
2 search_key = "non-existent key"
----> 3 my_dict[search_key]
KeyError: 'non-existent key'You can handle KeyError in almost the same way you handled IndexError.
- You can try accessing the value corresponding to the key specified by the
search_key. - If
search_keyis indeed a valid key, the corresponding value is printed out. - If you run into an exception because of a non-existent key, you use the
exceptblock to let the user know.
This is explained in the code snippet below:
try:
print(my_dict[search_key])
except KeyError:
print("Sorry, that's not a valid key!")Sorry, that's not a valid key!▶ If you want to provide additional context such as the name of the invalid key, you can do that too. It’s possible that the key was misspelled which made it invalid. In this case, letting the user know the key used will probably help them fix the typo.
You can do this by catching the invalid key as <error_msg> and use it in the message printed when the exception occurs:
try:
print(my_dict[search_key])
except KeyError as error_msg:
print(f"Sorry,{error_msg} is not a valid key!")▶ Notice how the name of the key is also printed out:
Sorry,'non-existent key' is not a valid key!How to Handle a FileNotFoundError in Python
Another common error that occurs when working with files in Python is the FileNotFoundError.
▶ In the following example, you’re trying to open the file my_file.txt by specifying its path to the function open(). And you’d like to read the file and print out the contents of the file.
However, you haven’t yet created the file in the specified location.
If you try running the code snippet below, you’ll get a FileNotFoundError:
my_file = open("/content/sample_data/my_file.txt")
contents = my_file.read()
print(contents)---------------------------------------------------------------------------
FileNotFoundError Traceback (most recent call last)
<ipython-input-4-4873cac1b11a> in <module>()
----> 1 my_file = open("my_file.txt")
FileNotFoundError: [Errno 2] No such file or directory: 'my_file.txt'And using try and except, you can do the following:
- Try opening the file in the
tryblock. - Handle
FileNotFoundErrorin theexceptblock by letting the user know that they tried to open a file that doesn’t exist. - If the
tryblock succeeds, and the file does exist, read and print out the contents of the file. - In the
finallyblock, close the file so that there’s no wastage of resources. Recall how the file will be closed regardless of what happens in the file opening and reading steps.
try:
my_file = open("/content/sample_data/my_file.txt")
except FileNotFoundError:
print(f"Sorry, the file does not exist")
else:
contents = my_file.read()
print(contents)
finally:
my_file.close()Notice how you’ve handled the error as an exception and the program ends gracefully displaying the message below:
Sorry, the file does not exist▶ Let’s consider the case in which the else block is triggered. The file my_file.txt is now present at the path mentioned earlier.
And here’s what the file my_file.txt contains:
Now, re-running the earlier code snippet works as expected.
This time, the file my_file.txt is present, the else block is triggered and its contents are printed out, as shown below:
I hope this clarifies how you can handle exceptions when working with files.
Conclusion
In this tutorial, you’ve learned how you can use try and except statements in Python to handle exceptions.
You coded examples to understand what types of exception may occur and how you can use except to catch the most common errors.
Hope you enjoyed this tutorial. Happy coding! Until next time
Learn to code for free. freeCodeCamp’s open source curriculum has helped more than 40,000 people get jobs as developers. Get started
Применение try except Python 3 — наиболее распространенный способ обработки ошибок. В этой статье мы познакомимся с лучшими практиками использования try except Python 3.
Используя блок try, можно перехватить исключение и обработать ошибку внутри блока except. Всякий раз, когда код дает сбой внутри блока try, выполнение программы останавливается, и управление передается блоку исключений.
- Для чего используются условия Try-Except Python / Try-Except-else?
- Выведение исключений
- Для чего используются исключения?
- Советы по использованию Try Except Python 3, Try-Except-Else и многое другое
- Как обрабатывать произвольное исключение
- Перехват нескольких исключений в одном блоке except
- Обработка нескольких исключений в одном блоке except
- Повторное выведение исключений в Python
- Когда использовать условие else
- Использование блока [finally]
- Используйте ключевое слово as для перехвата конкретных типов исключений
- Лучшие практики вывода исключений
- Как пропустить ошибки и продолжить выполнение кода
- Как использовать Try-Except в Python
С помощью try-except и try-except-else можно избежать многих проблем, которые могут возникнуть. Например, код Python, использующий стиль LBYL (Look before you leap), может привести к зацикливанию условий. В подобном случае поможет try-except.
Также бывают случаи, когда правильность выполнения кода зависит от актуальности данных. Например, код, вызывающий os.path.exists или Queue.full, может завершиться неудачно. Эти функции могут возвращать данные, которые устаревают к моменту их использования. Поэтому лучше использовать try-except-else.
В Python можно выводить исключение каждый раз, когда это необходимо. Это можно сделать, вызвав из кода [raise Exception (‘Test error!’)]. После чего исключение остановит текущее выполнение и перейдет дальше по стеку вызовов до тех пор, пока исключение не будет обработано.
Исключения также используются для управления ошибками, которые возникают в циклах, при работе с базой данных, доступе к сети и т.д.
Обработка исключений — это искусство, которое помогает в написании надежного и качественного кода.

Как в Python лучше всего использовать Try-Except
Иногда может понадобиться способ для обработки и вывода сообщения об ошибке. Это можно сделать с помощью исключений Python. Во время тестирования вы можете разместить код внутри блока try.
try:
#ваш код
except Exception as ex:
print(ex)
Можно перехватить несколько исключений в одном блоке except.
except (Exception1, Exception2) as e:
pass
Обратите внимание, что в Python 2.6 / 2.7 нужно отделить исключения от переменной запятой. Но этого нельзя делать в Python 3. Вместо этого необходимо использовать ключевое слово [as].
Существует множество способов обработки сразу нескольких исключений. Первый из них требует размещения всех исключений, которые могут возникнуть. Смотрите приведенный ниже код:
try:
file = open('input-file', 'open mode')
except EOFError as ex:
print("Caught the EOF error.")
raise ex
except IOError as e:
print("Caught the I/O error.")
raise ex
Последний метод — использовать исключение без упоминания какого-либо атрибута исключения.
try:
file = open('input-file', 'open mode')
except:
# In case of any unhandled error, throw it away
raise
Последний вариант может быть полезен, если у вас нет информации об исключении, которое может возникнуть.
Однажды выведенные исключения продолжают обрабатываться в вызывающих их методах до тех пор, пока они не будут обработаны. Но можно добавить условие except, которое содержит только вызов [raise] без каких-либо аргументов. Это приведет к повторному исключению.
Смотрите приведенный ниже код.
try:
# Намеренное выведение исключения.
raise Exception('I learn Python!')
except:
print("Entered in except.")
# Повторное выведение исключения.
raise
Вывод:
Entered in except. Traceback (most recent call last): File "python", line 3, in <module> Exception: I learn Python!
Используйте условие else после блока try-except. Оно будет выполняться в том случае, если исключение не будет выдано. Оператор else всегда должен предшествовать блокам except .
В блоках else можно добавить код, который необходимо запустить, если ошибок не возникло.
В приведенном ниже примере видно, что цикл while работает бесконечно. Код запрашивает значение у пользователя, а затем анализирует его с помощью встроенной функции [int()]. Если пользователь вводит нулевое значение, блок except будет заблокирован. В противном случае код будет проходить через блок else.
while True:
# Введете с консоли целое число.
x = int(input())
# Разделите 1 на x, чтобы протестировать ошибку
try:
result = 1 / x
except:
print("Error case")
exit(0)
else:
print("Pass case")
exit(1)
Если есть код, который должен выполняться во всех случаях, разместите его внутри блока [finally]. Python всегда будет запускать эти инструкции. Это самый распространенный способ выполнения задач очистки. Вы также можете проверить это.
Ошибка перехватывается условием try. После того, как будет выполнен код в блоке except, выполняется инструкции в [finally].
Смотрите приведенный ниже код.
try:
# Намеренно выводим ошибку.
x = 1 / 0
except:
# Условие Except:
print("Error occurred")
finally:
# Условие Finally:
print("The [finally clause] is hit")
Вывод:
Error occurred The [finally clause] is hit
С помощью <identifier> можно создать объект исключения. В приведенном ниже примере мы создаем объект IOError, а затем используем его внутри условия.
try:
# Намеренно выводим ошибку.
f = open("no-file")
except IOError as err:
# Создаем экземпляр IOError для учета.
print("Error:", err)
print("Code:", err.errno)
Вывод:
('Error:', IOError(2, 'No such file or directory'))
('Code:', 2)
Избегайте создания общих исключений, иначе конкретные exception также будут перехватываться. Лучшей практикой является отображение конкретного исключения, близкого к возникшей проблеме.
Не рекомендуется:
def bad_exception():
try:
raise ValueError('Intentional - do not want this to get caught')
raise Exception('Exception to be handled')
except Exception as error:
print('Inside the except block: ' + repr(error))
bad_exception()
Вывод:
Inside the except block: ValueError('Intentional - do not want this to get caught',)
Рекомендуется:
В приведенном ниже примере перехватывается конкретный тип исключения, а не общий. Мы также используем параметр args для вывода некорректных аргументов, если они есть. Рассмотрим этот пример.
try:
raise ValueError('Testing exceptions: The input is in incorrect order', 'one', 'two', 'four')
except ValueError as err:
print(err.args)
Вывод:
('Testing exceptions: The input is in incorrect order', 'one', 'two', 'four')
Лучше не применять данную практику. Но если это нужно, то используйте следующий пример.
try:
assert False
except AssertionError:
pass
print('Welcome to Prometheus!!!')
Вывод:
Рассмотрим наиболее распространенные исключения в Python с примерами.
Распространенные ошибки исключений:
- IOError–возникает, если файл не открывается.
- ImportError — если модуль python не может быть загружен или размещен.
- ValueError — возникает, если функция получает аргумент корректного типа, но с некорректным значением.
- KeyboardInterrupt — когда пользователь прерывает выполнение кода нажатием на Delили Ctrl-C.
- EOFError — когда функции input() / raw_input()достигают конца файла (EOF), но без чтения каких-либо данных.
Примеры распространенных исключений
except IOError:
print('Error occurred while opening the file.')
except ValueError:
print('Non-numeric input detected.')
except ImportError:
print('Unable to locate the module.')
except EOFError:
print('Identified EOF error.')
except KeyboardInterrupt:
print('Wrong keyboard input.')
except:
print('An error occurred.')
В процессе программирования ошибки неизбежны. Но их можно обработать, используя конструкции try-except или try-except-else, try-except-finally.