
Среднее квадратическое
отклонение
случайной величины
(сокращенно
с. к. о.). Это положительное значение
квадратного корня из ее дисперсии
![]()
где D
— дисперсия,
т. е. второй центральный момент случайной
величины, а р(х)
— плотность
распределения, Xц
– координата центра распределения..
Для определения оценки дисперсии по
экспериментальным данным пользуются
соотношением
![]()
где xi—значения
отдельных отсчетов; п—объем
выборки.
Отсюда оценка с.
к. о. определяется как

Основным достоинством
оценки разброса случайных величин
средним квадратическим значением
является возможность определения
дисперсии суммы статистически независимых
величин независимо от разнообразия
законов распределения каждой из
суммируемых величин и деформации законов
распределения при образовании композиций.
Таким образом для
того, чтобы отдельные составляющие
погрешности средств измерений можно
было суммировать расчётным путём, они
должны быть предварительно представлены
своими средними квадратическими
значениями ,
а не максимальными m
или доверительными д
значениями. При этом открывается
возможность расчётным путём не только
складывать любое число составляющих
погрешности, что необходимо при анализе
точности косвенных измерений или сложных
измерительных устройств, но и достаточно
точно вычитать погрешности, что необходимо
при синтезе методов измерений или
сложных устройств с заданной результирующей
погрешностью. Действительно, если
![]() ,
,
то![]() .
.
Это правомерно для независимых случайных
величин.
Из предыдущего
следует, что
![]() .
.
В случае сложения не двух, а большего
числа дисперсий или с.к.о. независимых
случайных величин закон сложения будет
таким же. Следует обратить внимание на
то, что как вы уже убедились, для нахождения
суммарной погрешности следует складывать
не сами погрешности, а их квадраты. В
том случае. Если мы складываем вероятности,
то закон сложения будет тем же.![]() .
.
Из закона сложения
погрешностей следуют два очень важных
вывода. Первый относится к роли каждой
из погрешностей в общей погрешности
результата. Он состоит в том, что значение
отдельных погрешностей очень быстро
падает по мере
их уменьшения.
Поясним сказанное примером: пусть X
и Y
— два слагаемых, определенных со средними
квадратическими погрешностями x
и y
, причем
известно, что y.
в два раза меньше, чем x.
Тогда погрешность суммы Z=X+Y
будет
![]()
Откуда
![]() .
.
Следовательно, если одна из погрешностей
в два раз меньше другой, то общая
погрешность возросла за счет этой
меньшей погрешности всего на 10%, что
обычно играет очень малую роль. Это
означает, что если мы хотим повысить
точность измерений величины Z,
то нам нужно в первую очередь стремиться
уменьшить ту погрешность измерения,
которая больше, т.е. погрешность измерения
величины X.
Если оставим точность измерения Х
неизменной, то, как бы мы ни повышали
точность измерения слагаемого Y,
нам не удастся уменьшить погрешность
конечного результата измерений величины
Z
более чем
на 10%.
Этот вывод всегда
нужно иметь в виду, и для повышения
точности измерений в первую очередь
уменьшать погрешность, имеющую наибольшее
значение. Конечно, если слагаемых много,
а не два, как в нашем примере, то и малые
погрешности могут внести заметный вклад
в суммарную погрешность.
Если нужная нам
величина Z;
является разностью двух независимо
измеряемых величин Х
и Y,
то из выражения для суммы с.к.о. следует,
что ее относительная погрешность
![]()
где X,
Y,
Z
– погрешности измерений величин X,
Y,
Z.
Очевидно, что она
будет тем больше, чем меньше
![]() ,
,
и относительная погрешность возрастает
до бесконечности, еслиX
стремиться к Y.
Это означает, что
невозможно добиться хорошей точности
определения какой-либо величины, строя
измерения так, что она находится как
небольшая разность результатов
независимых измерений двух величин,
существенно превышающих искомую. В
противоположность этому относительная
погрешность суммы
![]()
![]()
очевидно не зависит
от соотношения величин X
и Y.
Следующий вывод,
вытекающий из закона сложения погрешностей,
относится к определению погрешности
среднего арифметического. Следует
отметить, что среднее арифметическое
из ряда измерений числом n
отягощено меньшей погрешностью, чем
результат каждого отдельного измерения.
Запишем этот вывод в количественной
форме. Пусть x1,
x2,
xn
результаты отдельных измерений, причем
каждое из них характеризуется одной и
той же дисперсией D
. Образуем
величину Y
, равную
![]()
Дисперсии этой
величины Dy
определяются в соответствии с формулой
сложения дисперсий
![]() как
как
![]()
Но у
, по определению, это — среднее арифметическое
из всех величин xi
и мы можем написать
![]() (13)
(13)
Средняя квадратическая
погрешность среднего арифметического
равна средней квадратической погрешности
отдельного результата измерений,
деленной на корень квадратный из числа
измерений. Это — фундаментальный закон
возрастания точности при росте числа
наблюдений. Мы его уже обсуждали в
разделе 5.1. Из него следует, что, желая
повысить точность измерений в 2 раза,
мы должны сделать вместо одного — четыре
измерения; чтобы повысить точность в 3
раза, нужно увеличить число измерений
в 9 раз, и, наконец, увеличение числа
наблюдений в 100 раз приведет к десятикратному
увеличению точности измерений.
Разумеется, это
рассуждение относится лишь к измерениям,
при которых точность результата полностью
определяется случайной погрешностью.
В этих условиях, как уже указывалось,
выбрав n
достаточно большим, мы можем существенно
уменьшить погрешность результата. Такой
метод повышения точности широко
используется. Отметим, что повышение
точности измерений целесообразно
производить таким способом в том случае,
если погрешность измерительного средства
намного превышает цену деления шкалы
отсчёта. В этом случае погрешность можно
свести к значению цены деления. Очевидно,
что получить точность выше цены деления
не представляется возможным т.к. при
отсчёте показаний округления производятся
до целых делений шкалы. С помощью такого
приёма легко снизить погрешность от
вариации показаний.
При практической
работе очень важно строго разграничивать
применение средней квадратической
погрешности отдельного измерения i
и средней квадратической погрешности
среднего арифметического
![]()
Последняя применяется
всегда, когда нам нужно оценить погрешность
того значения, которое мы получили в
результате всех произведенных измерений.
В тех случаях,
когда мы
хотим
характеризовать точность применяемого
способа измерений, следует использовать
погрешность i
, если n,
достаточно велико.
Приведем примеры пользования результатами
таблицы. Пусть для некоторого ряда измерений получили ![]() =20,
=20,
σ =2. Какова вероятность того, что результат отдельного измерения не выйдет за
пределы, определяемые равенством 17 < хi < 23?
Доверительные границы равны ± 3, что составляет в долях σ -1,5. Из таблицы 3.1
находим, что доверительная вероятность для ε = 1,5 равна 0,87. Иначе говоря,
87% всех измерений уложится в интервал погрешности ± 3 .
Сформулируем вторую задачу, какой
доверительный интервал нужно выбрать для тех же измерений, чтобы 99% результатов
попала в него? По таблице 3.1 находим, что значению α =0,99 соответствует значение
ε =2.6, следовательно, доверительный искомый интервал равен Δх = ε*σ = 2,6*
2=5,2.
Таким образом, для нахождения случайной
погрешности нужно определи два числа — доверительный интервал /величину
погрешности/ и доверительную вероятность. Средней квадратичной погрешности σ
соответствует доверительная вероятность 0.68, удвоенной средней квадратичной
погрешности 2σ — доверительная вероятность 0.95; утроенной /Зσ/ — 0.997.
Приведенные три значения α полезно
запомнить, так как обычно в литературе дается значение средней квадратичной
погрешности и не указывается соответствующая ей доверительная вероятность.
Наряду со среднеквадратичной погрешностью
иногда используется погрешность среднеарифметическая, вычисляемая по формуле
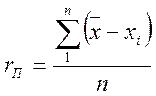 ;
; ![]()
При большом числе наблюдений rп
и SП существуют простые соотношения
SП =1.25 rП;
rП = 0.80 SП
Известным преимуществом средней
арифметической погрешности является сравнительно простой способ ее вычисления. Если
пользоваться средней арифметической погрешностью и при малой n, то правильнее
ее вычислять по соотношению
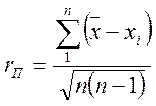
СЛОЖЕНИЕ
СЛУЧАЙНЫХ ПОГРЕШНОСТЕЙ
Предположим, что измеряемая величина Z
является суммой /или разностью/ двух величин Х и Y, результаты измерений
которых независимы. Тогда, если ![]() ,
,![]() —
—
дисперсия величин Х и Ү, то дисперсия измеряемой величины ![]() будет равна
будет равна
![]() =
=![]() +
+![]() или
или ![]() =
= ![]()
Если Z является суммой не двух, а
большего числа слагаемых — закон сложения погрешностей будет таким же.
Таким образом, средняя квадратичная
погрешность суммы /ила разности/ нескольких независимых величин равна корню квадратному,
из суммы дисперсий отдельных слагаемых. Необходимо твердо помнить, что для
нахождения суммарной погрешности нужно складывать не сами погрешности, а их квадраты
и извлечь квадратный корень.
Из закона сложения погрешностей следует
два важных вывода. Первый из них относится к роли каждой из погрешностей в
общей погрешности результата. Поясним сказанное на примере: пусть Х и Y два
слагаемых, определенных со средней квадратичной погрешностью ![]() и
и ![]() , причем
, причем
![]() в два раза меньше
в два раза меньше![]() .
.
Тогда ошибка суммы будет
![]() =
=![]() +
+![]() =
=![]() +
+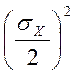 ;
;
![]()
Иначе говоря, если одна из ошибок в два
раза меньше другой, то общая погрешность возросла за счет меньшей из
погрешностей всего на 10%. Это означает, что если необходимо повысить точность
измерения величины Z, то нужно в первую очередь стремиться уменьшить ту
погрешность измерения, которая больше. Если оставить точность измерения Х
неизменной, то, как бы мы не повышали точность измерения Y, погрешность
конечного результата не удастся уменьшить более чем на 10%. Этот вывод нужно
иметь в виду и при повышении измерений в первую очередь уменьшать погрешность,
имеющую наибольшую величину.
Второй вывод, вытекающий из закона
сложения погрешностей, относится к определению погрешности среднего
арифметического. Среднее арифметическое оточено меньшей ошибкой, чем результат
каждого отдельного измерения. Покажем это. Пусть х1,х2,…,хn
— результаты отдельных измерений, каждое из которых характеризуется дисперсией
σ². Среднее арифметическое всех измерений можно представить в виде
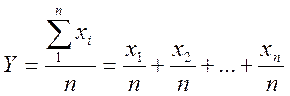
В соответствии с законом сложения
погрешностей дисперсию величины Y можно найти как
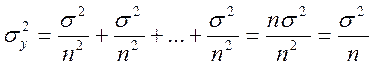
Но Y и есть среднее арифметическое из всех величин хi,
поэтому
Уважаемый посетитель!
Чтобы распечатать файл, скачайте его (в формате Word).
Ссылка на скачивание — внизу страницы.
Для применения закона сложения ошибок надо знать формулы, связывающие отдельные измеряемые величины и частные ошибки различных стадий процесса измерения. В дальнейшем мы будем исходить из предположения, что все измерения взаимно независимы (см. с. 42). [c.64]
Закон сложения ошибок [c.64]
Ошибку определения получают из уравнения (4.12) по закону сложения ошибок [уравнение (4.36)] [c.69]
Закон сложения ошибок. Для независимых случайных величин свойством аддитивности обладают дисперсии, а не среднеквадратичные ошибки. Если 1, Х2….. Хп — независимые случайные величины а, й2,. .., йп — неслучайные величины и [c.31]
Случайная ошибка метода анализа чаще всего складывается из нескольких частных ошибок. Для минимизации общей ошибки анализа надо найти оптимальные условия измерения. Этому способствуют законы сложения ошибок. Рассмотрение ошибок такого рода прежде всего сосредоточивается на возникающих ошибках измерений. Поэтому рассмотрение таких ошибок лишь в исключительных случаях может дать некоторые представления о точности аналитического метода, так как ошибки измерений обычно гораздо меньше, чем случайные колебания, например хода химических реакций. Тем не менее метод анализа может полностью проявить свои возможности только в том случае, когда ошибки измерений сведены к минимуму. [c.64]
Ниже описывается действие закона сложения ошибок при поиске наилучших условий измерения для нескольких типичных методов аналитической химии. [c.64]
Глава 4. Закон сложения ошибок [c.68]
Из уравнения (4.34) по закону сложения ошибок [уравнение (4.3а)] и с учетом (7 яа [уравнение (3.14)] получаем [c.78]
Пусть даны два средних Хх и Х2, которые получены из двух независимых друг от друга серий с Пх и пг измерениями. Средние слегка различаются. Надо проверить, можно ли объяснить это различие только случайной ошибкой, т. е. принадлежат ли оба средних нормально распределенной генеральной совокупности с одним и тем же средним р. Значит, проверяется гипотеза для данного параметрического критерия р = рз = Р- Перед ее проверкой надо выяснить, нет ли разницы между стандартными отклонениями обеих серий 1 и г (по Г-критерию, см. разд. 7.2). Если значимое различие между 1 и 2 не обнаруживается, то сначала по закону сложения ошибок находят стандартное отклонение для разности двух средних из пх и П2 измерений. Уравнения (4.3а) и (3.4) дают [c.121]
Общая ошибка метода анализа чаще всего складывается из ряда отдельных частных ошибок. Они суммируются по закону сложения ошибок (см. гл. 4). Знание этих частных ошибок важно, например, при разработке нового метода анализа, так как стоит улучшать ход анализа на наиболее ответственной стадии — там, где наибольшая ошибка. [c.140]
Если из двух взаимосвязанных (коррелированных) случайных величин х и у вычисляют третью 2 = [/(х у)], то в законе сложения ошибок надо дополнительно учесть еще и степень корреляции между хну. Для четырех основных действий арифметики — как обобщение уравнения (4.3) — получим следующие закономерности [c.162]
Дисперсии для констант а тл Ь можно искать с помощью закона сложения ошибок тогда получим [c.168]
Закон сложения ошибок. Для независимых случайных величин свойством аддитивности обладают дисперсии, а не среднеквадратичные [c.35]
Закон сложения ошибок. В химическом эксперименте искомая величина часто не может быть измерена непосредственно. Для ее определения используются различные математические выражения, в которых эта искомая величина является функцией других измеряемых в эксперименте величин. Таким образом, возникает вопрос о нахождении среднего значения функции и ее средней квадратичной ошибки, если известны средние значения и средние квадратичные ошибки аргументов. [c.229]
Формулы (17) и (18) известны в математической статистике под названием закона сложения ошибок. Они позволяют рассчитать ошибку функции, если известны ошибки аргументов при различных видах функциональной зависимости. [c.230]
I 4] ЗАКОН СЛОЖЕНИЯ ОШИБОК 53 [c.53]
ЗАКОН СЛОЖЕНИЯ ОШИБОК [c.55]
Закон сложения ошибок можно интерпретировать геометрически при помощи векторов, так как. это показано на рис. 7. В первом примере на рис. 7 между величинами X ш у нет линейной корреляционной связи (г у = 0). Из геометрического построения ясно видно, что в этом случае нет необходимости затрачивать усилия на з меньше-ние меньшей из двух компонентов, так как уменьшение [c.55]
Пользуясь законом сложения ошибок, можно получить формулу для подсчета ошибок воспроизводимости по текущим измерениям, состоящим из двух параллельных определений [101, 117, 121]. Допустим, что анализу подвергалось п различных по своему составу проб. Обозначим через d разность между двумя параллельными определениями тогда мы можем написать [c.56]
ЗАКОН СЛОЖЕНИЯ ОШИБОК 57 [c.57]
ЗАКОН СЛОЖЕНИЯ ОШИБОК 59 [c.59]
Здесь м общ — результирующая ошибка, и 1 — ошибки отдельных операций. При этом безразлично, какие из случайных ошибок суммируются формула (118) написана для коэффициента вариации йУ, совершенно так н<е суммируются средние квадратичные ошибки а пли средние арифметические ошибки г. Из закона сложения ошибок следует важное правило существенный вклад вносят только те ошибки, которые близки к наибольшей из ошибок. Поясним сказанное численным примером. Допустим, что ошибка измерения интенсивности составляет 1%, ошибка, вносимая источником возбуждения, 3% и ошибка, вносимая неоднородностью проб, 0,5%. Тогда суммарная ошибка будет н, общ = V 9 1 0,25 = = 3,2%. Практически эта величина не отличается от 3%. Поэтому нет никакого смысла для повышения точности стараться уменьшить ошибку измерения интенсивности или неоднородности проб, пока не уменьшена ошибка, вносимая генератором. В разных случаях анализа ошибки различных звеньев процесса играют определяющую роль. При анализе руд обычно так велики неоднородности проб, что нет смысла прибегать к точным методам регистрации спектров. При анализе сплавов именно измерительное звено часто играет решающую роль. Воспроизводимость и точность тех или иных методов анализа будут приведены в соответствующих разделах. Здесь ограничимся только указанием, что лучшие методы количественного анализа позволяют делать определения с коэффициентом вариации до 0,1%. Обычно нри количественных анализах его значение лежит в пределах 1—10%. При определениях вблизи границы чувствительности метода ю быстро возрастает. [c.164]
Из закона сложения ошибок следует, что существенное влияние на величину Отобщ оказывают наибольшие из ошибок. [c.195]
По закону сложения ошибок средняя квадратичная ошибка суммы независимых величин равна корню квадратному из суммы дисперсий отдельных слагаемых, т. е. ошибка определения содержания Н3РО4 в пробе — Sxi равна [c.85]
Статистика в аналитической химии (1994) — [
c.64
]
Применение математической статистики при анализе вещества (1960) — [
c.53
,
c.60
]
Слайд 1ОСНОВЫ ТЕОРИИ ОШИБОК ИЗМЕРЕНИЙ
Измерением какой-либо физической величины называется операция, в
результате которой мы узнаем, во сколько раз измеряемая величина больше (или меньше) соответствующей величины, принятой за единицу
Виды измерений и погрешностей

Слайд 2Виды измерений классифицируются:
– по способу получения результата (прямые и косвенные);
– по
методу измерений (абсолютные, относительные и пороговые);
– по условиям измерений (равноточные, неравноточные);
– по степени достаточности измерений (необходимые, избыточные)
;– по методу")
Слайд 3 При прямых измерениях измеряется непосредственно исследуемая величина
При косвенных измерениях
исследуемая величина измеряется как функция по результатам измерения других величин
Например, ускорение автомобиля при разгоне определяется по результатам измерения расстояния и времени разгона; вычисление плотности – по массе и объему

Слайд 4 Абсолютные измерения – это прямые измерения в единицах измеряемой величины
Относительные измерения представляют собой отношения измеряемой величины к величине играющей роль единицы или к величине, принимаемой за исходную
При пороговых измерениях фиксируется только факт нахождения величины в одностороннем или двухстороннем допуске
(по принципу «да/нет»)

Слайд 5Равноточные измерения проводятся в одинаковых условиях одними и теми же измерительными
приборами и с одинаковой степенью тщательности.
При этом в ряду измерений нельзя отдать предпочтение какому-либо одному или нескольким значениям
Неравноточные измерения не отвечают указанным выше требованиям

Слайд 6Избыточные измерения имеют по сравнению с необходимыми большее число измерений либо
большую точность, содержат среди измерений зависимые, т. е. дают избыточную информацию
Надежность результатов исследования в значительной степени зависит от точности измерений
Под точностью измерений понимают степень соответствия результата измерения действительному значению измеряемой величины

Слайд 7Снять показания с прибора – не значит только измерить. Необходимо еще
оценить ошибки (погрешности) измерений
Погрешность измерения – это отклонение результата измерения от истинного значения измеряемой величины

Слайд 8Под истинным значением измеряемой величины принято считать
– среднюю арифметическую величину
ряда измерений;
– известное эталонное значение;
– величину, полученную в результате более точных (не менее чем на порядок) измерений

Слайд 9Основные источники ошибок
Первый источник заключен в датчике, который неправильно реагирует
на измеряемую величину.
Например, если тензосопротивление плохо наклеено на упругий элемент, то деформация его решетки не будет соответствовать деформации упругого элемента
Второй источник – измерительное устройство, в котором возможны погрешности из-за неправильного функционирования его механических или электрических элементов

Слайд 10Третий источник – сам наблюдатель, который из-за неопытности или усталости неправильно
считывает показания прибора
Ошибки могут возникнуть из-за влияния измерительного устройства на объект измерения (например, при разрушающем методе контроля), влияния окружающей среды (температура, загазованность и т. п.), методических погрешностей, допущенных экспериментатором

Слайд 11Случайная погрешность – это погрешность, которая в отдельных измерениях может принимать
случайные, заранее конкретно неизвестные значения.
Случайные погрешности обязаны своим происхождением ряду как объективных, так и субъективных факторов, действие которых неодинаково в каждом опыте и не может быть учтено.
Эти источники ошибок приводят к появлению трех типов ошибок: случайных, систематических и грубых

Слайд 12Случайные погрешности различаются в отдельных измерениях, сделанных в одинаковых условиях одними
и теми же измерительными приборами. Исключить случайные погрешности нельзя. Можно только оценить их значение
Случайные погрешности определяются по законам теории ошибок, основанной на теории вероятностей

Слайд 13Систематическая погрешность – это погрешность, вызванная факторами, действующими одинаковым образом при
многократном повторении одних и тех же измерений с помощью одних и тех же измерительных приборов
В качестве примера систематической ошибки рассмотрим случай взвешивания на чашечных весах с помощью неточных гирь. Если взятая нами гиря имеет ошибку, скажем 0,1 г, то вес тела (пусть 1000 г) будет завышенным (или заниженным) на эту величину, и чтобы получить верное значение, необходимо учесть эту ошибку, прибавив к полученному весу (или вычтя из него) 0,1 г, P=(1000±0,1) г

Слайд 14Грубая погрешность или промах вызывается просчетом экспериментатора или неисправностью средств измерения,
или резко изменившимися внешними условиями
Грубые погрешности приводят к явному искажению результата, поэтому их надо исключить из общего числа измерений

Слайд 15Абсолютная погрешность – это разность между результатом измерения и его истинным
значением:
где x – результат измерения; a – истинное значение
По форме числового представления погрешности делятся на абсолютные и относительные
Относительная погрешность – это погрешность, приходящаяся на единицу измеренной величины; обычно выражается в процентах

Слайд 16 Чтобы выявить случайную погрешность измерений, необходимо повторить измерение несколько
раз
Случайные погрешности и их распределение
Если каждое измерение дает заметные от других результаты, мы имеем дело с ситуацией, когда случайная погрешность играет существенную роль

Слайд 17 Наиболее вероятным значением измеряемой величины из серии измерений является
ее среднее значение
Разброс измеряемой величины относительно ее среднего значения определяется величиной средней квадратической погрешности отдельного измерения

Слайд 18Абсолютные погрешности
рассматривают как случайные величины
Пусть в эксперименте в результате независимых и равноточных измерений постоянной величины получены значения х1, х2, …, хn
Независимость измерений понимается как взаимная независимость случайных величин , а равноточность – как подчинение величин одному и тому же закону распределения (кроме того измерения сделаны одним и тем же методом и с одинаковой степенью тщательности)

Слайд 19 В качестве оценки неизвестной величины по данным
измерений обычно берут среднее арифметическое результатов измерений
Дисперсия отдельных измерений
обычно неизвестна, и для ее оценки используется величина

Слайд 20
Среднюю квадратическую (стандартную) погрешность (СКО) находятся по формуле
Величина
для ее
оценки вычисляется величина
называется коэффициентом вариации
Обычно принимается, что погрешности подчиняются нормальному закону распределения случайных величин
 погрешность (СКО) находятся по формуле Величина для ее оценки")
Слайд 21При этом предполагается:
2) при большом числе наблюдений погрешности равных значений,
но разных знаков встречаются одинаково часто;
1) погрешности измерений могут принимать непрерывный ряд значений;
3) частота появления погрешностей уменьшается с увеличением величин погрешностей
 при большом числе наблюдений погрешности равных значений, но")
Слайд 22Эти предположения приводят к закону распределения погрешностей, описываемому формулой Гаусса:
Форма
кривых Гаусса зависит от величин .
Чем больше , тем больше рассеивание случайной погрешности

Слайд 23Известно, что под кривой распределения в пределах по оси абсцисс от
до заключено 68,3% всей площади; в пределах от
–2 до +2 – 95,5%, в пределах от –3 до +3 – 99,7%

Слайд 24Известно, что под кривой распределения в пределах по оси абсцисс от
до заключено 68,3% всей площади; в пределах от
–2 до +2 – 95,5%, в пределах от –3 до +3 – 99,7%

Слайд 25Замечание. В ряде случаев экспериментальные данные лучше описываются другими законами распределения
случайных величин, например, законом Пуассона:

Слайд 26 Пусть измеряемая величина Z является суммой (или разностью) двух
величин X и Y, результаты измерений которых независимы.
Закон сложения случайных ошибок
Тогда можно доказать, что
если , , – дисперсии величин, или
 двух величин X")
Слайд 27
Если Z является суммой не двух, а большего числа слагаемых, то
закон сложения ошибок будет таким же, т. е. средняя квадратичная ошибка суммы или разности двух (или нескольких) независимых величин равна корню квадратному из суммы дисперсий отдельных слагаемых
Для нахождения суммарной ошибки нужно складывать не сами ошибки, а их квадраты

Слайд 28Средняя квадратичная ошибка суммы или разности двух (или нескольких) независимых величин
равна корню квадратному из суммы дисперсий отдельных слагаемых
 независимых величин равна")
Слайд 29Необходимо учитывать роль каждой из ошибок в общей ошибке результата.
Значение отдельных ошибок очень быстро падает по мере их уменьшения.
Выводы:
В первую очередь стоит уменьшать ошибку, имеющую наибольшую величину
Относительная погрешность суммы

Слайд 30
Пример: пусть X и Y – два слагаемых, определенных со средними
квадратичными ошибками и , причем, известно, что В два раза меньше, чем . Тогда ошибка суммы будет

Слайд 312. Средняя квадратическая погрешность среднего арифметического равна средней квадратической погрешности отдельного
результата, деленная на корень квадратный из числа измерений:
– средняя квадратичная погрешность отдельного измерения

Слайд 32 Пусть измеряемая величина Z является разностью двух величин X
и Y, результаты измерений которых независимы.
Тогда ее относительная погрешность

Слайд 33Невозможно добиться хорошей точности измерений какой-либо величины, строя измерения так, что
она находится как небольшая разность результатов независимых измерений двух величин, существенно превышающих искомую

Слайд 36Необходимо учитывать роль каждой из ошибок в общей ошибке результата.
Значение отдельных ошибок очень быстро падает по мере их уменьшения.
Доверительный интервал и доверительная вероятность
Тогда можно доказать, что
если , , – дисперсии величин, или
Средняя квадратичная ошибка суммы или разности двух (или нескольких) независимых величин равна корню квадратному из суммы дисперсий отдельных слагаемых

Слайд 37Необходимо учитывать роль каждой из ошибок в общей ошибке результата.
Значение отдельных ошибок очень быстро падает по мере их уменьшения.
Доверительный интервал и доверительная вероятность
Тогда можно доказать, что
если , , – дисперсии величин, или
Средняя квадратичная ошибка суммы или разности двух (или нескольких) независимых величин равна корню квадратному из суммы дисперсий отдельных слагаемых

Слайд 38где 2n – количество опытов, образующих полный факторный эксперимент; 2n –
число так называемых «звездных» точек в факторном пространстве, имеющих координаты (±α, 0, 0, …, 0);
(0, ±α, 0, …, 0), …, (0, 0, …, ±α). Здесь величина α называется «звездным» плечом; 1 – опыт в центре планирования, т. е. в точке факторного пространства с координатами (0, 0, …, 0)
Значения «звездного» плеча α для ЦКП с различным числом факторов n следующие:
Количество опытов при ортогональном ЦКП определяется по формуле
Эти значения α выбраны из условия ортогональности матрицы планирования

Слайд 41 Если поверхность отклика не может быть описана многочленом вида
Закон сложения случайных ошибок
для адекватного математического описания используется многочлен более высокой степени, например, отрезок ряда Тейлора, содержащий члены с квадратами переменных. Тогда используют центральное композиционное планирование (ЦКП) эксперимента.
Различают два вида ЦКП:
ортогональное и
ротатабельное

Слайд 42где 2n – количество опытов, образующих полный факторный эксперимент; 2n –
число так называемых «звездных» точек в факторном пространстве, имеющих координаты (±α, 0, 0, …, 0);
(0, ±α, 0, …, 0), …, (0, 0, …, ±α). Здесь величина α называется «звездным» плечом; 1 – опыт в центре планирования, т. е. в точке факторного пространства с координатами (0, 0, …, 0)
Значения «звездного» плеча α для ЦКП с различным числом факторов n следующие:
Количество опытов при ортогональном ЦКП определяется по формуле
Эти значения α выбраны из условия ортогональности матрицы планирования

Слайд 43Переменные величины
здесь j – номер опыта; i – номер фактора,
введены для того, чтобы матрица планирования была ортогональна и коэффициенты регрессии определялись независимо друг от друга по результатам опытов. Чтобы получить уравнение регрессии в обычной форме
Уравнение регрессии при ортогональном ЦКП ищут в следующем виде
находят величину

Слайд 44Это план 2-ого порядка после преобразований (*)
Эти преобразования позволяют усреднить случайные
погрешности
Ортогональный план
Ортогональный план 2-ого порядка
Тогда уравнение регрессии
В итоге уравнение регрессии преобразуется к виду
Эти преобразования позволяют усреднить случайные погрешностиОртогональный")
Слайд 45где i ≠ 0
Коэффициенты регрессии при ортогональном ЦКП считают по
следующим формулам
где i ≠ k

Слайд 46где i ≠ 0
Для расчета оценок дисперсий в определении коэфф-тов
регрессии используют следующие выражения
Коэффициент bi, считается значимым, если . Аналогично проверяется значимость остальных коэфф-тов регрессии. Проверка адекватности уравнения регрессии осуществляется с помощью критерия Фишера
где i ≠ k

Слайд 47 Метод ротатабельного планирования эксперимента позволяет получать более точное математическое
описание поверхности отклика по сравнению с ортогональным ЦКП, что достигается благодаря увеличению числа опытов в центре плана и специальному выбору величины «звездного» плеча α.
Метод ротатабельного центрального композиционного планирования
Это план, у которого точки плана располагаются на окружностях (сферах, гиперсферах)
Точность оценивания функции отклика по любому направлению факторного пространства (для всех точек плана) одинаковая, что позволяет наилучшим образом извлечь максимальное количество (несмещенной) информации из плана

Слайд 48Ротабельный план 2-ого порядка
Для того, что бы привести план
2-ого порядка к ротатабельному, величину плеча выбирают из условия

Слайд 49 При ротатабельном ЦКП для вычисления коэффициентов регрессии и соответствующих
оценок дисперсий находят следующие константы
где n – число факторов; N – общее число опытов ротатабельного ЦКП; N0 – число опытов в центре плана
На основании результатов эксперимента вычисляют след. суммы
(где i=1,2,…,n),
(где i ≠ k),
(где i=1,…, n)

Слайд 50
Формулы для расчета коэффициентов регрессии имеют следующий вид
где i ≠

Слайд 51
Оценки дисперсий в определении коэфф-тов регрессии вычисляют по следующим формулам
Коэффициент
bi, считается значимым, если . Аналогично проверяется значимость остальных коэфф-тов регрессии
(где i=1,2,…,n)
(где i≠k)

Слайд 52
Оценку дисперсии адекватности рассчитывают по формуле
С ней связано число степеней
свободы
Проверку адекватности уравнения регрессии осуществляют с помощью критерия Фишера

Слайд 53
Пример. Рассмотреть ротатабельное ЦКП для двух факторов. Матрица планирования и результаты
эксперимента приведены в таблице
Матрица планирования и результаты эксперимента

Слайд 54Для нахождения коэффициентов регрессии вычислим следующие вспомогательные коэффициенты
На основании результатов
опытов вычислим вспомогательные суммы
Коэффициенты регрессии рассчитываем по формулам

Слайд 56Оценку дисперсии воспроизводимости можно найти на основании результатов опытов, проведенных в
центре плана
Эта величина найдена при числе степеней свободы
Оценки дисперсий в определении коэфф. регрессии

Слайд 57Пользуясь таблицей значений критерия Стьюдента, находим
для
и
Для проверки значимости коэффициентов регрессии рассмотрим соотнош.
Все коэффициенты регрессии значимы. Вычисляем оценку дисперсии адекватности

Слайд 58Число степеней свободы, связанных с этой оценкой дисперсии
Расчетное значение критерия
Фишера
Из таблицы значений критерия Фишера соответствующее значение критерия . Условие выполнено, следовательно, уравнение регрессии
адекватно представленным результатам эксперимента
Перейдем в уравнение регрессии от кодированных переменных к физическим
Пусть в нашем примере кодированные переменные X1 и X2 представляют собой температуру и концентрацию, причем координаты центра плана
x01= 60°С и x02= 30%, а шаги варьирования Δx1= 5°С и Δх2= 1% . Тогда

Слайд 59Подставляя их в полученное в этом примере уравнение регрессии, преобразуем его
к виду
Пользуясь таким уравнением, исследователь избавляется от необходимости переводить всякий раз условия опыта в кодированные переменные

Слайд 60Планирование активного эксперимента
При планировании экспериментов чаще всего применяются планы 1-ого и
2-ого порядков. Планы более высоких порядков применяются редко из-за их большой вычислительной сложности
Планы 1-ого порядка – это планы, которые позволяют провести эксперимент для отыскания уравнения регрессии, содержащее только первые степени факторов и их произведения
Планы 2-ого порядка – это планы, которые позволяют провести эксперимент для отыскания уравнения регрессии, содержащие вторые степени факторов

Слайд 61Планирование первого порядка
В качестве факторов выбираются только контролируемые и управляемые факторы
(переменные)
Обеспечивается возможность независимого изменения каждого из факторов и поддержание его на определенном уровне
Для каждого фактора указывается интервал (+/-), в пределах которого ставится исследование
Обеспечивается")
Слайд 62Представления плана эксперимента
(на примере эксперимента с 3-мя независимыми факторами)
Табличное (матричное) представление
Геометрическое
представление
Уравнением регрессии
b0, b1, b2, b3 – коэффициенты регрессии
xi*xu – члены двойного взаимодействия
x1*x2*x3 – члены тройного взаимодействия
Табличное (матричное) представлениеГеометрическое")
Слайд 63Свойства матрицы представления эксперимента
1. Свойство симметричности – алгебраическая сумма элементов вектор-столбца
каждого фактора равна нулю (за исключением столбца, соответствующего свободному члену)
2. Свойство нормирования – сумма квадратов каждого столбца равна числу опытов
3. Свойство ортогональности – скалярное произведение всех вектор-столбцов (сумма почленных произведений элементов любых вектор столбцов) равно нулю
i = номер фактора, j – номер опыта

Слайд 64Определение коэффициентов b уравнения регрессии
По свойствам матрицы планирования
Методом наименьших квадратов находятся
оценки b коэффициентов
Получаем

Слайд 65Планирование второго порядка
Применяется если описание функции отклика первым порядком получается недостаточным
(например, процесс носит нелинейный характер)
Каждый фактор варьируется не менее чем на трех уровнях – полный эксперимент содержит 3^k (k – количество факторов) опытов.
План 2-ого порядка при k=2 n=1
Опыты проводятся
В «крайних точках» — как в планировании 1-ого порядка
В «звездных точках» — xi=(+/-)a, xj=0, 1,…,n; 1,…,n; i!=j
В «центре» — xi=0, j=1,2,3,…,n
Уравнение регрессии для эксперимента с 2-мя факторами

Закон сложения ошибок
Все мы ошибаемся. Мы люди. Но иногда мы совершаем глупые мелкие оплошности просто от недостатка внимания — и дорого расплачиваемся за них в дальнейшем. Первая ошибка влечет за собой вторую, затем следующую… а пять ошибок подряд могут сбить с пути истинного, и вернуться на него уже не удастся. Гении знают о Законе сложения ошибок и много работают над тем, чтобы избежать этой ловушки.
Мы, возможно, никогда не узнаем в точности, что делает гения гением, откуда берутся в человеке необычайная творческая мощь и изобретательность, почему одни люди используют свои творческие возможности чаще, чем другие, или почему некоторые люди в определенный период своей жизни проявляют особую творческую активность. Моцарт написал свои лучшие вещи в юности, тогда как другой музыкальный гений — Людвиг ван Бетховен — создал главные свои шедевры ближе к концу жизни. Кроме того, существуют гении, которые в течение всей жизни демонстрируют исключительные результаты, подобно Стиву Джобсу или Стивену Спилбергу. Никакой системы здесь не просматривается. Но даже если ответы на эти вопросы навсегда останутся для нас загадкой, одно очень важное утверждение мы смело можем сделать: нельзя назвать точный набор ингредиентов гения. Гений имеет сложный состав, хотя следует, конечно, обратить внимание на некоторые тенденции. Так, спагетти можно приготовить бесконечным числом способов путем комбинирования обычных ингредиентов; все равно получатся спагетти. (Надо сказать, что не все спагетти одинаковы на вкус, точно так же как вклад Моцарта в копилку общества — то, что вышло из его «кухни» — совершенно не похож на вклад Эйнштейна.) Так что рецепт гениальности весьма неточен, но это и хорошо: дверь открыта для каждого, кто готов работать над общими характеристиками (обычными ингредиентами) гения. Это сортировка и анализ данных, желание экспериментировать и нестандартно смотреть на вещи, работа воображения и творческий подход, хранение в памяти большого количества хорошо организованной информации, отвага, необходимая, чтобы выступать с новыми идеями, отвергающими здравый смысл, готовность ломать устоявшиеся каноны и срывать покровы. Мы перечислили те самые шесть умений, которые вы сможете приобрести при помощи этой книги. Еще раз: можно ли научить свой мозг работать подобно мозгу гения? Да!
Я должен также добавить, что каждый из нас обладает способностями, позволяющими достичь вершин во всех перечисленных областях. Это не врожденные способности немногих избранных. Может быть, вы считаете, что ваше воображение не особенно богато, а творческое начало слабо развито. А может быть, уверены, что слова «изобретатель» и «первопроходец» не годятся для описания вас и ваших способностей. Моя задача при написании этой книги состояла отчасти в том, чтобы доказать вам: эти навыки можно развить, независимо от того, велики или малы соответствующие врожденные таланты. Не принимайте ничего за чистую монету и ни в коем случае не ограничивайте себя жесткими рамками. Будьте всегда открыты новым возможностям.
Для применения закона сложения ошибок надо знать формулы, связывающие отдельные измеряемые величины и частные ошибки различных стадий процесса измерения. В дальнейшем мы будем исходить из предположения, что все измерения взаимно независимы (см. с. 42). [c.64]
Закон сложения ошибок [c.64]
Ошибку определения получают из уравнения (4.12) по закону сложения ошибок [уравнение (4.36)] [c.69]
Закон сложения ошибок. Для независимых случайных величин свойством аддитивности обладают дисперсии, а не среднеквадратичные ошибки. Если 1, Х2….. Хп — независимые случайные величины а, й2,. .., йп — неслучайные величины и [c.31]
Случайная ошибка метода анализа чаще всего складывается из нескольких частных ошибок. Для минимизации общей ошибки анализа надо найти оптимальные условия измерения. Этому способствуют законы сложения ошибок. Рассмотрение ошибок такого рода прежде всего сосредоточивается на возникающих ошибках измерений. Поэтому рассмотрение таких ошибок лишь в исключительных случаях может дать некоторые представления о точности аналитического метода, так как ошибки измерений обычно гораздо меньше, чем случайные колебания, например хода химических реакций. Тем не менее метод анализа может полностью проявить свои возможности только в том случае, когда ошибки измерений сведены к минимуму. [c.64]
Ниже описывается действие закона сложения ошибок при поиске наилучших условий измерения для нескольких типичных методов аналитической химии. [c.64]
Глава 4. Закон сложения ошибок [c.68]
Из уравнения (4.34) по закону сложения ошибок [уравнение (4.3а)] и с учетом (7 яа [уравнение (3.14)] получаем [c.78]
Пусть даны два средних Хх и Х2, которые получены из двух независимых друг от друга серий с Пх и пг измерениями. Средние слегка различаются. Надо проверить, можно ли объяснить это различие только случайной ошибкой, т. е. принадлежат ли оба средних нормально распределенной генеральной совокупности с одним и тем же средним р. Значит, проверяется гипотеза для данного параметрического критерия р = рз = Р- Перед ее проверкой надо выяснить, нет ли разницы между стандартными отклонениями обеих серий 1 и г (по Г-критерию, см. разд. 7.2). Если значимое различие между 1 и 2 не обнаруживается, то сначала по закону сложения ошибок находят стандартное отклонение для разности двух средних из пх и П2 измерений. Уравнения (4.3а) и (3.4) дают [c.121]
Общая ошибка метода анализа чаще всего складывается из ряда отдельных частных ошибок. Они суммируются по закону сложения ошибок (см. гл. 4). Знание этих частных ошибок важно, например, при разработке нового метода анализа, так как стоит улучшать ход анализа на наиболее ответственной стадии — там, где наибольшая ошибка. [c.140]
Если из двух взаимосвязанных (коррелированных) случайных величин х и у вычисляют третью 2 = [/(х у)], то в законе сложения ошибок надо дополнительно учесть еще и степень корреляции между хну. Для четырех основных действий арифметики — как обобщение уравнения (4.3) — получим следующие закономерности [c.162]
Дисперсии для констант а тл Ь можно искать с помощью закона сложения ошибок тогда получим [c.168]
Закон сложения ошибок. Для независимых случайных величин свойством аддитивности обладают дисперсии, а не среднеквадратичные [c.35]
Закон сложения ошибок. В химическом эксперименте искомая величина часто не может быть измерена непосредственно. Для ее определения используются различные математические выражения, в которых эта искомая величина является функцией других измеряемых в эксперименте величин. Таким образом, возникает вопрос о нахождении среднего значения функции и ее средней квадратичной ошибки, если известны средние значения и средние квадратичные ошибки аргументов. [c.229]
Формулы (17) и (18) известны в математической статистике под названием закона сложения ошибок. Они позволяют рассчитать ошибку функции, если известны ошибки аргументов при различных видах функциональной зависимости. [c.230]
I 4] ЗАКОН СЛОЖЕНИЯ ОШИБОК 53 [c.53]
ЗАКОН СЛОЖЕНИЯ ОШИБОК [c.55]
Закон сложения ошибок можно интерпретировать геометрически при помощи векторов, так как. это показано на рис. 7. В первом примере на рис. 7 между величинами X ш у нет линейной корреляционной связи (г у = 0). Из геометрического построения ясно видно, что в этом случае нет необходимости затрачивать усилия на з меньше-ние меньшей из двух компонентов, так как уменьшение [c.55]
Пользуясь законом сложения ошибок, можно получить формулу для подсчета ошибок воспроизводимости по текущим измерениям, состоящим из двух параллельных определений [101, 117, 121]. Допустим, что анализу подвергалось п различных по своему составу проб. Обозначим через d разность между двумя параллельными определениями тогда мы можем написать [c.56]
ЗАКОН СЛОЖЕНИЯ ОШИБОК 57 [c.57]
ЗАКОН СЛОЖЕНИЯ ОШИБОК 59 [c.59]
Здесь м общ — результирующая ошибка, и 1 — ошибки отдельных операций. При этом безразлично, какие из случайных ошибок суммируются формула (118) написана для коэффициента вариации йУ, совершенно так н<е суммируются средние квадратичные ошибки а пли средние арифметические ошибки г. Из закона сложения ошибок следует важное правило существенный вклад вносят только те ошибки, которые близки к наибольшей из ошибок. Поясним сказанное численным примером. Допустим, что ошибка измерения интенсивности составляет 1%, ошибка, вносимая источником возбуждения, 3% и ошибка, вносимая неоднородностью проб, 0,5%. Тогда суммарная ошибка будет н, общ = V 9 1 0,25 = = 3,2%. Практически эта величина не отличается от 3%. Поэтому нет никакого смысла для повышения точности стараться уменьшить ошибку измерения интенсивности или неоднородности проб, пока не уменьшена ошибка, вносимая генератором. В разных случаях анализа ошибки различных звеньев процесса играют определяющую роль. При анализе руд обычно так велики неоднородности проб, что нет смысла прибегать к точным методам регистрации спектров. При анализе сплавов именно измерительное звено часто играет решающую роль. Воспроизводимость и точность тех или иных методов анализа будут приведены в соответствующих разделах. Здесь ограничимся только указанием, что лучшие методы количественного анализа позволяют делать определения с коэффициентом вариации до 0,1%. Обычно нри количественных анализах его значение лежит в пределах 1—10%. При определениях вблизи границы чувствительности метода ю быстро возрастает. [c.164]
Из закона сложения ошибок следует, что существенное влияние на величину Отобщ оказывают наибольшие из ошибок. [c.195]
По закону сложения ошибок средняя квадратичная ошибка суммы независимых величин равна корню квадратному из суммы дисперсий отдельных слагаемых, т. е. ошибка определения содержания Н3РО4 в пробе — Sxi равна [c.85]
Статистика в аналитической химии (1994) — [
c.64
]
Применение математической статистики при анализе вещества (1960) — [
c.53
,
c.60
]
Министерство образования и науки Российской Федерации Ярославский государственный университет
им. П. Г. Демидова
В.П. Алексеев, Е. О. Неменко,
В.А. Папорков, Е. В. Рыбникова
Лабораторная работа № 1
Статистическая обработка результатов прямых измерений
Ярославль 2013
Лабораторная работа № 1.
Статистическая обработка результатов прямых измерений
Цель работы:
1)изучить теорию статистической обработки результатов прямых измерений;
2)определить доверительный интервал методом среднего арифметического и статистическим способом по заданному набору значений измеряемой величины с учётом обусловленной доверительной вероятности.
1.1. Краткая теория
1.1.1. О точности и ошибках измерений
Под точностью измерений понимают качество измерения, отражающее близость его результата к действительному значению измеряемой величины. Она определяется той наименьшей долей единицы измеряемой величины, до которой с уверенностью в правильности результата можно вести измерения. Приближенный характер измерения заключается в том, что измерение не может быть абсолютно точным, а только в той или иной мере приближается к истинному значению измеряемой величины.
Абсолютно точное (истинное) значение физической величины X0 является идеализацией. Ис-
тинное значение величины надо рассматривать лишь как значение, идеально отображающее в качественном и количественном отношениях соответствующее свойство данного физического объекта. Оно является пределом, к которому приближается значение физической величины с повышением точности измерения.
Для практического же использования вводится понятие действительного значения величины Xi,
под которым понимается значение, определенное экспериментально — с помощью средств измерения — и приближающееся к истинному значению в такой мере, что для данной конкретной цели оно может быть принято вместо истинного значения.
В науке идет постоянная борьба за точность, т. к. каждый знак после запятой может скрывать новый физический эффект.
К примеру, в начале метр определялся как 1/40000000 часть окружности земного шара по Па-
рижскому меридиану. В 1889 г. был изготовлен точный международный эталон метра из сплава платины и иридия и имел поперечное сечение в виде буквы ¾X¿. Его копии были переданы на хранение в страны, в которых метр был признан в качестве стандартной единицы длины. Этот эталон всё ещё хранится в Международном бюро мер и весов как музейный экспонат, хотя больше по своему первоначальному назначению не используется. С 1960 г. было решено отказаться от использования изготовленного людьми предмета в качестве эталона метра, и с этого времени по 1983
˚
г. метр определялся как число 1 650 763,73, умноженное на длину волны оранжевой линии (6056 A) спектра, излучаемого изотопом криптона 86Kr в вакууме. С 1983 г. за эталон метра принята длина отрезка, который свет проходит в вакууме за 1/299792458 долю секунды. Скорость света в вакууме очень точно измерена и равна c = 299792458 м/с. Это одна из фундаментальных физических
констант.
1

1.1.2. Типы погрешностей измерений
Значения физических величин находят опытным путем, поэтому они все содержат погрешность измерений. Поскольку никакие измерения не могут быть выполнены абсолютно точно, их результаты всегда содержат некоторую ошибку X. Поэтому в задачу измерений входит не только нахож-
дение максимально точного значения величины, а определение интервала, в котором оно лежит, и вероятности, с которой результаты измерений в него укладываются.
|
Абсолютная погрешность |
||||
|
Каждое измерение дает значение определяемой величины Xизм с некоторой погрешностью |
X. |
|||
|
Это значит, что действительное значение лежит в интервале |
||||
|
(Xизм − X) < Xi < (Xизм + |
X), |
|||
|
где Xизм – значение величины Xi, полученное при измерении; |
X – характеризует точность изме- |
|||
|
рения Xi. Величину X называют абсолютной погрешностью, с которой определяется Xi. |
||||
|
0тносительная погрешность |
||||
|
Качество результатов измерений удобно характеризовать не абсолютной величиной ошибки |
X, |
|||
|
а ее отношением к измеряемой величине X/X, которое называют относительной ошибкой и обычно |
||||
|
выражают в процентах |
X |
|||
|
E = |
100%. |
|||
|
X0 |
Классы точности приборов
Для характеристики большинства измерительных приборов часто используют понятие приведенной погрешности Eп (класса точности).
Приведенная погрешность Eп – это отношение абсолютной погрешности X к предельному значению Xmax величины, измеряемому данным прибором
Eп = X 100%.
Xmax
По приведенной погрешности приборы делятся на семь классов: 0.1; 0.2; 0.5; 1.0; 1.5; 2.5; 4. Приборы класса точности 0.1; 0.2; 0.5 применяют для точных лабораторных измерений (прецизионные). В технике применяют приборы классов 1.0; 1.5; 2.5; 4 (технические). Приборы, у которых значение класса выше 4, считаются индикаторами, т. к. об измерениях ими с какой-либо приемлемой точно-
стью речь не идёт. Класс точности прибора указывается на его шкале и означает его погрешность, выраженную в процентах от максимального значения на ней.
Погрешности цифровых приборов обычно указываются в их технической документации. Если таковая отсутствует, то величину ошибки можно определить следующим образом. Для измерительных (прецизионных) приборов она составляет 1/2 от единицы наименьшего разряда в данном
диапазоне (поскольку такие приборы, как правило, являются многопредельными). Т. е., если мы имеем вольтметр, который измеряет значения напряжения в интервале от −9.999 В до +9.999 В, то его погрешность будет равна ±0.0005 В. Для приборов технического класса величина погрешности
принимается в единицу наименьшего разряда, для вольтметра с таким же диапазоном она будет равна ±0.001 В.
Для приборов, класс точности которых не указан, принято считать, что их погрешность равна половине точности.
Систематическая погрешность
Одной из основных забот при производстве измерений должны быть учет и исключение систематических ошибок, которые в ряде случаев могут быть так велики, что совершенно исказят результаты измерений. Ошибки, величина которых одинакова во всех измерениях, проводящихся одним и тем же методом с помощью одних и тех же измерительных приборов, называются систематическими.
Систематические ошибки можно разделить на три группы:
Группа 1 — ошибки, природа которых известна и величина может быть достаточно точно определена. Их можно в дальнейшем учесть и исключить, скорректировав конечный результат. Такие ошибки называются поправками. При определении длины к поправкам относятся, например, удлинение, обусловленное изменением температуры измеряемого тела и измерительной линейки. Источники таких ошибок нужно тщательно анализировать, величины поправок определять и учитывать в окончательном результате. Величина поправок, которые есть смысл вводить, устанавливается в зависимости от величин других ошибок, сопровождающих измерение. Также к таким ошибкам относятся случаи, когда отсчёт измерения приходится вести не от нулевого значения шкалы прибора.
Группа 2 — ошибки известного происхождения, но неизвестной величины, их ещё называют инструментальными. К их числу относится погрешность измерительных приборов, которая определяется классом точности или иным способом. Если на приборе указан класс точности 0.5, то это означает, что показания прибора правильны с точностью до 0.5 процентов от всей действующей шкалы прибора. Иначе говоря, вольтметр с пределом измерения до 150 В и классом точности 0.5 дает ошибку в измерении напряжения не более 0.75 В. Очевидно, что нет ни-
какого смысла пытаться с помощью такого вольтметра измерять напряжение с точностью до 0.01 В. В отличие от первой группы, эти систематические ошибки не могут быть исключены,
но их наибольшее значение, как правило, известно, и если мы, измеряя напряжение с помощью вышеуказанного вольтметра, получили U = 65.3 В, то следует писать U = 65.30 ± 0.75 В.
Больше ничего о величине сказать невозможно.
Группа 3 — самые опасные ошибки, о существовании которых мы не подозреваем, хотя их величина может быть очень значительна. Такие ошибки возникают, например, при измерении напряжения на высокоомной нагрузке с помощью вольтметра, входное сопротивление которого одного порядка с сопротивлением нагрузки. Для устранения ошибок третьей группы нужно всегда очень аккуратно продумывать методику измерений, тщательно учитывать параметры приборов, и чем сложнее опыт, тем больше оснований думать, что какой-то источник систематических погрешностей остался неучтенным.
Случайная погрешность
Погрешности, величина которых различна даже для измерений, выполненных одинаковым образом. Случайные ошибки обязаны своим происхождением ряду причин, действие которых неодинаково в каждом опыте и не может быть учтено. Источниками случайных ошибок при физических измерениях могут являться, например, случайные изменения питающих напряжений, колебания температуры.
Промахи
Случайные погрешности, источником которых является недостаток внимания экспериментатора, называются промахами. Для устранения промахов нужно соблюдать аккуратность и тщательность в работе и записях результатов. Иногда можно выявить промах, повторив измерение в несколько отличных условиях, например перейдя на другой участок шкалы прибора.
Вероятность случайного события
Случайными называются такие события, о появлении которых не может быть сделано точного предсказания. Характеристикой частоты появления случайного события является его вероятность. Если возможно n благоприятных и m неблагоприятных событий, то вероятность благоприятного
|
события равна |
||||
|
P (n) = |
n |
= α, |
(1.1) |
|
|
m + n |
||||
|
а неблагоприятного |
m |
|||
|
(1.2) |
||||
|
P (m) = 1 − P (n) = |
. |
|||
|
m + n |
Средняя квадратичная и средняя арифметическая ошибки
Для того чтобы выявить случайную ошибку измерений, необходимо повторить измерение несколько раз. Если каждое измерение дает несколько отличные от других измерений результаты, мы имеем дело с ситуацией, когда случайная ошибка играет существенную роль.
Рис. 1.1. Форма кривой Гаусса
В подавляющем большинстве простых измерений случайные ошибки подчиняются следующим закономерностям:
1)Ошибки измерений Xi могут принимать непрерывный ряд значений.
2)При большом числе наблюдений ошибки одинаковой величины, но разного знака встречаются одинаково часто.
3)Частота появления ошибок уменьшается с увеличением величины ошибки. Иначе говоря, большие ошибки наблюдаются реже, чем малые.
Закон распределения ошибок описывается формулой Гаусса
|
1 |
( |
−x)2 |
|||||
|
e− |
x |
||||||
|
Y (x) = |
√ |
, |
(1.3) |
||||
|
2σ2 |
|||||||
|
σ |
2π |
где Y (x) – плотность распределения случайной величины x (плотность вероятности), x – среднее значение величины x, σ – дисперсия измерений. Величина σ характеризует степень влияния случайных погрешностей на результаты измерений. Чем меньше σ, тем точнее проведено измерение.
Более подробная информация о распределении Гаусса содержится в Приложении Г. Форма кривой Гаусса показана на рис. 1.1.
Вообще говоря, дисперсия – очень важное понятие, которое используется при математической обработке физических измерений. Её величина определяется на каждом шаге итерации, и, сравнивая текущее и предыдущее значения σ2, можно управлять выбором расчётных параметров, с тем
чтобы быстро привести результат вычислений к заданному уровню точности.
Чаще всего ошибкой измерения называют среднюю квадратичную погрешность. Различают среднюю квадратичную погрешность единичного измерения и среднюю квадратичную погрешность среднего арифметического. Средняя квадратичная погрешность единичного измерения (стандартное отклонение) имеет вид:
|
v |
n |
( |
xi)2 |
||||||||||||
|
x |
− |
||||||||||||||
|
u i=1 |
|||||||||||||||
|
Sn = u |
X |
, |
(1.4) |
||||||||||||
|
n |
1 |
||||||||||||||
|
u |
|||||||||||||||
|
u |
|||||||||||||||
|
n |
t |
− |
|||||||||||||
|
xi |
|||||||||||||||
|
i=1 |
|||||||||||||||
|
где x = |
X |
— среднее арифметическое. |
|||||||||||||
|
n |
Примечание. Многие программы обработки данных имеют встроенную функцию для вычисления стандартного отклонения. К примеру в пакете MS Excel эта функция называется СТАНДОТКЛ, в Open O ce Calc и Libre O ce Calc – STDDIV, в MATLAB и его клонах (Octave, Scilab, FreeMat, O-Matrix и т. п.) – std(x), где “x” – массив данных.

|
1.1. Краткая теория |
5 |
|||||||||||
|
Средняя квадратичная погрешность среднего арифметического: |
||||||||||||
|
v |
n |
( |
− xi)2 |
|||||||||
|
Sn |
x |
|||||||||||
|
u i=1 |
||||||||||||
|
√n |
u |
|||||||||||
|
u |
n(n |
− |
1) |
|||||||||
|
Sn,x = |
= |
u |
X |
. |
(1.5) |
|||||||
|
t |
Если число наблюдений очень велико, то величина Sn стремится к σ.
σ = lim Sn.
n→∞
Собственно говоря, именно этот предел и называется средней квадратичной ошибкой. Квадрат этой величины называется дисперсией измерений. Иногда применяется среднеарифметическая ошибка:
|
Zn = |
n |
. |
(1.6) |
||
|
X |
|||||
|
| |
x |
− xi| |
|||
|
i=1 |
|||||
|
n |
|||||
|
Значение средней арифметической ошибки ρ определяется соотношением: |
|||||
|
ρ = |
lim Zn. |
(1.7) |
|||
|
n→∞ |
При достаточно большом числе наблюдений (практически n > 30) существуют зависимости Sn =
1.25Zn или Zn = 0.8Sn.
Предположим, что значение измеряемой величины равно x . Ее среднее арифметическое значение, полученное в результате серии измерений, равно x , а погрешность измерений этой величины Δx . Вероятность α того, что результат измерений отличается от среднего значения на величину, не
|
большую, чем x |
|||||||||
|
α = P [( |
− x) < x < ( |
+ x)], |
(1.8) |
||||||
|
x |
x |
||||||||
|
носит название доверительной вероятности. Интервал значений от |
− |
x до |
+ x назы- |
||||||
|
x |
x |
вается доверительным интервалом. Выражение (1.8) означает, что с вероятностью, равной α, результат измерений не выходит за пределы доверительного интервала (x − x) ÷ (x + x). Разу-
меется, для большей доверительной вероятности большим получается и доверительный интервал. Для любой величины доверительного интервала по формуле Гаусса может быть рассчитана соответствующая доверительная вероятность. Эти вычисления были проделаны, и их результаты
сведены в таблицу Д.1 (Приложение Д). Приведем примеры пользования таблицей Д.1.
1. Пусть для некоторого ряда измерений получены х = 1.27; σ = 0.032.
Какова вероятность α того, что результат отдельного измерения не выйдет за пределы, определяе-
мые неравенством
1.26 < xi < 1.28.
Доверительные границы равны ±0.01, что составляет в долях σ
0.01/0.032 = 0.31 = ε.
Из таблицы Д.1 находим, что доверительная вероятность для ε = 0.3 равна 0.24. Иначе говоря, примерно 1/4 измерений уложится в интервал ошибок ±0.01.
2. Какой доверительный интервал нужно выбрать для тех же измерений, чтобы примерно 98%
результатов попали в него?
Из таблицы Д.1 находим, что значению α = 0.98 соответствует значение ε = 2.4, следовательно, X = σε = 0.032· 2.4 ≈ 0.077 и указанной доверительной вероятности соответствует интервал
1.193 < x < 1.347,
или, округляя,
1.19 < x < 1.35.
Результат записывают в виде
х = 1.27 ± 0.08.
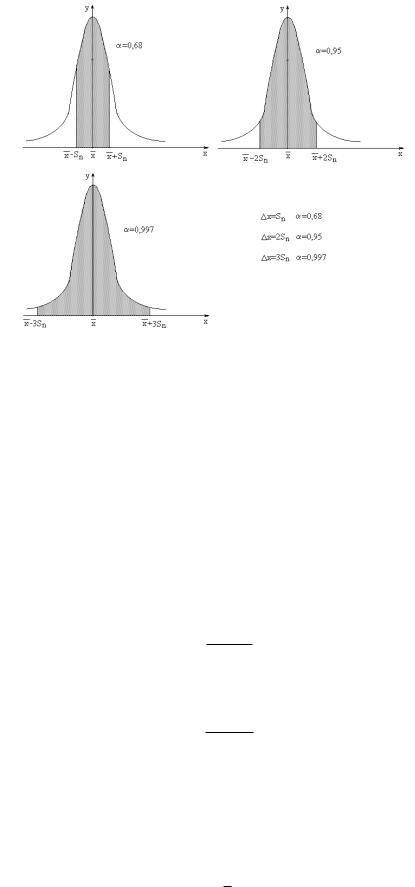
Рис. 1.2. Типовые значения доверительной вероятности при доверительном интервале x = Sn, x = 2Sn и x = 3Sn
с указанием доверительной вероятности α = 0.98.
Таким образом, для нахождения случайной ошибки нужно определить два числа: доверительный интервал (величину ошибки) и доверительную вероятность.
Для погрешности x = Sn доверительная вероятность α будет составлять 0.68. Для x = 2Sn
– 0.9, и для x = 3Sn – 0.997 (см. рис. 1.2). Приведенные здесь три значения α полезно помнить,
так как обычно, когда в книгах или статьях дается значение средней квадратичной ошибки, уже не указывается соответствующая ей доверительная вероятность.
Закон сложения случайных ошибок
Если измеряемая величина z является суммой (или разностью) двух величин x и y, результаты измерений которых независимы, тогда дисперсии Sz этих величин связаны соотношением
|
Sz2 = Sx2 + Sy2 |
|
|
или |
|
|
Sz = qSx2 + Sy2, |
(1.9) |
т. е. средняя квадратичная ошибка суммы (или разности) двух (или нескольких величин) независимых величин равна квадратному корню из суммы средних квадратичных ошибок отдельных слагаемых. Для средних арифметических ошибок закон сложения будет тот же самый
q
Zz = Zx2 + Zy2. (1.10)
Из закона сложения ошибок следуют два чрезвычайно важных вывода:
а) Вклад отдельных ошибок очень быстро падает по мере их уменьшения. Этот вывод всегда нужно иметь в виду и при повышении точности измерений в первую очередь уменьшать ошибку, имеющую большую величину.
б) Средняя квадратичная погрешность среднего арифметического равна средней квадратичной погрешности отдельного результата, деленной на корень квадратный из числа измерений n
Это фундаментальный закон возрастания точности при росте числа наблюдений. Разумеется, это рассуждение относится лишь к измерениям, при которых точность результата полностью определяется случайной ошибкой.
1.1.3.Определение доверительного интервала и доверительной вероятности
Очевидно, важно знать, насколько может уклоняться от истинного значения x0 среднее арифметическое х измерений. Для этого можно воспользоваться таблицей Д.1, взяв вместо величины σxi
|
величину σxср , т. е. |
σxi |
|||||||
|
σxср |
= √ |
. |
(1.12) |
|||||
|
n |
||||||||
|
Тогда для аргумента ε, который используется в таблице Д.1, справедлива зависимость |
||||||||
|
x |
x√ |
|||||||
|
ε = |
= |
n |
(1.13) |
|||||
|
σxcр |
σxi |
|||||||
При применении формул (1.12) и (1.13) считается известной средняя квадратичная погрешность σ. Для того чтобы определить последнюю, нужно сделать очень много измерений, что не всегда
возможно и удобно. В тех случаях, когда выполняются измерения с помощью уже хорошо исследованного метода, ошибки которого известны, заранее известна и величина σ. Однако, как правило,
погрешность метода приходится определять в процессе измерений. Обычно можно определить только величину Sn, соответствующую сравнительно небольшому числу измерений (см. формулу 1.4). Если для оценки доверительной вероятности α считать, что Sn совпадает с σ, и пользоваться таблицей Д.1, то получаются неверные значения α.
|
Чтобы учесть это обстоятельство, интервал |
x можно представить в виде: |
||||||
|
tα,nSn |
|||||||
|
x = |
√ |
, |
|||||
|
n |
|||||||
|
откуда |
x√ |
||||||
|
tα,n = |
n |
. |
(1.14) |
||||
|
Sn |
|||||||
Из формулы (1.14) видно, что tα,n – величина, аналогичная ε. Она играет ту же роль, но в случае, когда число измерений, из которых определена ошибка Sn, не очень велико. Значения величины tα,n, носящей название коэффициента Стьюдента, вычислены для различных значений n и α приведены
в таблице Д.2 (Приложение Д).
Сравнивая приведенные в ней данные с табл. Д.1, легко убедиться, что при больших n величины tα,n стремятся к соответствующим значениям ε. С увеличением n, Sn стремится к σ. Используя
коэффициенты Стьюдента, равенство (1.8) можно переписать в виде
|
P « |
x − tα,n √n |
< x < |
x + tα,n √n |
# |
= α. |
(1.15) |
||
|
Sn |
Sn |
Пользуясь этим соотношением и таблицей Д.2, легко определить доверительные интервалы и доверительные вероятности при любом небольшом числе измерений.
Пример. Среднее арифметическое x из 5 измерений равно 31.2. Средняя квадратичная ошибка, определенная из этих 5 измерений, равна 0.24. Найти доверительную вероятность того, что x отличается от истинного значения х не более чем на 0.2, так как будет выполняться неравенство
31 < x < 31.4.
Значение tα,n найдем, подставив наши величины в формулу (1.14):
√
tα,n = 0.2 × 5 = 1.86. 0.24
По таблице Д.2 находим для n = 5 при tα,n = 1.5 , α = 0.8; при tα,n = 2.1 α = 0, 9. Вообще говоря,
можно удовлетвориться ответом, что доверительная вероятность для этого случая лежит между 0.8 и 0.9. Если необходимо получить более точное значение, применяют метод интерполяции. В рассматриваемом примере получается α = 0, 86.

1.1.4. Погрешность определения погрешности
Если средняя квадратичная ошибка Sn определяется из очень большого числа измерений, то получается величина, как угодно мало отличающаяся от своего предельного значения σ. Но когда n невелико, то Sn отягчена случайными погрешностями. Для определения доверительного интервала, в котором находится σ при заданной доверительной вероятности α, пользуются таблицей Д.3
(Приложение Д) в соответствии с алгоритмом
P γ1Sn < σ < γ2Sn = α. (1.16)
Приведем два примера пользования таблицей Д.3.
1. Средняя квадратичная погрешность, определенная из 5 измерений, равна 2. Нужно вычислить доверительный интервал для σ с надежностью 0, 95.
Из таблицы Д.3 имеем для n = 5 и α = 0.95, γ1 = 0, 599 и γ2 = 2, 87. Для σ можно записать неравенство, выполняемое с вероятностью 0.95
0.599 × 2 < σ < 2.87 × 2 или 1.2 < σ < 5.7.
2. При 40 измерениях γ1 = 0.821, γ2 = 1.28
1.6 < σ < 2.6.
По сравнению с первым случаем здесь интервал значительно уже´ и почти симметричный.
1.1.5. Необходимое число измерений
Для уменьшения случайной ошибки результата могут быть использованы два пути: улучшение точности измерений, т. е. уменьшение σ, и увеличение числа измерений, т. е. использование
соотношения, аналогичного (1.12):
Предположим, что все возможности совершенствования техники измерений (т. е. первый путь) уже исчерпаны. Пусть систематическая ошибка измерений равна δ. Известно, что уменьшать случай-
ную ошибку целесообразно до тех пор, пока общая погрешность измерений не будет полностью определяться систематической ошибкой. Практически должно выполняться требование
|
x 6 |
δ |
или даже |
x 6 |
δ |
, |
||
|
3 |
2 |
||||||
где x – полуширина доверительного интервала для величины σ. Надежность α, с которой требуется установить доверительный интервал, в большинстве случаев не должна превышать 0, 95. Для оценки необходимого числа измерений приведена таблица Д.5 (Приложение Д), в которой x дано
в долях средней квадратичной ошибки.
Пример. Измеряется напряжение с помощью вольтметра, имеющего погрешность в 1 В. Средняя квадратичная погрешность измерений равна 2.3 В. Сколько измерений нужно проделать, чтобы получить ошибку не более 1.5 В с надежностью 0.95?
Положим
|
x = |
δ |
, Sn = 2.3 B, |
x |
= |
0.5 |
= 0.22. |
|
2 |
Sn |
2.3 |
Из таблицы Д.5 находим в колонке α = 0.95 для ε = 0.3, n = 46 и для ε = 0.2, n = 99. Методом
интерполяции определяем, что для
|
ε = |
x |
= 0.22 |
|
Sn |
||
|
получается n = 88. |

1.1.6. Обнаружение промахов
Если осуществляется ряд одинаковых измерений, подверженных случайным ошибкам, то в этом ряду могут встретиться измерения с очень большими случайными ошибками. Однако большие ошибки имеют малую вероятность, и если среди результатов измерений встретится одно, имеющее резко отличное от других значение, то мы будем склонны приписать такой результат промаху и отбросить его как заведомо неверный. Естественно, следует объективно оценить, является ли данное измерение промахом или же результатом случайного, но совершенно закономерного отклонения.
Для оценки вероятности β случайного появления выскакивающих значений в ряду n измерений (для n < 25) на основании результатов, даваемых теорией вероятностей, была составлена таблица Д.4 (Приложение Д). При пользовании этой таблицей вычисляется среднее арифметическое x и средняя квадратичная погрешность Sn всех измерений, включая подозреваемое xk, которое, на
наш взгляд, недопустимо велико или мало.
Вычисляется относительное уклонение этого измерения от среднего арифметического, выраженное в долях средней квадратичной ошибки
|
max |
Sn |
||||||
|
Θ |
= |
x − xk |
. |
(1.18) |
|||
По таблице Д.4 находится, какой вероятности β соответствует полученное значение Θmax. Разумеется, следует договориться, при каких значениях β будет отбрасываться (считаться промахом) измерение. Таблица Д.4 составлена так, что наименьшее значение β = 0.01. Оставлять измерения,
вероятность появления которых меньше этой величины, обычно нецелесообразно.
Пример. Среднее арифметическое значение измеряемой величины, полученное из 15 измерений, равно 257.1, средняя квадратичная погрешность Sn = 2.6. Определить, является ли промахом одно из измерений, равное 266.0.
Находим:
Θmax = 266 − 257.1 = 3.42. 2.6
Наибольшее значение Θmax для n = 15, приведенное в таблице Д.4, равно 2.8, чему соответствует β = 0.01. Так как с ростом Θmax соответствующее значение β уменьшается, то при Θmax = 3.42 должно быть значительно меньше 0.01. Из того, что β 0.01, следует, что результат 266 надо
отбросить, считая его промахом.
Если вероятность появления данного измерения в ряду лежит в промежутке 0.1 > β > 0.01,
то представляется одинаково правильным как оставить это измерение, так и отбросить. Решая вопрос об отбрасывании выскакивающего измерения, полезно посмотреть, как сильно оно меняет окончательный результат.
В тех случаях, когда β выходит за указанные пределы, вопрос об отбрасывании решается просто. При n, большем 25, оценку β можно производить с помощью соотношения:
Здесь α – доверительная вероятность, определяемая для нормального распределения (α берется из таблицы Д.1, полагая Sn = σ).
1.1.7. Учёт систематической и случайной ошибки
Измерения следует проводить так, чтобы погрешность результата целиком определялась систематической ошибкой измерений, которая обычно задается погрешностью измерительного прибора. Для этого следует определенным образом выбирать необходимое число измерений. Однако это не всегда удается сделать. В результате часто приходится мириться с положением, когда систематическая и случайная ошибки измерений соизмеримы друг с другом, и они обе в одинаковой степени определяют точность результата. При этом в качестве верхней границы суммарной ошибки можно принять
где δ – систематическая ошибка, σ – среднеквадратичная ошибка. Данная оценка верна с вероятностью не менее 0.95.
Соседние файлы в предмете Механика
- #
- #
- #
- #
- #
- #
Отклонения результатов измерения $x$ от истинного значения
$x_0$ (которое обычно неизвестно) называют ошибками
измерения $|x — x_0|.$
Ошибки измерений принято разделять на две группы: систематические и
случайные (или статистические) ошибки.
Теория ошибок справедлива только для случайных ошибок. Рассмотрим наиболее простой случай,
когда одна и та же физическая величина измеряется $N$ раз.
Если измеряемая величина $x$ изменяется непрерывно, то область полученных значений разделяют на некоторое
количество интервалов одинаковой ширины $Delta x$ и, далее, определяют количество измерений,
попавших в каждый из этих интервалов ($x_i pm frac 12 Delta x$). Такое частотное
распределение представляют с помощью диаграммы (гистограммы).
Для описания серий измерений удобно вместо
$N_i$ — количества результатов,
попавших в класс $x_i$ ввести относительные частоты
$n_i = frac{N_i}{N},$ нормированные на единицу.
При увеличении числа измерений $n$ это
распределение стремится к теоретическому распределению
вероятностей, которое характеризует результаты бесконечного числа опытов. Существование теоретического
распределения вероятностей является
основополагающим предположением теории ошибок, которое,
строго говоря, нельзя проверить экспериментально.
Математически предел при $Nto infty$ для каждого класса $x_i$
выражается в виде
$$
P(x_i)=limlimits_{nto infty}frac{N_i}{N}; hspace{10pt} sum_{i}P(x_i)=1.
$$
Величина $P$ есть не что иное, как вероятность попадания измеряемого значения в $i$–тый интервал при одном измерении.
Теоретическое распределение вероятностей переходит при $Delta xto 0$ в гладкую кривую. Вероятность
попадания исхода одного измерения $x$ в интервал $Delta x$ равна $p(x)Delta x.$ Функцию $p(x)$ называют плотностью вероятности. Вероятность $P$ попадания результата
измерения в интервал $[x_1,x_2]$ равна
$$
P(x_1leqslant xleqslant x_2)=int limits_{x_1}^{x_2} p(x), dx.
$$
Вероятность попадания исхода одного измерения в
область от $-infty$ до $x$ в математической
статистике называют функцией распределения $F(x):$
$$
F(x)=int limits_{-infty}^{x} p(xi), dxi.
$$
Теоретическая функция распределения в сжатой форме содержит
всю информацию, которую можно получить из опыта, в том числе и истинное значение измеряемой
величины $x_0.$ Эту величину для дискретного распределения значений $x$ называют арифметическим
средним $E:$
$$
x_0=overline{x}=E(x)=sum_{i}x_iP(x_i),
$$
а в случае непрерывного распределения:
$$
x_0=overline{x}=E(x)=int limits_{- infty}^{infty} xp(x), dx
=int limits_{- infty}^{infty} x, dF(x).
$$
Если сравнивать результаты нескольких серий измерений одной и той же физической
величины, то наиболее точное значение будет получено в той серии, в которой кривая распределения
будет самой узкой. Чем уже кривая распределения,
тем меньше ошибка $delta = x- x_0$ отдельного измерения,
поэтому целесообразно характеризовать распределение вероятностей не только средним значением $x_0$, но и
шириной кривой распределения. Арифметическое
среднее ошибки $delta $ для этого не подходит, поскольку
оно в точности равно нулю. Для этой цели выбирают
математическое ожидание квадрата ошибки $sigma ^2,$
которое называют дисперсией
$$
sigma ^2=E(delta ^2)= int limits_{- infty}^{infty} delta ^2 p(x), dx=
int limits_{- infty}^{infty} (x-x_0)^2p(x), dx.
$$
Квадратный корень из дисперсии $sigma = sqrt{sigma ^2}$ называют средним квадратичным
отклонением распределения. Оно непосредственно характеризует ширину распределения
вероятностей — разброс измеряемых значений:
$$
sigma ^2=overline{x^2}-overline{x}^2.
$$
Наилучшим приближением истинной величины х
является так называемое выборочное среднее
значение
$$
overline{x}_N=frac 1N sum_{i=1}^{N}x_i.
$$
Вводя выборочную дисперсию $s ^2_N$,
которая определяется как среднее значение квадрата отклонений $(x_i-overline{x}_N)$ (Здесь не может идти речь об истинной ошибке
поскольку не известно истинное значение $overline{x}$):
$$
s_N^2=frac 1{N-1} sum_{i=1}^{N}(x_i-overline{x}_N)^2.
$$
Квадратный корень из выборочной дисперсии
называют выборочным стандартным отклонением $s_N.$
Оно характеризует разброс отдельных результатов
измерений вблизи среднего значения и является
наилучшей оценкой среднеквадратичного отклонения $sigma $
генеральной совокупности, которое можно определить
по выборке из $N$ результатов.
Для практического расчета выборочной дисперсии пользуются формулой:
$$
s^2_N=frac 1{N-1}left( sum_{i=1}^{N} x_i^2-frac 1N left(sum_{i=1}^{N} x_iright)^2 right) .
$$
Кроме среднего значения результатов измерений экспериментатора интересует еще и его точность. Мы
можем определить ее, несколько раз повторяя серии по $n$ измерений. Тогда величины математических
ожиданий $overline{x}_N$ образуют распределение, стандартное
отклонение которого $s_{overline{x}}$ будет характеризовать разброс
средних значений $overline{x}_N$ от выборки к выборке. Поэтому
величину $s_{overline{x}}$ называют стандартным отклонением
выборочного среднего (или его средней ошибкой).
Пользуясь законом сложения ошибок получим
$$
s_{overline{x}}=frac{s_N}{sqrt{N}}=sqrt{frac{sum_{i=1}^{N}(x_i-overline{x}_N)^2}{N(N-1)}}.
$$
Стандартное отклонение среднего, полученного по
$N$ измерениям, отличается в $frac 1{sqrt{N}}$ раз от стандартного
отклонения отдельного измерения. Таким образом,
точность измерений достаточно медленно растет с
увеличением количества измерений при больших $N.$
Поэтому нужно стремиться не к увеличению
количества опытов, а к улучшению измерительных методов,
которые позволят уменьшить стандартные отклонения
$s_N$ отдельного измерения.
На практике могут реализовываться различные распределения вероятностей, мы рассмотрим нормальное распределение которое было найдено
К. Ф. Гауссом. Важная роль гауссова распределения объясняется тем, что, с одной стороны, оно хорошо описывает плотность вероятностей для многих, кроме того, многие другие распределения переходят в предельном случае в нормальное распределение.
Плотность вероятностей для случайной переменной $x$, меняющейся в пределах от $-infty $ до $infty $ имеет вид
$$
p(x,x_0,sigma )=frac 1{sigma sqrt{2pi}} text{exp}left( -frac{(x-x_0)^2}{2sigma ^2}right).
$$
Для описания функции распределения
$$
F(x)=frac 1{sigma sqrt{2pi}}intlimits_{-infty}^{x} text{exp}left( -frac{(z-x_0)^2}{2sigma ^2}right) , dz.
$$
используют функцию ошибок (интеграл ошибок Гаусса)
$$
text{erf}(t)=frac 2{ sqrt{pi}}intlimits_{0}^{t} text{exp}left( -z^2right) , dz
$$
так, что
$$
F(x)=frac 12 left(1+text{erf}left(frac{x-x_0}{sigma sqrt{2}}right)right).
$$
Вероятность того, что случайная переменная $x$, распределенная по нормальному закону, попадет в интервал $[x_1, x_2],$ равна
$$
P(x_1leqslant xleqslant x_2)=F(x_2)-F(x_1)=frac 12 left(
text{erf}left(frac{x_2-x_0}{sigma sqrt{2}}right)-
text{erf}left(frac{x_1-x_0}{sigma sqrt{2}}right)
right).
$$
Величину $P(x_1leqslant xleqslant x_2),$ выраженную в процентах, называют также {bf статистической достоверностью}, например,
$P(x_0-sigmaleqslant xleqslant x_0+sigma) = 68,3%$, $P(x_0-2sigmaleqslant xleqslant x_0+2sigma ) = 95,5%$.
Введённые границы называют доверительными границами, а интервал — доверительным интервалом. Величина статистической достоверности в каждом конкретном случае зависит от требуемой надежности измерений.
Эмпирические средние являются случайной величиной и их поведение можно описать некоторой функцией распределения относительно величины математического ожидания со своей дисперсией $s_x$ и если $x$ определено из $n$ измерений, то
$$s_x^2=frac{sigma ^2}{n}.$$
К сожалению заранее $sigma $ неизвестна и, следовательно, выражение невозможно использовать. Вместо $sigma $ используется оценка среднего квадратичного отклонения $s_n$, а величину
$$s_x=frac{sigma _n}{sqrt{n}}$$
будем называть стандартной ошибкой, причём она, в отличие от стандартного отклонения $s_n$, уменьшается с ростом числа измерений пропорционально $frac{1}{sqrt{n}}$. По этой причине нет смысла увеличивать
количество измерений после того, как величина $s_x$ станет сравнима с величиной
систематической ошибки (или точности измерительного прибора).
В идеализированном случае, когда $sigma $ точно известна, можно задать необходимую
доверительную вероятность и по соотношению
$
2Phi(t) = P,
$
определить соответствующее значение верхнего предела
$
t = t(P)
$
и утверждать, что с вероятностью $P$ отклонение измеренного значения $overline{x}$ от истинного $x$ не превышает
$$
|overline{x}-x| <t(P)frac{sigma}{sqrt{n}}.
$$
В реальности дисперсия неизвестна, а величина
$$
t=frac{overline{x}-x}{frac{s_n}{sqrt{n}}}
$$
соответствует не закону нормального распределения, а распределению Стьюдента, переходящему при $nto infty$ в нормальное распределение.
Доверительная оценка при выбранном уровне статистической достоверности $P$
в принимает вид
$$
|overline{x}-x| <t(P,n-1)frac{s_n}{sqrt{n}}.
$$
Функция $t(P, n-1),$ называемая коэффициентом Стьюдента, зависит не только от $P$, но и от числа измерений $n.$ Таблицы значений
этого коэффициента для нескольких уровней доверительной вероятности (называемых еще уровнями надежности) $P$ и различных $n$ табулированы.
| Таблица коэффициентов Стьюдента | ||||
|---|---|---|---|---|
| $n-1$ | $P=68,3%$ | $P=95%$ | $P=99%$ | $P=99,73%$ |
| 1 | 1.8 | 12.7 | 67 | 235 |
| 2 | 1.32 | 4.70 | 9.9 | 19.2 |
| 3 | 1.20 | 31.18 | 5.8 | 9.2 |
| 4 | 1.15 | 2.78 | 4.6 | 6.6 |
| 5 | 1.11 | 2.57 | 4.0 | 5.5 |
| 6 | 1.09 | 2.45 | 3.7 | 4.9 |
| 7 | 1.08 | 2.37 | 3.5 | 4.5 |
| 8 | 1.07 | 2.31 | 3.4 | 4.3 |
| 9 | 1.06 | 2.26 | 3.2 | 4.1 |
| 10 | 1.05 | 2.23 | 3.2 | 4.0 |
| 15 | 1.03 | 2.13 | 3.0 | 3.6 |
| 20 | 1.03 | 2.09 | 2.8 | 3.4 |
| 30 | 1.02 | 2.04 | 2.8 | 3.3 |
| 50 | 1.01 | 2.01 | 2.7 | 3.2 |
| 100 | 1.00 | 1.98 | 2.6 | 3.1 |
| 200 | 1.00 | 1.97 | 2.6 | 3.0 |
| предел $nto infty$ | 1.00 | 1.96 | 2.58 | 3.0 |
При обработке результатов измерений предлагается следующий
порядок операций.
При прямых измерениях
-
Результаты каждого измерения записываются в таблицу.
-
Вычисляется среднее значение из $n$ измерений $$overline{x}=frac 1n sum_{i=1}^{n}x_i.$$
-
Находятся погрешности отдельного измерения $$Delta x_i=overline{x}-x_i$$ и вычисляются их квадраты $left(Delta x_i right)^2 .$
-
Определяется среднеквадратичная погрешность среднего арифметического $$ Delta S_{overline{x}}=sqrt{frac{sum_{i=1}^{n}left( Delta x_iright)^2 }{n(n-1)}}. $$
-
Задается значение надежности $alpha $ (обычно выбирают одно из стандартных значений — 0,68; 0,9; 0,95; 0,99; 0,995; 0,999, обычно выбирают 0,95).
-
Определяется коэффициент Стьюдента $t_{alpha n}$ для заданной надежности $alpha $ и числа произведенных измерений $n$ (по таблице).
-
Находится доверительный интервал (погрешность результата измерений): $$Delta x= t_{alpha n}cdot Delta S_{overline{x}}.$$
-
Если величина погрешности результата измерений $Delta x$ окажется сравнимой с величиной погрешности прибора $delta ,$ то в качестве границы доверительного интервала следует взять величину $$ Delta x =sqrt{left( t_{alpha n} Delta S_{overline{x}}right) ^2+delta ^2}. $$
-
Окончательный результат записывается в виде $$ x=overline{x}pm Delta x. $$
-
Оцените относительную погрешность результата измерений $$ varepsilon = frac{Delta x}{x}cdot 100%. $$